无疑使用单点登录 (SSO)访问组织中的多种应用程序能够提升用户体验 。 如果您负责为 Amazon Redshift 启用 SSO,则可以使用 ADFS、PingIdentity、Okta、Azure AD 或其他基于 SAML 浏览器的身份提供程序设置 SSO 身份验证。
这篇文章向您展示了如何将 PingOne 设置为您的 IdP。包含以下步骤:
- 配置 IdP(PingOne) 用户组和用户 – PingOne 集成 Microsoft AD 获取用户组和用户
- 配置 IdP(PingOne) 应用程序 – 创建 PingOne 应用程序,在应用程序中指定使用的 Amazon IAM Role,并指定使用该 Role 的用户组,用户使用该 Role 可以访问 Redshift 群集
- 配置 IAM SAML 联合认证 – 通过在 PingOne IdP 和 Amazon 之间建立信任关系,设置允许 PingOne 访问 Amazon Redshift 的角色
- 创建 Amazon Redshift DBGroups 配置权限 – 在 Amazon Redshift 数据库中创建 DBGroups 并授权这些 DBGroups 访问的 schemas 和 tables。
- 测试单点登录 – 使用 Workbench 客户端工具进行 SSO 登录测试并进行权限验证
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
解决方案概览
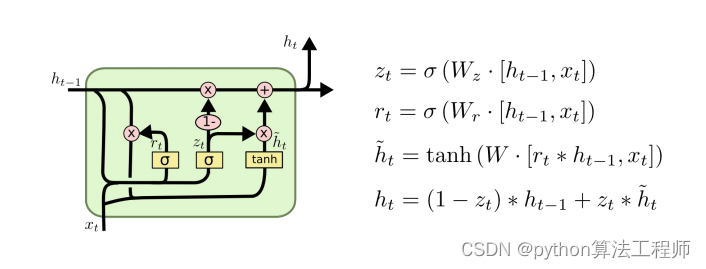
联合身份验证的流程以及步骤如下所示:
- 用户使用 workbench 客户端登录
- IdP(PingOne) 读取 Microsoft AD 里的用户名和密码进行身份验证,
- IDP 认证通过返回 SAML 断言
- 客户端使用 Amazon SDK 调用 Amazon Security Token Service (Amazon STS) 以使用 SAML 代入角色(assume Role)
- Amazon STS 返回临时 Amazon 凭证
- 客户端使用临时 Amazon 凭证访问 Redshift

联合身份单点登录流程图
配置步骤
前提
(1)配置之前如果没有组织内没有购买 PingOne 服务你需要访问
Try Ping for Free and Secure Your Customers/Workforce with leading SSO and MFA Solutions注册免费账户
(2)Microsoft AD 需要访问互联网权限 需要在 AD 服务器上安装 PingOne AD 连接器用于访问 PingOne 服务
Microsoft AD 域中创建用户组和用户
登录 AD 创建用户和用户组并把用户加入相应的用户组
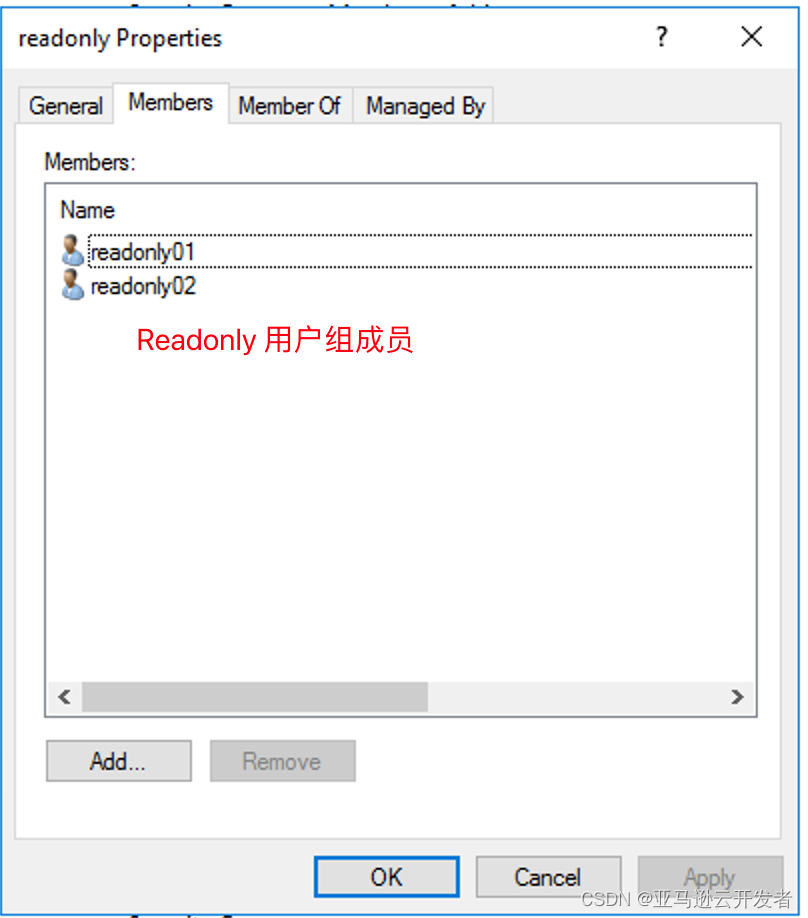
例如:创建四个用户 readonly01 readonly02 readwrite01 readwrite02 创建两个用户组 readonly readwrite 将用户 readonly01 readonly02 加入用户组 readonly 将用户 readwrite01 readwrite02 用户加入用户组 readwrite
注意:添加用户时为用户配置邮箱地址
用户组成员:

配置 PingOne 连接 Microsoft AD
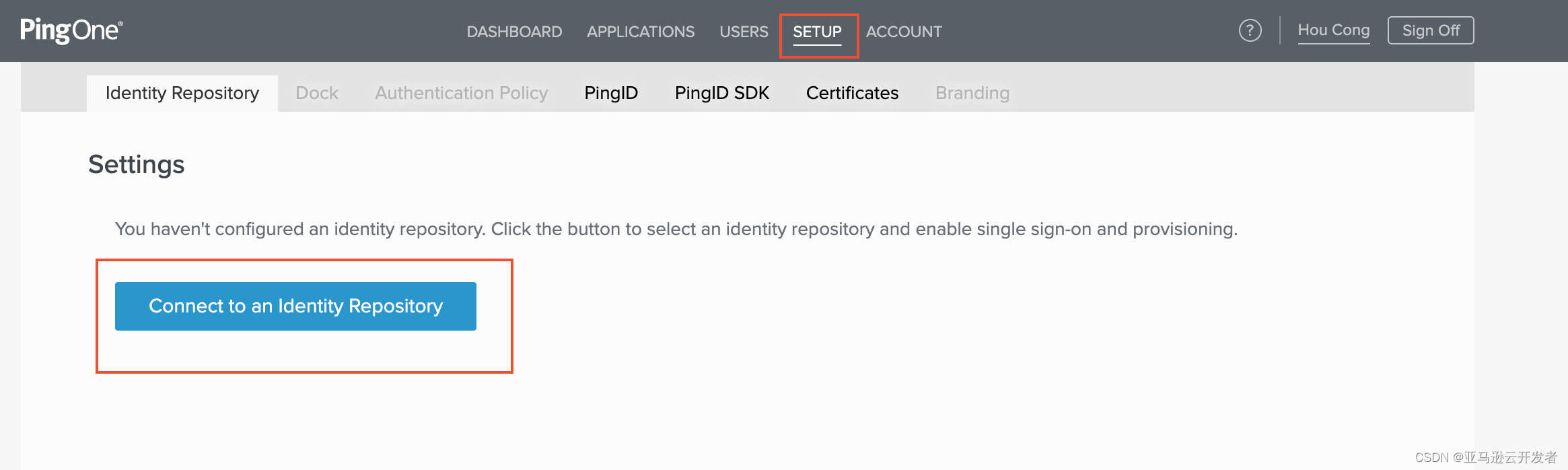
- 登录 PingOne 管理 Portal PingOne - Login

