目录
前言
爬虫是个啥?
铺垫知识
运行环境
Requests库
BeautifulSoup 库
PhatomJS + Selenium
记住,技术本身是无罪的,有罪的在于滥用技术的人
前言
当你看到这篇博客时,恭喜你被我的标题骗了进来🤪🤪 欸欸欸,别走,精彩的在下面。
本篇文章并不是什么高大上的爬虫教学,旨在激发一位小白的好奇心,通过本文的学习,基本可以满足你的爬虫小心思~
如果你是小白,这篇文章对你入坑有所帮助的话,麻烦点个赞❗
如果你是大佬,这篇文章有什么说的不对的地方,麻烦给予指导✍
对了,本篇基于你得对所使用的语言Python有所了解,其次还基于你对前端三剑客HTML、CSS、JavaScript有所了解。如果你对上述没有了解,你可以先去了解一下再来食用本篇文章。
其次,以下代码我都会添加上time.sleep() 睡眠函数,目的是为了不对目标网址造成不可逆的伤害(虽然不太可能),但是各位还是要注意,爬虫可以,搞破坏就小心呵呵哒。
废话不多说,我们来入坑了
爬虫是个啥?
国际惯例,先给大家科普(虽然我很不情愿,毕竟你想学这个东西,你起码有所了解)
爬虫,就是打开一个网页,将你想要的东东下载下来。
XX:(小声bb:这不就是鼠标点一点的事吗,弄得这么复杂)
这位同学,你说的没错,就是鼠标点一点的事,但是加入你打开了某个网站,里面琳琅满足的又大又白好看的图片😍
如果用鼠标点,点一天可能才下载几十张上百张,还有几万张等着你。这时候可心疼了,小孩子才选择,我想全都要,这可咋办?
爬虫这时候就出来,爬虫就是通过代码的形式,帮你自动化的完成点击操作,几万张的图片,你要肆无忌惮(但千万别肆无忌惮)的话一会就搞定了,然后就点开文件夹....
铺垫知识
打开浏览器(建议谷歌浏览器),找到浏览器地址栏,然后在里敲https://www.doutula.com/photo/list/,你会看到网页内容。没错,今天我们就是来爬这些又大又白的表情包。(如果侵犯了斗图啦,联系我立马更新)

我们Crtl+U,看到这些文字了吗?这就是网页源代码,这才是网页赤裸裸的样子。(也可以鼠标右键->查看网页源代码)

我们回到刚刚页面,按一下F12,带你一下弹出窗口左上角的箭头,接着把鼠标移到你想要的图片上,就可以找到对应的标签。

好了,如何找到想要的东西我们就讲到这,下一部分我们将编写代码,初步获取到网页的源代码。
运行环境
首先说一下运行环境:
Windows10 我也想摸摸mac
Python3.7 推荐使用Anaconda这个管理工具,但是本篇我是不用的,避免大家的学习成本(而且Pycharm也有类似的工具)
PyCharm 2019.3.3
贴心的大暖男给你准备好了Python和PyCharm安装包了(温馨提示,Pycharm破解是失效的,需要自己弄)
安装包链接:https://share.weiyun.com/5CMS5fx 密码:5ct54a
Requests库
Requests库是python中强大的网络请求库,可以实现跟浏览器一样发送各种HTTP请求来获取网站的数据。
安装:win+R 输入cmd打开命令行窗口,输入下面这一句
pip install requestsRequests就安装好了,提供一份 Requests中文文档
我们来看看如何获取网页源代码
首先创建项目 quick_in_pit

创建文件 pit.py

编写代码
import requests # 导入requests库r = requests.get('https://www.doutula.com/photo/list/', ) # 像目标url地址发送get请求,返回一个response对象
print(r.text) # r.text是http response的网页HTML
执行,发现获取到了内容,不看内容,至少没有报错,证明我们是请求成功了
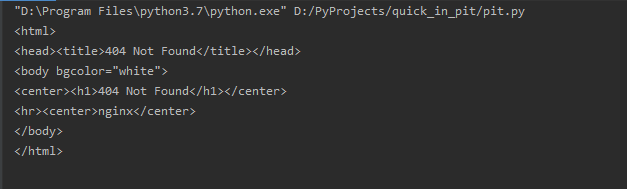
再来看看内容,报的是404。假装深思熟路一会,没想到这么快就祭出杀手锏了。这个网站用nginx代理,还进行了反爬操作。
(关于反爬不是我这篇要说的内容,说了我以后的素材怎么办?)
