接着,我们聊聊复杂度的第二个要求高可用。
参考维基百科,先来看看高可用的定义。
系统无中断地执行其功能的能力,代表系统的可用性程度,是进行系统设计时的准则之一。
这个定义的关键在于“ 无中断”,但恰好难点也在“无中断”上面,因为无论是单个硬件还是单个软件,都不可能做到无中断,硬件会出故障,软件会有bug;硬件会逐渐老化,软件会越来越复杂和庞大……
除了硬件和软件本质上无法做到“无中断”,外部环境导致的不可用更加不可避免、不受控制。例如,断电、水灾、地震,这些事故或者灾难也会导致系统不可用,而且影响程度更加严重,更加难以预测和规避。
高可用性是指系统在没有中断的情况下能够持续执行其功能的能力,是进行系统设计时的重要准则之一。然而,要实现无中断是非常困难的,因为单个硬件或软件都有可能出现故障或错误,且硬件随着时间的推移会逐渐老化,软件也会变得越来越复杂和庞大。此外,外部环境因素如断电、水灾、地震等灾难也可能导致系统不可用,而且其影响程度更加严重,更难以预测和规避。
因此,实现高可用性的方案是通过增加冗余性来提高系统的可用性。简单来说,就是增加更多的机器或部署多个机房来解决单点故障问题。这样做的目的是为了增强系统的冗余性,从而实现高可用性。需要注意的是,实现高性能和高可用性都需要增加机器,但它们的目的不同,前者是为了“扩展”处理性能,而后者是为了“冗余”处理单元。
