不定时更新,素材来自网络,都附注有超链接,侵删联系邮箱:zhenyu_li1998@163.com
数据量太大在线更新不方便,有需要的可以邮箱联系给原稿(typora文档)
我是2022届双非软件工程应届生,目前在准备秋招,总结了一篇的八股文,如果你正好需要可以关注一下,共同学习;善用Ctrl+F查找
CSDN已停止更新,可关注语雀,不间断更新 超链接:点击跳转![]() https://www.yuque.com/qietingfengyin-jxsea
https://www.yuque.com/qietingfengyin-jxsea
目录
Java基础知识
面向对象
接口
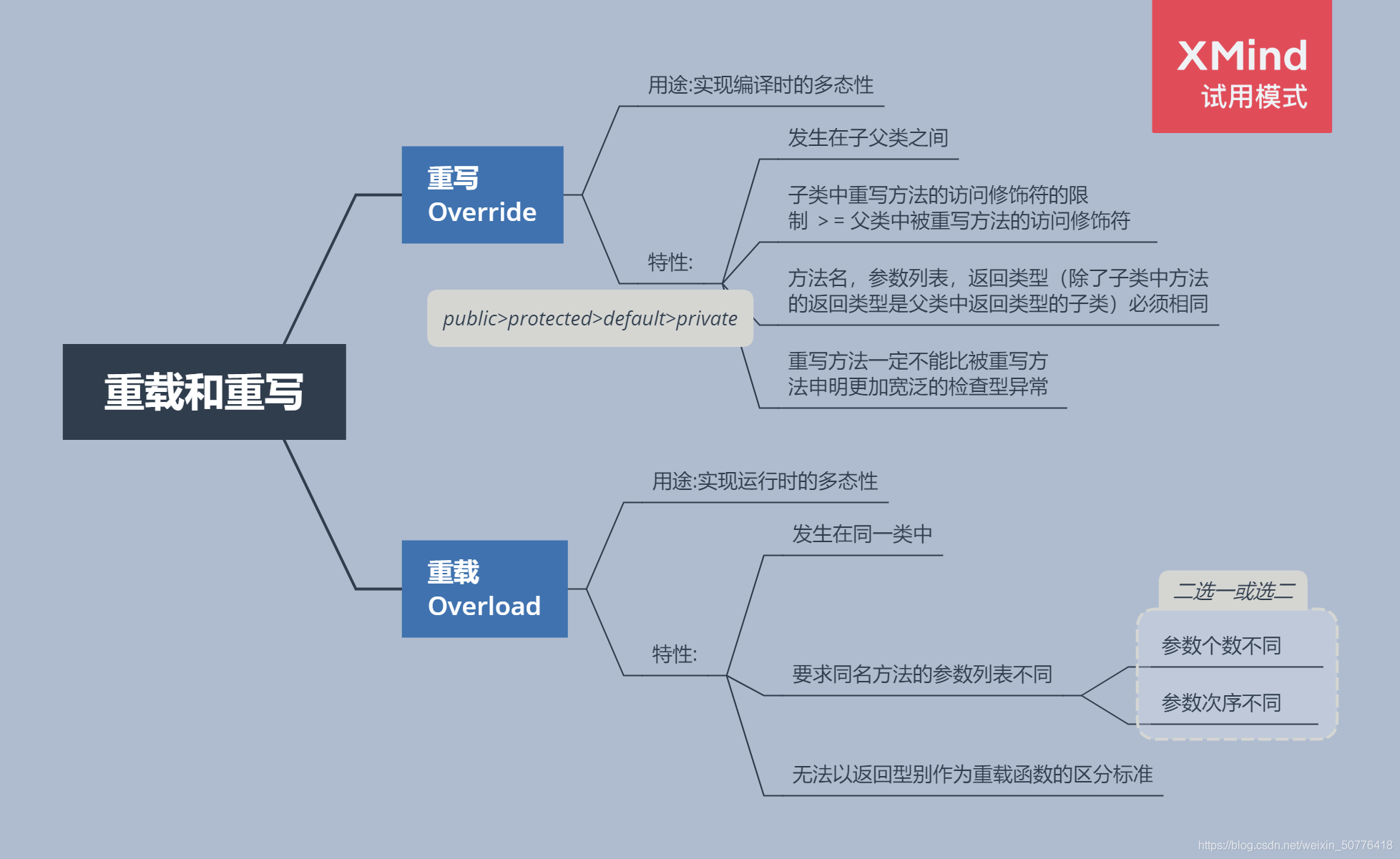
重写与重载
Java数据类型
局部变量与成员变量对于基本数据类型与引用类型的存储
什么是构造方法
类之间几种常见的关系
泛型
IO流
面向字符的流
BIO NIO AIO
适用场景
同步和异步
阻塞与非阻塞
同步阻塞与同步非阻塞
异步阻塞与异步非阻塞
数组初始化后默认值
反射
正则表达式
Java的位运算
JDK、JRE与JVM的关系
Java体系结构包括四个独立但相关的技术
关键字
标识符
权限修饰符
for 与 foreach
abstract 与 implement
switch
final
static
super
String、StringBuffer、StringBuilder
new String 与String
栈与堆的区别
==和equals比较
instanceof运算符
Scanner,BufferedReader,InputStreamReader 简介与对比
函数取值方法
集合
java.util.Collection [I]
List和Map区别
java.util.Map [I]
哪些集合类是线程安全的?
多线程
线程和进程区别
多进程和多线程区别
进程间通信和线程间通信区别
线程状态
守护线程和用户线程
进程状态
创建多线程
序列化
Thread与Runnable
执行流程
线程安全
线程池
异常处理
RuntimeException和非RuntimeException的区别
throw与throws
try catch }finally
死锁
常用方法
throw和throws区别
start与run方法
sleep与wait
volatile
发布与逸出
synchronized使用与原理
Sychronized的自旋锁、偏向锁、轻量级锁、重量级锁
synchronized与Lock的区别:
sychronized和ReentrantLock
CAS与synchronized的使用情景
乐观锁与悲观锁
多线程与事务
框架与后台传输
Spring 事务
AOP IOC
Spring装配Bean的两种方式:
Aspect Oriented Program 面向切面编程
IOC控制反转
applicationContext & BeanFactory区别
Bean 定义
Bean的生命周期
注解
@Bean
@Component
@ComponentScan
@Autowired
@Autowired 与@Resource的区别(详细)
@Configuration
forward与redirect
Servlet (了解)
状态码
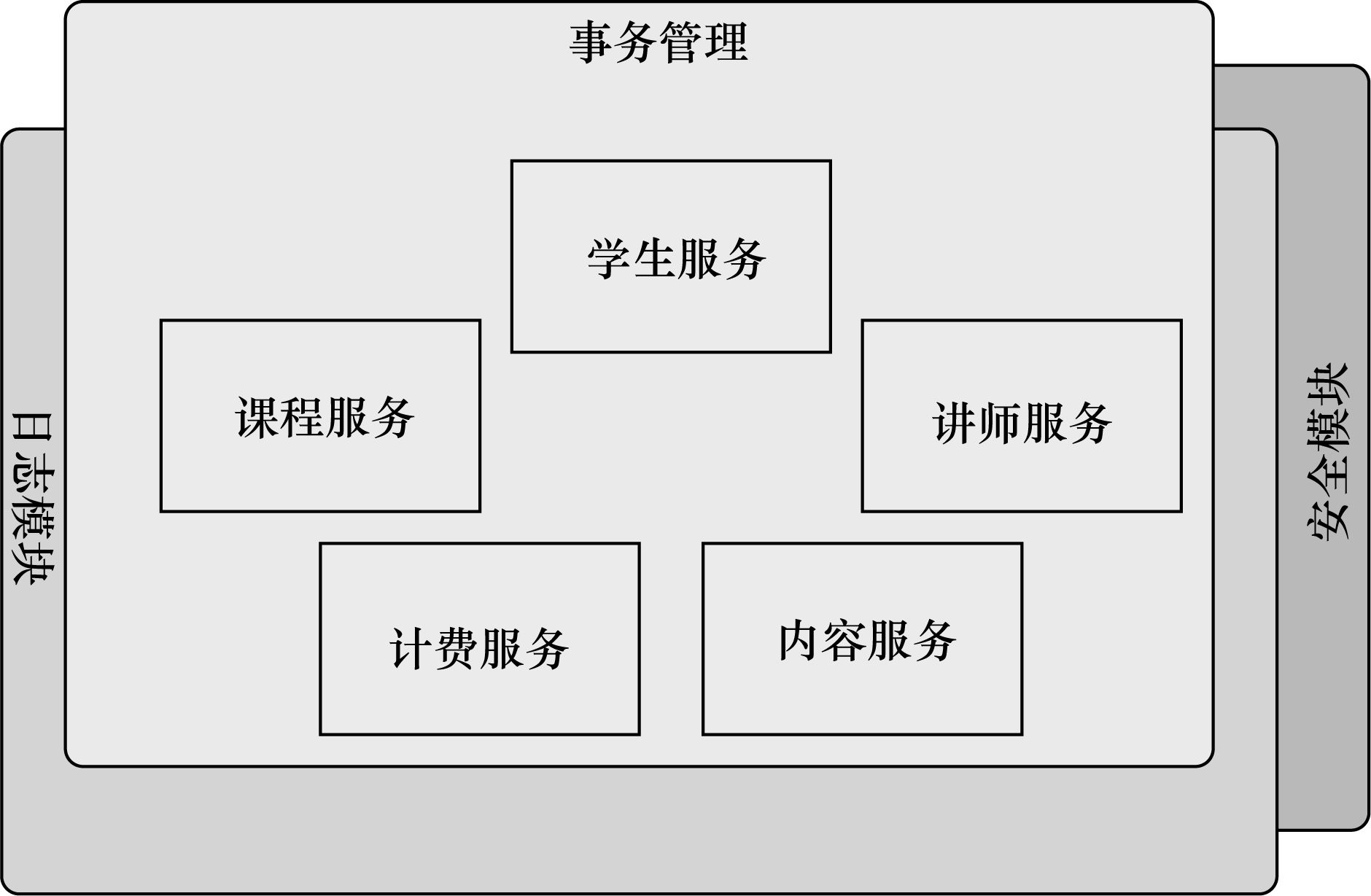
项目
验证码
图片上传
拦截器
1.实现HandlerInterceptor接口自定义拦截器
2.重写addInterceptor方法实例化LoginHandlerInterceptor
常用算法
基础概念
时间复杂度
什么是稳定排序
刷题算法
二分
贪心
冒泡改进版
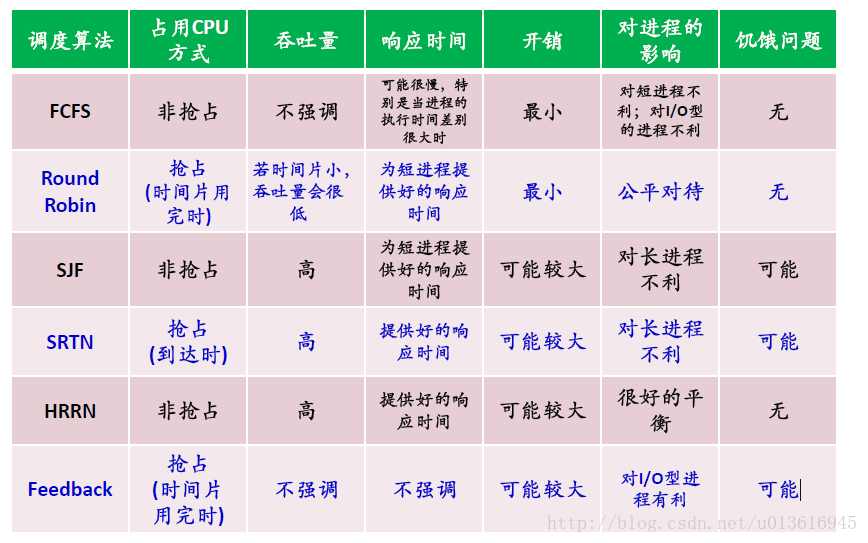
CPU调度算法
JVM
运行时数据区
java堆、栈、堆栈,常量池的区别
垃圾回收
什么是GC
GC收集器有哪些?
判断是否回收
垃圾收集算法
内存分配与回收
类加载机制
双亲委派
Java内存模型
数据库
NoSQL四大分类
Redis
数据类型
Redis是单线程
操作案例
MySQL
事务四大特性ACID
范式通俗理解
数据类型优化
执行SQL相关
索引
脏读、不可重复读、幻读
事务隔离级别
SQL注入
mybatis是如何做到防止sql注入的
MySQL连接数
MySQL的读写分离
设计模式
设计模式的六大原则
单例模式
1.懒汉式
2.懒汉式(加锁)
3.饿汉式
观察者模式
工厂模式
桥接模式
装饰者模式
生产者-消费者
计算机网络
访问一个网页的全过程
TCP与UDP
http与https
三次握手
get请求与post请求
Cookie 与 Session
Linux简单命令
创建进程
查询日志
查看进程
文件操作
ls — List
2.mkdir — Make Directory
3.pwd — Print Working Directory
4.cd — Change Directory
5.rmdir— Remove Directory
6. rm— Remove
7. cp— Copy
8. mv— Move
12.grep
13.find
14.tar
15. gzip
16. unzip
通过关键词查找文件
vim编辑机
yum 命令
yum 语法
yum常用命令
Git
git与svn
工作流程
具体使用
忽略上传
使用码云(gitee)上传
传统软件架构与互联网软件架构
传统行业
互联网行业
能力要求
行业关注点
待总结
Java基础知识
锁的实现原理
面向对象
面向对象基本概念 面向对象通俗举例蛋炒饭与盖饭
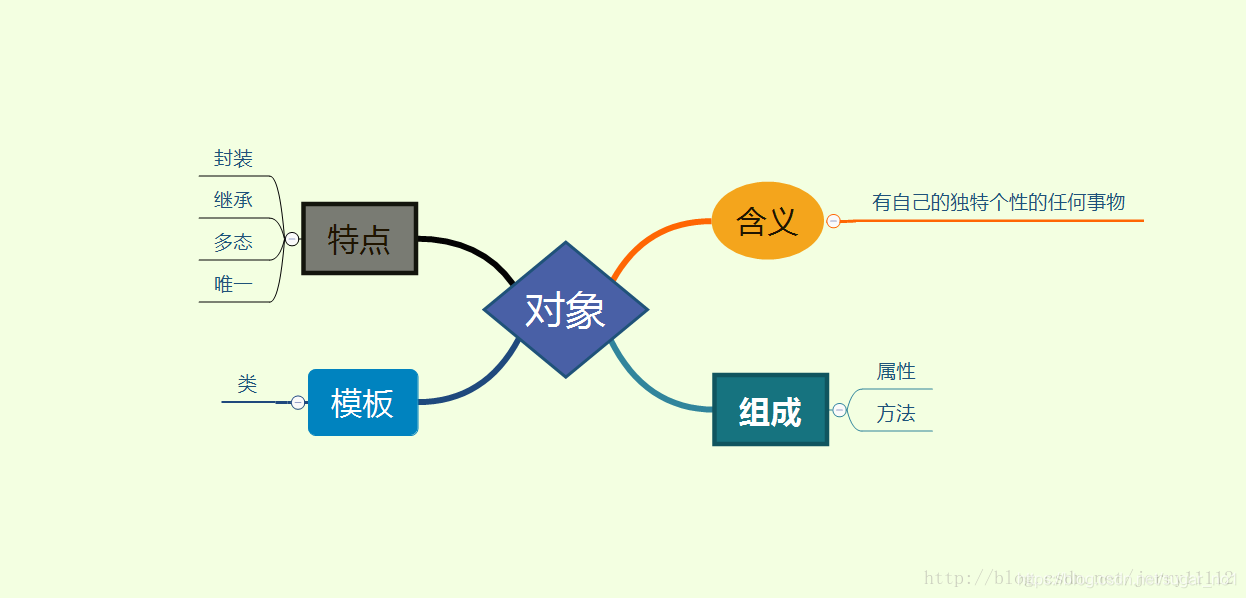
概论:面向对象是把一组数据结构和处理他们的方法组成对象;把具有相同行为的对象归纳成类;
通过封装隐藏类的内部细节;通过继承使类得到泛化;通过多态实现基于对象类型的动态分派
吃饭
-
面向过程:买菜,洗菜,做饭,洗手吃饭,洗碗
-
面向对象:点外卖,吃饭,扔外卖盒
两者区别:对比面向过程,面向对象更注重事情的每一个步骤及顺序,面向对象更注重事情有哪些参与者(对象),以及如何更好按需分配 面向对象更加易于复用,扩展和维护; 面向过程直接高效
面向过程优点:流程化使得编程任务明确,在开发之前基本考虑了实现方式和最终结果,具体步骤清楚,便于节点分析。
效率高,面向过程强调代码的短小精悍,善于结合数据结构来开发高效率的程序。
java是面向对象的,但是不是所有的都是对象,基本数据类型就不是对象,所以才会有封装类的;
封装:明确标识出允许外部使用的所有成员函数和数据项;内部细节对外部调用透明,外部调用无需修改或关心内部实现
1.JavaBean的属性私有,提供get set对外访问,因为属性的赋值或者获取逻辑只能由JavaBean本身决定,而不能由外部糊涂乱改
private String name;public void setName(String name){this.name = "java 是最好的语言"+name;}//该name有自己命名规则,明显不能由外部直接赋值
2.orm框架:操作系统库,我们不需要关心连接是如何建立的,sql如何执行,只需引入mybatis调方法即可
继承:继承基类方法,并做出自己的改变和/或扩展子类共性的方法或者直接使用父类的属性,而无需自己再定义,只需扩展自己个性化的;继承让变化中的软件系统有了一定的延续性,同时继承也是封装程序中可变因素的重要手段; 访问修饰符决定了是否可继承
多态:基于对象所属类的不同,外部相同类型变量对同一方法的调用,实际执行逻辑不同
继承,方法重写,父类引用指向子类对象 .前提条件:必须有子父类关系。
作用:提高了代码的扩充性和可维护性
牛客例题
父类类型 变量名 = new 子类对象变量名.方法名()
无法直接调用子类特有功能(需要向下转型)
-
多态的转型分为向上转型和向下转型两种
-
向上转型:多态本身就是向上转型过的过程使用格式:父类类型 变量名=new 子类类型();
适用场景:当不需要面对子类类型时,通过提高扩展性,或者使用父类的功能就能完成相应的操作。
-
向下转型:一个已经向上转型的子类对象可以使用强制类型转换的格式,将父类引用类型转为子类引用各类型使用格式:
子类类型 变量名=(子类类型) 父类类型的变量;适用场景:当要使用子类特有功能时。
成员变量:编译看左边,执行看左边; 成员方法:编译看左边,执行看右边。
向下转型可以调用子类类型中所有的成员,不过需要注意的是如果父类引用对象指向的是子类对象,那么在向下转型的过程中是安全的,也就是编译是不会出错误。但是如果父类引用对象是父类本身,那么在向下转型的过程中是不安全的,编译不会出错,但是运行时会出现我们开始提到的 Java 强制类型转换异常,一般使用 instanceof 运算符来避免出此类错误。
//安全的向下转型是先把子类对象向上转型为父类,再将该父类强制转换为子类Animal animal = new Cat();if (animal instanceof Cat) {Cat cat = (Cat) new animal(); // 向下转型...}
instanceof 是 Java 的保留关键字。它的作用是测试它左边的对象是否是它右边的类的实例,返回 boolean 的数据类型。二元运算符,左边是对象,右边是类;当对象是右边类或子类所创建对象时,返回true;否则,返回false
抽象:抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行为抽象两方面,抽象只关注对象的哪些属性和行为,并不关注这此行为的细节是什么 可以有构造函数,但不能实例化
牛客例题 牛客例题2 牛客例题3
接口
牛客例题 牛客例题2 牛客例题3 JAVA基础——接口(全网最详细教程) Java之implements
为什么要用接口:接口被用来描述一种抽象。因为Java不像C++一样支持多继承,所以Java可以通过实现接口来弥补这个局限。 接口也被用来实现解耦。 接口被用来实现抽象,而抽象类也被用来实现抽象,为什么一定要用接口呢?接口和抽象类之间又有什么区别呢?原因是抽象类内部可能包含非final的变量,接口的静态成员变量要用static final public 来修饰 \接口中的方法都是抽象的,是没有方法体的,可以使用接口类型的引用指向一个实现了该接口的对象,并且可以调用这个接口中的方法。
可以直接把接口理解为*100%的抽象类*,既接口中的方法*必须全部*是抽象方法。(JDK1.8之前可以这样理解)
牛客例题4 类实现多个接口的时候,只需要一个implements,多个接口通过逗号进行隔开,先继承类再实现接口
重写与重载
Java中重载与重写 牛客例题 牛客例题2

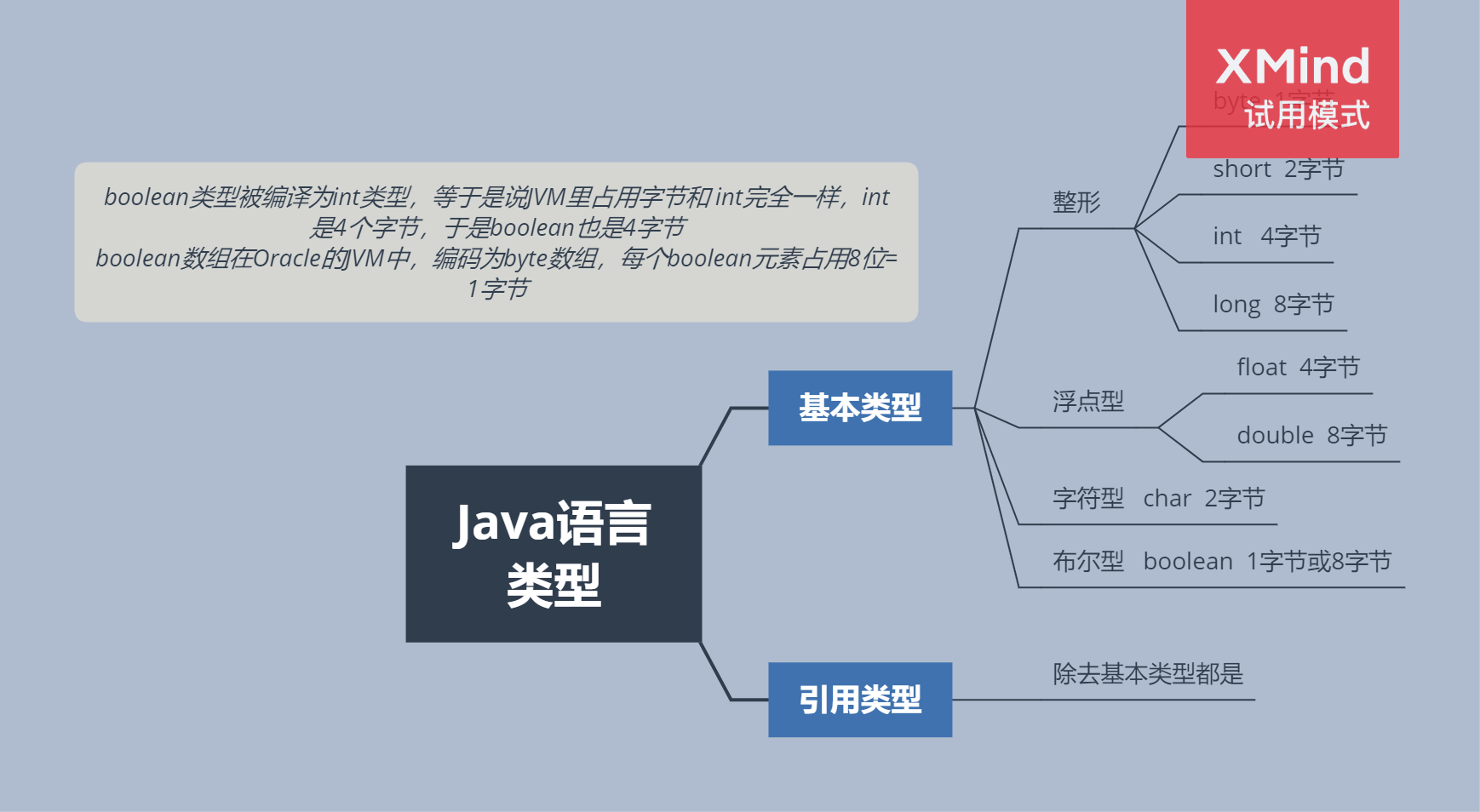
Java数据类型
Java基本数据类型 Java 基本数据类型 及 == 与 equals 方法的区别 牛客例题 牛客例题2 牛客例题3 牛客例题4
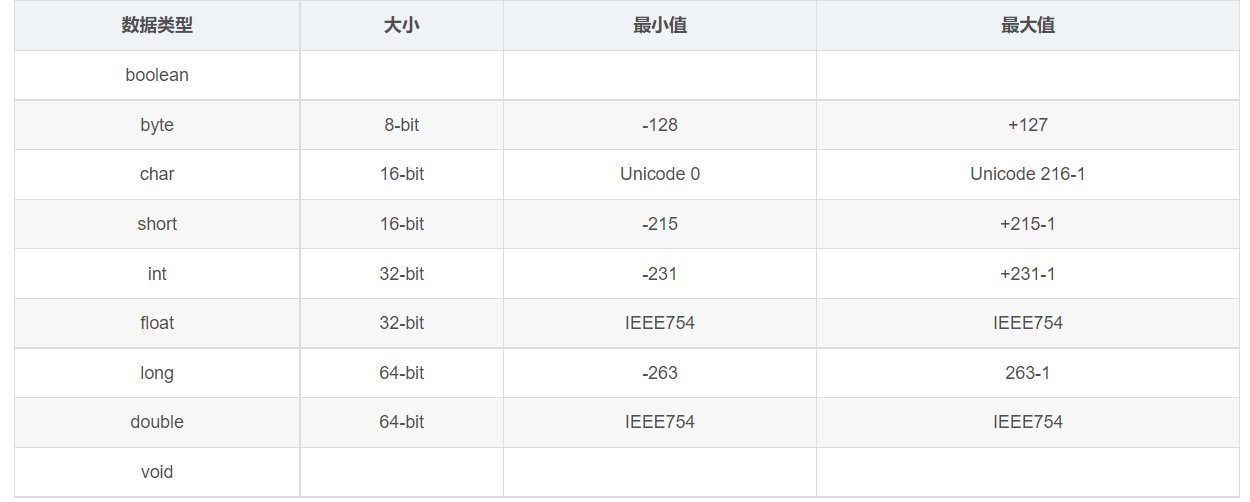
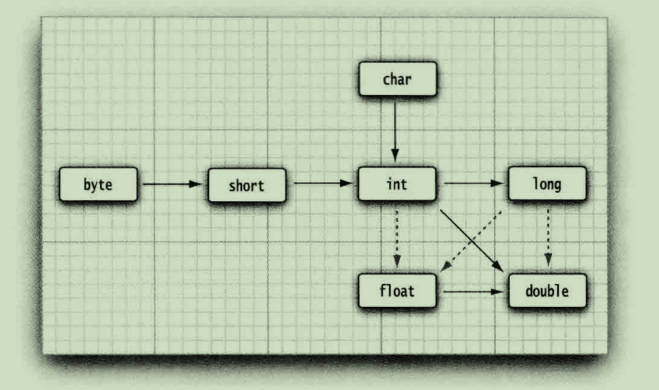
实线可以直接转,虚线直接的转换可能损失精度
位移运算符
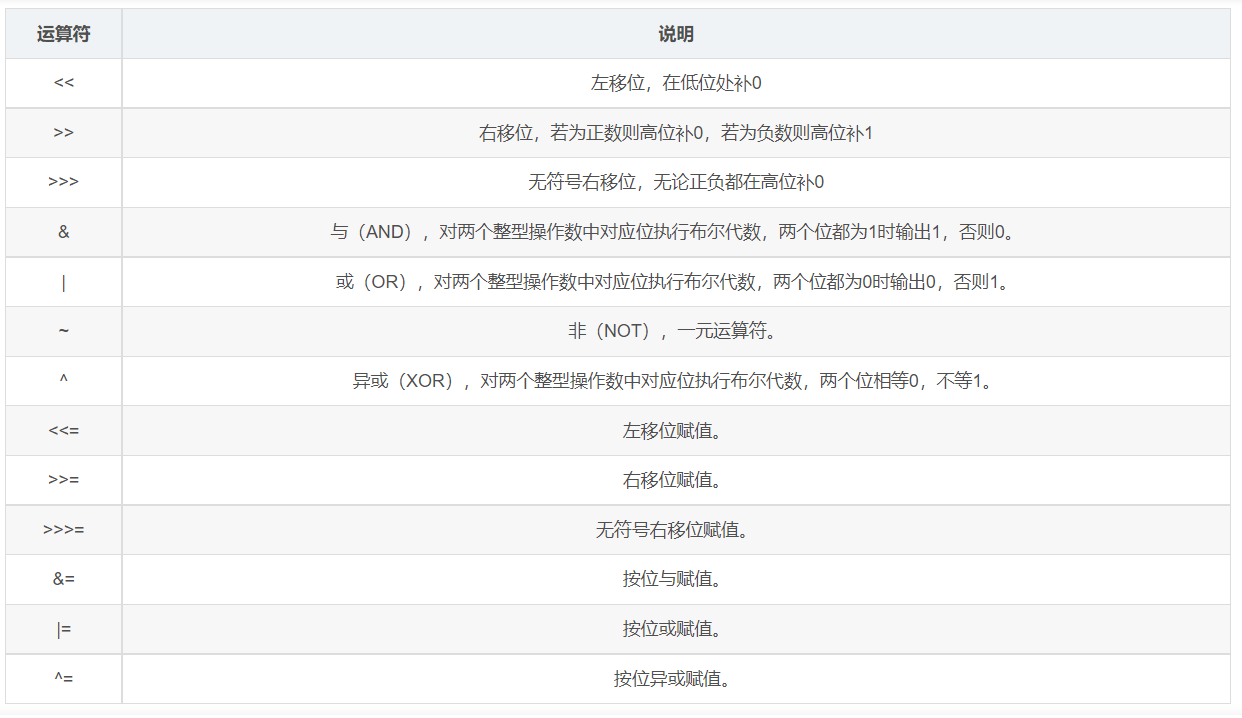
& ( " and " ) | ( " or " ) ^ ( " xor " ) ~ ( " not " )
局部变量与成员变量对于基本数据类型与引用类型的存储
-
对于局部变量来说,不论是基本数据类型还是引用类型,他们都会先在栈中分配一块内存,对于基本类型来说,这块区域包含的是基本类型的内容;而对于引用类型来说,这块区域包含的是指向真正内容的指针,真正的内容被手动的分配在堆上。
-
对于成员变量来说,不论是基本数据类型还是引用类型,他们都会存储在堆内存或者方法区中;成员变量可细分为静态成员变量和普通成员变量,静态成员变量类属于类,类可以直接访问,存储在方法区中;普通成员变量属于类对象,必须声明对象之后,通过对象才能访问,存储在堆中。
基本类型的变量数据和对象的引用都是放在栈里面的,对象本身放在堆里面,显式的String常量放在常量池,String对象放在堆中
什么是构造方法
什么是构造方法? Java构造方法 牛客例题 牛客例题2 牛客例题3 牛客例题4
构造方法的声明:修饰符 class_name(类名) (参数列表){逻辑代码}
-
构造⽅法的⽅法名和类名⼀致(包括⼤⼩写)
-
构造⽅法没有返回值类型(连void都没有)
-
构造⽅法可以重载
-
构造⽅法不可以⼿动调⽤,只能在创建对象的时,jvm⾃动调⽤
-
构造⽅法在创建对象时只能调⽤⼀次
当⼀个类中,没有定义构造⽅法 系统会⾃动提供⼀个公开的 ⽆参的构造⽅法 当类中已经定义了构 造⽅法,系统不再提供⽆参公开构造,如果需要使⽤⽆参的构造 那么必须⾃⼰定义出来 ⼀般开发如果 定义了有参的构造 都会再定义⼀个⽆参的构造
构造方法不能被 static、final、synchronized、abstract 和 native(类似于 abstract)修饰。构造方法用于初始化一个新对象,所以用 static 修饰没有意义。构造方法不能被子类继承,所以用 final 和 abstract 修饰没有意义。
构造函数的作用是创建一个类的实例。用来创建一个对象,同时可以给属性做初始化。当程序执行到new操作符时, 首先去看new操作符后面的类型,因为知道了类型,才能知道要分配多大的内存空间。分配完内存之后,再调用构造函数,填充对象的各个域,这一步叫做对象的初始化。
类之间几种常见的关系
“USES-A”关系 依赖关系,A类会用到B类,这种关系具有偶然性,临时性;在代码中的体现为:A类方法中的参数包含了B类“HAS-A”关系 表示组合。是整体与部分的关系,同时它们的生命周期都是一样的 (接口)“IS-A”关系 表示继承。父类与子类
泛型
泛型概述 牛客例题 牛客例题2
-
泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)
-
泛型类型在逻辑上可以看成是多个不同的类型,实际上都是相同的基本类型
泛型使用过程中操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法
Java中的泛型,只在编译阶段有效。在编译过程中,正确检验泛型结果后,会将泛型的相关信息擦出,并且在对象进入和离开方法的边界处添加类型检查和类型转换的方法
使用泛型的好处
1,类型安全。 泛型的主要目标是提高 Java 程序的类型安全。通过知道使用泛型定义的变量的类型限制,编译器可以在一个高得多的程度上验证类型假设。没有泛型,这些假设就只存在于程序员的头脑中(或者如果幸运的话,还存在于代码注释中)。
2,消除强制类型转换。 泛型的一个附带好处是,消除源代码中的许多强制类型转换。这使得代码更加可读,并且减少了出错机会。
3,潜在的性能收益。 泛型为较大的优化带来可能。在泛型的初始实现中,编译器将强制类型转换(没有泛型的话,程序员会指定这些强制类型转换)插入生成的字节码中。但是更多类型信息可用于编译器这一事实,为未来版本的 JVM 的优化带来可能。由于泛型的实现方式,支持泛型(几乎)不需要 JVM 或类文件更改。所有工作都在编译器中完成,编译器生成类似于没有泛型(和强制类型转换)时所写的代码,只是更能确保类型安全而已。
所以泛型只是提高了数据传输安全性,并没有改变程序运行的性能
-
? 表示不确定的 java 类型
-
T (type) 表示具体的一个 java 类型
-
K V (key value) 分别代表 java 键值中的 Key Value
-
E (element) 代表 Element
泛型擦除后是作为Object而存在的,而基础数据类型并没有继承自Object,所以编译器不允许将基础类型声明为泛型类型。最近版本的编译器当涉及基础类型作为泛型参数时,编译器会自动进行拆箱和装箱,所以编译器不会报错
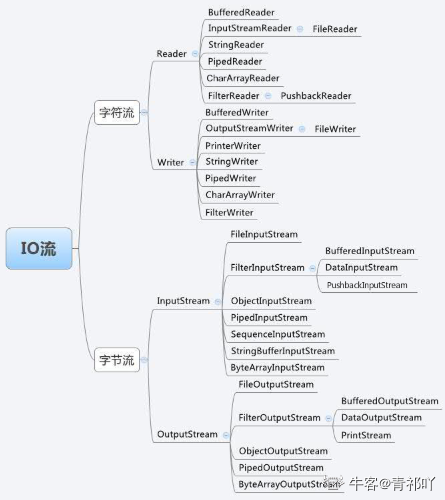
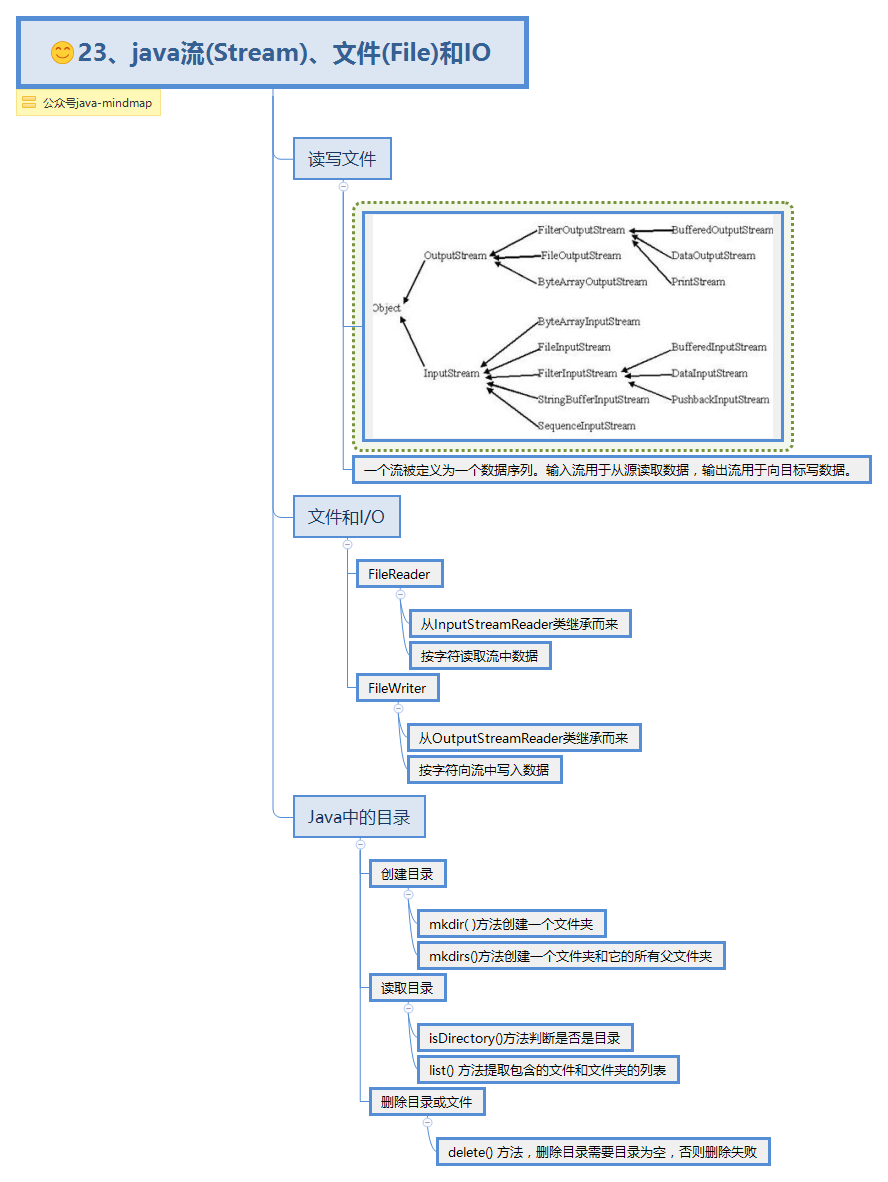
IO流
输入输出(IO)是指计算机同任何外部设备之间的数据传递。常见的输入输出设备有文件、键盘、打印机、屏幕等。数据可以按记录(或称数据块)的方式传递,也可以 流的方式传递 。
* IO流:* 流向* 输入流 读数据 FileReader Reader* 输出流 写数据 FileWriter Writer* 数据类型* 字节流* 字节输入流 读数据 InputStream* 字节输出流 写数据 OutputStream* 字符流* 字符输入流 读数据 Reader* 字符输出流 写数据 Writer
字节流传输需要刷新缓冲区,字符流无需刷新缓冲区,直接转换
-
二进制文件只能使用字节流进行复制
-
文本文件可以用字节流也可以用字符流进行复制
字节流
InputStream |-- FileInputStream (基本文件流) |-- BufferedInputStream |-- DataInputStream
|-- ObjectInputStream
字符流
Reader |-- InputStreamReader (byte->char 桥梁) |-- BufferedReader (常用) Writer |-- OutputStreamWriter (char->byte 桥梁) |-- BufferedWriter |-- PrintWriter (常用)
牛客例题 处理Unicode字符
面向字符的流
牛客例题 牛客例题2 牛客例题3 牛客例题4
BIO NIO AIO
JAVA中BIO、NIO、AIO的分析理解 什么是BIO、NIO和AIO?
-
BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
-
NIO:New IO(或 None Blocking IO)同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
-
AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非阻塞IO ,异步 IO 的操作基于事件和回调机制。
适用场景
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
AIO方式适用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
NIO 比 BIO 把一些无效的连接挡在了启动线程之前,减少了这部分资源的浪费。因为我们都知道每创建一个线程,就要为这个线程分配一定的内存空间。``AIO 比 NIO 进一步改善是,将一些暂时可能无效的请求挡在了启动线程之前,比如在 NIO 的处理方式中,当一个请求来的话,开启线程进行处理,但这个请求所需要的资源还没有就绪,此时必须等待后端的应用资源,这时线程就被阻塞了。
——————————————————————————————————————————————
以下了解即可,理解性记忆
同步和异步
-
同步——指的是用户进程触发 IO 操作并等待或者轮询的去查看 IO 操作是否就绪。
-
异步——异步是指用户进程触发IO操作以后便开始做自己的事情,而当 IO 操作已经完成的时候会得到 IO 完成的通知(异步的特点就是通知)
区别:O 操作主要分为两个步骤,即发起 IO 请求和实际 IO 操作,同步与异步的区别就在于第二个步骤是否阻塞。若实际 IO 操作阻塞请求进程,即请求进程需要等待或者轮询查看 IO 操作是否就绪,则为同步 IO;若实际 IO 操作并不阻塞请求进程,而是由操作系统来进行实际 IO 操作并将结果返回,则为异步 IO。
阻塞与非阻塞
-
阻塞——所谓阻塞方式就是指,当视图对文件描述符或者网络套接字进行读写时,如果当时没有东西可读,或者暂时不可写,程序就进入等待状态,直到有东西读或者写
-
非阻塞——所谓的非阻塞方式就是指,当视图对文件描述符或者网络套接字进行读写时,如果没有东西可读,或者不可写,读写函数马上返回,无须等待
区别:O 操作主要分为两个步骤,即发起 IO 请求和实际 IO 操作,阻塞与非阻塞的区别就在于第一个步骤是否阻塞。若发起 IO 请求后请求线程一直等待实际 IO 操作完成,则为阻塞 IO;若发起 IO 请求后请求线程返回而不会一直等待,即为非阻塞 IO。
阻塞和非阻塞是针对于进程在访问数据的时候,根据 IO 操作的就绪状态来采取的不同方式,说白了是一种读取或者写入操作函数的实现方式,阻塞方式下读取或者写入函数将一直等待,而非阻塞方式下,读取或者写入函数会立即返回一个状态值。
同步阻塞与同步非阻塞
-
同步并阻塞 IO——服务器实现模式一个连接一个线程,即客户端有连接请求时服务端就需要启动一个线程进行处理,如果这个连接不做任何事情,就会造成不必要的线程开销,当然可以通过线程池(Thread-Pool)程机制改善
-
同步非阻塞——同步非阻塞,服务器实现模式一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有 I/O 请求时才启动一个线程处理。用户进程也需要时不时地询问IO操作是否就绪,这就要求用户进程不停的去询问。
异步阻塞与异步非阻塞
-
异步阻塞——应用发起一个 IO 操作以后,不需要等待内核 IO 操作完成,等待内核完成 IO 操作以后会通知应用程序,这其实就是异步和同步的关键区别,同步必须等待或者主动去询问 IO 操作是否完成。那为什么说阻塞呢?因为此时是通过 select 系统调用来完成的,而 select 函数本身的实现方式就是阻塞的,但采用 select 函数有个好处就是它可以同时监听多个文件句柄(如果从UNP的角度看,select 属于同步操作。因为 select 之后,进程还需要读写数据),从而提高系统的并发性。
-
异步非阻塞——此种方式下,用户进程只需要发起一个IO操作便立即返回,等 IO 操作真正完成以后,应用程序会得到IO操作完成的通知,此时用户进程只需要对数据处理就好了,不需要进行实际的 IO 读写操作,因为真正的 IO 操作已经由操作系统内核完成了。
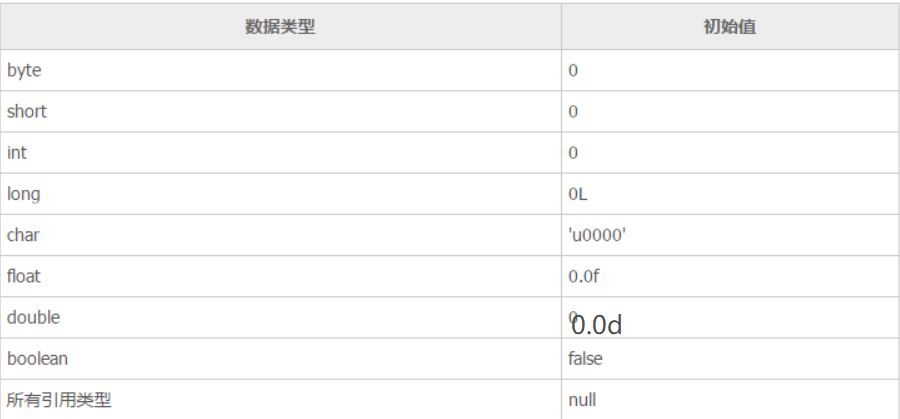
数组初始化后默认值
牛客例题 牛客例题2
牛客例题 数组的复制的效率System.arraycopy>clone>Arrays.copyOf>for循环
反射
反射小白入门 反射总结
Reflection(反射) 是 Java 程序开发语言的特征之一,它允许运行中的 Java 程序对自身进行检查,或者说“自审”,也有称作“自省”。 在程序运行状态中,对于任意一个类或对象,都能够获取到这个类的所有属性和方法(包括私有属性和方法),这种动态获取信息以及动态调用对象方法的功能就称为反射机制
优点
-
可以在程序运行过程中,操作这些对象;
-
可以解耦,提高程序的可扩展性。
获取Class对象的三种方式
-
【Source源代码阶段】 Class.forName(“全类名”):将字节码文件加载进内存,返回Class对象; 多用于配置文件,将类名定义在配置文件中,通过读取配置文件加载类。
-
【Class类对象阶段】 类名.class:通过类名的属性class获取; 多用于参数的传递
-
【Runtime运行时阶段】对象.getClass():此方法是定义在Objec类中的方法,因此所有的类都会继承此方法。 多用于对象获取字节码的方式
牛客例题
正则表达式
简书 牛客例题
[://] 表示匹配 :// 中的任何一个字符,也就是匹配 : 或 /
[htps] 表示匹配 htps 中的任何一个字符,[htps]+ 表示一次或多次匹配前面的字符或子表达式,所以 [htps]+ 可以匹配 https
Java的位运算
JDK、JRE与JVM的关系
JDK = JRE + 开发工具
JRE = JVM + 类库