修改一下代码,给我们的代码添加上请求头。伪造一个User-Agent
import requests # 导入requests库headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/54.0.2840.99 Safari/537.36'}
r = requests.get('https://www.doutula.com/', headers=headers) # 像目标url地址发送get请求,返回一个response对象
print(r.text) # r.text是http response的网页HTML
在执行一次,这次源代码还不被我们手到擒来😤

Requests就介绍到这里,Requests的更多使用请自己翻文档啦,有中文还有什么看不懂的
BeautifulSoup 库
上一小节我们拿到了网页的源代码啦,那么怎么提取我们想要的内容呢?xi大大教我们要不忘初心,我们的初心是什么?是又大又白的图片!BeautifulSoup库就是一个解析HTML文档的库,能够帮助我们提取我们想要的指定标签的内容。
安装:
pip install beautifulsoup4我们简称 beautifulsoup4 为bs4 温馨提供:bs4中文文档
使用bs4 解析器推荐使用lxml,这里使用自带html.parser
首先我们需要定位我们要找到的图片,还记得F12吗?我们可以用肉眼加手定位标签,计算机怎么做呢?当然是根据字符,有什么可以定位标签的字符? 当然是标签属性啦,像 id、class这些,还有css选择器,还有Xpath(强烈推荐Xpath,但是我就不告诉你)
这里我们观察这个标签,发现class,这应该是所有图片都有的class。

然后我们编写下面代码
import requests # 导入requests库
import bs4headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/54.0.2840.99 Safari/537.36'}
r = requests.get('https://www.doutula.com/', headers=headers) # 像目标url地址发送get请求,返回一个response对象
#print(r.text) # r.text是http response的网页HTMLsoup = bs4.BeautifulSoup(r.text, 'html.parser')
all_img = soup.findAll('img', class_='lazy image_dtb img-responsive loaded')
for img in all_img:print(img)执行代码,发现竟然什么都没有输出?你们就会想立马拉到最下面说评论说:你个大屁眼子,根本行不通。
客官别急,我们想一想,为啥呀!再次深思熟虑后,这里我们是对获取到的源码进行提取,不是网页显示的源码进行提取,是不是这个网站又做了什么手脚?我们把 print(r.txt)打开,好你的XXX,和我们网页上看到的class进入不一样。

修改代码
import requests # 导入requests库
import bs4headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/54.0.2840.99 Safari/537.36'}
r = requests.get('https://www.doutula.com/', headers=headers) # 像目标url地址发送get请求,返回一个response对象
# print(r.text) # r.text是http response的网页HTML
soup = bs4.BeautifulSoup(r.text, 'html.parser')
all_img = soup.findAll('img', class_='img-responsive lazy image_dta')
for img in all_img:print(img)
执行,img标签就被我们手到擒来了。

提取到标签,进一步提取内容,因为我们只用src的内容呀,放心,强大的bs4就可以做到,不用学新东西了
提取属性简直不要太简单,在上面基础上,添加上['src']即可
print(img['src'])
路径获取到了,我们再写一个保存就应该可以搞定了,下方高能!
import bs4
import os
import requests
import timeclass BeautifulPicture:def __init__(self): # 类的初始化操作self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/54.0.2840.99 Safari/537.36'} # 给请求指定一个请求头来模拟chrome浏览器self.web_url = 'https://www.doutula.com/photo/list/' # 要访问的网页地址self.folder_path = 'D:\youDaYouBai' # 设置图片要存放的文件目录def get_pic(self):print('开始网页get请求')r = self.request(self.web_url)print('开始获取所有a标签')all_img = bs4.BeautifulSoup(r.text, 'html.parser').find_all('img',class_='img-responsive lazy image_dta') # 获取网页中的class为img-responsive lazy image_dta的所有img标签print('开始创建文件夹')self.mkdir(self.folder_path) # 创建文件夹print('开始切换文件夹')os.chdir(self.folder_path) # 切换路径至上面创建的文件夹for img in all_img: # 循环每个标签,获取标签中图片的url并且进行网络请求,最后保存图片img_src = img['data-original'] # img标签中完整的 data-original 字符串print('img标签的style内容是:', img_src)img_name = img['alt']time.sleep(2) # 不要肆无忌惮,2s抓一张图self.save_img(img_src, img_name) # 调用save_img方法来保存图片def save_img(self, url, name): ##保存图片print('开始请求图片地址,过程会有点长...')img = self.request(url)file_name = name + os.path.splitext(url)[-1]print('开始保存图片')f = open(file_name, 'ab')f.write(img.content)print(file_name, '图片保存成功!')f.close()def request(self, url): # 返回网页的responser = requests.get(url, headers=self.headers) # 像目标url地址发送get请求return rdef mkdir(self, path): ##这个函数创建文件夹path = path.strip()isExists = os.path.exists(path)if not isExists:print('创建名字叫做', path, '的文件夹')os.makedirs(path)print('创建成功!')else:print(path, '文件夹已经存在了,不再创建')beauty = BeautifulPicture() # 创建类的实例
beauty.get_pic() # 执行类中的方法
接着我们执行代码。控制台打出一系列说明,代码正常运行。看着飞快流动的控制台,不说了,我先去拿纸巾了.....