虽然通过冗余增强了系统的可用性,但同时也带来了复杂性。因此,在实际应用中需要根据不同的场景逐一分析,采取不同的高可用方案。
计算高可用
在这里,“计算”指的是业务逻辑处理。与计算相关的高可用性的复杂性在于,无论在哪台机器上执行计算,只要算法和输入数据相同,计算结果就应该是相同的。因此,将计算从一台机器转移到另一台机器,对业务逻辑没有任何影响。
以最简单的单机变双机架构为例,我们可以看到以下几个方面的复杂性:先来看一个单机变双机的简单架构示意图。
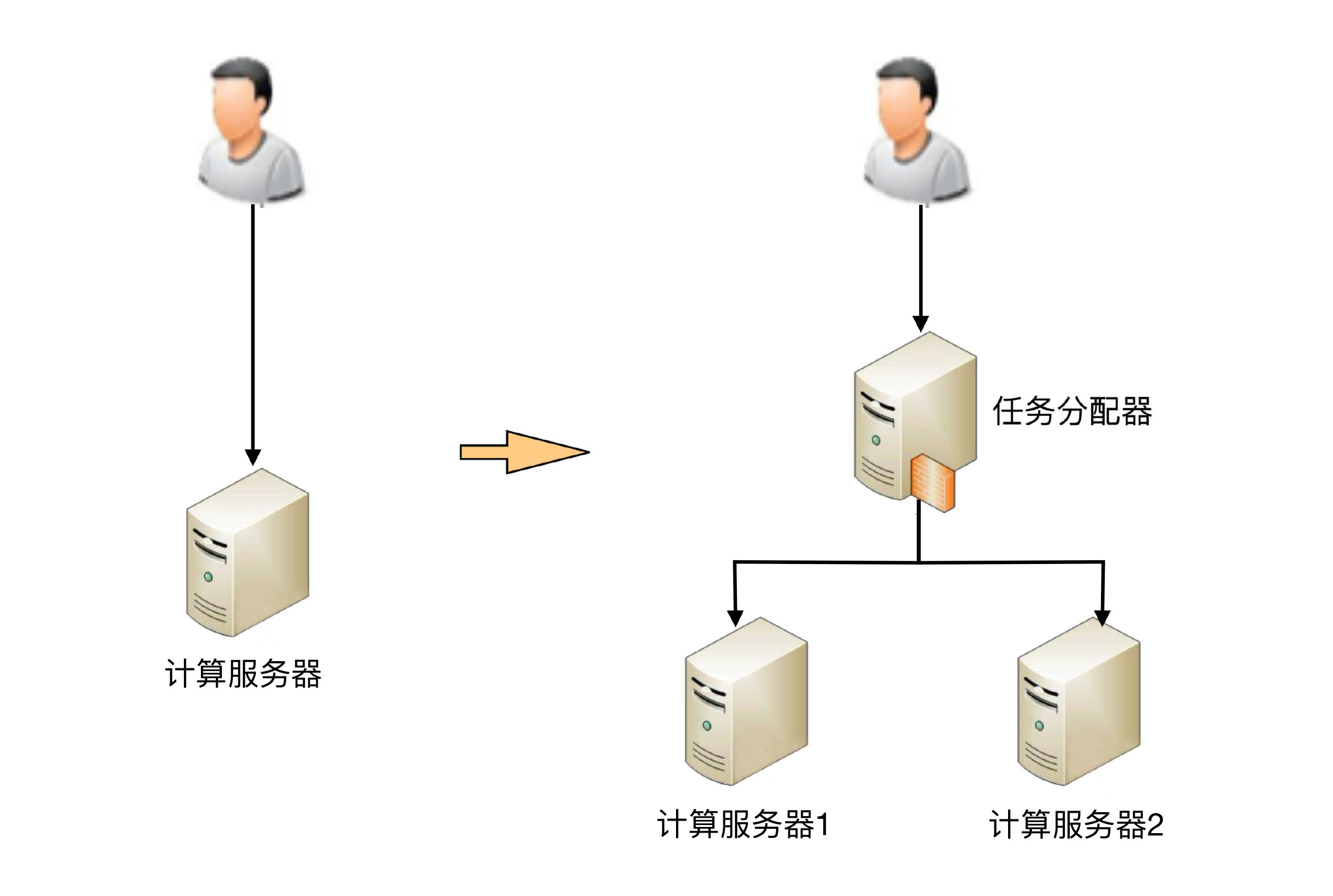
你可能会发现,这个双机的架构图和上期“高性能”讲到的双机架构图是一样的,因此复杂度也是类似的,具体表现为:
需要增加任务分配器,选择合适的任务分配器也是一个复杂的过程,需要考虑各种因素,例如性能、成本、可维护性和可用性等等。
任务分配器与真正的业务服务器之间需要进行连接和交互。因此,需要选择合适的连接方式,并且对连接进行管理。例如,建立连接、检测连接、处理连接中断等等。
任务分配器需要增加分配算法。常见的双机算法有主备、主主,主备方案又可以细分为冷备、温备、热备等等。
上面这个示意图只是简单的双机架构,我们再看一个复杂一点的高可用集群架构。