JDK
Java Development Kit 是用于开发 Java 应用程序的软件开发工具,包括了 Java 运行时的环境(JRE)、解释器(Java)、编译器(javac)、Java 归档(jar ——一种软件包文件格式)、文档生成器(Javadoc)等工具。
JRE
Java Runtime Enviroment 提供 Java 应用程序执行时所需的环境,由 Java 虚拟机(JVM)、核心类、支持文件组成。
JVM
Java Virtual Machine(Java 虚拟机)有三层含义,分别是:
-
JVM规范要求
-
满足 JVM 规范要求的一种具体实现(一种计算机程序)
-
一个 JVM 运行实例,在命令提示符下编写 Java 命令以运行 Java 类时,都会创建一个 JVM 实例。
Java程序的开发过程为:
-
我们利用 JDK (调用 Java API)编写出 Java 源代码,存储于
.java文件中 -
JDK 中的编译器 javac 将 Java 源代码编译成 Java 字节码,存储于
.class文件中 -
JRE 加载、验证、执行 Java 字节码
-
JVM 将字节码解析为机器码并映射到 CPU 指令集或 OS 的系统调用。
Java体系结构包括四个独立但相关的技术
-
Java程序设计语言
-
Java.class文件格式
-
Java应用编程接口(API)
-
Java虚拟机
我们再在看一下它们四者的关系:
当我们编写并运行一个Java程序时,就同时运用了这四种技术,用Java程序设计语言编写源代码,把它编译成Java.class文件格式,然后再在Java虚拟机中运行class文件。当程序运行的时候,它通过调用class文件实现了Java API的方法来满足程序的Java API调用
牛客例题
关键字
对象的初始化方法:
new初始化 静态工厂 newInstance() 反射Class.forname() clone() 反序列化
其中new初始化和反射用到了构造方法,静态的newInstance()只能调用无参构造器
牛客例题
abstract continue for new switch default if package synchronized do goto private this break double implements protected throw byte else import public throws case enum instanceof return transient catch extends int short try char final interface static void class finally long strictfp volatile const float native super whileboolean assert
标识符
牛客例题
-
1.不能数字开头 2.标识符用$,_,字母,数字组成 3.不能用java关键字,保留字(关键字都是小写的)
-
4.不能用true,false,null来定义标识符 5.java大小写敏感 6.没有长度限制
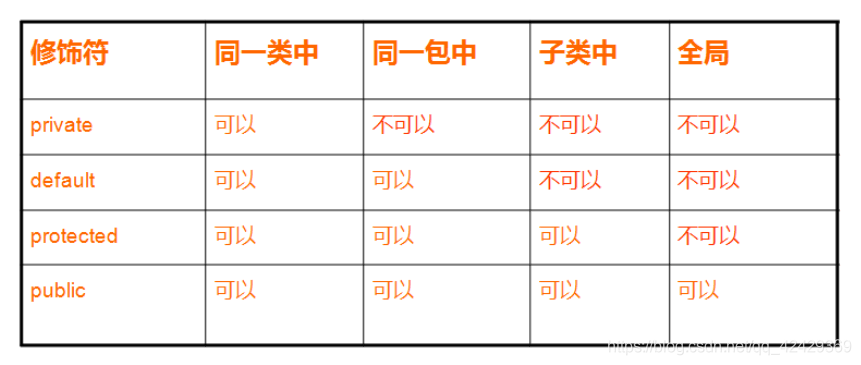
权限修饰符
Java中各类修饰符 牛客例题 牛客例题2
for 与 foreach
foreach适用于只是进行集合或数组遍历,for则在较复杂的循环中效率更高。
foreach不能对数组或集合进行修改(添加删除操作),如果想要修改就要用for循环。 所以相比较下来for循环更为灵活。
for能对集合进行动态删除
public static void main(String[] args) {Set<Integer> set = new HashSet<>();for (int i = 0; i < 10; i++) {set.add(i);System.out.print(set.remove(i) + "- ");}System.out.print("\n" + set.toString());}

foreach会报错
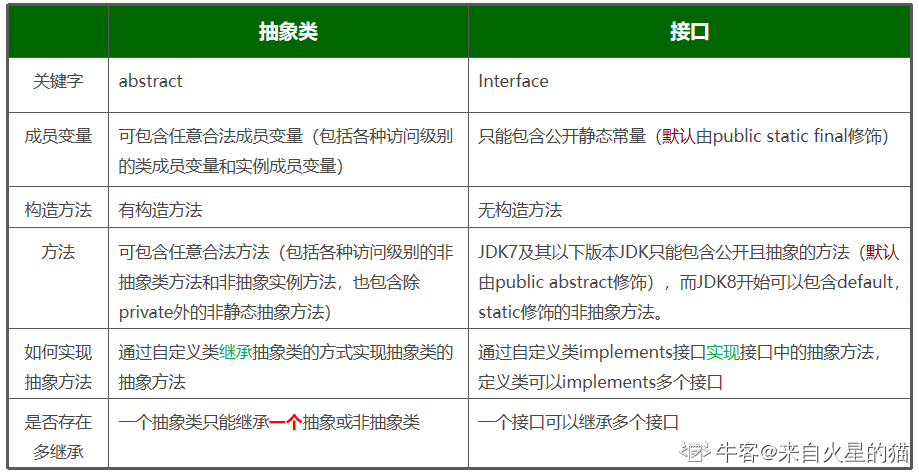
abstract 与 implement
-
一个抽象类可以是public、private、protected、default,接口只有public;
-
一个抽象类中的方法可以是public、private、protected、default,接口中的方法只能是public和default
-
abstract不能与final并列修饰同一个类;abstract 不能与private、static、final或native并列修饰同一个方法
-
抽象方法不能有方法体,抽象方法不能使用private修饰符,也不宜使用默认修饰符(default)接口 不**可以 实例化 。 通过接口实现类创建对象
Java抽象类、接口能否有构造方法 趣说abstract 简书 abstract牛客例题 牛客例题2 牛客例题3 牛客例题(抽象类)
构造方法作用:对类进行初始化
结论:Java中接口只有常量定义,没有变量声明,不能有构造方法; 抽象类可以有构造方法
原因:
-
一、接口可以理解为“完全抽象类”,只包含常量和抽象方法;接口中的方法默认被 public 、abstract 修饰,不能有方法体,所以接口中不能有构造方法。 一个类实现了一个接口,则必须实现所有方法,否则必须标志abstract (弱的所属关系is-a)
-
二、抽象类可以有构造方法 (强的所属关系is-a)
-
抽象类中可以有抽象方法和普通方法,不能使用new创建它的实例;含有抽象方法的类必须声明为抽象类,抽象类扩展的非抽象子类中,必须实现所有的抽象方法
-
普通方法可以有方法体,构造方法是没有返回值的方法,在new实例化对象时被调用。所以抽象类可以有构造方法。
-
一个子类只能继承一个父类,但可以实现任意个数的接口,某种程度上接口比抽象类更加灵活
外部抽象类不允许使用static声明,而内部的抽象类可以使用static声明。
使用static声明的内部抽象类相当于一个外部抽象类,继承的时候使用“外部类.内部类”的形式表示类名称。
abstract class A{//static定义的内部类属于外部类static abstract class B{public abstract void print();}
}class C extends A.B{public void print(){System.out.println("**********");}
}public class TestDemo {public static void main(String[] args) {//向上转型A.B ab = new C();ab.print();}
}
switch
byte short int char 枚举 在JDK1.7版本以后,Switch语句也可以接string类型
final
浅谈Java中的final关键字 java中的Static、final、Static final各种用法 牛客例题
可用来修饰类,方法,变量
1.final修饰变量,则等同于常量 2.final修饰方法中的参数,称为最终参数。
3.final修饰类,则类不能被继承 (太监类)
4.final修饰方法,则方法不能被重写。5.final 不能修饰抽象类
6.final修饰的方法可以被重载 但不能被重写 (不能继承)
-
当用final修饰一个类时,表明这个类不能被继承。也就是说,如果一个类你永远不会让他被继承,就可以用final进行修饰。final类中的成员变量可以根据需要设为final,但是要注意final类中的所有成员方法都会被隐式地指定为final方法。在使用final修饰类的时候,要注意谨慎选择,除非这个类真的在以后不会用来继承或者出于安全的考虑,尽量不要将类设计为final类
-
使用final方法的原因有两个:第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升。在最近的Java版本中,不需要使用final方法进行这些优化了。
只有在想明确禁止 该方法在子类中被覆盖的情况下才将方法设置为final的。 注:类的private方法会隐式地被指定为final方法
-
对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
static作用于成员变量用来表示只保存一份副本,而final的作用是用来保证变量不可变
即使没有final修饰的情况下,在方法内部改变了变量i的值也不会影响方法外的i;java采用的是值传递,对于引用变量,传递的是引用的值,也就是说让实参和形参同时指向了同一个对象,因此让形参重新指向另一个对象对实参并没有任何影响
static
深入理解static关键字
static修饰的变量没有发生变化是因为static作用于成员变量只是用来表示保存一份副本,其不会发生变化。怎么理解这个副本呢?其实static修饰的在类加载的时候就加载完成了(初始化),而且只会加载一次也就是说初始化一次,所以不会发生变化!
static是不允许用来修饰局部变量 静态变量只能在类主体中定义,不能在方法中定义
-
静态变量: 静态变量由于不属于任何实例对象,属于类的,所以在内存中只会有一份,在类的加载过程中JVM只为静态变量分配一次内存空间。
-
实例变量: 每次创建对象都会为每个对象分配成员变量内存空间,实例变量是属于实例对象的,在内存中,创建几次对象,就有几份成员变量。
牛客例题 静态方法中不能调用对象的变量,因为静态方法在类加载时就初始化,对象变量需要在新建对象后才能使用
牛客例题2 静态变量和静态块的初始化顺序是靠他们俩的位置决定的
牛客例题3 static成员函数既可以通过类名直接调用,也可以通过对象名进行调用
牛客例题4 静态变量只能在类主体中定义,不能在方法中定义
牛客例题5 被动引用不会出发子类初始化 1.子类引用父类的静态字段,只会触发子类的加载、父类的初始化,不会导致子类初始化 2.通过数组定义来引用类,不会触发此类的初始化 3.常量在编译阶段会进行常量优化,将常量存入调用类的常量池中, 本质上并没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化。
牛客例题6 静态变量会默认赋初值,局部变量和final声明的变量必须手动赋初值
修饰符大汇总
super
super的作用 牛客例题
-
调用父类被子类重写的方法;
-
调用父类被子类重定义的字段(被隐藏的成员变量);
-
调用父类的构造方法;
如果子类没有重写父类的方法,调用父类的方法用不用super关键字结果都一样。 如果子类重写父类的方法,调用父类的方法必须用super关键字
super关键字详解
this与super
牛客例题
-
this是引用。this也保存内存地址,this也指向任何对象,不能调用static静态成员变量
-
super 不是引用。super也不保存内存地址,super也不指向任何对象。super 只是代表当前对象内部的那一块父类型的特征。
-
this的作用其中一个就是在一个构造方法中调用另一个构造方法,格式为this(参数);
super可以访问父类中public、default、protected修饰的成员变量,实例方法,构造方法格式如下 super.属性名 【访问父类的属性】 super.方法名(实参) 【访问父类的方法】 super(实参) 【调用父类的构造方法】
super()在无参构造的使用
为什么要有无参构造
在子类的构造方法中编译器会自动在子类构造函数的第一句加上 super(); 来调用父类的无参构造器;此时可以省略不写。如果想写上的话必须在子类构造函数的第一句,可以通过super来调用父类其他重载的构造方法,只要相应的把参数传过去就好 牛客例题
String、StringBuffer、StringBuilder
String、StringBuffer与StringBuilder之间区别 牛客例题 牛客例题2
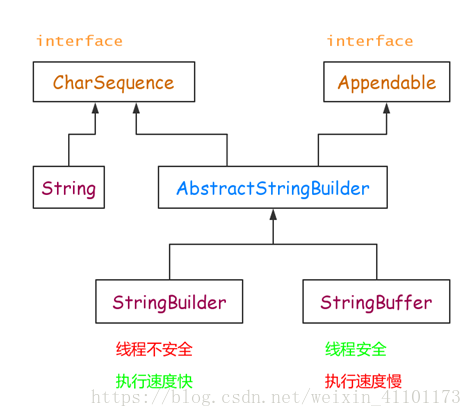
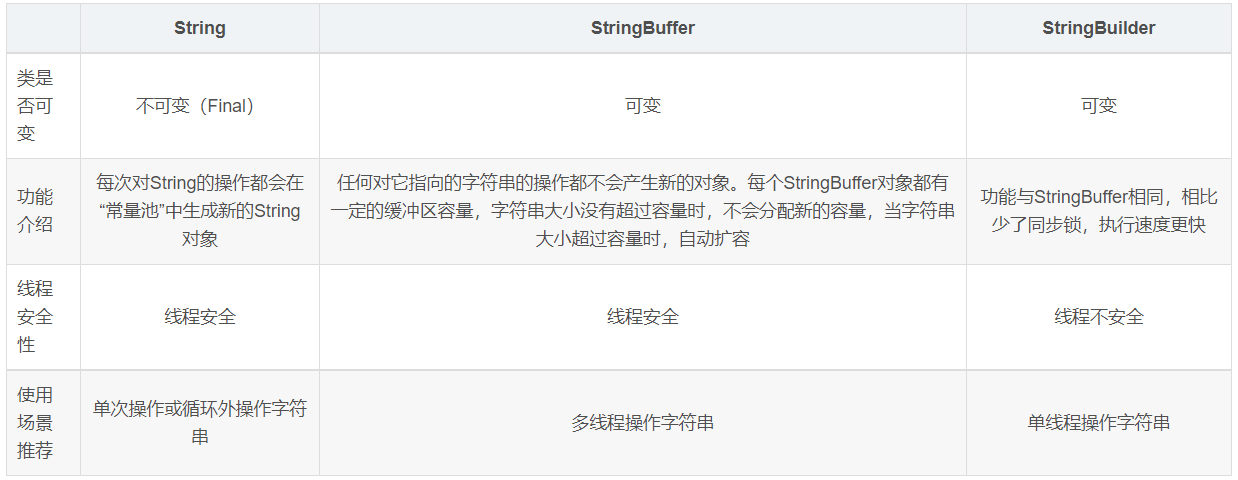
-
String由final修饰,是不可变的,每次操作都会产生新的String对象
-
StringBuffer和StringBuilder都是在原对象上操作的,可改变 (常量池可追加字符串)
-
StringBuffer线程安全,StringBuilder线程不安全;StringBuffer方法都是synchronized修饰
性能:StringBuilder > StringBuffer > String
场景:经常需要改变字符串内容时使用后面两个;单线程环境下优先使用StringBuilder,多线程使用共享变量时使用StringBuffer;
new String 与String
java堆、栈、堆栈,常量池的区别 String不new和new的区别 Java的String类常量池 图解 牛客例题 牛客例题2 牛客例题3 牛客例题4
栈区存引用和基本类型,不能存对象,而堆区存对象。 ==是比较地址,equals()比较对象内容。
String str1 = “ABC”;可能创建一个或者不创建对象,如果常量池中有“ABC”,则不创建对象,直接指向那个地址;如果”ABC”这个字符串在java 常量池里不存在,会在常量池里创建一个创建一个String对象(“ABC”),然后str1指向这个内存地址,无论以后用这种方式创建多少个值为”ABC”的字符串对象,始终只有一个内存地址被分配,之后的都是String的拷贝,Java中称为“字符串驻留”,所有的字符串常量都会在编译之后自动地驻留。
String str2 = new String(“ABC”);至少创建一个对象,也可能两个。如果常量池有“ABC”这个字符串,new关键字意味着将在heap中创建一个str2的String对象,value引用至“ABC”。如果这个字符串(ABC)在java 常量池里不存在,还会在常量池里创建这个String对象“ABC”(创建了第二个对象),即创建了两个对象。
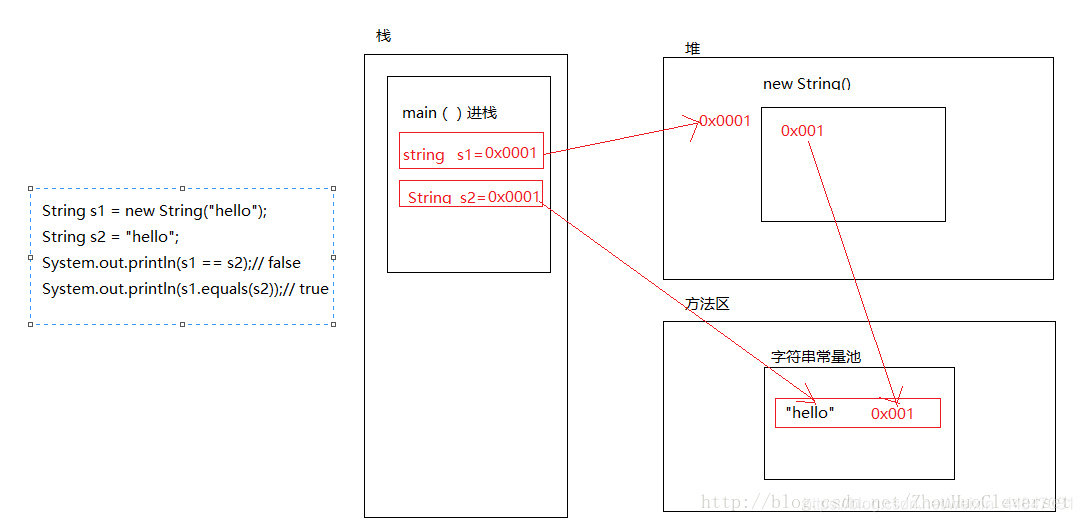
栈与堆的区别
程序内存布局场景下,堆与栈表示两种内存管理方式:
(1)管理方式不同。栈由操作系统自动分配释放,无需我们手动控制;堆的申请和释放工作由程序员控制,容易产生内存泄漏;
(2)空间大小不同。每个进程拥有的栈的大小要远远小于堆的大小。理论上,程序员可申请的堆大小为虚拟内存的大小,进程栈的大小 64bits 的 Windows 默认 1MB,64bits 的 Linux 默认 10MB;
(3)生长方向不同。堆的生长方向向上,内存地址由低到高;栈的生长方向向下,内存地址由高到低。
(4)分配方式不同。堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是由操作系统完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由操作系统进行释放,无需我们手工实现。
(5)分配效率不同。栈由操作系统自动分配,会在硬件层级对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是由C/C++提供的库函数或运算符来完成申请与管理,实现机制较为复杂,频繁的内存申请容易产生内存碎片。显然,堆的效率比栈要低得多。
(6)存放内容不同。栈存放的内容,函数返回地址、相关参数、局部变量和寄存器内容等。当主函数调用另外一个函数的时候,要对当前函数执行断点进行保存,需要使用栈来实现,首先入栈的是主函数下一条语句的地址,即扩展指针寄存器的内容(EIP),然后是当前栈帧的底部地址,即扩展基址指针寄存器内容(EBP),再然后是被调函数的实参等,一般情况下是按照从右向左的顺序入栈,之后是被调函数的局部变量,注意静态变量是存放在数据段或者BSS段,是不入栈的。出栈的顺序正好相反,最终栈顶指向主函数下一条语句的地址,主程序又从该地址开始执行。堆,一般情况堆顶使用一个字节的空间来存放堆的大小,而堆中具体存放内容是由程序员来填充的。
==和equals比较
-
==对比的是栈中的值,基本数据类型是变量值,引用数据类型是堆中内存对象的地址;
直接比较的两个对象的堆内存地址,如果相等,则说明这两个引用实际是指向同一个对象地址的
-
equals:object中默认也是采用==比较,通常会重写
== 是java提供的等于比较运算符,用来比较两个变量指向的内存地址是否相同.而equals()是Object提供的一个方法.Object中equals()方法的默认实现就是返回两个对象==的比较结果.但是equals()可以被重写,所以我们在具体使用的时候需要关注equals()方法有没有被重写. ==和equals 牛客例题 牛客例题
instanceof运算符
牛客例题
用来判断,instanceof 左边对象是否为instanceof 右边类的实例,返回一个boolean类型值。还可以用来判断子父类的所属关系。
//测试它左边的对象是否是它右边的类的实例,返回boolean类型的数据String s = "I AM an Object!";boolean isObject = s instanceof Object;
应用场景:需要用到对象的强制类型转换时,需要使用instanceof进行判断。
可以判断 一个类的实例 一个子类的实例 一个实现指定接口的类的实例
instanceof详解
Scanner,BufferedReader,InputStreamReader 简介与对比
Scanner 类和BufferedReader 类的区别:Scanner类是读取并转换输入流的,而BufferedReader类是直接读取输入流,并不做转换;由此BufferedReader类读取的速度要比Scanner类读取的速度快;由于BufferedReader类读取输入流不进行转换,Scanner类也可以通过一个BufferedReader对象来实例化;
函数取值方法
牛客例题
-
大数取整(四舍五入) Math.round 取最接近整数,如果遇到一样近,则取最大值 Math.round(10.5) = 11 Math.rond(-10.5) = -10
-
向上取整 Math.ceil 无脑进位(向大方向) Math.ceil(10.1) = 11 Math.ceil(-9.6)= 9
-
向下取整 Math.floor 无脑退位(向负方向) Math.floor(10.6) = 10 Math.floor(-9.2)=-10
集合
牛客例题
线程安全的类有hashtable concurrentHashMap synchronizedMap
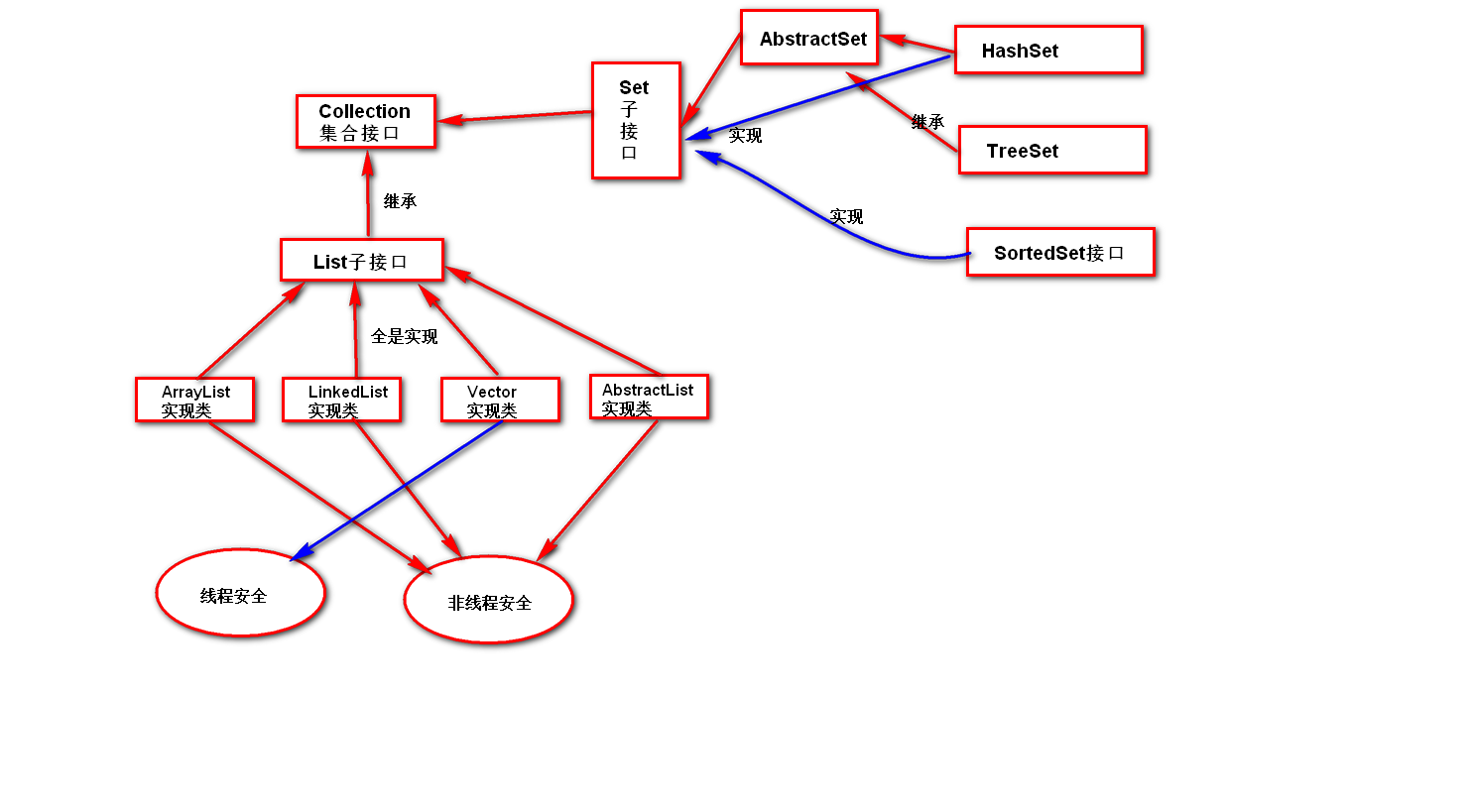
总共有两大接口:Collection 和Map ,一个元素集合,一个是键值对集合;
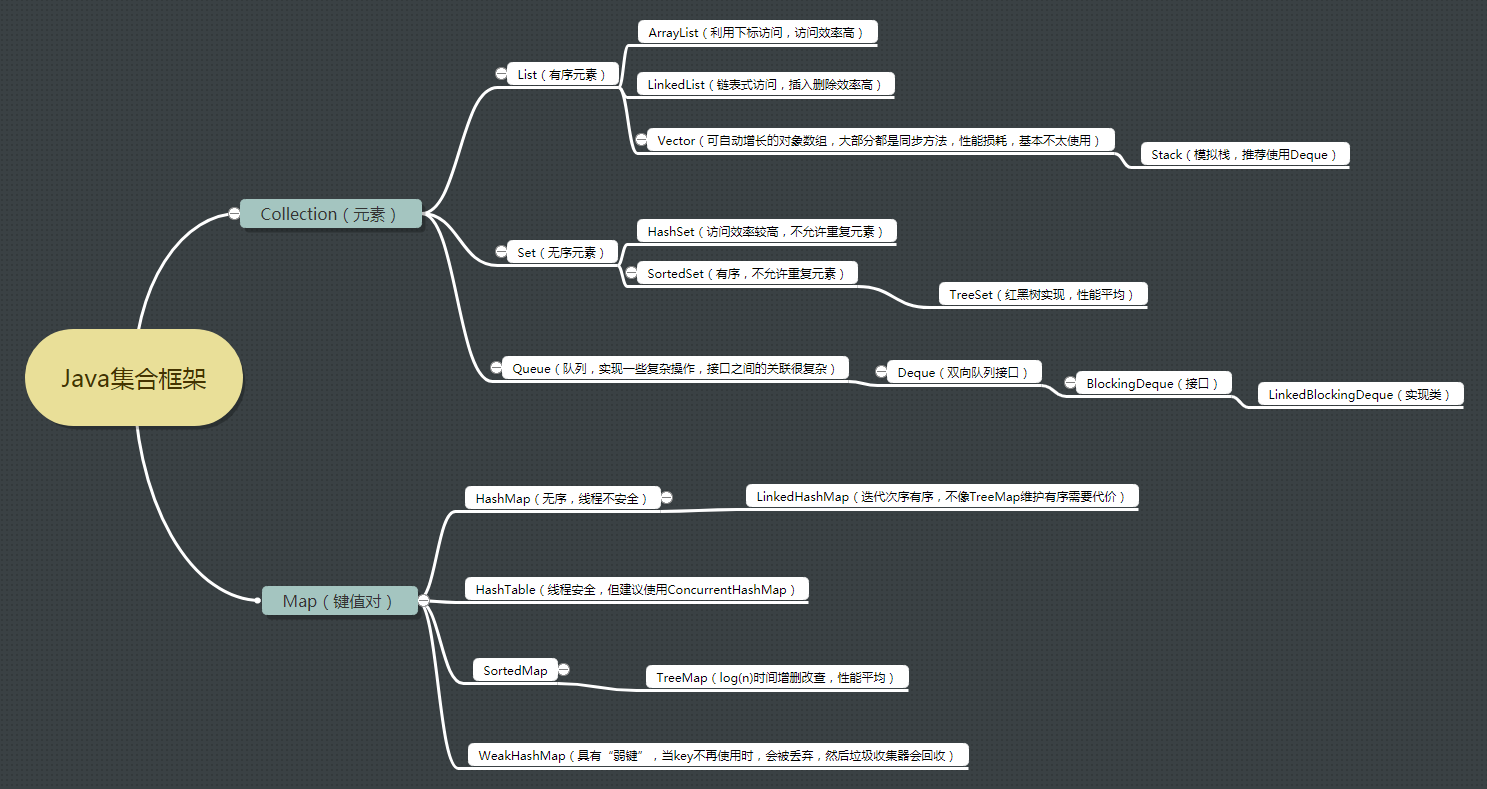
链接:Java集合类框架的基本接口有哪些?__牛客网 来源:牛客网
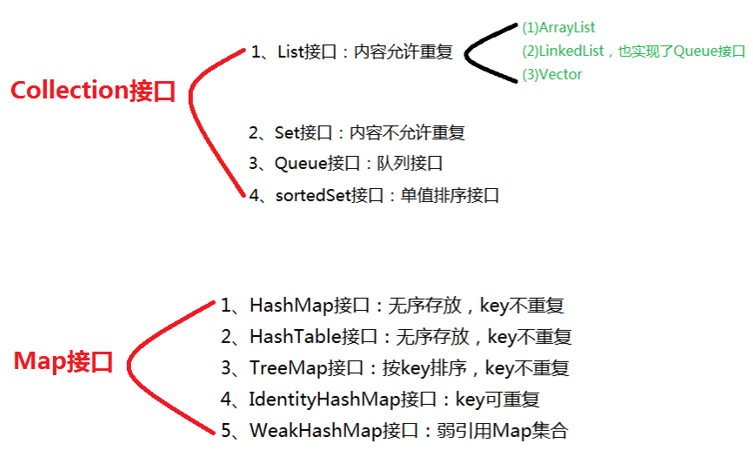
java.util.Collection [I]
Collection 接口常用的方法
牛客例题
| 方法名称 | 说明 |
|---|---|
| boolean add(E e) | 向集合中添加一个元素,如果集合对象被添加操作改变了,则返回 true。E 是元素的数据类型 |
| boolean addAll(Collection c) | 向集合中添加集合 c 中的所有元素,如果集合对象被添加操作改变了,则返回 true。 |
| void clear() | 清除集合中的所有元素,将集合长度变为 0。 |
| boolean contains(Object o) | 判断集合中是否存在指定元素 |
| boolean containsAll(Collection c) | 判断集合中是否包含集合 c 中的所有元素 |
| boolean isEmpty() | 判断集合是否为空 |
| Iterator<E>iterator() | 返回一个 Iterator 对象,用于遍历集合中的元素 |
| boolean remove(Object o) | 从集合中删除一个指定元素,当集合中包含了一个或多个元素 o 时,该方法只删除第一个符合条件的元素,该方法将返回 true。 |
| boolean removeAll(Collection c) | 从集合中删除所有在集合 c 中出现的元素(相当于把调用该方法的集合减去集合 c)。如果该操作改变了调用该方法的集合,则该方法返回 true。 |
| boolean retainAll(Collection c) | 从集合中删除集合 c 里不包含的元素(相当于把调用该方法的集合变成该集合和集合 c 的交集),如果该操作改变了调用该方法的集合,则该方法返回 true。 |
| int size() | 返回集合中元素的个数 |
| Object[] toArray() | 把集合转换为一个数组,所有的集合元素变成对应的数组元素。 |
Collection:单列集合的根接口
Map:双列集合的根接口,用于存储具有键(key)、值(value)映射关系的元素。
List:元素有序 可重复
-
ArrayList:类似一个长度可变的数组 。适合查询,不适合增删
-
LinkedList:底层是双向循环链表。适合增删,不适合查询。
Set:元素无序,不可重复
-
HashSet:根据对象的哈希值确定元素在集合中的位置
-
TreeSet: 以二叉树的方式存储元素,实现了对集合中的元素排序
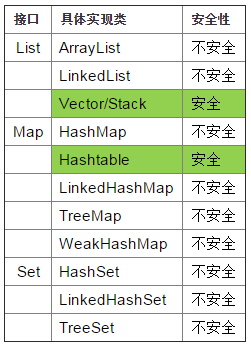
|—java.util.List [I]|—java.util.ArrayList [C] 非同步,实现了可变大小的元素数组|—java.util.LinkedList [C] 非同步|—java.util.Vector [C] 同步 |—java.util.Stack [C]|—java.util.Set [I] 不允许有相同的元素|—java.util.HashSet [C]|—java.util.SortedSet [I]|—java.util.TreeSet [C]
牛客例题 牛客例题2
LinkedHashSet继承于HashSet、又基于 LinkedHashMap 来实现
TreeSet使用二叉树的原理对新 add()的对象按照指定的顺序排序(升序、降序),每增加一个对象都会进行排序,将对象插入的二叉树指定的位置。
HashSet存储元素的顺序并不是按照存入时的顺序(和 List 显然不同) 而是按照哈希值来存的所以取数据也是按照哈希值取得
ArrayList 中RandomAccess
实现RandomAccess接口的List(ArrayList)可以通过for循环来遍历数据比使用iterator遍历数据更高效,未实现RandomAccess接口的List(LinkedList)可以通过iterator遍历数据比使用for循环来遍历数据更高效。
简书 RandomAccess判断是否支持快速访问
当一个List拥有快速访问功能时,其遍历方法采用for循环最快速。而没有快速访问功能的List,遍历的时候采用Iterator迭代器最快速。
当我们不明确获取到的是Arraylist,还是LinkedList的时候,我们可以通过RandomAccess来判断其是否支持快速随机访问
集合List列表 牛客例题 牛客例题
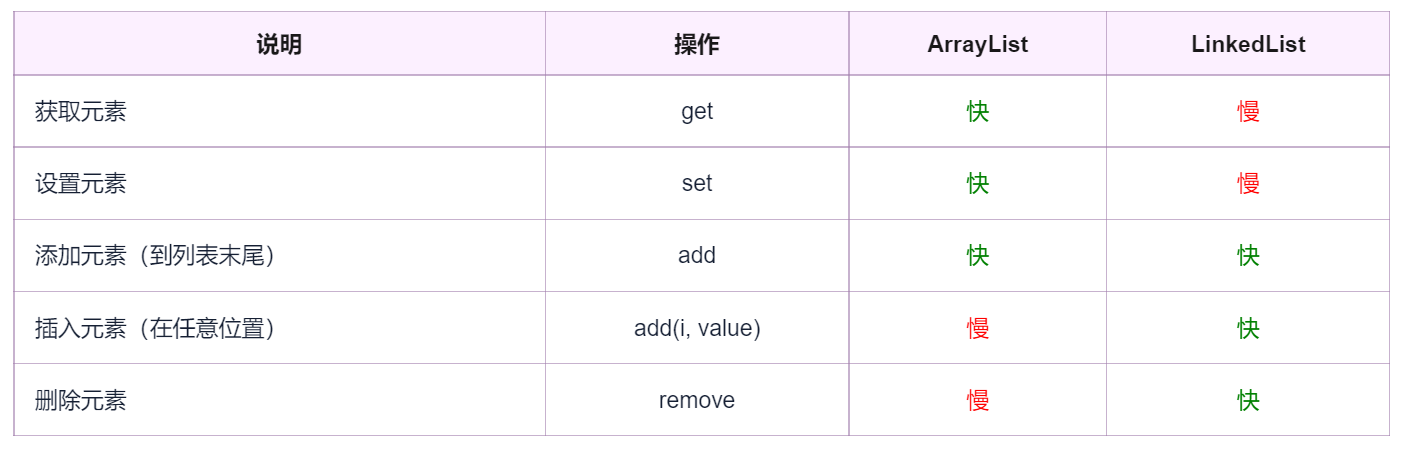
ArrayList与LinkedList区别
codeGym
-
arrayList使用的是数组数据结构,可以以O(1)时间复杂度对元素进行随机访问;LinkedList使用的是(双)链表结构查找某个元素的时间复杂度是O(n)
-
arrayList更适合于随机查找操作,linkedList更适合增删改查,时间复杂度根据数据浮动
-
两者都实现了List接口,但LinkedList额外实现了Deque接口,因此Linked还可以当作队列使用
-
LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素
在添加操作中数组如果不涉及扩容,添加速率比较快;链表指定索引添加的话和索引值相关;在插入操作中(指定索引添加),两者性能要根据实际使用情况评判。
//遍历ArrayListpublic static void main(String args[]){List<String> list = new ArrayList<String>();list.add("luojiahui");list.add("luojiafeng");//方法1Iterator it1 = list.iterator();while(it1.hasNext()){System.out.println(it1.next());}//方法2for(Iterator it2 = list.iterator();it2.hasNext();){System.out.println(it2.next());}//方法3for(String tmp:list){System.out.println(tmp);}//方法4for(int i = 0;i < list.size(); i ++){System.out.println(list.get(i));}}
ArrayList、LinkedList与vector区别
ArrayList 和 Vector 的区别是什么?
-
线程安全:Vector 使用了 Synchronized 来实现线程同步,是线程安全的,而 ArrayList 是非线程安全的。
-
性能:ArrayList 在性能方面要优于 Vector。
-
扩容:ArrayList 和 Vector 都会根据实际的需要动态的调整容量,只不过在 Vector 扩容每次会增加 1 倍,而 ArrayList 只会增加 50%。
使ArrayList线程安全方法: 1、继承Arraylist,然后重写或按需求编写自己的方法,这些方法要写成synchronized,在这些synchronized的方法中调用ArrayList的方法。2、List list = Collections.synchronizedList(new ArrayList());
Array 和 ArrayList 有何区别?
-
Array 可以存储基本数据类型和对象,ArrayList 只能存储对象。
-
Array 是指定固定大小的,而 ArrayList 大小是自动扩展的。
-
Array 内置方法没有 ArrayList 多,比如 addAll、removeAll、iteration 等方法只有 ArrayList 有。
此部分来自:Java-interview
ArrayList敖丙
List和Set区别
-
List:有序,按对象进入顺序保存对象,允许添加重复对象,允许添加多个null元素对象;可以使用iterator取出所有元素逐一遍历;可以使用get(int index)获取指定下标的元素
-
Set:无序,最多允许一个null元素存在,元素对象不可重复。取元素时只能使用iterator接口取得所有元素,再进行遍历操作。
list方法常用的实现类有:
ArrayList、LinkedList 和 Vector。ArrayList最常用,提供使用索引(index)访问,定位、查询效率高;而LinkedList 则对于经常需要从 List 中添加或删除元素的场合更为合适,Vector 表示底层数组,线程安全,效率低被边缘化~
Set方法中常用的实现类有:
HashSet、LinkedHashSet 以及 TreeSet。最常用的是基于 HashMap 实现的 HashSet;另外TreeSet 还实现了 SortedSet 接口(支持排序),因此 TreeSet 是一个可根据 compare() 和compareTo()方法进行排序的有序容器。
遍历方式 List 支持for循环,也就是通过下标来遍历,也可以用迭代器(Iterator),但是set只能用迭代,因为他无序,无法用下标来取得想要的值。
* Map和Collection区别: * Map是双列集合:常用语处理有对应关系的数据,key不可以重复(夫妻对集合) * Collection:单列集合,Collection有不同的子体系,有的允许重复有索引有序,有的不允许重复且无序(单身汉集合)
List和Map区别
List , Set, Map都是接口,前两个继承至Collection接口(Collection接口下还有个Queue接口,有PriorityQueue类),Map为独立接口
(1)List下有ArrayList,Vector,LinkedList
(2)Set下有HashSet,LinkedHashSet,TreeSet
(2)Map下有Hashtable,LinkedHashMap,HashMap,TreeMap
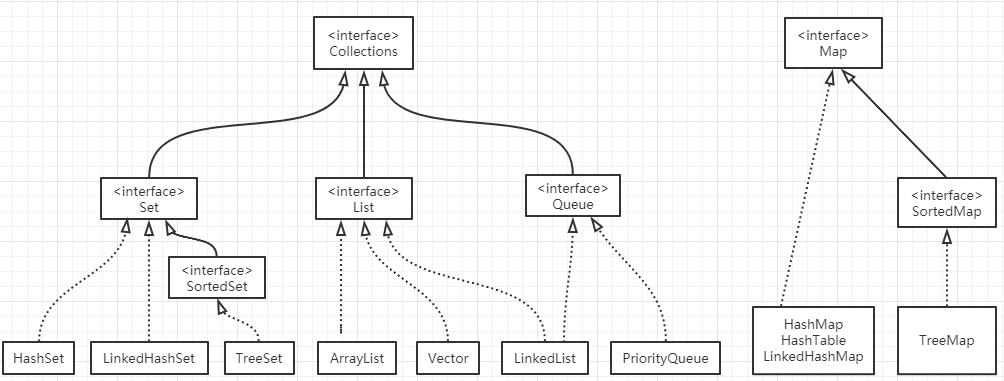
List :存储有序单列数据的集合,可重复
Map:存储双列数据的集合,通过键值对存储数据,存储的数据是无序的,Key值不能重复,value值可以重复
java.util.Map [I]
牛客例题
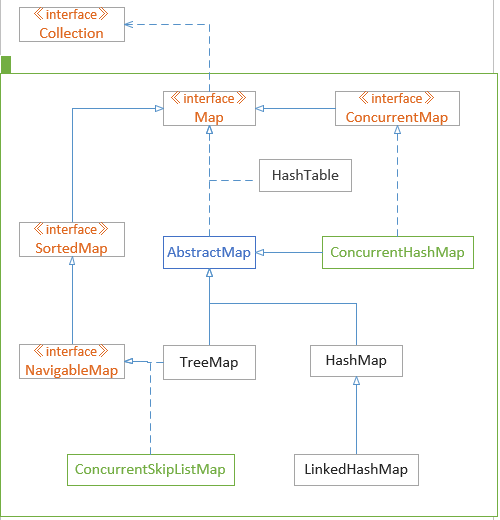
Map 遍历Map可以使用增强for循环 可以用 Map.Entry 面向对象实现(更常用) Map.Entry详解
//定义Hashmap集合 键值对为String类型
HashMap<String,String> hash = new HashMap<String,String>();
hash.put("IS1","lucy");
hash.put("IS2","tom");
hash.put("IS3","Li");//方式一:获取key,通过key来获取value
Set<String> keys = hash.keySet();
for (String k : keys){String n = hash.get(k);System.out.println(k + "==" + n);
}
System.out.println("---------------");
//方式二:通过对象获取键值对 Map.Entry实现
Set<Map.Entry<String,String>> entries = hash.entrySet();
for (Map.Entry<String,String> entry : entries){String key = entry.getKey();String value = entry.getValue();System.out.println(key + "==" + value);
}
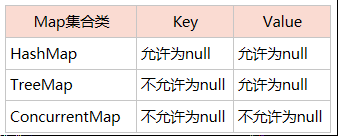
Map和SortedMap是接口,不能直接new对象
-
-----HashTable 同步,实现一个key--value映射的哈希表,key和value都不允许出现null值
-
-----HashMap 非同步,允许出现null-null键值对;将键映射到值的对象,一个映射不能包含重复的键;每个键最多只能映射到一个值 使用put()建立映射关系,key存在时候覆盖对应值
-
-----WeakHashMap 改进的HashMap,实现了“弱引用”,如果一个key不被引用,则被GC回收
-
-----TreeMap:用来存储键值映射关系,不能出现重复的键key,所有的键按照二叉树的方式排列
注:
List接口中的对象按一定顺序排列,允许重复 Set接口中的对象没有顺序,但是不允许重复 Map接口中的对象是key、value的映射关系,key不允许重复
|—java.util.SortedMap [I]|—java.util.TreeMap [C]|—java.util.Hashtable [C]|—java.util.HashMap [C]|—java.util.LinkedHashMap [C]|—java.util.WeakHashMap [C]
codeGym关于hashmap
HashMap与HashTable
HashTable和HashMap的区别详解 - 割肉机 - 博客园 JAVA面试题:HashMap和Hashtable的区别_岁月求索-CSDN博客
程序员小灰
-
HashMap线程不安全,没有synchronized;HashTable线程安全
-
Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
-
HashMap允许key和value为null,HashTable不允许
-
HashMap继承自AbstractMap类。但二者都实现了Map接口。Hashtable继承自Dictionary类,Dictionary类是一个已经被废弃的类(见其源码中的注释)。父类都被废弃,自然而然也没人用它的子类Hashtable了。
-
遍历方式: Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。 Enumeration接口的功能和Iterator接口的功能是重复的,主要区别其实就是Iterator可以删除元素,但是Enumration却不能
-
.HashMap不能保证元素的顺序,而LinkedHashMap可以保持数据的插入顺序,TreeMap可以按照键值进行排序(可自定比较器)
HashMap的key可以重复么 hashmap总结 hashmap底层
key不能重复 value可以重复
| HashMap(JDK1.8) | ConcurrentHashMap(JDK1.8) | Hashtable | |
|---|---|---|---|
| 底层实现 | 数组+链表/红黑树 | 数组+链表/红黑树 | 数组+链表 |
| 线程安全 | 不安全 | 安全(Synchronized修饰Node节点) | 安全(Synchronized修饰整个表) |
| 效率 | 高 | 较高 | 低 |
| 扩容 | 初始16,每次扩容成2n | 初始16,每次扩容成2n | 初始11,每次扩容成2n+1 |
| 是否支持Null key和Null Value | 可以有一个Null key,Null Value多个 | 不支持 | 不支持 |
Hashmap使用拉链法解决哈希冲突
牛客网Enumeration接口和Iterator接口的区别
底层:数组+链表
默认长度16;jdk8开始链表高度达到8,数组长度超过64,链表将转变为红黑树,元素以内类Node节点存在
-
计算key的hash值,二次hash然后对数组长度取模,对应到数组下标
-
如果没有产生hash冲突,直接创建Node存入数组;产生hash冲突的话,先进性equal比较,相同则取代;不同则判断链表高度插入链表,当链表高度到8,数组长度超过64,转为红黑树;长度低于6则重新转回链表
-
key为null,存在下标0位置
hashTable涉及到数组扩容
HashMap使用键/值得形式保存数据HashMap允许将null用作键 HashMap允许将null用作值
Collection与Collections
牛客例题 百度 Collection和Collections的区别及Collections常用方法
-
Collection 是一个集合接口。提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection 接口的意义是为各种具体的集合提供了最大化的统一操作方式
-
Collections 是一个包装类。它包含有各种有关集合操作的静态多态方法。此类不能实例化,就像一个工具类,服务于Java的Collection框架
可以使用 Collections.unmodifiableCollection(Collection c) 方法来创建一个只读集合,这样改变集合的任何操作都会抛出 java.lang.UnsupportedOperationException 异常
请你说说Iterator和ListIterator的区别
Iterator可用来遍历Set和List集合,但是ListIterator只能用来遍历List。ListIterator是一个更强大的Iterator子类型 Iterator 只能向前移动,而 ListIterator 可以双向移动 ListIterator实现了Iterator接口,并包含其他的功能,比如:增加元素,替换元素,获取前一个和后一个元素的索引,等等。
简单说明一下什么是迭代器
Java迭代器的查找操作和位置变更是紧密相连的。只能顺序next()或者反序previous()依次遍历。不能像get(index)那样随机访问
-
Iterator提供了统一遍历操作集合元素的统一接口, Collection接口实现Iterable接口;
-
每个集合都通过实现Iterable接口中iterator()方法返回Iterator接口的实例, 然后对集合的元素进行迭代操作;
-
有一点需要注意的是:在迭代元素的时候不能通过集合的方法删除元素, 否则会抛出ConcurrentModificationException 异常. 但是可以通过Iterator接口中的remove()方法进行删除;