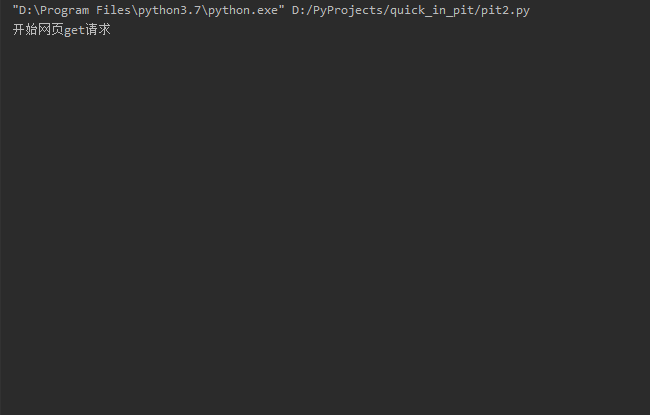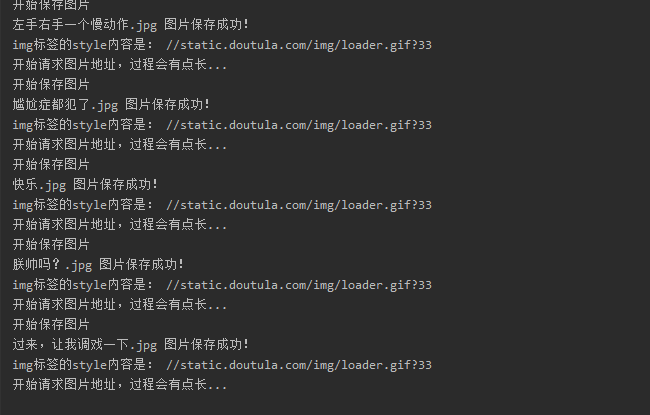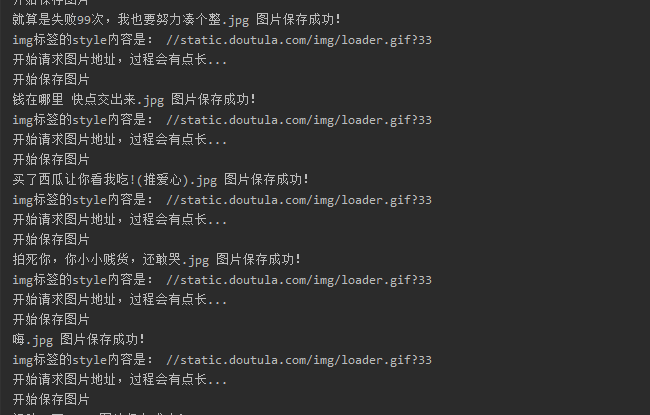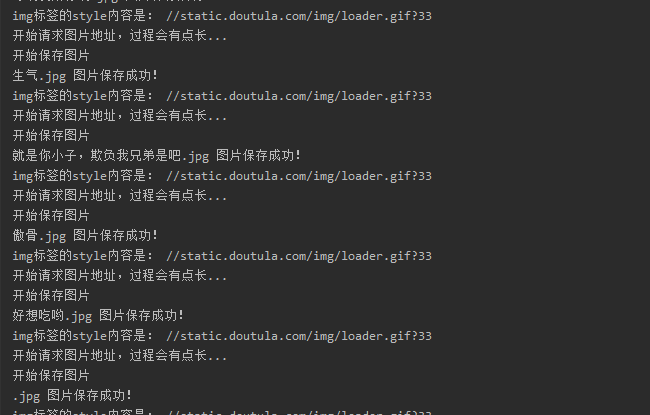
我回来啦
迫不及待点开文件夹一看,这都是些啥啊。我要这纸巾有何用?

没想到这里还有一关,再次陷入沉思,等会,我们回头看刚刚的动图,发现怎么都是loader.gif?33 再回头看看网页源代码,发现问题不简单,原来真正的图片路径保存在 data-original 和 data-backup属性中,这里我想说的是 我们要学会和网站开发者斗智斗勇

修改代码!
import bs4
import os
import requestsclass BeautifulPicture:def __init__(self): # 类的初始化操作self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/54.0.2840.99 Safari/537.36'} # 给请求指定一个请求头来模拟chrome浏览器self.web_url = 'https://www.doutula.com/photo/list/' # 要访问的网页地址self.folder_path = 'D:\youDaYouBai' # 设置图片要存放的文件目录def get_pic(self):print('开始网页get请求')r = self.request(self.web_url)print('开始获取所有a标签')all_img = bs4.BeautifulSoup(r.text, 'html.parser').find_all('img',class_='img-responsive lazy image_dta') # 获取网页中的class为img-responsive lazy image_dta的所有img标签print('开始创建文件夹')self.mkdir(self.folder_path) # 创建文件夹print('开始切换文件夹')os.chdir(self.folder_path) # 切换路径至上面创建的文件夹for img in all_img: # 循环每个标签,获取标签中图片的url并且进行网络请求,最后保存图片img_src = img['data-original'] # img标签中完整的 data-original 字符串print('img标签的style内容是:', img_src)img_name = img['alt']time.sleep(2) # 睡2s 不要肆无忌惮,被抓了我不负责self.save_img(img_src, img_name) # 调用save_img方法来保存图片def save_img(self, url, name): ##保存图片print('开始请求图片地址,过程会有点长...')img = self.request(url)file_name = name + os.path.splitext(url)[-1]print('开始保存图片')f = open(file_name, 'ab')f.write(img.content)print(file_name, '图片保存成功!')f.close()def request(self, url): # 返回网页的responser = requests.get(url, headers=self.headers) # 像目标url地址发送get请求,返回一个response对象。有没有headers参数都可以。return rdef mkdir(self, path): ##这个函数创建文件夹path = path.strip()isExists = os.path.exists(path)if not isExists:print('创建名字叫做', path, '的文件夹')os.makedirs(path)print('创建成功!')else:print(path, '文件夹已经存在了,不再创建')beauty = BeautifulPicture() # 创建类的实例
beauty.get_pic() # 执行类中的方法
再跑一遍!
