pytorch神经网络及训练(一)
随机梯度下降算法
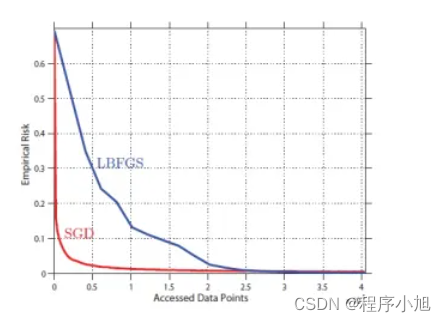
随机梯度下降算法(SGD)是对梯度下降算法的一种改进。
直观上SG的方法可能效率上更优。考虑这样一个情况,我们的训练数据集合 是由小的数据 集合复制10份得到的。此时,对样本做batch训练,是对样本 做batch训练计算复杂度的10倍,效果却是一样的。与之相对,SGD的方法在 中随机抽取样本的概率和在中的概率是相同的。在实际上虽然没有这种,样本完全是复制的情况,但是真实的样本却是经常有大量冗余的情况,此时SGD的效率更高。
实际效果(Practical Motivation)
pytorch中的优化器
在pytorch中的optim模块,提供了多种可以直接使用的深度学习的优化器,包括了Adam、SGD、RMSprop等可以直接进行调用
| 类 | 算法名称 |
|---|---|
| torch.optim.Adam | Adam算法 |
| torch.optim.SGD | SGD算法 |
| torch.optim.RMSprop | RMSprop算法 |
以Adam算法为例介绍优化器中参数的使用情况
torch.optim.Adam(params,lr=0.001,betas(0.9,0.999),eps=le-08,weight_decay=0)
参数说明如下
- param:待优化的iterable或定义了参数的dict
- lr:算法学习率
- betas:用于计梯度和梯度平方的系数
- eps:增加数值稳定性的项
- weight_decay权重衰减
pytorch中的损失函数
深度学习的优化算法可以直接作用的对象是损失函数,损失函数就是用来表示预测与实际数据之间的差异程度
pytorch中的nn模块提供了多种可以之间使用的深度学习损失函数——常用的有均方误差损失和交叉熵误差损失
pytorch中常见的损失函数(部分)
