今日CS.CV 计算机视觉论文速览
Wed, 12 Jun 2019
Totally 52 papers
?上期速览✈更多精彩请移步主页

Interesting:
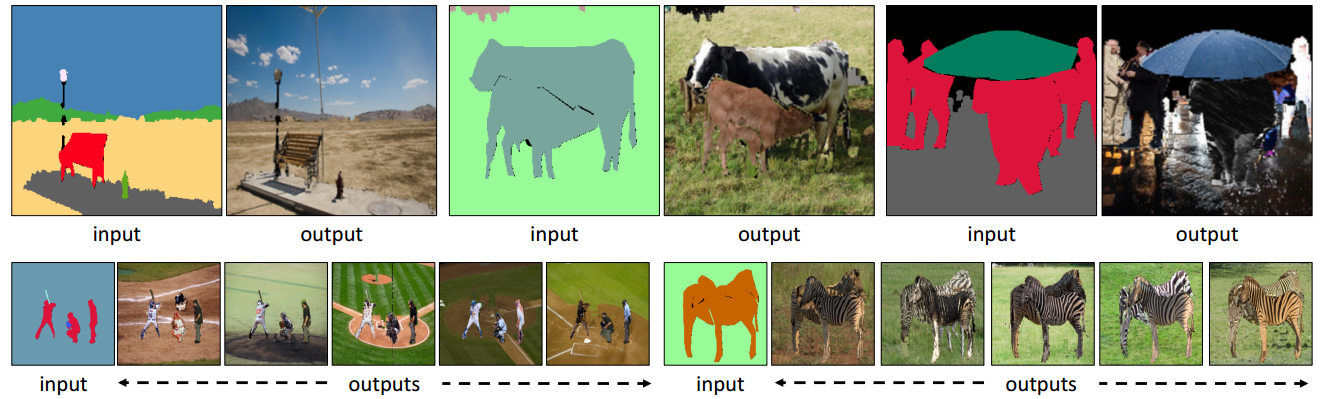
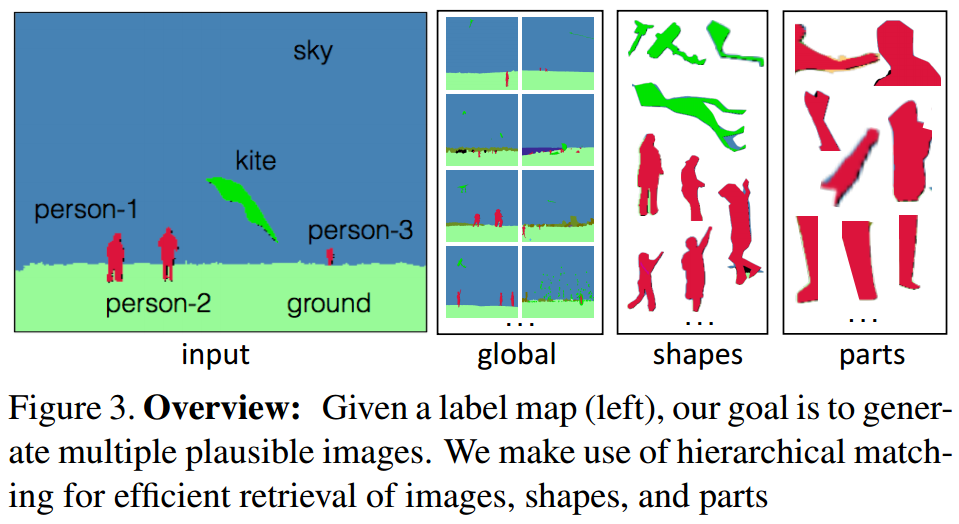
?Shapes and Context, 研究人员提出了一种从语义标签图合成图像以及操作图像内容的方法,具有丰富的适应性、可以合成十分高分辨的图像,这些图像具有合适的外形和视觉结果,可以通过这种方法合成丰富的图像资源。(from CMU)
输入语义图像,输出合成的彩色图像:
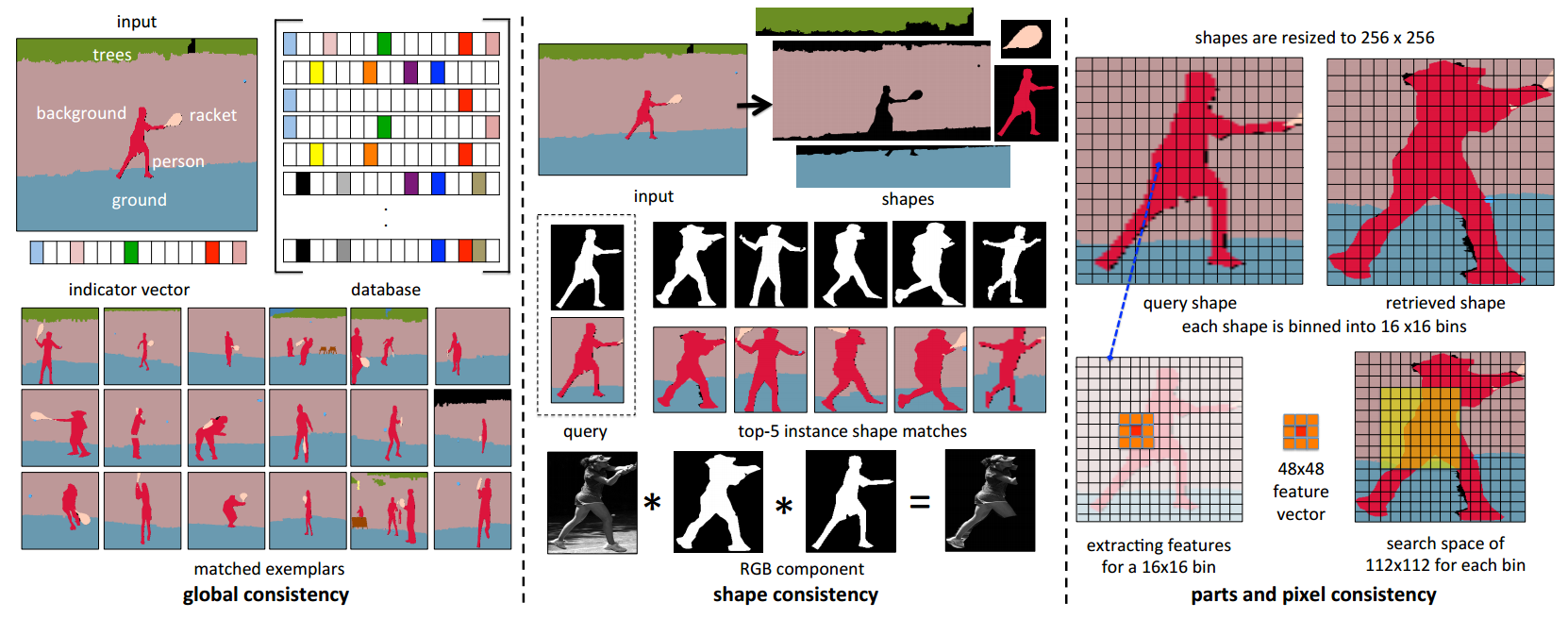
对于输入的语义图,研究人员提出了非参数的匹配方法来处理全局、外形、部分甚至像素的细节,以便合成出新的图像:
非参数匹配的过程主要分为四个步骤,首先利用知识矢量来从数据集中找到相关样本,随后利用形状连续性并基于形状和内容特征来寻找到最适合的掩膜,接着利用部分连续性和局域合成方法来补全细节的信息,最后在像素水平对图形进行处理:
一些合成的结果:

统一输入多个合成的输出:

图像插入元素的操作结果:

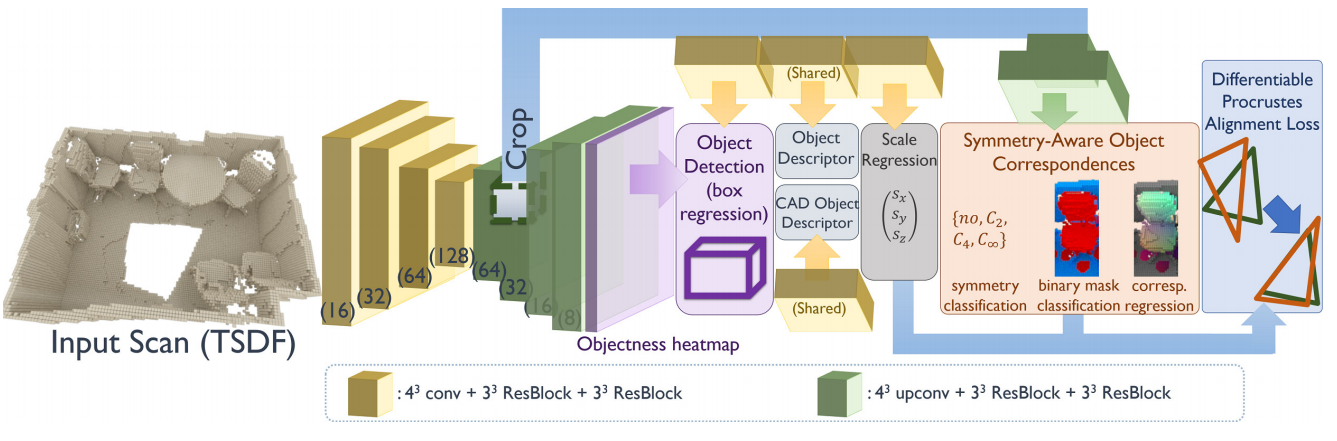
?三维场景中CAD模型检索与9DoF的匹配, 研究人员提出了一种对扫描场景中的物体进行6D位姿检测,并利用检测结果与对应的CAD模型进行匹配和对齐(symmetry-aware
object correspondences ,SOCs),随后将生成有效的CAD重建结果,包含干净的、完整的物体几何模型。(from 慕尼黑工大)
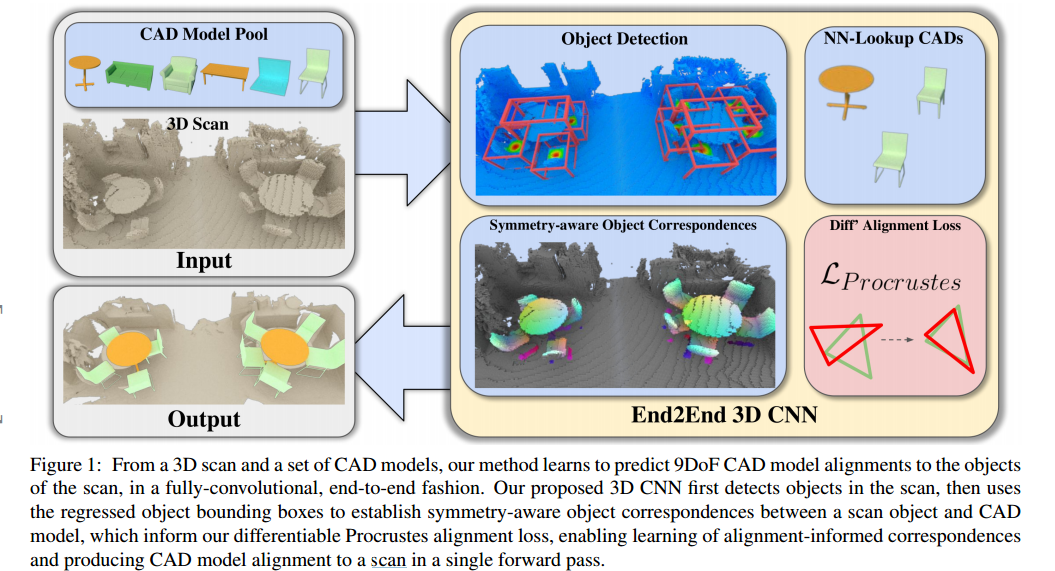
用于CAD模型匹配的端到端模型:
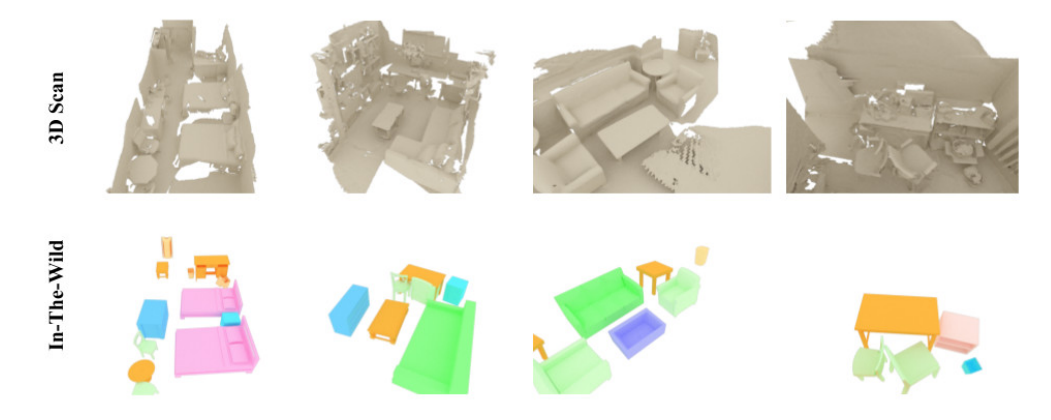
得到的一些结果,其中扫描数据来自,家具的CAD模型来自shapent core:
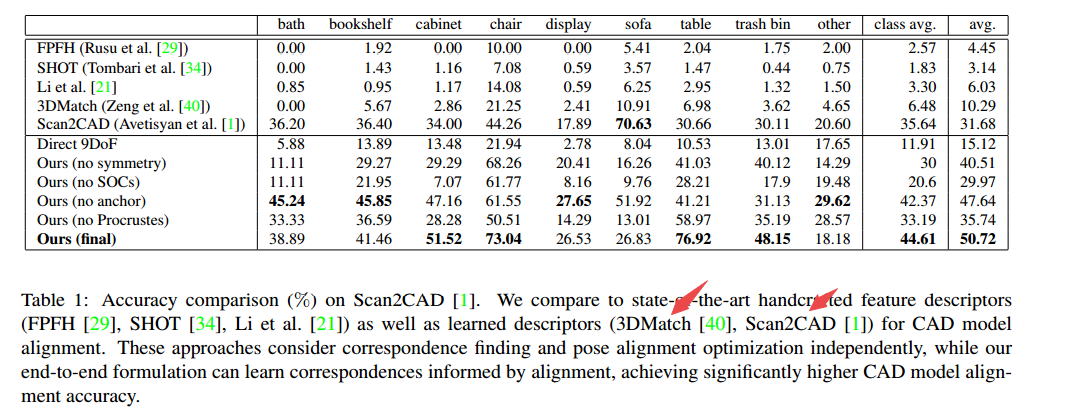
一些相关方法的比较:
数据主要来自于扫描数据的TSDF编码,encoded in a volumetric grid and generated through volumetric fusion [5]
场景数据来自Scan2CAD annotations provide 1506 scenes for training. SUNCG.
using the level-set generation toolkit by Batty [2]生成CAD模型的表示
?提出了一种新的三维表示方法clouds of oriented gradient ,COG, 可以精确的描述透视投影的角度如何影响成像图像的梯度。为了更好地表示大尺度的三维物体以及对于小物体的检测,研究人员引入了隐支持表面。最后提出的曼哈顿体素方法来更好的捕捉房间的三维几何布局信息。最后利用了多级分类器来捕捉内容上的关系,在SUN RGB-D数据集上实现了很好的结果(from 佐治亚理工 )
从输入的图像和深度图中首先对齐包含物体的立方体并转换到惯用的坐标系下,随后从中抽取出点云密度特征、3D法向量直方图和COG 描述子。并将点云密度和体素密度匹配起来。
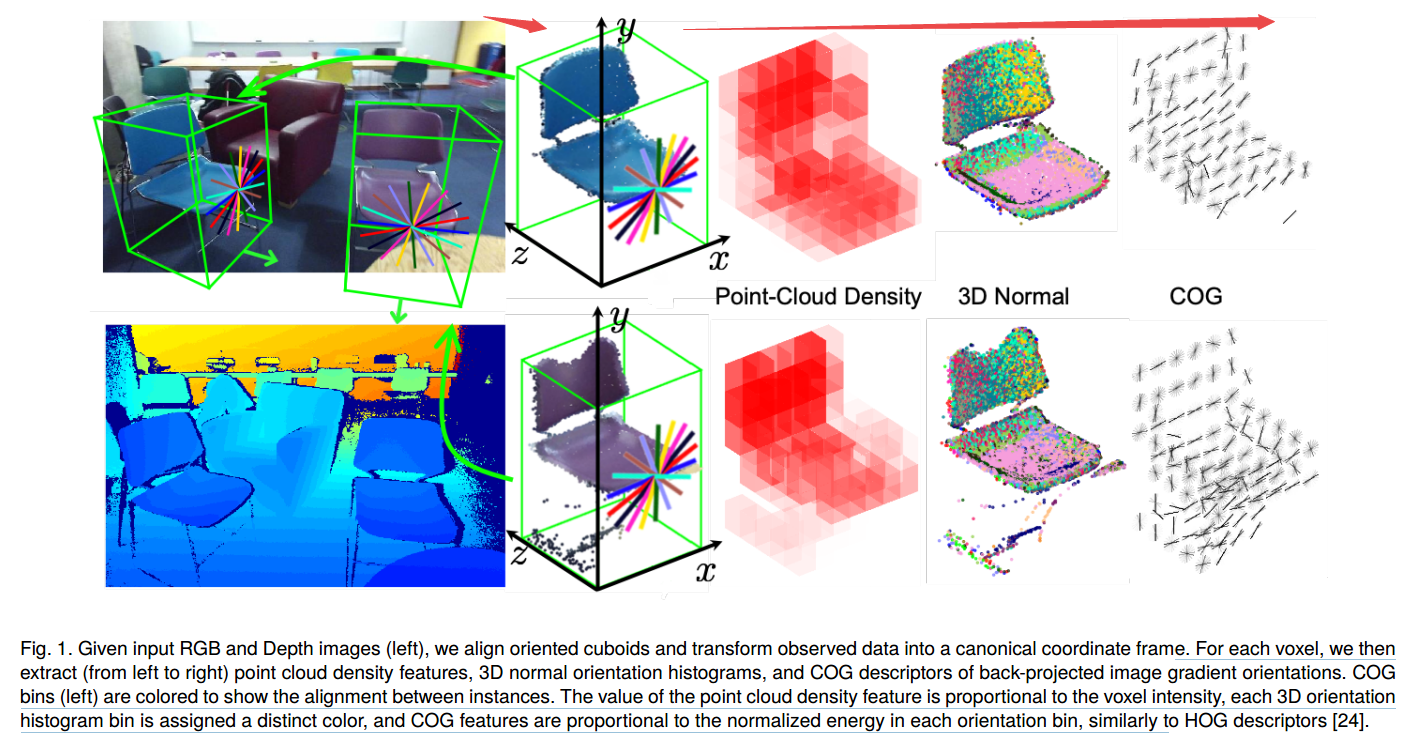
对于床和床上用品的检测结果:

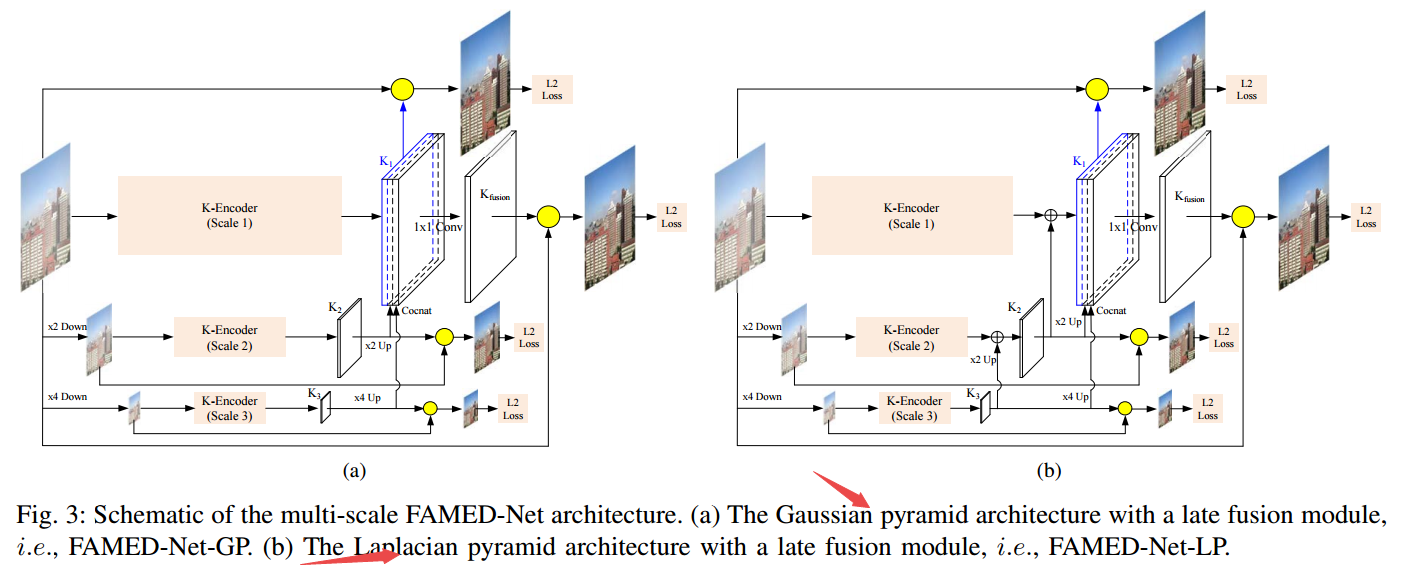
?FAMED-Net高速高精度的多尺读去雾方法, 图像去雾方法目前受制于模型复杂、计算效率和表达能力,为了解决这些问题,研究人员尝试使用三个不同尺度的编码器和融合模块构建去雾算法。每一个编码器由级联和稠密连接的逐点卷积层和池化层相连(类似shufflenet)。由于特征的复用和没有大型卷积操作使得这一模型十分轻量和高效。(from 悉尼大学 UBTECH)
网络有多个point-wise的卷积层和池化层的dense链接构成,
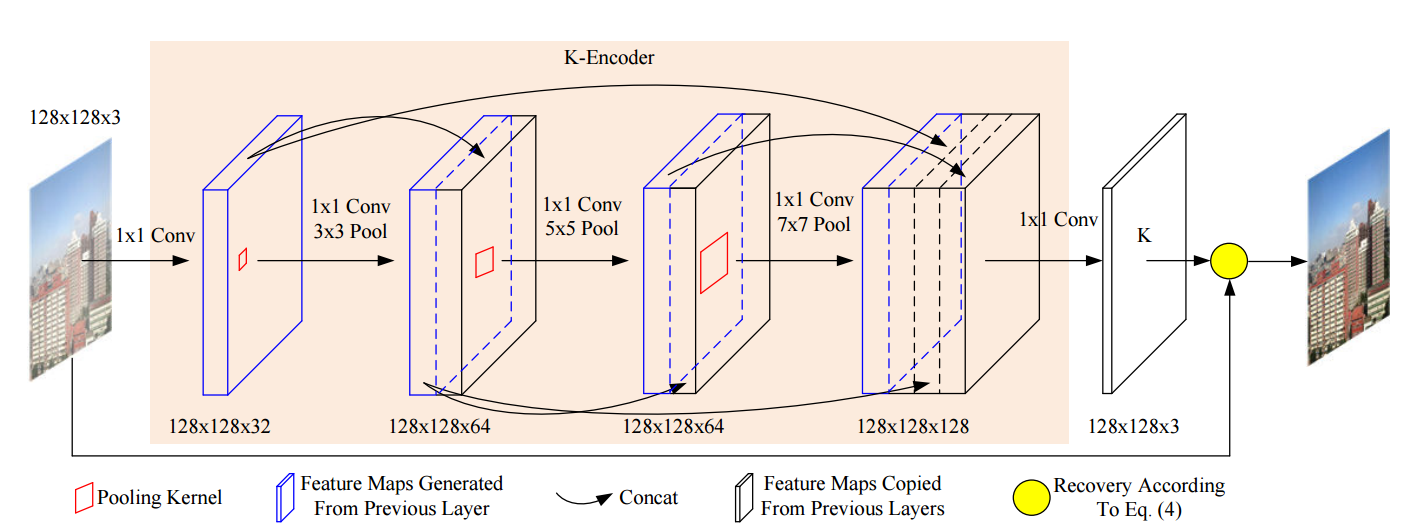
高斯金字塔和拉普拉斯金字塔结构的编码器和融合模型:
模型的一些结果:

真实图像的结果:

与相关结果的比较:
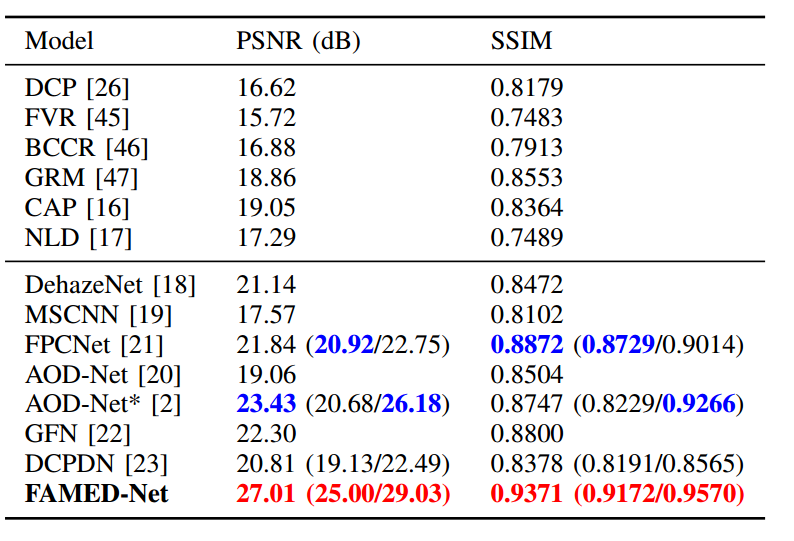
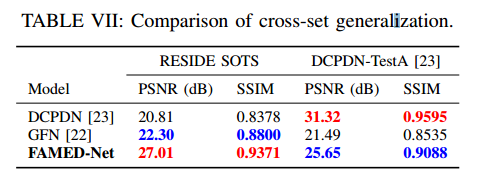
code:https://github.com/chaimi2013/FAMED-Net 作者即将放出
dataset:ITS and OTS,< RESIDE and TestSet-S
Daily Computer Vision Papers
| ****Shapes and Context: In-the-Wild Image Synthesis & Manipulation Authors Aayush Bansal, Yaser Sheikh, Deva Ramanan 我们引入了一种数据驱动方法,用于交互式地合成来自语义标签图的野外图像。我们的方法与此领域的近期工作截然不同,因为我们不使用任何学习方法。相反,我们的方法使用简单但经典的工具将场景上下文,形状和部件与存储的样本库进行匹配。虽然简单,但这种方法比近期工作1有几个明显的优势,因为没有学到任何东西,它不仅限于特定的训练数据分布,如城市景观,立面或面部2,它可以合成任意高分辨率的图像,仅受到分辨率的限制。通过适当地组成形状和部分,示例库3,它可以生成指数大的可行候选输出图像集,可以说是由用户交互式搜索。我们在不同的COCO数据集上展示结果,在标准图像合成指标上显着优于基于学习的方法。最后,我们探索用户交互和用户可控性,证明我们的系统可以用作用户驱动的内容创建的平台。 |
| **Clouds of Oriented Gradients for 3D Detection of Objects, Surfaces, and Indoor Scene Layouts Authors Zhile Ren, Erik B. Sudderth 我们开发了新的表示和算法,用于在杂乱的室内场景中进行三维三维物体检测和空间布局预测。我们首先提出了一个定向梯度COG描述符云,它将对象类别的2D外观和3D姿态联系起来,从而准确地模拟透视投影如何影响感知的图像渐变。为了更好地表示大型物体的3D视觉样式并提供上下文提示以改善小物体的检测,我们引入了潜在的支撑表面。然后,我们提出了曼哈顿体素表示,它更好地捕捉了常见室内环境的3D房间布局几何形状。通过潜在的结构化预测框架来学习有效的分类规则。通过级联分类器捕获类别和布局之间的上下文关系,从而导致超出SUN RGB D数据库的现有技术水平的整体场景假设。 |
| **3-D Surface Segmentation Meets Conditional Random Fields Authors Leixin Zhou, Zisha Zhong, Abhay Shah, Xiaodong Wu 在许多医学图像分析应用中,自动表面分割是重要且具有挑战性的。已经为各种对象分割任务开发了最近的基于深度学习的方法。它们中的大多数是基于分类的方法,例如, U net,它预测每个体素成为目标对象或背景的概率。这些方法的一个问题是缺乏对分割对象的拓扑保证,并且通常需要后处理来推断对象的边界表面。本文提出了一种基于三维卷积神经网络CNN和条件随机场CRF的新型模型,用于解决端到端训练的表面分割问题。据我们所知,这是第一个将3D神经网络与CRF模型应用于直接表面分割的研究。在NCI ISBI 2013 MR前列腺数据集和医学分割十项全能脾脏数据集上进行的实验证明了非常有前景的分割结果。 |