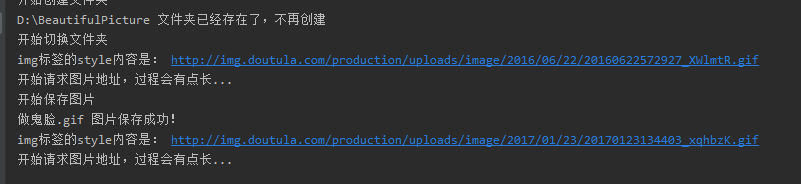

Wow,又白又大的表情包就被我们下载下来了。但是还有个问题!他怎么只能保存这一页的,我还得手动更换页码吗?这里我们下一节说
bs4当然还有很多妙用,像上面说的 css选择器,还有Xpath ,自学才是王道啊
PhatomJS + Selenium
上文中,我们的爬虫面临着一个问题,我们还是被网站识别到了我们使用爬虫操作的,这可咋办啊?难不成要回到起点,手动点击?更重要的是,现在的JS技术这么炫酷,下拉刷新,Ajax渲染,这些等页面加载完了还得加载一堆东西的网址,单纯使用request并不能满足需求了,这可怎么办?
作为推动时间发展的程序员,怎么会被这点问题难到?没有浏览器?我们就创建一个浏览器出来,这就是这一小节要说的PhatomJS + Selenium
PhatomJS是一个WebKit内核的浏览器引擎,它能像浏览器一样(它就是一个浏览器,只不过没有界面)解析网页,以及运行JavaScript脚本。
Selenium是一个自动化测试框架,因为它能够模拟人工操作,比如能在浏览器中点击按钮、在输入框中输入文本、自动填充表单、还能进行浏览器窗口的切换、对弹出窗口进行操作。也就是说你能手动做的东西,基本都能用它来实现自动化!
听到上面这两句话,是不是大彻大悟,频频点头,可行!Python + PhatomJS + Selenium 是爬虫的无敌三件套。
PhatomJS 不能使用pip install 来安装。需要去官网安装,小暖男在这里给你备好了,在上文的包里面一并拥有,因为实在是下不下来,后面用服务器weget去下载下载了一个多小时才下下来的。
下载完成的是一个压缩包,解压到你想存放的目录,同时配置环境变量,没错又是环境变量。
只找到了英文文档 PhatomJS 英文文档
![]()
安装selenium就用pip安装就可以 Selenium中文文档
pip install seleniumselenium也提供了对标签进行提取的操作,我们既可以用selenium也可以继续使用bs4,下面我使用selenium。
PhatomJS 无页面版本已经被废弃了,现在都推荐使用浏览器驱动的形式,如果我们使用PhatomJS会在控制台输出这样一句话。
