本篇博客主要参考/节选中科院自动化所王唯康博士的博士论文《任务型对话系统中对话管理方法研究》。
文章目录
- 1. 概述
- 2. 基于管道的任务型对话系统
- 2.1 语言理解模块
- 2.2 对话管理模块
- 2.3 语言生成模块
- 3. 端到端的任务型对话系统
- 3.1 基于检索的任务型对话系统
- 3.2 基于生成的任务型对话系统
- 4. 任务型对话语料收集
- 5. 用户仿真技术
- 6. 问题分析
1. 概述
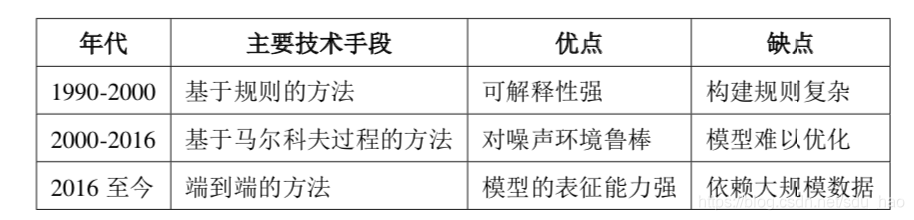
早期任务型对话系统基于规则实现,实现比较简单并在简单的对话任务中取得了不错的效果,但难以适用于复杂的对话任务,规则的撰写和维护需要消耗大量的人力和物力。
后来得益于SVM、概率图模型和强化学习的发展,研究人员开始利用统计模型设计任务型对话系统,并提出部分可观测的马尔科夫决策过程设计框架,可以从对话数据中自动学习对话知识,一定程度上摆脱了对规则的依赖。
随着深度学习的发展,end2end模型被应用在了任务型对话系统设计中[1-5]。基于深度学习的任务型对话系统有两种路线:一种是基于Pipline,整个系统仍采用模块拼接的方式,但各个子模块采用神经网络实现,利用神经网络提升各个子模块的性能,从而最终提高整个对话系统的性能。另一种end2end模型,和聊天机器人建模方式类似, 即利用检索式或生成式模型直接实现对话上下文到回复的映射,可以避免级联模型带来的误差传递问题。
目前,任务型对话系统的设计方法可以分为两大类:基于管 道的方法和基于端到端的方法。在基于管道的方法中,研究者可以采取不同的技 术手段实现各个模块,因此便于开发和调试。而基于端到端的方法通过对系统进行全局建模,因此可以避免模块级联所带来的误差传递问题。
2. 基于管道的任务型对话系统
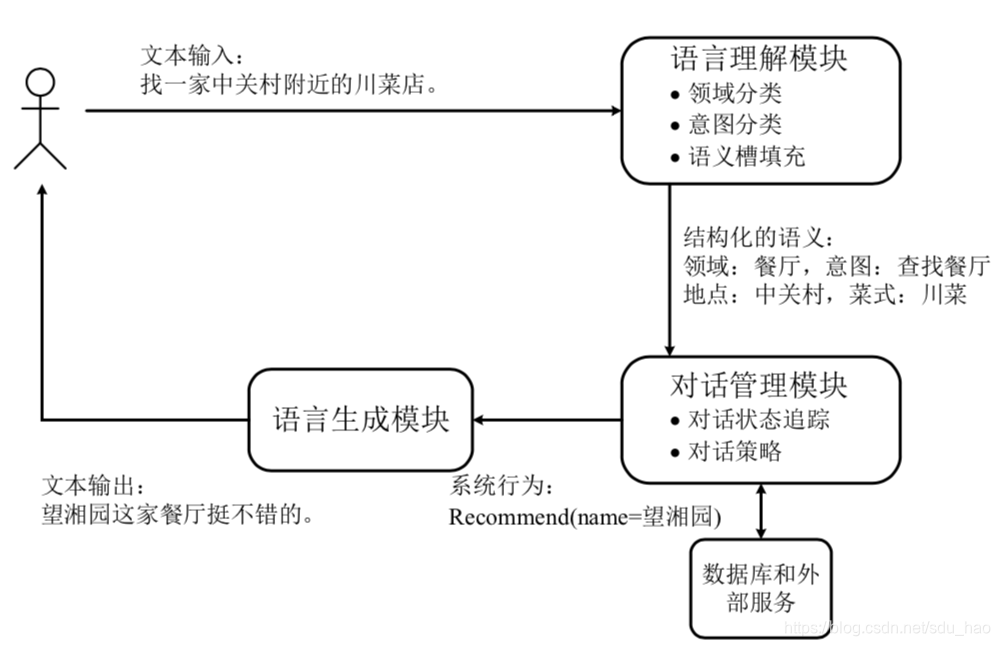
基于管道的设计方法要求开发者分别实现系统的各个子模块,然后拼接这些模块,最终形成一个完整的系统。这种方法的特点是不同模块可以采取不同的技术手段实现,各个模块之间彼此无关联。
2.1 语言理解模块
把用户的自然语言输入转化为结构化语义(semantic frame)形式的输出。一般涉及:领域分类(domain classification,有些工作不考虑领域分类)、意图分类(intent classification)和语义槽填充(slot filling)。如上图所示:用户输入“找一家中关村附近的川菜店。”后,语言理解模块的解析结果。其中, 语言理解模块首先判断出当前对话涉及的领域为“餐厅”,用户意图为“查找餐 厅”,所包含的语义槽为“地点”以及“菜式”,属性值/槽值分别为“中关村”和“川菜”。
领域分类和意图分类 领域分类要求模型识别当前对话属于哪个任务/领域,意图分类则要求模型识别用户当前轮的对话意图。这两个任务均属于句子分类任务(sentence classification)/文本分类。其差别是,较意图分类而言,领域分类的分类粒度更大。 通常有两种方法完成这两个任务。第一种是层次化的分类方法,即先进行领域分类,然后再在相应的领域下进行意图分类。这种做法需要根据前一次领域分类的结果进行意图分类。当前一次分类存在错误时,后一次分类也会给出错误的结果(误差传播)。第二种是扁平化的分类方法,即先对领域标签和意图标签进行组合,然后一次性地确定用户输入所涉及的领域和意图。这种做法避免了误差传递问题。 但是,由于分类标签的急剧增多,模型的性能通常会有所下降。所有可用于文本分类的模型都适用于这两个任务,如SVM、CNN、RNN、Bert等。