| Rethinking Person Re-Identification with Confidence Authors George Adaimi, Sven Kreiss, Alexandre Alahi 人体识别系统的一个共同挑战是区分具有非常相似外观的人。目前基于交叉熵最小化的学习框架不适合这一挑战。为了解决这个问题,我们建议使用三种方法标记平滑,置信度惩罚和深度变分信息瓶颈来修改表示学习框架中的交叉熵损失和模型置信度。我们的方法的一个关键属性是我们不使用任何手工制作的人类特征,而是将注意力集中在学习监督上。虽然建模置信度的方法没有显示出对象分类等其他计算机视觉任务的显着改进,但我们能够显示其在3个公开可用数据集上重新识别超出最新技术方法的任务的显着影响。我们的分析和实验不仅提供了人们所面临的问题的见解,而且还提供了一个简单而直接的方法来解决这个问题。 |
| Gated CRF Loss for Weakly Supervised Semantic Image Segmentation Authors Anton Obukhov, Stamatios Georgoulis, Dengxin Dai, Luc Van Gool 用于语义分割的现有技术方法依赖于在完全注释的数据集上训练的深度卷积神经网络,已经证明在时间和金钱方面收集都是非常昂贵的。为了弥补这种情况,弱监督方法利用需要少得多的注释努力的其他形式的监督,但是由于这些区域中的监督信号的近似性质,它们通常表现出无法预测精确的对象边界。虽然在提高性能方面取得了很大进展,但许多弱监督方法都是根据自己的具体情况量身定制的。这在重用算法和稳步前进方面提出了挑战。在本文中,我们在处理弱监督语义分割时故意避免这种做法。特别是,我们为标记像素训练具有部分交叉熵损失函数的标准神经网络,并为未标记像素训练我们提出的门控CRF损失。门控CRF损失旨在提供几个重要的资产1它使内核构造具有灵活性,以掩盖不受欢迎的像素位置的影响2它将学习上下文关系卸载到CNN并集中于语义边界3它不依赖于高维过滤和因此具有简单的实现。在整篇论文中,我们介绍了损失函数的优点,分析了弱监督训练的几个方面,并表明我们的纯粹方法实现了基于点击和基于涂鸦的注释的最新技术性能。 |
| **Scale Invariant Fully Convolutional Network: Detecting Hands Efficiently Authors Dan Liu, Dawei Du, Libo Zhang, Tiejian Luo, Yanjun Wu, Feiyue Huang, Siwei Lyu 现有的手检测方法通常遵循具有高计算成本的多级流水线,即特征提取,区域建议,边界框回归和用于旋转区域检测的附加层。在本文中,我们提出了一种新的尺度不变全卷积网络SIFCN,它以端到端的方式进行训练,以有效地检测手部。具体来说,我们以迭代的方式合并从高层到低层的特征映射,与简单地连接它们相比,它可以更好地处理不同规模的手,而且时间开销更少。此外,我们开发了互补加权融合CWF模块,以充分利用多层之间的独特特征来实现尺度不变性。为了处理旋转手部检测,我们提出了旋转图来摆脱复杂的旋转和反旋转层。此外,我们设计了多尺度损失方案,通过增加对网络中间层的监督来显着加速训练过程。与现有技术方法相比,我们的算法具有可比较的精度,在VIVA数据集上的运行速度提高了4.23倍,并以62.5 fps的速度在牛津手检测数据集上实现了更好的平均精度。 |
| On Stabilizing Generative Adversarial Training with Noise Authors Simon Jenni, Paolo Favaro 我们提出了一种新的方法和分析,以稳定的方式训练生成对抗网络GAN。如最近的分析所示,训练通常受到数据空间上邻域数据的概率分布的破坏。我们注意到,即使它们经历相同的过滤,实际数据和生成数据的分布也应该匹配。因此,为了解决有限的支持问题,我们建议通过使用实际和生成的数据分布的不同过滤版本来训练GAN。通过这种方式,过滤不会阻止数据分布的精确匹配,同时通过扩展两个分布的支持来帮助进行培训。作为过滤,我们考虑将来自任意分布的样本添加到数据中,这对应于数据分布与任意分布的卷积。我们还建议学习这些样本的生成,以便在对抗训练中挑战鉴别者。我们表明,即使是最初的minimax GAN配方,我们的方法也能实现稳定且良好的训练。此外,我们的技术可以结合到大多数现代GAN配方中,并导致对几个常见数据集的持续改进。 |
| Mimic and Fool: A Task Agnostic Adversarial Attack Authors Akshay Chaturvedi, Utpal Garain 目前,对抗性攻击是以任务特定的方式设计的。然而,对于下游计算机视觉任务,例如图像字幕,图像分割等,当前的深度学习系统使用诸如VGG16,ResNet50,Inception v3等的图像分类器作为特征提取器。牢记这一点,我们提出了Mimic和Fool,一种与任务无关的对抗性攻击。给定特征提取器,所提出的攻击找到可以模仿原始图像的图像特征的对抗图像。这确保了两个图像无论任务如何都给出相同或相似的输出。我们随机选择1000个MSCOCO验证图像进行实验。我们对两个图像字幕模型,Show和Tell,Show Attend和Tell以及一个VQA模型,即端到端神经模块网络N2NMN进行实验。对于Show and Tell,Show Attend和Tell以及N2NMN,提议的攻击成功率分别为74.0,81.0和89.6。我们还建议对我们的攻击稍作修改,以生成看起来自然的对抗图像。此外,它表明所提出的攻击也适用于可逆架构。由于Mimic和Fool只需要有关模型特征提取器的信息,因此可以将其视为灰盒攻击。 |
| Joint Subspace Recovery and Enhanced Locality Driven Robust Flexible Discriminative Dictionary Learning Authors Zhao Zhang, Jiahuan Ren, Weiming Jiang, Zheng Zhang, Richang Hong, Shuicheng Yan, Meng Wang 我们提出了一种联合子空间恢复和基于增强局部性的鲁棒灵活标签一致字典学习方法,称为鲁棒灵活判别字典学习RFDDL。 RFDDL主要通过增强稀疏误差的鲁棒性和更准确地编码局部性,重建误差和标签一致性来改进数据表示和分类能力。首先,对于数据和原子中噪声和稀疏误差的鲁棒性,RFDDL旨在联合恢复底层清洁数据和清理原子子空间,然后执行DL并对恢复的子空间中的位置进行编码。其次,为了能够潜在地处理从非线性流形采样的数据并通过避免过度拟合来获得精确的重建,RFDDL以灵活的方式最小化重建误差。第三,为了准确地编码标签一致性,RFDDL涉及有区别的灵活稀疏码错误以促使系数变软。第四,为了很好地编码局部性,RFDDL定义了恢复原子上的拉普拉斯矩阵,包括在类内紧致性和类间分离方面的原子标签信息,并与组稀疏码和分类器相关联,以获得准确的判别局部约束系数和分类。公共数据库的广泛结果显示了我们的RFDDL的有效性。 |
| Challenges in Time-Stamp Aware Anomaly Detection in Traffic Videos Authors Kuldeep Marotirao Biradar, Ayushi Gupta, Murari Mandal, Santosh Kumar Vipparthi 交通视频中的时间戳识别异常检测是智能交通系统发展的重要任务。由于异常事件的稀疏发生,不同类型异常的不一致行为以及正常和异常情况下的不平衡可用数据,视频中的异常检测是一个具有挑战性的问题。在本文中,我们提出了一个三阶段管道来学习视频中的运动模式以检测视觉异常。首先,从最近的历史帧估计背景以识别静止的对象。该背景图像用于定位帧内的正常异常行为。此外,我们在估计的背景中检测感兴趣的对象,并基于时间戳识别异常检测算法将其分类为异常。我们还讨论了在改善交通异常检测的看不见的测试数据方面所面临的挑战。实验在NVIDIA AI城市挑战2019的第3轨道上进行。结果显示了所提出的方法在检测交通道路视频中的时间戳感知异常方面的有效性。 |