D:\Program Files\python3.7\lib\site-packages\selenium\webdriver\phantomjs\webdriver.py:49: UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox insteadwarnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '首先下载Chrome浏览器驱动:Chrome浏览器驱动下载地址 选择你浏览器的版本,大版本要一致。选择自己的系统版本,然后下载。这是一个压缩包,解压后存到一个目录中,然后把该目录添加到环境变量。我就直接把他放在PhatomJS 的目录下了
查看自己版本在网址上输入
chrome://version/
写段代码测试一下
from selenium import webdriver # 导入Selenium的webdriver
from selenium.webdriver.common.keys import Keys # 导入Keys
import time # 导入time控制时间driver = webdriver.Chrome() # 指定使用的浏览器,初始化webdriver
driver.get("http://www.baidu.com") # 请求网页地址
assert "百度一下" in driver.title # 看看 “百度一下” 关键字是否在网页title中,如果在则继续,如果不在,程序跳出。
elem = driver.find_element_by_name("wd") # 找到name为wd的元素,这里是个搜索框
elem.clear() # 清空搜索框中的内容
elem.send_keys("大誌的博客") # 在搜索框中输入 “大誌的博客”
time.sleep(2) # 睡两秒
elem.send_keys(Keys.RETURN) # 相当于回车键,提交
assert "No results found." not in driver.page_source # 如果当前页面文本中有“No results found.”则程序跳出time.sleep(10) # 睡10秒
driver.close() # 关闭webdriver
接下来就是改造我们上一节的项目了
首先是创建Chrome,__init__方法中追加 self.browser = webdriver.Chrome()