语义槽填充 语义槽是完成对话任务所需的关键信息。例如在餐厅领域中, 交互过程可能会涉及餐厅的“地点”、“人均消费”和“菜式”等属性(语义槽)。语义槽填充的目的即把用户输入中的这些属性信息给抽取出来。例如,在上图所示的例子当中,槽填充需要抽取的信息包括“地点”和“菜式”。早期使用基于规则的方法,后来研究人员把语义槽填充问题建模为一个序列标注任务,并采用 BIO 格式的标签对句子中的每个词进行预测。因此,所有可用于序列标注任务的模型都可以用来做语义槽填充,如:BiLSTM+CRF、基于Bert的槽填充模型。
联合模型 语言理解模块中的三个子任务在某种程度上存一定的联系。同时利用这三个任务的学习信号训练模型将会促进模型在各个任务上的表现。基于此,研究人员利用了多任务学习的思想(multi-task learning)对这几个任务进行联合建模,使得表示层的语义信息得到强化,最终在这三个任务中均取得了更好的效果。在联合学习模型中,基于 BERT 的模型能够有效地利 用无标注数据,同时具备更精确的语义表示能力和更好的长距离依赖建模能力。 因此,该模型取得了目前最好的效果,并在实际系统中得到了成功的应用。
近期还出现了一些小样本学习的方式,即few-shot的文本分类(意图分类)和few-shot的序列标注(语义槽填充)
2.2 对话管理模块
对话管理模块是任务型对话系统的中枢部分,由对话状态追踪模块和对话策略模块组成。
其中,对话状态追踪模块负责记录和更新对话过程中所涉及的变量及其相应的属性值。例如在餐厅领域,用户可以利用餐厅的“地点”、“人均消费”和“菜式”来检索心仪的餐厅。那么,对话状态追踪模块需要记录这三个属性所对应的值。当完成用户状态的更新后,系统会依据当前的对话状态同后台数据库交互,并按照某一对话策略选择系统行为。

基于状态机的对话管理方法 早期的对话管理采用基于状态机的方法实现。开发者需要枚举出所有可能的对话状态、状态跳转规则和对话策略。用户输入结束后,系统将根据预定义的规则进行状态的转移,同时根据转移后的对话状态执行相应的系统行为。上图是餐厅领域的一个简单的对话状态转移图。图中节点表示对话状态,不同对话状态的差异在于节点记录了不同的语义槽信息。整个对话过程可以看作从开始状态到结束状态的转移。
优点是具有很好的可解释性。但是,当对话任务变得复杂时,对话状态会急剧增多。另外,对话策略的设计依赖于开发者的经验。在实际开发过程中,开发人员需要根据用户的反馈反复地调整对话策略,设计成本高,难以在复杂对话任务中实用。
基于部分可观测马尔科夫决策过程的对话管理方法 和基于状态机的对话管理不同,该框架下的对话状态是一个随机变量而非一个确定值。这种方法考虑到了语音识别和语言理解的噪声,并通过信念状态(belief state)建模对话状态的不确定性。因此,该对话管理方法具备更好的鲁棒性。
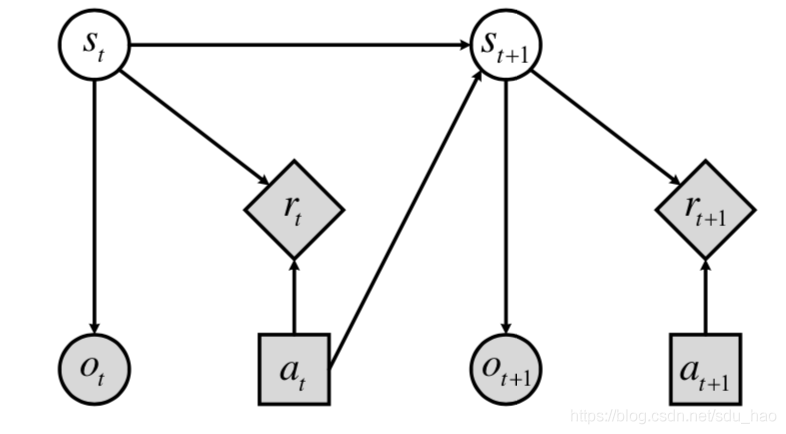
下图给出了基于马尔科夫过程的对话管理中的状态转移示意图。白色的节点代表不可观测的信念状态,灰色的节点代表可观测的变量(语言理解的结果,从环境中获取的反馈以及系统行为)。在基于马尔科夫过程的对话管理中,下一时刻的信念状态 s t + 1 s_{t+1} st+1取决于当前时刻的信念状态 s t s_t st、当前时刻的系统行为 a t a_t at和下一时刻观测到的语言理解结果 o t + 1 o_{t+1} ot+1. 信念状态的求解较为复杂,研究者通常采用近似估计的方法对其进行求解。常用的两种方法为修剪重组策略(pruning and recombination strategies)和基于因式贝叶斯网络的方法(factored bayesian network approach)。