牛客例题
Iterator 支持从源集合中安全地删除对象,只需在 Iterator 上调用 remove() 即可。这样做的好处是可以避免 ConcurrentModifiedException ,当打开 Iterator 迭代集合时,同时又在对集合进行修改。有些集合不允许在迭代时删除或添加元素,但是调用 Iterator 的remove() 方法是个安全的做法。
hashCode与equals
进行对比值操作
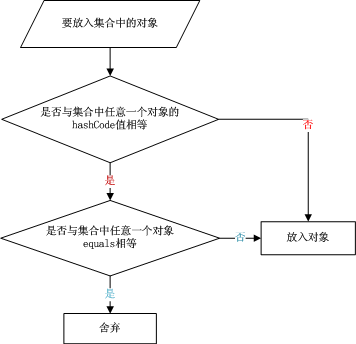
hashcode()和equals()的作用、区别、联系 - 简书 牛客例题 hashCode()定义在JDK的Object.java 中,java中任何类都包含有hashCode()函数。散列表存储的是键值对(key-value),特点:能根据“键”快速检索对应的“值”
hashCode:在对象加入HashSet时,会先计算对象的hashCode值来判断对象加入位置,如果对应位置没有值,hashSet会假设对象没有重复;如果有值,将调用equal()方法检查两个对象是否真的相同,如果相同,hashSet不让其加入操作执行;如果不同将被散列到其他位置,从而减少调用equal次数,提升运行速度
-
如果两个对象相等,hashcode一定相同;对两个对象分别调用equal方法 都返回true
-
两个对象有相同的hashcode值也不一定相等;equal方法被覆盖过的话,hashcode方法也必须被覆盖
-
hashCode()的默认行为是对堆上对象产生独特值;如果没有重写hashCode(),则改class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
HashMap因为key也是唯一的,HashMap对象是根据其Key的hashCode来定位存储位置,并使用equals(key)获取对应的Value,所以在put时判断key是否重复用到了hashcode和equals,若重复了则会覆盖。

ConcurrentHashMap原理(jdk7和jdk8版本区别)
jdk7:ReentrantLock+Segment+HashEntry
数据结构:ReentrantLock+Segment+HashEntry,一个Segment中包含一个HashEntry数组,每个HashEntry有时一个链表
元素查询:二次hash,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表头部 锁:Segment分段锁

Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样
jdk8:synchronized+CAS+HashEntry+红黑树
接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发
锁的粒度就是HashEntry(首节点);因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档

哪些集合类是线程安全的?
Vector、Hashtable、Stack 都是线程安全的,而像 HashMap 则是非线程安全的,不过在 jdk 1.5 之后随着 java.util.concurrent 并发包的出现,它们也有了自己对应的线程安全类,比如 HashMap 对应的线程安全类就是 ConcurrentHashMap。
牛客例题 牛客例题2
多线程
多线程编程优缺点 多线程面试 代码实现
响应性:对于用户图形界面尤其有用,当用户点击一个按钮执行耗时操作时(比如复制一个巨大的文件),应用程序依旧可以通过其他线程响应用户的操作
资源共享:进程只能通过共享内存和消息传递之类由程序员显示安排的技术共享资源;线程默认共享他们所属进程的内存和资源,系统允许一个应用程序在同一地址空间内有多个不同活动线程,一个线程的数据可以直接为其它线程所用;
经济:通常情况下创建一个进程所需的内存和资源相比线程要多得多,且进程的销毁操作也需要系统进行资源回收;线程能够共享所属线程资源,因此在创建和切换操作上更加经济
可伸缩性:多处理器体系结构更适合多线程,能够支持多个任务并行执行;多CPU系统更加有效,操作系统会保证当线程数不大于CPU数目时,不同的线程运行于不同的CPU上

线程和进程区别
参考博客
线程具有许多传统进程所具有的特征,故又称为轻型进程(Light—Weight Process)或进程元;而把传统的进程称为重型进程(Heavy—Weight Process),它相当于只有一个线程的任务。在引入了线程的操作系统中,通常一个进程都有若干个线程,至少包含一个线程。
根本区别:进程是操作系统资源分配和调度的基本单位,而线程是处理器任务调度和执行的基本单位
资源开销:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
包含关系:如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
内存分配:同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的
影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
执行过程:每个独立的进程有程序运行的入口、顺序执行序列和程序出口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,两者均可并发执行
管程:Monitor——一种加锁实现的同步机制,保障同一时间只有一个线程可以访问被保护(加锁)的数据和代码; JVM中同步是基于进入和退出监视器对象(Monitor,管程对象)来实现的,每个对象实例都会有一个Monitor对象; 其和Java对象一并创建和销毁,底层由C++实现
执行线程要求先成功持有管程,然后执行方法,最后方法完成(正常与非正常)时释放管程;方法执行期间,执行线程持有管程,其他任何线程都无法再获取到同一管程;如出现异常,且方法内部无法进行处理,那么这个同步方法所持有的管程将在异常抛到同步方法边界之外自动释放
多进程和多线程区别
-
多进程:操作系统中同时运行的多个程序
-
多线程:在同一个进程中同时运行的多个任务
举个例子,多线程下载软件,可以同时运行多个线程,但是通过程序运行的结果发现,每一次结果都不一致。 因为多线程存在一个特性:随机性。造成的原因:CPU在瞬间不断切换去处理各个线程而导致的,可以理解成多个线程在抢CPU资源。
进程间通信和线程间通信区别
通信方式差异
一、进程间的通信方式
-
管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。 有名管道 (namedpipe) :有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
-
信号量(semophore ) :信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
-
消息队列( messagequeue ) :消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
-
信号 (sinal ) :信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
-
共享内存(shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量配合使用,来实现进程间的同步和通信。
-
套接字(socket ) :套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同设备及其间的进程通信。
二、线程间的通信方式
锁机制:包括互斥锁、条件变量、读写锁
-
互斥锁提供了以排他方式防止数据结构被并发修改的方法。
-
读写锁允许多个线程同时读共享数据,而对写操作是互斥的。
-
条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
-
信号量机制(Semaphore):包括无名线程信号量和命名线程信号量 信号机制(Signal):类似进程间的信号处理 线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制。
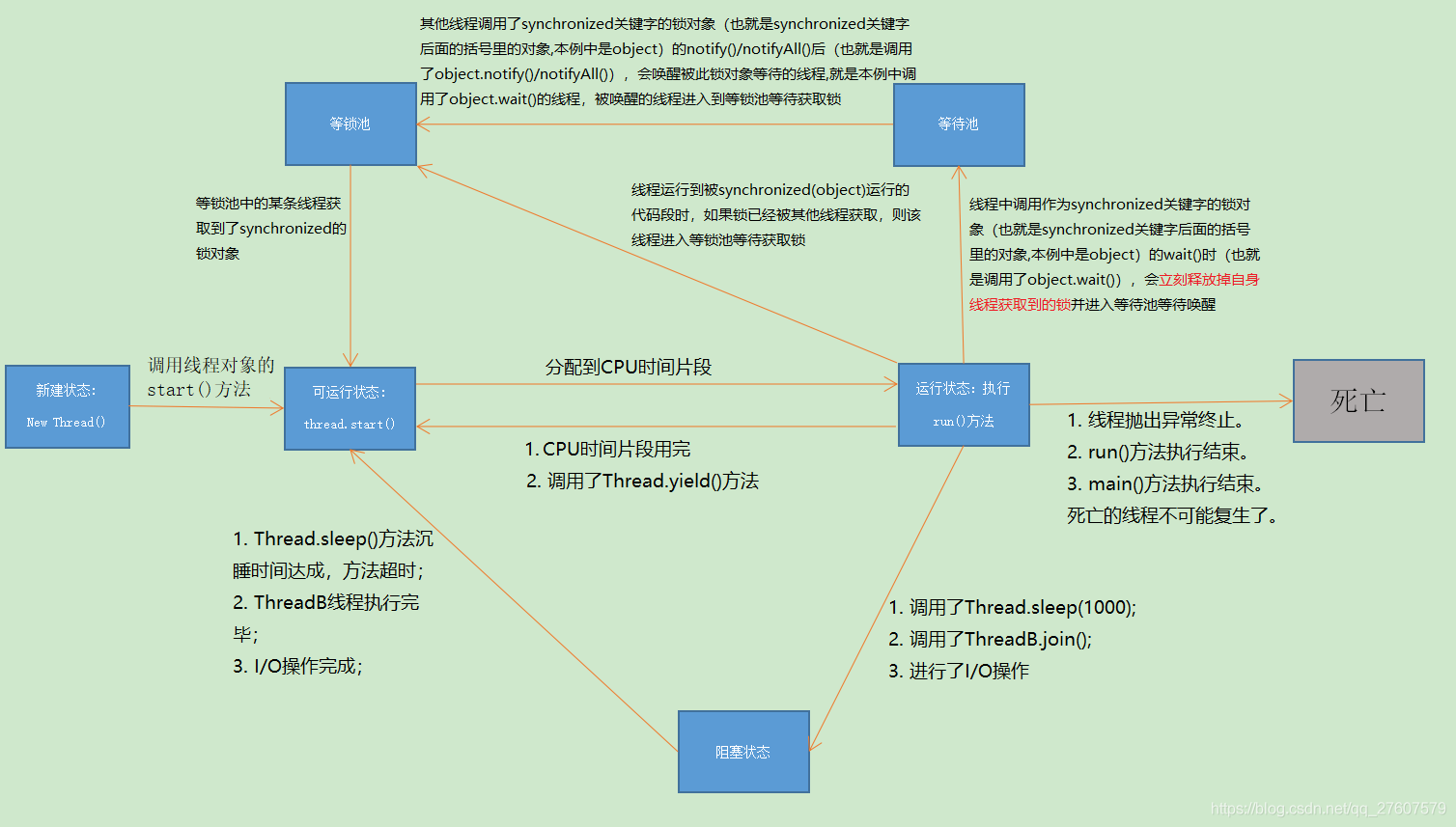
线程状态
java线程+并发机制 线程的5种状态总结 牛客例题

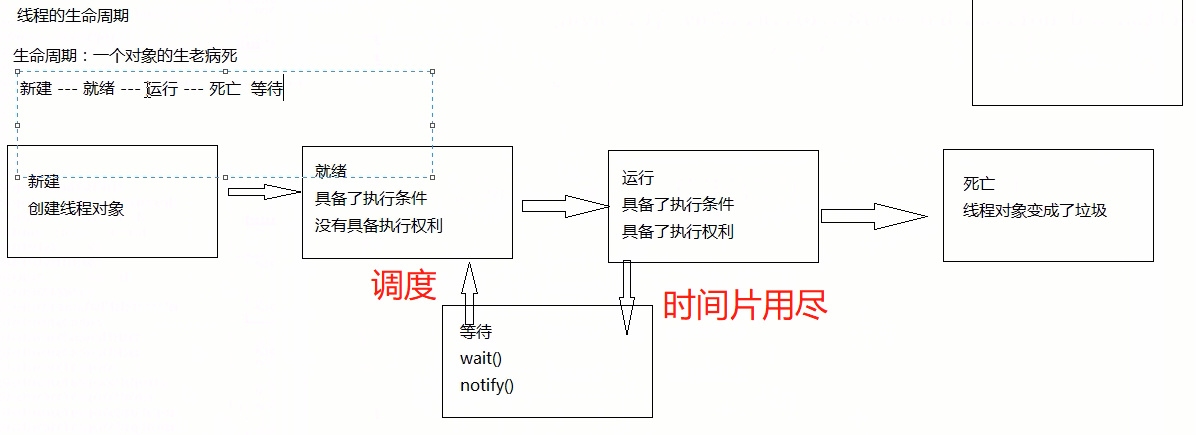
线程有五个状态:
-
创建状态:线程被创建
-
就绪状态:线程一旦被创建,等待CPU的调用—形成就绪队列
-
运行状态:就绪状态的线程被CPU选中被执行,当时间片轮转调度到期后 线程由运行状态进行就绪状态
-
等待状态:线程运行过过程中由于缺少资源或者其他原因将中途被迫退出 ,即进入等待状态。当满足资源条件的时候,线程由等待状态进行就绪状态,重新等待CPU的调度(就绪状态不能回到等待状态)
-
结束状态:线程正常执行完毕,进入结束状态(等待状态可以直接进入结束状态 如果发生死锁,计算机不加与干预,系统根据策略将等待状态的进程直接转到结束状态 —非正常结束)
并发 牛客例题
A,CopyOnWriteArrayList适用于写少读多的并发场景
B,ReadWriteLock即为读写锁,他要求写与写之间互斥,读与写之间互斥,
读与读之间可以并发执行。在读多写少的情况下可以提高效率
C,ConcurrentHashMap是同步的HashMap,读写都加锁
D,volatile只保证多线程操作的可见性,不保证原子性
守护线程和用户线程
线程的daemon属性为true时表示守护线程,false表示用户线程(默认为false) 当用户线程全部结束时意味程序需要完成的业务已全部结束,系统只剩下守护进行,Java虚拟机会自动退出
守护线程:后台默认完成的一系列系统性服务,比如垃圾回收;是一种特殊线程
用户线程:系统的工作线程,完成系统需要完成的业务操作
进程状态
牛客例题
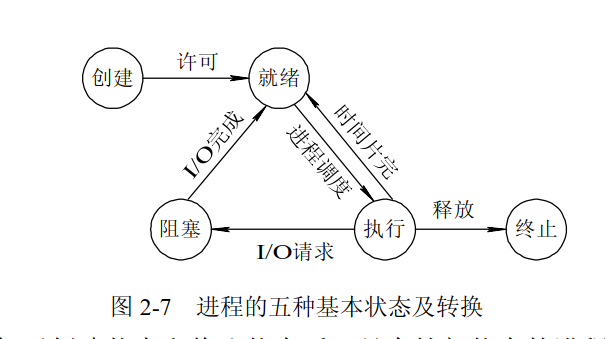
创建状态:进程在创建时需要申请一个空白PCB,向其中填写控制和管理进程的信息,完成资源分配。如果创建工作无法完成,比如资源无法满足,就无法被调度运行,把此时进程所处状态称为创建状态
就绪状态:进程已经准备好,已分配到所需资源,只要分配到CPU就能够立即运行
执行状态:进程处于就绪状态被调度后,进程进入执行状态
阻塞状态:正在执行的进程由于某些事件(I/O请求,申请缓存区失败)而暂时无法运行,进程受到阻塞。在满足请求时进入就绪状态等待系统调用
终止状态:进程结束,或出现错误,或被系统终止,进入终止状态。无法再执行
创建多线程
多线程总结 多线程实现及常用方法 多线程创建的三个方法对比
1.继承Thread类,重载run方法; 2.实现Runnable接口,实现run方法 3.实现Callable接口
Java多线程实现方式主要有四种:
-
继承Thread类 实现Runnable接口
-
实现Callable接口通过FutureTask包装器来创建Thread线程
-
使用ExecutorService、Callable、Future实现有返回结果的多线程。
其中前两种方式线程执行完后都没有返回值,后两种是带返回值的。
序列化
牛客例题
序列化是把对象转换为字节序列的过程,为了存储在磁盘上或者进行网络传输。 反序列化是把存储在磁盘或网络节点上的字节序列恢复为对象的过程。 这是java进程之间通信的方式
序列化:将数据结构转换称为二进制数据流或者文本流的过程。序列化后的数据方便在网络上传输和在硬盘上存储。
反序列化:与序列化相反,是将二进制数据流或者文本流转换称为易于处理和阅读的数据结构的过程。本质其实还是一种协议,一种数据格式,方便数据的存储和传输。
Thread与Runnable
csdn 简书
-
效果上没区别,写法上的区别而已。
-
Thread实现了Runnable接口并进行了扩展,而Thread和Runnable的实质是实现的关系,不是同类东西,所以Runnable或Thread本身没有可比性。
写法上的区别无非就是你是new Thead还是new你自定义的thread,如果你有复杂的线程操作需求,那就自定义Thread,如果只是简单的在子线程run一下任务,那就直接实现runnable,当然如果自己实现runnable的话可以多一个继承(自定义Thread必须继承Thread类,java单继承规定导致不能在继承别的了)
说一下 runnable 和 callable 有什么区别?
-
Runnable 接口 run 方法无返回值;Callable 接口 call 方法有返回值,支持泛型
-
Runnable 接口 run 方法只能抛出运行时异常,且无法捕获处理;Callable 接口 call 方法允许抛出异常,可以获取异常信息
执行流程
牛客例题
线程安全
线程安全与线程不安全
线程池
简书 csdn(带例子)
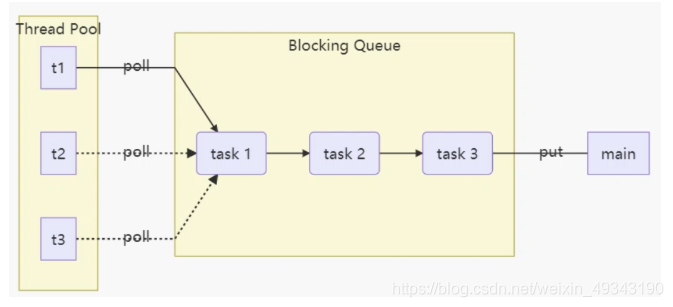
线程池示意图
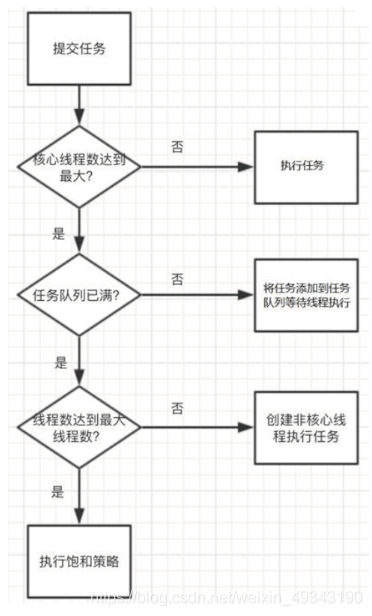
任务流程图
主要思想:在进程开始时创建一定数量的线程,并加到池中等待服务器收到请求后被唤醒去完成相应请求,一旦完成了服务便返回池中继续等待工作;如果池内没有可用线程,那么服务器会持续等待到有空线程为止。
优点:使用现有的线程服务比等待创建一个线程更快 ,过于频繁创建/销毁线程对处理效率影响较大
允许采用不同策略运行任务 比如:延时执行、定时循环执行的策略等
线程池限制了任何时刻可用的线程总数,对不能支持高并发线程的系统十分重要 避免导致系统资源不足引起阻塞
线程池
//corePoolSize核心线程数 maximumPoolSize=核心线程数+非核心线程数//五个参数的构造函数public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue)//六个参数的构造函数-1public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory)//六个参数的构造函数-2public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler)//七个参数的构造函数public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
Java通过Executors提供了四种线程池,这四种线程池都是直接或间接配置ThreadPoolExecutor的参数实现的
CachedThreadPool()
可缓存线程池:
-
线程数无限制
-
有空闲线程则复用空闲线程,若无空闲线程则新建线程
-
一定程序减少频繁创建/销毁线程,减少系统开销
创建方法:
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
源码:
public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}
通过我上面行云流水谈笑风生天马行空滔滔不绝的对各种参数的说明,这个源码你肯定一眼就看懂了,想都不用想(下面三种一样啦)
FixedThreadPool()
定长线程池:
-
可控制线程最大并发数(同时执行的线程数)
-
超出的线程会在队列中等待
创建方法:
//nThreads => 最大线程数即maximumPoolSizeExecutorService fixedThreadPool = Executors.newFixedThreadPool(int nThreads);//threadFactory => 创建线程的方法,这就是我叫你别理他的那个星期六!你还看!ExecutorService fixedThreadPool = Executors.newFixedThreadPool(int nThreads, ThreadFactory threadFactory);
源码:
public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}
2个参数的构造方法源码,不用我贴你也知道他把星期六放在了哪个位置!所以我就不贴了,省下篇幅给我扯皮
ScheduledThreadPool()
定长线程池:
-
支持定时及周期性任务执行。
创建方法:
//nThreads => 最大线程数即maximumPoolSizeExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(int corePoolSize);
源码:
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {return new ScheduledThreadPoolExecutor(corePoolSize);}//ScheduledThreadPoolExecutor():public ScheduledThreadPoolExecutor(int corePoolSize) {super(corePoolSize, Integer.MAX_VALUE,DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,new DelayedWorkQueue());}
SingleThreadExecutor()
单线程化的线程池:
-
有且仅有一个工作线程执行任务
-
所有任务按照指定顺序执行,即遵循队列的入队出队规则
创建方法:
ExecutorService singleThreadPool = Executors.newSingleThreadPool();
源码:
public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}
还有一个Executors.newSingleThreadScheduledExecutor()结合了3和4,就不介绍了,基本不用。
拒绝策略
RejectedExecutionHandler接口 当要创建的线程数量大于线程池的最大线程数的时候,新的任务就会被拒绝
public interface RejectedExecutionHandler {void rejectedExecution(Runnable r, ThreadPoolExecutor executor);}
AbortPolicy
ThreadPoolExecutor中默认的拒绝策略就是AbortPolicy。直接抛出异常。
CallerRunsPolicy
CallerRunsPolicy在任务被拒绝添加后,会调用当前线程池的所在的线程去执行被拒绝的任务。
DiscardPolicy
让被线程池拒绝的任务直接抛弃,不会抛异常也不会执行
DiscardOldestPolicy
当任务被拒绝添加时,会抛弃任务队列中最旧的任务也就是最先加入队列的,再把这个新任务添加进去。
-
当LinkedBlockingDeque塞满时,新增的任务会直接创建新线程来执行,当创建的线程数量超过最大线程数量时会抛异常。
-
SynchronousQueue没有数量限制。因为他根本不保持这些任务,而是直接交给线程池去执行。当任务数量超过最大线程数时会直接抛异常。
异常处理
Throwable、Error、Exception、RuntimeException 区别 联系 常见的几种RuntimeException
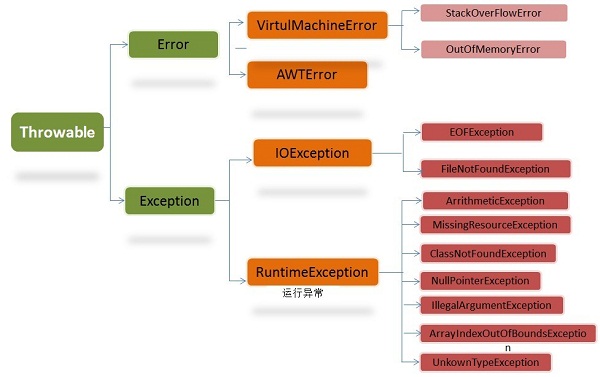
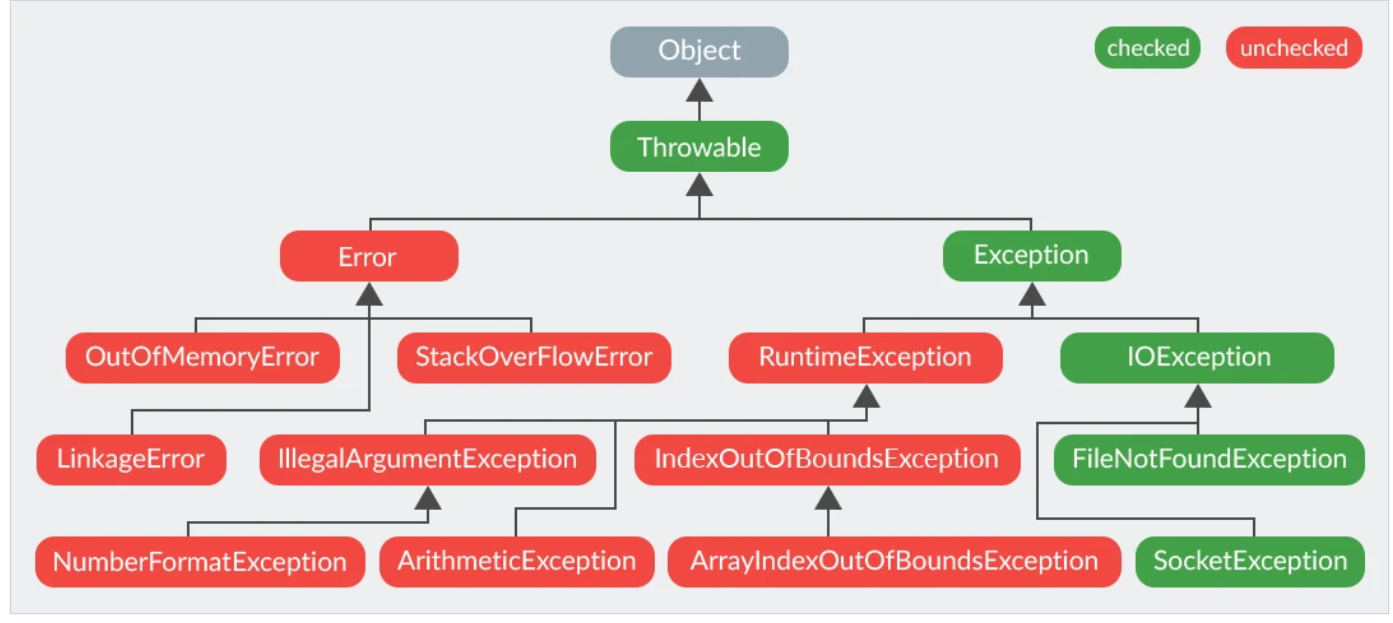
CodeGym
我们可以将异常运行时情况分为两组:**Throwable**
-
程序无法恢复并继续正常运行的情况。
-
可以恢复的情况。
第一组包括涉及从Error类下降的异常的情况。这些是由于JVM故障、内存溢出或系统故障而发生的错误。它们通常表示软件无法修复的严重问题。在 Java 中,编译器不会检查此类异常的可能性,因此称为未检查异常。该组还包括RuntimeException,它们是从Exception类派生并由JVM在运行时生成的异常。它们通常是由编程错误引起的。这些异常也没有被检查(unchecked) 在编译时,因此您不需要编写代码来处理它们。第二组包括在您编写程序时可以预见的异常情况(因此您应该编写代码来处理它们)。此类异常称为受检异常。谈到异常时,Java 开发人员的大部分工作就是处理这种情况。
RuntimeException和非RuntimeException的区别
Error : 系统级别的错误,如栈溢出 内存溢出之类,此类错误一般情概况保证程序能安全退出即可
Exception : 分为 RuntimeException 和 非RuntimeException RuntimeException: 程序员的错误,程序的错误,需要修改程序 如: 空指针异常 类型转换错误 数组越界 非RuntimeException: 外部环境导致程序的异常,和程序无关 如:在读取外部文件的时候,出现文件找不到的情况
java异常和错误的基类Throwable,包括Exception和Error
throw与throws
牛客例题
-
throw用于抛出异常。
-
throws关键字可以在方法上声明该方法要抛出的异常,然后在方法内部通过throw抛出异常对象。
-
throws关键字可以在方法上声明该方法要抛出的异常,然后在方法内部通过throw抛出异常对象。
-
try是用于检测被包住的语句块是否出现异常,如果有异常,则捕获异常,并执行catch语句。
-
cacth用于捕获从try中抛出的异常并作出处理。
-
finally语句块是不管有没有出现异常都要执行的内容。
throws 关键字和 throw 关键字在使用上的几点区别如下:
-
throws 用来声明一个方法可能抛出的所有异常信息,表示出现异常的一种可能性,但并不一定会发生这些异常;throw 则是指拋出的一个具体的异常类型,执行 throw 则一定抛出了某种异常对象。
-
通常在一个方法(类)的声明处通过 throws 声明方法(类)可能拋出的异常信息,而在方法(类)内部通过 throw 声明一个具体的异常信息。
-
throws 通常不用显示地捕获异常,可由系统自动将所有捕获的异常信息抛给上级方法; throw 则需要用户自己捕获相关的异常,而后再对其进行相关包装,最后将包装后的异常信息抛出。
try catch }finally