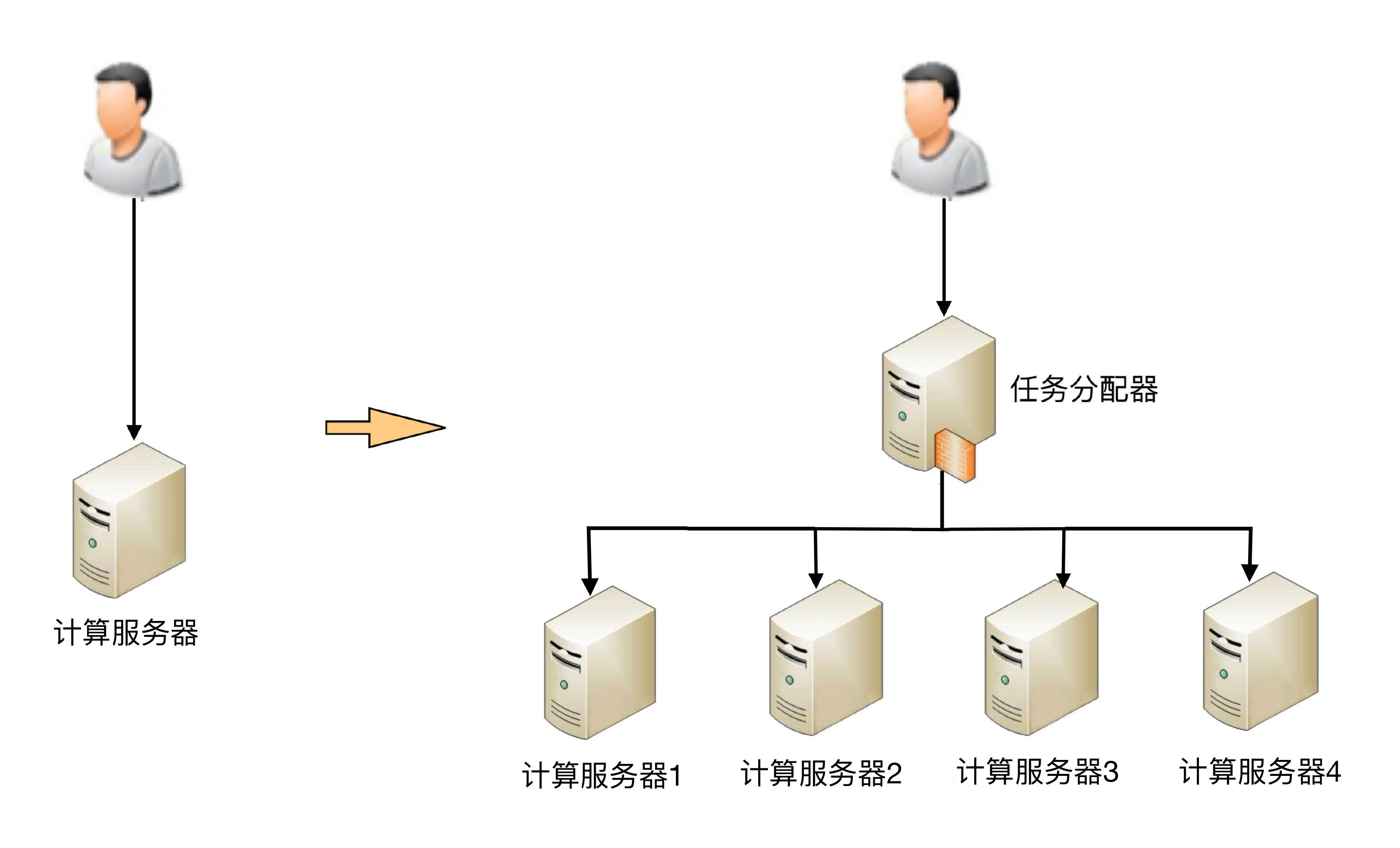
上面这个示意图只是一个简单的双机架构,而复杂度会随着集群的规模和结构的变化而增加。例如,上图展示了一个更为复杂的高可用集群架构。这种情况下,分配算法的选择更加复杂,可以是1主3备、2主2备、3主1备、4主0备等等。具体应该采用哪种方式,需要根据实际业务需求进行分析和判断,不存在一种算法一定比其他算法更优。例如,ZooKeeper采用的是1主多备,而Memcached则采用全主0备。
存储高可用
对于需要存储数据的系统来说,整个系统的高可用设计的关键点和难点在于“存储高可用”。与计算相比,存储有一个本质的不同点:将数据从一台机器搬到另一台机器需要经过线路传输。线路传输的速度是毫秒级别,同一机房内部可以做到几毫秒,但分布在不同地方的机房,传输耗时需要几十甚至上百毫秒。例如,从广州机房到北京机房,稳定情况下ping延时大约是50ms,不稳定情况下可能达到1秒甚至更长。
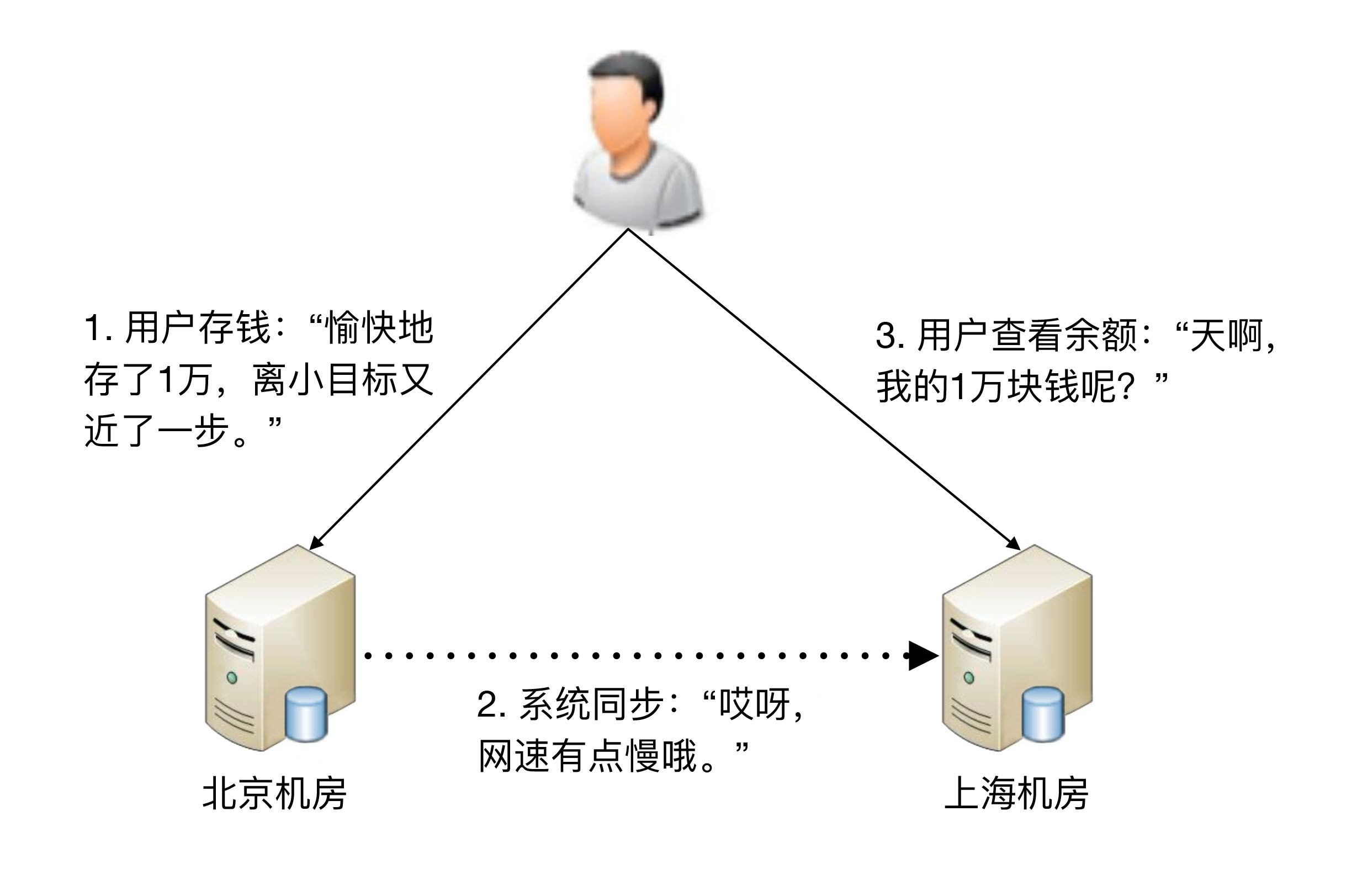