基于马尔科夫(决策)过程的对话管理采用强化学习 [6] 优化对话策略。其核心思想是让系统通过不断地尝试,从试错中学习完成任务的策略。在使用强化学习优化对话策略之前,人们需要设计一个奖励函数评估系统策略的好坏。奖励函数设计得是否合理会直接影响策略优化的质量。常用的奖励函数是鼓励系统在最少的交互轮次内完成任务。但是,在涉及多个对话领域的复杂任务中,这样的奖励函数不一定适用且存在奖励稀疏的问题。因此,Takanobu 等 [7]提出从专家示范 (expert trajectories)中学习奖励函数,并利用学到的奖励函数指导强化学习训练。 这种方法被称为逆强化学习(Inverse Reinforcement Learning,IRL)。Peng 等 [8]则借鉴了生成式对抗网络(Generative Adversarial Networks,GAN)的思想,利用人机对话和专家示范的差异程度评估对话策略的好坏。人机对话和专家示范之间差异越小说明当前系统的对话策略越接近人类的对话策略,因此系统会收到较大的奖励。反之,则收到较小的奖励。Shi 等 [9]提出利用无监督 学习(unsupervised learning)的方法从对话语料中挖掘对话的结构逻辑,并把挖掘出来的结构信息作为辅助奖励函数指导策略优化。此外,在语音交互场景下, Shi 和 Yu [10]首先对用户的输入进行多模态情感分析,然后把用户的情感状态作为奖励函数。这些工作都极大地丰富了奖励函数的设计手段。
在设计好奖励函数之后,开发者需要采取某种强化学习算法优化对话策略。 较为常用的优化方法是基于值迭代的方法 。基于值迭代的方法通过状态动作值函数(q-function)度量智能体在某个状态下执行某一操作后收到的期望累计奖励值。该函数满足 Bellman 等式,可以通过时序差分估计或蒙特卡洛估计的方法计算优化目标。状态动作值函数优化结束后,对话策略模块会选择期望累计奖励最大的动作作为输出。
值得注意的是,使用强化学习优化对话策略时,用户需要和系统进行多次的交互。此外,强化学习算法普遍存在数据利用率低、探索与利用难以平衡和收敛缓慢等问题。这使得基于强化学习的对话管理模块需要和用户进行较多轮的交互后才能得到充分的训练。因此,使用强化学习训练对话管理模块的成本非常高。针对这个问题,Gašić 和 Young [11]提出利用核函数(kernel function)建模两个状态动作值函数之间的关系,显著地降低了训练对话策略所需的交互次数。Su 等 [12]提出利用主动学习(active learning)[13-15] 的方法减少在线强化学习过程中人工评价的工作量。Asadi 和 Williams [16]以及 Su 等 [5]提出使用重要性采样机制(importance sampling)[82] 对系统之前探索到的对话数据加以利用。Lipton 等 [17]提出使用贝叶斯神经网络(bayesian neural networks)[18] 对状态动作值函数的不确定性进行建模,并让对话智能体优先探索不确定性大的对话状态,从而提高了对话管理模块的探索效率。Peng 等 [19]提出利用基于模型的强化学习算法(model based reinforcement learning)[20] 显式地对用户进行建模,并从用户模型中采样伪对话数据训练对话策略,从而缓解了对真实用户的依赖(用户模拟器)。这些方法均有效地减少了利用强化学习训练对话管理模块的训练开销。
端到端的对话管理方法 随着深度学习技术的发展,研究人员开始利用深度神经网络模型设计对话管理模块。由于深度神经网络是端到端可微分的,且具备更强大的表征能力,因此这种方法成为了目前的研究热点。