| ***CVPR19 Tracking and Detection Challenge: How crowded can it get? Authors Patrick Dendorfer, Hamid Rezatofighi, Anton Milan, Javen Shi, Daniel Cremers, Ian Reid, Stefan Roth, Konrad Schindler, Laura Leal Taixe 标准化基准测试对于大多数计算机视觉应用至关重要。虽然排行榜和排名表不应过度宣称,但基准通常提供最客观的绩效衡量标准,因此是研究的重要指南。 |
| Learning robust visual representations using data augmentation invariance Authors Alex Hern ndez Garc a, Peter K nig, Tim C. Kietzmann 训练用于图像对象分类的深度卷积神经网络与在灵长类动物腹侧视觉流中发现的表示显示出显着的相似性。然而,人工和生物网络仍然表现出重要的差异。在这里,我们研究了一个这样的属性增加不变性,以保持沿腹侧流发现的身份保持图像变换。尽管有理论证据表明不变性应该从优化过程中自然出现,但我们提出了经验证据,即对于对象分类训练的卷积神经网络的激活对于数据增强中常用的身份保持图像变换不具有鲁棒性。作为解决方案,我们提出数据增强不变性,无监督学习目标,其通过促进增强图像样本的激活之间的相似性来改善学习表示的鲁棒性。我们的结果表明,这种方法是一种简单,有效和高效的训练时间增加方式,在增加模型的不变性的同时获得相似的分类性能。 |
| Simultaneously Learning Architectures and Features of Deep Neural Networks Authors Tinghuai Wang, Lixin Fan, Huiling Wang 本文提出了一种新方法,可以在多个时期内同时重复学习滤波器和网络特征的数量。我们提出了一种新颖的修剪损失,以明确强制优化器专注于有希望的候选过滤器,同时抑制不太相关的过滤器的贡献。同时,我们进一步建议强制过滤器之间的多样性,这种基于多样性的正则化术语改善了模型大小和精度之间的权衡。结果表明,体系结构和特征优化之间的相互作用改进了最终的压缩模型,并且所提出的方法在模型大小和精度方面与现有方法相比有利,适用于广泛的应用,包括图像分类,图像压缩和音频分类。 |
| Cross-Modal Relationship Inference for Grounding Referring Expressions Authors Sibei Yang, Guanbin Li, Yizhou Yu 将引用表达式接地是一项基本但具有挑战性的任务,有助于物理世界中的人机交流。它基于对引用自然语言表达与图像之间的关系的理解来定位图像中的目标对象。用于接地引用表达式的可行解决方案不仅需要在图像和引用表达式中提取所有必要信息,即对象和它们之间的关系,而且还从提取的信息中计算和表示多模态上下文。遗憾的是,关于接地引用表达式的现有工作不能准确地从引用表达式中提取多顺序关系,并且它们获得的上下文与通过引用表达式描述的上下文存在差异。在本文中,我们提出了一种交叉模态关系提取器CMRE,以自适应地突出显示具有与给定表达式的连接的对象和关系,具有交叉模态注意机制,并将提取的信息表示为语言引导的视觉关系图。此外,我们提出了一种门控图形卷积网络GGCN,通过融合来自不同模式的信息并在结构化关系图中传播多模态信息来计算多模态语义上下文。各种常见基准数据集的实验表明,我们的交叉模态关系推理网络(由CMRE和GGCN组成)优于所有现有技术方法。 |
| TW-SMNet: Deep Multitask Learning of Tele-Wide Stereo Matching Authors Mostafa El Khamy, Haoyu Ren, Xianzhi Du, Jungwon Lee 在本文中,我们介绍了估算由两个具有不同视场的摄像机捕获的场景中元素的真实世界深度的问题,其中第一视场FOV是由广角镜头捕获的宽视场WFOV,以及第二FOV包含在第一FOV中并由远摄变焦镜头捕获。我们指的是估计FOV并集的逆深度的问题,同时利用重叠FOV中的立体声信息,作为远程宽立体匹配TW SM。我们为TW SM问题提出了不同的深度学习解决方案。由于视差与反深度成比例,因此我们训练立体匹配视差估计SMDE网络以估计联合WFOV的视差。我们进一步提出了端到端深度多任务远程广播立体匹配神经网络MT TW SMNet,其同时学习用于WFOV的重叠Tele FOV和单图像逆深度估计SIDE任务的SMDE任务。此外,我们设计了多种融合SMDE和SIDE网络的方法。我们评估TW SM在流行的KITTI和SceneFlow立体数据集上的性能,并通过从远程宽立体图像对合成WFOV上的散景效果来展示其实用性。 |
| Bag of Color Features For Color Constancy Authors Firas Laakom, Nikolaos Passalis, Jenni Raitoharju, Jarno Nikkanen, Anastasios Tefas, Alexandros Iosifidis, Moncef Gabbouj 在本文中,我们提出了一种新的颜色恒常方法,称为Bag of Color Features BoCF,建立在Bag of Features汇集之上。所提出的方法大大减少了照明估计所需的参数的数量。同时,所提出的方法与颜色恒常性假设一致,表明全局空间信息与照明估计无关,并且局部信息边缘等是足够的。此外,BoCF与颜色恒定统计方法一致,可以解释为许多统计方法的基于学习的概括。为了进一步提高光照估计精度,我们提出了一种基于自我关注的BoCF模型的新型注意机制。与现有技术相比,BoCF方法及其变体实现了竞争,同时在三个基准数据集ColorChecker推荐,INTEL TUT版本2和NUS8上需要更少的参数。 |
| **Single Image Blind Deblurring Using Multi-Scale Latent Structure Prior Authors Yuanchao Bai, Huizhu Jia, Ming Jiang, Xianming Liu, Xiaodong Xie, Wen Gao 盲目图像去模糊是计算机视觉中的一个具有挑战性的问题,其旨在仅通过模糊观察来恢复模糊核和潜在清晰图像。受到图像超分辨率之前的流行自我实例的启发,在本文中,我们观察到从模糊观察下采样的粗糙图像大致是潜在清晰图像的低分辨率版本。我们在理论上证明了这种现象,并将足够粗糙的图像定义为未知清晰图像之前的潜在结构。从此之前开始,我们建议在模糊图像金字塔上将最粗糙的图像恢复到最精细的比例,并使用新恢复的清晰图像逐步更新先前的图像。这些粗到精的先验被称为textit Multi Scale Latent Structures MSLS。利用MSLS先验,我们的算法包括两个阶段1我们首先在粗尺度2中初步恢复清晰图像然后我们应用最精细尺度的细化处理以获得最终的去模糊图像。在每个尺度中,为了实现更低的计算复杂度,我们交替执行具有快速局部自我示例匹配的尖锐图像重建,具有误差补偿的加速核估计和快速非盲图像去模糊,而不是计算任何计算上昂贵的非凸起先验。我们进一步扩展了所提出的算法,以解决更具挑战性的非均匀盲图像去模糊问题。大量实验表明,我们的算法能够以更快的运行速度实现与最先进方法相比的竞争结果。 |
