前言
容器的网络是一大难点,不管是docker 还是kubernetes 都绕不开计算机网络。以下的介绍主要以计算机网络的namespace 和bridge 两个方面来展开介绍,方便深入理解容器的网络原理。
1.namespace分析
linux 支持六种资源的namespace :mount ns 、UTS ns 、IPC ns 、PID ns、Network ns 、User ns
为了让每一个进程从属于某一个namespace ,linux 内核为描述符增加了一个struct nsproxy 结构。
struct task_struct {.../* namespaces */struct nsproxy *nsproxy;...
}struct nsproxy {atomic_t count;struct uts_namespace *uts_ns;struct ipc_namespace *ipc_ns;struct mnt_namespace *mnt_ns;struct pid_namespace *pid_ns;struct user_namespace *user_ns;struct net *net_ns;
};
从上面的结构体可以看出,Linux 为每一种不同类型的资源定义了不同的命名空间的结构体进行管理。这里结构体就是上面说到的六种namespace。
这里主要以pid_namespace 为例来介绍:
首先看下pid_namespace 的结构体
struct pid_namespace {struct kref kref; //成员是一个引用计数器,用于记录引用这个结构的进程数struct pidmap pidmap[PIDMAP_ENTRIES];//成员用于快速找到可用pid的位图int last_pid;//成员是记录最后一个可用的pidstruct task_struct *child_reaper; struct kmem_cache *pid_cachep;unsigned int level;// 成员记录当前 pid命名空间 所在的层次struct pid_namespace *parent;//成员记录当前 pid命名空间 的父命名空间
#ifdef CONFIG_PROC_FSstruct vfsmount *proc_mnt;
#endif
};
由于PID 命名空间是分层的,也就是说新创建一个pid命名空间时会记录父级pid 命名空间到
parent 字段中,所以随着pid 命名空间的创建,在内核中会形成一颗pid 命名空间的树。
-
成员记录当前
pid命名空间的父命名空间。pid 初始化的是在level0 这一层。在这个命名空间树中,低层的pid 对高层的pid 命名空间进程不可见。 -
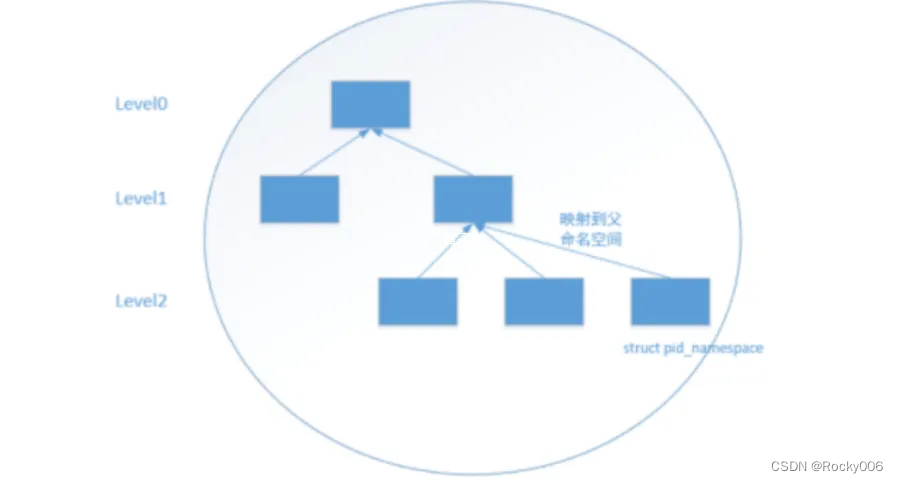
从level0 到 levelN 是如何保存这些进程ID 信息的。在解析完子进程pid 后,如何将信息保存在task_struct 中,看看PID相关代码,有两处保存进程ID 信息相关:
p->pid = pid_nr(pid); //获取global pid_ns中的pid,即第0层… …
init_task_pid(p, PIDTYPE_PID, pid); //将struct pid 结构地址保存到进程描述符中
首先task_struct->pid中存的是global pid namespace中的PID value,因为对于内核来说,它只需要看全局的pid namespace即可(init进程),里面包含系统全局进程的global PID。微信搜索公众号:信安黑客技术,回复:黑客 领取资料 。
在linux 中并不区分进程和线程,都是同task_struct 抽象,只不过支持多线程的进行是由一组task_struct 来抽象的。
接下来看看系统调用clone() ,传入以上 不同类型的参数实现复制不同的ns 。这里以clone_newpid 参数为例。实际是复制pid 命名空间,在新的pid 命名空间里可以使用与其他pid 命名空间相同的pid
#define _GNU_SOURCE
#include <sched.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <signal.h>
#include <stdlib.h>
#include <errno.h>char child_stack[5000];int child(void* arg)
{printf("Child - %d\n", getpid());return 1;
}int main()
{printf("Parent - fork child\n");int pid = clone(child, child_stack+5000, CLONE_NEWPID, NULL);if (pid == -1) {perror("clone:");exit(1);}waitpid(pid, NULL, 0);printf("Parent - child(%d) exit\n", pid);return 0;
}
输入如下:
Parent - fork child
Parent - child(9054) exit
Child - 1
从运行结果来看,在子进程的PID命名空间里,当前进程的PID为1,但在父进程的pid 命名空间中子进程的pid 却是9045。
2.birdge
从上文中可以看到namespace 隔离了内核资源,让一些进程只能看到与自己相关的一部分资源。进程与进程之间没办法通信。但是Linux 之间需要两个或者两个以上的ns 链接。这个时候就需要veth pair 和bridge 出场了,veth pair 在这里不着重介绍,以bridge 为主来展开。
docker 中也用到了namespace 做隔离,但是docker 的隔离只是部分资源隔离,docker 的网络模式也有bridge。
2.1 网桥的实际应用
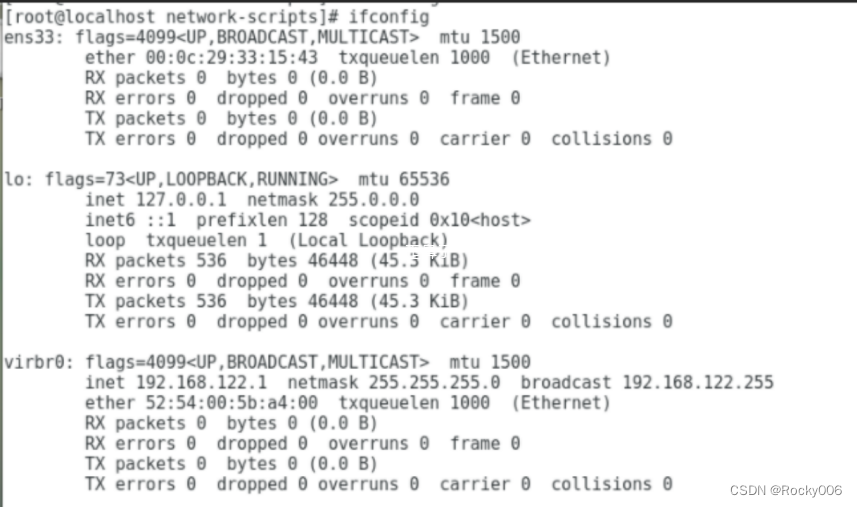
关于网桥配置ip 地址,首先先看看我自己的本机的网桥ip地址,再来看看有什么作用。