def __init__(self): # 类的初始化操作self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/54.0.2840.99 Safari/537.36'} # 伪造请求头self.web_url = 'https://www.doutula.com/photo/list/' # 要访问的网页地址self.folder_path = 'D:\youDaYouBai' # 设置图片要存放的文件目录self.browser = webdriver.Chrome()
接着改造get_pic 方法
首先我们要找到下一页的按钮,但是我们发现没办法太明确的获取到这个a标签,但是我们换个思路,这个是所有的page-link最后一个,所以我们可以这样做。爬虫中思路很重要。
# 先获取所有的分页按钮pages = self.browser.find_elements_by_class_name("page-link")# 最后一个就是下一页 这里并没有做最后一页的判断 可以用一个current 来比较next_page = pages[len(pages) - 1]

接着是递归到下一页,很简单,我们修改web_url,递归调用get_pic()方法即可。这里我只抓取前三页。
# 获取href路径next_page_href = next_page.get_attribute("href")# 只抓取前三页的内容,不要太肆无忌惮了。if int(next_page_href[-1]) > 3:print("抓取完成")self.browser.close()exit()# 这里开始递归获取下一页# 设置访问路径time.sleep(5) # 每抓一页 睡五秒self.web_url = next_page_hrefself.get_pic()我们看看效果
拉取图片中:
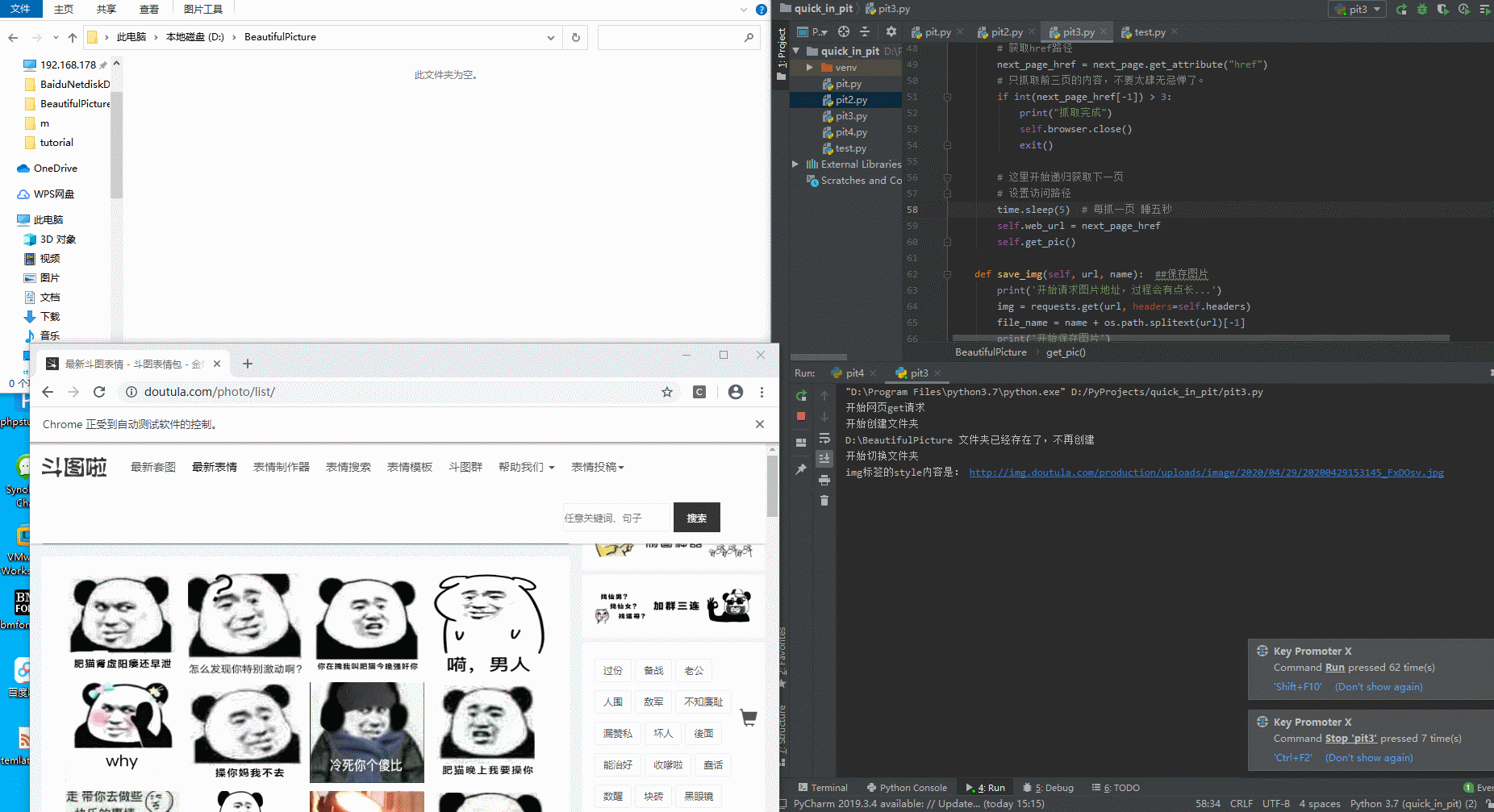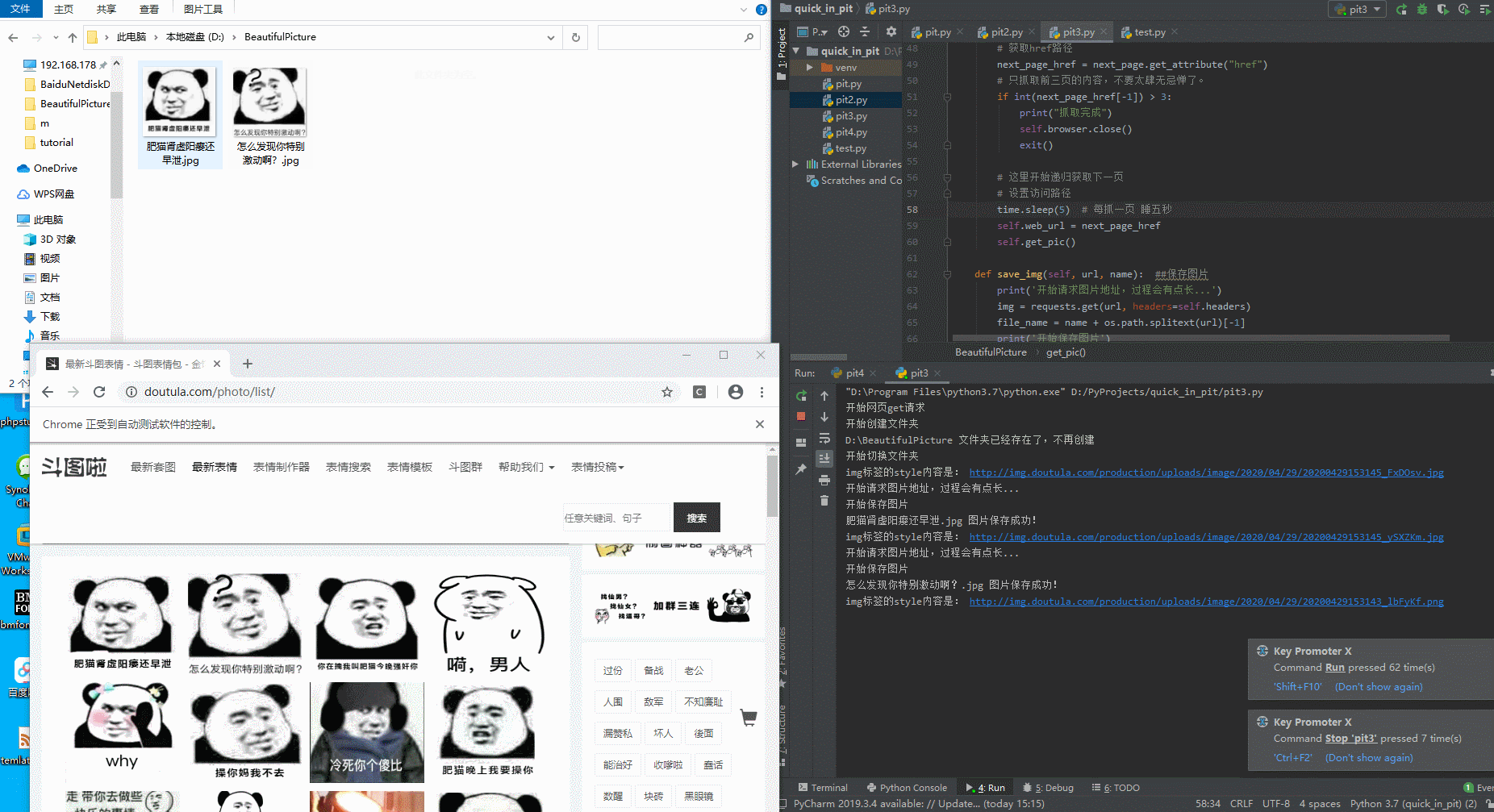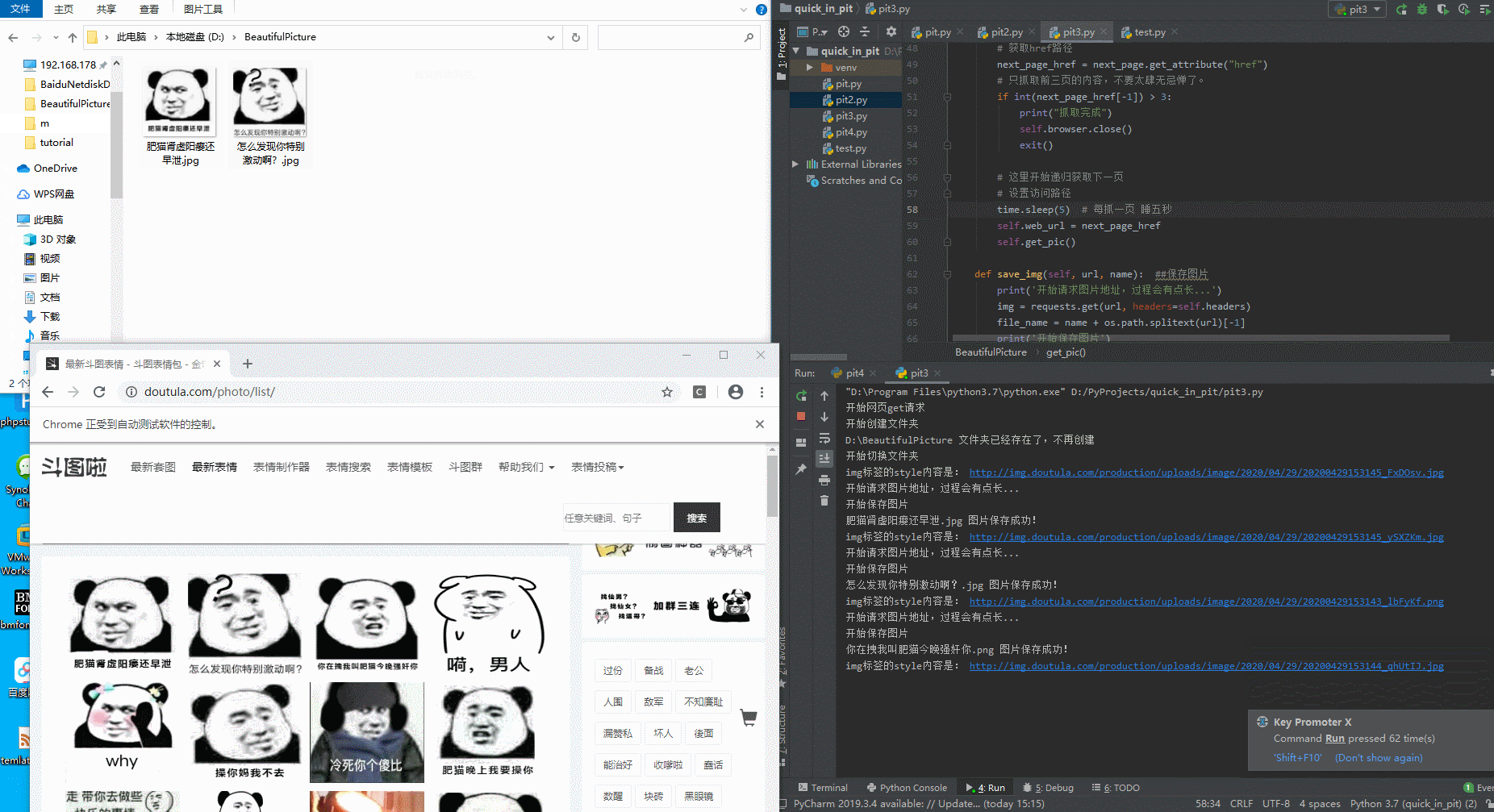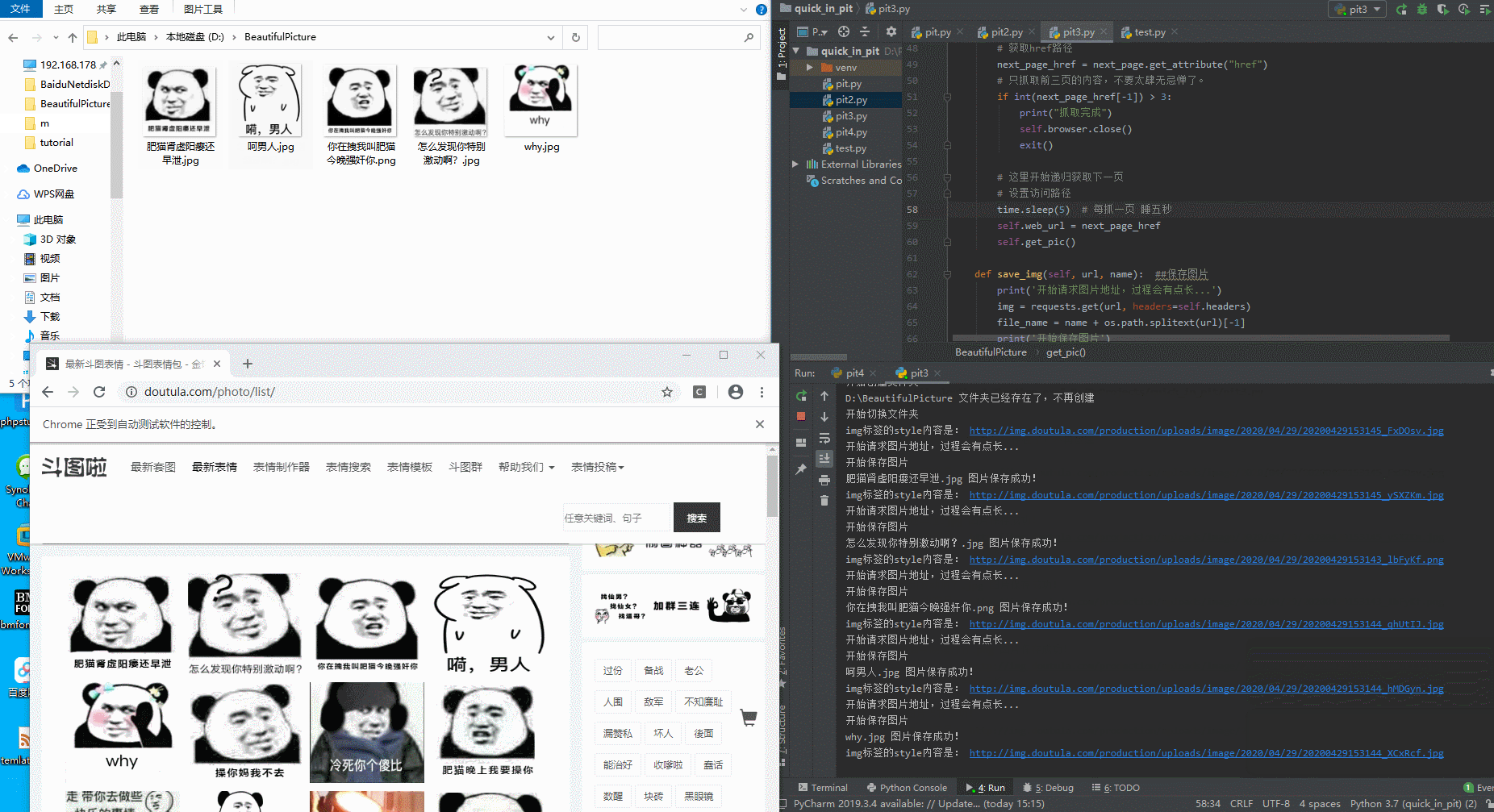
切换下一页,注意url和刷新
附上究极形态源码:
import os
import requests