虽然对人类来说,毫秒几乎没有什么感觉,但对于高可用系统来说,这是本质的不同之处。这意味着在某个时间点上,整个系统中的数据肯定是不一致的。按照“数据 + 逻辑 = 业务”这个公式来看,数据不一致即使逻辑一致,最终的业务表现也会不同。以银行储蓄业务为例,假设用户的数据存在北京机房,用户存入1万块钱,然后查询时被路由到了上海机房,而北京机房的数据没有同步到上海机房。用户会发现他的余额并没有增加1万块。想象一下,此时用户肯定会感到不安,会怀疑自己的钱被盗了,赶紧打客服电话投诉,甚至可能打110报警。即使最终发现只是因为传输延迟导致的问题,从用户的角度来看,这个过程的体验肯定很不好。
除了物理传输速度限制,传输线路本身也可能出现可用性问题。传输线路可能会中断、拥塞、异常(如错包、丢包),并且线路故障的恢复时间通常较长,可能持续几分钟甚至几小时。例如,2015年支付宝因为光缆被挖断,业务受到了超过4个小时的影响;2016年中美海底光缆中断3小时等。线路中断意味着存储无法同步,这段时间内整个系统的数据将不一致。
综合考虑,在正常情况下的传输延迟和异常情况下的传输中断都会导致系统在某个时间点或时间段内的数据不一致,从而影响业务。然而,如果完全不做冗余,整个系统的高可用性就无法保证。因此,存储高可用的难点不在于如何备份数据,而在于如何减少或规避数据不一致对业务造成的影响。
在分布式系统领域,有一个著名的CAP定理,从理论上证明了存储高可用的复杂度。也就是说,存储高可用不可能同时满足“一致性、可用性、分区容错性”,最多只能满足其中两个。因此,在架构设计时,需要根据实际业务需求进行取舍。
