对比用request抓取而言,使用selenium库会更简便抓取
话不多说现在开始:
首先我们要配置一下chromedriver:
1、chromedirver 下载网站![]() https://registry.npmmirror.com/binary.html?path=chromedriver/下载与自己对应的谷歌版本
https://registry.npmmirror.com/binary.html?path=chromedriver/下载与自己对应的谷歌版本
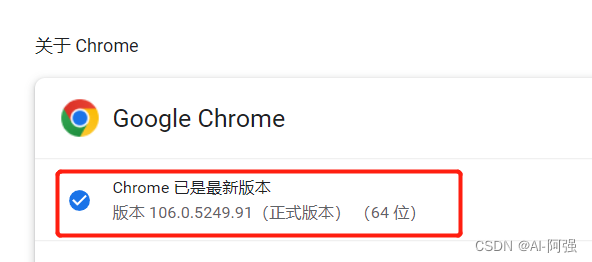
查看谷歌版本 如我自己的是106.0.5249.91 实际只需要看到106.0.5249即可
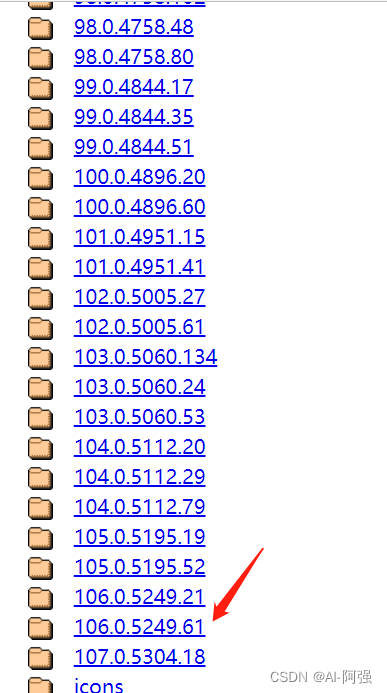
2、下载好后 找到自己对应的python环境 将刚下载好的 托到python环境的文件夹里面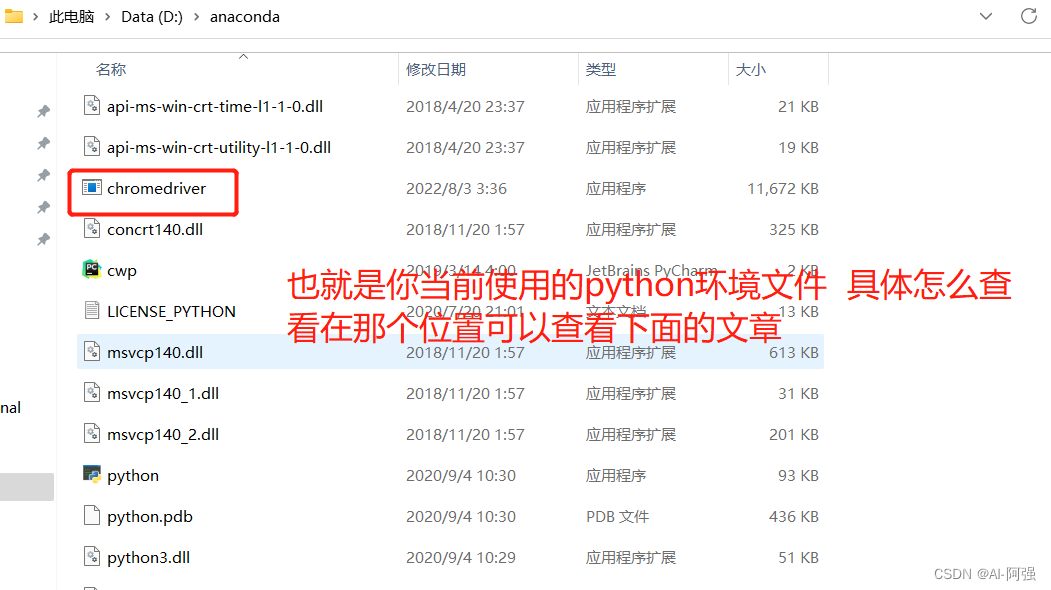
查看pycharm当前使用python环境位置(不清楚看下面环境配置)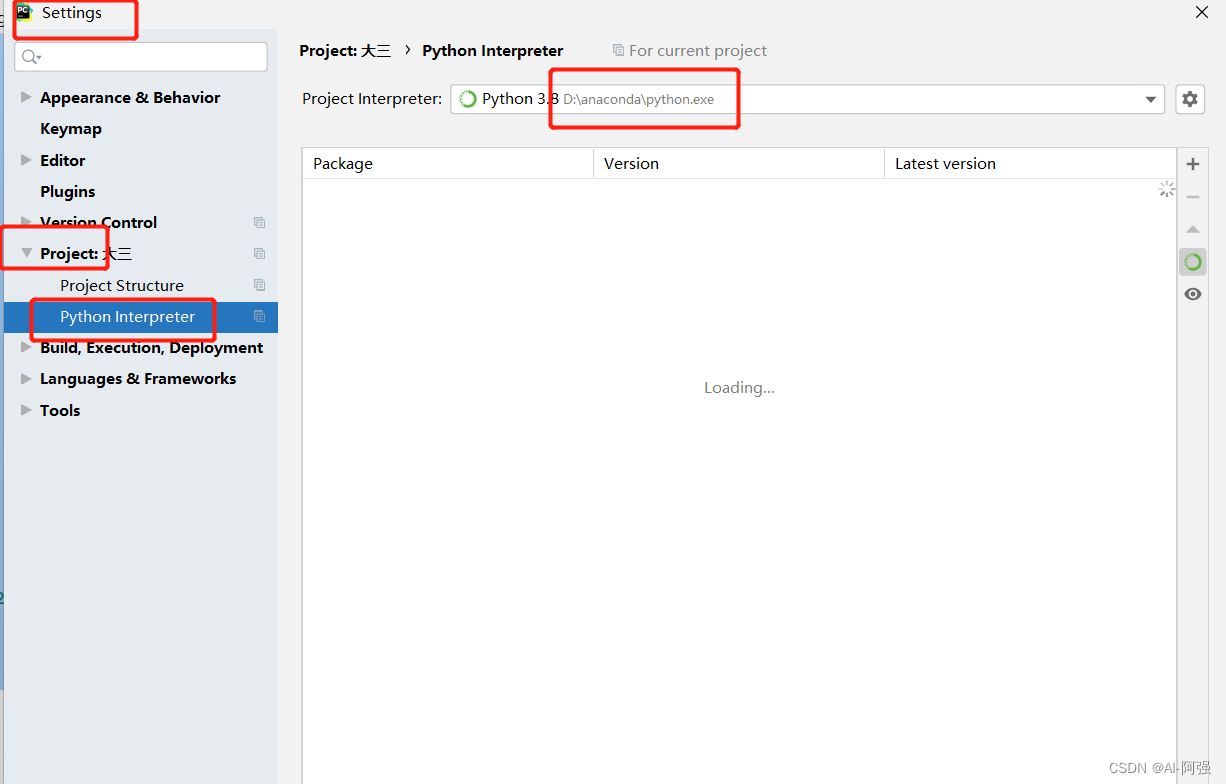
https://blog.csdn.net/weixin_52486467/article/details/126121666![]() https://blog.csdn.net/weixin_52486467/article/details/126121666
https://blog.csdn.net/weixin_52486467/article/details/126121666
就此便配置好浏览器的自动化程序
下面是全代码 比用request简洁
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import urllib.parsedef start_down_laod():i =0while i<300:driver.find_element(By.XPATH,'//*[@id="toolbar"]/span[7]').click() #点击下载driver.find_element(By.XPATH,'//*[@id="container"]/span[2]').click() #点击下一页i+=1time.sleep(3) #静默时间 if __name__ == '__main__':name = input('输入花卉名:')name_url = urllib.parse.quote(name) #将中文转url编码url ='https://image.baidu.com/search/detail?ct=503316480&z=0&ipn=d&word={}&step_word=&hs=0&pn=0&spn=0&di=7146857200093233153&pi=0&rn=1&tn=baiduimagedetail&is=0%2C0&istype=2&ie=utf-8&oe=utf-8&in=&cl=2&lm=-1&st=-1&cs=1424606054%2C4059693723&os=983658436%2C1733260201&simid=4181941755%2C737821062&adpicid=0&lpn=0&ln=1756&fr=&fmq=1664773991321_R&fm=result&ic=&s=undefined&hd=&latest=©right=&se=&sme=&tab=0&width=&height=&face=undefined&ist=&jit=&cg=&bdtype=0&oriquery=&objurl=https%3A%2F%2Fgimg2.baidu.com%2Fimage_search%2Fsrc%3Dhttp%3A%2F%2Fimg.photo.163.com%2FnuKA8_4iodXLyRjIQs4Uzg%3D%3D%2F1874341869916410374.jpg%26refer%3Dhttp%3A%2F%2Fimg.photo.163.com%26app%3D2002%26size%3Df9999%2C10000%26q%3Da80%26n%3D0%26g%3D0n%26fmt%3Dauto%3Fsec%3D1667370752%26t%3Df2db11aacbeaaad5969db9797471c474&fromurl=ippr_z2C%24qAzdH3FAzdH3Fks52_z%26e3B8mn_z%26e3Bv54AzdH3Fzyv1xx_caAzdH3Fks52AzdH3FfpwptvAzdH3Fd08dm9a8bda80dd8l98dd0lAzdH3F&gsm=1e0000000000001e&rpstart=0&rpnum=0&islist=&querylist=&nojc=undefined&dyTabStr=MCwzLDYsMiwxLDQsNSw3LDgsOQ%3D%3D'.format(name_url)driver = webdriver.Chrome() #实例化一个浏览器driver.maximize_window() #浏览器最大化driver.get(url) #打开网页start_down_laod() #调用图片下载函数