from selenium import webdriver # 导入Selenium的webdriverimport timeclass BeautifulPicture:def __init__(self): # 类的初始化操作self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/54.0.2840.99 Safari/537.36'} # 伪造请求头self.web_url = 'https://www.doutula.com/photo/list/' # 要访问的网页地址self.folder_path = 'D:\youDaYouBai' # 设置图片要存放的文件目录self.browser = webdriver.Chrome()def get_pic(self):print('开始网页get请求')self.browser.get(self.web_url)# selenium 获取标签 classname是用 . 间隔的all_img = self.browser.find_elements_by_class_name("img-responsive.lazy.image_dta.loaded")if (len(all_img)) < 1:print("没有获取到图片,程序退出")self.browser.close()exit()# 先获取所有的分页按钮pages = self.browser.find_elements_by_class_name("page-link")# 最后一个就是下一页 这里并没有做最后一页的判断 可以用一个current 来比较next_page = pages[len(pages) - 1]print('开始创建文件夹')self.mkdir(self.folder_path) # 创建文件夹print('开始切换文件夹')os.chdir(self.folder_path) # 切换路径至上面创建的文件夹for img in all_img: # 循环每个标签,获取标签中图片的url并且进行网络请求,最后保存图片img_src = img.get_attribute('data-original') # img标签中data-original完整的字符串print('img标签的style内容是:', img_src)img_name = img.get_attribute('alt')time.sleep(1) # 1秒抓一张图,不要太肆无忌惮了self.save_img(img_src, img_name) # 调用save_img方法来保存图片# 获取href路径next_page_href = next_page.get_attribute("href")# 只抓取前三页的内容,不要太肆无忌惮了。if int(next_page_href[-1]) > 3:print("抓取完成")self.browser.close()exit()# 这里开始递归获取下一页# 设置访问路径time.sleep(5) # 每抓一页 睡五秒self.web_url = next_page_hrefself.get_pic()def save_img(self, url, name): ##保存图片print('开始请求图片地址,过程会有点长...')img = requests.get(url, headers=self.headers)file_name = name + os.path.splitext(url)[-1]print('开始保存图片')f = open(file_name, 'ab')f.write(img.content)print(file_name, '图片保存成功!')f.close()def mkdir(self, path): ##这个函数创建文件夹path = path.strip()isExists = os.path.exists(path)if not isExists:print('创建名字叫做', path, '的文件夹')os.makedirs(path)print('创建成功!')else:print(path, '文件夹已经存在了,不再创建')beauty = BeautifulPicture() # 创建类的实例
beauty.get_pic() # 执行类中的方法
最后,希望这篇文章能够激起你的兴趣。上述讲的可以满足我们的大多数需求,但还有很多优秀的技术框架,还有反爬以及避免被封杀等操作,这些都不是重点,
记住,技术本身是无罪的,有罪的在于滥用技术的人
我去斗图了,我们下次再见~
有什么问题可以评论或者私信我,每日在线解(LIAO)疑(SAO)。
我是大誌,一位准备996的卑微码农🐶,觉得好用记得点赞收藏!!!