2. 导航栏中点击 “setup”,选择 “Identity Repository” 点击 “Connect to an Identiy Repositry”
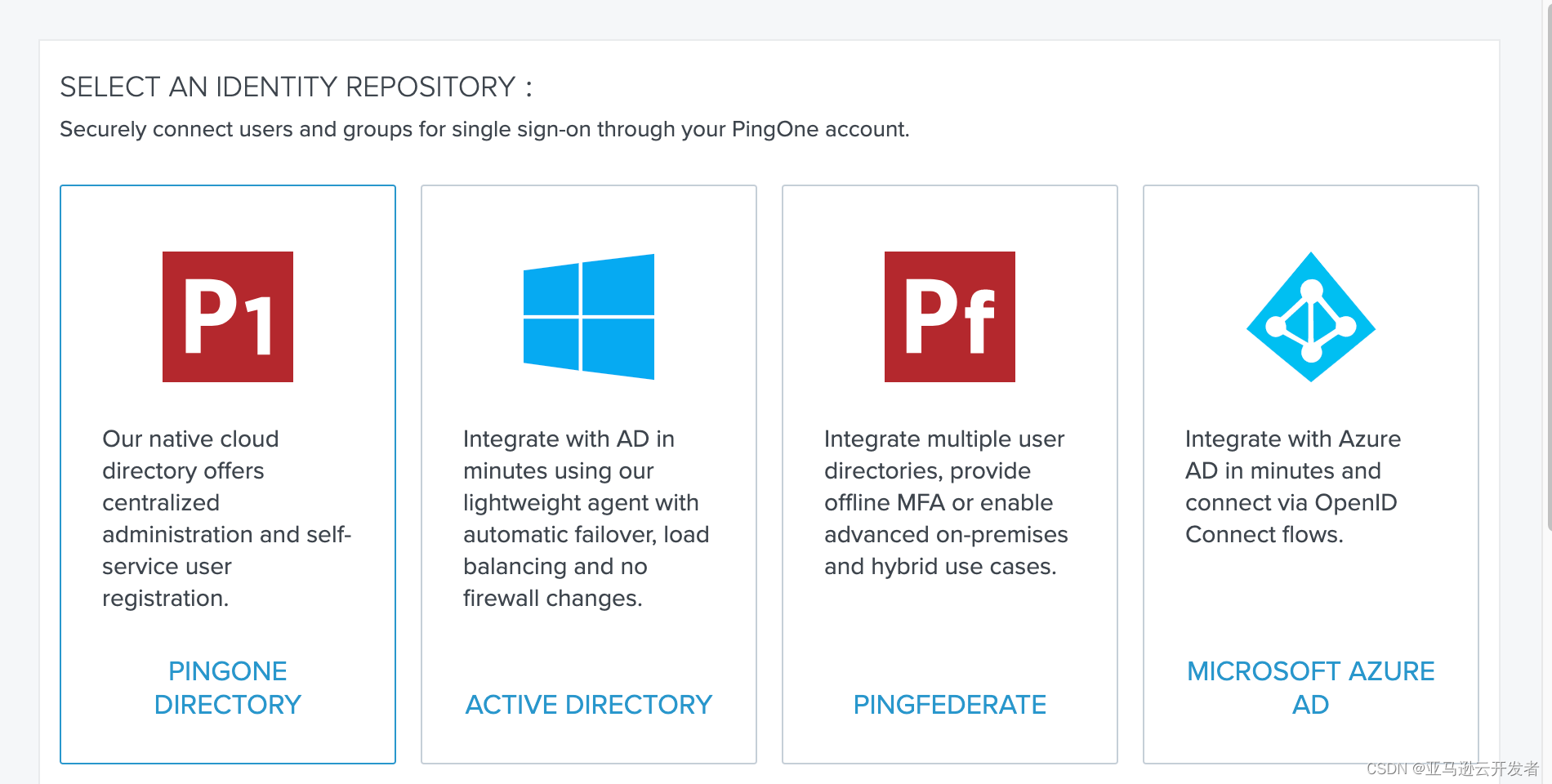
3. 选择 “Active Directory” 作为认证源
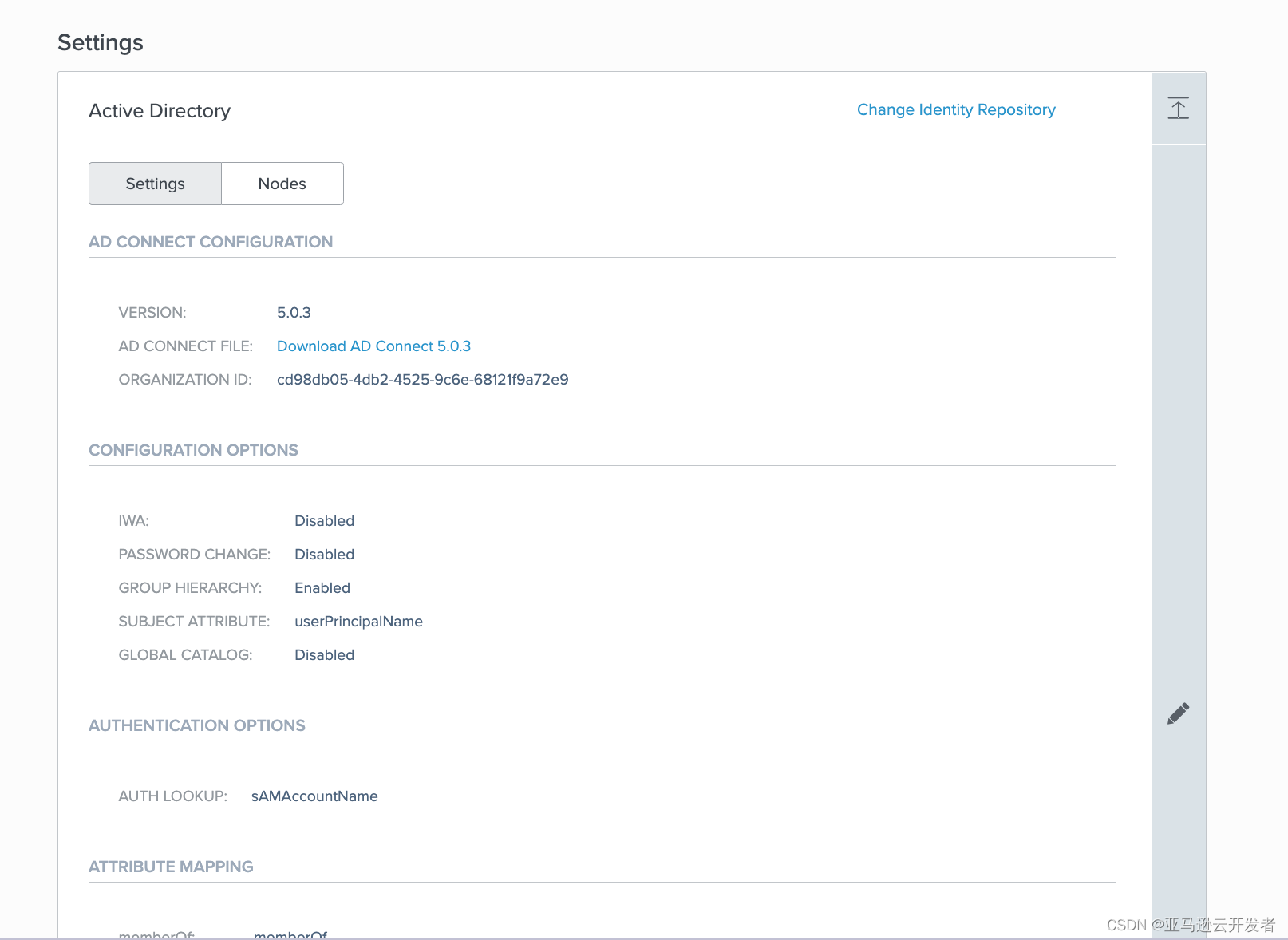
4. 按照提示步骤进行操作,完成 AD 认证集成
AD Connector 安装步骤可参考链接