| **On the Vector Space in Photoplethysmography Imaging Authors Christian S. Pilz, Vladimir Blazek, Steffen Leonhardt 我们研究了可见波长强度的矢量空间,这些面部视频广泛用作Photoplethysmography Imaging PPGI的输入特征。基于欧几里德空间中的群不变性的理论原理,我们推导出拓扑的变化,其中连续测量之间的相应距离被定义为黎曼流形上的测地线。如几种先前方法所讨论的,传感器信号的这种较低维度嵌入统一了关于特征的平移的不变性属性。生成的算子隐含在特征空间上,不需要任何先验知识,也不需要参数调整。根据已知的血容量变化的扩散过程,所得特征的时变准周期性成形自然地以规范状态空间表示的形式发生。计算复杂度低,实现变得相当简单。在实验期间,操作员通过两个公共数据库上的面部视频实现了强大且有竞争力的心率估计性能。 |
| NAS-FCOS: Fast Neural Architecture Search for Object Detection Authors Ning Wang, Yang Gao, Hao Chen, Peng Wang, Zhi Tian, Chunhua Shen 深度神经网络的成功依赖于重要的架构工程。最近,神经架构搜索NAS已经成为通过自动搜索最佳架构来大大减少网络设计中的手动努力的承诺,尽管通常这种算法需要过多的计算资源,例如几千GPU天。迄今为止,对于具有挑战性的视觉任务,例如物体检测,NAS,尤其是快速版本的NAS,研究较少。这里我们建议搜索具有搜索效率的对象检测器的解码器结构。更具体地说,我们的目标是使用定制的强化学习范例有效地搜索特征金字塔网络FPN以及简单的无锚对象检测器的预测头,即FCOS 20。通过精心设计的搜索空间,搜索算法和评估网络质量的策略,我们能够在大约30个GPU天内有效地搜索超过2,000个架构。所发现的体系结构在COCO数据集上超过了现有的对象检测模型,如Faster R CNN,RetinaNet和FCOS,在AP上1到1.9个点,具有可比较的计算复杂度和内存占用,证明了所提出的NAS用于对象检测的功效。 |
| Few-Shot Point Cloud Region Annotation with Human in the Loop Authors Siddhant Jain, Sowmya Munukutla, David Held 我们提出了一种点云注释框架,该框架采用人类循环学习,能够创建具有每点注释的大点云数据集。来自人类注释器的稀疏标签被迭代地传播以通过经由几个镜头学习范例微调联合任务的预训练模型来生成网络的完整分段。我们表明,所提出的框架显着减少了注释点云所需的人工交互量,而不会牺牲注释的质量。我们的实验还通过注意到随着系统完成的完整注释的数量增加而减少人类交互,建议框架在注释大数据集时的适用性。最后,我们展示了框架的灵活性,以支持同一点云的多个不同注释,从而能够创建具有不同粒度注释的数据集。 |
| iProStruct2D: Identifying protein structural classes by deep learning via 2D representations Authors Loris Nanni, Alessandra Lumini, Federica Pasquali, Sheryl Brahnam 在本文中,我们从蛋白质的多视图2D表示开始解决蛋白质分类的问题。从每个3D蛋白质结构,使用蛋白质可视化软件Jmol生成大量2D投影。这组多视图2D表示包括13种不同类型的蛋白质可视化,其强调蛋白质结构的特定性质,例如,骨架可视化,其显示蛋白质的骨架结构作为Cα原子的痕迹。每种类型的表示用于训练不同的卷积神经网络CNN,并且这些CNN的融合被证明能够利用不同类型的表示的多样性来提高分类性能。另外,通过围绕其中心X,Y和Z视轴均匀旋转蛋白质结构以获得125个图像,获得若干多视图投影。该方法可以被认为是用于改进分类器性能的数据增强方法,并且可以用于训练和测试阶段。所提出的方法对两个数据集的实验评估证明了所提出的方法相对于其他现有技术方法的强度。本文中使用的MATLAB代码可在以下位置获得 |
| Polysemous Visual-Semantic Embedding for Cross-Modal Retrieval Authors Yale Song, Mohammad Soleymani 视觉语义嵌入旨在找到共享的潜在空间,其中相关的视觉和文本实例彼此接近。大多数当前方法学习内射嵌入函数,其将实例映射到共享空间中的单个点。不幸的是,内射嵌入不能有效地处理具有多种可能含义的多义实例,它会找到不同含义的平均表示。这阻碍了它在现实世界场景中的使用,其中个体实例及其交叉模态关联通常是模糊的。在这项工作中,我们介绍了多义实例嵌入网络PIE网络,它通过多头自我关注和残留学习将全局上下文与本地引导的特征相结合来计算实例的多个和不同的表示。为了学习视觉语义嵌入,我们将两个PIE网络绑定在多实例学习框架中共同优化它们。大多数关于交叉模态检索的现有工作都集中在图像文本数据上。在这里,我们还处理了一个更具挑战性的视频文本检索案例。为了促进视频文本检索的进一步研究,我们发布了一个新的数据集,从社交媒体收集的50K视频句子对,称为MRW我的反应。我们使用MS COCO,TGIF和新的MRW数据集演示了我们在图像文本和视频文本检索方案中的方法。 |
| Subspace Attack: Exploiting Promising Subspaces for Query-Efficient Black-box Attacks Authors Ziang Yan, Yiwen Guo, Changshui Zhang 与广泛研究且易于获取的白盒对应物不同,由于难以估计梯度,黑盒设置中的对抗性示例通常更加艰难。许多方法通过向目标分类系统发出大量查询来实现该任务,这使得整个过程对于系统来说是昂贵且可疑的。在本文中,我们旨在降低此类别中黑盒攻击的查询复杂性。我们建议利用一些参考模型的梯度,这些参考模型可以跨越一些有希望的搜索子空间。实验结果表明,与现有技术相比,我们的方法可以在必要的平均值和中等数量的查询中获得高达2倍和4倍的减少,并且故障率低得多,即使参考模型训练较小且不充分数据集与用于训练受害者模型的数据集不相交。用于复制我们结果的代码和模型将公开发布。 |
| Band Attention Convolutional Networks For Hyperspectral Image Classification Authors Hongwei Dong, Lamei Zhang, Bin Zou 在高光谱图像HSI的频带中存在冗余和噪声。因此,对于HSI分类方法,能够从数百个输入频带中选择合适的部分是一个很好的特性。在这封信中,提出了一个频带注意模块BAM来实现基于深度学习的HSI分类,其具有频带选择或加权的能力。所提出的BAM可以被视为现有分类网络的即插即用补充组件,其充分考虑了当使用卷积神经网络CNN进行HSI分类时由频带冗余引起的不利影响。与HSI中使用的大多数深度学习方法不同,根据高光谱图像的特征定制的频带注意模块嵌入在普通CNN中以获得更好的性能。同时,与经典的频带选择或加权方法不同,所提出的方法实现了端到端训练而不是分离的阶段。实验在两个HSI基准数据集上进行。与一些经典和先进的深度学习方法相比,不同评价标准下的数值模拟表明,该方法具有良好的性能。最后但并非最不重要的是,一些先进的CNN与提议的BAM相结合以获得更好的性能。 |
| PAN: Projective Adversarial Network for Medical Image Segmentation Authors Naji Khosravan, Aliasghar Mortazi, Michael Wallace, Ulas Bagci 已经证明,对抗性学习对于在语义分割中捕获长程和高级标签一致性是有效的。医学成像的独特之处在于,以有效且计算有效的方式捕获3D语义仍然是一个悬而未决的问题。在这项研究中,我们通过提出一种称为PAN的新型投射对抗网络来解决这一计算负担,该网络通过2D投影结合了高级3D信息。此外,我们在我们的框架中引入了一个注意力模块,该模块有助于将全球信息直接从我们的分割器选择性地整合到我们的对抗性网络中。对于临床应用,我们选择CT扫描的胰腺分割。我们提出的框架在不增加分段器复杂性的情况下实现了最先进的性能。 |