当一个try块中抛出异常时,JVM 会在下一个catch块中寻找合适的异常处理程序。如果catch块具有所需的异常处理程序,则控制传递给它。如果没有,则JVM 会进一步查找catch块链,直到找到合适的处理程序。执行一个catch块后,控制转移到可选finally块。如果catch没有找到合适的块,JVM 会停止程序并显示stack trace(当前的方法调用堆栈),在第一次执行之后finally如果存在则阻止
public static void main(String[] args) {int result = test();System.out.println(result);}public static int test() {int t = 0;try {return t;} finally {++t;}}
控制台: 0
死锁
死锁面试题(什么是死锁,产生死锁的原因及必要条件)
必要条件:
-
互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
-
请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
-
不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
-
环路等待条件:在发生死锁时,必然存在一个进程--资源的环形链。
常用方法
throw和throws区别
throw:表示方法内抛出某种异常对象 如果异常对象是非 RuntimeException 则需要在方法申明时加上该异常的抛出 即需要加上 throws 语句 或者 在方法体内 try catch 处理该异常,否则编译报错 执行到 throw 语句则后面的语句块不再执行 throws:方法的定义上使用 throws 表示这个方法可能抛出某种异常 需要由方法的调用者进行异常处理
start与run方法
Java Thread 的 run() 与 start() 的区别 牛客例题 牛客例题2 牛客例题3 牛客例题4
调用start()后,线程会被放到等待队列,处于就绪(可运行)状态,并没有运行,一旦得到cpu时间片,就开始执行run()方法,执行本线程的线程体。run方法运行结束,此线程随即终止。
-
start()方法来启动线程,真正实现了多线程运行,不能多次重复启动一个线程;无需等待run方法体代码执行完毕,可以直接继续执行下面的代码;
-
run方法只是thread的一个普通方法调用,还是在主线程里执行,可以在同一线程重复调用;程序要顺序执行,要等待run方法体执行完毕后,才可继续执行下面的代码,因此run()没有达到多线程的目的。run()方法必须是public访问权限,返回值类型为void
start是异步非阻塞调用,run是同步阻塞调用,多线程要求就是异步非阻塞调用,所以start才能体现多线程本质
实现并启动线程有两种方法 1、写一个类继承自Thread类,重写run方法。用start方法启动线程 继承Thread类实现重写的run方法 2、写一个类实现Runnable接口,实现run方法。用new Thread(Runnable target).start()方法来启动 实现Runnable接口,实例化Thread后调用run方法
sleep与wait
牛客例题 牛客例题2
在调用sleep()方法的过程中,线程不会释放对象锁。 sleep()是Thread的方法
而当调用wait()方法的时候,是Object类的方法;线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify()方法后本线程才进入对象锁定池准备
volatile
为了提高处理速度,JVM会对代码进行编译优化,也就是指令重排序优化,并发编程下指令重排序会带来一些安全隐患:如指令重排序导致的多个线程操作之间的不可见性

-
编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序;
-
指令级并行的重排序。现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序;
-
内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行的。
满足三点时才应该使用volatile
-
对变量的写入操作不依赖变量当前值,或只有单个线程更新变量值
-
该变量不会与其他变量同时纳入不变性条件中
-
访问变量时不需要加锁
java编译器会在生成指令系列时在适当的位置会插入内存屏障指令来禁止特定类型的处理器重排序

volatile写是在前面和后面分别插入内存屏障,而volatile读操作是在后面插入两个内存屏障
- 保证变量的内存可见性 - 禁止指令重排序
-
volatile修饰符适用于以下场景:某个属性被多个线程共享,其中有一个线程修改了此属性,其他线程可以立即得到修改后的值,比如booleanflag;或者作为触发器,实现轻量级同步。
-
volatile属性的读写操作都是无锁的,它不能替代synchronized,因为它没有提供原子性和互斥性。因为无锁,不需要花费时间在获取锁和释放锁_上,所以说它是低成本的。
-
volatile只能作用于属性,我们用volatile修饰属性,这样compilers就不会对这个属性做指令重排序。
-
volatile提供了可见性,任何一个线程对其的修改将立马对其他线程可见,volatile属性不会被线程缓存,始终从主 存中读取。
-
volatile提供了happens-before保证,对volatile变量v的写入happens-before所有其他线程后续对v的读操作。
-
volatile可以使得long和double的赋值是原子的。
-
volatile可以在单例双重检查中实现可见性和禁止指令重排序,从而保证安全性
-
volatile可以看做是轻量版的synchronized,volatile不保证原子性,但是如果是对一个共享变量进行多个线程的赋值,而没有其他的操作,那么就可以用volatile来代替synchronized,因为赋值本身是有原子性的,而volatile又保证了可见性,所以就可以保证线程安全了。
-
当我们用
volatile关键字修饰共享变量时就可以做到以下两点 -
-
当线程修改变量时,会强制刷新到主内存中
-
当线程读取变量时,会强制从主内存读取变量并且刷新到工作内存中
-

线程局部存储TLS(thread local storage)
牛客例题
线程释放锁资源
join()底层就是调用wait()方法的,wait()释放锁资源,故join也释放锁资源
读锁与写锁
发布与逸出
发布:使对象能够在当前作用域之外的代码中使用对象逸出:一种错误的发布,当一个对象还没构建完成时,就被其他线程所见。
避免逸出的方法 发布与逸出
常见对象逸出:
//内部可变状态逸出 在发布一个对象时,该对象的非私有域中引用的所有对象同样会被发布
class UnsafeStates{private String[] states = {"AK","AL",...};public String[] getStates(){return states;}
}
// 隐式的使用this引用逸出 在ThisEscape发布EventListener时因为其内部类实例包含对ThisEscape的引用,因此在发布同时也隐
//含发布了ThisEscape实例本身
public class ThisEscape{public ThisEscape(EventSource source){source.registerListener(new EventListener(){public void onEvent(Event e){dosomething(e);}})}
}
隐式逸出可能导致的问题:本应该是私有的变量被发布(试想你的银行密码被发布到网上); 对象未完全构造便被发布
//使用工厂模式防止this引用在构造函数过程中逸出 发布完整的构造函数(对象)public class SafeListener{private final EventListener listener;private SafeListener(){listener = new EventListener(){public void onEvent(Event e){dosomething(e);}};}public static SafeListener newInstance(EventSource source){SafeListener safe = new SafeListener();source.registerListener(safe.listener);return safe;}}
synchronized使用与原理
-
修饰实例方法,作用于当前实例加锁,进入同步代码前要获得当前实例的锁
-
修饰静态方法,作用于当前类对象加锁,进入同步代码前要获得当前类对象的锁
-
修饰代码块,指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
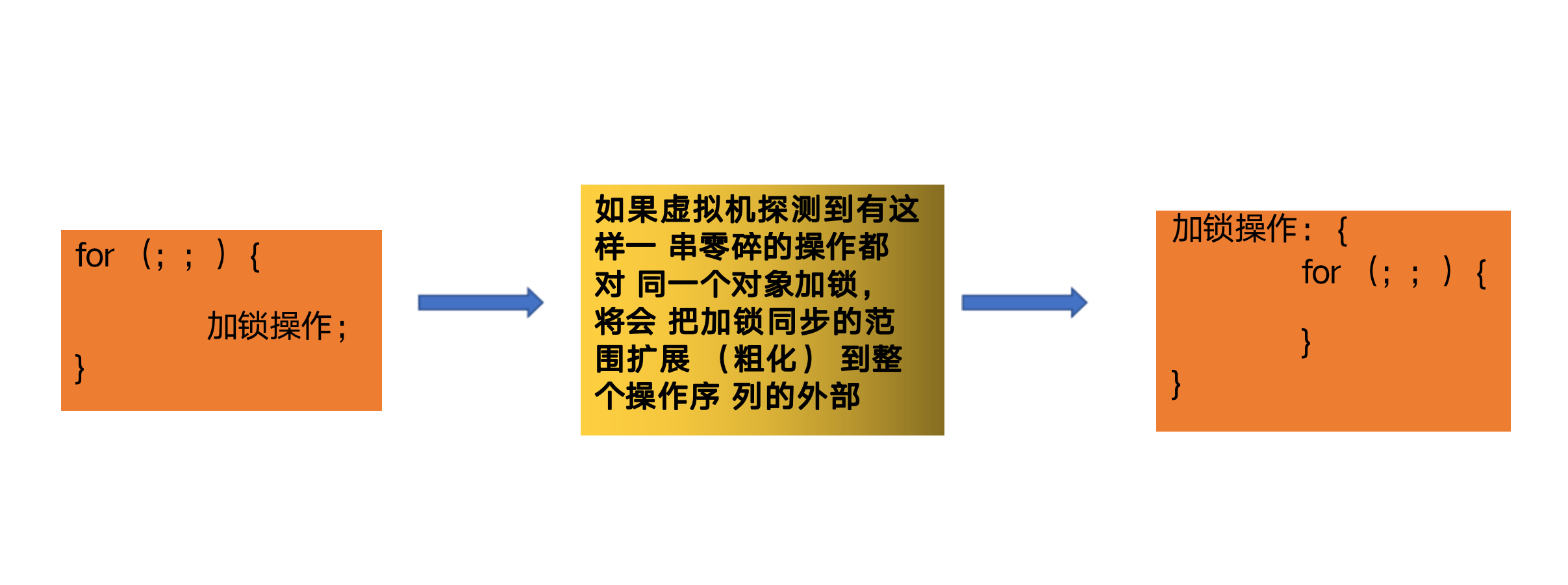
sychronized实现原理 说一下你对Sychronized锁的了解 牛客例题
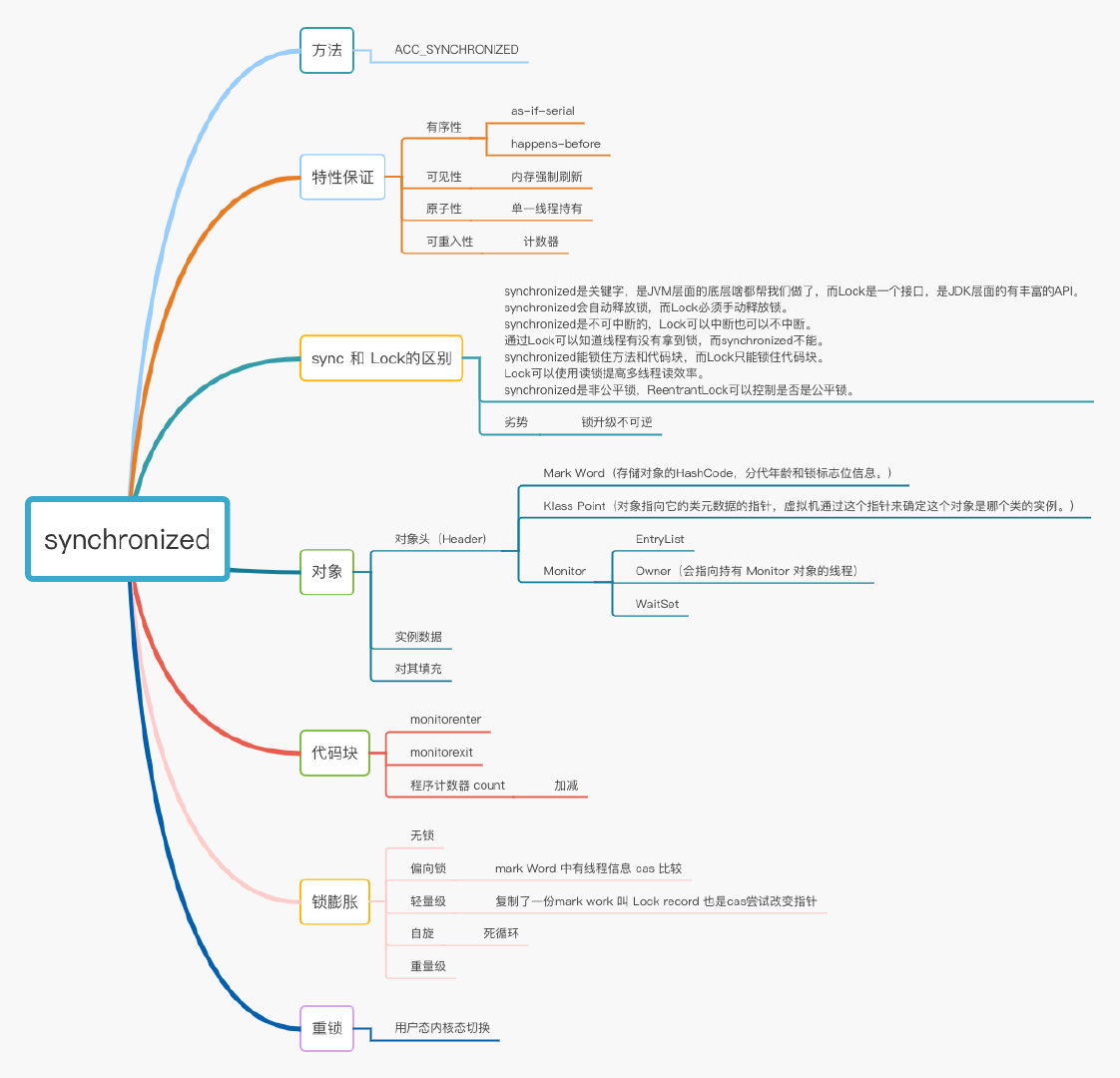
Sychronized的自旋锁、偏向锁、轻量级锁、重量级锁

锁只能进行升级不能降级
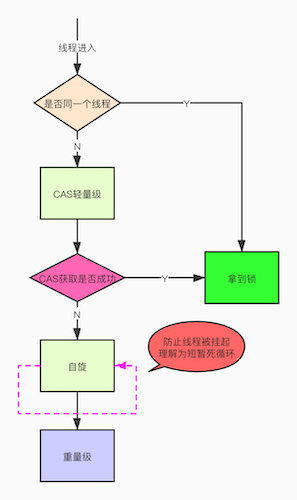
synchronized升级流程简图
sychronized
-
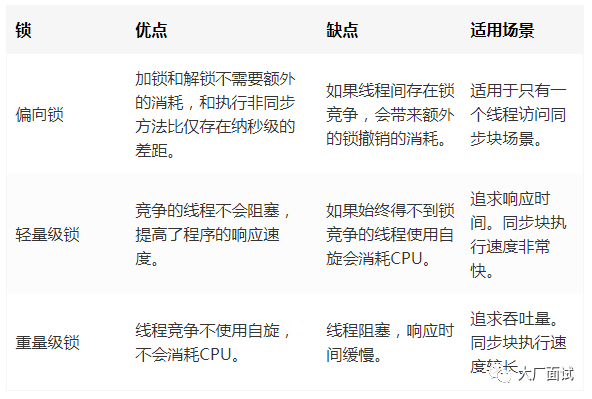
偏向锁:在锁对象的对象头中记录一下当前获取到该锁的线程ID,该线程下次如果又来获取该锁就可以直接获取到了
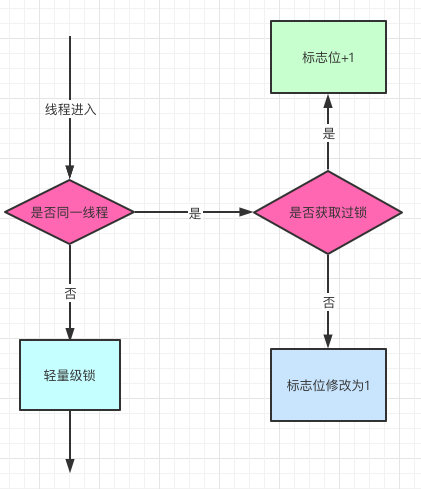
2.轻量级锁:由偏向级锁升级而来,当一个线程获取到锁后,此时这把锁是偏向锁,此时如果有第二个线程来竞争锁,偏向锁就会升级为轻量级锁,之所以叫轻量级锁,是为了与重量级锁区分凯;轻量级锁底层是通过自旋来实现的,并不会阻塞线程
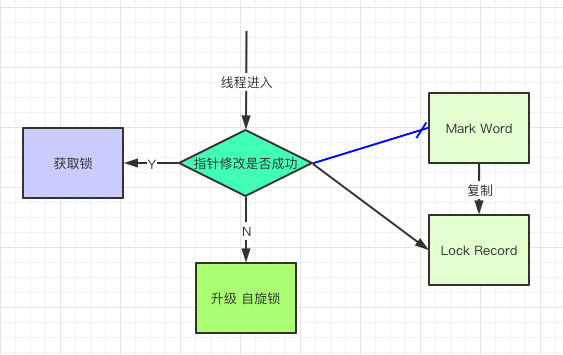
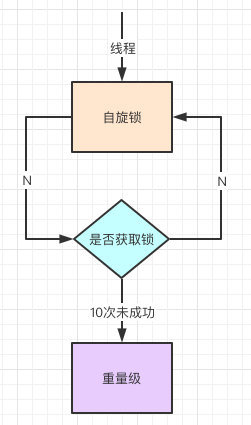
如果自旋次数过多仍然没有获取到锁,则会升级为重量级锁,重量级锁导致线程阻塞
自旋锁:线程在获取锁的过程中不会去阻塞线程,也就无所谓的唤醒线程,阻塞和唤醒这两个步骤都是需要操作系统去进行的,比较消耗时间,自旋锁是线程通过CSA获取预期的一个标记;如果没有获取到,则继续循环获取,获取到了则表示获取到了锁,这个过程一直在运行,相对而言没有使用太多的操作系统资源,比较轻量级
synchronized与Lock的区别:
-
synchronized是关键字,是JVM层面的底层啥都帮我们做了,而Lock是一个接口,是JDK层面的有丰富的API。
-
synchronized会自动释放锁,而Lock必须手动释放锁。
-
synchronized是不可中断的,Lock可以中断也可以不中断。
-
通过Lock可以知道线程有没有拿到锁,而synchronized不能。
-
synchronized能锁住方法和代码块,而Lock只能锁住代码块。
-
Lock可以使用读锁提高多线程读效率。
-
synchronized是非公平锁,ReentrantLock可以控制是否是公平锁。
sychronized和ReentrantLock
相同点:都是加锁方式同步,而且都是阻塞式的同步,也就是说当如果一个线程获得了对象锁,进入了同步块,其他访问该同步块的线程都必须阻塞在同步块外面等待,而进行线程阻塞和唤醒的代价是比较高的(操作系统需要在用户态与内核态之间来回切换,代价很高,不过可以通过对锁优化进行改善)
性能:自从Synchronized引入了偏向锁,轻量级锁(自旋锁)后,两者的性能就差不多了,在两种方法都可用的情况下,官方甚至建议使用synchronized
CAS算法 CAS(Compare And Swap 比较并且替换)是乐观锁的一种实现方式,是一种轻量级锁,JUC 中很多工具类的实现就是基于 CAS 的。;是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。CAS算法涉及到三个操作数
需要读写的内存值 V 进行比较的值 A 拟写入的新值 B 当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个自旋操作,即不断的重试(查询)。
CAS与synchronized的使用情景
-
简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少)
-
synchronized适用于写比较多的情况下(多写场景,冲突一般较多)
对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。 对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
乐观锁与悲观锁
图解悲观锁,乐观锁 乐观锁与CAS实现
乐观锁
认为数据的变动不会太频繁,因此线程在读取数据时不进⾏加锁,它允许多个事务同时对数据进行变动,在准备写回数据时,先去查询原值,操作的时候⽐较原值是否修改,若未被其他线程修改则写回,若已被修改,则重新执⾏读取流程
乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁
乐观锁一般会使用版本号机制或CAS算法实现。 版本号与CAS算法详解
存在的问题 ABA 问题 循环时间长开销大 只能保证一个共享变量的原子操作

悲观锁
悲观锁认为被它保护的数据是极其不安全的,每时每刻都有可能变动,所以都会加锁(读锁、写锁、行锁等),当其他线程想要访问数据时,都需要阻塞挂起。可以依靠数据库实现,如行锁、读锁和写锁等,都是在操作之前加锁,在Java中,synchronized和ReentrantLock等独占锁就是悲观锁思想的实现
两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,因此悲观锁适合应用在写为居多的场景下。 ———————————————— 版权声明:本文为CSDN博主「JavaGuide」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:面试必备之乐观锁与悲观锁_不忘初心-CSDN博客_悲观锁和乐观锁
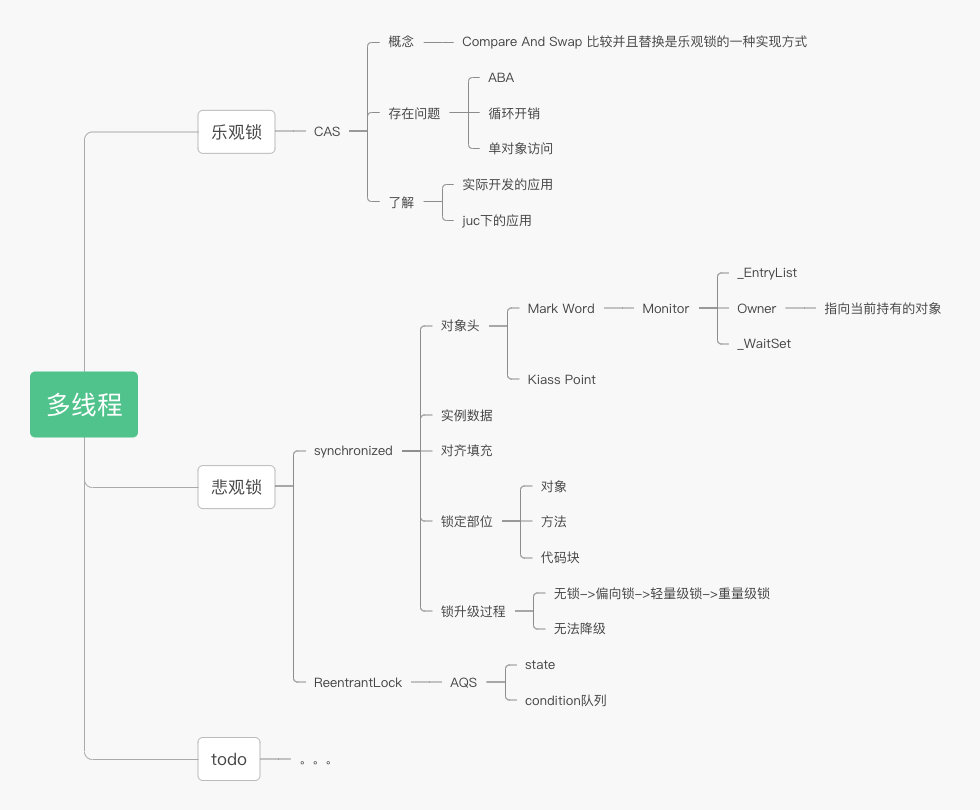
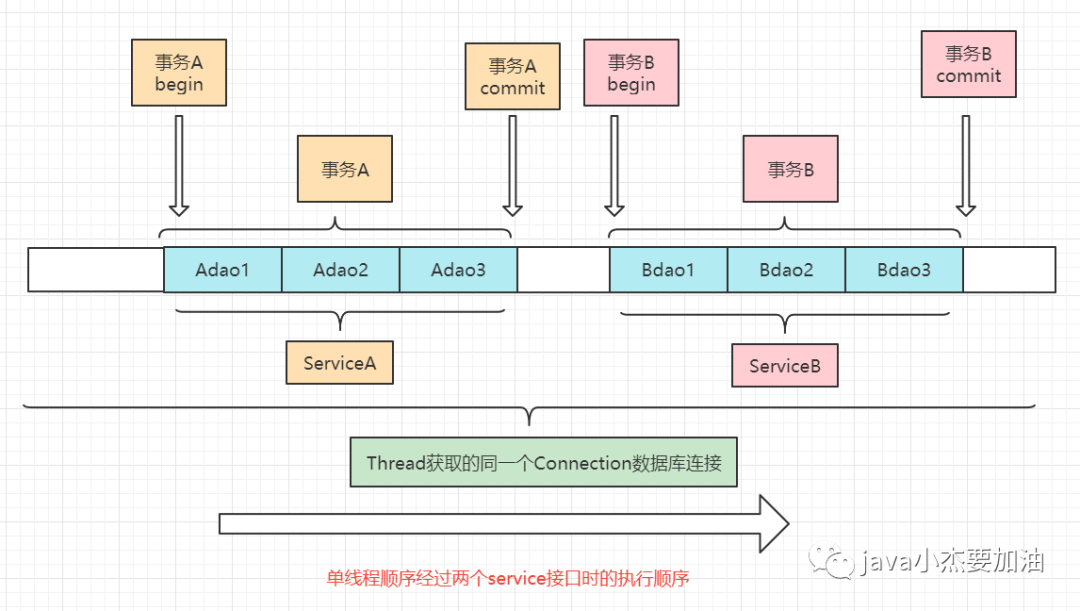
多线程与事务
事务的隔离性是基于不同的连接的
单个线程Thread持有一个数据库连接Connection ,这个连接上可以有多个事务
假设事务中有三个操作数据库的dao方法,如果想用一个事务来管三个操作dao的方法,那么这三个dao的方法必须基于同一个Connection连接,此线程A会获得数据库连接池中的数据库连接ConnectionA
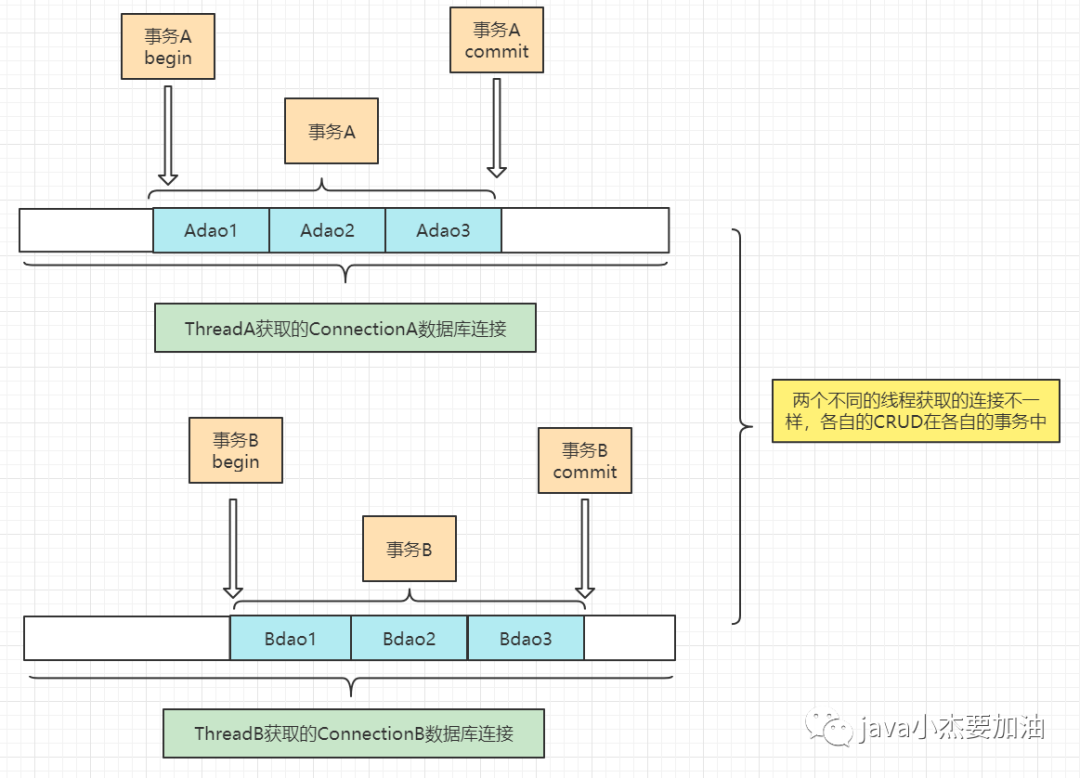
两个线程分别获得不同的数据库连接
框架与后台传输
Spring事务实现分析
Spring 事务
Spring 本身并不实现事务,Spring事务 的本质 还是 底层数据库 对事务的支持,没有 数据库 事务的支持,Spring事务就不会生效。
Spring 事务 提供一套抽象的事务管理,并且结合 Spring IOC 和 Spring AOP,简化了应用程序使用数据库事务,通过声明式事务,可以做到对应用程序无侵入的实现事务功能。例如 使用JDBC 操作数据库,想要使用事务的步骤为:
1、获取连接 Connection con = DriverManager.getConnection()
2、开启事务con.setAutoCommit(true/false);
3、执行CRUD
4、提交事务/回滚事务 con.commit() / con.rollback();
5、关闭连接 con.close();
011609 167601 161022 162412
牛客例题
AOP IOC
AOP IOC W3school
相对于EJB(Enterprise JavaBean,EJB)来说,Spring提供了更加轻量级和简单的编程模型
为了降低Java开发的复杂性,Spring采取了以下4种关键策略:
-
基于POJO的轻量级和最⼩侵⼊性编程;
-
通过依赖注⼊和⾯向接⼝实现松耦合;
-
基于切⾯和惯例进⾏声明式编程;
-
通过切⾯和模板减少样板式代码。
耦合具有两⾯性(two-headed beast)。⼀⽅⾯,紧密耦合的代码难以测试、难以复⽤、难以理解,并且典型地表现出“打地⿏”式的bug特性(修复⼀个bug,将会出现⼀个或者更多新的bug)。另⼀⽅⾯,⼀定程度的耦合⼜是必须的——完全没有耦合的代码什么也做不 了。为了完成有实际意义的功能,不同的类必须以适当的⽅式进⾏交互。总⽽⾔之,耦合是必须的,但应当被⼩⼼谨慎地管理
自动装配实现依赖注入,可以在不改变所依赖的类的情况下,修改依赖关系
Spring装配Bean的两种方式:
1.通过xml实现装配 2.通过使⽤Java来描述配置