5. 配置完成
6. 导航至 user 可以查看到 PingOne 已经同步 Microsoft AD 用户组

配置 IdP(PingOne) 应用程序
这一步骤需要创建 PingOne 应用程序,以便用户组成员可以访问 Amazon Redshift,由于有两个用户组,我们需要创建两个应用程序
- 登录 PingOne 管理界面,导航至 Application 栏

2. 在 “My Application” 栏选择 SAML
3. 选择 “Add Application”
4. 选择 “New SAML Application”
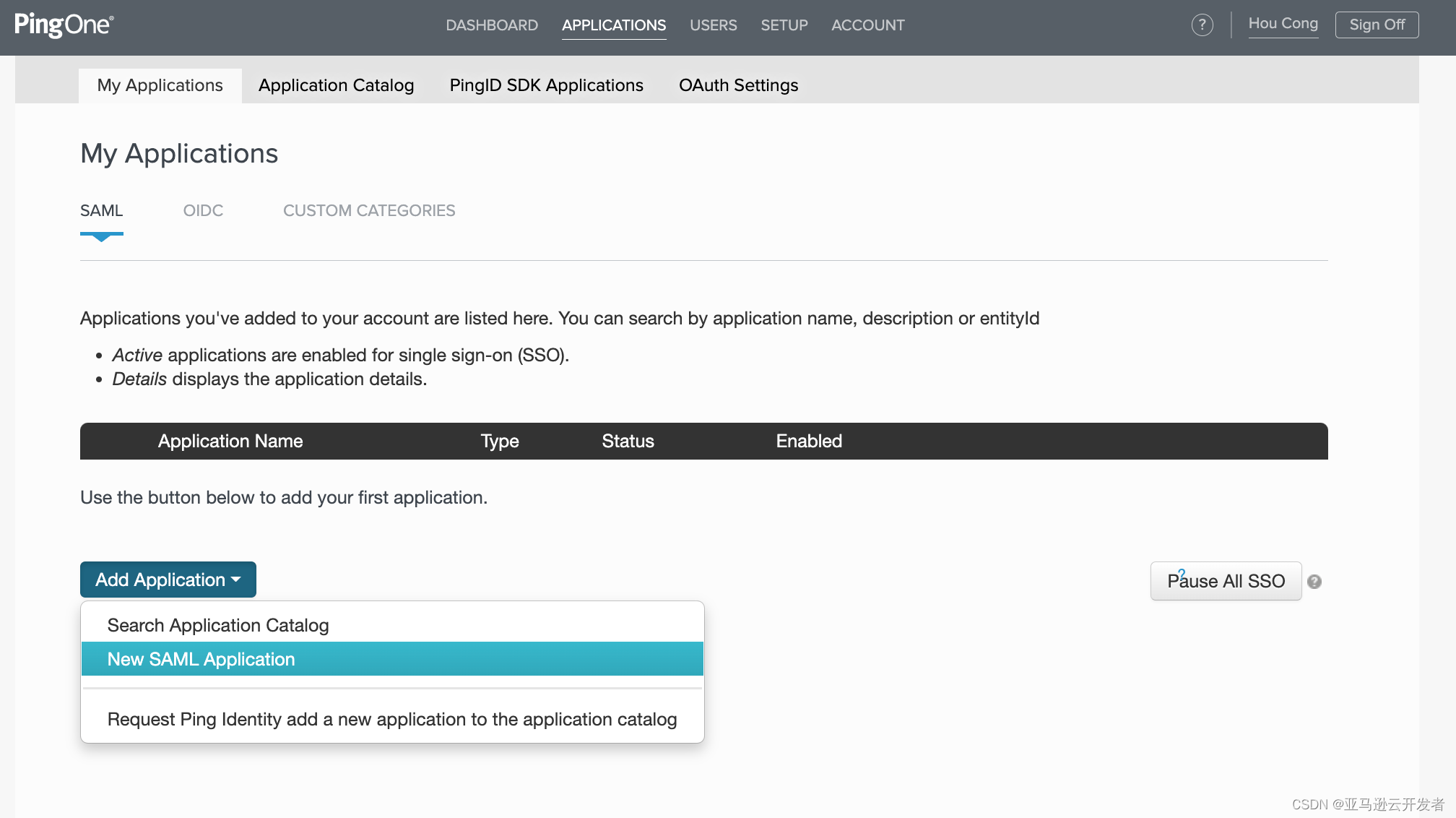
5. 输入 Application 名称 比如: AmazonRedshiftReadOnly
6. 继续下一步
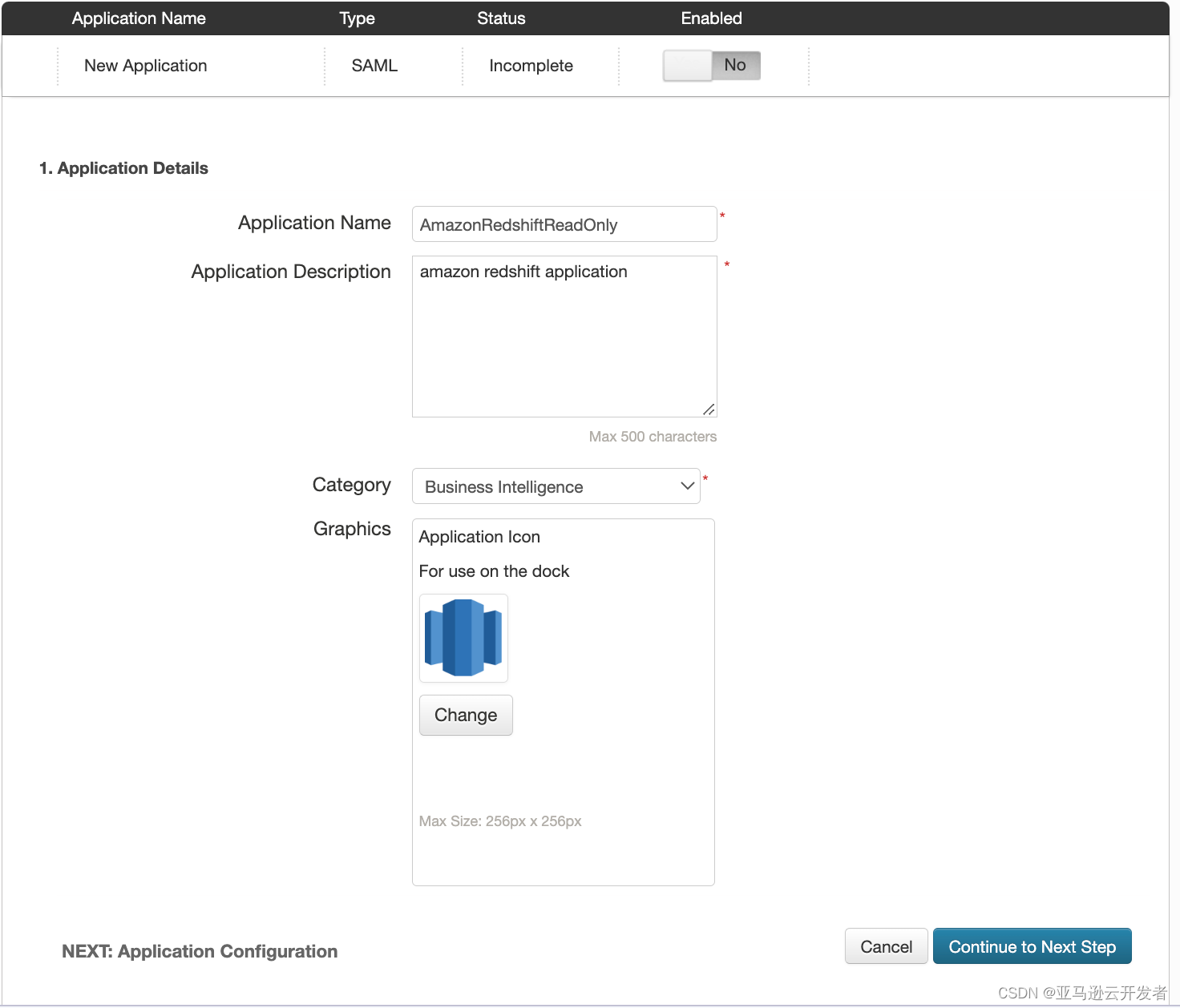
7. 在 “Application Configuration” 配置界面配置参数如下:

8. 点击下一步
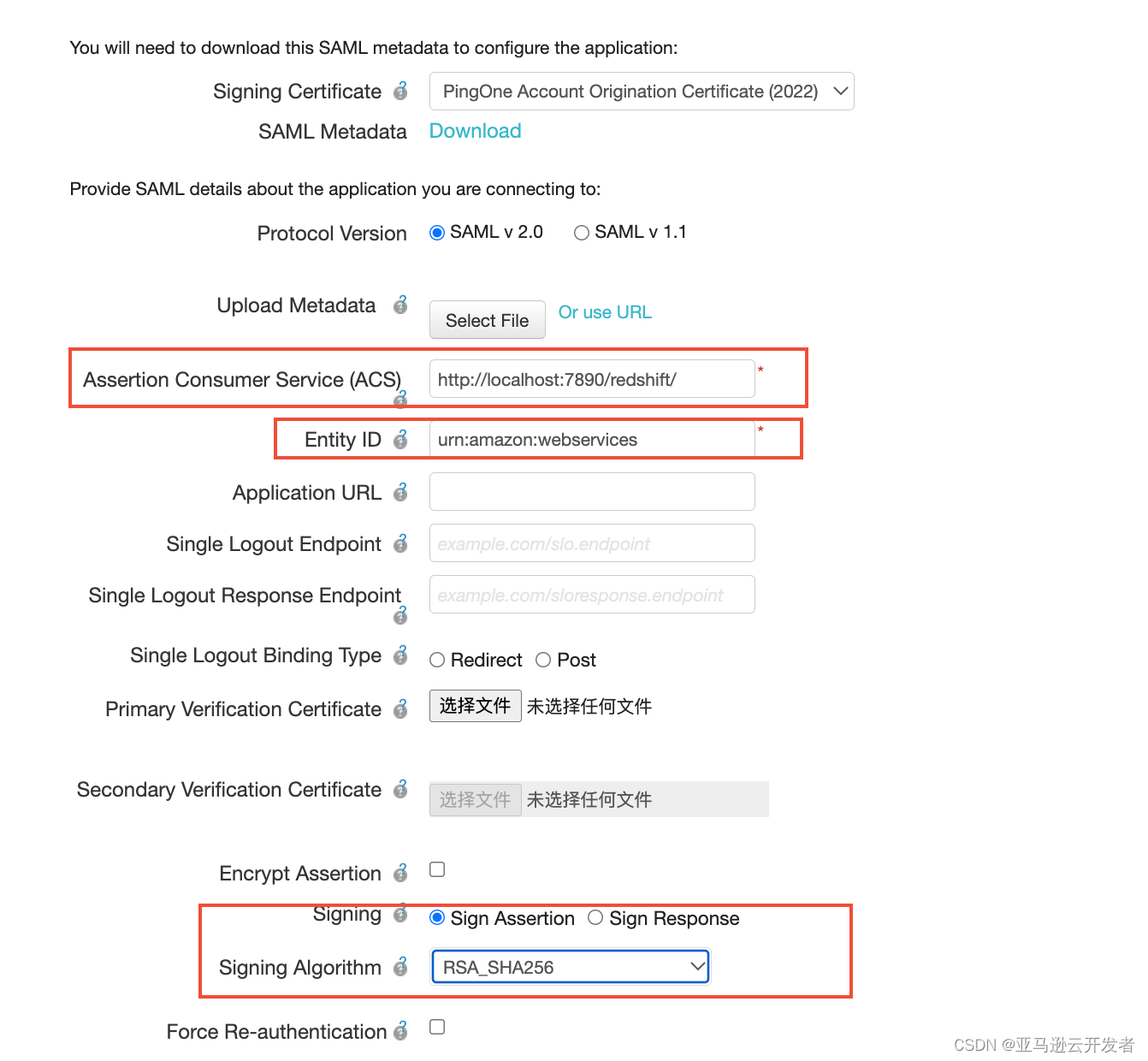
9. 在 “SSO Attribute Mapping” 配置界面输入以下
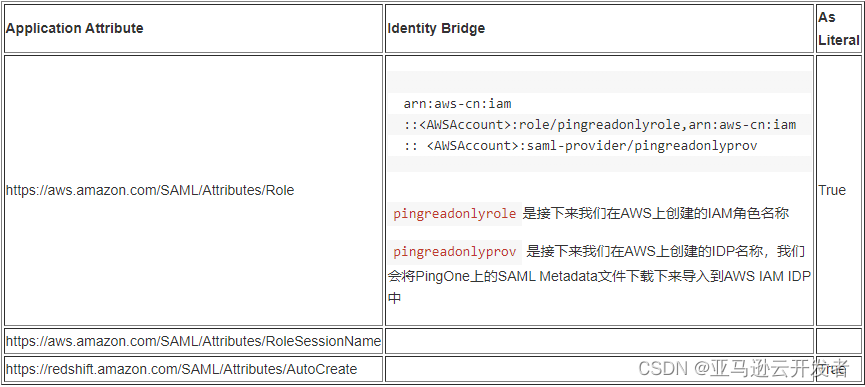