| Recognizing License Plates in Real-Time Authors Xuewen Yang, Xin Wang 车牌检测和识别LPDR对于实现智能交通和确保城市的安全性非常重要。然而,LPDR在实际环境中面临着巨大的挑战。牌照可以具有极其多样的尺寸,字体和颜色,并且板图像通常由于倾斜的捕获角度,不均匀的照明,遮挡和模糊而导致质量差。在监视等应用中,通常需要快速处理。为了实现实时和准确的车牌识别,在这项工作中,我们提出了一套技术1一种轮廓重建方法以及边缘检测,以快速检测候选板2一个简单的零一交替方案,以有效地去除假的顶部和底部围绕板块的边界以便于在板3上更准确地分割字符3一组技术以增强训练数据,将SIFT特征结合到CNN网络中,并利用转移学习来获得用于更有效训练的初始参数和4两阶段验证以低成本确定正确平板的程序,在平板检测阶段进行统计过滤以快速去除不需要的候选者,以及CR过程之后的准确CR结果,以进行进一步的平板验证而无需额外处理。我们基于算法实现了完整的LPDR系统。实验结果表明,我们的系统可以实时准确识别车牌。此外,它可以在各种水平的照明和噪音下以及在汽车运动的情况下稳健地工作。与对等方案相比,我们的系统不仅是最准确的系统,而且也是最快的系统,可以轻松应用于其他方案。 |
| Object-aware Aggregation with Bidirectional Temporal Graph for Video Captioning Authors Junchao Zhang, Yuxin Peng 视频字幕旨在自动生成视频内容的自然语言描述,近年来引起了很多关注。生成准确且细粒度的字幕不仅需要了解视频的全局内容,还需要捕获详细的对象信息。同时,视频表示对生成的字幕质量有很大影响。因此,视频字幕捕获具有详细时间动态的显着对象并使用判别性时空表示来表示它们是很重要的。在本文中,我们提出了一种新的基于对象感知聚合的视频字幕方法和双向时间图OA BTG,它捕获视频中显着对象的详细时间动态,并通过对检测到的对象执行对象感知局部特征聚合来学习判别性时空表示。区域。主要的新颖性和优点是1双向时间图双向时间图沿着时间顺序构建并反向构建,提供了捕获每个显着对象的时间轨迹的互补方式。 2对象感知聚合可学习的局部聚合描述符模型的VLAD向量在对象时间轨迹和全局帧序列上构建,其执行对象感知聚合以学习判别性表示。还开发了分层注意机制以区分多个对象的不同贡献。两个广泛使用的数据集上的实验证明我们的OA BTG在BLEU 4,METEOR和CIDEr指标方面达到了最先进的性能。 |
| ***Hybrid Function Sparse Representation towards Image Super Resolution Authors Junyi Bian, Baojun Lin, Ke Zhang 基于训练的字典的稀疏表示已经在超分辨率SR上显示成功但仍然具有一些限制。基于在不失去其保真度的情况下进行函数曲线放大的思想,我们提出了一种基于函数的超分辨率稀疏表示字典,称为混合函数稀疏表示HFSR。我们设计的字典直接由预设的混合功能生成,无需额外的培训,由于其可扩展的属性,可以根据需要缩放到任何大小。我们将近似的Heaviside函数AHF,正弦函数和DCT函数混合为字典。然后提出多尺度细化以利用字典的可缩放属性来改善结果。此外,采用重建策略来处理重叠。在Set14 SR数据集上的实验表明,与基于非学习的现有技术方法相比,我们的方法具有优异的性能,特别是对于包含丰富细节和上下文的图像。 |
| ***FAMED-Net: A Fast and Accurate Multi-scale End-to-end Dehazing Network Authors Jing Zhang, Dacheng Tao 单图像去雾是后续高级计算机视觉任务的关键图像预处理步骤。然而,由于其不良的性质,它仍然具有挑战性。现有的去雾模型倾向于遭受模型过复杂性和计算效率低下或具有有限的表示能力。为了应对这些挑战,我们在此提出了一种快速,准确的多尺度端到端去雾网络,称为FAMED Net,它包括三个刻度的编码器和一个融合模块,可以高效,直接地学习无雾图像。每个编码器由级联和密集连接的点式卷积层和池化层组成。由于没有使用更大的卷积内核并且逐层重用特征,因此FAMED Net具有轻量级和计算效率。对包括RESIDE和真实世界模糊图像在内的公共合成数据集进行的全面实证研究表明,FAMED网络在模型复杂性,计算效率,恢复精度和交叉集概括方面优于其他代表性的现有模型。该代码将公开发布。 |
| Online Object Representations with Contrastive Learning Authors S ren Pirk, Mohi Khansari, Yunfei Bai, Corey Lynch, Pierre Sermanet 我们提出了一种自我监督的方法,用于学习单目视频对象的表示,并证明它在机器人等位置设置中特别有用。本文的主要贡献是1一个自我监督的目标,通过对比学习训练,可以发现和解开视频中的对象属性而不使用任何标签2我们利用对象自我监督进行在线自适应我们的在线模型看待视频中的对象的时间越长,对象识别错误越低,而离线基线仍然存在大的固定误差3,以探索完全没有人为监督的系统的可能性,我们让机器人收集自己的数据,用我们的自我监督方案训练这些数据,然后显示机器人可以指向类似于前面呈现的对象的对象,展示对象属性的概括。这种方法的一个有趣且可能令人惊讶的发现是,给定一组有限的对象,当使用对比学习而不需要明确的正对时,对象对应自然会出现。可在以下网址获取说明在线对象调整和机器人指向的视频 |
| Semantic-guided Encoder Feature Learning for Blurry Boundary Delineation Authors Dong Nie, Dinggang Shen 编码器解码器架构广泛用于医学图像分割任务。通过横向跳过连接,模型可以在深层中获取并融合语义和分辨率信息,以实现更准确的分割性能。然而,在许多应用中,例如模糊的边界图像,这些模型通常不能精确地定位复杂的边界并且分割出微小的孤立部分。为了解决这个具有挑战性的问题,我们首先分析为什么简单的跳过连接不足以帮助准确定位模糊边界,并认为这是由于编码器层中提供的跳过连接中的模糊信息。然后,我们提出了一种语义引导的编码器特征学习策略,以学习高分辨率和丰富的语义编码器特征,以便我们可以更准确地定位模糊边界,这也可以通过选择性地学习判别特征来增强网络。此外,我们进一步提出了一种软轮廓约束机制来模拟模糊边界检测。实际临床数据集的实验结果表明,我们提出的方法可以实现最先进的分割精度,特别是对于模糊区域。进一步分析还表明,我们提出的网络组件确实有助于提高性能。对其他数据集的实验验证了我们提出的方法的泛化能力。 |
| SymNet: Symmetrical Filters in Convolutional Neural Networks Authors Gregory Dzhezyan, Hubert Cecotti 对称性存在于自然和科学中。在图像处理中,用于空间滤波的内核具有一些对称性,例如,索贝尔算子,高斯,拉普拉斯算子。人工前馈神经网络中的卷积层通常在没有任何约束的情况下考虑核权重。在本文中,我们建议研究卷积层中对称约束对图像分类任务的影响,从初级视觉皮层和常见图像处理技术中涉及的过程中获取灵感。目标是通过修改在反向传播算法期间执行的权重更新并评估性能变化来评估在整个卷积神经网络CNN的训练过程中对过滤器实施对称约束的程度。本文的主要假设是对称约束减少了网络中自由参数的数量,并且能够实现与现代训练方法几乎相同的性能。特别地,我们解决了以下情况:轴对称,点反射和反点反射。已经在四个图像数据库上评估了性能。结果支持这样的结论:虽然随机权重为模型提供了更多的自由度,但对称约束提供了类似的性能水平,同时大大减少了模型中自由参数的数量。这种方法在需要整个特征提取过程中具有线性相位特性的相敏应用中是有价值的。 |
