1. Spark的shuffle阶段发生在阶段划分时,也就是宽依赖算子时。
宽依赖算子不一定发生shuffle。
2. Spark的shuffle分两个阶段,一个使Shuffle Write阶段,一个使Shuffle read阶段。
3. Shuffle Write阶段会选择分区器,比如HashPartitioner,RangePartitioner,或者使自定义分区器
也会根据一些条件,来选择到底使用哪一个Writer对象
unsafeshuffleWriter
sortShuffleWriter: 预排序,默认的
bypassMergeShuffleWriter:不排序,<=200,不预聚合
4. 将RDD的一个分区的数据先按照分区器来划分不同的分区(分区数量由分区器来决定)
5. 如果是默认的sortShuffle,则会预排序,然后写入buffer中
6. 当buffer达到阈值时,或者是最后一次时,会溢写成临时文件
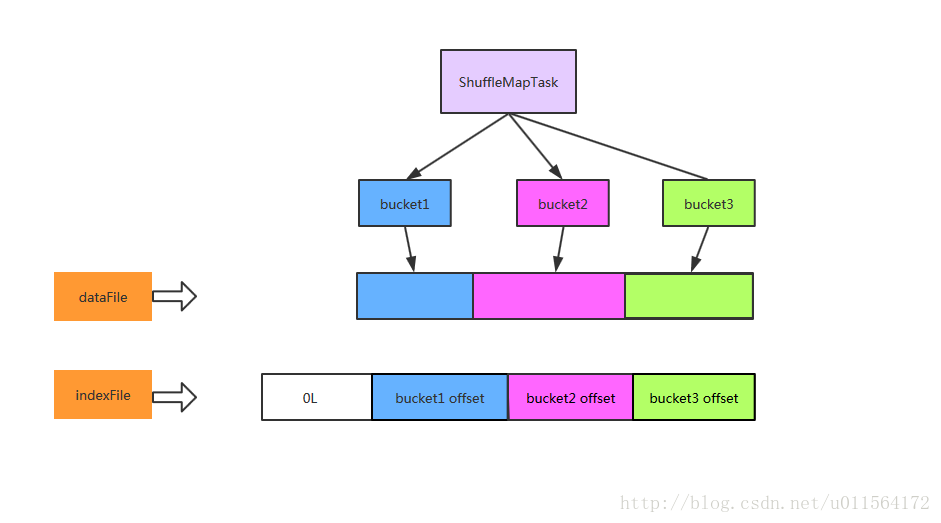
7. 如果产生多个临时文件,则会merge成一个临时文件,一个分区对应一个临时文件
8. 多个分区的临时文件最终会合并成一个临时文件,同时会保存这个文件的索引信息到索引文件里,比如一个分区的偏移量,数据的长度等,到此位置,Shuffle Write阶段结束
9. 下游的RDD的每一个分区对应一个Task,并提供了读buffer,然后开始从各个executor处读取属于自己分区的数据到buffer中,因为可能来自多个executor处,所以会涉及到合并
注意:排序时,使用的是归并算法,字典升序排序规则