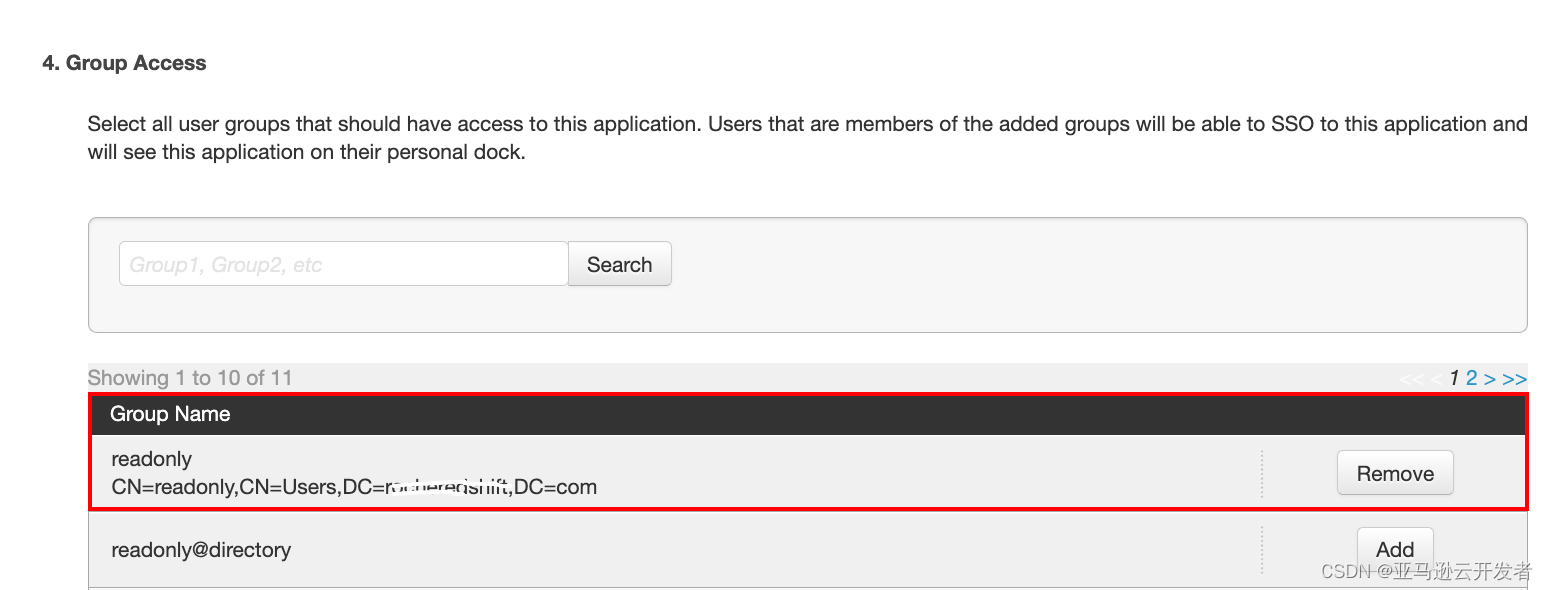
10. 在 “Group Access” 界面选择 AD 用户组 readonly
11. 点击下一步
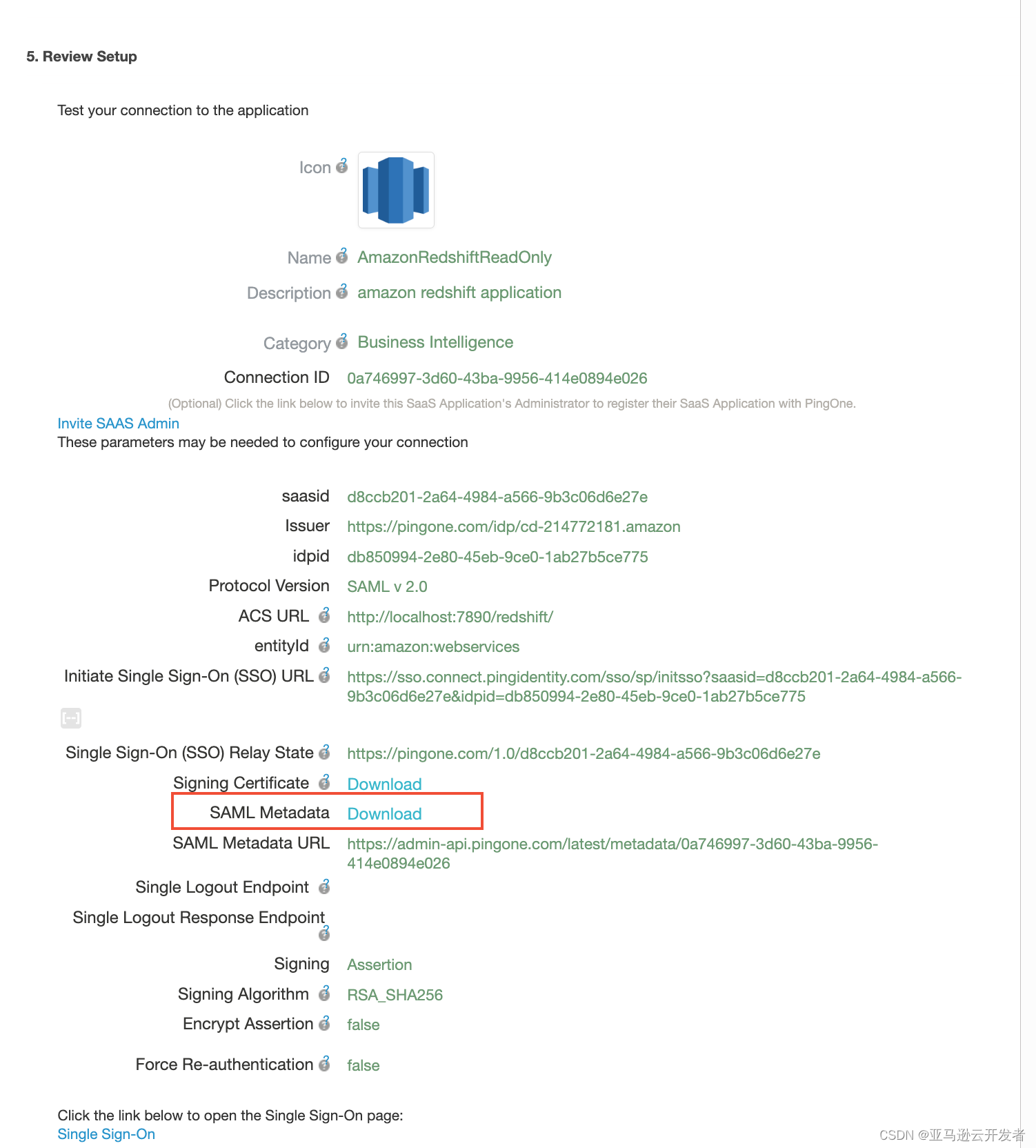
12. 查看配置界面 下载 SAML Metadata 文件到本地,下一步骤会导入到 Amazon IDP 中
13. 记录 Initial Single Sign-On(SSO) URL,配置 Workbench JDBC 连接信息是需要该参数
14. 点击完成
15. 重复上述步骤创建第二个应用程序 AmazonRedshiftReadWrite,需要调整以下两部分的参数:
- SSO Attribute mapping: https://aws.amazon.com/SAML/Attributes/Role 参数的值更改为