高可用状态决策
无论是计算高可用还是存储高可用,其基础都是“状态决策”,即系统需要能够判断当前的状态是正常还是异常,如果出现异常就需要采取行动来保证高可用。如果状态决策本身存在错误或偏差,那么后续的任何行动和处理都将失去意义和价值。然而,在具体实践中,存在一个本质的矛盾:通过冗余实现的高可用系统,状态决策本质上不可能做到完全正确。以下是对几种常见的决策方式的详细分析:
1.独裁式
独裁式决策指的是存在一个独立的决策主体,我们称之为“决策者”,其负责收集信息并做出决策。所有冗余的个体,我们称之为“上报者”,将状态信息发送给决策者。
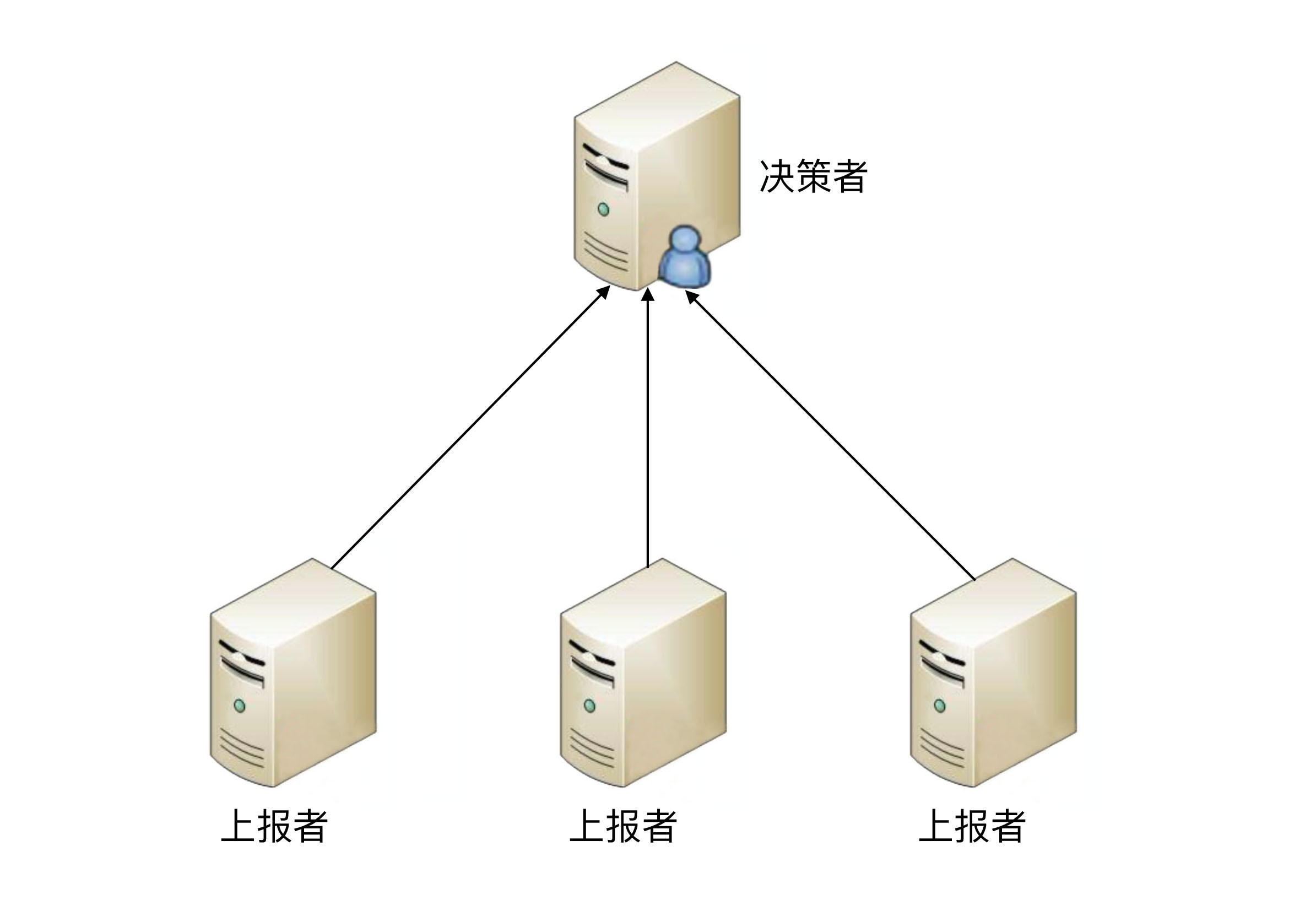
独裁式的决策方式不会出现决策混乱的问题,因为只有一个决策者,但问题也正是在于只有一个决策者。当决策者本身故障时,整个系统就无法实现准确的状态决策。如果决策者本身又做一套状态决策,那就陷入一个递归的死循环了。
2.协商式
协商式决策指的是两个独立的个体通过交流信息,然后根据规则进行决策, 最常用的协商式决策就是主备决策。
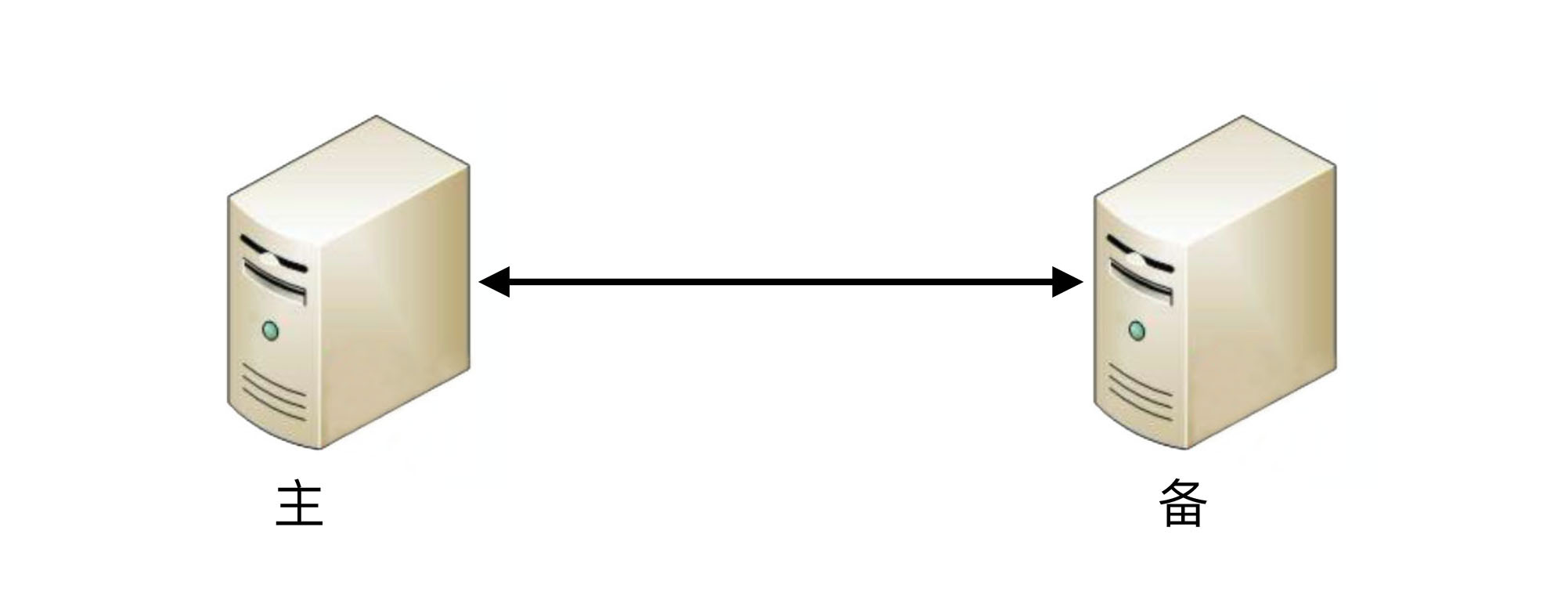
