爬虫1000+个C程序
问题场景
由于实验需要,我需要1000+个elf文件,可是网络可获取的elf文件较少,c程序较多,所以首先下载c程序,之后gcc编译链接生成elf文件。我需要的C源码不是项目级别的,正常100行左右就可以的!
爬取c程序
一开始,我的爬虫水平以及爬取思路仅限于:给定一个URL,包含C源码网址,我查看网页源码,设计程序逐个爬虫,下载C程序至文件👍
最初选择的URL如下:
菜鸟|C语言练习实例

我设计了如下程序:
import os
import sys
import numpy as np
import tensorflow as tf
from sequence.data_process import *
from nn.wd_trainer import WassersteinTrainer
from nn.scale_model import ScaleModel
from config import *
from nn.optimizer import Optimizer
import random
import requests
from bs4 import BeautifulSoup
import redef example_urls():url = 'https://www.runoob.com/cprogramming/c-100-examples.html'c = requests.get(url)c.encoding = "utf-8"html = c.textexample_url = []soup = BeautifulSoup(html, features="html.parser")for i in range(1, 101):item = soup.find("a", title="C 语言练习实例"+str(i))attrs = item.attrshref = attrs['href']example_url.append(href)return example_urlif __name__ == '__main__':example_url = example_urls()# example_url = ['/cprogramming/c-exercise-example1.html', '/cprogramming/c-exercise-example2.html', '/cprogramming/c-exercise-example3.html', '/cprogramming/c-exercise-example4.html', ...]i = 0while i < 101:e_url = example_url[i-1]url = 'https://www.runoob.com'+e_urlprint('url:', url)c = requests.get(url)c.encoding = "utf-8"html = c.textsoup = BeautifulSoup(html, features="html.parser") # 加html.parse代表识别为html语言item_1 = soup.find("div", class_="example_code")if item_1 is None:item_1 = soup.find("pre")print("item:", item_1)d_1 = item_1.text.strip()with open("data/readelf/c_source/id:{}.c".format(str(i).zfill(4)), "w", encoding='utf-8') as f:f.write(d_1)f.close()i += 1break在菜鸟官网,只可以下载C语言经典100例,与我需要爬取的数量相差较大!
我又开始寻找包含需要C源码的网址,一个只发布C源码的博主,我重写编写程序(我的代码就是这么的局限),又找到26个程序,我要这样一直查找下去吗?
BFS爬取c程序
打开CSDN,我就打开了新世界的大门,我不需要寻找一个包含许多C源码的网址,我可以任意访问一个URL,查找网页是否包含C代码,之后利用BFS的思想,依次访问该URL可以链接的下一级URL。我的思想与下面文章的思想不谋而合,这篇文章介绍得很具体,如下所示:
通用爬虫技术
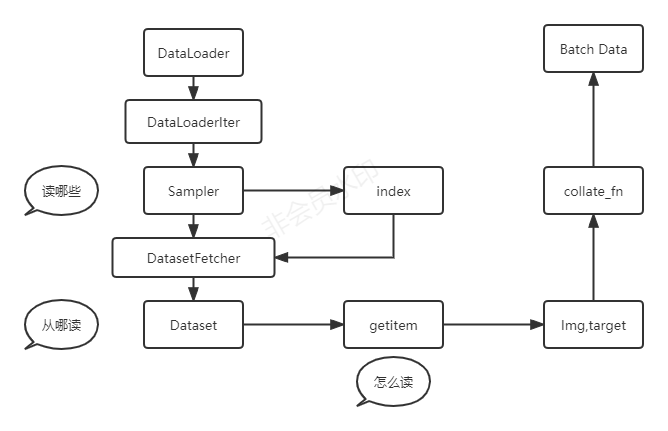
通用爬虫技术(general purpose Web crawler)也就是全网爬虫。其实现过程如下。
第一,获取初始URL。初始URL地址可以由用户人为指定,也可以由用户指定的某个或某几个初始爬取网页决定。
第二,根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,需要先爬取对应URL地址中的网页,接着将网页存储到原始数据库中,并且在爬取网页的同时,发现新的URL地址,并且将已爬取的URL地址存放到一个URL列表中,用于去重及判断爬取的进程。
第三,将新的URL放到URL队列中,在于第二步内获取下一个新的URL地址之后,会将新的URL地址放到URL队列中。
第四,从URL队列中读取新的URL,并依据新的URL爬取网页,同时从新的网页中获取新的URL并重复上述的爬取过程。