package com.springinaction.knights.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.springinaction.knights.BraveK night;
import com.springinaction.knights.K night;
import com.springinaction.knights.Quest;
import com.springinaction.knights.SlayDragonQuest;
@Configurationpublic class K nightConfig {@Beanpublic K night knight() {return new BraveK night(quest());}@Beanpublic Quest quest() {return new SlayDragonQuest(System.out);}
}
Spring通过应⽤上下⽂(Application Context)装载bean的定义并把它们组装起来
Aspect Oriented Program 面向切面编程
在面向切面编程的思想里面,把功能分为核心业务功能,和周边功能。⾯向切⾯往往被定义为促使软件系统实现关注点分离的⼀项技术
-
所谓的核心业务,比如登陆,增加数据,删除数据都叫核心业务
-
所谓的周边功能,比如性能统计,日志,事务管理等等
周边功能在 Spring 的面向切面编程AOP思想里,即被定义为切面;在面向切面编程AOP的思想里面,核心业务功能和切面功能分别独立进行开发,然后把切面功能和核心业务功能 "编织" 在一起,这就叫AOP
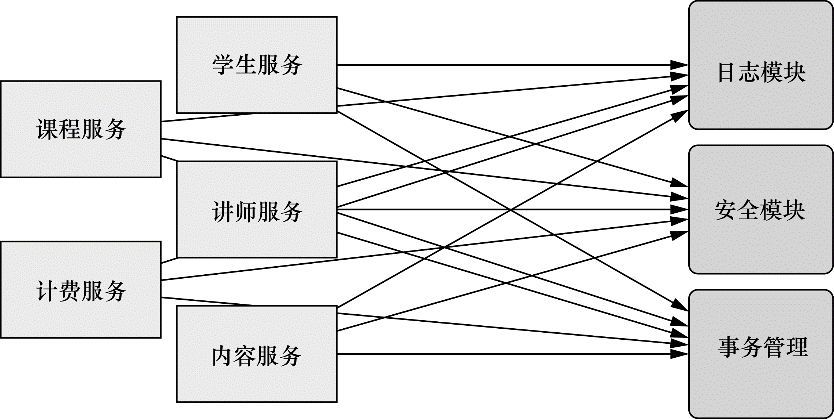
关注点(例如⽇志和安全)的调⽤经常散布到各个模块中,⽽这些关注点并不是模块的核⼼业务
利⽤AOP,系统范围内的关注点覆盖在它们所影响组件之上
AOP 的目的
牛客例题 核心业务还是要OOP来发挥作用,与AOP的侧重点不一样,前者有种纵向抽象的感觉,后者则是横向抽象的感觉, AOP只是OOP的补充,无替代关系
让关注点代码与业务代码分离 AOP使用场景 AOP能够确保POJO的简单性
AOP能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来使这些服务模块化,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
| 注解 | 说明 |
|---|---|
@Before | 前置通知,在连接点方法前调用 |
@Around | 环绕通知,它将覆盖原有方法,但是允许你通过反射调用原有方法,后面会讲 |
@After | 后置通知,在连接点方法后调用 |
@AfterReturning | 返回通知,在连接点方法执行并正常返回后调用,要求连接点方法在执行过程中没有发生异常 |
@AfterThrowing | 异常通知,当连接点方法异常时调用 |
AOP实现
Spring AOP的两种实现技术 Spring实现AOP的四种方式 Spring AOP实现原理
实现AOP的技术,主要分为两大类:
-
一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;
-
二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。
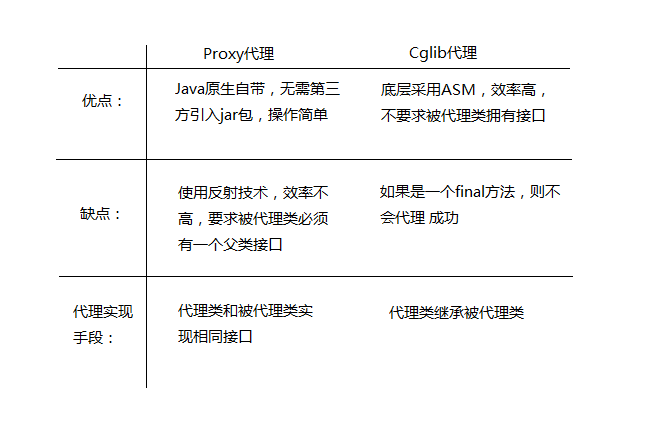
Spring提供了4种实现AOP的方式: 1.经典的基于代理的AOP 2.@AspectJ注解驱动的切面 3.纯POJO切面 4.注入式AspectJ切面
IOC控制反转
《Inversion of Control Containers and the Dependency Injection pattern》
IOC: 控制反转 即控制权的转移,将我们创建对象的方式反转了,以前对象的创建时由我们开发人员自己维护,包括依赖关系也是自己注入。使用了spring之后,对象的创建以及依赖关系可以由spring完成创建以及注入,反转控制就是反转了对象的创建方式,从我们自己创建反转给了程序创建(spring)
由IoC容器帮对象找相应的依赖对象并注入,而不是由对象主动去找
DI: Dependency Injection 依赖注入 spring这个容器中,替你管理着一系列的类,前提是你需要将这些类交给spring容器进行管理,然后在你需要的时候,不是自己去定义,而是直接向spring容器索取,当spring容器知道你的需求之后,就会去它所管理的组件中进行查找,然后直接给你所需要的组件. 实现IOC思想需要DI做支持 注入方式: 1.set方式注入 2.构造方法注入 3.字段注入 注入类型: 1.值类型注入 2.引用类型注入
IOC目的
-
1.降低组件之间的耦合度,实现软件各层之间的解耦.
-
2.可以使容器提供众多服务如事务管理消息服务处理等等。当我们使用容器管理事务时,开发人员就不需要手工 控制事务,也不需要处理复杂的事务传播
-
3.容器提供单例模式支持,开发人员不需要自己编写实现代码.
-
4.容器提供了AOP技术,利用它很容易实现如权限拦截,运行期监控等功能
-
5.容器提供众多的辅佐类,使这些类可以加快应用的开发.如jdbcTemplate HibernateTemplate
applicationContext & BeanFactory区别
Spring⾃带了多个容器实现,可以归为两种不同的类型:
-
bean⼯⼚(由org.springframework.beans.factory.BeanFactory接⼝定义)是最简单的容器,提供基本的DI⽀持。
-
应⽤上下⽂(由org.springframework.context.ApplicationContext接⼝定义)基于BeanFactory构建,并提供应⽤框架级别的服务,例如从属性⽂件解析⽂本信息以及发布应⽤事件给感兴趣的事件监听者
BeanFactory接口 (1) spring的原始接口,针对原始接口的实现类功能较为单一;最简单的容器,它主要的功能是为依赖注入 (DI) 提供支持 (2)BeanFactory接口实现类的容器,特点是每次在获得对象时才会创建对象
ApplicationContext接口
Application Context 是 BeanFactory 的子接口,也被称为 Spring 上下文;是 spring 中较高级的容器。和 BeanFactory 类似,它可以加载配置文件中定义的 bean,将所有的 bean 集中在一起,当有请求的时候分配 bean
(1)每次容器启动时就会创建容器中配置的所有对象 (2)提供了更多功能 (3)多种类型的应⽤上下⽂
-
AnnotationConfigApplicationContext:从⼀个或多个基于Java的配置类中加载Spring应⽤上下⽂。
-
AnnotationConfigWebApplicationContext:从⼀个或多个基于Java的配置类中加载Spring Web应⽤上下⽂。
-
ClassPathXmlApplicationContext:从类路径下的⼀个或多个XML配置⽂件中加载上下⽂定义,把应⽤上下⽂的定义⽂件作为类资源。
-
FileSystemXmlapplicationcontext:从⽂件系统下的⼀个或多个XML配置⽂件中加载上下⽂定义。
-
XmlWebApplicationContext:从Web应⽤下的⼀个或多个XML配置⽂件中加载上下⽂定义
在资源宝贵的移动设备或者基于 applet 的应用当中, BeanFactory 会被优先选择。否则,一般使用的是 ApplicationContext,除非你有更好的理由选择 BeanFactory
Bean 定义
被称作 bean 的对象是构成应用程序的支柱也是由 Spring IoC 容器管理的。bean 是一个被实例化,组装,并通过 Spring IoC 容器所管理的对象。
Spring从两个⾓度来实现⾃动化装配Bean:
-
组件扫描(component scanning):Spring会⾃动发现应⽤上下⽂中所创建的bean。
-
⾃动装配(autowiring):Spring⾃动满⾜bean之间的依赖。
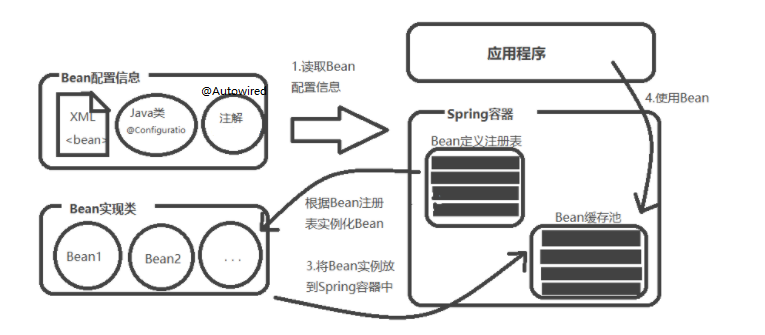
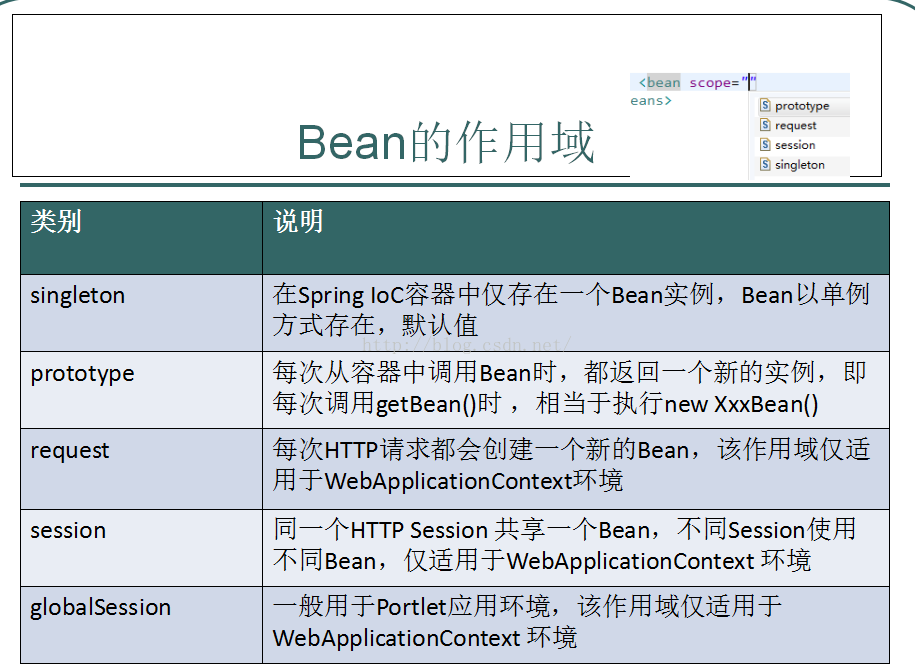
Bean的作用域及生命周期
Bean的生命周期
传统的Java应⽤中,bean的⽣命周期很简单。使⽤Java关键字new进⾏bean实例化,然后该bean就可以使⽤了。⼀旦该bean不再被使 ⽤,则由Java⾃动进⾏垃圾回收
-
实例化 Instantiation
-
属性赋值 Populate
-
初始化 Initialization
-
销毁 Destruction
实例化 -> 属性赋值 -> 初始化 -> 销毁
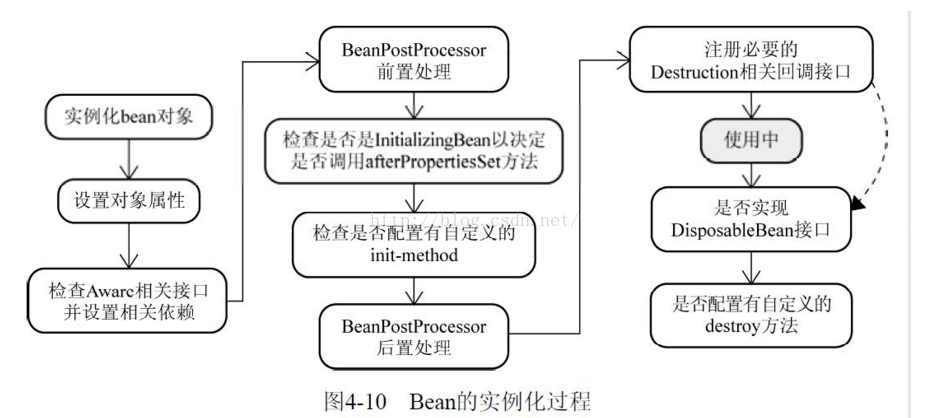
bean装载到Spring应⽤上下⽂中的⼀个典型的⽣命周期过程
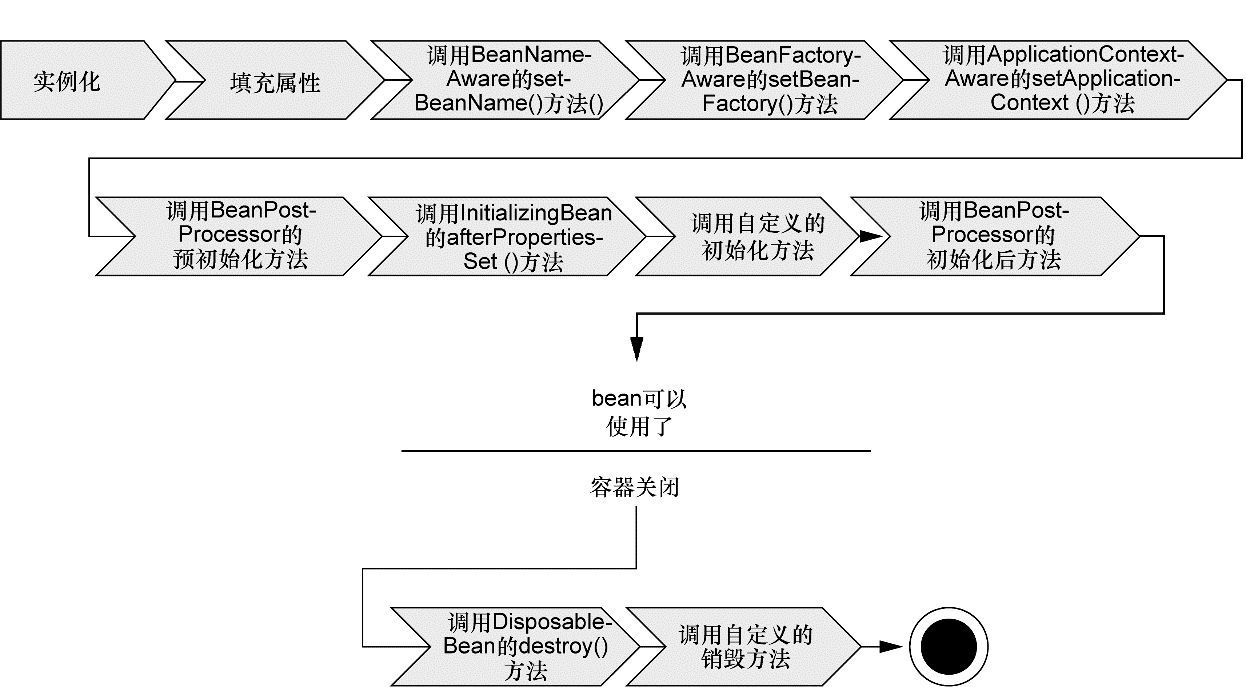
1.Spring对bean进⾏实例化; 2.Spring将值和bean的引⽤注⼊到bean对应的属性中; 3.如果bean实现了BeanNameAware接⼝,Spring将bean的ID传递给setBean-Name()⽅法; 4.如果bean实现了BeanFactoryAware接⼝,Spring将调⽤setBeanFactory()⽅法,将BeanFactory容器实例传⼊; 5.如果bean实现了ApplicationContextAware接⼝,Spring将调⽤setApplicationContext()⽅法,将bean所在应⽤上下⽂的引⽤传进来 6.如果bean实现了BeanPostProcessor接⼝,Spring将调⽤它们的post-ProcessBeforeInitialization()⽅法; 7.如果bean实现了InitializingBean接⼝,Spring将调⽤它们的after-PropertiesSet()⽅法。类似地,如果bean使⽤init-method声明了初始化⽅法,该⽅法也会被调⽤; 8.如果bean实现了BeanPostProcessor接⼝,Spring将调⽤它们的post-ProcessAfterInitialization()⽅法; 9.此时,bean已经准备就绪,可以被应⽤程序使⽤了,它们将⼀直驻留在应⽤上下⽂中,直到该应⽤上下⽂被销毁; 10.如果bean实现了DisposableBean接⼝,Spring将调⽤它的destroy()接⼝⽅法。同样,如果bean使⽤destroy-method声明了销毁⽅法,该⽅法也会被调⽤
Spring组成
Spring从两个⾓度来实现⾃动化装配Bean:
-
组件扫描(component scanning):Spring会⾃动发现应⽤上下⽂中所创建的bean。
-
⾃动装配(autowiring):Spring⾃动满⾜bean之间的依赖。
注解
@Bean
@Bean注解会告诉Spring这个⽅法将会返回⼀个对象,该对象要注册为Spring应⽤上下⽂中的bean。⽅法体中包含了最终产⽣bean实例 的逻辑。
@Bean
public CompactDisc sgtPeppers() {return new SgtPeppers();
}/**默认情况下,bean的ID与带有@Bean注解的⽅法名是⼀样的。在本例中,bean的名字将会是sgtPeppers。如果你想为其设置成⼀个不同
的名字的话,那么可以重命名该⽅法,也可以通过name属性指定⼀个不同的名字:**/
@Bean(name="lonelyHeartsClubBand")
public CompactDisc sgtPeppers() {
return new SgtPeppers();
}
@Component
这个简单的注解表明该类会作为组件类,并告知Spring要为这个类创建bean 还可以为bean设置不同ID
还有另外⼀种为bean命名的⽅式,@Named注解为bean设置ID(Java Dependency Injection Java依赖注⼊规范)
还需要显式配置⼀下Spring,从⽽命令它去寻找带有@Component注解的类,并为其创建bean
//如果想将这个bean标识为lonelyHeartsClub,那么你需要将SgtPeppers类的@Component注解配置为如下所⽰:
@Component("lonelyHeartsClub")
public class SgtPeppers implements CompactDisc {
...
}
@ComponentScan
默认规则,它会以配置类所在的包作为基础包(basepackage)来扫描组件 ;可以通过basePackages属性设置多个基础包
@Configuration
//扫描当前指定的basePackages数组中的包
@ComponentScan(basePackages={"soundsystem", "video"})
public class CDPlayerConfig {}
除了将包设置为简单的String类型之外,@ComponentScan还提供了另外⼀种⽅法,那就是将其指定为包中所包含的类或接⼝:
@Configuration
@ComponentScan(basePackageClasses={CDPlayer.class,DVDPlayer.class})
public class CDPlayerConfig {}
basePackages属性被替换成了basePackageClasses。同时,我们不是再使⽤String类型的名称来指定包,为basePackageClasses属性所设置的数组中包含了类。这些类所在的包将会作为组件扫描的基础包
@Autowired
@Autowired是Spring特有的注解。如果你不愿意在代码中到处使⽤Spring的特定注解来完成⾃动装配任务的话,那么你可以考虑将其替换为@Inject(来源于Java依赖注⼊规范)
构造器装配:构造器上添加@Autowired注解表明当Spring创建CDPlayerbean的时候,会通过这个构造器来进⾏实例化并且会传⼊⼀个可设置给CompactDisc类型的bean。
@Componentpublic class CDPlayer implements MediaPlayer {private CompactDisc cd;//将required属性设置为false时,Spring会尝试执⾏⾃动装配,但是如果没有匹配的bean的话Spring将会让这个bean处于未装配的状态@Autowired(required=false)public CDPlayer(CompactDisc cd) {this.cd = cd;}}
方法装配:在属性的Setter⽅法上
@Autowired 与@Resource的区别(详细)
知乎
@Autowired按类型装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它required属性为false。如果查询的结果不止一个,那么@Autowired会根据名称来查找。如果我们想使用按名称装配,也可以结合@Qualifier注解一起使用。
@Resource有两个中重要的属性:name和type。name属性指定byName,如果没有指定name属性,当注解标注在字段上,即默认取字段的名称作为bean名称寻找依赖对象,当注解标注在属性的setter方法上,即默认取属性名作为bean名称寻找依赖对象。需要注意的是,@Resource如果没有指定name属性,并且按照默认的名称仍然找不到依赖对象时, @Resource注解会回退到按类型装配。但一旦指定了name属性,就只能按名称装配了。
推荐使用@Resource注解在字段上,这样就不用写setter方法了.并且这个注解是属于J2EE的,减少了与Spring的耦合,这样代码看起就比较优雅
@Configuration
进⾏显式配置的时候,有两种可选⽅案:Java和XML
JavaConfig显式配置Spring 关键在于为其添加@Configuration注解,表明这个类是⼀个配置类,该类应该包含在Spring应⽤上下⽂中如何创建bean的细节
forward与redirect
请求转发与重定向
1.从地址栏显示来说
-
forward是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器.浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址.
-
redirect是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址.所以地址栏显示的是新的URL.
2.从数据共享来说
-
forward:转发页面和转发到的页面可以共享request里面的数据.
-
redirect:不能共享数据.
3.从运用地方来说
-
forward:一般用于用户登陆的时候,根据角色转发到相应的模块.
-
redirect:一般用于用户注销登陆时返回主页面和跳转到其它的网站等.
4.从效率来说
forward:高. redirect:低.
Servlet (了解)
牛客例题 牛客例题2
Servlet的生命周期分为5个阶段:加载、创建、初始化、处理客户请求、卸载。
(1)加载:容器通过类加载器使用servlet类对应的文件加载servlet
(2)创建:通过调用servlet构造函数创建一个servlet对象
(3)初始化:调用init方法初始化
(4)处理客户请求:每当有一个客户请求,容器会创建一个线程来处理客户请求
(5)卸载:调用destroy方法让servlet自己释放其占用的资源
牛客例题 牛客例题2
HttpServlet容器响应Web客户请求流程如下:
1)Web客户向Servlet容器发出Http请求;2)Servlet容器解析Web客户的Http请求;
3)Servlet容器创建一个HttpRequest对象,在这个对象中封装Http请求信息; 4)Servlet容器创建一个HttpResponse对象;
5)Servlet容器调用HttpServlet的service方法,这个方法中会根据request的Method来判断具体是执行doGet还是doPost,把HttpRequest和HttpResponse对象作为service方法的参数传给HttpServlet对象;
6)HttpServlet调用HttpRequest的有关方法,获取HTTP请求信息; 7)HttpServlet调用HttpResponse的有关方法,生成响应数据;
8)Servlet容器把HttpServlet的响应结果传给Web客户
状态码
状态码分类:
-
1XX- 信息型,服务器收到请求,需要请求者继续操作。
-
2XX- 成功型,请求成功收到,理解并处理。
-
3XX - 重定向,需要进一步的操作以完成请求。
-
4XX - 客户端错误,请求包含语法错误或无法完成请求。
-
5XX - 服务器错误,服务器在处理请求的过程中发生了错误。
301状态码:被请求的资源已永久移动到新位置
401:请求要求身份验证
403:服务器已经理解请求,但拒绝他
404、请求失败,请求所希望得到的资源未被在服务器上发现
503:由于临时的服务器维护或者过载,服务器无法处理请求。
项目
验证码
shrio实现验证登陆
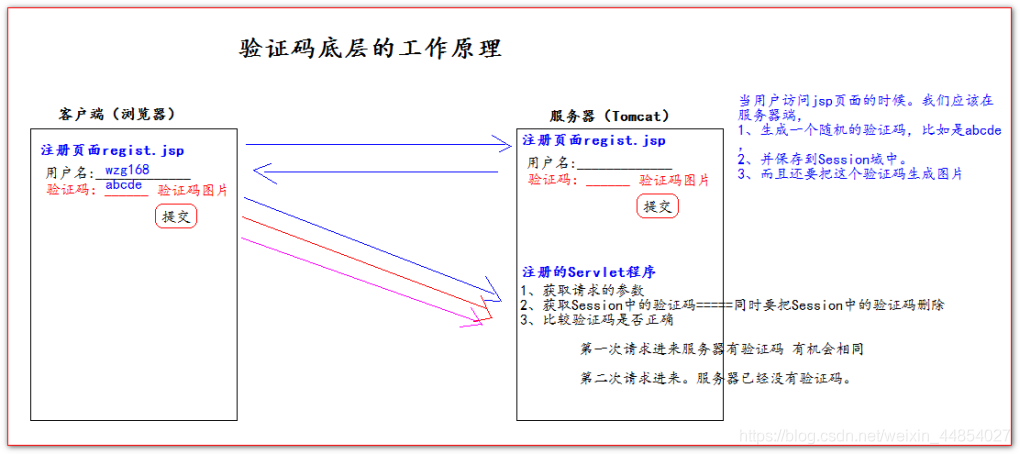
生成:将通过Kaptcha生成的验证码以字符存入session中,然后将图片验证码以流的形式写入到图形流对象后存入response;然后设置header(响应头),然后将此图片流响应回调用方
检验:从session中获取生成的验证码后与用户提交的验证码比对并跳转
// 生成验证码字符串并保存到 session 中String capText = defaultKaptcha.createText();System.out.println("capText: " + capText);session.setAttribute(Constants.KAPTCHA_SESSION_KEY, capText);// 向客户端写出BufferedImage bi = defaultKaptcha.createImage(capText);ServletOutputStream out = null;try {out = response.getOutputStream();ImageIO.write(bi, "jpg", out);out.flush();} catch (IOException e) {System.err.println("输出图形验证码失败");} finally {if (out != null) {try {out.close();} catch (IOException e) {e.printStackTrace();}}}
//验证码检验方法,由login页面调用public static boolean checkVerifyCode(HttpSession session, String key) {// 获取生成的验证码String verifyCode = (String) session.getAttribute(Constants.KAPTCHA_SESSION_KEY);System.out.println("verifyCode: " + verifyCode);// 获取用户输入的验证码return key != null && key.equals(verifyCode);}
Request、Response、Session对象
Response对象用于动态响应客户端请示,控制发送给用户的信息,并将动态生成响应。Response对象提供了一个数据集合cookie,它用于在客户端写入cookie值。若指定的cookie不存在,则创建它。若存在,则将自动进行更新。结果返回给客户端浏览器。
Session对象用户访问网站过程中的会话,Web上这种会话方式是无状态的,一般用于保存用户名等单个用户的信息,比QueryString安全,在浏览器关闭或者Session到期(默认20分钟)时关闭,Session也可以存储数组信息。
图片上传
通过使用SpringMVC 类包MultipartFile类中getInputStream()方法读取返回文件流赋值给inputStream对象 (通过类包java.io中FileInputStream 新建的);然后调用QiNiuUtil.uploadQNImg(inputStream, imgName)七牛工具类以字节流形式上传图片文件,并返回可以直链访问云存储的图片地址 FileInputStream 创建对象这个过程比较复杂有点看不懂,有看的懂的大佬请指点一二;
注意:首先,这个流转换要明晰 MultipartFile 是SpringMVC类包
图片名定义:通过package org.springframework.web.multipart类调用 getOriginalFilename() 获取文件名,而后通过 UUID.randomUUID() 生成16位唯一随机码然后拼接文件名生成新的图片名称用于上传
@PostMapping("/personal")public String personal(HttpSession session, String name, String introduction, @RequestParam("file") MultipartFile file) throws IOException {String path = null;// 获取文件的名称String fileName = file.getOriginalFilename();// 使用工具类根据上传文件生成唯一图片名称String imgName = UUID.randomUUID().toString() + fileName;if (!file.isEmpty()) {FileInputStream inputStream = (FileInputStream) file.getInputStream();path = QiNiuUtil.uploadQNImg(inputStream, imgName);System.out.print("七牛云返回的图片链接:" + path);}User user = (User) session.getAttribute("user");user.setName(name);if (path != null) {user.setAvatar(path);}user.setIntroduction(introduction);userMapper.updateById(user);return "redirect:/manage?uid=" + user.getId();}
uploadQNImg.java
public static String uploadQNImg(FileInputStream file, String key) {// 构造一个带指定Zone对象的配置类, 注意这里的Zone.zone0需要根据主机选择UploadManager uploadManager = new UploadManager(new Configuration(Zone.zone1()));Auth auth = Auth.create(ACCESS_KEY, SECRET_KEY );// 根据命名空间生成的上传tokenString path=null;String token = auth.uploadToken(BUCKETNAME);try{// 上传图片文件Response res = uploadManager.put(file, key, token, null, null);if (!res.isOK()) {throw new RuntimeException("上传七牛出错:" + res.toString());}// 解析上传成功的结果DefaultPutRet putRet = new Gson().fromJson(res.bodyString(), DefaultPutRet.class);path = DOMAIN + "/" + putRet.key;// 这个returnPath是获得到的外链地址,通过这个地址可以直接打开图片}catch (QiniuException e){e.printStackTrace();}return "http://"+path;}
拦截器
WebMvcConfigurer详解 重写addInterceptor方法配置拦截器 拦截器注册使用 preHandle、postHandle与afterCompletion
WebMvcConfigurer配置类其实是Spring内部的一种配置方式,采用JavaBean的形式来代替传统的xml配置文件形式进行针对框架个性化定制,可以自定义一些Handler,Interceptor,ViewResolver,MessageConverter。基于java-based方式的spring mvc配置,需要创建一个配置类并实现WebMvcConfigurer 接口;
-
方式一实现WebMvcConfigurer接口(推荐)
-
方式二继承WebMvcConfigurationSupport类
(1)拦截器中的方法将按 preHandle -> Controller -> postHandle -> afterCompletion 的顺序执行,注意:
-
只有 preHandle 方法返回 true,postHandle、afterCompletion 才有可能被执行;
-
如果 preHandle 方法返回 false,则该拦截器的 postHandle、afterCompletion 必然不会被执行。
(2)当拦截器链内存在多个拦截器时:
-
其中 preHandle 方法返回 true 的拦截器的 afterCompletion 会执行。
-
只有所有拦截器的 preHandle 方法都返回 true,postHandle 才会执行。
1.实现HandlerInterceptor接口自定义拦截器
Interceptor的使用及使用场景
preHandle 调用时间:Controller方法处理之前 执行顺序:链式Intercepter情况下,Intercepter按照声明的顺序一个接一个执行
若返回false,则中断执行,注意:不会进入afterCompletion
public class LoginHandlerInterceptor implements HandlerInterceptor {/*** 在控制器执行之前完成业务逻辑操作* 方法的返回值决定逻辑是否继续执行, true,表示继续执行, false, 表示不再继续执行。*/@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {//判断用户操作状态,非登陆状态操作直接重定位到登录页User loginUser = (User)request.getSession().getAttribute("user");if(loginUser==null){response.sendRedirect("/login?msg=true");return false;}return true;}}
2.重写addInterceptor方法实例化LoginHandlerInterceptor
@Configurationpublic class MyMvcConfig implements WebMvcConfigurer {@Overridepublic void addInterceptors(InterceptorRegistry registry) {//指定拦截器要拦截的请求(/user/* 即user下所有页面)registry.addInterceptor(new LoginHandlerInterceptor()).addPathPatterns("/user/*");//.excludePathPatterns("/admin","/admin/login");//"/css/*","/img/*","/lib/*",}}
常用算法
基础概念
时间复杂度
算法复杂度分为时间复杂度和空间复杂度。其作用: 时间复杂度是指执行算法所需要的计算工作量;而空间复杂度是指执行这个算法所需要的内存空间。
-
T(n)的上界与输入大小无关,则称其具有常数时间,记作O(1)时间
-
T(n) =O(logn),则称其具有对数时间
-
的时间复杂度为O(n),则称这个算法具有线性时间
-
T(n) = O(nlog n),则称这个算法具有线性对数时间
不是时间复杂越低的越好,要考虑数据规模,如果数据规模很小 甚至可以用O(n^2)的算法比 O(n)的更合适
==
什么是稳定排序
保证排序前两个相等的数其在序列的前后位置顺序与排序后它们的前后位置顺序一致。形式化解释如下:一列数中,如果Ai = Aj,Ai位于Aj的前置位,那么经过升降序排序后Ai仍然位于Aj的前置位。 体现程序健壮性
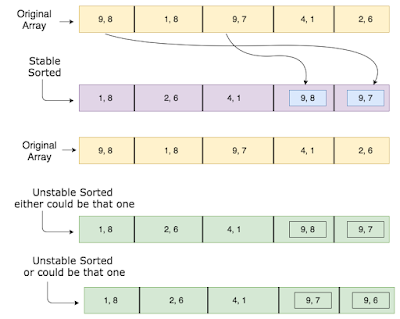
如果在排序的输出中保持相等键或数字的原始顺序,则该算法称为排序算法
-
不稳定排序:选择排序、快速排序、希尔排序、堆排序
-
稳定排序:冒泡排序、插入排序、归并排序和基数排序
快速排序 常见排序
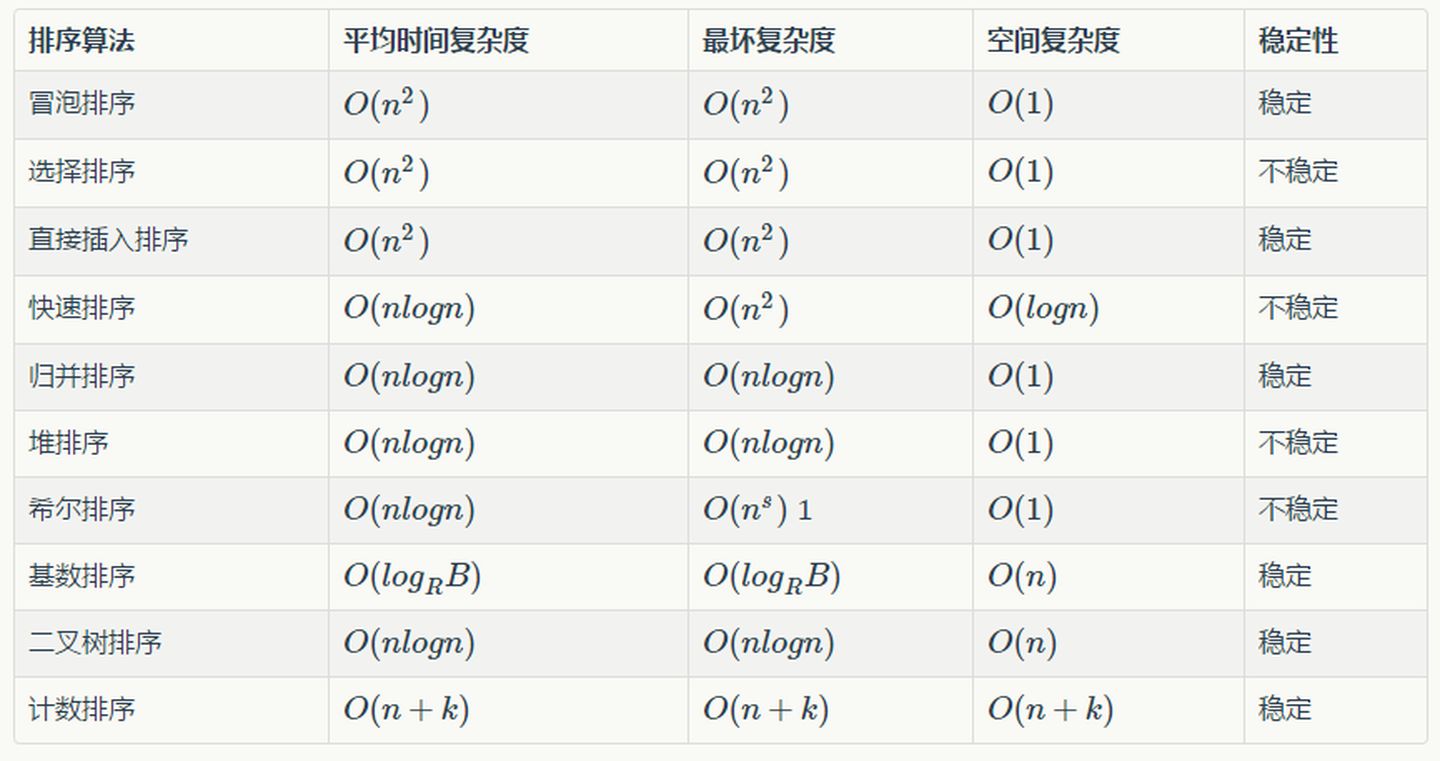
元素的移动次数与关键字的初始排列次序无关的是:基数排序
元素的比较次数与初始序列无关是:选择排序
算法的时间复杂度与初始序列无关的是:选择排序
牛客例题 直接插入排序是数据越有序越快,最快时间复杂度可达到O(n) .选择排序无论何时都是O(n^2)快速排序越有序越慢,它要从后到前遍历找比基准小的,时间复杂度达到O(n)
牛客例题 最坏最好情况下时间复杂度都为O(n^2) 选择排序
牛客例题 稳定排序:冒泡排序、插入排序、归并排序和基数排序 排序稳定性分析
牛客例题
| 查找方式 | 时间复杂度 |
|---|---|
| 顺序查找 | O(N) |
| 分块查找 | O(logN+N/m) |
| 折半查找 | O(logN) |
| 哈希查找 | O(1) |
牛客例题
归并排序在归并过程中需要与原始序列相等的存储空间O(n)用于存放归并结果:递归实现的归并排序还需考虑深度为log2n的栈空间,因此空间复杂度为O(n+log2n);而非递归实现的归并排序避免了递归时深度为log2n的栈空间,因此空间复杂度为O(n)。归并排序是所有排序中占用内存最多,但是效率比较高且稳定的算法,即牺牲内存提高了效率。
牛客例题 时间复杂度,加开根号,乘取对数
牛客例题 快排 1.在完全无序的情况下效果最好,时间复杂度为O(nlogn)2.在有序情况下效果最差,时间复杂度为O(n^2)
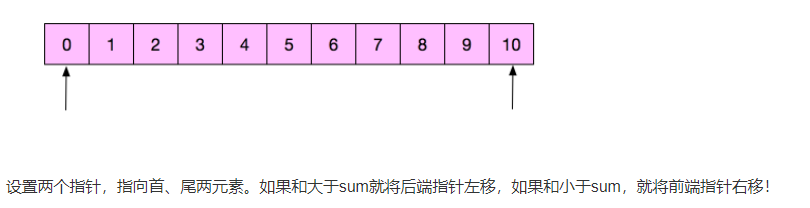
牛客例题 长度为 N 的有序数列中寻找两个数,使得两数之和等于某指定值
target = set()for i in data:if i in target:print(i,sum-i)else:target.add(sum-i)print("not find")
//双指针法
//p,q分别从0和最后一位开始,
//1.如果p+q<S,p++;
//2.如果大于,--q;
//3 如果p=q了还没找到就是不存在。
//p和q就遍历了一遍数组,所以是O(n)
为了更好的让你记住,我给你总结 一下。
常用的排序有简单插入排序,希尔排序,简单选择排序,冒泡排序,归并排序,堆排序还有快速排序。
其中稳定的排序有:简单插入排序,冒泡排序,归并排序。
不稳定的有:希尔排序,简单选择排序,堆排序,快速排序。
时间复杂度为O(n²)的:简单选择排序,简单插入排序,冒泡排序。
时间复杂度为O(nlogn)的:快速排序,堆排序,归并排序。
其中最快的一般为快速排序,但是如果是有序数列,则快速排序的时间复杂度为O(n2);
快速排序虽然快,但是不稳定。
既稳定又快的就是归并排序。
还有堆排序的作用是快速选出最大的几个数,使用小顶堆、快速选出最小的数,使用大顶堆。
当然还有一个基数排序。这个比较特殊,如果想懂推荐你去百度一下它。
刷题算法
二分
在有序数组进行快速查找
如何定义边界值 常见例题及题解

牛客例题
循环队列的相关条件和公式: 队尾指针是rear,队头是front,其中QueueSize为循环队列的最大长度 1.队空条件:rear==front 2.队满条件:(rear+1) %QueueSIze==front 3.计算队列长度:(rear-front+QueueSize)%QueueSize 4.入队:(rear+1)%QueueSize 5.出队:(front+1)%QueueSize
贪心
牛客例题
由上一步的最优解推导下一步的最优解,而上一部之前的最优解则不作保留
单源最短路径中的Dijkstra算法 最小生成树的Prim算法 最小生成树的Kruskal算法
贪心算法:
-
1.贪心算法中,作出的每步贪心决策都无法改变,因为贪心策略是由上一步的最优解推导下一步的最优解,而上一部之前的最优解则不作保留。保证了子问题只会被计算一次,不会被多次计算
-
2.由(1)中的介绍,可以知道贪心法正确的条件是:每一步的最优解一定包含上一步的最优解。
对解空间树的遍历不需要自底向上,而只需要自根开始,选择最优的路,一直走到底就可以了;代价只取决于子问题的数目,而选择数目总为1。
动态规划算法:
-
1.全局最优解中一定包含某个局部最优解,但不一定包含前一个局部最优解,因此需要记录之前的所有最优解
-
2.动态规划的关键是状态转移方程,即如何由以求出的局部最优解来推导全局最优解
-
3.边界条件:即最简单的,可以直接得出的局部最优解
自底向上(从叶子向根)构造子问题的解,对每一个子树的根,求出下面每一个叶子的值,并且以其中的最优值作为自身的值,其它的值舍弃;代价就取决于可选择的数目(树的叉数)和子问题的的数目(树的节点数,或者是树的高度?)
冒泡改进版
for (int i = 1; i < arr.length; i++) {// 设定一个标记,若为true,则表示此次循环没有进行交换,也就是待排序列已经有序,排序已经完成。boolean flag = true;for (int j = 0; j < arr.length - i; j++) {if (arr[j] > arr[j + 1]) {int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;flag = false;}}if (flag) {break;}}return arr;
CPU调度算法
JVM
牛客例题
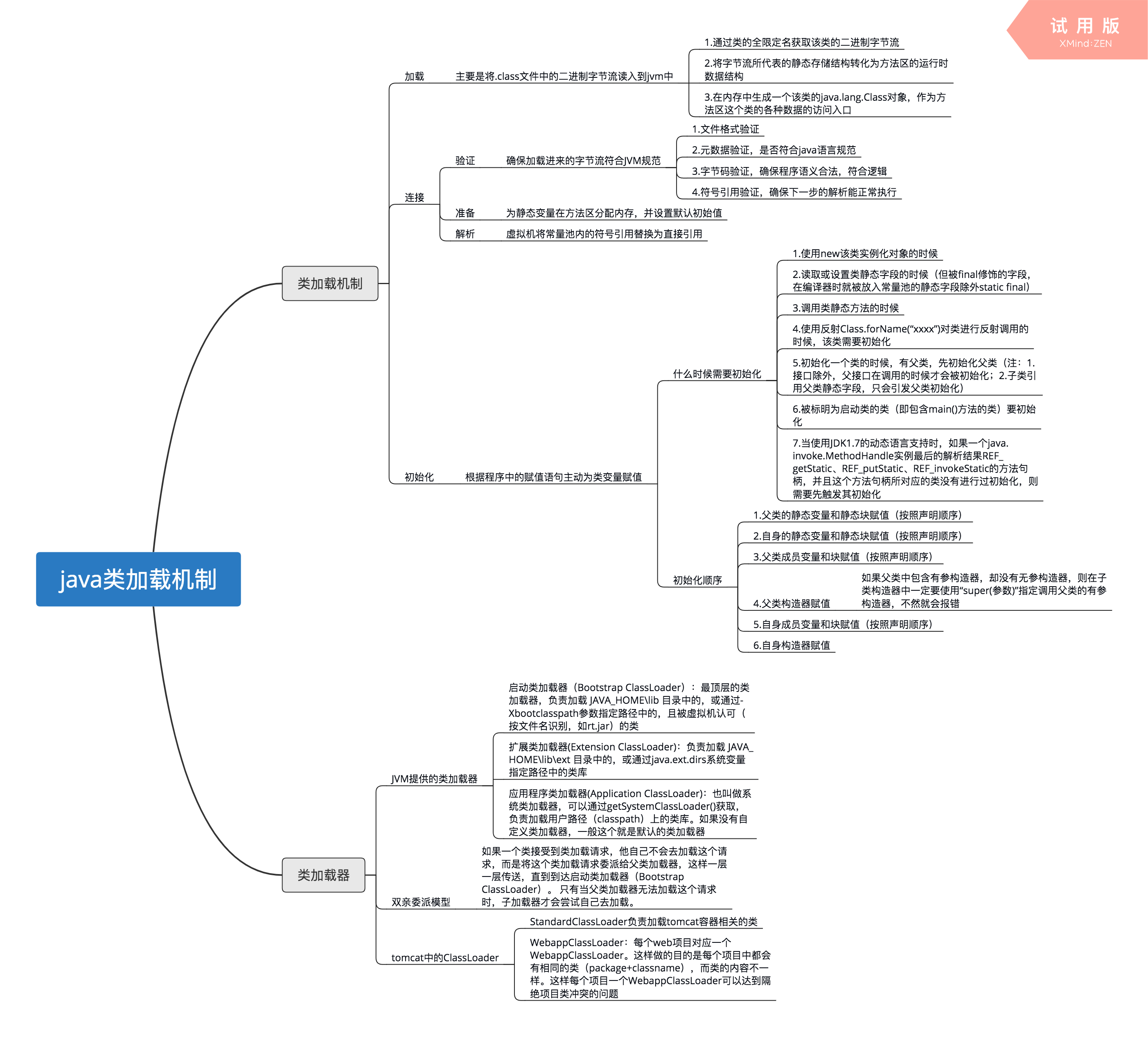
Java体系结构包括四个独立但相关的技术:
-
Java程序设计语言
-
Java.class文件格式
-
Java应用编程接口(API)
-
Java虚拟机
我们再在看一下它们四者的关系:
当我们编写并运行一个Java程序时,就同时运用了这四种技术,用Java程序设计语言编写源代码,把它编译成Java.class文件格式,然后再在Java虚拟机中运行class文件。当程序运行的时候,它通过调用class文件实现了Java API的方法来满足程序的Java API调用

牛客例题
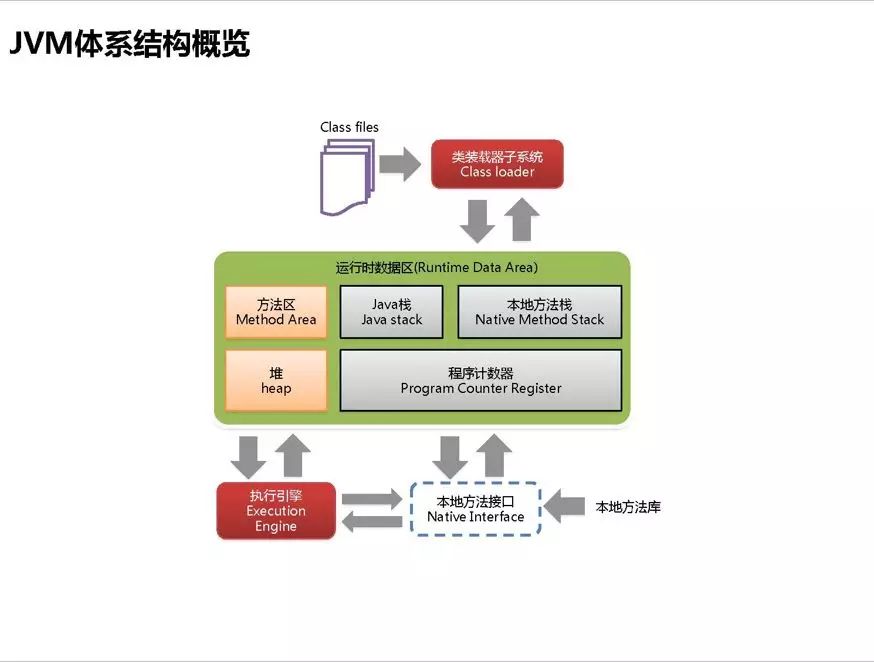
运行时数据区
JVM基础 牛客例题
程序计数器(Program Counter Register)
线程私有,各条线程之间的计数器互不影响,用于在线程执行时充当行号指示器;
程序控制流的指示器,分支,循环,跳转,异常处理,线程恢复等基础功能都依赖这个计数器来完成;
Java虚拟机栈(Java Virtual Machine Stack)
线程私有,生命周期与线程相同;为虚拟机执行Java方法服务
Java虚拟机在方法执行时同步创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态连接、方法出口,每个方法被调用直至执行完毕过程对应栈帧在虚拟机栈中从入栈到出栈的过程。
局部变量表:存放编译期间可知的各种Java虚拟机基本数据类型,对象引用和returnAddress类型
-
StackOverflowError——线程请求的栈深度大于虚拟机所允许的深度
-
OutOfMemoryError——如过Java虚拟机栈容量可以动态扩展时,栈扩展无法申请到足够内存
本地方法栈(Native Method Stacks)
为虚拟机使用到的本地(Native)方法服务; 与虚拟机栈作用相似
与虚拟机一样,在栈深度溢出或栈扩展失败时分别抛出StackOverflowError和OutOfmemoryError异常
Java堆(Heap)
线程共享,在虚拟机创建时存放对象实例; 又称GC堆(Garbage Collected Heap)
-
从内存分配角度看,Java堆中可以划分出多个线程私有的分配缓冲区(Thread Local Allocation Buffer,TLAB)以提升对象分配时的效率。但不论如何划分都不会改变Java堆中存储内容的共性;
-
可以处在不连续的内存空间中,但逻辑上应该连续
-
在Java堆中没有内存完成实例分配,且堆无法再扩展时,Java虚拟机将抛出OutOfMemoryError异常
方法区(Method Area)
线程共享,用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据;逻辑上是堆的一部分,有一个别名叫做非堆(Non-Heap),目的是与Java堆区分开来
方法区受到的约束相对较为宽松,不需要连续的内存、可以选择固定大小或扩展,甚至还可以选择不实现垃圾收集——该区域的内存回收目标主要是针对常量池的回收和对类型的卸载,一般而言这个区域的回收效果较难令人满意,尤其是类型卸载的条件相当苛刻,但这部分的回收有时也是必要的。
运行时常量池(Runtime Constant Pool)
属于方法区的一部分,Class文件中除了有类的版本,字段,方法,接口等,还有一项信息——常亮表(Constant Poll Table),用于存放编译时期生成的各种字面量与符号引用;对于运行常量池《Java虚拟机规范》没有做任何细节要求,不同提供商实现的虚拟机可以按照自己的需求来实现这个内存区域。
java堆、栈、堆栈,常量池的区别
堆,栈,方法区,常量池,的概念
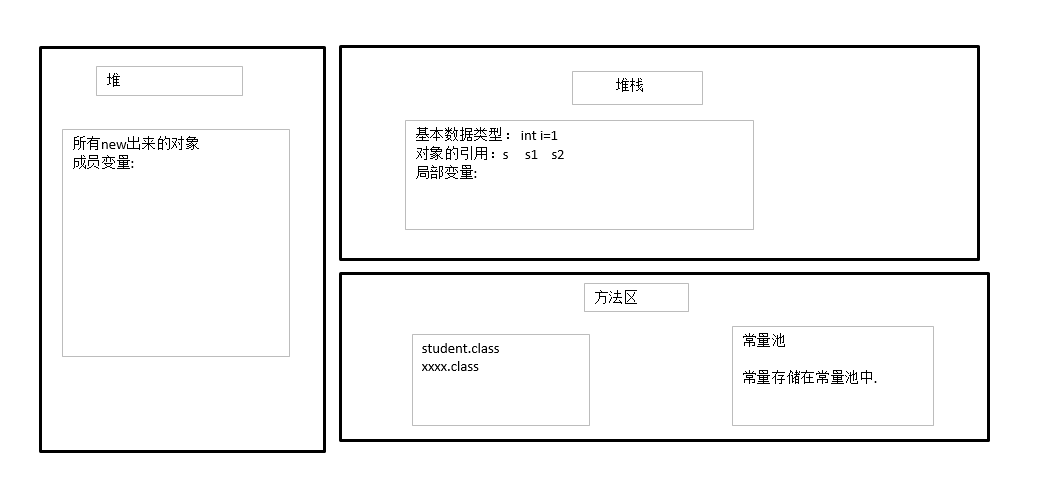
垃圾回收
参考 参考2 为什么垃圾回收
当程序运行时,至少会有两个线程开启启动,一个是我们的主线程,一个是垃圾回收线程,垃圾回收线程的priority(优先级)较低 垃圾回收器会对我们使用的对象进行监视,当一个对象长时间不使用时,垃圾回收器会在空闲的时候(不定时)对对象进行回收,释放内存空间,程序员是不可以显式的调用垃圾回收器回收内存的,但是可以使用System.gc()方法建议垃圾回收器进行回收,但是垃圾回收器不一定会执行。 Java的垃圾回收机制可以有效的防止内存溢出问题,但是它并不能完全避免内存溢出。例如当程序出现严重的问题时,也可能出现内存溢出问题
什么是GC
MinorGC 和 FullGC的理解
垃圾回收(Garbage Collection)是Java虚拟机(JVM)垃圾回收器提供的一种用于在空闲时间不定时回收无任何对象引用的对象占据的内存空间的一种机制。其体现在追踪所有正在使用的对象,并且将剩余的对象标记为垃圾,随后标记为垃圾的对象会被清除,回收这些垃圾对象占据的内存,从而实现内存的自动管理;
如果不进行垃圾回收,内存迟早都会被消耗完,垃圾回收可以有效的防止内存泄露,有效的使用可以使用的内存在C/C++中,释放无用变量内存空间的事情要由程序员自己来解决。Java有了GC,就不需要程序员去人工释放内存空间。当Java虚拟机发觉内存资源紧张的时候,就会自动地去清理无用变量所占用的内存空间
没有GC就不能保证应用程序的正常运行。而经常造成STW的GC又跟不上实际的需求,所以才会不断的进行GC优化。
GC收集器有哪些?
-
1.serial收集器 单线程,工作时必须暂停其他工作线程。多用于client机器上,使用复制算法
-
2.ParNew收集器 serial收集器的多线程版本,server模式下虚拟机首选的新生代收集器。复制算法
-
3.Parallel Scavenge收集器 复制算法,可控制吞吐量的收集器。吞吐量即有效运行时间。
-
4.Serial Old收集器 serial的老年代版本,使用整理算法。
-
5.Parallel Old收集器 第三种收集器的老年代版本,多线程,标记整理
-
6.CMS收集器 目标是最短回收停顿时间。7.G1收集器,基本思想是化整为零,将堆分为多个Region,优先收集回收价值最大的Region。
判断是否回收
Java语言规范没有明确地说明JVM使用哪种垃圾回收算法,但是任何一种垃圾回收算法一般要做2件基本的事情:
(1)找到所有存活对象;(2)回收被无用对象占用的内存空间,使该空间可被程序再次使用
参考
方法一:引用计数算法*(Reference Counting Collector)*
堆中每个对象(不是引用)都有一个引用计数器。当一个对象被创建并初始化赋值后,该变量计数设置为1。每当有一个地方引用它时,计数器值就加1(a = b, b被引用,则b引用的对象计数+1)。当引用失效时(一个对象的某个引用超过了生命周期(出作用域后)或者被设置为一个新值时),计数器值就减1。任何引用计数为0的对象可以被当作垃圾收集。当一个对象被垃圾收集时,它引用的任何对象计数减1。
-
优点:引用计数收集器执行简单,判定效率高,交织在程序运行中。对程序不被长时间打断的实时环境比较有利(OC的内存管理使用该算法)。
-
缺点: 难以检测出对象之间的循环引用。同时,引用计数器增加了程序执行的开销。所以Java语言并没有选择这种算法进行垃圾回收。
public static void main(String[] args){Object object1 = new Object();Object object2 = new Object();object1.object = object2;object2.object = object1;object1 = null;object2 = null;
}
显然,在最后,object1和object2的内存块都不能再被访问到了,但他们的引用计数都不为0(即他们互相引用),这就会使他们永远不会被清除。
方法二:可达性分析*根搜索算法(Tracing Collector)*

