欢迎关注,本专栏主要更新MATLAB仿真、界面、基础编程、画图、算法、矩阵处理等操作,拥有丰富的实例练习代码,欢迎订阅该专栏!(等该专栏建设成熟后将开始收费,快快上车吧~~)
【MATLAB数学建模编程实战】Kmeans算法编程及算法的简单原理
kmeans算法是比较简单的一个算法,K-Means算法是一种「无监督」的聚类算法。什么叫无监督呢?就是对于训练集的数据,在训练的过程中,并没有告诉训练算法某一个数据属于哪一个类别。对于K-Means算法来说,他就是通过某一些骚操作,将一堆“相似”的数据聚集在一起然后当作同一个类别。例如下图:最后将数据聚集成了3个类别。
K就是代表类别的个数,它可以根据用户的需求进行确定
算法的流程很简单,如下所示:
-
选取初始化质心
-
计算数据集样本中其它的点到质心的距离,然后选取最近质心的类别作为自己的类别。
-
重新计算质心
通过上面的步骤我们就得到了3个簇,然后我们从这三个簇中重新选举质心,也就是我们选举出一个新的“爸爸”,这个"爸爸"可以为样本点(比如说红点),也可以不是样本中的点(比如说蓝点和绿色点)。选举方式很简单,就是计算每一个簇中样本点的平均值。 -
重复第3,4步骤,直到达到某一个阈值
这个阈值可以是迭代的轮数,也可以是当质心不发生改变的时候或者质心变化的幅度小于某一个值得时候停止迭代。
代码结果演示
完整代码下载链接
首先生成符合正太分布的简单数据集:
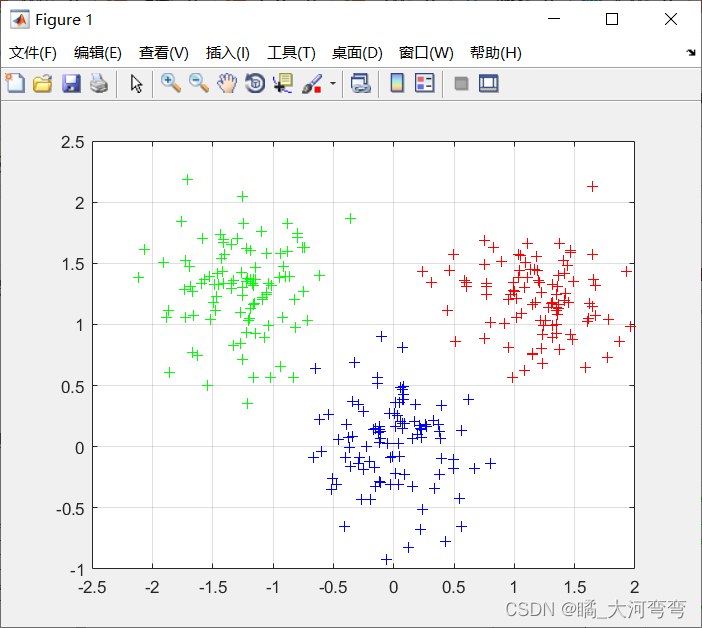
生成的代码如下:
% 第一组数据
mu1=[0 0 ]; %均值
S1=[.1 0 ;0 .1]; %协方差
data1=mvnrnd(mu1,S1,100); %产生高斯分布数据
%第二组数据
mu2=[1.25 1.25 ];
S2=[.1 0 ;0 .1];
data2=mvnrnd(mu2,S2,100);
% 第三组数据
mu3=[-1.25 1.25 ];
S3=[.1 0 ;0 .1];
data3=mvnrnd(mu3,S3,100);
% 显示数据
plot(data1(:,1),data1(:,2),'b+');
hold on;
plot(data2(:,1),data2(:,2),'r+');
plot(data3(:,1),data3(:,2),'g+');
grid on;然后进入Kmeans算法,开始聚类,最终的聚类结果如图所示:
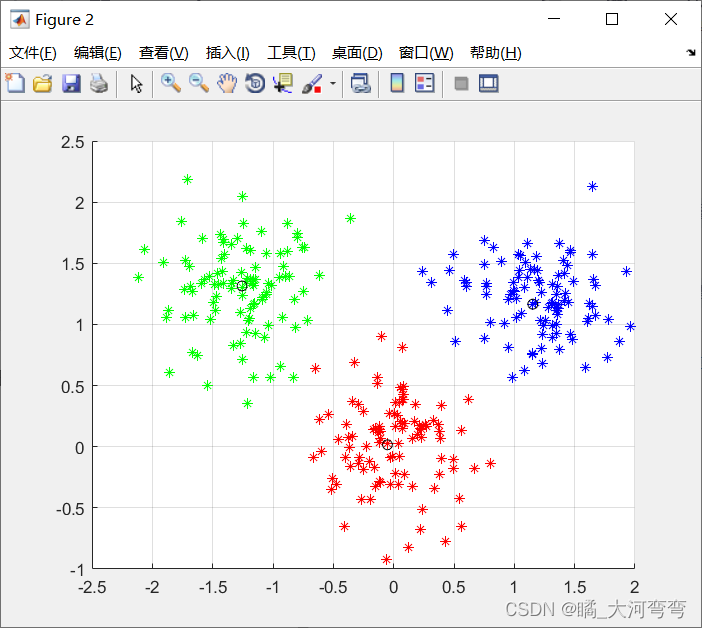
中间的空心原点就是生成的聚类中心:

算法部分代码:
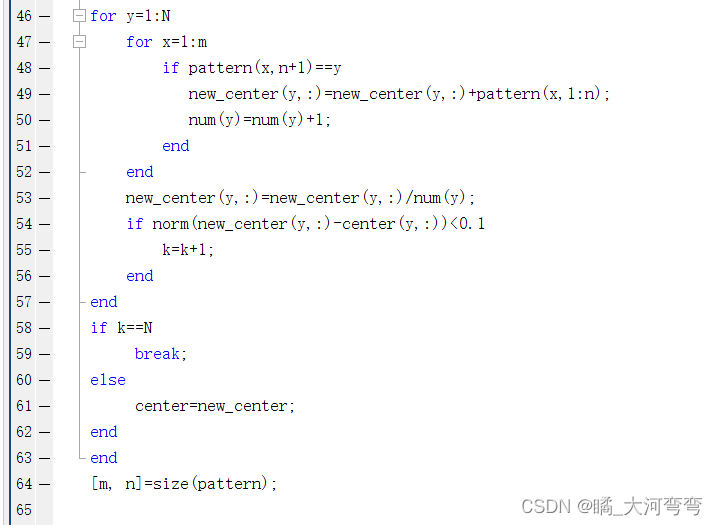
可以看到和上面所述的流程差不多;