首先,针对对话状态追踪任务,相关工作可以分为基于打分的模型和基于生成的模型。基于打分的模型的典型例子是 Mrkšić 等 [21]提出的对话状态追踪器。首先使用卷积神经网络对对话上下文和对话状态的候选结果进行表征,然后在这个表征的基础上对对话状态的候选结果进行评估,最后把每个语义槽下打分最高的候选结果当作用户当前的对话状态。但在实际的应用中,人们 无法枚举出语义槽所有可能的取值,因此基于打分的方法无法处理候选结果之外的情形。为了解决这个问题,研究者提出了基于生成的模型。其基本思想是利用指针网络(pointer network)[22] 直接从上下文中拷贝出某一语义槽对应的属性值。这种方法能够处理任意的对话状态值,因此成为了设计对话状态追踪器的主流方法。较为典型的例子是 Xu 和 Hu [23]以及 Wu 等 [24]的工作。
其次,针对对话策略优化问题,相关研究可以划分为基于策略梯度的方法 (policy gradient)和基于深度 Q 网络的方法(deep q-network)。基于策略梯度算 法的典型例子是 Williams 等 [4]提出的基于混合编码网络的对话管理模块。该模型把语言理解模块的结果、系统上一时刻的行为和数据库中的结果输入到循环神经网络单元中,从而得到当前时刻的对话状态,最后根据这个对话状态从系统行为集合中选择合适的系统行为。和这项工作类似的还有 Su 等 [25]和 Liu 等 [26]提出的对话管理模型。与基于策略梯度更新方法不同的是,基于深度 Q 网络的对话管理模块通过神经网络估计对话智能体的状态动作值函数,其输入是对话状态的表征,输出则是状态动作值(函数)。较为典型的工作是 Zhao 和 Eskenazi [2]以及 Li 等 [3]提出的端到端对话管理模型。和基于策略梯度的方法相比,基于深度 Q 网络的方法对数据的利用率更低,因此模型更难以收敛。
2.3 语言生成模块
基于规则的语言生成方法 当对话管理模块选择系统行为后,语言生成模块会把相应的系统行为翻译为自然语言。语言生成模块一般基于规则实现 [3, 4]。 开发者会预先构造回复模板,然后依据系统行为选择相应的回复模板,最后把回复模板中的通配符替换为相应的实体信息。例如,对话管理模块的输出“Recommend(name= 望湘园)”表示向用户推荐一个名为“望湘园”的餐厅。那么,语言生成模块会选择回复模板“ n a m e name name 这家餐厅挺不错的”。其中,通符“ n a m e name name” 可以被替换为餐厅名称“望湘园”。进行实体替换操作后的回复模板将作为语言生成模块的输出。基于规则的语言生成方法因为实现简单,所以在商用系统中得到了广泛的应用。
数据驱动的语言生成方法 除此之外,有工作研究了数据驱动的语言生成方法。Walker 等 [28]首先提出了一种句子规划器,并利用该句子规划器生成由多个短句组成的复杂句子。Stent 和 Molina [29]则直接从有标注的语料中学习句子组合规则。Rieser 和 Lemon [30]使用强化学习生成句子。然而,这些方法对语料标注的要求较高,且在某种程度上依然依赖启发式的规则。最近几年,人们开始尝试使用神经网络实现语言生成模块。这一方向最早的工作是 Oh 和 Rudnicky [31]提出的基于短语的语言生成模型。后来,随着循环神经网络语言模型 [32, 33] 的兴起,研究人员提出了基于循环神经网络的语言生成模型。较为典型的工作是 Wen 等 [34]提出的基于 LSTM 的语言生成模块。该模型使句子生成过程条件于需要表达的语义上,同时引入了门控机制使得解码器在解码时能够利用对话行为和语义槽等信息。数据驱动的语言生成方法虽然能够基于有标注的数据进行模型训练,但是也严重地依赖大规模高质量的平行句对。
3. 端到端的任务型对话系统
端到端的任务型对话系统不再独立地设计各个子模块,而是直接学习对话上下文到系统回复的映射关系,设计方法更简单。相关研究可以划分为两大类:基于检索的方法和基于生成的方法。