上图中 object1~object4对GC Root都是可达的,说明不可被回收,object5和object6对GC Root节点不可达,说明其可以被回收。
现在大多数JVM采用对象引用遍历(根搜索算法);根集(Root Set)就是正在执行的Java程序可以访问的引用变量(注意:不是对象)的集合(包括局部变量、参数、类变量),程序可以使用引用变量访问对象的属性和调用对象的方法。
GC Roots对象:
-
虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆中使用到的参数、局部变量、临时变量等
-
在方法区中类静态属性引用的对象,譬如Java类的引用类型静态变量
-
在方法区中常量引用的对象,譬如字符串常量池(String Table)里的引用
-
在本地方法栈中JNI(即通常说的Native方法)引用的对象
-
Java虚拟机内部的引用,如基本数据类型对应的Class对象,一些常驻的异常对象,还有系统类加载器
-
所有被同步锁(synchronized关键字)持有的对象
-
反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等
算法的基本思路:
(1)通过一系列名为“GC Roots”的对象作为起始点,寻找对应的引用节点。
(2)找到这些引用节点后,从这些节点开始向下继续寻找它们的引用节点。
(3)重复(2)。
(4)搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连时,就证明此对象是不可用的。
Java中的对象引用分类
(1)强引用(Strong Reference):如“Object obj = new Object()”,这类引用是Java程序中最普遍的。只要强引用还存在,垃圾收集器就永远不会回收掉被引用的对象。
(2)软引用(Soft Reference):它用来描述一些可能还有用,但并非必须的对象。在系统内存不够用时,这类引用关联的对象将被垃圾收集器列为回收范围进行二次回收。JDK1.2之后提供了SoftReference类来实现软引用。
(3)弱引用(Weak Reference):它也是用来描述非须对象的,但它的强度比软引用更弱些,被弱引用关联的对象只能生存到下一次垃圾收集发生之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。在JDK1.2之后,提供了WeakReference类来实现弱引用。
(4)虚引用(Phantom Reference):最弱的一种引用关系,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的是希望能在这个对象被收集器回收时收到一个系统通知。JDK1.2之后提供了PhantomReference类来实现虚引用。
对象引用与可达性算法说明
finalize()方法
运行代价较高,且不确定性较大,不推荐使用
在根搜索算法中,要真正宣告一个对象死亡,至少要经历两次标记过程:
1.如果对象在进行根搜索后发现没有与GC Roots相连接的引用链,那它会被第一次标记并且进行一次筛选。筛选的条件是此对象是否有必要执行 finalize()方法(可看作析构函数,类似于OC中的dealloc,Swift中的deinit)。当对象没有覆盖finalize()方法,或finalize()方法已经被虚拟机调用过,虚拟机将这两种情况都视为没有必要执行。
2.如果该对象被判定为有必要执行finalize()方法,那么这个对象将会被放置在一个名为F-Queue队列中,并在稍后由一条由虚拟机自动建立的、低优先级的Finalizer线程去执行finalize()方法。finalize()方法是对象逃脱死亡命运的最后一次机会(因为一个对象的finalize()方法最多只会被系统自动调用一次),稍后GC将对F-Queue中的对象进行第二次小规模的标记,如果要在finalize()方法中成功拯救自己,只要在finalize()方法中让该对象重新引用链上的任何一个对象建立关联即可。而如果对象这时还没有关联到任何链上的引用,那它就会被回收掉。
(4)实际上GC判断对象是否可达看的是强引用。
当标记阶段完成后,GC开始进入下一阶段,删除不可达对象。
判断类是否应该回收
-
该类的实例化都已被回收,即Java堆中不存在该类及其任何派生子类的实例
-
加载该类的类加载器已经被回收(通常较难完成,存在于精心设计的可替换类场景
-
该类对应的java.lang.Class对象没有在任何地方被引用,无法再任何地方通过反射访问该类的方法
需要同时满足以上三点可以回收
垃圾收集算法
牛客例题
这两篇博文主要讲的垃圾回收: 浅谈GJava垃圾回收机制(GC) 深入理解JVM虚拟机笔记
在JVM规范中并没有明确GC的运作方式,各个厂商可以采用不同的方式去实现垃圾回收器。垃圾回收算法可划分为“引用计数式垃圾收集”(Reference Counting GC)和“追踪式垃圾收集”(Tracing GC)两类
标记-清除算法(Mark-Sweep)
最基础的垃圾回收算法,分为两个阶段,标注和清除。标记阶段标记出所有需要回收的对象,清除阶段回收被标记的对象所占用的空间。如图:
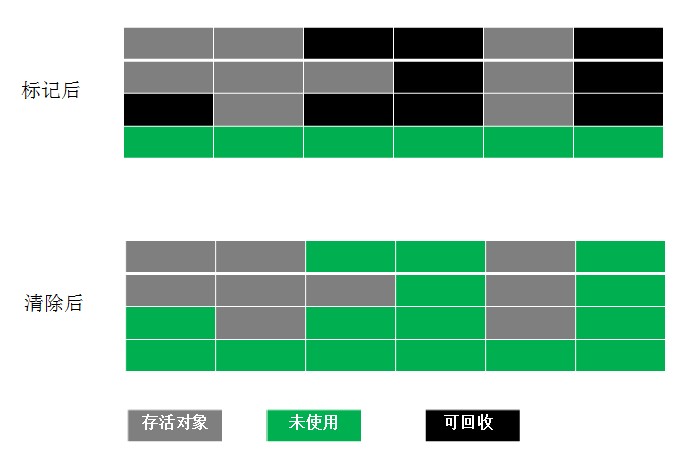
-
优点:不需要进行对象的移动,并且仅对不存活的对象进行处理,在存活对象比较多的情况下极为高效。
-
缺点:(1)标记和清除过程的效率都不高。(这种方法需要使用一个空闲列表来记录所有的空闲区域以及大小。对空闲列表的管理会增加分配对象时的工作量)(2)标记清除后会产生大量不连续的内存碎片。虽然空闲区域的大小是足够的,但却可能没有一个单一区域能够满足这次分配所需的大小,因此本次分配还是会失败(在Java中就是一次OutOfMemoryError)不得不触发另一次垃圾收集动作

标记-复制算法( Copying)
新生代回收算法
现在商业虚拟机都采用这种收集算法回收新生代;为了解决Mark-Sweep算法内存碎片化的缺陷而被提出的算法。按内存容量将内存划分为等大小的两块。每次只使用其中一块,当这一块内存满后将尚存活的对象复制到另一块上去,把已使用的内存清掉,如图:
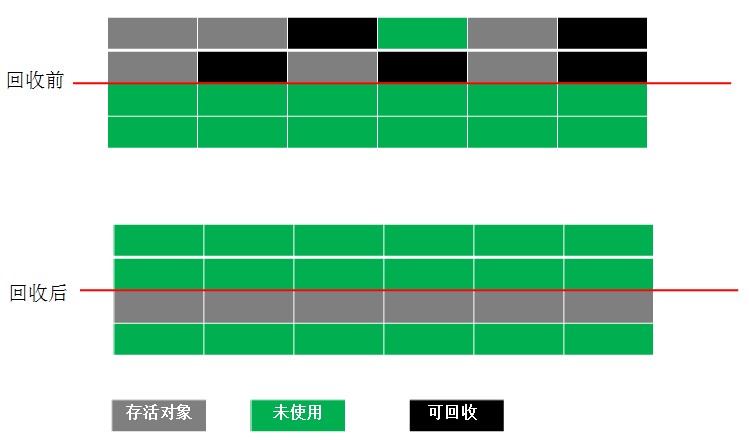
-
优点:(1)标记阶段和复制阶段可以同时进行。(2)每次只对一块内存进行回收,运行高效。(3)只需移动栈顶指针,按顺序分配内存即可,实现简单。(4)内存回收时不用考虑内存碎片的出现(得活动对象所占的内存空间之间没有空闲间隔)。
-
缺点:需要一块能容纳下所有存活对象的额外的内存空间。因此,可一次性分配的最大内存缩小了一半。

标记-整理算法(Mark-Compact)
老年代回收算法
结合了以上两个算法,为了避免缺陷而提出。标记阶段和Mark-Sweep算法相同,标记后不是清理对象,而是将存活对象移向内存的一端。然后清除端边界外的对象。如图:
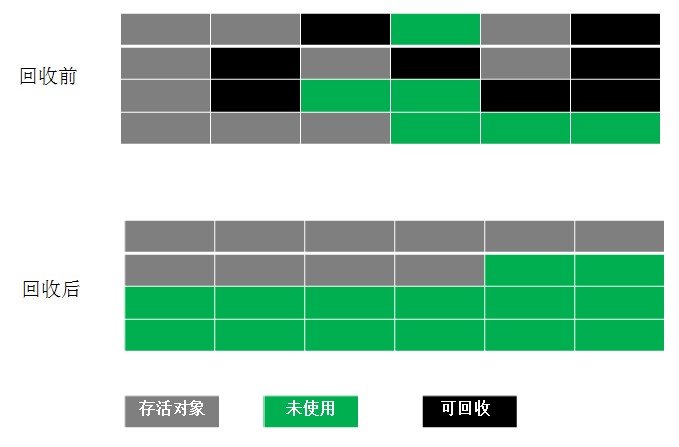
-
优点:(1)经过整理之后,新对象的分配只需要通过指针碰撞便能完成(Pointer Bumping),相当简单。(2)使用这种方法空闲区域的位置是始终可知的,也不会再有碎片的问题了。
-
缺点:GC暂停的时间会增长,因为你需要将所有的对象都拷贝到一个新的地方,还得更新它们的引用地址。

分代收集理论(Generational Collection)
-
弱分代假说(Weak Generational Hypothesis)——绝大多数对象都是朝生夕灭 对应新生代(Young Generation)
-
强分代假说(Strong Generational Hypothesis)——熬过越多次垃圾收集过程的对象就越难以消亡 对应老年代(Old Generation)
-
跨代引用假说(Intergenerational Reference Hypothesis)——跨代引用相对同代引用来说仅占少数;存在互相引用关系的两个对象应倾向于同时生存或同时消亡的
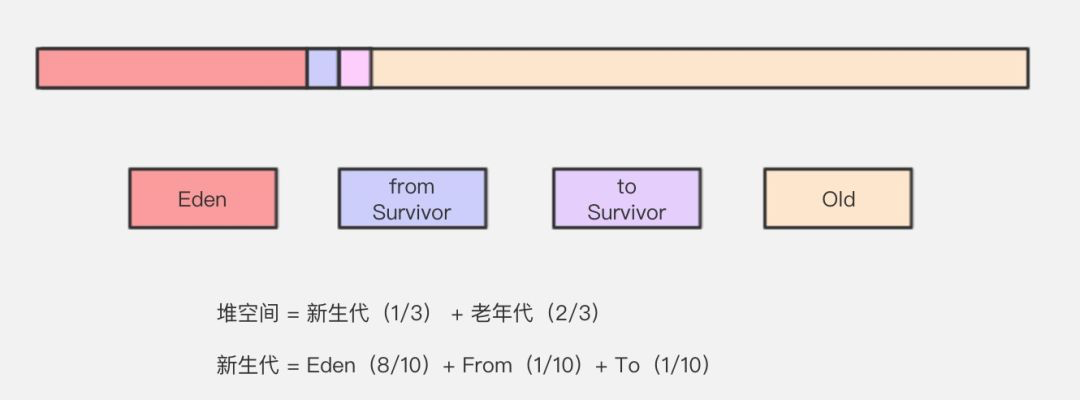
目前大部分JVM的GC对于新生代都采取Copying算法,因为新生代中每次垃圾回收都要回收大部分对象,即要复制的操作比较少,但通常并不是按照1:1来划分新生代。一般将新生代划分为一块较大的Eden空间和两个较小的Survivor空间(From Space, To Space),每次使用Eden空间和其中的一块Survivor空间,当进行回收时,将该两块空间中还存活的对象复制到另一块Survivor空间中。

而老生代因为每次只回收少量对象,因而采用Mark-Compact算法。
-
新生代使用:复制算法
-
老年代使用:标记 - 清除 或者 标记 - 整理 算法
另外,不要忘记在Java基础:Java虚拟机(JVM)中提到过的处于方法区的永生代(Permanet Generation)。它用来存储class类,常量,方法描述等。对永生代的回收主要包括废弃常量和无用的类。
对象的内存分配主要在新生代的Eden Space和Survivor Space的From Space(Survivor目前存放对象的那一块),少数情况会直接分配到老生代。当新生代的Eden Space和From Space空间不足时就会发生一次GC,进行GC后,Eden Space和From Space区的存活对象会被挪到To Space,然后将Eden Space和From Space进行清理。如果To Space无法足够存储某个对象,则将这个对象存储到老生代。在进行GC后,使用的便是Eden Space和To Space了,如此反复循环。当对象在Survivor区躲过一次GC后,其年龄就会+1。默认情况下年龄到达
Java垃圾回收机制 java的gc为什么要分代? - RednaxelaFX的回答 - 知乎
内存分配与回收
这两篇博文对于JVM整体更为透彻: 深入理解JVM 备战java虚拟机
年轻代与年老代
存储在JVM的Java对象分为两类:
-
一类是生命周期比较短的瞬间,这类对象的创建和消亡都比较迅速
-
另外一类对象的生命周期却非常长,在某些极端的情况下还能够与JVM的生命周期保持一致。 Java堆区进一步细分的话,分为YoungGen和OldGen。
配置YoungGen和OldGen在堆结构的占比 默认 -XX:NewRatio=2,表示新生代占1,老年代占2,新生代占整个堆的1/3。
在HotSpot中,Eden空间和另外两个Survivor空间省所占比例是8:1:1。开发人员可以通过-XX:SurvivorRatio=8来调整这个空间比例。 -XX:-UseAdaptiveSizePlicy : 关闭自适应的内存分配策略。
几乎所有的Java对象都是在Eden区被new出来。
绝大部分的Java对象的销毁都是在新生代进行的。
可以使用"-Xmn"设置新生代最大内存大小,这个值一般默认就好了。
Minor GC、Major GC、Full GC
GC检索哪些是垃圾时,会导致用户线程暂停,所以希望GC出现的情况少,这里主要对Major GC、Full GC进行调优。因为它们两个GC的时间是Minor GC的10倍以上。
JVM在进行GC时,并非每次都对上面三个内存(新生代、老年代;方法区)区域一起回收,大部分时候回收的是新生代。
针对HotSpot VM的实现,他里面的GC按照回收区域分为两大类型:一种是部分收集(Partial GC),一种是整堆收集(Full GC)。
-
部分收集(Partial GC)
-
新生代(Eden、S0、S1)进行回收采用(Minor GC/ YGC)
-
老年代进行回收采用(Major GC/ OGC)
-
混合收集(Mixed GC):收集整个新生代以及部分老年代的垃圾收集。
-
-
整堆收集(Full GC)
-
收集整个java堆和方法区的垃圾收集(Full GC)。
-
Minor GC的触发机制:
-
当年轻代空间不足时,就会触发Minor GC,这里的年轻代指得是Eden代满,Survivor满不会触发GC。
-
Minor GC非常频繁,一般回收速度也比较快。
-
Minor GC会引发STW,暂停其他用户的线程,等垃圾回收线程结束,线程才恢复运行。
老年代GC(Major GC/Full GC)触发机制:
-
指发生在老年代的GC,对象从老年代消失。
-
出现了Major GC,经常会伴随至少一次的Minor GC。
-
如果Major GC后,内存还不足,就报OOM。
Full GC触发机制:
-
调用System.gc()时,系统建议执行Full GC,但是不必然执行。
-
老年代空间不足
-
方法区空间不足
-
通过Minor GC后进入老年代的平均大小大于老年代的可用内存。
Java 堆主要分为2个区域-年轻代与老年代,其中年轻代又分 Eden 区和 Survivor 区,其中 Survivor 区又分 From 和 To 2个区
类加载机制
类是在运行期间第一次使用时动态加载的,而不是一次性加载所有类。因为如果一次性加载,那么会占用很多的内存。
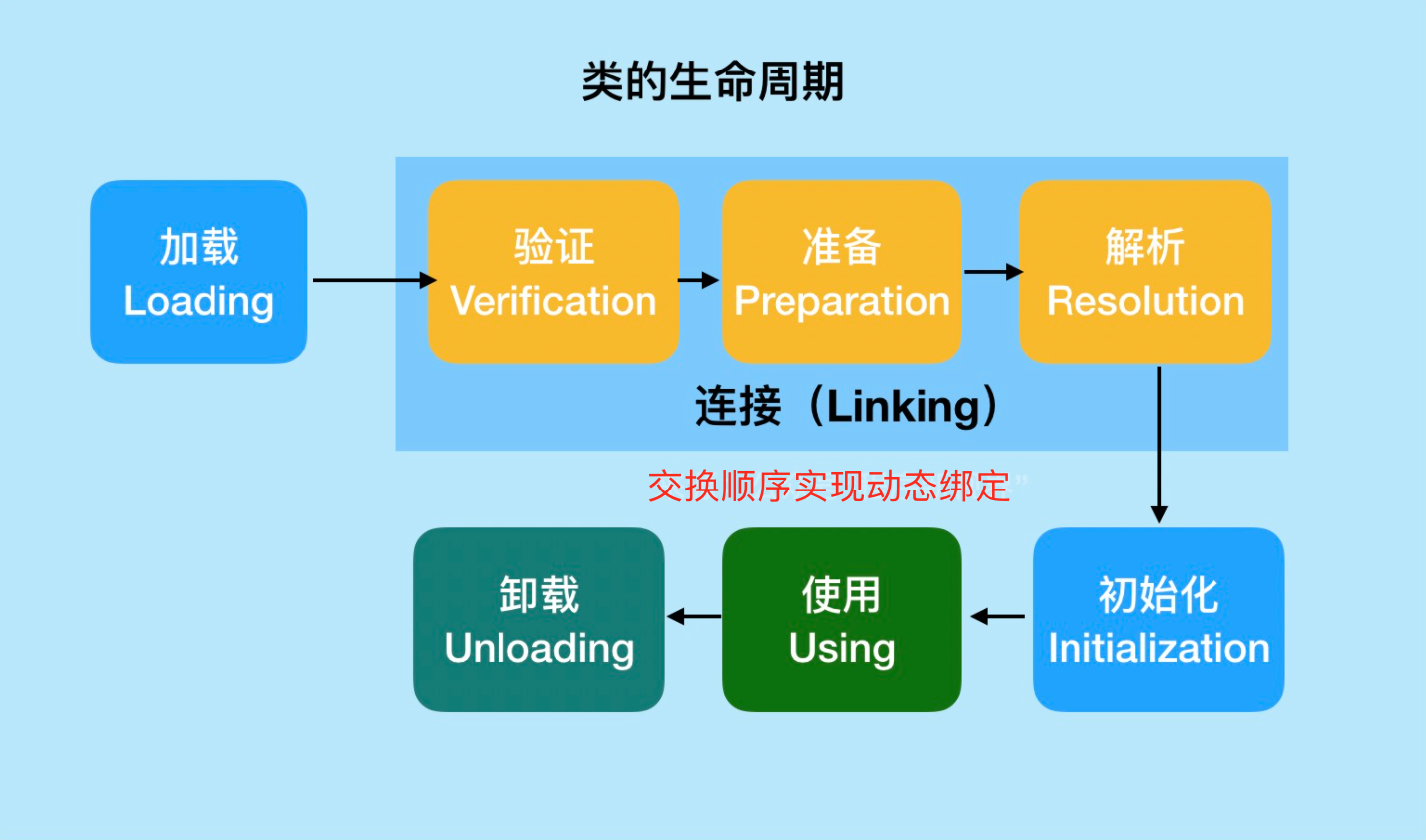
加载(Loading) 验证(Verification) 准备(Preparation) 解析(Resolution)
初始化(Initialization) 使用(Using)卸载(Unloading) 如果要深入JVM推荐此博文:备战Java虚拟机
双亲委派
牛客例题
JDK中提供了三个ClassLoader,根据层级从高到低为:
-
Bootstrap ClassLoader,主要加载JVM自身工作需要的类。
-
Extension ClassLoader,主要加载%JAVA_HOME%\lib\ext目录下的库类。
-
Application ClassLoader,主要加载Classpath指定的库类,一般情况下这是程序中的默认类加载器,也是ClassLoader.getSystemClassLoader() 的返回值。(这里的Classpath默认指的是环境变量中配置的Classpath,但是可以在执行Java命令的时候使用-cp 参数来修改当前程序使用的Classpath)
JVM加载类的实现方式,我们称为 双亲委托模型:
如果一个类加载器收到了类加载的请求,他首先不会自己去尝试加载这个类,而是把这个请求委托给自己的父加载器,每一层的类加载器都是如此,因此所有的类加载请求最终都应该传送到顶层的Bootstrap ClassLoader中,只有当父加载器反馈自己无法完成加载请求时,子加载器才会尝试自己加载。
双亲委托模型的重要用途是为了解决类载入过程中的安全性问题。
假设有一个开发者自己编写了一个名为*Java.lang.Object*的类,想借此欺骗JVM。现在他要使用自定义ClassLoader来加载自己编写的java.lang.Object类。然而幸运的是,双亲委托模型不会让他成功。因为JVM会优先在Bootstrap ClassLoader的路径下找到java.lang.Object类,并载入它
Java内存模型
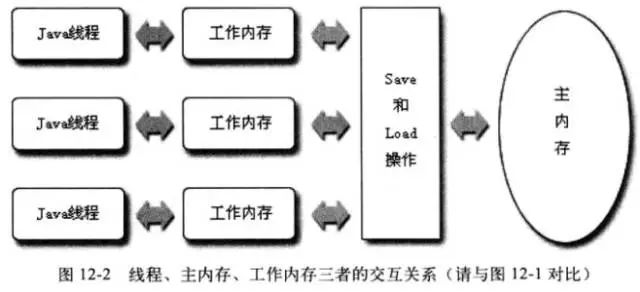
JMM 定义了 8 个操作来完成主内存和工作内存之间的交互操作。JVM 实现时必须保证下面介绍的每种操作都是 原子的(对于 double 和 long 型的变量来说,load、store、read、和 write 操作在某些平台上允许有例外 )。
-
lock(锁定) - 作用于主内存的变量,它把一个变量标识为一条线程独占的状态。 -
unlock(解锁) - 作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。 -
read(读取) - 作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。 -
write(写入) - 作用于主内存的变量,它把 store 操作从工作内存中得到的变量的值放入主内存的变量中。 -
load(载入) - 作用于工作内存的变量,它把 read 操作从主内存中得到的变量值放入工作内存的变量副本中。 -
use(使用) - 作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值得字节码指令时就会执行这个操作。 -
assign(赋值) - 作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。 -
store(存储) - 作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后write操作使用。
volatile 禁止指令重排序(内存屏障) 以及保证可见性 具体可见第二章多线程常用方法volatile部分
原子性(Atomicity)
使用Java内存模型直接保证原子性变量包括read、load、assign、use、store和write六个,即大致可以认为基本数据类型的访问、读写都是具备原子性的;
虚拟机为了保证原子性,提供了两个高级的字节码指令 monitorenter 和 monitorexit隐式使用lock与unlock操作。这两个字节码,在 Java 中对应的关键字就是 synchronized。因此,在 Java 中可以使用 synchronized 来保证方法和代码块内的操作是原子性的。
可见性(Visibility)
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
JMM 是通过 "变量修改后将新值同步回主内存, 变量读取前从主内存刷新变量值" 这种依赖主内存作为传递媒介的方式来实现的。
Java 实现多线程可见性的方式有:
-
volatile保证新值能立即同步到主内存,以及每次使用立即从主内存刷新 -
synchronized对一个变量执行unlock操作前必须将此变量同步到主内存中(执行store、write操作) -
final被final修饰的字段一旦被初始化完成,且构造器没有把this的引用传递出去(this引用逃逸会导致其他线程访问到初始化一半的对象),那么在其他线程中就能看见final字段的值
有序性(Ordering)
有序性规则表现在以下两种场景: 线程内和线程间
-
线程内 - 从某个线程的角度看方法的执行,指令会按照一种叫“串行”(
as-if-serial)的方式执行,此种方式已经应用于顺序编程语言。 -
线程间 - 这个线程“观察”到其他线程并发地执行非同步的代码时,由于指令重排序优化,任何代码都有可能交叉执行。唯一起作用的约束是:对于同步方法,同步块(
synchronized关键字修饰)以及volatile字段的操作仍维持相对有序。
在 Java 中,可以使用 synchronized 和 volatile 来保证多线程之间操作的有序性。实现方式有所区别:
-
volatile关键字会禁止指令重排序。 -
synchronized关键字通过互斥(lock)保证同一时刻只允许一条线程操作。
数据库
阿里最新手册,数据库单表数据超过500w行或数据超过2GB,效率大幅下降
数据库管理系统要做的工作通常有以下四个方面:①描述数据库;②管理数据库;③维护数据库;④ 数据通讯。
一、关系型数据库,指采用了关系模型来组织数据的数据库,而关系模型是由二维表及其联系组成的数据组织。
二、非关系型数据库,也称为NOSQL(Not Only SQL),作为关系型数据库的一个补充,能在特定场景和特点问题下发挥高效率和高性能。常见的非关系型数据库类型有键值(Key-Value)存储数据库和面向文档数据库(Document-oriented)。键值存储数据库类似hash,通过key做添加、删除、查询,性能高,优势在于简单、易部署、高并发。
数据库类型是根据数据模型来划分的;数据模型采用了形式化描述方法,表示了数据和数据之间的联系。
范式通俗理解
详解第一范式、第二范式、第三范式、BCNF范式
范式是关系数据库理论的基础,也是我们在设计数据库结构过程 中所要遵循的规则和指导方法。数据库的设计范式是数据库设计所需要满足的规范。只有理解数据库的设计范式,才能设计出高效率、优雅的数据库,否则可能会设 计出错误的数据库.目前有迹可寻的共有8种范式,依次是:1NF,2NF,3NF,BCNF,4NF,5NF,DKNF,6NF。
-
第一范式(1NF)无重复的列;就是数据库表中的字段都是单一属性的,不可再分。这个单一属性可以是数据库中任何一种基本数据类型,如整形、字符型、日期型等。只要是关系型数据库都会满足第一范式。
-
第二范式的定义是要求 属性完全依赖于主键;在数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖。首先要满足它是1NF,另外还需要包含两部分内容:一是表必须有一个主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分
-
第三范式的要求是属性不传递依赖于其它非主属性。首先是满足 2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。满足第三范式的数据表应该不存在依赖关系。
-
BCNF范式 简单的说,bc范式是在第三范式的基础上的一种特殊情况,既每个表中只有一个候选键(在一个数据库中每行的值都不相同,则可称为候选键)
-
反范式化(空间换时间)反范式的过程就是通过冗余数据来提高查询性能,但冗余数据会牺牲数据一致性;也就是利用空间来换取时间,把数据冗余在多个表中,当查询时可以减少或者是避免表之间的关联;
优点: 缺点:
-
可以减少表关联 存在大量冗余数据
-
可以更好进行索引优化 数据维护成本更高(删除异常,插入异常,更新异常)
-
举例对比
数据库设计之三范式与反范式
升级范式可以避免:
-
数据冗余 同一个产品由n个顾客购买,“产品类型”就重复n-1次;同一个顾客购买多件产品,那么就会多次记录顾客的个人信息。
-
更新异常 若调整了某个产品的类型,数据表中所有行的“产品类型”值都要更新,否则会出现同一个产品不同类型的情况。
-
插入异常 假设新进了一个产品,暂时还没有人购买。这样,由于没有人购买,产品的名称和类型也无法记录到数据库中。
-
删除异常 假设一批顾客把以及购买完的商品退货,这些产品信息就从数据表中删除了。但是与此同时,产品名称和产品类型等信息也被删除了。这样就导致了删除异常。
1:第二范式和第三范式如何区别?
第二范式:非主键列是否依赖主键(包括一列通过某一列间接依赖主键),要是有依赖关系的就是第二范式; 第三范式:非主键列是否是直接依赖主键,不能是那种通过传递关系的依赖的。要是符合这种就是第三范式;
2:范式的存在有什么好处?
范式可以避免数据冗余,减少数据库的空间,减轻维护数据完整性的麻烦。
缺点:所用的范式越高,对数据操作的性能越低。所以我们在利用范式设计表的时候,要根据具体的需求再去权衡是否使用更高范式去设计表。在一般的项目中,我们用的最多也就是第三范式,第三范式也就可以满足我们的项目需求,性能好而且方便管理数据;
Redis
面试点
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)
数据类型
命令不分大小写,key分大小写
Redis有8种数据类型,常用的主要是 String、Hash(hashTable)、List(双向链表)、Set(hashTable)、 SortSet 这5种类型
String
#向key中通过append追加字符串 如不存在指定字符,那么进行新建APPEND key "hello" #定义浏览量为0set views 0#自增1 #自减1incr views decr views#指定增量 #指定减量INCRBY views 【数字】 DECRBY views 【数字】#获取浏览量get views#查看指定字符串范围【索引值】 如取 0 至 -1 那么相当于get keyGETRANGE key 【起始位】 【终止】set key2 abcde GETRANGE 1 3 ————》bcd#替换指定索引SETRANGE key2 1 dd ————》 addcde
统计点赞量
Hash
购物车(京东早期)
list
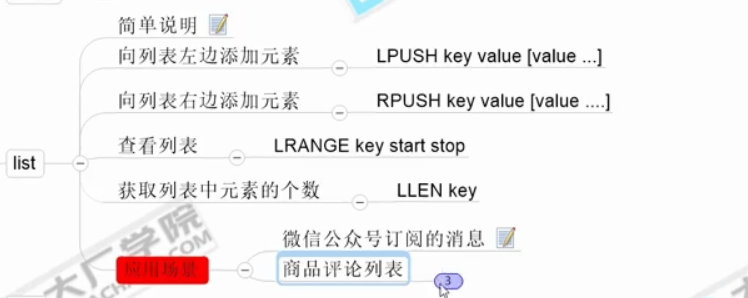

