主从切换的坑
主从数据不一致
- 主从库间的命令是异步进行的(主库在本地执行完命令后,就向客户端返回结果了,如果从库还没执行命令,数据就不一致了)
滞后的原因
- 主从网络延迟。
- 从库可能接收到了命令,但是从库可能在执行复杂度高的命令,这个时候就主从不一致了。
读取过期数据
redis使用了惰性删除和定期删除
- 惰性删除:发现读取的数据过期了就进行删除,减少cpu资源
- 定期删除:默认100ms,随机选择一些数据检查是否过期,进行删除
redis3.2之前,从库在读请求时,不会判断数据是否过期,返回过期数据。3.2之后,如果读取数据过期,从库不会删除,但是会返回空值。
redis主从延迟导致过期时间延后
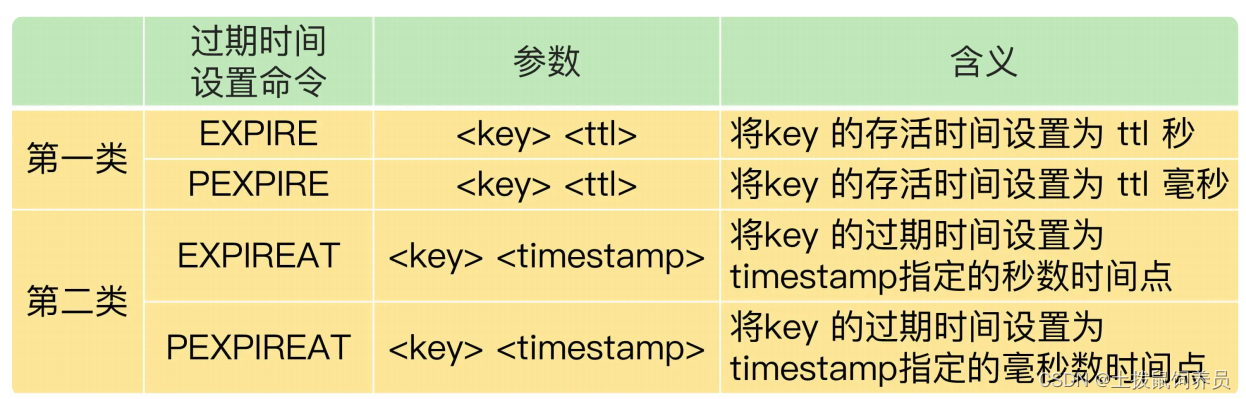
- 使用expire ,因为主从同步延迟,导致从库执行延迟,导致过期延迟。
- 在业务应用中使用 EXPIREAT/PEXPIREAT 命令,把数据的过期时间设置为具体的时间点,避免读到过期数据(让主从节点和相同的 NTP 服务器(时间服务器)进行时钟同步)
不合理配置项导致的服务挂掉
protected-mode 配置项
- 当
protected-mode为yes时,只能在部署的服务器本地进行访问,其余哨兵在其他服务器,哨兵之间无法通讯,主库故障无法判断下线,主从切换 protected-mode no ,bind 192.168.10.3 192.168.10.4 192.168.10.5这样设置保证了主从切换,保证了哨兵安全性。
cluster-node-timeout 配置项
- 配置项设置了 Redis Cluster 中实例响应心跳消息的超时时间。
- 如果执行主从切换的实例超过半数,主从切换时间又长,可能导致整个集群挂掉。
slave-serve-stale-data配置项为no时,只能服务INFO,SLAVEOF命令,避免在从库数据不一致
slave-read-only设置为yes时,从库只能读取读请求,无法处理写请求。
脑裂
脑裂,就是指在主从集群中,同时有两个主节点,它们都能接收写请求。客户端不知道往哪个主节点写数据,不同的客户端会往不同的节点写入数据。
- 主从复制看master_repl_offset 和 slave_repl_offset 的差值,判断是否数据丢失。