可以看到两个网桥都配置了对应的ip 地址,但是其实网桥不用配置ip的,给网桥配制ip地址,是为了方便网桥所在的主机和网桥所桥接的网卡(包括虚拟网卡)进行通信。一般情况下会配成 同一网段的ip .但是其对应的虚拟机(容器)可以配制ip地址,如果和网桥的ip是同一个网段的话,网桥所在的物理主机和这个网桥上桥接的网卡所对应的虚拟主机就可以进行通信了(能够ping通。那一下例子,我在本机ping 不同虚拟机的地址,是因为不在同一网段内。我自己本机的地址是192.168.138... 虚拟机的ip 地址是
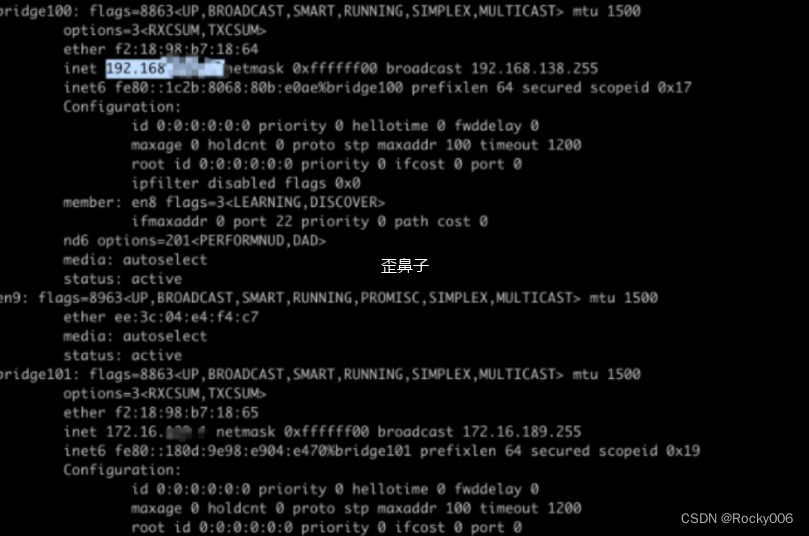
而在虚拟集中我自己的IP地址是192.168.122.. 不在同一网段内,所以造成了无法通信的情况。
2.2 网桥的工作原理
网桥是以混杂的模式工作的,混杂模式简称Promisc mode,即监听模式,常被用来诊断网络问题,混杂模式是指一个网卡会把它接受的所有的网络流量都交给cpu,而不是只想把它转交的部分交给cpu。每个桥维护了一个基于MAC地址的过滤数据库,网桥根据这个数据库,把收到的帧往相应的局域网(端口)进行转发。在过滤数据库中,列出了每个可能的目的地(目的MAC地址),以及它属于哪一条输出线路(一个端口号,即表示转发给哪个LAN),每个表项还有一个超时设置。通过下图网桥的实际作用来看网桥时候如何工作的。
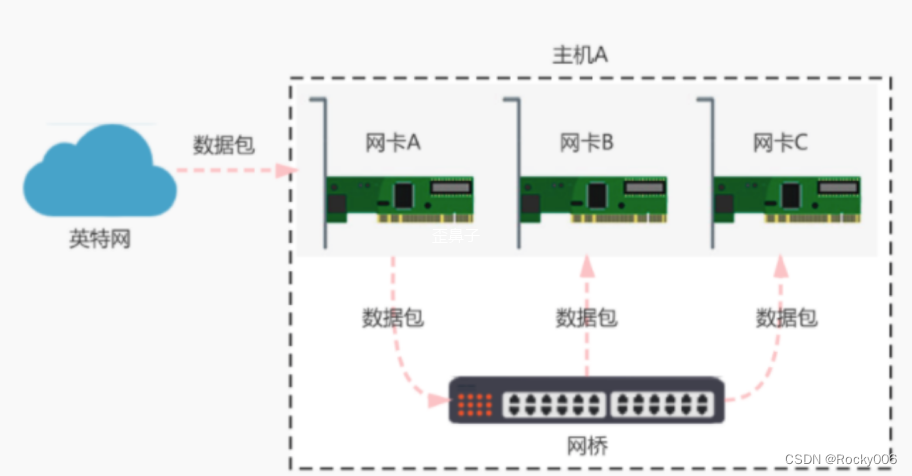
如上图所示,当网络接口A接收到数据包后,网桥 会将数据包复制并且发送给连接到 网桥 的其他网络接口(如上图中的网卡B和网卡C)。通过上图可以将网桥总结为以下几点:
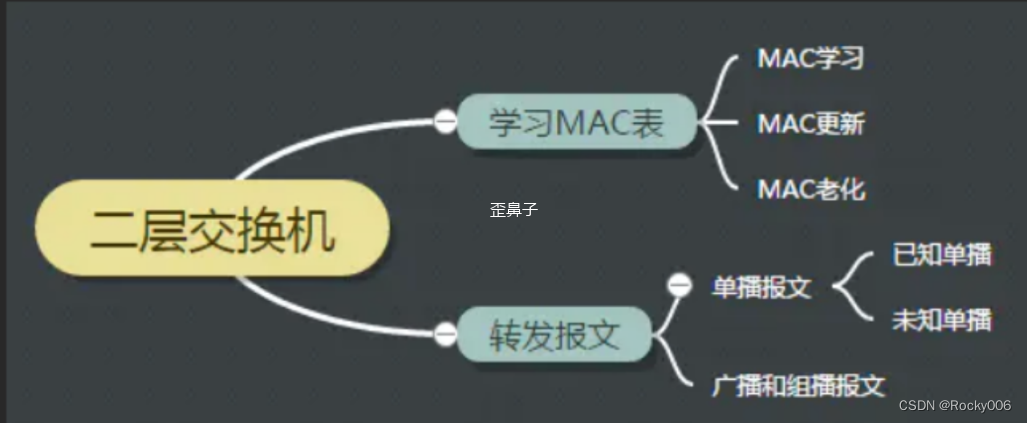
收到一个报文后,根据报文的目的MAC,选择适当的端口进行转发。对于不同的报文,起转发流程略有差异:
a. 已知单播 - 单播:对于单播报文,如果知道目的地址在哪个端口(MAC表中能找到该目的MAC),就从该端口转发出去
b. 未知单播 - 泛洪:对于单播报文,如果暂时还不知道目的地址是哪个端口,则从所有非源端口泛洪出去
c. 组播广播 - 泛洪:对于广播和组播,也需要泛洪。
网桥的这种工作方式,是为了尽可能小的代价保证报文能最终到达它的目的地。
3.3 通过命令行来看看网桥实现
增加网桥
[root@controller]# brctl addbr br0
查看网桥
[root@controller]# brctl show
bridge name bridge id STP enabled interfaces
br0 8000.000000000000 no
docker0 8000.000000000000 no
这里回到内核源码来看看创建网桥源码:
int br_add_bridge(char *name)
