引入所需库
import osimport cv2
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from PIL import Image
MNIST数据集
下载MNIST数据集
mnist=tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train、y_train、x_test 和 y_test 是用于机器学习的数据集,具体说明如下:
- x_train:训练数据集的特征集,即包含多个训练样本的输入数据。对于 MNIST 数据集来说,x_train 是一个四维数组,形状为 (num_samples, height, width, num_channels),表示训练样本的图像数据。
- y_train:训练数据集的标签集,即包含多个训练样本的输出标签或类别信息。对于 MNIST 数据集来说,y_train 是一个一维数组,形状为 (num_samples,),其中每个元素代表相应训练样本的数字标签(0-9)。
- x_test:测试数据集的特征集,即包含多个测试样本的输入数据。与 x_train 类似,x_test 也是一个四维数组,形状为 (num_samples, height, width, num_channels),表示测试样本的图像数据。
- y_test:测试数据集的标签集,即包含多个测试样本的输出标签或类别信息。与 y_train 类似,y_test 是一个一维数组,形状为 (num_samples,),其中每个元素代表相应测试样本的数字标签。
这些数据集是经过预处理和分割的手写数字数据集(MNIST),通常用于机器学习中的图像分类任务。通过将模型训练在 x_train 和 y_train 上,然后在 x_test 上进行测试并与 y_test 进行比较,可以评估模型的性能和准确度。
查看各个变量的形状大小
print("训练数据集的特征集",x_train.imag.shape)
print("训练数据集的标签集",y_train.imag.shape)
print("测试数据集的特征集",x_test.imag.shape)
print("测试数据集的标签集",y_test.imag.shape)
训练数据集的特征集 (60000, 28, 28)
训练数据集的标签集 (60000,)
测试数据集的特征集 (10000, 28, 28)
测试数据集的标签集 (10000,)
将MNIST数据保存为图片
#设置保存路径
save_dir="./data/images/mnist"
#判断路径是否存在
if os.path.exists(save_dir) is False:os.makedirs(save_dir)
#设置画布大小
plt.figure(figsize=(20, 18))
#获取前二十张图片索引
indices = list(range(1, 21))
#绘制前二十张图片并且保存为图片文件
for i in indices:img = x_train[i].reshape((28, 28))#设置为四行五列plt.subplot(4, 5, i)plt.imshow(img, cmap='gray')#保存图片到本地plt.savefig(save_dir+'/image_{}.png'.format(i))#设置横轴标签plt.xlabel('image_{}.png'.format(i))plt.xticks([])plt.yticks([])
plt.show()

图象标签的独热表示
独热编码(One-Hot Encoding)是一种将分类变量转换为二进制向量的方法,其中每个类别都被表示为一个独立的二进制向量。在图象标签的独热表示中,每个标签都被视为一个独立的二进制向量,其中只有一个元素为1,其余元素为0。
例如,假设我们有三个类别:猫、狗和鸟。如果我们要对这些类别进行独热编码,那么每个类别都将被表示为一个长度为3的向量,其中第一个元素为1,其余元素为0。因此,独热编码后的向量可以表示为:
[1, 0, 0]
[0, 1, 0]
[0, 0, 1]
在这个例子中,第一个向量表示“猫”,第二个向量表示“狗”,第三个向量表示“鸟”。
使用TensorFlow识别MNIST
Softmax回归的原理
Softmax回归是一种用于多分类问题的回归方法。它的原理是将输出值变换成值为正且和为1的概率分布,从而得到每个类别的概率。这个概率可以看作是对每个类别的置信度,即该类别被预测为正类的概率。
在Softmax回归中,我们使用softmax函数来计算每个类别的概率。softmax函数的定义如下:
softmax ( x ) i = exp ( x i ) ∑ j = 1 n exp ( x j ) \text{softmax}(x)_i = \frac{\exp(x_i)}{\sum_{j=1}^n \exp(x_j)} softmax(x)i=∑j=1nexp(xj)exp(xi)
其中, x i x_i xi表示第i个输入特征, softmax ( x ) \text{softmax}(x) softmax(x)表示所有输入特征的softmax函数值。
Softmax回归的通俗解释
让我用一个通俗的例子结合公式来解释softmax。
假设你和两个朋友要一起去餐厅吃晚饭,并且有三个餐厅选项可供选择:餐厅A、餐厅B和餐厅C。为了决定去哪个餐厅,你们每个人对每个餐厅都进行评分,分数范围从1到10。
朋友A给餐厅A评分为7,对餐厅B评分为5,对餐厅C评分为3。
朋友B给餐厅A评分为8,对餐厅B评分为6,对餐厅C评分为4。
你给餐厅A评分为6,对餐厅B评分为4,对餐厅C评分为9。
现在,我们将使用softmax来计算每个餐厅被选中的概率。
首先,我们将每个朋友对每个餐厅的评分转化为指数化值。使用公式:
e^评分
根据公式,对于朋友A来说,餐厅A的指数化评分为e7,餐厅B的指数化评分为e5,餐厅C的指数化评分为e^3。同样地,我们可以计算朋友B和你对每个餐厅的指数化评分。
接下来,我们对每个餐厅的指数化评分求和。即将朋友A、朋友B和你对于每个餐厅的指数化评分进行相加。
然后,我们使用每个餐厅的指数化评分除以总和,得到每个餐厅被选中的概率。
例如,假设餐厅A的指数化评分之和为S,餐厅B的指数化评分之和为S2,餐厅C的指数化评分之和为S3:
餐厅A的选择概率 = S / (S + S2 + S3)
餐厅B的选择概率 = S2 / (S + S2 + S3)
餐厅C的选择概率 = S3 / (S + S2 + S3)
最终的结果就是每个餐厅被选中的概率。这样,你们可以依据每个餐厅的概率来做出最终的决定。
请注意,上述例子中的具体数字仅用于解释softmax的思想和过程,并不代表真实的计算结果。
Softmax的使用场景
Softmax函数通常在机器学习和深度学习中应用广泛。以下是一些常见的使用场景:
- 多分类问题:Softmax函数可以将多个输入值转化为表示各个类别概率的输出,适用于多类别分类任务。例如,图像分类中将图像分为不同的类别。
- 神经网络输出层:在神经网络的最后一层,Softmax函数常用于将神经元的输出转化为表示各个类别概率的形式。这样可以方便地对输入进行分类预测。
- 概率预测:由于Softmax函数输出的是概率分布,因此可以用于各种需要从给定选项中选择最可能的选项的任务。例如,语言模型中的下一个单词预测、机器翻译中的词汇选择等。
- 强化学习中的动作选择:在强化学习中,Softmax函数可用于基于动作价值估计来选择下一步的动作。将每个动作的估计值经过Softmax函数转化为选择概率,从而根据概率选择行动。
总之,Softmax函数在需要将一系列输入值转化为表示概率分布的输出时非常有用,特别适用于多分类问题和概率预测任务。
Softmax 函数进行 MNIST 数据集的多分类
导入库和数据集:
import tensorflow as tf
from tensorflow.keras.datasets import mnist# 加载 MNIST 数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
数据预处理:
# 将像素值归一化到 0-1 范围内
train_images = train_images / 255.0
test_images = test_images / 255.0# 将标签转换为独热编码形式
train_labels = tf.keras.utils.to_categorical(train_labels, num_classes=10)
test_labels = tf.keras.utils.to_categorical(test_labels, num_classes=10)
构建模型:
# 定义模型结构
model = tf.keras.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
训练模型:
# 模型训练
model.fit(train_images, train_labels, epochs=5, batch_size=32)
Epoch 1/5
1875/1875 [==============================] - 7s 3ms/step - loss: 0.2555 - accuracy: 0.9265
Epoch 2/5
1875/1875 [==============================] - 9s 5ms/step - loss: 0.1127 - accuracy: 0.9665
Epoch 3/5
1875/1875 [==============================] - 10s 5ms/step - loss: 0.0777 - accuracy: 0.9763
Epoch 4/5
1875/1875 [==============================] - 9s 5ms/step - loss: 0.0589 - accuracy: 0.9821
Epoch 5/5
1875/1875 [==============================] - 9s 5ms/step - loss: 0.0452 - accuracy: 0.9857<keras.callbacks.History at 0x2a9800b7550>
评估模型:
# 在测试集上评估模型性能
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
313/313 [==============================] - 2s 5ms/step - loss: 0.0758 - accuracy: 0.9763
Test accuracy: 0.9763000011444092
进行预测:
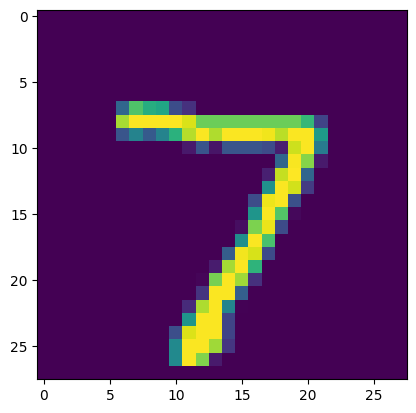
#先展示第一种图片作为辅助验证
plt.imshow(test_images[0])
plt.show()
# 对测试集进行预测
predictions = model.predict(test_images)
# 打印第一张图像的预测结果
print('Predicted label:', tf.argmax(predictions[0]))
# 获取最大值的索引
max_index = tf.argmax(predictions[0])
# 将索引转换为列表
result_list = max_index.numpy().tolist()
print(result_list)
Predicted label: tf.Tensor(7, shape=(), dtype=int64)
7
五层卷积+训练图象
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()# 将像素值缩放到0-1之间
x_train, x_test = x_train / 255.0, x_test / 255.0# 将标签转换为One-hot编码
y_train = tf.one_hot(y_train, depth=10)
y_test = tf.one_hot(y_test, depth=10)# 构建模型
model = tf.keras.models.Sequential([tf.keras.layers.Reshape((28, 28, 1), input_shape=(28, 28)),tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu'),tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'),tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),tf.keras.layers.Conv2D(filters=128, kernel_size=(3, 3), activation='relu'),tf.keras.layers.Flatten(),tf.keras.layers.Dense(256, activation='relu'),tf.keras.layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])# 训练模型
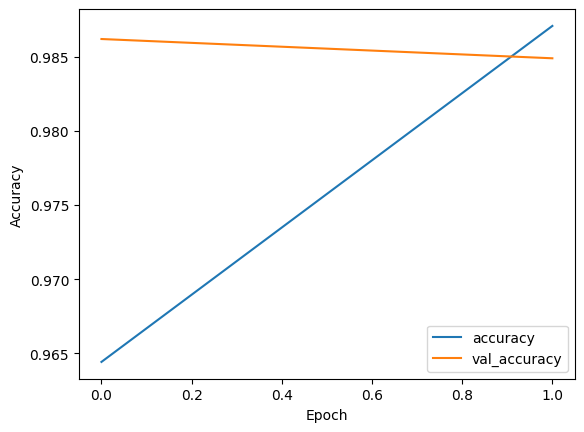
history = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=2)
Epoch 1/2
1875/1875 [==============================] - 21s 10ms/step - loss: 0.1172 - accuracy: 0.9644 - val_loss: 0.0400 - val_accuracy: 0.9862
Epoch 2/2
1875/1875 [==============================] - 19s 10ms/step - loss: 0.0419 - accuracy: 0.9871 - val_loss: 0.0476 - val_accuracy: 0.9849
# 绘制训练和验证的准确率曲线
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# 随机选择一张测试图像进行预测
index = np.random.randint(0, len(x_test))
image = x_test[index]
label = y_test[index]# 进行预测
pred = model.predict(np.expand_dims(image, axis=0))[0]
pred_label = np.argmax(pred)
# 进行预测
pred = model.predict(np.expand_dims(image, axis=0))[0]
pred_label = np.argmax(pred)# 显示图像和预测结果
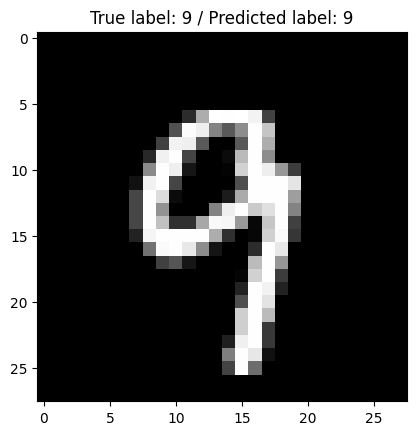
plt.imshow(image, cmap='gray')
plt.title('True label: {} / Predicted label: {}'.format(np.argmax(label), pred_label))
plt.show()