| FASTER Recurrent Networks for Video Classification Authors Linchao Zhu, Laura Sevilla Lara, Du Tran, Matt Feiszli, Yi Yang, Heng Wang 视频分类方法通常将视频分成短片段,独立地对这些片段进行推断,然后聚合这些预测以生成最终的分类结果。将这些高度相关的剪辑视为独立的两者都忽略了信号的时间结构并且带来了大的计算成本,模型必须从头开始处理每个剪辑。为了降低这种成本,最近的努力集中在设计更有效的剪辑级网络架构上。然而,对整体框架的关注较少,包括如何从相邻剪辑之间的相关性中受益以及改进聚合策略本身。在本文中,我们利用相邻视频剪辑之间的相关性来解决聚合阶段视频分类中计算成本效率的问题。更具体地,给定剪辑特征表示,计算下一剪辑表示的问题变得更容易。我们提出了一种名为FASTER的新型复现架构,用于视频级分类,它结合了高质量,昂贵的剪辑表示,捕捉细节的动作,以及轻量级表示,捕捉视频中的场景变化并避免冗余计算。我们还提出了一种新颖的处理单元来学习剪辑级表示的集成,以及它们的时间结构。我们将此单元称为FAST GRU,因为它基于门控循环单元GRU。所提出的框架在推理时间上实现了明显更好的FLOP与准确度之间的折衷。与现有方法相比,我们提出的框架将FLOP减少了10倍以上,同时在流行数据集(例如Kinetics,UCF101和HMDB51)中保持相似的准确性。 |
| ****End-to-End CAD Model Retrieval and 9DoF Alignment in 3D Scans Authors Armen Avetisyan, Angela Dai, Matthias Nie ner 我们提出了一种新颖的端到端方法,将CAD模型与场景的3D扫描对齐,从而将嘈杂,不完整的3D扫描转换为紧凑的CAD重建,并使用干净,完整的物体几何体。我们的主要贡献在于制定可区分的Procrustes对齐,该对齐与对称感知密集对象对应预测配对。为了同时将CAD模型与扫描场景的所有对象对齐,我们的方法检测对象位置,然后预测在统一对象空间中扫描和CAD几何体之间的对称感知密集对象对应关系,以及最近邻CAD模型,两者都是然后用于通知可区分的Procrustes对齐。我们的方法以完全卷积的方式运行,使CAD模型能够在单个前向传递中与扫描对象对齐。这使得我们的方法在19.04时能够胜过最先进的方法,用于CAD模型与扫描的对齐,运行时间比以前的数据驱动方法快约250倍。 |
| Data-Free Quantization through Weight Equalization and Bias Correction Authors Markus Nagel, Mart van Baalen, Tijmen Blankevoort, Max Welling 我们介绍了一种不需要微调或超参数选择的深度神经网络的无数据量化方法。它在常见的计算机视觉架构和任务上实现了接近原始的模型性能。 8位定点量化对于现代深度学习硬件架构中的有效推理至关重要。然而,量化模型以8位运行是一项非常重要的任务,经常导致显着的性能降低或者在训练网络上花费的工程时间适合于量化。我们的方法依赖于通过利用激活函数的尺度等效性来均衡网络中的权重范围。此外,该方法校正在量化期间引入的误差中的偏差。这提高了量化精度性能,并且可以通过直接的API调用无处不在地应用于几乎任何模型。对于常见的体系结构,例如MobileNet系列,我们实现了最先进的量化模型性能。我们进一步表明,该方法还扩展到其他计算机视觉架构和任务,如语义分割和对象检测。 |
| Automatic brain tissue segmentation in fetal MRI using convolutional neural networks Authors N. Khalili, N. Lessmann, E. Turk, N. Claessens, R. de Heus, T. Kolk, M.A. Viergever, M.J.N.L. Benders, I. Isgum 胎儿的MR图像允许临床医生在发育的早期阶段检测脑异常。胎儿MRI中体积和形态分析的基石是将胎儿大脑分成不同的组织类别。手动分割是麻烦且耗时的,因此自动分割可以大大简化过程。然而,由于包括强度不均匀性的伪影,这些扫描中的自动脑组织分割是挑战性的,特别是由扫描期间的自发胎儿运动引起的。与估计偏移场以消除强度不均匀性作为分割的预处理步骤的方法不同,我们建议使用卷积神经网络进行分割,该网络利用合成引入的强度不均匀性的图像作为数据增强。该方法首先使用CNN来提取颅内体积。此后,采用具有相同结构的另一CNN将提取的体积分成七个脑组织类别小脑,基底神经节和丘脑,脑室脑脊液,白质,脑干,皮质灰质和脑脊髓液。为了使该方法适用于显示强度不均匀性伪影的切片,通过将线性梯度与随机偏移和方向的组合应用于没有伪影的图像切片来增强训练数据。 |
| Generative adversarial network for segmentation of motion affected neonatal brain MRI Authors N. Khalili, E. Turk, M. Zreik, M.A. Viergever, M.J.N.L. Benders, I. Isgum 早产儿自动新生儿脑组织分割是评估大脑发育的先决条件。然而,自动分割经常受到图像采集期间婴儿头部运动引起的运动伪影的阻碍。已经开发了使用频域数据在图像重建期间去除或最小化这些伪像的方法。但是,频域数据可能并不总是可用。因此,在本研究中,我们提出了一种从已经重建的MR扫描中去除运动伪影的方法。该方法采用以循环一致性损失训练的生成对抗网络,以将受运动影响的切片转换成没有运动伪影的切片,反之亦然。在实验中,使用40个在经后年龄30周时成像的早产婴儿的T2加权冠状MR扫描。所有图像都包含受运动伪影影响的切片,妨碍了自动组织分割。为了评估校正是否允许更准确的图像分割,图像被分割成8个组织类别小脑,有髓白质,基底神经节和丘脑,脑室脑脊液,白质,脑干,皮质灰质和脑脊髓液。使用5点李克特量表定性评估针对运动和相应分割校正的图像。在校正运动伪影之前,中值图像质量和相应自动分割的质量分别被分配为2级差和3级中等。在校正运动伪影之后,两者分别改善到3级和4级。结果表明,使用所提出的方法校正图像空间中的运动伪影允许在受运动伪影影响的切片中精确分割脑组织类别。 |
| On Single Source Robustness in Deep Fusion Models Authors Taewan Kim, Joydeep Ghosh 融合多个输入源的算法受益于互补和共享信息。共享信息可以为故障或噪声输入提供稳健性,这对于自驾车等安全关键应用是必不可少的。我们研究了学习融合算法,该算法能够抵抗单个来源的噪声。我们首先证明在线性融合模型中不能保证对单源噪声的鲁棒性。在这一发现的推动下,提出了两种可能的方法来提高鲁棒性,使用相应的深度融合模型训练算法,以及在处理噪声方面具有结构优势的简单卷积融合层来提高精确设计的损耗。实验结果表明,训练算法和我们的融合层都使得基于深度融合的三维物体探测器能够抵抗应用于单个声源的噪声,同时保持原始性能对干净的数据。 |