基于检索的对话系统如下图所示。其基本框架是首先通过某种方法对上下文以及所有的候选回复进行编码,然后通过打分函数度量上下文和每个候选回复的匹配程度,最后把匹配程度最高的回复返回给用户。不同检索模型的区别主要在于句子表征模型和打分模型的不同。基于检索的模型 最早被应用在聊天机器人的设计中 [35–39]。Bordes 等 [2]通过规则构建了一批任务型对话数据,并在该数据中比较了各种基于检索的对话模型的性能。
3.1 基于检索的任务型对话系统
基于词袋法的检索模型 最简单的基于检索的对话系统通过词袋法(Bag of Words,BOW)表示文本,并采用余弦距离计算文本之间的匹配度 [2]。具体来说,模型首先用向量表示每个文本。向量中的每一位代表着一个单词,其值是该单词的频率和逆文档频率的乘积(TF-IDF)。然后,模型将计算上下文表征和候选回复表征的余弦距离,进而得到两者之间的匹配度打分。最后,余弦距离最大的那个候选回复将会返回给用户。除此之外,模型还可以计算两个上下文之间(对话历史)的相似性程度,并把距离当前上下文最近的那个上下文所对应的回复返回给用户。在实际的操作中,为了减少计算量,还可以用对话中的最后一句话代表整个对话上下文。 基于词袋法的对话模型无需学习任何参数,属于经典的信息检索模型,是基于检索的任务型对话系统中最简单的模型。
基于稠密向量的检索模型 随着词表示模型和句子表示模型的发展,研究人员开始利用稠密向量编码上下文和候选回复。具体做法是首先采用 Mikolov 等提出的 word2vec 模型编码单词,然后采用某种方法组合句中单词的信息, 进而得到整个句子的编码表示。常用的句子编码方法有简单的词向量相加和基于循环神经网络的方法。当完成对句子的编码后,对话模型会采取最大间距损失函数优化参数。相较于基于词袋法的检索模型,基于稠密向量的检索模型能够更好地学习到上下文的编码表示,因此在许多基于检索的对话系统中都取得了不错的效果 [2, 40]。
基于记忆网络的检索模型 此外,Bordes等[2]还使用了记忆网络模型(memory network)[41, 42] 学习上下文和候选回复的匹配度打分。具体而言,记忆网络首先把上下文中每个句子的表征存储在一个外部记忆单元中,然后把候选回复的表征当作查询向量,并利用这个查询向量从记忆单元中读取信息。在每次读操作后,模型都会根据读取出来的内容更新查询向量。当最后一次读操作结束后,模型读取出来的向量会被用于预测候选回复是正确回复的概率。这种多跳读操作模拟了人类的推理过程,因此能够很好地建模回复和上下文之间的长距离依赖关系。基于记忆网络的检索模型也在 Bordes 等 [2]提出的对话数据集中取得了最好的效果。
基于 BERT 的检索模型 除了 Bordes 等 [2]提到的检索模型之外,其它句子表征模型也可以用于检索型任务型对话系统的设计。例如,Henderson 等 [43]提出的基于 BERT 的对话模型 [44]。具体而言,Henderson 等 [43]首先通过 BERT 对上下文以及候选回复进行编码,然后利用开放域的对话数据对模型进行预训练,接着在任务型对话数据集上微调模型。由于基于BERT 的检索模型能够充分利用开放域的对话数据,所以该模型取得了目前最好的结果。
除了关注模型的设计之外,还有工作借鉴了自监督学习(self-supervised learning)的思想,为基于检索的任务型对话系统构造辅助任务,并利用这些辅助任务提升检索模型的性能 [45]。例如,Mehri 等 [45]构造了“下一个句子预测”、“下一个句子生成”、“掩码后的句子生成”以及“不一致句子识别”等四个辅助任务,并通过这些任务学习预训练句子编码模型。这种学习框架并不关注模 型结构的设计,而是着重构造标签易于获取的辅助任务,并通过辅助任务的训练丰富模型的学习信号,从而提升了目标任务的性能。
3.2 基于生成的任务型对话系统
基于生成的对话系统如下图所示。其基本思想是通过编码器对对话上下文进行编码,然后利用解码器解码出合适的回复。和基于检索的模型类似,基于生成的方法最早应用在了聊天机器人的设计当中 [46]。
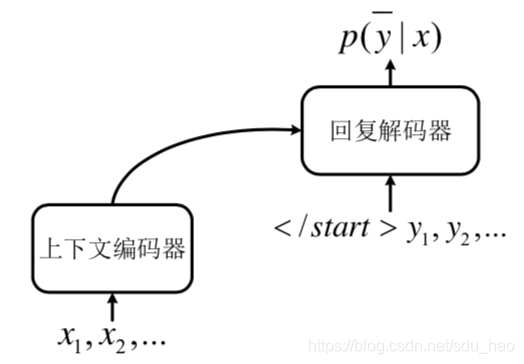
Wen 等 [1]借鉴了生成式聊天机器人的设计方法,设计了第一个基于生成式模型的任务型对话系统。该系统由四个网络组成。第一个网络是意图识别网络。意图识别网络首先对用户输入进行编码,然后预测用户当前的意图是哪一 个。从结构上来说,意图识别网络对应着语言理解模块。第二个网络是信念状态追踪网络。信念状态追踪网络的作用是记录用户的对话状态,并根据对话状态在数据库中进行各种查表操作。因此,该网络实现了对话状态追踪的功能。第三个网络是策略网络。该网络的输入是前两个网络的输出以及数据库操作的结果,输出是对话策略的表征。值得注意的是,和基于管道的方法不同,此处策略网络的输出是一个稠密的向量而非一个离散的系统行为。第四个网络是基于 LSTM 的句子解码器。该网络首先利用策略网络的输出进行状态初始化,然后通过注意力机制(attention mechanism)关注上下文中重要的单词信息,同时在每个解码时间步预测出一个单词,直到预测出结束符为止。因此,解码器可以被视作语言生成模块。
生成式模型和数据库交互的问题 自从 Wen 等 [1]提出了生成式的任务型对话模型后,学术界便针对其不足进行了改进。在 Wen 等 [1]提出的模型当中,数据库相关的查询操作是离散操作。这会破坏模型端到端可微分的特性。为了使数据库相关的操作具备可微分的特性,Dhingra 等 [47]提出了知识库的软查找方法。此外,在语言生成过程中,Wen 等 [1]提出的解码器难以有效地解码出数据库中的信息。因此,Eric 和 Manning [48]提出使用指针网络直接从数据库中拷贝出相应的条目作为解码器的输出。类似地,Madotto 等 [49]还利用记忆网络 [41, 42] 对对话历史以及数据库中的信息进行编码。在解码阶段,模型会通过门控单元决定每个时刻的解码信息来源于词表还是记忆部件。该方法有效地缓解了词表规模不足所带来的问题。但是,在解码数据库中的内容时,模型可能会利用不相关的两个条目。这将导致解码出的实体信息不一致。为了约束解码器对数据库相关内容的解码,Qin 等 [50]提出了实体一致网络。该方法有效地提升了解码过程的实体一致性。上述方法均使得生成式的任务型对话系统能够有效地和数据库进行交互,并正确地解码出数据库中的实体信息。
生成式模型的简化 Wen 等 [1]提出的模型会对针对每个语义槽分别使用一 个 LSTM 进行对话状态的追踪。这会让对话模型的结构变得相当复杂。针对该 问题,Lei 等 [51]提出了一种简化的序列到序列的对话模型。其核心思想是对上 下文编码后分两步进行解码。第一个解码过程对应着对话状态追踪,即根据上下 文解码出每个语义槽的对话状态。第二个解码过程对应着语言生成过程,即根据 上下文以及前一步解码出的对话状态解码出系统回复。此外,模型还采用注意 力机制拷贝输入端的信息,使解码器在解码时能够直接解码出编码器中的内容。 Lei 等 [51]提出的两阶段解码模型使生成式任务型对话系统无需专门的对话状 态追踪模块,因此有效地简化了模型的结构。
生成式模型回复多样性的问题 Li等[52]指出,基于生成式模型的聊天机器 人偏向于生成缺乏实际意义的回复,即“好的”等万能回复。类似地,Wen 等 [53]发现基于生成式模型的任务型对话系统解码出的句子句式过于单一。因此, Wen 等 [53]使用离散的隐变量(latent variable)建模用户意图的多样性,并采用 变分推断(variational inference)[54–56] 方法学习隐变量,最终使得模型的回复形式更加丰富。
基于强化学习的生成式模型 基于生成式的任务型对话系统一般采用有监督的方法训练。但仅仅通过有监督的方法训练模型会使得对话智能体无法学到语料中不存在的对话策略。因此,Lewis 等 [57]首先利用收集到的对话语料对智能体进行有监督的训练,然后再基于强化学习进一步优化智能体的对话策略。在强化学习的优化过程中,Lewis 等 [57]首先采用蒙特卡洛估计法估计智能体解码出某一句话后得到的期望累计奖励,然后利用策略梯度算法更新解码器的模型参数。强化学习使智能体能够在试错中学习语料中不存在的对话策略,因此提高了策略的丰富程度。但是,使用强化学习优化对话策略时,智能体所需探索的行为空间是整个解码空间。这会导致生成的句子不通顺和模型难以收敛等问题。针对该问题,Zhao 等 [58]提出使用隐变量表示当前智能体的对话策略。在进行强化学习优化时,模型只优化该隐变量,而不优化句子生成过程。这种方法减小 了智能体的行为空间,提升了优化效率,也使得生成出的回复更加流畅。
4. 任务型对话语料收集
通过人机交互收集对话语料 在早期的研究中,研究人员通过记录用户和系统的对话过程收集对话语料。比较著名的例子是 Sun 等 [59]提出的对话状态追踪评测数据集DSTC2。该语料是用户利用剑桥大学口语对话系统 [60] 完成餐厅预订任务的对话数据。和这项工作类似的还有 Williams 等 [4]提出的客服数据集。该数据是微软的自动客服系统协助用户排除电脑错误的交互日志。
通过人机交互收集对话语料的方式较为简单,且能够在系统上线后以较低 的成本收集大规模的对话数据。但是,所收集到的数据中系统方的对话策略较为 单一。此外,在语音识别和语言理解存在较高错误率时,系统不一定能够成功地完成任务。因此,使用这种方法收集到的数据质量偏低。
通过人人交互收集对话语料 为了提升数据的质量,Wen 等 [1]和 Peskov 等 [61]使用了 Wizard-of-Oz 方法 [62] 收集对话数据。具体而言,在构造对话数据之前,数据收集者会提供某一明确的对话任务,例如“寻找中关村附近的川菜店 并询问餐厅的人均消费”。然后,数据收集者会雇佣两位人员。其中一位扮演用户同系统进行交互;另一位扮演系统编写合理的回复辅助用户完成雇主提供的任务。在对话过程中,数据收集者还会要求系统方的雇佣者标注用户每一轮的对话意图和对话状态。
和人机交互数据相比,利用这种方法收集到的数据质量更高。但是,Wizard-of-Oz 方法的缺点是对人工的依赖程度高。在构造大规模对话数据集时,这种方法的成本相当高。为了减少成本,Byrne 等 [63]要求一个雇佣者同时扮演用户和系统,然后通过自我交互收集对话数据。
基于规则生成对话语料 除了上述数据收集方法之外,还有工作尝试基于规则构造对话数据。较为典型的例子是 Bordes 等 [2]提出的仿真数据集bAbI。这种方法要求研究人员编写对话脚本,并依据对话规则组合多个对话脚本,最终生成一个完整的对话。
基于规则的对话语料收集方法依赖开发者手工编写对话脚本和对话规则。当规则构造得不合理时,所生成的语料质量也不高。但是这种方法具有较好的可解释性。在对话数据难以获取时,利用这种方法构造数据不失为一种好的选择。
5. 用户仿真技术
使用强化学习训练任务型对话系统时需要雇佣用户同系统进行交互并要求用户对系统的表现进行评估。然而在实际的应用中,雇佣真实用户的成本较高,且数据获取周期长,因此不足以支持模型的快速迭代。针对该问题,研究人员提出了用户仿真器(user simulator),并用它代替真实用户同系统交互。
用户仿真器的设计目标有两个。首先是用户仿真器需要具备一个对话目标,并依据该对话目标产生合理且连贯的用户行为。其次是在交互结束后,用户仿真器需要对系统的表现给出定量的评分,以评估系统能否完成对话任务。一般而言,用户仿真器的设计方法可以分为基于规则的方法和基于模型学习的方法。
基于规则的用户仿真 基于规则的用户仿真器采用手工编写的规则模拟用户的行为。较为典型的工作是 Schatzmann 和 Young [64]以及 Schatzmann 等 [65]提出的基于议程的用户仿真器(agenda based user simulator)。该方法把用户的对话目标细化为一个个议程,并使用堆栈管理这些议程。仿真器对用户行为的模拟类似于一个出栈的过程。当用户表达了某一议程所代表的对话需求且系统能够合理地处理该需求时,仿真器对议程执行出栈操作。当栈中的议程全部被清空时, 系统便完成了对话任务。
基于规则的用户仿真方法的缺点是仿真用户的行为过于僵化,且规则的构建相当复杂。但是,基于规则的用户仿真技术具有很好的可解释性,且建模逻辑十分清晰,因此被广泛地应用在了实际系统的设计当中 [3, 66]。
基于模型学习的用户仿真基于模型学习方法的核心思想是从对话语料中学 习对话上下文到用户回复的映射。可以看出,基于模型的用户仿真器的构建和对话系统的构建本质上是相同的。因此,所有任务型对话系统的设计方法均可应用于基于模型的用户仿真的构建当中。比较典型的工作是基于生成的用户仿真模型 [67-69]。其基本思想是采用编码器编码对话上下文,然后使用解码器解码出用户的回复。此外,考虑到对话系统的设计与用户仿真器的设计属于镜像任务,Liu 和 Lane [70]分别采用两个 LSTM 建模对话系统的回复过程和用户仿真的回复过程,然后迭代地优化这两个网络。
基于模型学习的用户仿真的优点是可以从对话数据中自动地学习用户的对话行为。但是,通过这种方法训练得到的用户仿真器缺乏泛化性。在遇到语料中未出现的对话上下文时,用户仿真器的性能得不到保障。此外,这种方法对语料的规模和覆盖度要求较高。当语料获取较为困难时,这种方法并不适用。
6. 问题分析
任务型对话系统的设计手段逐渐从基于规则的方法发展到了数据驱动的方法。尤其是在最近的四年间,端到端任务型对话系统相关的研究取得了令人瞩目的成就。然而,目前工业界仍然严重地依赖基于规则的方法设计任务型对话系统,尤其是对话管理模块。其原因是多方面的。通过分析发现,现有的对话管理方法存在如下三方面的问题:
缺乏可维护性 在任务型对话系统的设计周期中,开发者会通过分析用户和系统的交互日志挖掘系统不能处理的问句,然后扩展系统使其能够处理新的用户行为。在扩展对话系统时,语言理解、对话管理和语言生成模块都需要进行相应的扩展。其中,在扩展基于强化学习的对话管理模块时,开发者需要根据新的本体结构重新设计对话管理模块的模型结构,然后构建新的用户仿真器或雇佣用户训练模型。然而,设计用户仿真的难度大,雇佣用户的花销高。这使得基于强化学习的对话管理模块难以维护。较差的可维护性正是基于强化学习的对话管理方法难以落地的原因之一。
缺乏在线学习能力 在设计数据驱动的任务型对话系统时,开发者需要收集人机交互数据。从相关工作中可以看出,收集对话数据的成本高,难度大。更重要的是,所收集到的对话数据难以覆盖某一对话任务所有的情形。因此,基于有偏数据训练得到的对话系统在遇到新的用户行为后会很容易地给出不合理的回复。此外,已有工作中的对话系统在部署后无法在线地学习如何处理新的用户需求。这也使得对话系统无法应对因业务变化而出现的用户需求。
缺乏知识建模能力 已有的对话管理方法主要针对解决槽填充任务。一般而言,解决槽填充任务的对话系统具备较为固定的对话逻辑,且无需利用世界知识同用户交互。如果对业务的流程有较为清晰的理解,基于规则的对话管理方法也 能取得不错的效果。但是在现实生活中,存在许多对话任务不具备和槽填充任务 类似的对话逻辑。在解决此类任务时,对话管理模块需要在交互过程中建模客观 知识,并依据知识制定交互策略。然而,已有的工作并没有探讨过对话管理中的知识建模方法。因此,缺乏知识建模能力无疑极大地限制了任务型对话系统的应用范围。