这个架构的基本协商规则可以设计成:
2台服务器启动时都是备机。 2台服务器建立连接。 2台服务器交换状态信息。 某1台服务器做出决策,成为主机;另一台服务器继续保持备机身份。
协商式决策的架构不复杂,规则也不复杂,其难点在于,如果两者的信息交换出现问题(比如主备连接中断),此时状态决策应该怎么做。
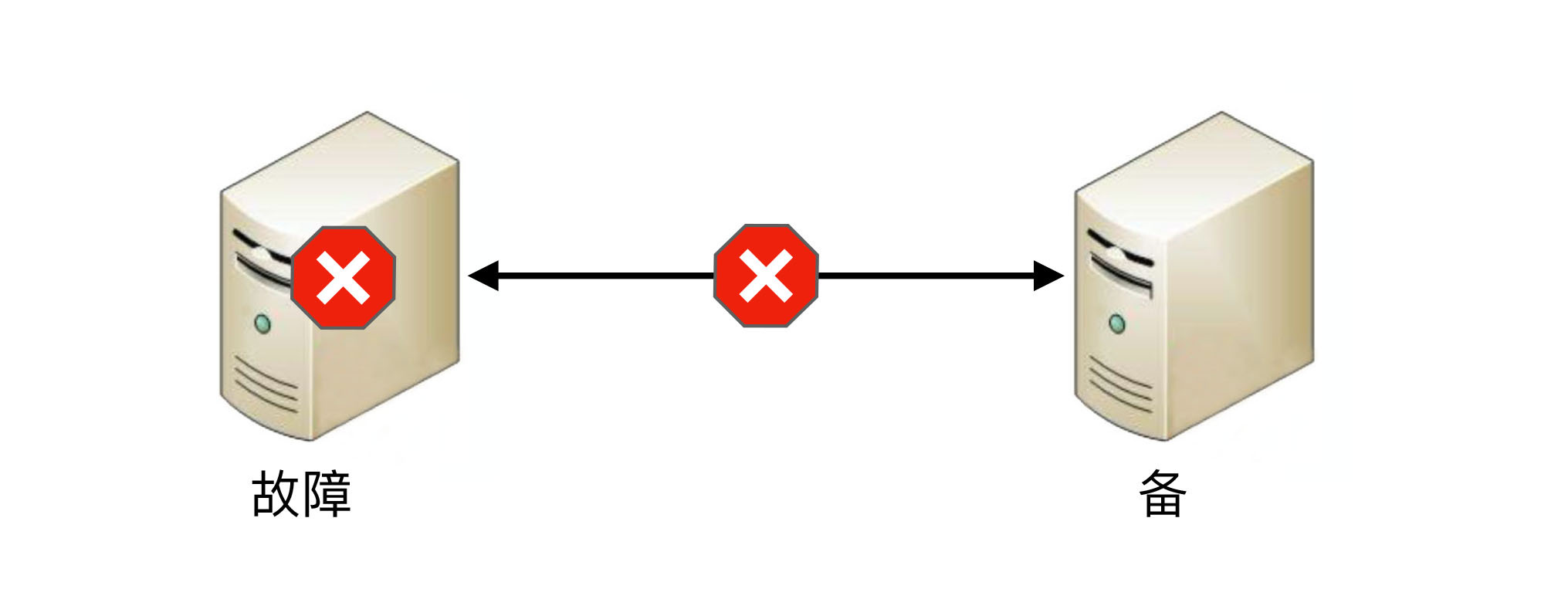
如果备机在连接中断的情况下认为主机故障,那么备机需要升级为主机,但实际上此时主机并没有故障,那么系统就出现了两个主机,这与设计初衷(1主1备)是不符合的。
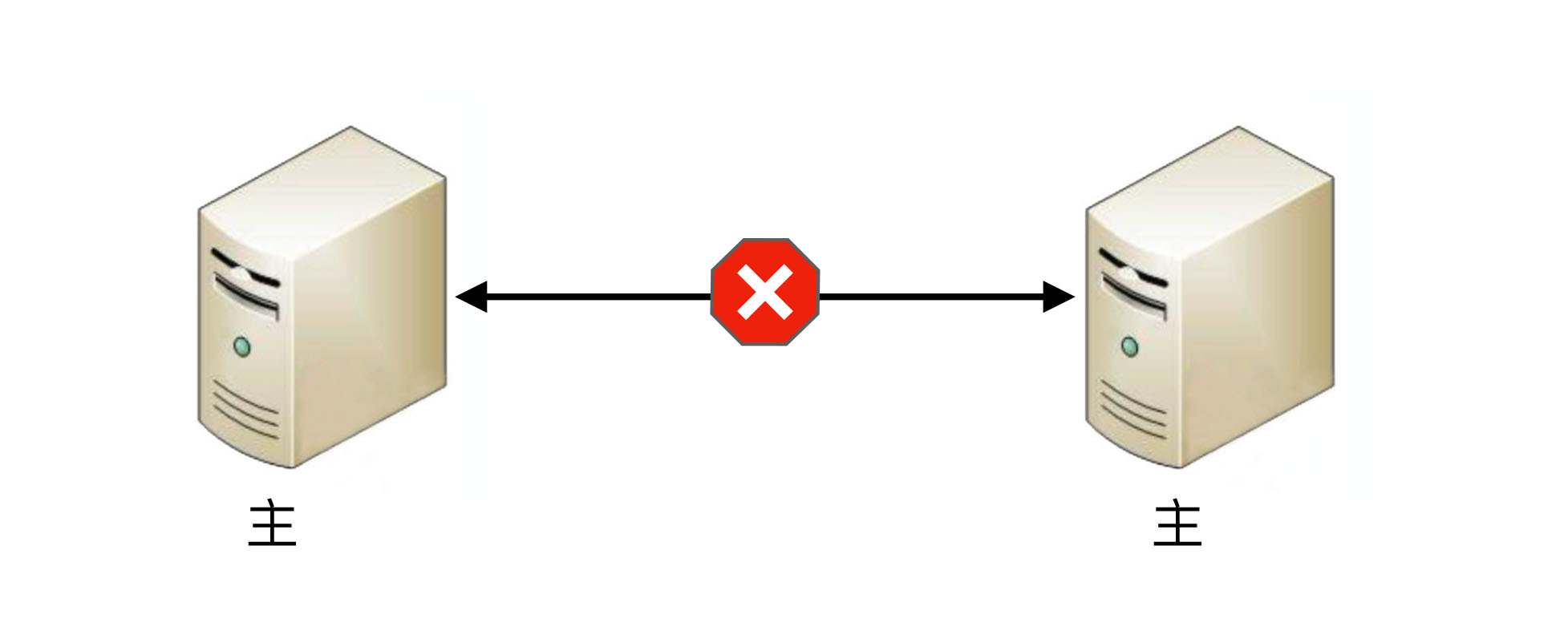
如果备机在连接中断的情况下不认为主机故障,则此时如果主机真的发生故障,那么系统就没有主机了,这同样与设计初衷(1主1备)是不符合的。
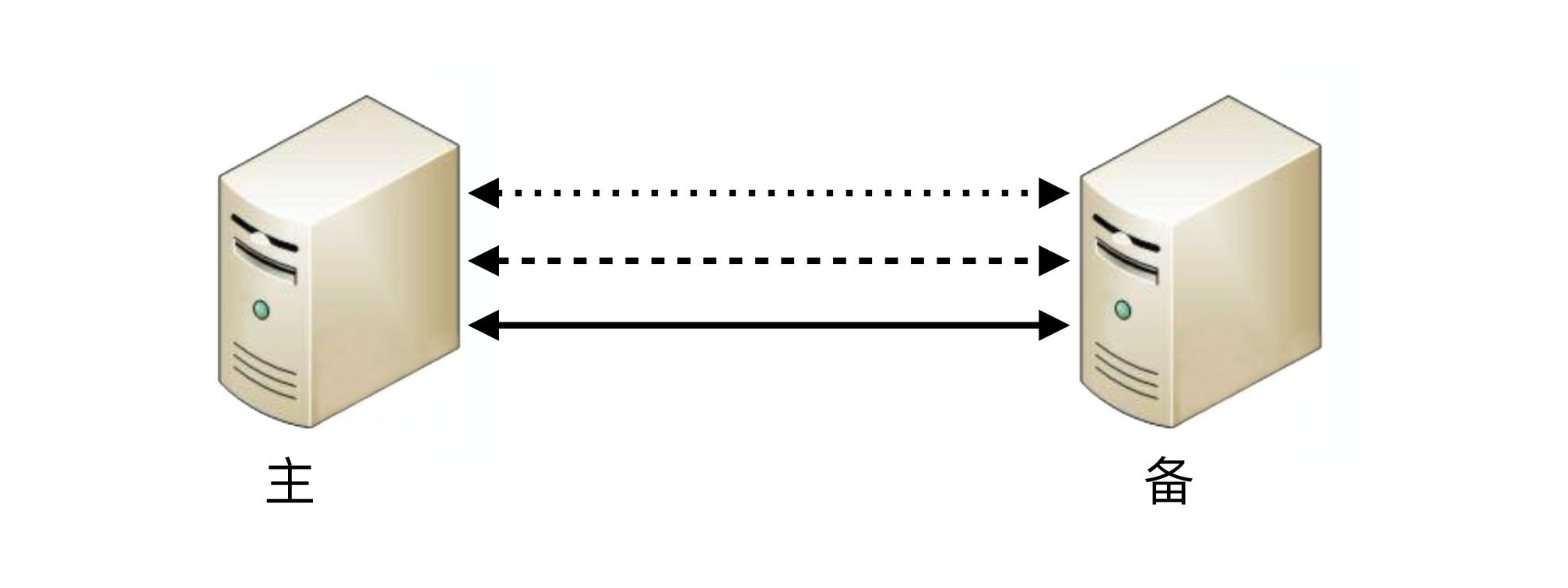
如果为了规避连接中断对状态决策带来的影响,可以增加更多的连接。例如,双连接、三连接。这样虽然能够降低连接中断对状态带来的影响(注意:只能降低,不能彻底解决),但同时又引入了这几条连接之间信息取舍的问题,即如果不同连接传递的信息不同,应该以哪个连接为准?实际上这也是一个无解的答案,无论以哪个连接为准,在特定场景下都可能存在问题。