{struct net_bridge *br;if ((br = new_nb(name)) == NULL) // 创建一个网桥设备对象return -ENOMEM;if (__dev_get_by_name(name) != NULL) { // 设备名是否已经注册过?kfree(br);return -EEXIST; // 返回错误, 不能重复注册相同名字的设备}// 添加到网桥列表中br->next = bridge_list;bridge_list = br;...register_netdev(&br->dev); // 把网桥注册到网络设备中return 0;
}
上述代码清晰的显示了,网桥到网络设备的注册
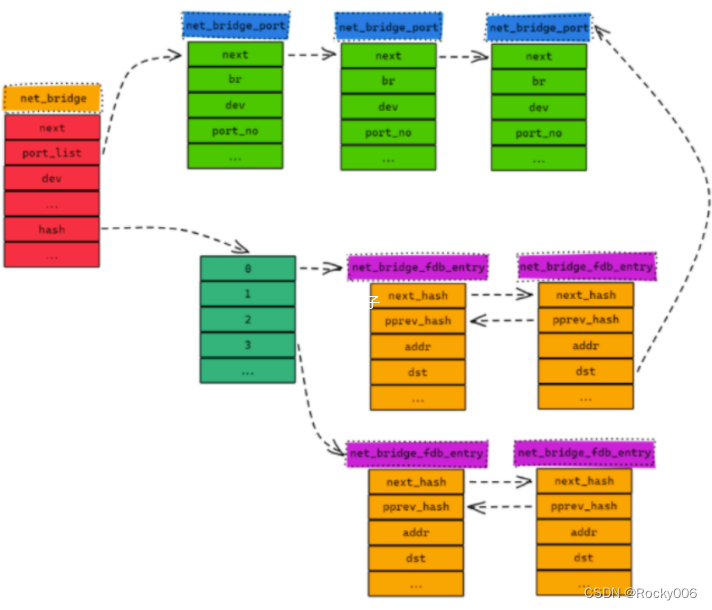
再看看net_bridge 的数据结构
struct net_bridge
{struct net_bridge *next; // 连接内核中所有的网桥对象rwlock_t lock; // 锁struct net_bridge_port *port_list; // 网桥端口列表struct net_device dev; // 网桥设备信息struct net_device_stats statistics; // 信息统计rwlock_t hash_lock; // 用于锁定CAM表struct net_bridge_fdb_entry *hash[BR_HASH_SIZE]; // CAM表struct timer_list tick;/* STP */...
};
网桥中比较重要的两个字段是:port_list、hash[BR_HASH_SIZE](保存着以网络接口 MAC地址 为键值,以网桥端口为值的哈希表)
网桥端口列表的数据结构:
struct net_bridge_port
{struct net_bridge_port *next; // 指向下一个端口struct net_bridge *br; // 所属网桥设备对象struct net_device *dev; // 网络接口设备对象int port_no; // 端口号/* STP */...
};
net_bridge_fdb_entry 数据结构主要用于描述网络接口设备MAC 地址与网桥端口的对应关系:
struct net_bridge_fdb_entry
{struct net_bridge_fdb_entry *next_hash;struct net_bridge_fdb_entry **pprev_hash;atomic_t use_count;mac_addr addr; // 网络接口设备MAC地址struct net_bridge_port *dst; // 网桥端口...
};
以上三个结构,我在搜索的过程中,一张图很好的展示了三者的关系
可见,要将 网络接口设备 绑定到一个 网桥 上,需要使用 net_bridge_port 结构来关联的。
小结
总的来说,不管是以上介绍的namespace 还是网桥,都是计算机网络的鼻祖,从docker 的网络连接方式到kubenetes的网络方式,其底层的技术原理都与之有关。理解了namespace 和网桥的连接,后续理解docker 、kubernetes网络会更加简单。
欢迎转发点赞收藏评论,感谢🙏
-End-