arn:aws-cn:iam:::role/pingreadwriterole,arn:aws-cn:iam:::saml-provider/pingreadwriteprov
- Group Access 选择 AD 用户组 readwrite
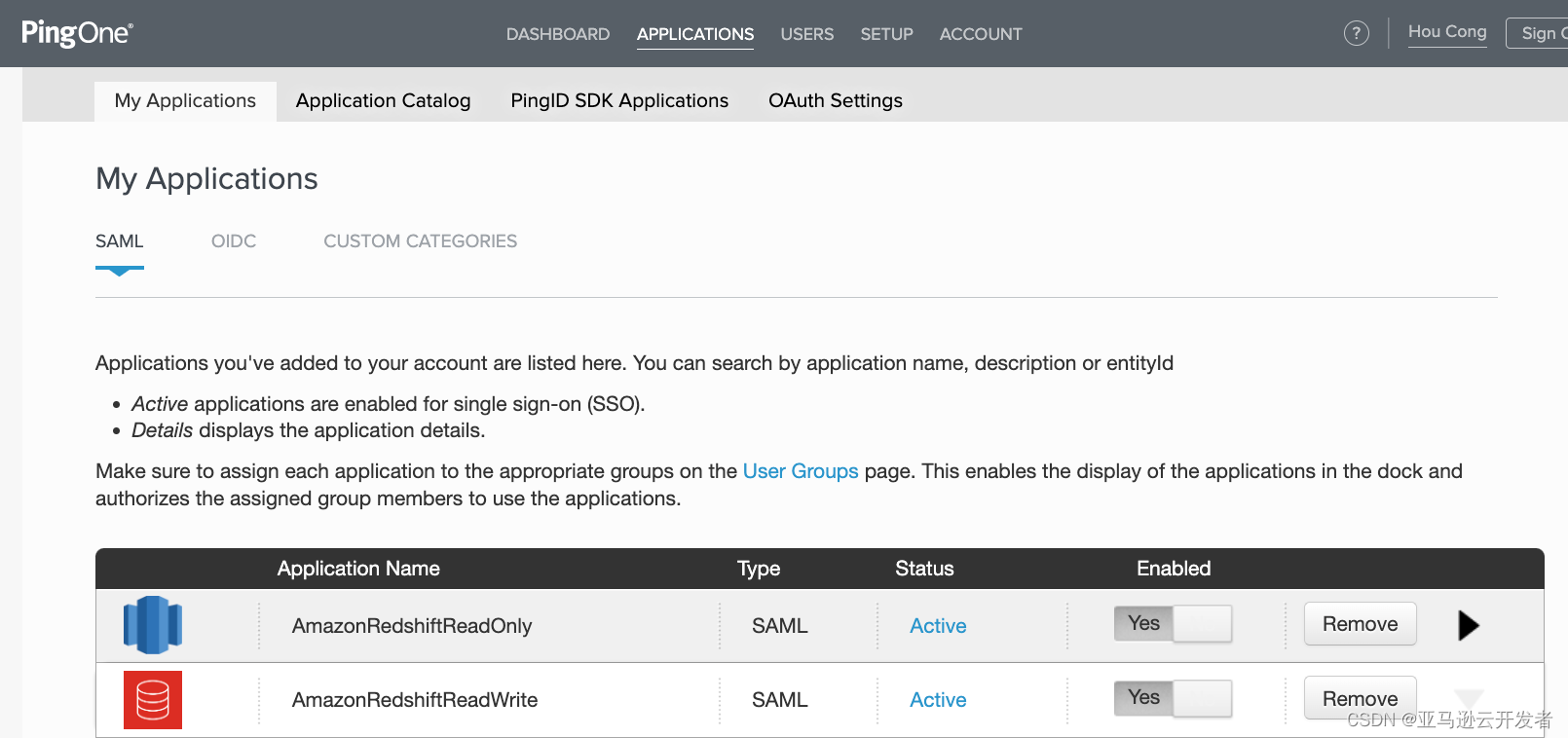
16. 配置完成后拥有两个应用程序
配置 IAM SAML 联合认证
创建IAM SAML IdP
要配置 IAM SAML,需要创建 IAM IdP 以及角色和策略。
配置步骤如下:
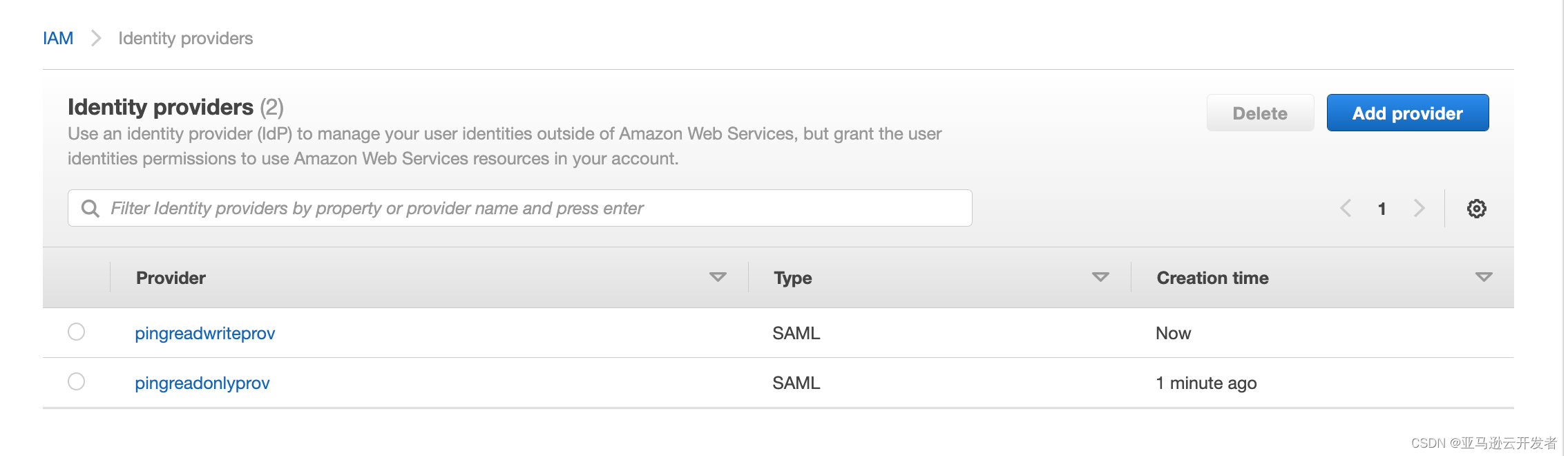
- 登录 Amazon Console,选择 IAM 服务导航至 Access management 下的 Identity Provider

