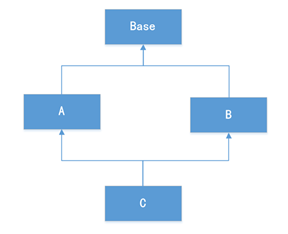
分布表
分布表是数据库中的一种数据组织方式,用于在分布式数据库环境中将数据划分和存储在多个节点或分区中。
它将数据按照特定的规则分散存储在不同的节点上,以实现数据的分布和并行处理,从而提高查询性能和系统的可扩展性。
分布表通常使用某种分片策略将数据分布到不同的节点上。常见的分片策略包括:
- 范围分片:根据某个列的范围将数据划分到不同的节点上。例如,按照订单日期范围将订单数据分片存储在不同的节点上。
- 哈希分片:根据某个列的哈希值将数据分片存储在不同的节点上。哈希函数将数据映射到节点,确保相同哈希值的数据存储在同一节点上。
- 列分片:按照列的值将数据分片存储在不同的节点上。例如,按照地理位置将用户数据分片存储在不同的节点上。
分布表的好处包括:
- 查询性能提升:数据分布在多个节点上,可以并行处理查询请求,提高查询性能。
- 系统可扩展性:通过将数据分布在多个节点上,可以方便地添加新的节点来扩展系统的存储容量和处理能力。
- 故障容错性:由于数据在多个节点上备份存储,当某个节点出现故障时,系统可以从其他节点恢复数据,提高系统的可用性和容错性。
需要注意的是,分布表的设计需要考虑数据分布的均衡性、查询的路由和数据一致性等因素。在使用分布表时,开发人员需要根据具体的应用场景和业务需求进行合理的设计和配置。
复制表
复制表是指在数据库中创建一个与现有表具有相同结构和数据的新表。通过复制表,您可以创建一个与现有表具有相同结构和内容的副本,而无需手动重新创建表结构和插入数据。
复制表的过程通常包括以下步骤:
- 创建新表:首先,您需要创建一个新的空表,该表将具有与原始表相同的列名、数据类型和约束。
- 复制表结构:将原始表的结构复制到新表中,包括列名、数据类型、约束、索引等。这可以通过使用CREATE TABLE语句和SELECT
INTO语句来完成。 - 复制数据:将原始表中的数据复制到新表中。可以使用INSERT INTO语句或其他数据复制方法,例如SELECT INTO或INSERT
SELECT。
需要注意的是,复制表只复制表的结构和数据,而不包括触发器、存储过程、视图等其他与表相关的对象。如果需要复制这些对象,您需要另外的步骤或工具。
复制表在数据库管理和开发中有许多用途,例如创建数据备份、创建测试环境、数据分析等。但请谨慎操作,确保复制表的操作不会对现有数据库的完整性和性能产生负面影响。在进行复制表之前,最好备份数据库以防止意外数据丢失。