综合分析,协商式状态决策在某些场景总是存在一些问题的。
3.民主式
民主式决策指的是多个独立的个体通过投票的方式来进行状态决策。例如,ZooKeeper集群在选举leader时就是采用这种方式。
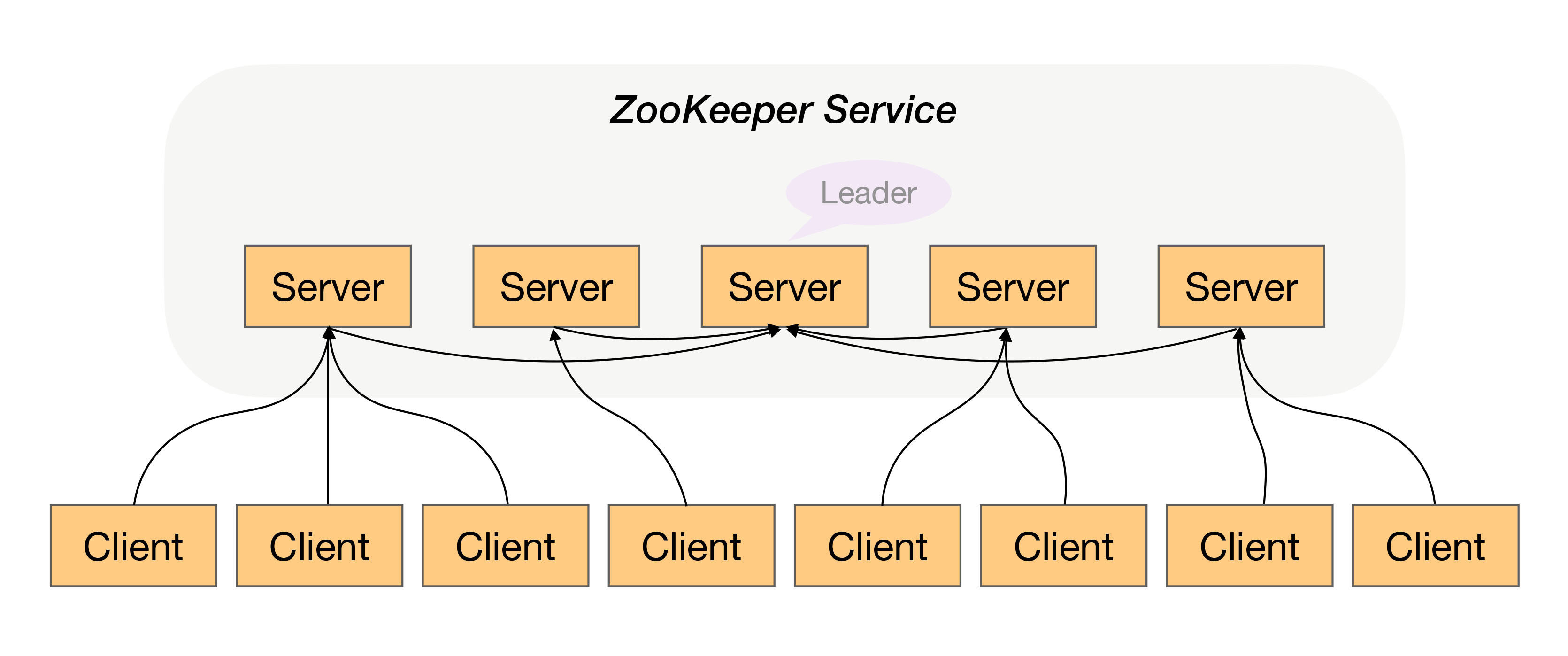
民主式决策和协商式决策比较类似,其基础都是独立的个体之间交换信息,每个个体做出自己的决策,然后按照“ 多数取胜”的规则来确定最终的状态。不同点在于民主式决策比协商式决策要复杂得多,ZooKeeper的选举算法ZAB,绝大部分人都看得云里雾里,更不用说用代码来实现这套算法了。
除了算法复杂,民主式决策还有一个固有的缺陷:脑裂。这个词来源于医学,指人体左右大脑半球的连接被切断后,左右脑因为无法交换信息,导致各自做出决策,然后身体受到两个大脑分别控制,会做出各种奇怪的动作。例如:当一个脑裂患者更衣时,他有时会一只手将裤子拉起,另一只手却将裤子往下脱。脑裂的根本原因是,原来统一的集群因为连接中断,造成了两个独立分隔的子集群,每个子集群单独进行选举,于是选出了2个主机,相当于人体有两个大脑了。

