这官网点击查看源码发现 毛都没有。。
这能这样,进入这个页面并点击第一个英雄

发现

然后查看第二个英雄同个地方的url
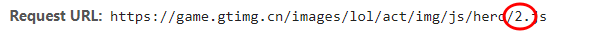
发现除了这个数字其他一样 嘿嘿。。 遍历全英雄的问题解决了
然后查看服务器返回的信息


都是明文的json数据,太棒了
到这里其实需要的信息已经收集完了,可以写代码了 ,先说一下实际运行碰到的问题:
url编号不规律 不是146 而是555
其中有的炫彩皮肤没有url
好了附上代码:
import os
import json
import requests
def get_url(url, hander): #获取页面数据try:r = requests.get(url, headers=hander, timeout=30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept requests.exceptions.ConnectTimeout:print("(1)连接超时")return ""except requests.exceptions.HTTPError as e:print(e)return ""def prasing_page(html, hander, n):s = 0 #定义变量方便一会儿输出进度条py_data = json.loads(html) #json数据转换成python数据hero_skins_list = py_data['skins']os.mkdir('O:\lol_hero_jpg\\'+hero_skins_list[0]['heroName']+'--'+hero_skins_list[0]['heroTitle']) #创建文件夹os.chdir('O:\lol_hero_jpg\\'+hero_skins_list[0]['heroName']+'--'+hero_skins_list[0]['heroTitle']) #进入文件夹for i in hero_skins_list:try: #如果有问题跳过本次循环进行下一次if i['mainImg'] == "": #如果图片url为空则跳过本次循环continues = s + 1with open(i['name']+'.jpg', 'wb') as f:r = requests.get(i['mainImg'], headers=hander, timeout=30)f.write(r.content)f.close()print("\r当前进度>>>第 {} 位英雄 {} >>>{:.0f}%----------总进度{:.0f}%".format(n, hero_skins_list[0]['heroTitle'], s * 100 / len(hero_skins_list), n * 100/146), end="")except:continue
def main():hander = {"User-Agent": "Mozilla/5.0"}hero_number = 555n = 0 #变量表示第几位英雄for i in range(hero_number):try:n = n+1url = "https://game.gtimg.cn/images/lol/act/img/js/hero/"+str(i+1)+".js"html = get_url(url, hander)prasing_page(html, hander, n)except:n = n - 1continue
main()
运行效果:


最后附上几张比较喜欢的英雄原画^_^