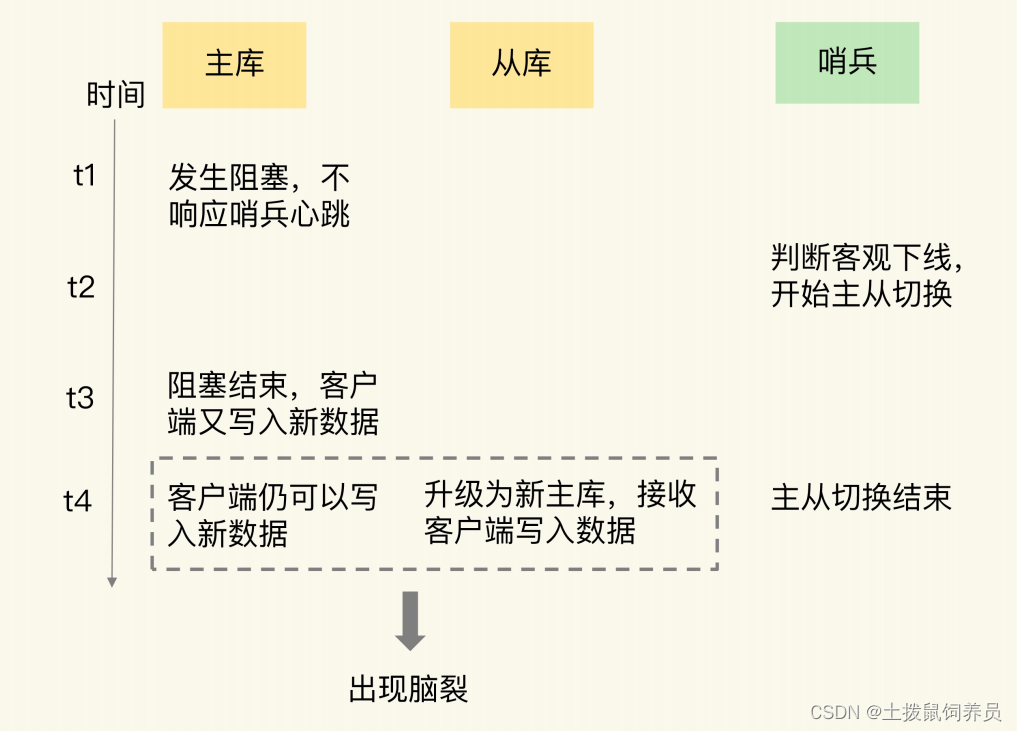
脑裂会导致数据丢失
- 主从切换后,从库一旦升级为新主库,哨兵就会让原主库执行 slave of 命令,和新主库重新进行全量同步。而在全量同步执行的最后阶段,原主库需要清空本地的数据,加载新主库发送的 RDB 文件,这样一来,原主库在主从切换期间保存的新写数据就丢失了。
- 在主从切换的过程中,如果原主库只是“假故障”,它会触发哨兵启动主从切换,一旦等它从假故障中恢复后,又开始处理请求,这样一来,就会和新主库同时存在,形成脑裂。等到哨兵让原主库和新主库做全量同步后,原主库在切换期间保存的数据就丢失了。
如何应对脑裂问题?
min-slaves-to-write:这个配置项设置了主库能进行数据同步的最少从库数量;min-slaves-max-lag:这个配置项设置了主从库间进行数据复制时,从库给主库发送 ACK消息的最大延迟(以秒为单位)。- 即使原主库是假故障,它在假故障期间也无法响应哨兵心跳,也不能和从库进行同步,自然也
就无法和从库进行 ACK 确认了。这样一来,min-slaves-to-write 和 min-slaves-max-lag的组合要求就无法得到满足,原主库就会被限制接收客户端请求,客户端也就不能在原主库中写入新数据了。 - 假设从库有 K 个,可以将 min-slaves-to-write 设置为 K/2+1(如果 K 等于 1,就设为 1),将 min-slaves-max-lag 设置为十几秒(例如 10~20s),在这个配置下,如果有一半以上的从库和主库进行的 ACK 消息延迟超过十几秒,我们就禁止主库接收客户端写请求。
- 即使 Redis 配置了 min-slaves-to-write 和 min-slaves-max-lag,当脑裂发生时,还是无法严格保证数据不丢失,它只能是尽量减少数据的丢失
- 脑裂产生问题的本质原因是,Redis 主从集群内部没有通过共识算法,来维护多个节点数据的强一致性。它不像 Zookeeper 那样,每次写请求必须大多数节点写成功后才认为成功。当脑裂发生时,Zookeeper 主节点被孤立,此时无法写入大多数节点,写请求会直接返回失败,因此它可以保证集群数据的一致性。