提取中文文本
- 简介
- unicode 编码转换
- re.findall
- re 中 [] +
- re.S
- [\u4e00-\u9fa5]+ 提取中文案例
简介
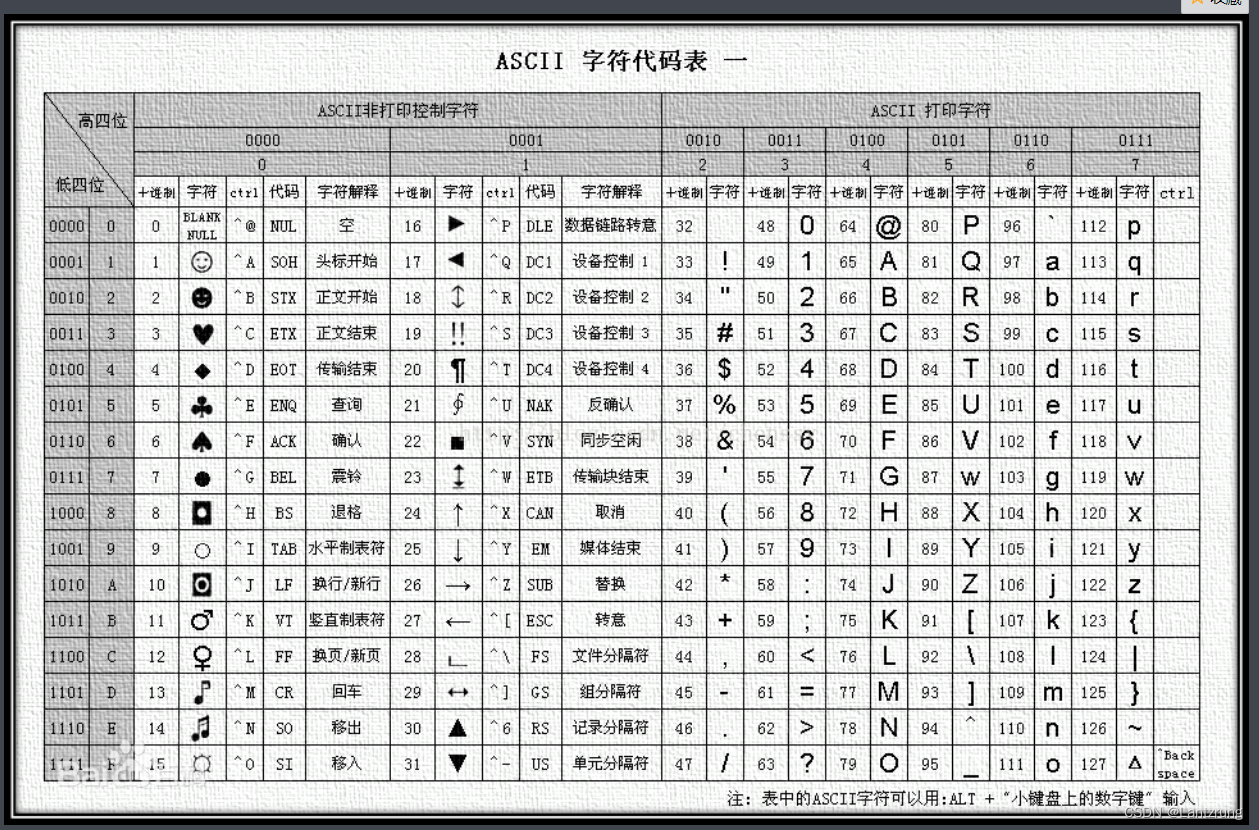
\u4e00 和 \u9fa5 是 unicode 编码,正好是中文编码开头和结尾对应的数值。
[\u4e00-\u9fa5]+ 在 re.findall 中可用来找出文本中所有中文。
unicode 编码转换
>>> '\u4e00'.encode().decode() #unicode码转换成字符
'一'
>>> '\u9fa5'.encode().decode()
'龥'
re.findall

>>> import re>>> re.findall(r'[a-z]+', 'which foot or hand fell fastest')
['which', 'foot', 'or', 'hand', 'fell', 'fastest']>>> re.findall(r'[0-9]', 'qfqefqe')
[]
re 中 [] +
[],用于表示一个字符集合。 -,在 [] 中表示字符范围。

+,对它前面的匹配式重复1到无数次。

re.S

[\u4e00-\u9fa5]+ 提取中文案例
>>> myText = '里面有我最宝贵的私家逆袭经验,全都毫无保留分享给你,比如优质书单和阅读方法推荐,理财经验技巧分享,哑巴英语变成英语达人的秘诀、自律长达10年的独门诀窍、连续高效学习工作10个小时的专注技巧…… 我还会每天分享一篇优质成长干货,如果你不甘于平庸,我就在那边等你,陪你一起精进噢~ 分享35个超炫酷好玩的网站: 有哪些能玩上一天的网站? 推荐让你能轻松消遣时间的良心app: 你手机最消遣时间的软件是什么? 强烈推荐35个让你颜值爆表的小技巧: 如何在半年内提高颜值?'
>>> cut_text = re.findall('[\u4e00-\u9fa5]+', myText, re.S)
>>> cut_text
['里面有我最宝贵的私家逆袭经验', '全都毫无保留分享给你', '比如优质书单和阅读方法推荐', '理财经验技巧分享', '哑巴英语变成英语达人的秘诀', '自律长达', '年的独门诀窍', '连续高效学习工作', '个小时的专注技巧', '我还会每天分享一篇优质成长干货', '如果你不甘于平庸', '我就在那边等你', '陪你一起精进噢', '分享', '个超炫酷好玩的网站', '有哪些能玩上一天的网站', '推荐让你能轻松消遣时间的良心', '你手机最消遣时间的软件是什么', '强烈推荐', '个让你颜值爆表的小技巧', '如何在半年内提高颜值']
>>> ' '.join(cut_text)
'里面有我最宝贵的私家逆袭经验 全都毫无保留分享给你 比如优质书单和阅读方法推荐 理财经验技巧分享 哑巴英语变成英语达人的秘诀 自律长达 年的独门诀窍 连续高效学习工作 个小时的专注技巧 我还会每天分享一篇优质成长干货 如果你不甘于平庸 我就在那边等你 陪你一起精进噢 分享 个超炫酷好玩的网站 有哪些能玩上一天的网站 推荐让你能轻松消遣时间的良心 你手机最消遣时间的软件是什么 强烈推荐 个让你颜值爆表的小技巧 如何在半年内提高颜值'

![oracle u4e00 u9fa5,Oracle 判断汉字 [\u4e00-\u9fa5]](/images/no-images.jpg)