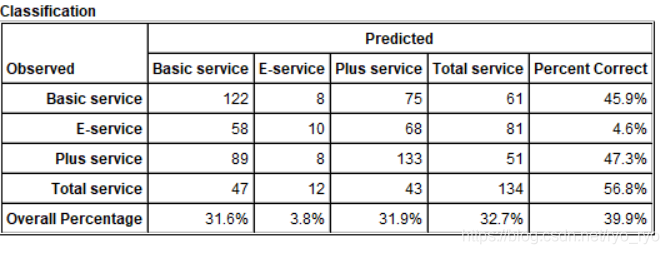
今天,小编和大家一起学习聚类算法,是在没有任何先验知识的情况下,基于样本的数据特征,把相似或相近的样本划为一群,把差异较大或相远的样本划分到另一群,形成不同的类别。
1. 聚类方法
1.1 距离
利用距离来判断样本间的相似程度。
常用的有:明氏距离、曼哈顿距离、欧式距离、切比雪夫距离。
1.2 K-means算法
基于原型的聚类算法。
在初始阶段,随机指定k个质心,之后通过距离度量的方式,把每个样本分配到距离他最近的质心中,从而形成初始的聚类类群。
接着,根据上一次的聚类结果重新计算新的质心并对样本进行重新划分,如此反复多次,直到获得满意结果。实现过程:
1.21 指定聚类数目k
先设置一个较小的k之后逐渐增加,对每个k均运行算法,最后通过最终结果的轮廓系数大小作为最终结果。
1.22 初始化k个聚类的中心
两种方法:
① 随机法:随机指定k个样本点作为初始化中心。
② 最远距离法:随机选择一个样本点作为第一个中心,接下来选择距离第一个中心最远的点作为质心,直至生成k个中心。
1.23 计算距离,把所有样本划分到不同类群。
计算每个样本到k个类群中心的距离,根据最小距离原则把每个样本点分配到距离它最近的中心,最终把所有的样本都划分到k个类群中。
1.24 根据上一步聚类结果,重新计算每个类群的中心。
每个样本分配完成后,需要重新计算每个类群的中心。
1.25 判定是否达到停止条件,否则返回第三步重复进行。
终止条件设定:
① 指定聚类中心变动阈值。
② 指定迭代次数。
1.3 K-means注意事项
1.31 聚类前应先对变量进行标准化
SPSS Modeler会在聚类前对数据自动进行标准化处理,0-1标准化,即离差标准化。
1.32 聚类前应对分类变量进行处理
由于聚类算法距离的计算是针对数值型变量的,分类变量不能直接处理,需要先对分类变量进行数值化处理,设置产生虚拟变量,即哑变量。对于m个水平的分类变量,可以引入m个虚拟化的0-1变量。
虽然采用哑变量的方式解决了分类变量距离计算的问题,但是通过哑变量计算将导致分类变量的权重大于其他数值型变量。为了保证分类变量的权重与数值型变量一致,SPSS Modeler会同样对哑变量进行标准化。
1.33 聚类结果好坏的度量方式
目标:同一个类群样本尽可能近,不同类群的样本尽可能远。
指标:轮廓系数,系数越大,说明聚类效果越好。一般地,当>0.5时,可认为聚类模型有较好的效果;当<0.2时,认为分类效果不明显。

在样本量较大的情况下,轮廓系数的计算会非常大,为了减低计算,SPSS Modeler将使用替代方案进行计算距离,如下图:

2. K-means聚类实践
使用“K-Means”节点完成。
案例:Demo数据文件“car_sales_knn_mod.sav”。
数据展示:157款已上市的不同型号的汽车属性数据,包括有制造商、型号、销量、4年转售价值、上市价格、销量等指标。2款待上市的新车数据,新车数据中不包括销量。
我们将利用聚类后的结果对这2款新车的后续表现进行预测。

数据流:

2.1 数据质量审核
在建模前,先借助“数据审核”节点(输出菜单条中)对数据进行审核。



通过审核结果及数据表,我们发现数据存在缺失,主要是:
- manufact,type字段:只有新型车存在缺失,此处缺失值需要进行填充。
- sales,resale(4年转售价值):新车数据刚上市,以及部分车上市不够4年数据为空。该值不参与建模,只作为最后比较使用。
- price,engine_s及其他:部分数据收集存在缺失,对于此部分数据进行删除。
2.2 建模前准备
2.21 使用“填充”节点对manufact字段进行缺失值填充

2.22 使用“填充”节点对type字段进行缺失值填充


2.23 使用“选择”节点对其他存在空值的字段进行删除

2.24 使用“选择”节点选择已上市的车辆数据,之后添加“类型”节点进行变量角色设定


2.3 建模
2.31 模型选项卡

2.32 专家选项卡

集合编码值越接近于1,分类型变量的权重就越大于数值型变量。
2.4 结果

模型共使用了10个输入变量,划分为4个类群,模型的轮廓系数为0.5,分类效果较好。




进一步,可以在模型块后连接“表格”节点,查看运行后结果:

最后,对上述模型进行复制,并将2款新车型数据输入模型,进行分析,看分别归入哪个类别。