| `Project & Excite' Modules for Segmentation of Volumetric Medical Scans Authors Anne Marie Rickmann, Abhijit Guha Roy, Ignacio Sarasua, Nassir Navab, Christian Wachinger 完全卷积神经网络F CNN实现了医学成像中图像分割的最先进性能。最近,已经引入挤压和激励SE模块及其变型以重新校准特征图通道和空间方式,这可以提高性能同时仅最小化地增加模型复杂性。到目前为止,SE的发展主要集中在2D图像上。在本文中,我们提出了基于SE思想的Project Excite PE模块,并将它们扩展到3D体积图像上。 Project Excite不执行全局平均合并,而是分别沿着张量的不同切片挤压特征贴图以保留随后在激励步骤中使用的更多空间信息。我们证明了PE模块可以轻松集成到3D U Net中,通过5个Dice点提升性能,同时仅将模型复杂度提高2倍。我们评估PE模块的两个具有挑战性的任务,MRI扫描的全脑分割和CT扫描的全身分割。码 |
| DropConnect Is Effective in Modeling Uncertainty of Bayesian Deep Networks Authors Aryan Mobiny, Hien V. Nguyen, Supratik Moulik, Naveen Garg, Carol C. Wu 深度神经网络DNN已经在许多重要领域实现了最先进的性能,包括医疗诊断,安全性和自动驾驶。在安全性非常关键的这些领域,错误的决策可能导致严重的后果。虽然完美的预测准确性并不总是可以实现,但贝叶斯深度网络的最新工作表明,有可能知道DNN何时更容易出错。了解DNN不知道的内容对于提高敏感应用中深度学习技术的安全性是可取的。贝叶斯神经网络试图解决这一挑战。然而,传统方法在计算上难以处理,并且不能很好地扩展到大型复杂的神经网络架构。在本文中,我们通过对模型权重施加伯努利分布,建立了一个理论框架来逼近DNN的贝叶斯推断。这种称为MC DropConnect的方法为我们提供了一种工具来表示模型的不确定性,而整体模型结构或计算成本几乎没有变化。我们在多个网络架构和数据集上广泛验证了所提出的算法,用于分类和语义分段任务。我们还提出了新的指标来量化不确定性估计。这使得MC DropConnect与先前方法之间能够进行客观比较。我们的实证结果表明,与现有技术相比,所提出的框架在预测准确性和不确定性估计质量方面产生显着改善。 |
| ***Anomaly Detection in High Performance Computers: A Vicinity Perspective Authors Siavash Ghiasvand, Florina M. Ciorba 响应于对更高计算能力的需求,高性能计算机HPC中的计算节点的数量迅速增加。 Exascale HPC系统预计到2020年到货。随着HPC系统组件数量的急剧增加,预计会出现故障数量的突然增加,从而对HPC系统的持续运行构成威胁。尽早检测故障并理想地预测故障是避免HPC系统运行中断的必要步骤。异常检测是计算系统中用于故障检测的众所周知的通用方法。大多数现有方法是针对特定体系结构设计的,需要对计算系统硬件和软件进行调整,需要过多信息,或对用户和系统隐私构成威胁。该工作提出了一种基于基于邻近的统计异常检测方法的节点故障检测机制,该方法使用被动收集和匿名的系统日志条目。将所提出的方法应用于8个月内收集的系统日志表明异常检测精度在62到81之间。 |
| BasisConv: A method for compressed representation and learning in CNNs Authors Muhammad Tayyab, Abhijit Mahalanobis 众所周知,卷积神经网络CNN在其滤波器权重方面具有显着的冗余。在文献中已经提出了各种方法来压缩训练的CNN。这些包括诸如修剪权重,滤波器量化和根据基函数表示滤波器的技术。我们的方法属于后一类策略,但不同之处在于我们展示了压缩学习和表示都可以在不对流行的CNN架构进行重大修改的情况下实现。具体来说,CNN的任何卷积层很容易被两个连续的卷积层取代,第一个是一组固定的滤波器,它们代表整个层的知识空间而不会改变,后面是一层代表一维滤波器这个领域的学识渊博。对于预训练的网络,固定层只是原始滤波器的截断特征分解。 1D滤波器初始化为线性组合的权重,但经过微调以恢复由于截断引起的任何性能损失。为了从头开始训练网络,我们使用一组永不改变的随机正交固定滤波器,并直接从标记数据中学习一维权重向量。我们的方法在训练期间大大减少了可学习参数的数量,以及ii在实现期间的乘法运算和滤波器存储要求的数量。它不需要卷积层中的任何特殊运算符,并且扩展到所有已知的流行CNN架构。我们将我们的方法应用于使用三种不同数据集训练的四种众所周知的网络架构。结果显示,操作次数最多可减少5倍,ii可学习参数数量最多减少18倍,CIFAR100数据集性能下降不到3次。 |
| A Novel Cost Function for Despeckling using Convolutional Neural Networks Authors Giampaolo Ferraioli, Vito Pascazio, Sergio Vitale 从SAR图像中去除斑点噪声仍然是一个悬而未决的问题。众所周知,对SAR图像的解释是非常具有挑战性的,并且为了提高提取信息的能力,必须使用去斑算法。由于不同的结构和不同的物体尺度,城市环境使这项任务更加沉重。随着最近与几种遥感应用相关的深度学习方法的普及,本文提出了一种基于卷积神经网络的去斑算法。网络接受模拟SAR数据的训练。本文主要关注成本函数的实现,该成本函数考虑了图像的空间一致性和噪声的统计特性。 |
| Deep learning analysis of cardiac CT angiography for detection of coronary arteries with functionally significant stenosis Authors Majd Zreik, Robbert W. van Hamersvelt, Nadieh Khalili, Jelmer M. Wolterink, Michiel Voskuil, Max A. Viergever, Tim Leiner, Ivana I gum 在患有阻塞性冠状动脉疾病的患者中,需要确定冠状动脉狭窄的功能意义以指导治疗。这通常通过在侵入性冠状动脉血管造影ICA期间执行的分数流量储备FFR测量来建立。我们提出了一种自动和非侵入性检测功能显着的冠状动脉狭窄的方法,采用心脏CT血管造影CCTA图像中的完整冠状动脉的深度无监督分析。我们回顾性收集了187例患者的CCTA扫描,其中137例在192个不同的冠状动脉中进行了侵入性FFR测量。这些FFR测量值作为冠状动脉狭窄的功能意义的参考标准。提取冠状动脉的中心线并用于重建拉直的多平面重新格式化的MPR体积。为了自动识别具有功能上显着的狭窄的动脉,使用分别执行空间和顺序编码的两个不相交的3D和1D卷积自动编码器将每个MPR体积编码成固定数量的编码。此后,使用支持向量机分类器,根据功能上显着的狭窄的存在,使用这些编码来对动脉进行分类。使用重复交叉验证实验评估的功能上显着的狭窄的检测导致接收器操作特征曲线下面积在动脉水平上为0.81pm 0.02,在患者水平上为0.87pm 0.02。结果表明,使用CCTA图像中完整冠状动脉的特征,自动非侵入性检测冠状动脉中功能上显着的狭窄是可行的。这可能会减少不必要地接受ICA的患者数量。 |