| 类 | 算法名称 | 适用问题类型 |
|---|---|---|
| torch.nn.L1Loss | 平均绝对值误差损失 | 回归 |
| torch.nn.MSELoss | 均方误差损失 | 回归 |
| torch.nn.CrossEntropyLoss | 交叉熵误差损失 | 多分类 |
交叉熵损失
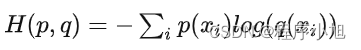
过拟合与防止过拟合
过拟合的简单概念:深度学习模型,在训练数据集上能够获得很高的识别精度(针对分类)或者很低的均方误差(针对回归)但是把训练模型应用到测试集时结果不是很理想
防止过拟合的几种简单方法
- 增加数据量
- 合理的数据切分
- 正则化方法
- Dropout
- 提前结束训练
网络参数初始化
nn模块下面的init模块下有常用的参数初始化类,包括了均匀分布和正态分布等
参数初始化方法应用示例:
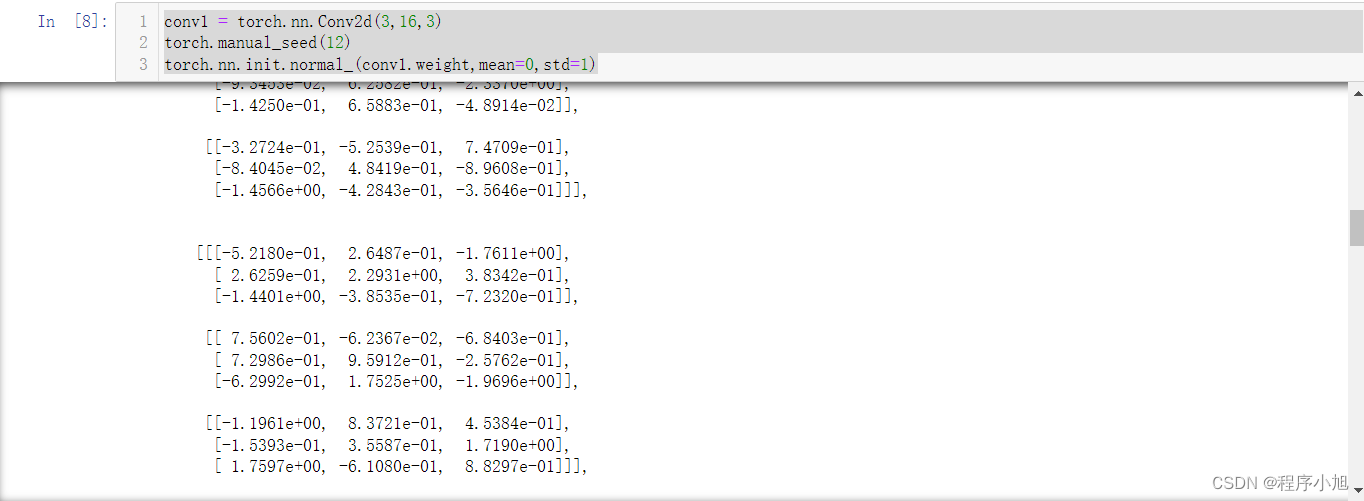
conv1.weight可以获取conv1卷积层的初始化权重参数,torch.manual_seed(12)定义随机数初始化,便于torch.nn.init.normal()生成的随机数重复使用
- conv1.weight:表示随机数用来替换张量的原始数据
- mean=0 表示均值为0
- std=1 表示标准差为1
conv1 = torch.nn.Conv2d(3,16,3)
torch.manual_seed(12)
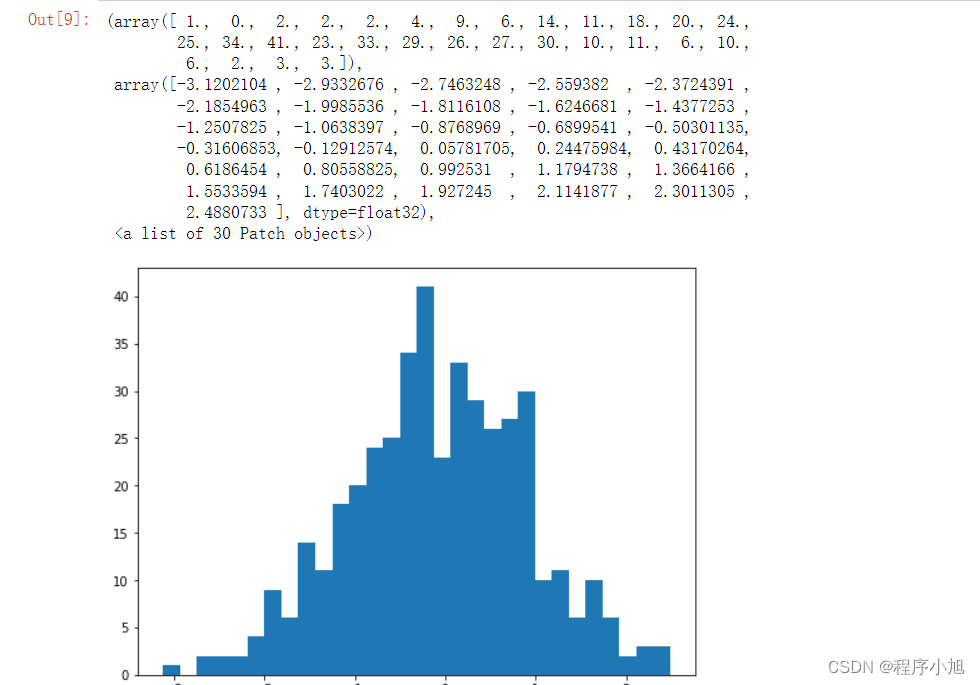
torch.nn.init.normal_(conv1.weight,mean=0,std=1)plt.figure(figsize=(8,6))
plt.hist(conv1.weight.data.numpy().reshape((-1,1)),bins= 30)