2. 选择 Add Provider,
3. 类型为 SAML,
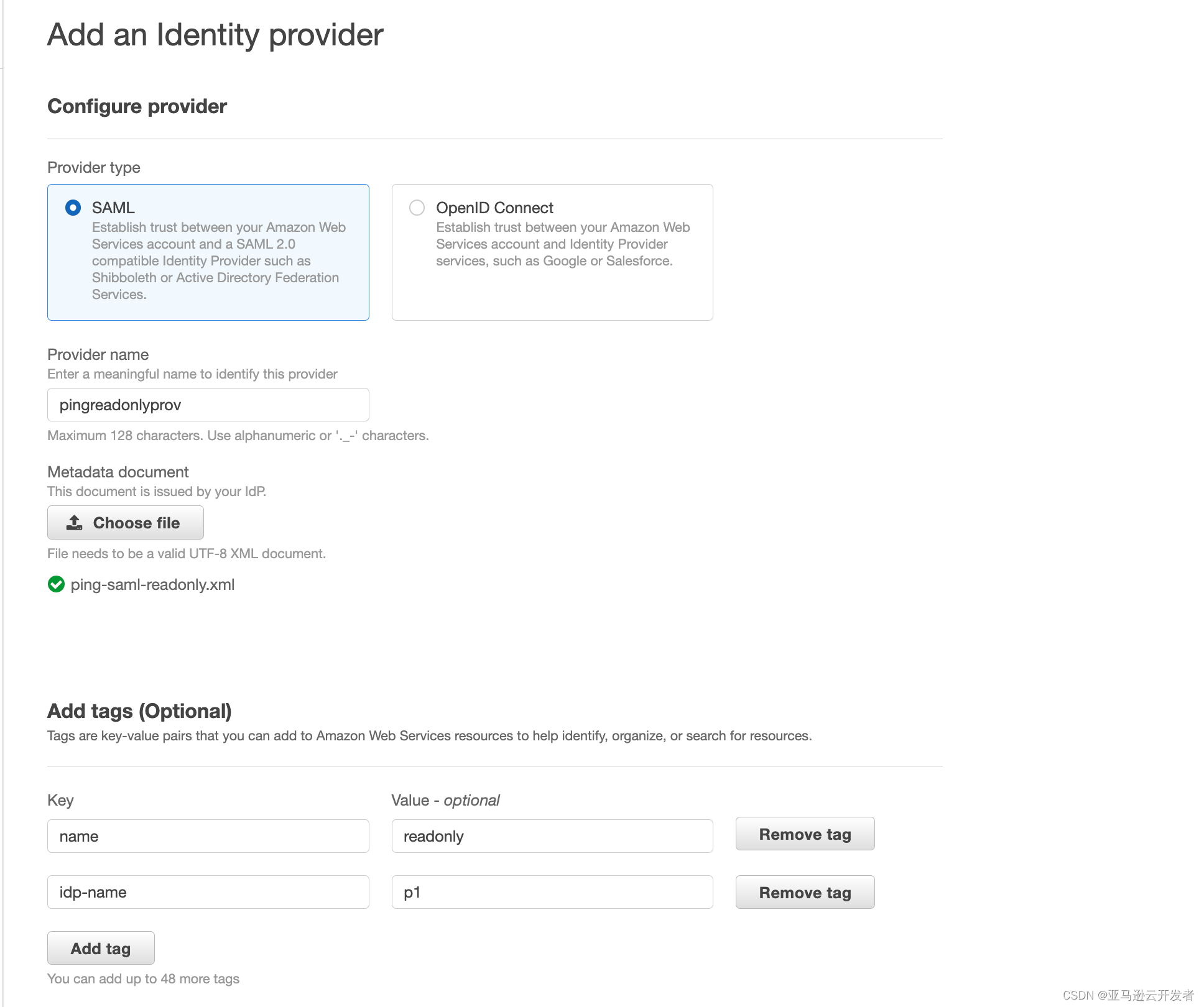
4. 名称输入 pingreadonlyprov(该名称与 PingOne SSO Attribute Mapping 中参数 https://aws.amazon.com/SAML/Attributes/Role 输入的值一致)
5. Metadata 文件 选择 PingOne 应用程序 AmazonRedshiftReadOnly 下载的 XML 文件
6. 重复上述步骤创建第二个 IdP (Metadata 文件选择 PingOne 应用程序 AmazonRedshiftReadWrite 的 XML 文件)
7. 创建完成后可以看到有两个 IdP Provider
创建 IAM Role 和 Policy
我们使用 IAM Role 来控制用户组访问 Redshift 数据库的权限。通过配置 IAM Role 并为该 Role 绑定策略的方式来限制不同的用户组对 Redshift 数据库的访问。该 Role 允许用户通过 IdP 来访问 Redshift 群集。
创建 IAM Role 之前我们需要创建 IAM Policy 该 Policy 允许用户拥有 joingroup 权限
-
Amazon IAM 服务配置界面选择 policy
-
选择创建 Policy
-
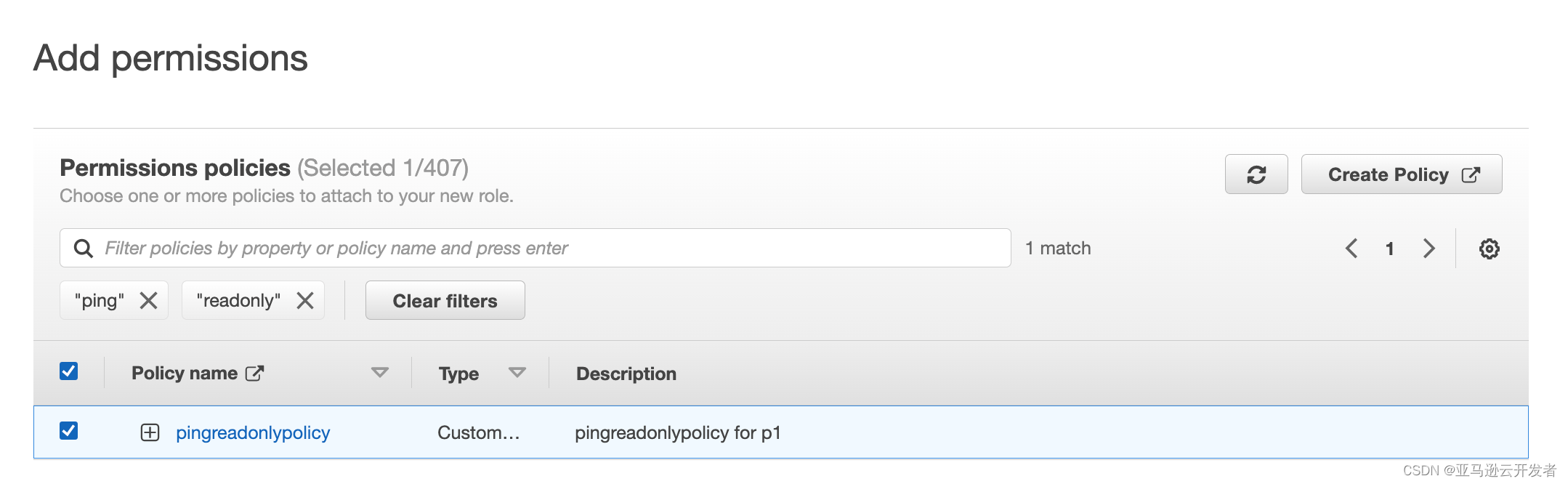
选择 JSON,创建两个 pingreadonlypolicy 和 pingreadwritepolicy
- 替换 为组织中的 Redshift cluster 名称
- 替换 为组织中的 Redshift dbname
两个 policy 的配置不同之处是在 JoinGroup 的 Resource。
“JoinGroup”:pingreadonlypolicy 允许用户加入 Redshift readonly 组
“JoinGroup”:pingreadwritepolicy 允许用户加入 Redshift readwrite 组
用户访问 Redshift 数据库并自动加入 Redshift DBGroup 只在会话存活期内有效,该策略中并未包含创建 DbGroup 的权限,因为创建 DBGroups 并赋予 DBgroup 相应的权限需要手动在 Redshift 数据库中完成。
以下代码展示pingreadonlypolicy内容:
{"Version": "2012-10-17","Statement": [{"Sid": "VisualEditor0","Effect": "Allow","Action": "redshift:GetClusterCredentials","Resource": ["arn:aws-cn:redshift:*:*:cluster:<cluster>","arn:aws-cn:redshift:*:*:dbname:<cluster>/<dbname>","arn:aws-cn:redshift:*:*:dbuser:<cluster>/${redshift:DbUser}"],"Condition": {"StringLike": {"aws:userid": "*:${redshift:DbUser}"}}},{"Sid": "VisualEditor1","Effect": "Allow","Action": "redshift:CreateClusterUser","Resource": ["arn:aws-cn:redshift:*:*:dbname:<cluster>/<dbname>","arn:aws-cn:redshift:*:*:dbuser:<cluster>/${redshift:DbUser}"]},{"Sid": "VisualEditor2","Effect": "Allow","Action": "redshift:JoinGroup","Resource": "arn:aws-cn:redshift:*:*:dbgroup:<cluster>/readonly"}]
}4. 配置完成后可以查看到刚刚创建的 Policy