第五,满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件。如果没有设置停止条件,爬虫便会一直爬取下去,一直到无法获取新的URL地址为止,若设置了停止条件,爬虫则会在停止条件满足时停止爬取。详情请参见图2-5中的右下子图。
通用爬虫技术的应用有着不同的爬取策略,其中的广度优先策略以及深度优先策略都是比较关键的,如深度优先策略的实施是依照深度从低到高的顺序来访问下一级网页链接。
在CSDN,若网页中包含C源码,其网页源码就包含code 标签,且class属性包含language-c,如下所示:
<code class="prism language-c has-numbering" onclick="mdcp.copyCode(event)" style="position: unset;">
我编写的代码如下,其中BFS部分我参考了如下链接:
BFS详解及代码参考
import os
import sys
import numpy as np
import tensorflow as tf
from sequence.data_process import *
from nn.wd_trainer import WassersteinTrainer
from nn.scale_model import ScaleModel
from config import *
from nn.optimizer import Optimizer
import requests
from bs4 import BeautifulSoup
import reheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'}# 已访问过的URL集合
url_set = {}def is_visit(url_set, url):if url_set.get(url) is None:return Falseelse:return Truedef c_source(url, i):c = requests.get(url, headers=headers, timeout=30)c.encoding = "utf-8"html = c.textsoup = BeautifulSoup(html, features="html.parser")items = soup.find_all("code", attrs={"class": "language-c"})for item in items:c_source = item.text.strip()with open("data/readelf/c_source/id:{}.c".format(str(i).zfill(4)), "w", encoding='utf-8') as f:f.write(c_source)f.close()i += 1return idef neighbor(url):c = requests.get(url, headers=headers, timeout=30)c.encoding = "utf-8"html = c.textneighbor_url = []soup = BeautifulSoup(html, features="html.parser")a_item = soup.find_all("a")for a in a_item:href = a.get("href")if href is None:continueif href.find("blog.csdn.net") != -1 and href.find("article") != -1 and href.find("details") != -1:neighbor_url.append(href) return neighbor_url# 输入一个起始点 URL
def BFS(url, i):# 创建队列queue = []# queue.append(url)url_set[url] = 1neighbor_url = neighbor(url)# 遍历neighbor_url中的元素for n_url in neighbor_url:# 如果n_url没访问过if not is_visit(url_set, n_url):queue.append(n_url)# 当队列不空的时候while len(queue) > 0:# 将队列的第一个元素读出来url = queue.pop(0)print("url:", url)neighbor_url = []new_i = c_source(url, i)if new_i > i:neighbor_url = neighbor(url)i = new_i# 加入url_set表示url我们访问过url_set[url] = 1# 遍历neighbor_url中的元素for n_url in neighbor_url:# 如果n_url没访问过if not is_visit(url_set, n_url):queue.append(n_url)if i > 7000:breakif __name__ == '__main__':# 广度优先搜索i = 0url = "https://blog.csdn.net/nav/algo"BFS(url, i)
下面是我爬取的C文件,存在许多片段代码,以及C++代码,所以建议大家发布博客时对应语言的代码使用对应的代码块!


c程序 gcc 为elf文件
import os
import sys
import numpy as np
import tensorflow as tf
from sequence.utils import *
from sequence.data_process import *
from nn.wd_trainer import WassersteinTrainer
from nn.scale_model import ScaleModel
from config import *
from nn.optimizer import Optimizer
import random
import requests
from bs4 import BeautifulSoup
import redef subprocess_call(cmd: str, encoding="utf-8"):"""开一个子进程执行命令, 并返回结果, 命令和返回结果的编码默认为utf-8编码.Args:cmd (str): 命令内容encoding (str): 编码格式Returns:Tuple[str, str]: (stdout, stderr)"""try:p = subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.STDOUT,encoding=encoding)result = p.communicate()p.terminate()return resultexcept Exception as e:print(e)return Noneif __name__ == '__main__':output_dir = OUTPUT_DIRformat_dir = FORMAT_DIRc_dir = output_dir + '/c_source'cmd = "ls {}".format(c_dir)result = subprocess_call(cmd)split = result[0].split()# if there exists no filesif len(split) == 0:print("Note: There exists no files!")print("文件数量:", len(split))i = 0while i <= 8005:file = split[i - 1]file_name = file.rstrip()file_path = "{}/{}".format(c_dir, file_name)outfile_name = 'org_elf:id:{}'.format(str(i).zfill(4))outfile_path = os.path.join(format_dir, outfile_name)print('file_path:', file_path)gcc_cmd = "gcc {} -o {}".format(file_path, outfile_path)# gcc c_source/id:0799.c -o format_set/org_elf:id:0001gcc_result = subprocess_call(gcc_cmd)# if gcc_result is not None:i += 1
上面代码中的gcc命令,如果不是c源码,就会产生编译错误,从而不会生成对应的ELF文件,我收集了8000个C程序,预处理之后保存下来1732个文件。
扩展
本文提出的方法同时可以适用于XML、C++和Java等文件,例如,我们可以修改code的属性为language-xml 进而完成下载XML文件。
本文的方法同时可以适用于PNG、JPEG文件的下载。PNG文件需要通过下载URL将文件保存至硬盘。
python requests库下载图片保存到本地
我的代码如下,思路与之前的代码一致:
import requests
from bs4 import BeautifulSoup
import re
from sequence.utils import *
from config import *# 已访问过的URL集合
url_set = {}
format_dir = 'data/libpng/format_set'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'}def is_visit(url_set, url):if url_set.get(url) is None:return Falseelse:return True# 单个img下载
def download_img(url, i):try:response = requests.get(url)# 获取的文本实际上是图片的二进制文本img = response.content# 保存路径 wb代表写入二进制文本path = '{}/org_png:id:{}'.format(format_dir, str(i).zfill(4))with open(path, 'wb') as f:f.write(img)f.close()except Exception as e:print(e)def neighbor(a_items):neighbor_url = []for a in a_items:href = a.get("href")if href is None:continueif href[0] == '/':url = "https://pngpai.com" + hrefif not is_visit(url_set, url):neighbor_url.append(url)return neighbor_url# 批量img下载
def png(queue, url, i):c = requests.get(url, headers=headers, timeout=30)c.encoding = "utf-8"html = c.textsoup = BeautifulSoup(html, features="html.parser")url_set[url] = 1a_items = soup.find_all("a")neighbor_url = neighbor(a_items)for n_url in neighbor_url:# 如果n_url没访问过if not is_visit(url_set, n_url):queue.append(n_url)img_items = soup.find_all("img")for item in img_items:src = item.get('src')if src is None:continueif src[0] == '/':img_url = "https://pngpai.com" + srcprint("img_url:", img_url)if img_url.find('.png') != -1:download_img(img_url, i)i += 1return i# 输入一个起始点 URL
def BFS(url, i):# 创建队列queue = []queue.append(url)# 当队列不空的时候while len(queue) > 0:# 将队列的第一个元素读出来url = queue.pop(0)print("url:", url)new_i = png(queue, url, i)if new_i > i:i = new_iif i > 2000:breakif __name__ == '__main__':url = "https://pngpai.com/"i = 1BFS(url, i)