set

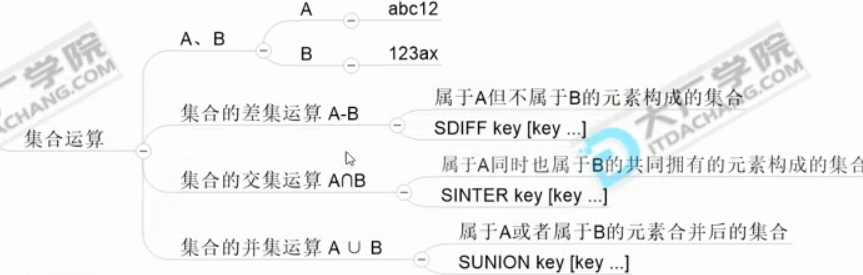
抽奖
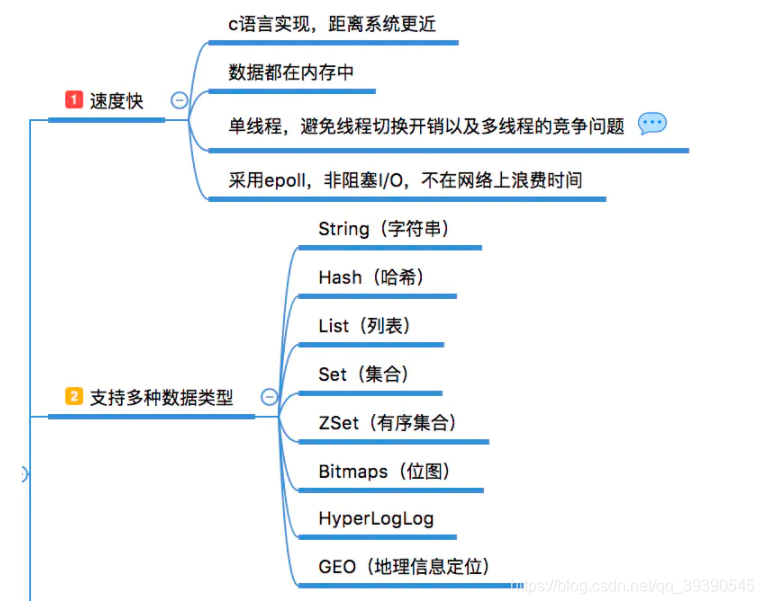
默认16个数据库,默认使用第一个;使用 select +【数字】 切换
清除 flushdb 清除所有 flushAll 端口号:6379
Redis是单线程
Redis是基于内存操作的,因此CPU不是性能瓶颈,Redis的瓶颈是机器内存和网络环境;既然使用单线程不会对性能有影响,选用单线程
速度快:redis将所有数据全部放在内存中,所以说使用单线程操作效率最高,多线程(CPU上下文 切换耗时),对于系统内存来说,如果没有上下文切换,多次读写在一个CPU上,是效率最高的
-
缓存穿透:指缓存和数据库中都没有的数据,导致所有的请求都打到数据库上,然后数据库还查不到(如null),造成数据库短时间线程数被打满而导致其他服务阻塞,最终导致线上服务不可用,这种情况一般来自黑客同学。
-
缓存击穿:指缓存中没有但数据库中有的数据(一般是热点数据缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去查,引起数据库压力瞬间增大,线上系统卡住。
-
缓存雪崩:指缓存同一时间大面积的失效,缓存击穿升级版。
缓存击穿解决:可以在第一个查询数据的请求上使用一个互斥锁来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
为何加入多线程
工作线程是单线程,整个Redis来说是多线程 4.0引入多线程命令用于异步删除,6.0引入I/O多线程读写;命令的执行依旧是由主线程串行执行(不会出现线程安全问题)
Redis中80%都是查询操作,6.0以后全面加入多线程I/O用于删除操作,当被删除的key是很大是数据时,如果是单线程同步操作那么将导致Redis服务卡顿
unlink keyflushdb asyncflushall async#使用子线程异步删除数据(后台删除)
从Redis主线程剥离BIO子线程进行删除操作,极大减少主线程阻塞时间,减少删除导致性能和稳定性有损的问题
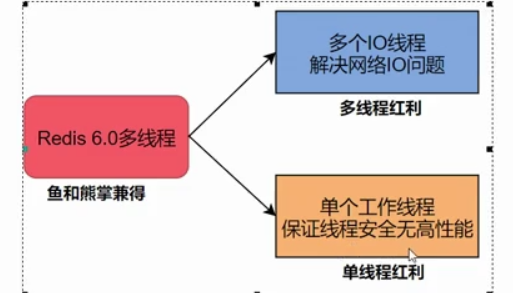
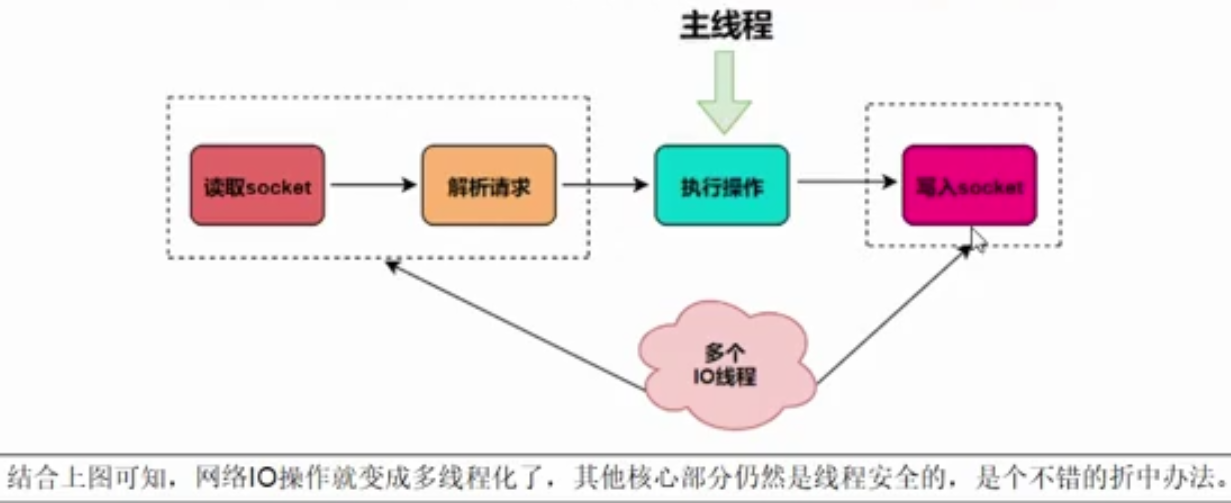
多线程机制默认是关闭的,需在redis.conf中完成两个设置开启
-
设置io- thread- do- reads no 配置项为yes表示启动多线程
-
设置线程个数:线程数一定要小于机器核数,对于4核,建议设置为2或3,8核建议设置为6
操作案例
在含有redis的多数据源项目中,每次操作要保证redis与MySQL数据的一致性;MySQL是底单数据,redis是常用查询数据
增加(insert)
//定义一个常量用于与id拼接作为redis的key值public static final String CACHE_KEY_USER = "user:";@Resourceprivate UserMapper userMapper;@Resourceprivate RedisTemplate redisTemplate;public void addUser(User user){//1 先插入mysql并成功int i = userMapper.insertSelective(user);if(i > 0){//2 需要再次查询一下mysql将数据捞回来并okuser = userMapper.selectByPrimaryKey(user.getId());//3 将捞出来的user存进redis,完成新增功能的数据一致性。String key = CACHE_KEY_USER+user.getId();redisTemplate.opsForValue().set(key,user);}}
MySQL插入成功后重新查询新增数据后加入redis,用于保证数据一致性
删除(delete)
public void deleteUser(Integer id){int i = userMapper.deleteByPrimaryKey(id);if(i > 0){String key = CACHE_KEY_USER+id;redisTemplate.delete(key);}}
更新(update)
public void updateUser(User user){int i = userMapper.updateByPrimaryKeySelective(user);if(i > 0){//2 需要再次查询一下mysql将数据捞回来并okuser = userMapper.selectByPrimaryKey(user.getId());//3 将捞出来的user存进redis,完成修改String key = CACHE_KEY_USER+user.getId();redisTemplate.opsForValue().set(key,user);}}
查询(Select)
查询操作先查Redis;Redis没有再查MySQL并将数据写入Redis保证下次缓存命中率; 如果都没就返回null
public User findUserById(Integer id){User user = null;String key = CACHE_KEY_USER+id;//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysqluser = (User) redisTemplate.opsForValue().get(key);if(user == null){//2 redis里面无,继续查询mysqluser = userMapper.selectByPrimaryKey(id);if(user == null){//3.1 redis+mysql 都无数据//你具体细化,防止多次穿透,我们规定,记录下导致穿透的这个key回写redisreturn user;}else{//3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率redisTemplate.opsForValue().set(key,user);}}return user;}
以上代码足够应对一般的QPS,但对于高QPS应该加互斥锁避免缓存击穿(多个查询请求同时打到MySQL),即在Redis查询不到时加锁进入MySQL查询并将数据写入Redis
public User findUserById(Integer id)
{User user = null;String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
user = (User) redisTemplate.opsForValue().get(key);if(user == null)
{//2 高QPS优化,加锁进行MySQL查询,避免缓存击穿synchronized (UserService.class){user = (User) redisTemplate.opsForValue().get(key);//3.二次查询redis还是null,再去MySQL查询(假设MySQL有数据if(user == null){//4.查询MySQL拿数据user = userMapper.selectByPrimarykey(id);if(user == null){// redis+mysql 都无数据//你具体细化,防止多次穿透,我们规定,记录下导致穿透的这个key回写redisreturn user;}else{//5. mysql有,需要将数据写回redis,保证下一次的缓存命中率,设置超时时间redisTemplate.opsForValue().set(key,user,7L,TimeUnit.DAYS);}}
return user;
}
MySQL
关系数据模型的三个组成部分 完整性规则、 数据结构、 数据操作。
-
数据结构:描述数据库的组成对象以及对象之间的联系。
-
数据操作:指对数据库中各种对象(型)的实例(值)允许执行的操作的集合,包括操作及有关的操作规则。
-
数据的完整性约束规则:一组完整性规则。
事务四大特性ACID
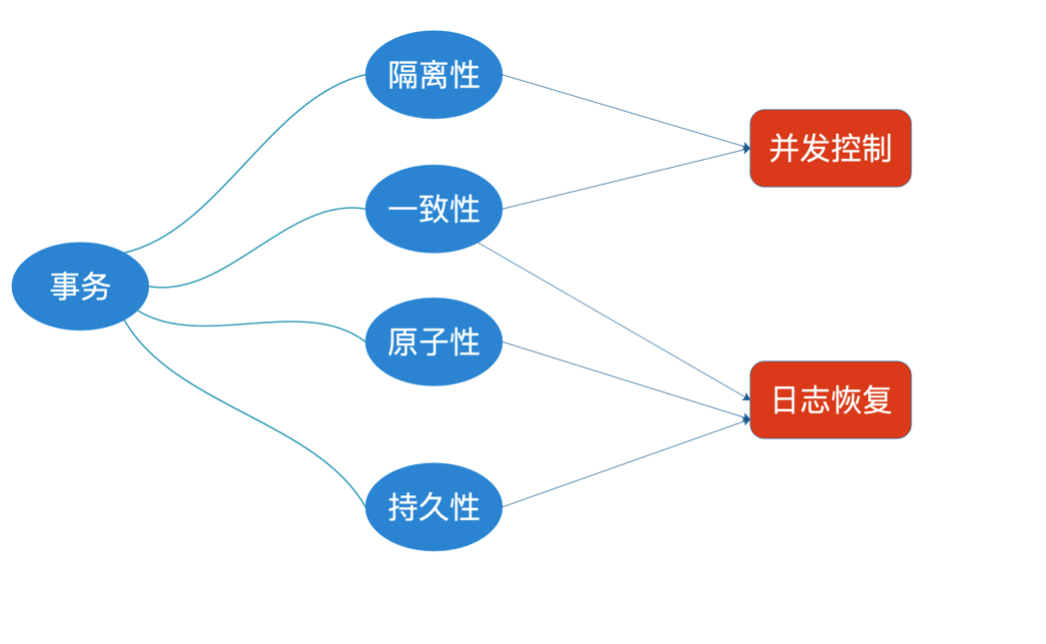
⑴ 原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
⑵ 一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。换一种方式理解就是:事务按照预期生效,数据的状态是预期的状态。
原子性和一致性的区别是什么?
一致性就规定了事物提交前后,永远只可能存在事物提交前的状态和事物提交后的状态,从一个一致性的状态到另一个一致性状态,而不可能出现中间的过程态。也就是说事物的执行结果是量子化状态,而不是线性状态
⑶ 隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
隔离性防止了多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括未提交读(Read uncommitted)、提交读(read committed)、可重复读(repeatable read)和串行化(Serializable)。以上4个级别的隔离性依次增强,分别解决不同的问题。事务隔离级别越高,就越能保证数据的完整性和一致性,但同时对并发性能的影响也越大
⑷ 持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务以及正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成,否则就会造成我们看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。
-
原子性:通过undo log(回滚日志)进行实现,所有事务进行的操作都会先记录到回滚日志中,然后在对数据库进行操作,当事务发生错误或者回滚时可以根据回滚日志对之前的操作进行撤销,如果数据库崩溃宕机,在数据库重新启动后,可以查询回滚日志将之前未提交的操作进行撤销
-
持久性:通过redo log实现,在事务对数据进行操作时,先将操作写入redo log中同时刷新缓存中的数据,等到空闲时再对磁盘中的数据进行操作
数据类型优化
高性能MySQL笔记 思维导图
更小的通常更好,应尽量使用可以正确存储数据的最小数据类型;他们占据更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期也更少;要确保没有低估要存储的值的范围,避免后期进行增加数据类型范围的操作
简单就好,简单的数据类型操作通常需要更少的CPU周期;例如:使用MySQL内建的类型而不是字符串来存储日期和时间;DateTime 和Timestamp都可以存储相同类型的数据,时间和日期,精确到秒。而Timestamp只使用DateTime一般的存储空间,并且会根据时区变化,具有自动更新的能力。
尽量避免NULL,除外需要存储NULL值,通常情况下最好指定列为NOT NULL;null对于mysql来说更难优化,为NULL的列使得索引,索引统计和值比较都更复杂,将使用更多的存储空间,且在MySQL中也需要特殊处理
char 和 varchar
char:定长,效率高,一般用于固定长度的表单提交数据存储 ;例如:身份证号,手机号,电话,密码等;当所插入的字符串超出它们的长度时,视情况来处理,如果是严格模式,则会拒绝插入并提示错误信息,如果是宽松模式,则会截取然后插入
varchar:不定长,效率偏低;需要使用一个(如果字符串长度小于255)或两个字节(长度大于255)来存储字符串的长度
效率来说基本是char>varchar>text,但是如果使用的是Innodb引擎的话,推荐使用varchar代替char。char和varchar可以有默认值,text不能指定默认值。对 char 来说,最多能存放的字符个数 255,和编码无关。而 varchar 呢,最多能存放 65532 个字符
执行SQL相关
工作流程
增删查改效率
查 > 改 > 增 > 删
分别涉及到数据变化,索引变化
插入字段
mysql插入数据
#单表插入 INSERT INTO 表名 (字段名) VALUES (内容); #多表插入 INSERT INTO 表名 (字段名) VALUES (内容1), (内容2), (内容3);
指定字段名插入:打乱了原本字段的排列顺序,只要插入的数据与之匹配,插入都不会出错
不指定字段名插入:必须老老实实的按字段顺序来填入相应的数据
只想插入部分指定字段:就是在INSERT中只向部分插入值,而其他字段的值为表定义时的默认值。(不填写其他字段)
查询字段
牛客
#查询表user中name字段中,第2个字母为A的所有数据 模糊查询 LIKE select * from user where name like ’_A%’;
联合查询
建表sql
-- ----------------------------
-- Table structure for `tbl_dept`
-- ----------------------------
DROP TABLE IF EXISTS `tbl_dept`;
CREATE TABLE `tbl_dept` (`id` int(11) NOT NULL AUTO_INCREMENT,`deptName` varchar(30) CHARACTER SET utf8 DEFAULT NULL,`locAdd` varchar(40) CHARACTER SET utf8 DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4;-- ----------------------------
-- Records of tbl_dept
-- ----------------------------
INSERT INTO `tbl_dept` VALUES ('1', 'RD', '11');
INSERT INTO `tbl_dept` VALUES ('2', 'HR', '12');
INSERT INTO `tbl_dept` VALUES ('3', 'MK', '13');
INSERT INTO `tbl_dept` VALUES ('4', 'MIS', '14');
INSERT INTO `tbl_dept` VALUES ('5', 'ZZY', '15');
INSERT INTO `tbl_dept` VALUES ('6', 'HRBR', '16');-- ----------------------------
-- Table structure for `tbl_emp`
-- ----------------------------
DROP TABLE IF EXISTS `tbl_emp`;
CREATE TABLE `tbl_emp` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(20) CHARACTER SET utf8 DEFAULT NULL,`deptId` int(11) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4;-- ----------------------------
-- Records of tbl_emp
-- ----------------------------
INSERT INTO `tbl_emp` VALUES ('1', 'z1', '1');
INSERT INTO `tbl_emp` VALUES ('2', 'z3', '2');
INSERT INTO `tbl_emp` VALUES ('3', 'zz', '3');
INSERT INTO `tbl_emp` VALUES ('4', 'yy', '10');
INSERT INTO `tbl_emp` VALUES ('5', 'll', null);
INSERT INTO `tbl_emp` VALUES ('6', 'uu', '11');
搞两个表,员工表,部门表;员工表设置一个外键deptId 关联 部门表的 主键id
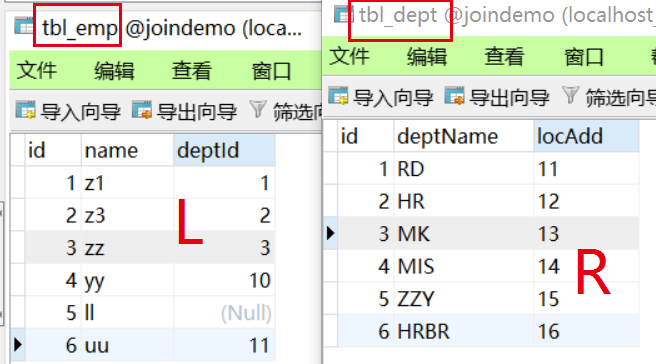
以下例子以员工表(tbl_emp)为左表 部门(tbl_dept)表为右表
INNER JOIN(输出两表公有部分)
#通过员工表外键deptId关联部门表主键id查询输出两表公有部分 SELECT * from tbl_emp R INNER JOIN tbl_dept L on R.deptId = L.id;
LEFT JOIN(左表独有,右边没有补NULL)
#以左表为主显示,右表没有的字段补null SELECT * from tbl_emp R LEFT JOIN tbl_dept L on R.deptId = L.id;
#在最后加where 右表.主键 is NULL 只显示左表独有字段 右表补null SELECT * from tbl_emp R LEFT JOIN tbl_dept L on R.deptId = L.id WHERE L.id is NULL;
RIGHT JOIN(右表独有,左表没有补NULL)
#以右表为主显示,左表没有的字段补null SELECT * from tbl_emp R RIGHT JOIN tbl_dept L on R.deptId = L.id;
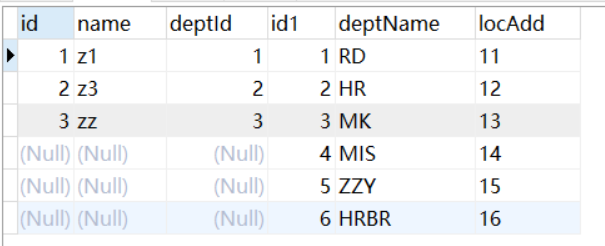
#在最后加where 左表.外键 is NULL 只显示右表独有字段 左表补null SELECT * from tbl_emp R RIGHT JOIN tbl_dept L on R.deptId = L.id WHERE R.deptId is NULL;
UNION(联合)
#联合LEFT JOIN 与 RIGHT JOIN 将分别显示左表 右表 补空另一个表没有的字段 SELECT * from tbl_emp R LEFT JOIN tbl_dept L on R.deptId = L.id UNION SELECT * from tbl_emp R RIGHT JOIN tbl_dept L on R.deptId = L.id
#分别显示两表独有字段 左 + 右 SELECT * from tbl_emp emp LEFT JOIN tbl_dept dept on emp.deptId = dept.id WHERE dept.id is NULL UNION SELECT * from tbl_emp emp RIGHT JOIN tbl_dept dept on emp.deptId = dept.id WHERE emp.deptId is NULL;
SQL查询优化
union 和union all的区别:
牛客例题
-
union会对结果集进行处理排除掉相同的结果
-
union all 不会对结果集进行处理,不会处理掉相同的结果
所以,union all 的效率会比union高, 另外,where也会对结果集进行处理掉相同的数据
preparedStatement和statement
牛客例题
PreparedStatement 接口继承 Statement , PreparedStatement 实例包含已编译的 SQL 语句, 所以其执行速度要快于 Statement 对象。 Statement为一条Sql语句生成执行计划, 如果要执行两条sql语句 select colume from table where colume=1;select colume from table where colume=2; 会生成两个执行计划 一千个查询就生成一千个执行计划! PreparedStatement用于使用绑定变量重用执行计划 select colume from table where colume=:x; 通过set不同数据只需要生成一次执行计划,可以重用
参考
减少请求的数据量
只返回必要的列:最好不要使用 SELECT * 语句。 只返回必要的行:使用 LIMIT 语句来限制返回的数据。
缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
索引
添加索引
哪些字段适合建立索引 mysql 中添加索引的三种方法
什么情况下不推荐使用索引?
1) 数据唯一性差(一个字段的取值只有几种时)的字段不要使用索引
比如性别,只有两种可能数据。意味着索引的二叉树级别少,多是平级。这样的二叉树查找无异于全表扫描。
2) 频繁更新的字段不要使用索引
比如logincount登录次数,频繁变化导致索引也频繁变化,增大数据库工作量,降低效率。
3) 字段不在where语句出现时不要添加索引,如果where后含IS NULL /IS NOT NULL/ like ‘%输入符%’等条件,不建议使用索引
只有在where语句出现,mysql才会去使用索引
4) where 子句里对索引列使用不等于(<>),使用索引效果一般
索引原理和实现 B树和B+树
建立索引的原则: 在最频繁使用的、用以缩小查询范围的字段上建立索引; 在频繁使用的、需要排序的字段上建立索引。 不适合建立索引的情况: 对于查询中很少涉及的列或者重复值比较多的列,不宜建立索引; 对于一些特殊的数据类型,不宜建立索引
InnoDB使用的B+Tree,按原数据格式进行存储,根据主键引用被索引的行; B-Tree索引适用于全键值,键值范围或键前缀查找
-
优势:可以快速检索,减少I/O次数,加快检索速度;根据索引分组和排序,可以加快分组和排序;
-
劣势:索引本身也是表,因此会占用存储空间,一般来说,索引表占用的空间的数据表的1.5倍;索引表的维护和创建需要时间成本,这个成本随着数据量增大而增大;构建索引会降低数据表的修改操作(删除,添加,修改)的效率,因为在修改数据表的同时还需要修改索引表;
B-Tree索引的一些限制:①必须按照索引的最左列开始查找 ②不能跳过索引中的列 ,比如定义三个索引,不能以1 3 去使用索引查询 ③如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找
逻辑索引分类:主键索引、唯一索引、普通索引、全文索引、组合索引
物理索引分类:聚簇索引,非聚簇索引 底层原理
聚簇索引和非聚簇索引
| 动作描述 | 使用聚集索引 | 使用非聚集索引 |
|---|---|---|
| 列经常被分组排序 | 应 | 应 |
| 返回某范围内的数据 | 应 | 不应 |
| 一个或极少不同值 | 不应 | 不应 |
| 小数目的不同值 | 应 | 不应 |
| 大数目的不同值 | 不应 | 应 |
| 频繁更新的列 | 不应 | 应 |
| 外键列 | 应 | 应 |
| 主键列 | 应 | 应 |
| 频繁修改索引列 | 不应 | 应 |
-
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据 最终目的就是在相同结果集情况下,尽可能减少逻辑IO
-
非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因
BTree&B+Tree
BTree索引,B+Tree索引,哈希索引,全文索引
BTree是平衡搜索多叉树
设树的度为2d(d>1),高度为h,那么BTree要满足以下条件:
-
每个叶子结点的高度一样,等于h;
-
每个非叶子结点由n-1个key和n个指针point组成,其中d<=n<=2d,key和point相互间隔,结点两端一定是key;
-
叶子结点指针都为null; 非叶子结点的key都是[key,data]二元组,其中key表示作为索引的键,data为键值所在行的数据
多叉树,每个节点存储索引值,data值,关键字只出现一次,每个节点存一个区间值;查找时间复杂度 最差h * log(n)最好 (1)
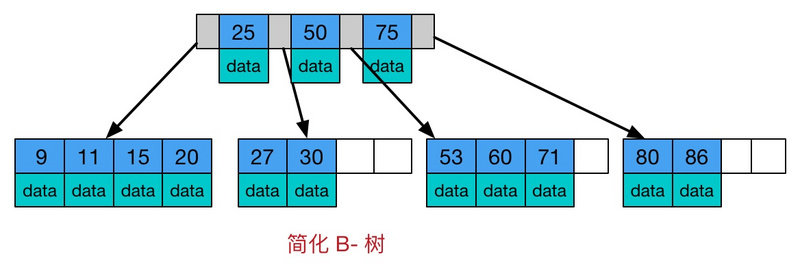
B+Tree是BTree的一个变种
设d为树的度数,h为树的高度,B+Tree和BTree的不同主要在于:
-
B+Tree中的非叶子结点不存储数据,只存储键值;
-
B+Tree的叶子结点没有指针,所有键值都会出现在叶子结点上,且key存储的键值对应data数据的物理地址;
-
B+Tree的每个非叶子节点由n个键值key和n个指针point组成;
进行查找操作时,首先在根节点进行二分查找,找到一个 key 所在的指针,然后递归地在指针所指向的节点进行查找。直到查找到叶子节点,然后在叶子节点上进行二分查找,找出 key 所对应的 data。 插入、删除操作会破坏平衡树的平衡性,因此在插入删除操作之后,需要对树进行一个分裂、合并、旋转等操作来维护平衡性。
B+树内节点不存储数据,所有 data 存储在叶节点导致查询时间复杂度固定为 log n;所有叶子节点有一个链指针,实现预读;预读基于存储局部性实现
由于B树的节点都存了key和data,而B+树只有叶子节点存data,非叶子节点都只是索引值,没有实际的数据,这就时B+树在一次IO里面,能读出的索引值更多。从而减少查询时候需要的IO次数!
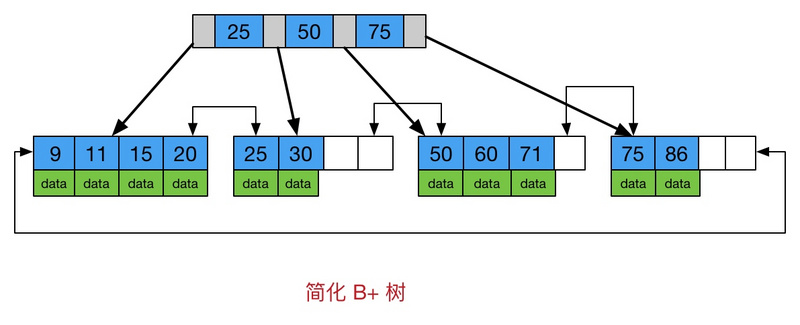
索引失效
参考2
除特殊情况,几乎所有的索引失效都是由于违背或没法遵循最左匹配原则造成的
1.有or必全有索引; 2.复合索引未用左列字段; 3.like以%开头; 4.需要类型转换; 5.where中索引列有运算; 6.where中索引列使用了函数; 7.如果mysql觉得全表扫描更快时(数据少); 8. 索引字段使用is null, is not null,可能导致索引失效
特殊情况:NULL null列是可以用到索引的,不管是单列索引还是联合索引,但仅限于is null,is not null是不走索引的。虽然MySQL可以在含有null的列上使用索引,但不代表null和其他数据在索引中是一样的。不建议列上允许为空。最好限制not null,并设置一个默认值,比如0和’'空字符串等,如果是datetime类型,可以设置成’1970-01-01 00:00:00’这样的特殊值。
判断索引是否失效
explain执行计划
查看查询语句中是否使用了索引: 方式一:EXPLAIN + 查询语句 查看语句的执行计划
其中包含了许多信息。可以通过其中和索引有关的信息来分析是否命中了索引,例如:possilbe_key、key、key_len 等字段,分别说明了此语句可能会使用的索引、实际使用的索引以及使用的索引长度。
EXPLAIN SELECT * FROM jingjia_info;
方式二:使用时间检测
# 运行时间检测set profiling=1;SQL;# 查看执行时间show profiles;
explain用法分析

-
表的读取顺序
-
数据读取操作的操作类型
-
哪些索引可以使用
-
哪些索引被实际使用
-
表之间的引用
-
每张表有多少行被优化器查询
脏读、不可重复读、幻读
脏读读取到另一个事务未提交的数据的现象就是脏读(Dirty Read)。
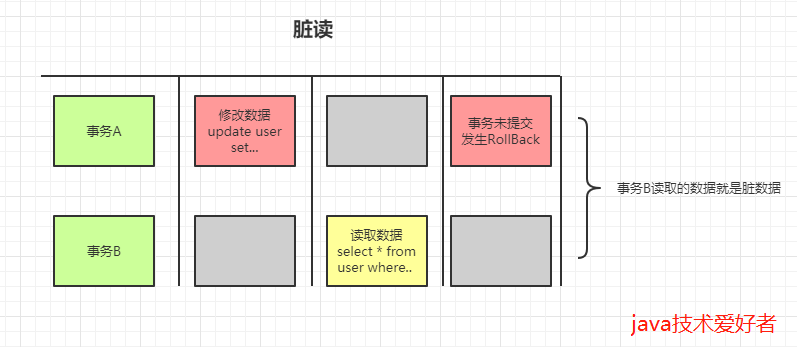
不可重复读事务B读取了两次数据资源,在这两次读取的过程中事务A修改了数据,导致事务B在这两次读取出来的数据不一致。
这种在同一个事务中,前后两次读取的数据不一致的现象就是不可重复读(Nonrepeatable Read)。
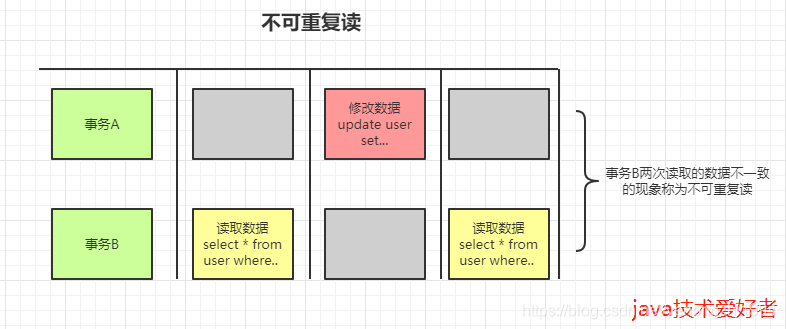
幻读事务B前后两次读取同一个范围的数据,在事务B两次读取的过程中事务A新增了数据,导致事务B后一次读取到前一次查询没有看到的行。 幻读和不可重复读有些类似,但是幻读强调的是集合的增减,而不是单条数据的更新
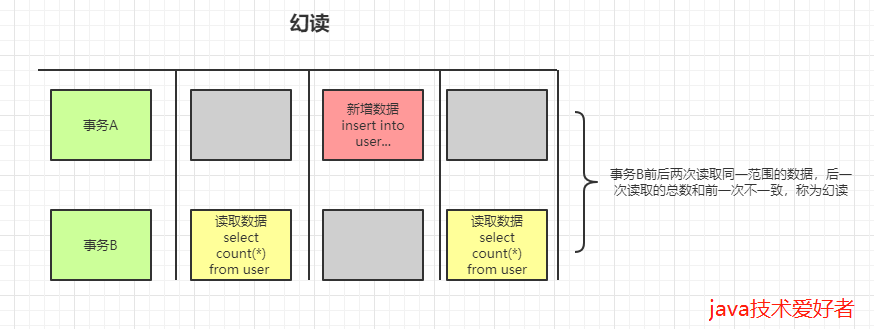
不可重复读和幻读
不可重复读的重点是现有数据的修改: 幻读的重点在于新增或者删除 (数据条数变化)
事务隔离级别
牛客例题
| 隔离级别 | 脏读 | 不可重复读 | 幻象读 |
|---|---|---|---|
| READ UNCOMMITTED (未提交读) | √ | √ | √ |
| READ COMMITED (提交读) | 不允许 | √ | √ |
| REPEATABLE READ (可重复读) | 不允许 | 不允许 | √ |
| SERIALIZABLE (序列化) | 不允许 | 不允许 | 不允许 |
SERIALIZABLE最高隔离级别:强制事务串行执行,在读取的每一行数据上都加锁,因此可能导致大量超时和锁争用问题;实际应用中只有在非常需要确保数据的一致性而且可以接收没有并发的情况下才会考虑该级别
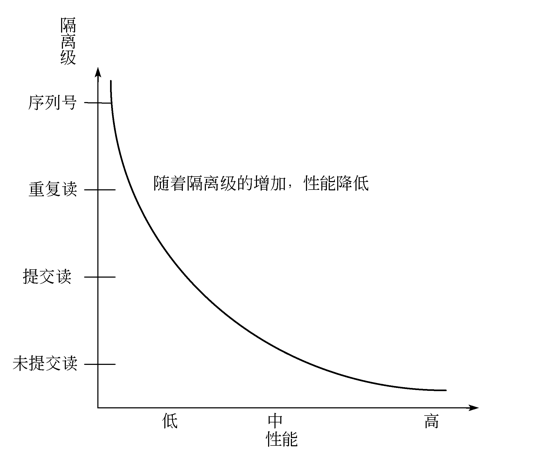
MySQL使用的InooDB存储引擎通过多版本并发控制解决幻读 可重复读是MySQL默认事务隔离级别
MVCC原理 深挖 Multiversion Concurrency Control 多版本控制
-
悲观并发控制(PCC)是一种用来解决读-写冲突和写-写冲突的的加锁并发控制, 为每个操作都加锁,同一时间下,只有获得该锁的事务才能有权利对该数据进行操作,没有获得锁的事务只能等待其他事务释放锁;所以可以解决脏读,幻读,不可重复读,第一类更新丢失,第二类更新丢失的问题
-
乐观并发控制(OCC)是一种用来解决写-写冲突的无锁并发控制,认为事务间争用没有那么多,所以先进行修改,在提交事务前,检查一下事务开始后,有没有新提交改变,如果没有就提交,如果有就放弃并重试。乐观并发控制类似自旋锁。乐观并发控制适用于低数据争用,写冲突比较少的环境;无法解决脏读,幻读,不可重复读,但是可以解决更新丢失问题
-
多版本并发控制(MVCC)是一种用来解决读-写冲突的无锁并发控制,也就是为事务分配单向增长的时间戳,为每个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据库的快照。 这样在读操作时就不用阻塞写操作,写操作也不用阻塞读操作;不仅可以提高并发性能,还可以解决脏读,幻读,不可重复读等事务问题。更新丢失问题除外
行锁
MySQL锁相关 InnoDB默认使用行锁
-
读锁(read lock),也叫共享锁(shared lock) 允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁
-
写锁(write lock),也叫排他锁(exclusive lock) 允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享锁和排他锁
-
意向共享锁(IS) 一个事务给一个数据行加共享锁时,必须先获得表的IS锁
-
意向排它锁(IX) 一个事务给一个数据行加排他锁时,必须先获得该表的IX锁
特点:对一行数据加锁 开销大 加锁慢 会出现死锁 锁粒度小,发生锁冲突概率最低,并发性高
SQL注入
mybatis是如何做到防止sql注入的
MyBatis框架作为一款半自动化的持久层框架,其SQL语句都要我们自己手动编写,这个时候当然需要防止SQL注入。其实,MyBatis的SQL是一个具有“输入+输出”的功能,类似于函数的结构,参考上面的两个例子。其中,parameterType表示了输入的参数类型,resultType表示了输出的参数类型。回应上文,如果我们想防止SQL注入,理所当然地要在输入参数上下功夫
在编写MyBatis的映射语句时,尽量采用“#{xxx}”这样的格式。若不得不使用“${xxx}”这样的参数,要手工地做好过滤工作,来防止SQL注入攻击
MySQL连接数
查看mysql的最大连接数:
show variables like '%max_connections%';
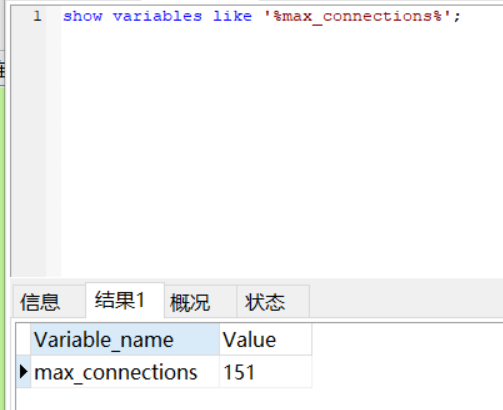
本人使用的是MySQL5.7.30,默认最大连接数可能就是151
如果服务器的并发连接请求量比较大,建议调高此值,以增加并行连接数量,当然这建立在机器能支撑的情况下,因为如果连接数越多,介于MySQL会为每个连接提供连接缓冲区,就会开销越多的内存,所以要适当调整该值,不能盲目提高设值。数值过小会经常出现ERROR 1040: Too many connections错误
查看当前连接数量
show global status like 'Max_used_connections';
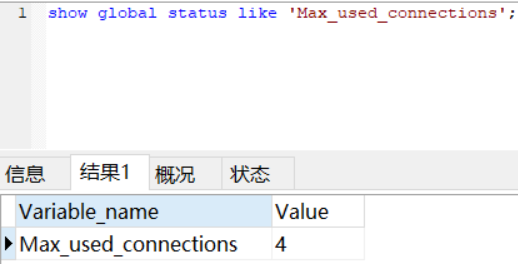
设置这个最大连接数值
方式一:(此设置在重启MySQL后失效)
set GLOBAL max_connections=1024; show variables like '%max_connections%';
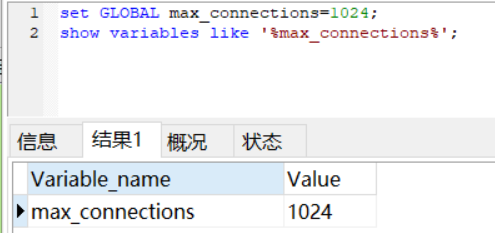
方式二:(重启MySQL服务后永久生效)
修改mysql配置文件my.cnf,在[mysqld]段中添加或修改max_connections值:max_connections=512
比较理想的设置是:Max_used_connections / max_connections * 100% ≈ 85%;如果发现比例在10%以下,MySQL服务器连接上线就设置得过高了。
MySQL的读写分离
读写分离顾名思义就是读和写分离了,对应到数据库集群一般都是一主一从(一个主库,一个从库)或者一主多从(一个主库,多个从库),业务服务器把需要写的操作都写到主数据库中,读的操作都去从库查询。主库会同步数据到从库保证数据的一致性。
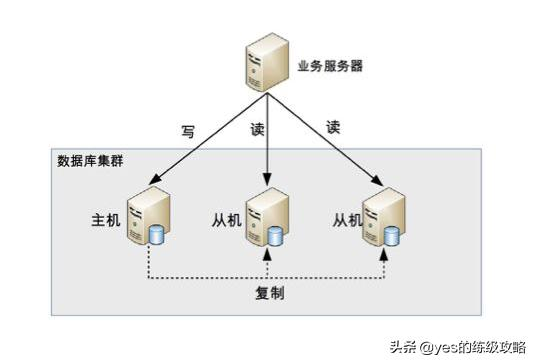
做了主从之后,我们可以单独的针对从库(读库)做索引上的优化,而主库(写库)可以减少索引而提高写的效率。有两点要注意:主从同步延迟、分配机制的考虑;
主从同步延迟
主库有数据写入之后,同时也写入在binlog(二进制日志文件)中,从库是通过binlog文件来同步数据的,这期间会有一定时间的延迟,可能是1秒,如果同时有大量数据写入的话,时间可能更长。
解决主从同步延迟的问题有以下几个方法:
\1. 二次读取:意思就是读从库没读到之后再去主库读一下
\2. 写之后的马上的读操作访问主库
\3. 关键业务读写都由主库承担,非关键业务读写分离
分配机制的考虑
分配机制的考虑也就是怎么制定写操作是去主库写,读操作是去从库读。
一般有两种方式:代码封装、数据库中间件。
技术没有贵贱,不是用了分布式就牛逼,越复杂的系统维护的成本和难度越高,出现问题的几率越大。这种架构的演化往往都是被用户所驱动的,可以说是"不得已而为之"。
基本上单机数据库可以支撑10万用户量级别。所以一般情况下像数据库吃不消就升级硬件,优化数据库配置、优化代码、引入redis等。只有在真的不行了才上这些更复杂的东西。
设计模式
设计模式的六大原则
1、开闭原则(Open Close Principle)
开闭原则的意思是:对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。简言之,是为了使程序的扩展性好,易于维护和升级。想要达到这样的效果,我们需要使用接口和抽象类,后面的具体设计中我们会提到这点。
2、里氏代换原则(Liskov Substitution Principle)
里氏代换原则是面向对象设计的基本原则之一。 里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。LSP 是继承复用的基石,只有当派生类可以替换掉基类,且软件单位的功能不受到影响时,基类才能真正被复用,而派生类也能够在基类的基础上增加新的行为。里氏代换原则是对开闭原则的补充。实现开闭原则的关键步骤就是抽象化,而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。
3、依赖倒转原则(Dependence Inversion Principle)
这个原则是开闭原则的基础,具体内容:针对接口编程,依赖于抽象而不依赖于具体。
4、接口隔离原则(Interface Segregation Principle)
这个原则的意思是:使用多个隔离的接口,比使用单个接口要好。它还有另外一个意思是:降低类之间的耦合度。由此可见,其实设计模式就是从大型软件架构出发、便于升级和维护的软件设计思想,它强调降低依赖,降低耦合。
5、迪米特法则,又称最少知道原则(Demeter Principle)
最少知道原则是指:一个实体应当尽量少地与其他实体之间发生相互作用,使得系统功能模块相对独立。
6、合成复用原则(Composite Reuse Principle)
合成复用原则是指:尽量使用合成/聚合的方式,而不是使用继承。
单例模式
牛客例题

优点
-
单例类只有一个实例对象,节省了系统资源(省去了对象的频繁创建 与销毁);
-
该单例对象必须由单例类自行创建;
-
单例类对外提供一个访问该单例的全局访问点。
缺点
-
单例模式一般没有接口,扩展困难。如果要扩展,则除了修改原来的代码,没有第二种途径,违背开闭原则。
-
在并发测试中,单例模式不利于代码调试。在调试过程中,如果单例中的代码没有执行完,也不能模拟生成一个新的对象。
-
单例模式的功能代码通常写在一个类中,如果功能设计不合理,则很容易违背单一职责原则。
使用场景
-
需要频繁的进行创建和销毁的对象;
-
创建对象时耗时过多或耗费资源过多,但又经常用到的对象;
-
工具类对象;
-
频繁访问数据库或文件的对象。
牛客例题 牛客例题
实现
1.懒汉式
是否 Lazy 初始化:是
是否多线程安全:否
实现难度:易
描述:这种方式是最基本的实现方式,这种实现最大的问题就是不支持多线程。因为没有加锁 synchronized,所以严格意义上它并不算单例模式。 这种方式 lazy loading 很明显,不要求线程安全,在多线程不能正常工作。
用的时候才去检查有没有实例,如果有则返回,没有则新建
public class Singleton { private static Singleton instance; private Singleton (){} public static Singleton getInstance() { if (instance == null) { instance = new Singleton(); } return instance; }
}
2.懒汉式(加锁)
是否 Lazy 初始化:是
是否多线程安全:是
实现难度:易
描述:这种方式具备很好的 lazy loading,能够在多线程中很好的工作,但是,效率很低,99% 情况下不需要同步。 优点:第一次调用才初始化,避免内存浪费。 缺点:必须加锁 synchronized 才能保证单例,但加锁会影响效率。 getInstance() 的性能对应用程序不是很关键(该方法使用不太频繁)。
public class Singleton { private static Singleton instance; private Singleton (){} public static synchronized Singleton getInstance() { if (instance == null) { instance = new Singleton(); } return instance; }
}
3.饿汉式
是否 Lazy 初始化:否
是否多线程安全:是
实现难度:易
描述:这种方式比较常用,但容易产生垃圾对象。 优点:没有加锁,执行效率会提高。饿汉式借助类加载机制,绝对保证单例唯一 缺点:类加载时就初始化,浪费内存。 它基于 classloader 机制避免了多线程的同步问题,不过,instance 在类装载时就实例化,虽然导致类装载的原因有很多种,在单例模式中大多数都是调用 getInstance 方法, 但是也不能确定有其他的方式(或者其他的静态方法)导致类装载,这时候初始化 instance 显然没有达到 lazy loading 的效果。
实例在初始化的时候就已经建好了,不管你有没有用到,都先建好了再说;没有线程安全问题,但浪费空间
public class Singleton { private static Singleton instance = new Singleton(); private Singleton (){} public static Singleton getInstance() { return instance; }
}
单例模式优化
观察者模式
一对多对象依赖,当一个对象发生改变,它的所有依赖者都将收到通知并自动更新;
典例:气象局信息与多个数据看板
定义一个基础接口定义相关方法(观测方法,查询方法);实现基础接口后将所有观察者存入ArrayList,当重新查询时遍历数组对象调用查询方法
松耦合,将对象之间依赖降到最低
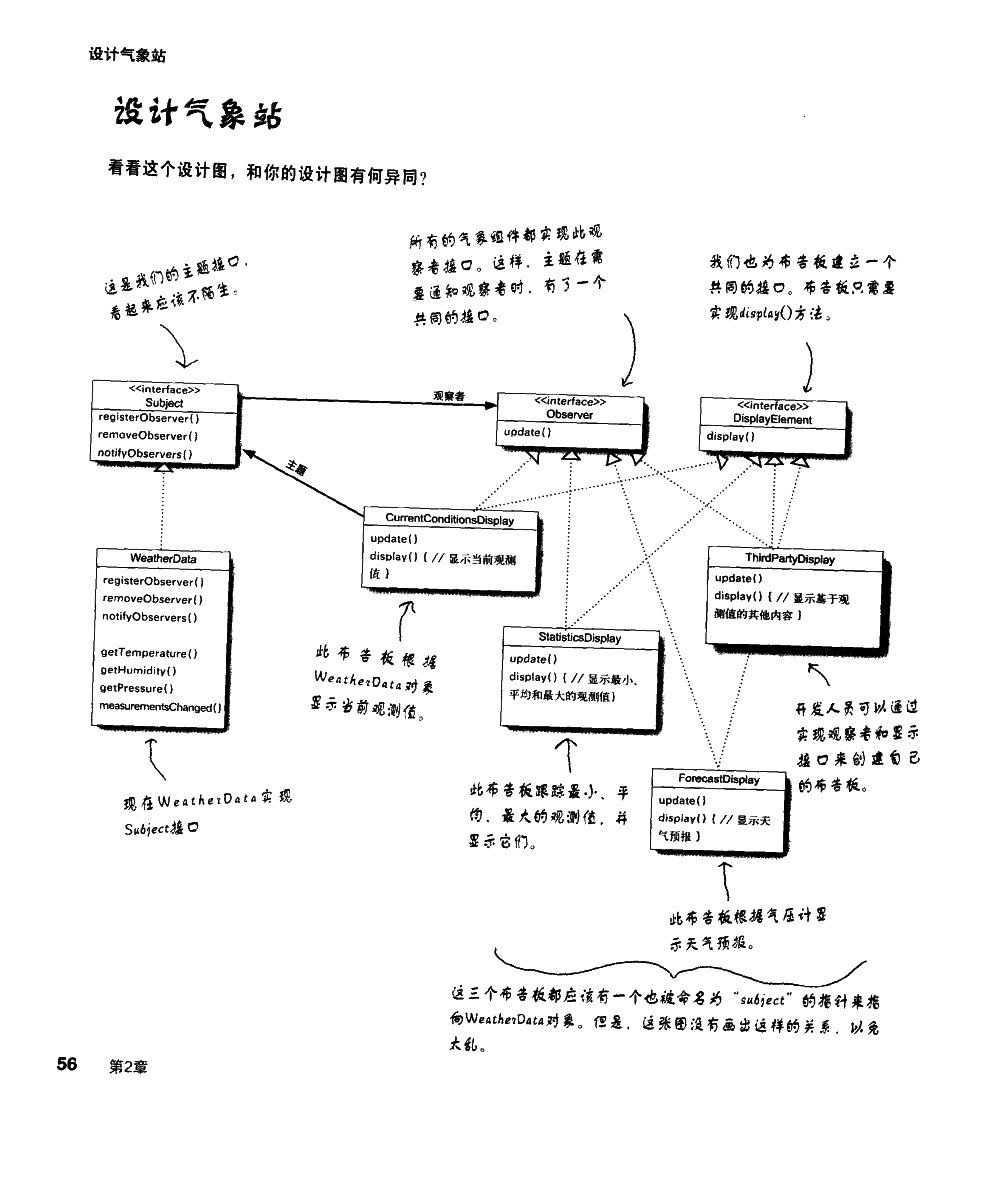
工厂模式
桥接模式
牛客例题
定义 :将抽象部分与它的实现部分分离,使它们都可以独立地变化。
意图 :将抽象与实现解耦。
桥接模式所涉及的角色 \1. Abstraction :定义抽象接口,拥有一个Implementor类型的对象引用 \2. RefinedAbstraction :扩展Abstraction中的接口定义 \3. Implementor :是具体实现的接口,Implementor和RefinedAbstraction接口并不一定完全一致,实际上这两个接口可以完全不一样Implementor提供具体操作方法,而Abstraction提供更高层次的调用 \4. ConcreteImplementor :实现Implementor接口,给出具体实现
Jdk中的桥接模式:JDBC JDBC连接 数据库 的时候,在各个数据库之间进行切换,基本不需要动太多的代码,甚至丝毫不动,原因就是JDBC提供了统一接口,每个数据库提供各自的实现,用一个叫做数据库驱动的程序来桥接就行了
装饰者模式
简书 csdn
生产者-消费者
-
解耦:将生产者类和消费者类进行解耦,消除代码之间的依赖性,简化工作负载的管理
-
复用:通过将生产者类和消费者类独立开来,那么可以对生产者类和消费者类进行独立的复用与扩展
-
调整并发数:由于生产者和消费者的处理速度是不一样的,可以调整并发数,给予慢的一方多的并发数,来提高任务的处理速度
-
异步:对于生产者和消费者来说能够各司其职,生产者只需要关心缓冲区是否还有数据,不需要等待消费者处理完;同样的对于消费者来说,也只需要关注缓冲区的内容,不需要关注生产者,通过异步的方式支持高并发,将一个耗时的流程拆成生产和消费两个阶段,这样生产者因为执行put()的时间比较短,而支持高并发
-
支持分布式:生产者和消费者通过队列进行通讯,所以不需要运行在同一台机器上,在分布式环境中可以通过redis的list作为队列,而消费者只需要轮询队列中是否有数据。同时还能支持集群的伸缩性,当某台机器宕掉的时候,不会导致整个集群宕掉