从图中可以看到,正常状态的时候,节点5作为主节点,其他节点作为备节点;当连接发生故障时,节点1、节点2、节点3形成了一个子集群,节点4、节点5形成了另外一个子集群,这两个子集群的连接已经中断,无法进行信息交换。按照民主决策的规则和算法,两个子集群分别选出了节点2和节点5作为主节点,此时整个系统就出现了两个主节点。这个状态违背了系统设计的初衷,两个主节点会各自做出自己的决策,整个系统的状态就混乱了。
为了解决脑裂问题,民主式决策的系统一般都采用“投票节点数必须超过系统总节点数一半”规则来处理。如图中那种情况,节点4和节点5形成的子集群总节点数只有2个,没有达到总节点数5个的一半,因此这个子集群不会进行选举。这种方式虽然解决了脑裂问题,但同时降低了系统整体的可用性,即如果系统不是因为脑裂问题导致投票节点数过少,而真的是因为节点故障(例如,节点1、节点2、节点3真的发生了故障),此时系统也不会选出主节点,整个系统就相当于宕机了,尽管此时还有节点4和节点5是正常的。
综合分析,无论采取什么样的方案,状态决策都不可能做到任何场景下都没有问题,但完全不做高可用方案又会产生更大的问题,如何选取适合系统的高可用方案,也是一个复杂的分析、判断和选择的过程。
小结
综上所述,我向你分析了复杂度之高可用,分析了计算高可用和存储高可用两个场景,给出了几种高可用状态决策方式,希望对你有帮助
本文由 mdnice 多平台发布