| SALT: Subspace Alignment as an Auxiliary Learning Task for Domain Adaptation Authors Kowshik Thopalli, Jayaraman J. Thiagarajan, Rushil Anirudh, Pavan Turaga 无监督域适应旨在将从标记源域学到的知识转移和调整到未标记的目标域。无监督域自适应的关键组件包括在源上最大化性能,以及b对齐源域和目标域。传统上,这些任务要么被认为是独立的,要么被假定为与高容量特征提取器一起隐式地解决。在本文中,我们提出了第三种广泛的方法,我们称之为SALT。核心思想是将对齐作为辅助任务,将最大化源性能的主要任务考虑在内。通过假设子空间形式的易处理数据几何,使辅助任务变得相当简单。我们协同地允许来自封闭形式辅助解决方案的某些参数受到来自主要任务的梯度的影响。所提出的方法代表了基于几何和基于模型的对齐与来自数据驱动的主要任务的梯度流的独特融合。 SALT很简单,根植于理论,并且在多个标准基准测试中表现优于最新技术水平。 |
| Multiscale Nakagami parametric imaging for improved liver tumor localization Authors Omar S. Al Kadi 有效的超声组织表征通常受到复杂组织结构的阻碍。散斑图案的交织使得反向散射分布参数的正确估计复杂化。基于局部形状参数映射的Nakagami参数化成像可以模拟不同的后向散射条件。然而,构建的Nakagami图像的性能取决于估计方法对反向散射统计和分析规模的敏感性。在估计Nakagami参数图像时使用感兴趣的固定焦点区域将增加估计方差。在这项工作中,通过多尺度基础上的最大似然估计自适应地估计局部Nakagami参数。变尺寸内核在多个尺度上集成了后向散射分布参数的拟合优度,以实现更稳定的参数估计。结果显示组织镜面反射变化的定量可视化改善,表明在低对比度超声图像中改善肿瘤定位的潜在方法。 |
| Adaptively Preconditioned Stochastic Gradient Langevin Dynamics Authors Chandrasekaran Anirudh Bhardwaj 随机梯度Langevin动力学向SGD注入各向同性梯度噪声,以帮助导航深层网络损失景观中的病理曲率。噪声的各向同性本质导致不良的缩放,并且已经提出了基于诸如Fisher Scoring的高阶曲率信息的自适应方法来预处理噪声以便实现更好的收敛。在本文中,我们描述了一种估计噪声参数的自适应方法,并在众所周知的模型架构上进行实验,以表明自适应预处理SGLD方法与Adam,AdaGrad等自适应一阶方法的速度实现收敛。在测试集中实现SGD的泛化等价。 |
| Transport Triggered Array Processor for Vision Applications Authors Mehdi Safarpour, Ilkka Hautala, Miguel Bordallo Lopez, Olli Silven 许多物联网中的低级感官数据处理物联网设备通过利用睡眠模式或将时钟减慢到最小来追求能效。为了抑制那些设计中的待机功耗的份额,采用接近阈值的子阈值操作点或制造中的超低泄漏过程。这些会显着限制时钟速率,从而降低各个处理内核的计算吞吐量。在此贡献中,我们探索通过大规模并行化来补偿在接近阈值区域Vdd 0.6V下操作的性能损失。近阈值操作和大规模并行性的好处分别是每指令操作的最佳能量消耗和最小化的存储器往返。设计的处理元件PE基于传输触发架构。细粒度可编程并行解决方案允许快速有效地计算可学习的低级特征,例如,本地二进制描述符和卷积。其他操作,包括Max pooling也已实施。可编程设计实现了局部二进制模式计算的出色能效。 |
| Identifying Visible Actions in Lifestyle Vlogs Authors Oana Ignat, Laura Burdick, Jia Deng, Rada Mihalcea 我们认为识别在线视频中可见的人类行为的任务。我们专注于广泛传播的生活方式视频博客类型,其中包括人们在口头描述时执行操作的视频。我们的目标是确定视频的语音描述中提到的动作是否在视觉上呈现。我们构建了一个包含可见动作的众包手动注释的数据集,并引入了一种多模式算法,该算法利用从视觉和语言线索中获得的信息来自动推断视频中哪些动作是可见的。我们证明了我们的多模态算法一次只能基于一种模态优于算法。 |
| BowNet: Dilated Convolution Neural Network for Ultrasound Tongue Contour Extraction Authors M. Hamed Mozaffari, Won Sook Lee 超声成像安全,相对实惠,并且具有实时性能。该技术的一个应用是在实时演讲期间可视化和表征人类舌头的形状和运动,以研究健康或受损的语音产生。由于具有低对比度特性的超声图像的嘈杂性质,可能需要非专业用户的专业知识来识别器官形状,例如舌头表面背部。为了减轻舌头形状和运动的定量分析的这种困难,可以提取,跟踪和可视化舌头表面而不是整个舌头区域。从每个框架描绘舌头表面是麻烦的,主观的和容易出错的任务。此外,舌头手势的快速性和复杂性使其成为具有挑战性的任务,并且手动分割对于实时应用来说不是可行的解决方案。利用现有技术的深度神经网络模型和训练技术,实现具有实时性能的全自动,准确,鲁棒的分割方法是可行的,适用于语音中舌头轮廓的跟踪。本文介绍了两种新的深度神经网络模型,名为BowNet,wBowNet受益于全局预测解码编码模型的能力,具有集成的多尺度上下文信息,以及扩散卷积的全分辨率局部提取能力。使用多个超声舌图像数据集的实验结果表明,定位和全球搜索的结合可以显着提高预测结果。使用定性和定量研究对BowNet模型的评估表明,与类似技术相比,它们在准确性和稳健性方面取得了显着成就。 |
| Alzheimer's Disease Brain MRI Classification: Challenges and Insights Authors Yi Ren Fung, Ziqiang Guan, Ritesh Kumar, Joie Yeahuay Wu, Madalina Fiterau 近年来,许多论文报道了使用卷积神经网络从阿尔茨海默氏病神经影像学计划ADNI数据集进行MRI扫描的阿尔茨海默病分类的最新技术表现。然而,我们发现,当我们将这些数据分成主题级别的培训和测试集时,我们无法获得类似的性能,从而使许多先前研究的有效性受到质疑。此外,我们指出以前的工作使用不同的ADNI数据子集,使得在类似工作中的比较变得棘手。在这项研究中,我们提出三种分裂方法的结果,讨论其有效性背后的动机,并使用所有可用的主题报告我们的结果。 |
| **Human-Machine Collaboration for Fast Land Cover Mapping Authors Caleb Robinson, Anthony Ortiz, Kolya Malkin, Blake Elias, Andi Peng, Dan Morris, Bistra Dilkina, Nebojsa Jojic 我们建议将人类贴标机纳入模型微调系统,以提供即时的用户反馈。在我们的框架中,人类贴标签者可以交互式地查询未标记数据的模型预测,选择要标记的数据,并查看对模型预测产生的影响。这种双向反馈回路允许人们了解模型如何响应新数据。我们的假设是,这种丰富的反馈允许人类贴标者创建心理模型,使他们能够更好地选择引入模型的偏差。我们将人类选择点与使用标准主动学习方法选择的点进行比较。我们进一步研究微调方法如何影响人类贴标机的性能。我们实现了这个框架,用于微调高分辨率土地覆盖分割模型。具体来说,我们微调了一个深度神经网络,该网络训练将高分辨率航空影像分割成美国马里兰州的不同土地覆盖类别,到达美国纽约的一个新的空间区域。紧密循环将算法和人类操作员转变为混合系统,可以比传统工作流程更有效地生成大面积的土地覆盖图。我们的框架在地理空间机器学习环境中具有应用,其中实际上无限制地提供未标记数据,其中只有一小部分可以通过人工努力进行标记。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com