1)容器中数据状态的一致性:当一个consumer执行了take()方法之后,此时容器为空,但是还没来得及更新容器的size,那么另外一个consumer来了之后以为size不等于0,那么继续执行take(),从而造成了了状态的不一致性
2)为了保证当容器里面没有数据的时候,消费者不会继续take,此时消费者释放锁,处于阻塞状态;并且一旦生产者添加了一条数据之后,此时重新唤醒消费者,消费者重新获取到容器的锁,继续执行take();
计算机网络
常用的协议及端口号:
| 端口号 | 服务 | 协议名称 |
|---|---|---|
| 21 | FTP | 文件传输协议 |
| 23 | Telnet | 远程登陆协议 |
| 25 | SMTP | 邮件传输协议(最原始) |
| 53 | DNS | 域名服务器(解析) |
| 80 | HTTP | Hyper Text Transfer Protocol |
| 109 | POP2 | 第二代简单邮局协议 |
| 110 | POP3 | 第三代简单邮局协议 |
| 111 | RPC | 远程过程调用协议 |
| 143 | IMAP | 网络消息访问协议 |
| 161 | SNMP | 简单网络管理协议 |
| 443 | https | HyperText Transfer Protocol over Secure Socket Layer |
访问一个网页的全过程
-
域名解析成IP地址;
-
与目的主机进行TCP连接(三次握手);
-
发送与收取数据(浏览器与目的主机开始HTTP访问过程);
-
与目的主机断开TCP连接(四次挥手);
发送与收取数据(浏览器与目的主机开始HTTP访问过程) 只有建立连接后才能开始传输数据。
浏览器向域名发出GET方法报文(HTTP请求); 该GET方法报文通过TCP->IP(DNS)->MAC(ARP)->网关->目的主机; 目的主机收到数据帧,通过IP->TCP->HTTP,HTTP协议单元会回应HTTP协议格式封装好的HTML形式数据(HTTP响应);[ 从请求信息中获得客户机想访问的主机名。从请求信息中获取客户机想要访问的web应用(web应用程序指提供浏览器访问的程序,简称web应用)。从请求信息中获取客户机要访问的web资源。(web资源,即各种文件,图片,视频,文本等)读取相应的主机下的web应用,web资源。用读取到的web资源数据,创建一个HTTP响应。] 该HTML数据通过TCP->IP(DNS)->MAC(ARP)->网关->我的主机; 我的主机收到数据帧,通过IP->TCP->HTTP->浏览器,浏览器以网页形式显示HTML内容。
首先通过域名找到IP,如果缓存里没有就要请求DNS服务器;得到IP后开始与目的主机进行三次握手来建立TCP连接;连接建立后进行HTTP访问,传输并获取网页内容;传输完后与目的主机四次挥手来断开TCP连接。
| UDP | TCP | |
|---|---|---|
| 是否连接 | 无连接 | 面向连接 |
| 是否可靠 | 不可靠传输,不使用流量控制和拥塞控制 | 可靠传输,使用流量控制和拥塞控制 |
| 连接对象个数 | 支持一对一,一对多,多对一和多对多交互通信 | 只能是一对一通信 |
| 传输方式 | 面向报文 | 面向字节流 |
| 首部开销 | 首部开销小,仅8字节 | 首部最小20字节,最大60字节 |
| 适用场景 | 适用于实时应用(IP电话、视频会议、直播等) | 适用于要求可靠传输的应用,例如文件传输 |
TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:
-
FTP文件传输
-
HTTP / HTTPS
UDP 面向无连接,它可以随时发送数据,再加上UDP本身的处理既简单又高效,因此经常用于:
-
包总量较少的通信,如 DNS 、SNMP等
-
视频、音频等多媒体通信
-
广播通信
http与https
-
HTTP 明文传输,数据都是未加密的,安全性较差,HTTPS(SSL+HTTP) 数据传输过程是加密的,安全性较好。
-
使用 HTTPS 协议需要到 CA(Certificate Authority,数字证书认证机构) 申请证书,一般免费证书较少,因而需要一定费用。证书颁发机构如:Symantec、Comodo、GoDaddy 和 GlobalSign 等。
-
HTTP 页面响应速度比 HTTPS 快,主要是因为 HTTP 使用 TCP 三次握手建立连接,客户端和服务器需要交换 3 个包,而 HTTPS除了 TCP 的三个包,还要加上 ssl 握手需要的 9 个包,所以一共是 12 个包。
-
http 和 https 使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443。
-
HTTPS 其实就是建构在 SSL/TLS 之上的 HTTP 协议,SSL运行在TCP协议之上;所以,要比较 HTTPS 比 HTTP 要更耗费服务器资源。
HTTP原理HTTP是一个基于TCP/IP通信协议来传递数据的协议,传输的数据类型为HTML 文件,、图片文件, 查询结果等。
HTTP协议一般用于B/S架构()。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。
存在的问题:请求信息明文传输,容易被窃听截取;数据的完整性未校验,容易被篡改;没有验证对方身份,存在冒充危险
HTTP 5大特点
-
支持客户/服务器模式。
-
简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有
GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。 -
灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由
Content-Type加以标记。 -
无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。早期这么做的原因是请求资源少,追求快。后来通过
Connection: Keep-Alive实现长连接 -
无状态:
HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
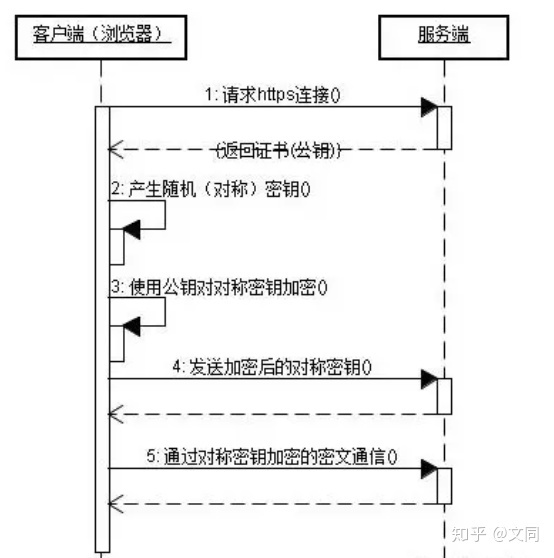
https传输数据流程
HTTPS 协议(HyperText Transfer Protocol over Secure Socket Layer):一般理解为HTTP+SSL/TLS,通过 SSL证书来验证服务器的身份,并为浏览器和服务器之间的通信进行加密。
HTTPS存在的问题:
-
HTTPS协议多次握手,导致页面的加载时间延长近50%;
-
HTTPS连接缓存不如HTTP高效,会增加数据开销和功耗;
-
申请SSL证书需要钱,功能越强大的证书费用越高。
-
SSL涉及到的安全算法会消耗 CPU 资源,对服务器资源消耗较大。
三次握手
TCP握手 半连接,二次握手 洪范攻击 牛客例题
TCP:状态控制码(Code,Control Flag)
标志位字段(U、A、P、R、S、F):占6比特。各 比特的含义如下:
-
URG:紧急比特(urgent),当URG=1时,表明紧急指针字段有效,代表该封包为紧急封包。它告诉系统此报文段中有紧急数据,应尽快传送(相当于高优先级的数据), 且上图中的 Urgent Pointer 字段也会被启用。
-
ACK:确认比特(Acknowledge)。只有当ACK=1时确认号字段才有效,代表这个封包为确认封包。当ACK=0时,确认号无效。
-
PSH:(Push function)若为1时,代表要求对方立即传送缓冲区内的其他对应封包,而无需等缓冲满了才送。
-
RST:复位比特(Reset) ,当RST=1时,表明TCP连接中出现严重差错(如由于主机崩溃或其他原因),必须释放连接,然后再重新建立运输连接。
-
SYN:同步比特(Synchronous),SYN置为1,就表示这是一个连接请求或连接接受报文,通常带有 SYN 标志的封包表示『主动』要连接到对方的意思。。
-
FIN:终止比特(Final),用来释放一个连接。当FIN=1时,表明此报文段的发送端的数据已发送完毕,并要求释放运输连接。
第一次握手:客户端发送 SYN 报文,并进入 SYN_SENT 状态,等待服务器的确认;
第二次握手:服务器收到 SYN 报文,需要给客户端发送 ACK 确认报文,同时发送一个 SYN 报文此时服务器进入 SYN_RCVD 状态;
第三次握手:客户端收到 SYN + ACK 报文,向服务器发送确认包,客户端进入 ESTABLISHED 状态。待服务器收到客户端发送的 ACK 包也会进入 ESTABLISHED 状态,完成三次握手。
第一次、第二次握手不可以携带数据,而第三次握手是可以携带数据的
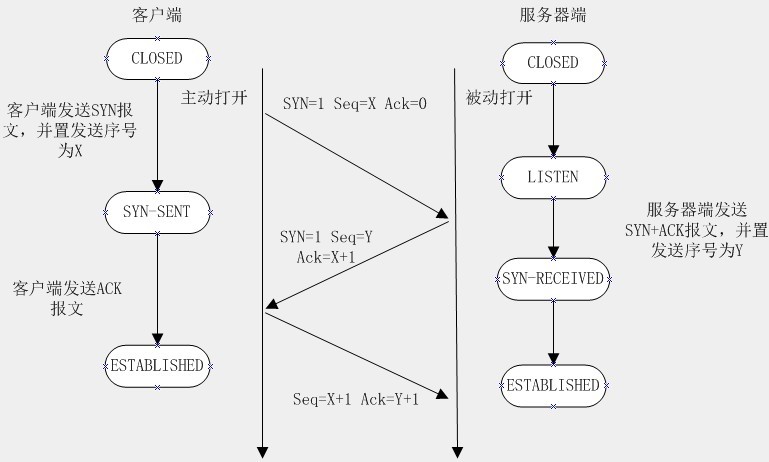
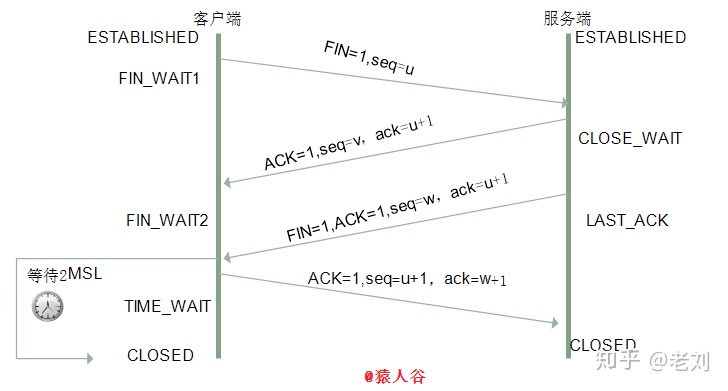
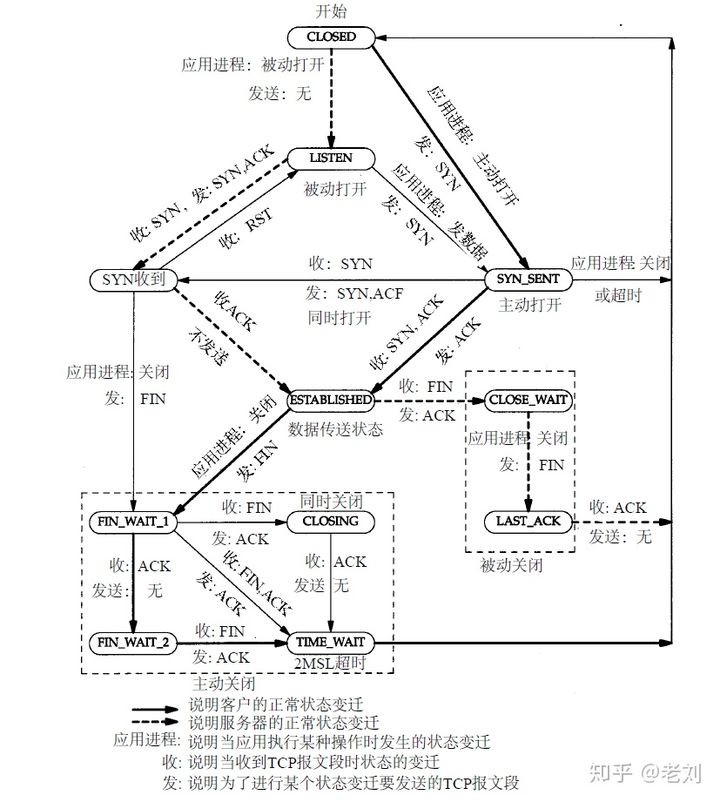
常见的防御 SYN 攻击的方法有如下几种:
-
缩短超时(SYN Timeout)时间
-
增加最大半连接数
-
过滤网关防护
-
SYN cookies技术
get请求与post请求
参考 参考2
GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。
-
Get产生一个TCP数据包;Post产生两个TCP数据包。
-
GET请求会被浏览器主动缓存,而POST不会,除非手动设置。
-
GET请求只能进行url编码,而POST支持多种编码方式。
-
GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据); 对于POST,浏览器先发送header,服务器响应100(continue),然后再发送data,服务器响应200(返回数据);
\1. GET与POST都有自己的语义,不能随便混用。
\2. 据研究,在网络环境好的情况下,发一次包的时间和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次包的TCP在验证数据包完整性上,有非常大的优点。
\3. 并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
Cookie 与 Session
简单区别
Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中。
Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
-
存取方式的不同,Cookie 只能保存 ASCII,Session 可以存任意数据类型,一般情况下我们可以在 Session 中保持一些常用变量信息,比如说 UserId 等
-
有效期不同,Cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,Session 一般失效时间较短,客户端关闭或者 Session 超时都会失效。
-
隐私策略不同,Cookie 存储在客户端,比较容易遭到不法获取,早期有人将用户的登录名和密码存储在 Cookie 中导致信息被窃取;Session 存储在服务端,安全性相对 Cookie 要好一些。
-
存储大小不同, 单个 Cookie 保存的数据不能超过 4K,Session 可存储数据远高于 Cookie。

Linux简单命令
菜鸟教程 27个linux常用命令
创建进程
clone()函数:创建轻量级进程的堆栈并且调用对编程者隐藏的clone()系统调用。调用sys_clone()服务例程。
主要用来创建一个线程,可以是内核线程和用户线程,也可以创建进程,有选择的复制父进程资源。系统调用fork()和vfork()是无参数的,而clone()则带有参数。fork()是全部复制,vfork()是共享内存,而clone()是则可以将父进程资源有选择地复制给子进程,而没有复制的数据结构则通过指针的复制让子进程共享,具体要复制哪些资源给子进程,由参数列表中的clone_flags来决定。另外,clone()返回的是子进程的pid。
fork()函数:用clone()实现,它的child_stack参数是父进程当前的堆栈指针。因此,父进程和子进程暂时共享同一个用户态堆栈。通常只要父子进程中有一个试图去改变栈,则立即各自得到用户态堆栈的一份拷贝。
do_fork()函数负责处理clone(), fork()和vfork()系统调用。利用辅助函数copy_process()来创建进程描述符以及子进程执行所需要的所有其他内核数据结构。
copy_process()函数:创建进程描述符以及子进程执行所需要的所有其他数据结构。(28个步骤)
do_fork()结束之后,继续完善子进程,1)把子进程描述符thread字段的值装入几个CPU寄存器;2)在fork(),vfork()或clone()系统调用结束时,新进程将开始执行。
进程终止(两个系统调用):
-
exit_group()系统调用,它终止整个线程组,即整个基于多线程的应用。do_group_exit()
-
exit()系统调用,它终止某一个线程,而不管该线程所属线程组中的所有其他进程。do_eixt()
牛客例题 牛客例题
查询日志
牛客
cat 由第一行开始显示文件内容 tac 从最后一行开始显示,可以看出 tac 是 cat 的倒着写! nl 显示的时候,顺道输出行号! more 一页一页的显示文件内容 less 与 more 类似,但是比 more 更好的是,他可以往前翻页! head 只看头几行 tail 只看尾巴几行
#查看日志 grep -n '2019-10-24 00:01:11' *.log
#根据文件名查文件路径 -i表示不区分大小写 find -iname "文件名" #根据关键字查询在文件哪一行(注意关键字与文件名大小写区分) grep -n 【关键字】 文件名
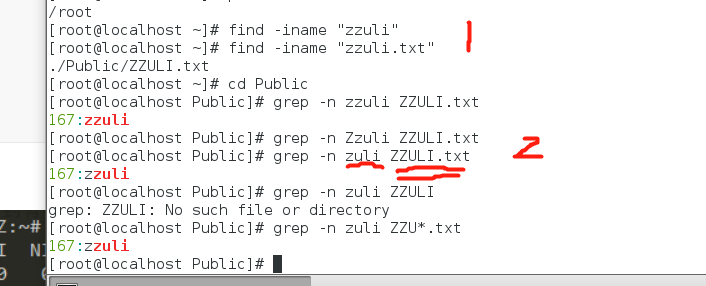
文件名可以使用“*”模糊查询
查看进程
ps -l 列出与本次登录有关的进程信息;ps -aux 查询内存中进程信息;ps -aux | grep *** 查询***进程的详细信息;top 查看内存中进程的动态信息;kill -9 pid 杀死进程
ps ( ps -l, 列出的是详细信息 )

F 代表这个程序的旗标 (flag), 4 代表使用者为 superuser; S 代表这个程序的状态 (STAT); ( 常见的进程的 STAT 如下: R 运行 Runnable (on run queue) 正在运行或在运行队列中等待, S 睡眠 Sleeping 休眠中, 受阻, 在等待某个条件的形成或接受到信号, I 空闲 Idle ,
文件操作
ls — List
ls会列举出当前工作目录的内容(文件或文件夹)。

ls命令演示
2.mkdir — Make Directory
mkdir 用于新建一个新目录

执行mkdir命令创建相应的文件夹
3.pwd — Print Working Directory
显示当前工作目录

显示当前工作目录
4.cd — Change Directory
切换文件路径,cd 将给定的文件夹(或目录)设置成当前工作目录。
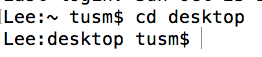
切换路径到桌面
5.rmdir— Remove Directory
删除给定的目录。

创建的文件夹会被删除
6. rm— Remove
rm 会删除给定的文件
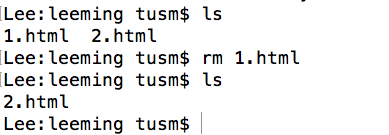
删除某个文件
7. cp— Copy
cp 命令对文件进行复制
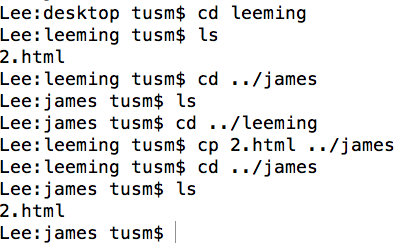
文件的复制
8. mv— Move
mv 命令对文件或文件夹进行移动,如果文件或文件夹存在于当前工作目录,还可以对文件或文件夹进行重命名。
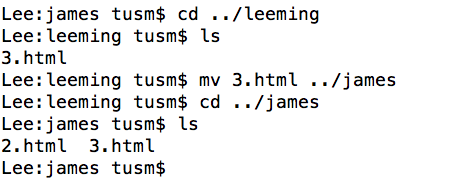
移动文件
12.grep
grep 在给定的文件中搜寻指定的字符串。grep -i “” 在搜寻时会忽略字符串的大小写,而grep -r “” 则会在当前工作目录的文件中递归搜寻指定的字符串。

查找相关内容
13.find
这个命令会在给定位置搜寻与条件匹配的文件。你可以使用find -name 的-name选项来进行区分大小写的搜寻,find -iname 来进行不区分大小写的搜寻。
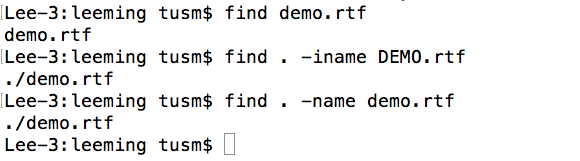
三种使用示例
14.tar
tar命令能创建、查看和提取tar压缩文件。tar -cvf 是创建对应压缩文件,tar -tvf 来查看对应压缩文件,tar -xvf 来提取对应压缩文件。

创建压缩文件

查看压缩文件
15. gzip
gzip 命令创建和提取gzip压缩文件,还可以用gzip -d 来提取压缩文件。

生成gzip文件
16. unzip
unzip 对gzip文档进行解压。在解压之前,可以使用unzip -l 命令查看文件内容。

解压缩文件
通过关键词查找文件
grep在文本中查找内容
文件名区分大小写
grep [选项] PATTERN [FILE]
#从多个文件中查找关键词 -n显示行号 [root@localhost test]# grep -n 'linux' test.txt test2.txt test.txt:1:hnlinux test.txt:4:ubuntu linux test.txt:7:linuxmint test2.txt:1:linux [root@localhost test]# grep 'linux' test.txt test2.txt test.txt:hnlinux test.txt:ubuntu linux test.txt:linuxmint test2.txt:linux
多文件时,输出查询到的信息内容行时,会把文件的命名在行最前面输出并且加上":"作为标示符
vim编辑机
Vim是从 vi 发展出来的一个文本编辑器。代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。简单的来说, vi 是老式的字处理器,不过功能已经很齐全了,但是还是有可以进步的地方。 vim 则可以说是程序开发者的一项很好用的工具。
连 vim 的官方网站 (http://www.vim.org) 自己也说 vim 是一个程序开发工具而不是文字处理软件
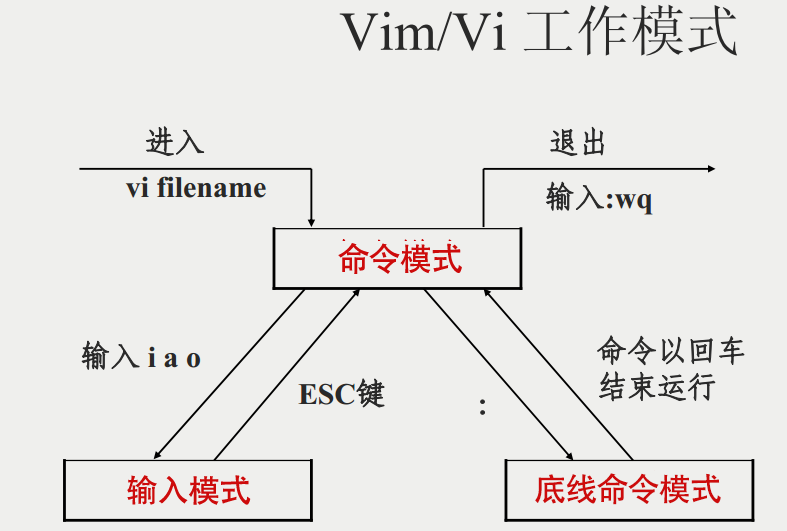
| 移动光标的方法 | |
|---|---|
| h 或 向左箭头键(←) | 光标向左移动一个字符 |
| j 或 向下箭头键(↓) | 光标向下移动一个字符 |
| k 或 向上箭头键(↑) | 光标向上移动一个字符 |
| l 或 向右箭头键(→) | 光标向右移动一个字符 |
| 进入输入或取代的编辑模式 | |
|---|---|
| i, I | 进入输入模式(Insert mode): i 为『从目前光标所在处输入』, I 为『在目前所在行的第一个非空格符处开始输入』。 (常用) |
| a, A | 进入输入模式(Insert mode): a 为『从目前光标所在的下一个字符处开始输入』, A 为『从光标所在行的最后一个字符处开始输入』。(常用) |
| o, O | 进入输入模式(Insert mode): 这是英文字母 o 的大小写。o 为在目前光标所在的下一行处输入新的一行; O 为在目前光标所在的上一行处输入新的一行!(常用) |
| r, R | 进入取代模式(Replace mode): r 只会取代光标所在的那一个字符一次;R会一直取代光标所在的文字,直到按下 ESC 为止;(常用) |
| 指令行的储存、离开等指令 | |
|---|---|
| :w | 将编辑的数据写入硬盘档案中(常用) |
| :w! | 若文件属性为『只读』时,强制写入该档案。不过,到底能不能写入, 还是跟你对该档案的档案权限有关啊! |
| :q | 离开 vi (常用) |
| :q! | 若曾修改过档案,又不想储存,使用 ! 为强制离开不储存档案。 |
| 注意一下啊,那个惊叹号 (!) 在 vi 当中,常常具有『强制』的意思~ | |
| :wq | 储存后离开,若为 :wq! 则为强制储存后离开 (常用) |
| ZZ | 这是大写的 Z 喔!如果修改过,保存当前文件,然后退出!效果等同于(保存并退出) |
| ZQ | 不保存,强制退出。效果等同于 :q!。 |
yum 命令
yum( Yellow dog Updater, Modified)是一个在 Fedora 和 RedHat 以及 SUSE 中的 Shell 前端软件包管理器。基于 RPM 包管理,能够从指定的服务器自动下载 RPM 包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装。
yum 语法
yum [options] [command] [package ...]
-
options:可选,选项包括-h(帮助),-y(当安装过程提示选择全部为 "yes"),-q(不显示安装的过程)等等。
-
command:要进行的操作。
-
package:安装的包名。
yum常用命令
-
\1. 列出所有可更新的软件清单命令:yum check-update
-
\2. 更新所有软件命令:yum update
-
\3. 仅安装指定的软件命令:yum install <package_name>
-
\4. 仅更新指定的软件命令:yum update <package_name>
-
\5. 列出所有可安裝的软件清单命令:yum list
-
\6. 删除软件包命令:yum remove <package_name>
-
\7. 查找软件包命令:yum search <keyword>
-
\8. 清除缓存命令:
-
yum clean packages: 清除缓存目录下的软件包
-
yum clean headers: 清除缓存目录下的 headers
-
yum clean oldheaders: 清除缓存目录下旧的 headers
-
yum clean, yum clean all (= yum clean packages; yum clean oldheaders) :清除缓存目录下的软件包及旧的 headers
-
Git
git与svn
git使用的是分布式版本控制系统,没有中央服务器,每个人电脑都是一个完整版本库;目前最先进的分布式版本控制系统
svn是集中式版本控制系统,版本库放在中央服务器,工作时需要使用自己电脑与服务器交互,必须联网工作
#查看配置信息 git config --system --list

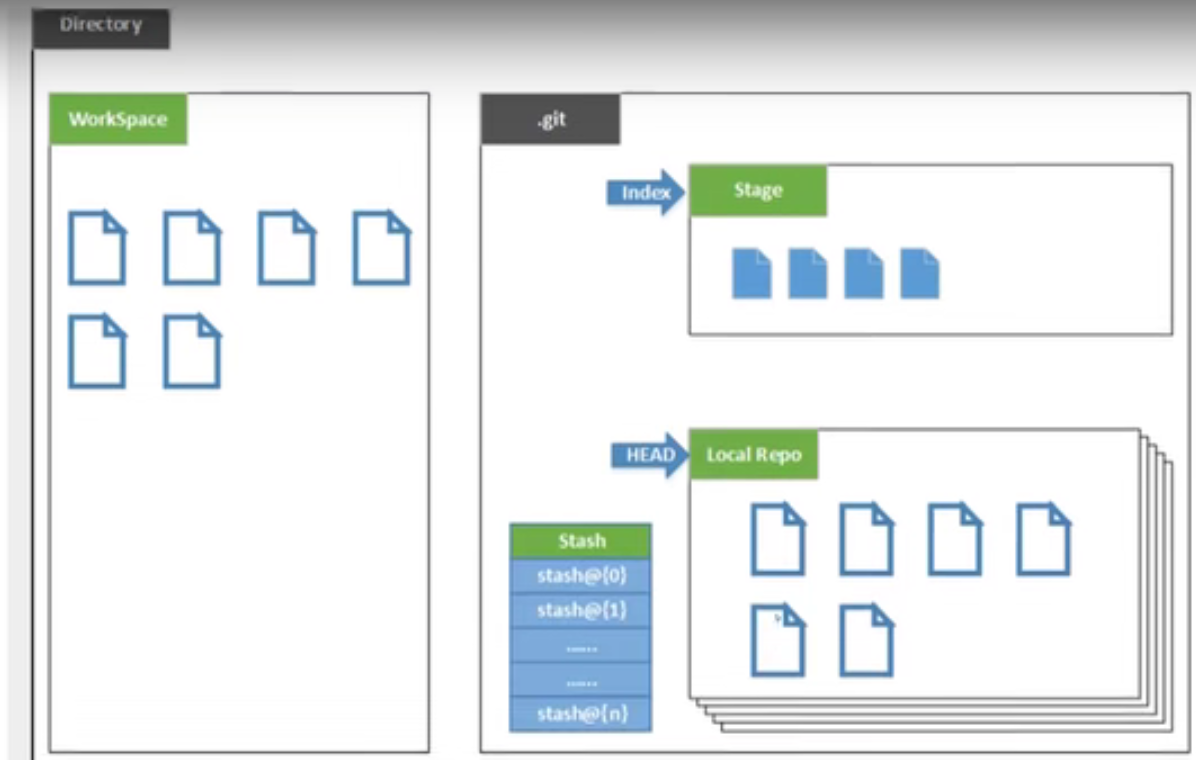
工作流程
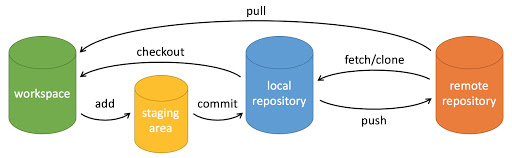
- git add. - git commit #本地初始化 git init#连接gitee仓库 git clone【url】https://gitee.com/zy0098/git-test.git
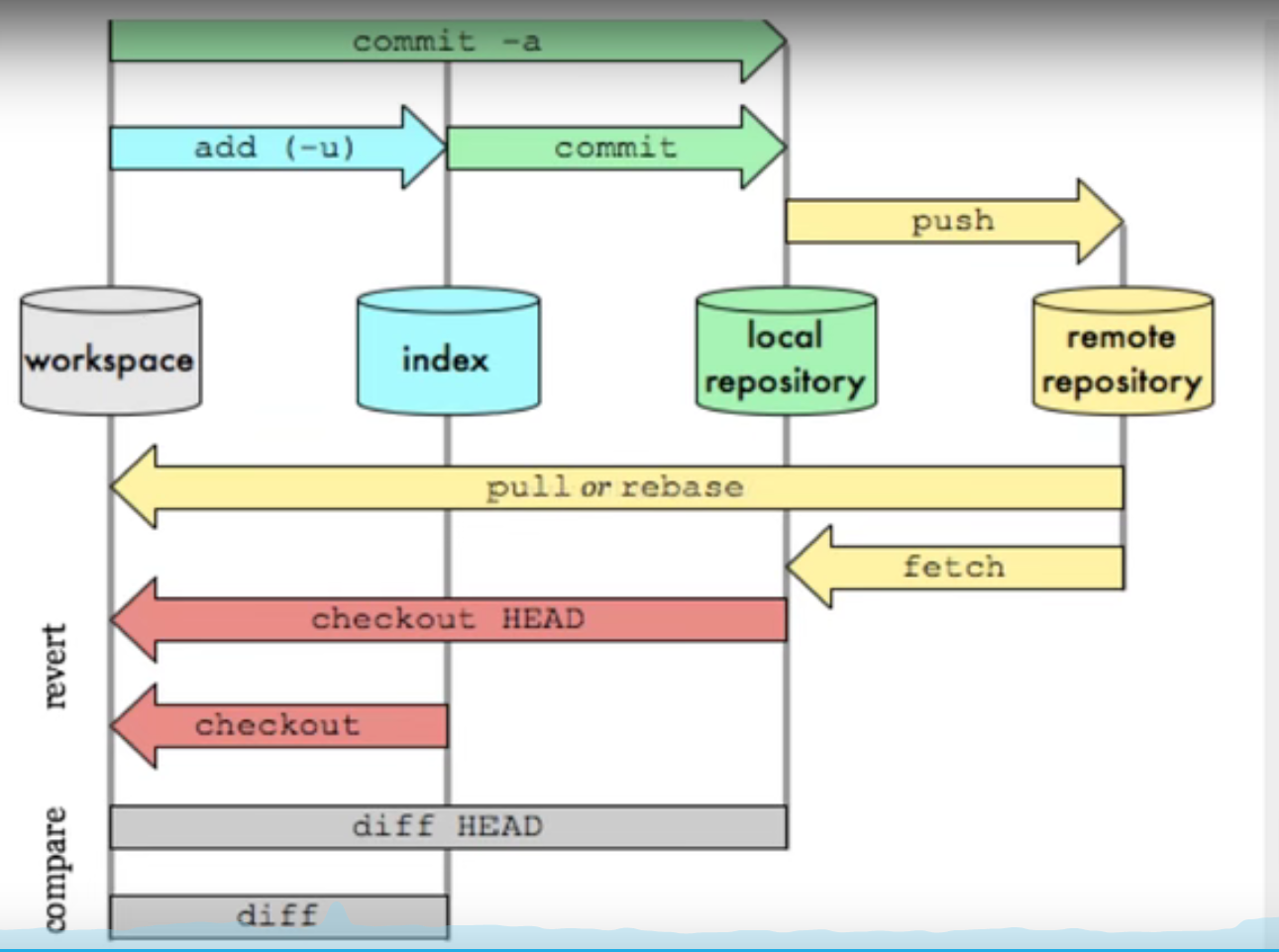
具体使用
-
git status 查看状态
-
git add . 添加入暂存区
-
git commit -m "注释" 提交信息到本地缓存区
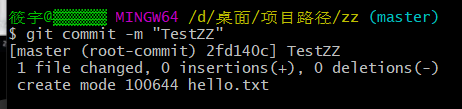
-
git push 提交到云
| 命令 | 说明 |
|---|---|
git add | 添加文件到仓库 |
git status | 查看仓库当前的状态,显示有变更的文件。 |
git diff | 比较文件的不同,即暂存区和工作区的差异。 |
git commit | 提交暂存区到本地仓库。 |
git reset | 回退版本。 |
git rm | 删除工作区文件。 |
git mv | 移动或重命名工作区文件。 |
忽略上传
.txt #忽略所有txt结尾文件 !lib.txt #除了lib.txt /temp #仅忽略项目根目录下TODO文件,不包括其他目录temp build/ #忽略build/目录下素有文件 doc/*.txt #忽略doc/*.txt 但不包括doc/server/arch.txt
使用码云(gitee)上传
-
~/.ssh 进入ssh公钥目录

-
在ssh文件夹下生成公钥(可以设置邮箱与其他信息)
-
将公钥添加设置到gitee
-
使用码云创建仓库(可以设置不同许可证,可查看相关开源规则)
git clone http网址
将仓库克隆到本地,然后将文件复制到项目下覆盖项目中自动生成的文件,此时项目已经可以与云连接
传统软件架构与互联网软件架构
一文弄清传统软件开发与互联网软件异同
传统行业
核心诉求: 在满足功能需求的情况下,怎么好维护,怎么开发成本低怎么来。机器都是甲方出,所以能通过堆机器解决的问题都不是问题 (不过也需要为客户考虑项目整体成本)
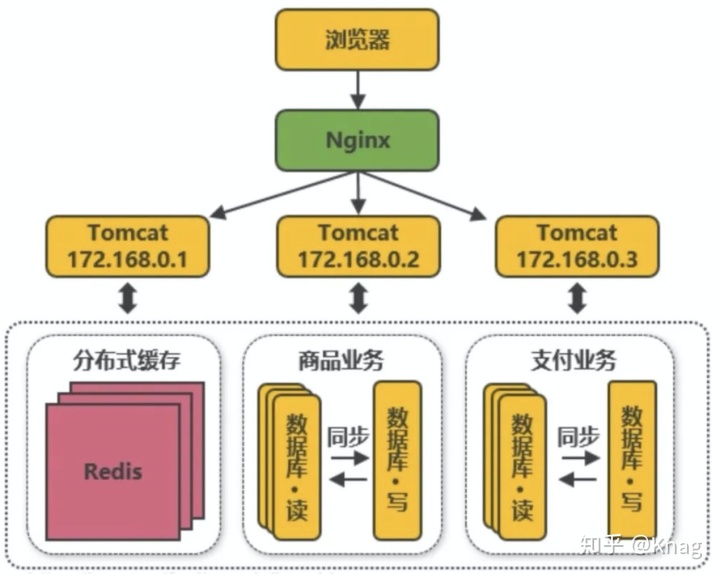
互联网行业
核心诉求: 支持快速迭代、稳定、高并发。另外,机器都是自己出,多一台都是成本….
能力要求
-
传统软件开发 在传统软件开发中,更多的是要求技术的广度,以及综合能力,希望技术人员是多面手,要求以最快的速度,最低的成本搞定需求。开发时,更多的也是按功能模块拆分,希望开发人员能够从前到后一条龙搞定。对时间、代码质量不敏感,对项目的资源投入与收益敏感。
-
互联网软件开发 在互联网公司中,岗位拆分的很细,会更多的要求单一方向的技术深度,专门的岗位干专业的事。之所以会把岗位拆这么细,是因为这样方便模块拆分,实现更多的并行开发,尽力做到增加人员,就能加快项目开发进度,实现快速抢占市场的目的。
行业关注点
-
传统行业 更多的关心一个项目的投入与产出比,所以会在产品上多下功夫,尽量的把通用功能产品化,以更多的复用来减少开发成本。同时,更注重业务解决方案的抽取,提升核心竞争力。
-
互联网行业 更多的关心需求的上线速度,更快的速度占领市场就会有更多的优势;所以会更多的关注模块化,实现通过不断的增加开发人员,就能明显提升开发速度,所以岗位、系统才会拆得比较细粒度。为了解决复用问题,衍生出中台概念。