5. 在 IAM Console 界面选择 Roles
6. 创建 Role
7. Type 选择 SAML 2.0 federation.
8. SAML provider 选择上述步骤中创建的 IdP
9. 选择 Allow programmatic access only.
10. Attribute: SAML:aud.
11. Value 输入 http://localhost:7890/redshift/.

12. 为第一个 Role 选择 pingreadonlypolicy 第二个 Role 选择 pingreadwritepolicy
13. 为该 Role 输入名称(pingreadonlyrole 和 pingreadwriterole)
14. 创建两个 Role 显示如下

创建 Amazon Redshift DBGroups 配置权限
该步骤将在 Redshift 数据库中创建 DbGroups,该 DbGroups 的名称需要与 IAM Policy 中 Joingroup 的名称保持一致,然后需要赋予 DbGroup 对 Redshift 数据库中的 shemale 以及 Table 相应的权限,你无需创建 DbUser,因为 DbUser 在通过 PingOne SSO 登录 Redshift 后自动加入相应的 DbGroup.
- 使用 admin 账户通过 Workbench 登录 Redshift 群集
- 使用如下命令创建 DbGroups 并赋予 Group 相应的 Schema 以及 Table 权限
CREATE SCHEMA finance;
CREATE TABLE IF NOT EXISTS finance.revenue
(
account INTEGER ENCODE az64,
customer VARCHAR(20) ENCODE lzo,
salesamt NUMERIC(18,0) ENCODE az64
)DISTSTYLE AUTO;
CREATE GROUP readonly;
CREATE GROUP readwrite;
ALTER DEFAULT PRIVILEGES IN SCHEMA finance
GRANT SELECT on TABLES to GROUP readonly;
GRANT USAGE on SCHEMA finance to GROUP readonly;
GRANT SELECT on ALL TABLES in SCHEMA finance to GROUP readonly;
ALTER DEFAULT PRIVILEGES IN SCHEMA finance
GRANT ALL on TABLES to GROUP readwrite;
GRANT USAGE on SCHEMA finance to GROUP readwrite;
GRANT ALL on ALL TABLES in SCHEMA finance to GROUP readwrite;
INSERT INTO finance.revenue values
(101, 'ABC Company', 12000),
(102, 'Tech Logistics', 175400),
(103, 'XYZ Industry', 24355),
(104, 'The tax experts', 186577);测试单点登录
该步骤将使用 Microsoft AD 用户使用 Workbench SQL Client 通过 PingOne SSO 登录访问 Redshift 数据库进行操作。
1. 配置 Workbench SQL 客户端
如果安装 Workbench SQL 客户端的服务器未安装 JDBC Driver 可通过以下链接进行下载安装。 下载链接
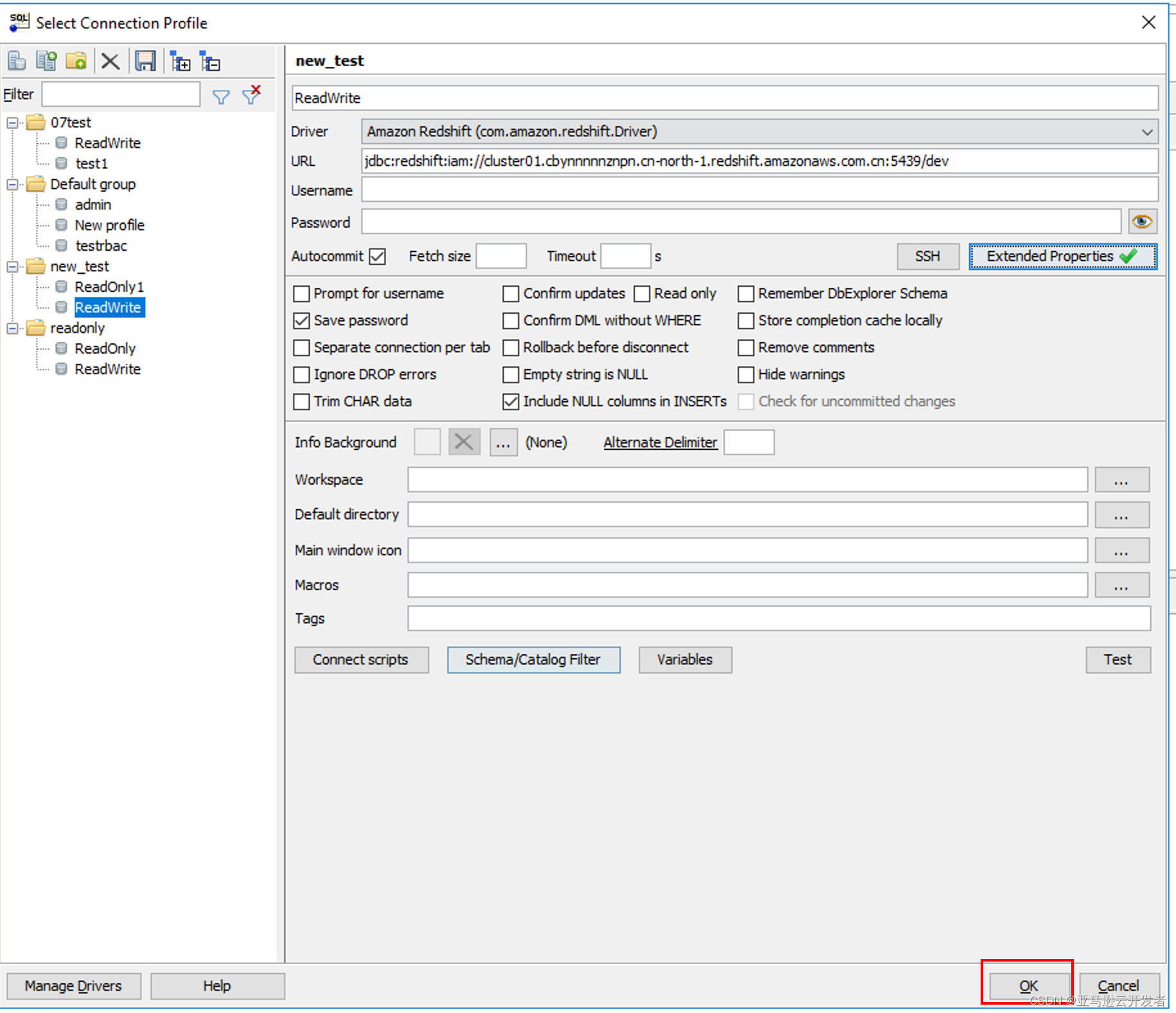
2. 创建 Connection Profile(该测试将测试 ReadWrite 权限)
URL:jdbc:redshift:iam://<cluster endpoint>

3. 选择 Extended Properties,输入 SSO 相关参数

login_url 输入 PingOne Application Initial Single Sign-On(SSO) URL


4. 点击 OK
5. connection Profile 界面点击 OK 按钮
6. 浏览器将会打开 PingOne 登录界面 输入 AD 账户用户名以及密码
7. 登录成功

8. 运行 select 命令:select * from current_user

9. 运行 insert 命令
INSERT INTO finance.revenue values
(1111111111, 'ABCDE Company', 12000);
其它补充:
- 通过 SSO 登录的 AD 用户会永久保存在 Redshift 数据用户列表中,但是无法通过本地登录,原因是该用户名为 AD 用户与 IAM Role 集成后的联合用户,生成的是临时 Credentials 并非保存在 Redshift 数据库用户配置中。参考链接
- 该文档在测试步骤中的 extended properties 指定了参数 DbGroups,该参数也可以通过配置 PingOne Application SSO Attribute Mapping 的参数 https://redshift.amazon.com/SAML/Attributes/DbGroups进行指定
总结:
在这篇博文中,我向您介绍了如何配置和使用 PingOne 作为您的 IdP 并为 Amazon Redshift 集群启用联合 SSO 的部署指南。 您可以按照这些步骤为您的组织设置联合 SSO,并根据读/写权限或业务功能管理访问权限,并将 PingOne IdP 中定义的组成员身份传递到您的 Amazon Redshift 集群中。
本篇作者

侯聪
Amazon 专业服务团队云运维咨询顾问,专注于云上运维以及优化方案的咨询与实施。多年从事云基础架构设计交付工作,对虚拟化,SDN,容器,自动化运维等技术领域有深入的研究和热情。

银硕
Amazon 专业服务团队云运维咨询顾问,对云上服务建设运维、 DevOps 迁移改造等项目交付有丰富的经验。负责企业级客户的云架构设计、云上自动化运维、容器化平台设计咨询等,对云原生技术有深入的研究和热情。
文章来源:https://dev.amazoncloud.cn/column/article/630a1bc4d4155422a4610a59?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN