从上个世纪本腾I电脑播放VCD,通过巧妙的算法优化,可以在损失部分效果的情况下在低性能的电脑上播放VCD。时至今日,硬件性能大幅飙升,许多算法近乎“失传”了。但对于充满好奇心的程序员,研究这些算法能够更加了解多媒体底层实现原理。本文是资深多媒体开发工程师鲍金龙在《移动音视频开发进阶暨新书分享会》上的分享整理而成。谨以此文向鲍金龙这样还在一线开发的多媒体老兵致敬。
文 / 鲍金龙
整理 / LiveVideoStack
大家好,我是第二次参加LiveVideoStack举办的活动,第一次参加的时候我准备了两部分内容:程序化和流行的VR、AR。当时出品人陆老师(陆其明)谈到单纯地讲程序化太偏,可能整体效果不好,于是我临时改换了演讲主题,讲另外一个也就是VR、AR的案例。但是在参会时有人向我反映,在这种纯粹的讲代码讲技术的特殊行业,只讲例子反而不如今天讲的这个,所以我的思想发生了变化。这次来分享,我就迫不及待的把之前准备的东西拿出来,今天的内容也比较适合,短小精悍。我会与大家分享几个小例子和编码中一些小的技巧,而最近火热的区块链播放器,AI增强的另外一些编码器主题可能太大,需要更多的时间与大家讨论。我认为这些话题有可能在今年10月份有可能有结果,现在定论为时尚早。程序开发就是如此,等到大家出结果的时候,可能风口已经过去,大家也已经不追了,这是一种趋势。
我今天想与大家分享的有关程序化的最基本原则,如果你写C代码的话应该会对以下内容略知一二。

但接下来我要着重介绍的内容也许你之前并未有所了解。因为在10年前,业界还没有出现像LiveVideoStack这样的技术交流社区。当时在音视频这样一个特殊的技术领域,这种中立开放的技术交流平台是非常少的。当时国内的CSDN也不聚焦在音视频上,所以分享想法与观点就比较困难。我在CSDN确实分享过这些东西,但是,听众也不多。
这些话题是什么呢?

第一个话题是上古时代的SIMD技术。我们知道,英特尔SIMD技术是在1997年发布的。但是在那之前,在奔腾处理器的时代,大家也有使用视频播放器的需求。那时候程序员想了很多的办法,实现了类似于SIMD的技术,也就是单指令多数据技术,用普通指令模拟执行 。当时的这个代码现在不太能找到,其最经典的作者是梁肇新先生,一位令人尊敬的前辈。
第二个话题是上古时代的机器学习。这里介绍一种比较原始的机器学习和统计分析的例子。如果探讨DCT编码中DCT系数的分布规律,非零系数的分布是很稀疏的,换句话说当你看到一个8*8的块,看到图像的数值范围分布是非常少的,并不是分布在所有的数据范围内的,那么当你看到这种分布之后便有可能会得出一种很实用的快速算法。当时这个算法用于IDCT变换时创造了一个奇迹,其性能大幅领先于当时所有的著名算法200%以上。
第三个话题是快速开平方和并行查表。近些年这些技术在移动互联网、软件、手机、ARM等平台上复活了。因为在2005年时,这些技术我准备放弃了,因为当时大家都在用GPU CUDA、DSP,可能永远用不到这些了。但是马上到了2007~2009年,以 IOS、安卓为代表的移动互联网终端操作系统诞生,手机芯片性能很弱需要大幅优化;而且当时这些手机SoC中也没有GPU加速。也正因为这样快速开平方与并行查表再次被重视,得以快速发展,使用的效果也非常好。
第四个话题是使用动态代码做快速重采样。动态代码之前多被用于嵌入设备,包括图形处理,尤其在显卡的驱动上都在被使用。但是在移动平台,或者对于下一代的编解码技术,在仿射变化等技术上需要大量的重采样计算,那么当需要极度的性能优化时我们可以使用动态代码进行快速重采样。
一、上古时代的SIMD技术
1、极端应用

关于这个话题的例子是视频YUV转RGB。上个世纪还没有YUV加速,显卡最多是65536色,16位色,甚至是256色,性能上十分捉襟见肘,如何让用户看上VCD?有人提出一种极端的堪称世界纪录的方法以满足这种需求,直接用数值计算 :r=g=b=y。这就使得我们不需要任何加速,和memcpy一样直接进行拷贝。

虽然因此导致了视频画面发红(紫),但这种算法至少改进了无法观看或
观看卡顿的现象。但是很快有人思考其实不需要如此极端,并进行了稍微改进。也就是做一个查表。
2、查表

以上是详细算法。对y进行详细计算,实际上是用整数计算再做一个裁减。这种算法显示的是黑白电影,效果比较好,画面没有了色差,几乎与原画一致,但处理速度只是稍微慢了一点点。这就是所谓的在VCD时代处理大家看的黑白视频的一些技术。
3、进阶
接下来,如果大家想观看彩色视频该怎么办?当然不能是直接复制了。如果按照标准进行计算,那时还没有SIMD技术,只能常规进行一次一次的乘法,计算量浩大;加之那时CPU性能有限,即使算一个320*240分辨率的视频硬件也无法应对。面对这种困境有些人提出了新的算法,这种算法不仅在X86计算机上存在:例如在一个32位寄存器中储存两个小于等于255的无符号短整数时,可以给它乘上一个小于等于128的无符号整数,这个效果等于并行做了两次短整数乘法。如果从C语言开发的角度理解这个例子应该不难。用32位寄存器保存2个无符号的16位整数,要保证计算结果不会越界。
为了计算方便我们可以把这个式子稍微转换一下,调整常数,把乘法提出来。

然后用一个简单的乘法, 可以乘64或者2.018*32直接就等于2 。

当然这个效果是非常粗糙的,但是这样节省了做乘法的次数,之前每个点要做5次乘法,现在只需要4次了,而用“SMID”技术只需做两次。

因为这段汇编语言很长,我摘取了一部分。这种情况基本采用了一般的汇编语言编写技巧,在读取的时候一次读四个字节进来,然后取中间的两个,这样数据打包的操作都不需要了;再一次并行做两个乘法,之后进行加点、移位等操作,后面的加法等操作是一个个做的。

这个代码如果相比于用编译器对C语言进行全程优化的版本,速度快一倍。那么将这个效果跟ARM的V6T2进行对比,如果大家写过ARM体系结构下的汇编语言便能了解,那时有SIMD但是其并行度只有2,也就是一次做两个乘法两个加法减法。它的提升幅度跟今天这个算法是类似的,并不能做到完全的倍速加速,基本上耗时降低到0.6,0.7就已经很显著了。但这个颜色跟精确解码还是有点差距的,如果你想要做得更好 一点,可以加一些简单的非常快速的DITHER。当然不用也可以,画面也能看。其精度相当于RGB555,但由于上面介绍的这种算法会损失部分精度,画面颜色会偏暖。
二、上古时代的机器学习

第二个话题的例子是一维IDCT。 如果算1个点,用一个标准的原始reference算法,需要做8个乘加运算,8个点的就64个乘加运算,这样非常慢;如果使用快速算法,快速算法用加法移位替换乘法,一般小于16个乘法,这样相当于每个点只做了2次乘法运算,所以说IDCT快速算法是非常有效的。
这时候我们思考,那时还没有SIMD技术,能不能做的更快一点呢?
1、统计分析

我们可以在解码器里加入一些统计代码来统计一下IDCT的系数。I帧的8*8dct矩阵平均有7个非零点,也就是64个点当中只有7非零点,至于P、B因为它的残差更小,平均只有2.8个非零点。这样平均到每个行上面非零点更少了不够一个。面对这种情况就可以用最简单的算法,一个非零点做一次乘法,8个点做8个乘法就可以解决。这比IDCT快速算法又快了很多,两个非零点的情况也是类似的。如果说两个以上系数不为0用快速算法就可以解决,因为用一个点算不如快速算法。面对这种情况,我们可以直接准备这三个类型的函数。
2、实施方案

当然这里有个问题值得我们探讨,这个算法和标准算法的区别是它需要判断非零点。判断非零点是一件很慢的事情,我们可以看到一些开源型代码,包括fast,IDCT或者AAN,或者是JREV IDCT,这些非常著名的算法里面都有进行判断的代码,这些代码自身带有很大的性能损失,我们能不能避免这件事呢?如果做DCT系数解码的时候,一个DCT系数如果都是零解可以不用编码,直接skip这个块。在做DCT解码时解非零系数的时候,只需填一个表就行了,填写unsinged chart dctinf[8],或者int64,一个比特代表一个非零点,这种处理对性能的损失是非常小的。那么这个函数应该怎么准备呢?我们可以使用一个256个入口的函数,因为一行IDCT有8个标志位,我们可以先找一个非零点有8个入口,两个非零点有56个入口,其余的优先解快速算法就可以了。调用的时候可以把这个8个比特位当成一个表的索引直接调用。下面就是一个测试结果。
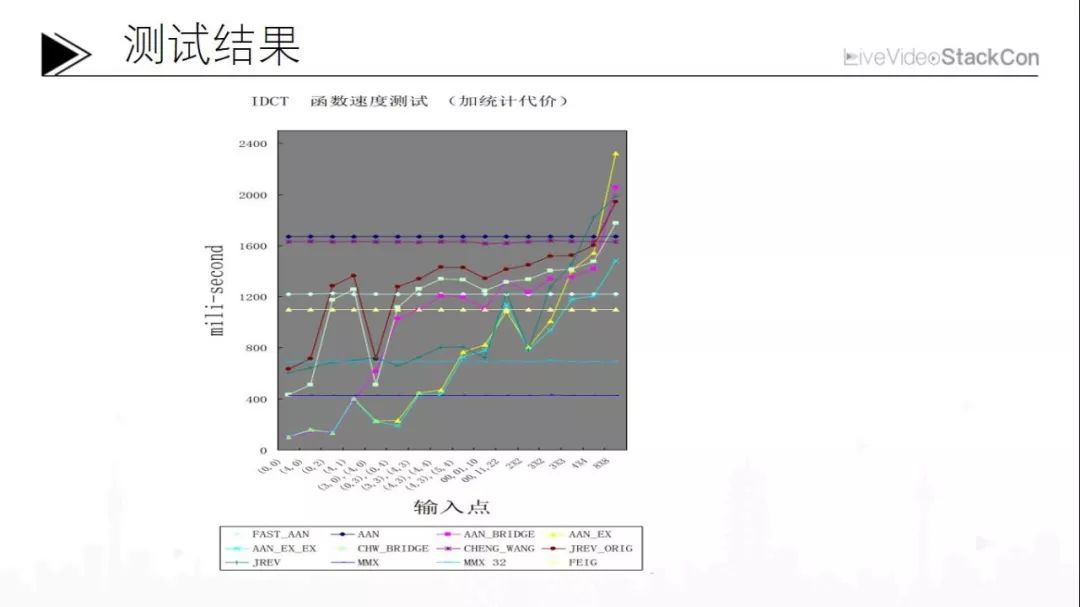
这个测试同时做了MMX的实验,我们可以看到水平线是没有做统计分析的标准算法,这是恒定的值。我们可以看到,英特尔的IDCT 400多clock完成;精度更高的MMX技术接近800多clock;二维IDCT也就是FEIG大约900多clock。我们使用的这个加入统计分析的算法其测试结果是典型的增长曲线;最快的结果就是带MMX技术的,可以通过最下面的几条曲线看出。在常规的情况下,也就是非零点非常少的情况下,这种技术的速度远远超过了一般的MMX算法。
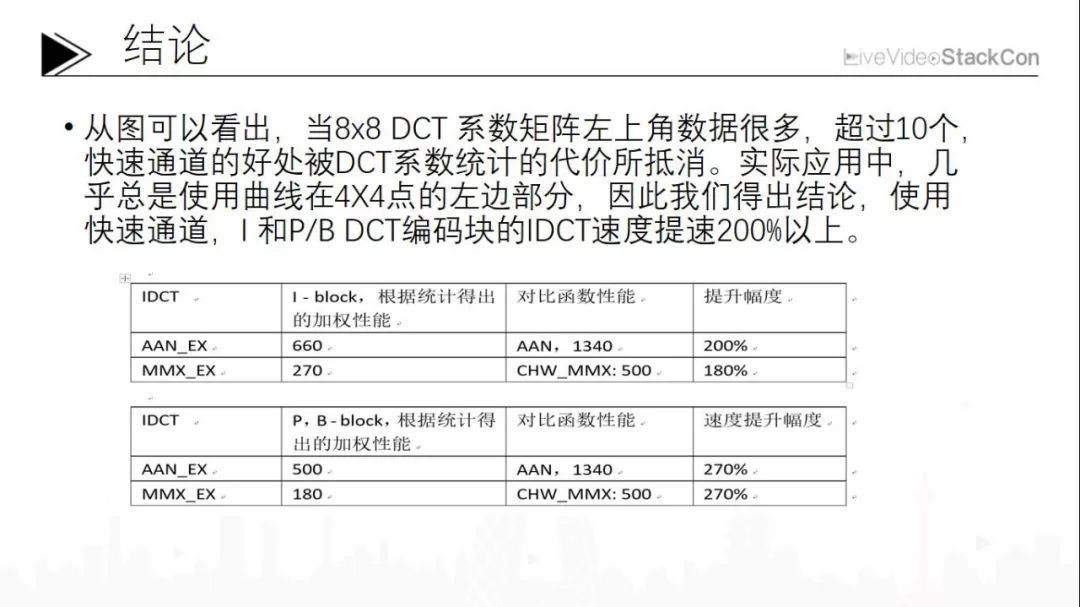
由此我们可以得出结论:一般来说,只有在十个以上零点的时候,统计分析型IDCT,速度明显的下降,跟MMX技术持平,这也是统计分析的代价。但是当在常规应用时,因为平均只有七八个零点,最严重情况下也不过如此,所以还是快很多的。也就是说在I-block时,性能提升幅度大概是180%至200%;如果是P、B-block时性能提升幅度可达270%以上,这是一个相当惊人的结果,历史上从未有过这样一个快速算法能一步提升如此巨大,一般来说少一个乘法少两个乘法就可以发表一篇论文了,但这个提升如此巨大确实令人惊叹。可奇怪的是,这种快速算法一直没有被人们整理与描述,而是作为一个传说在程序员中流传,大家认为不可能存在查表。我们需要注意的是,查表不是查运算,而是查一个函数指针表。
三、快速开平方与并行查表
第三个话题是快速开平方和并行查表。很早以前也就是在Windows图形化窗口普及之前出现的一些3D游戏就要大量的浮点运算,即使做一个开方也无法避免。但这之中有几个奇迹般的开方函数,这个函数原理究竟是怎样的,我一直没有研究透彻。这是一个很神奇的代码,你可以看到它里面有一个魔法系数,也就是这个0x5f3759df。这是一个很神奇的系数,其运算也很诡异,最后通过一个从整数到浮点的强制转换就可以使这个结果返回,相当于牛顿迭代法迭代了三次。它的速度比标准的math.lib.sqrt的函数快了3倍,这在当初也是个奇迹,一直没有人能对此进行合理解释,大家有兴趣可以自己研究一下。

我还想分享另外一个想法。当数值动态范围太大时我们可以调用FastSQRT来算;但是动态小的时候,我们可以不算而是先算好然后查表。紧接着随着SIMD的出现,我们也可以用SIMD、SQRTPS这样的来做4个查表甚至8个16个查表,这些都比一次查一个更快。在此之后大家就改用SQRTPS了。但是随着指令的发展,大家发现可以进行并行查表,并行查表出现使得处理速度再上一个台阶。
这里讲两个例子:
1、ARM-neon,VTBX指令

第一是ARM-neon、VTBX指令。VTBX指令几乎是为我们量身打造的,以上是原代码。首先声明Table并加载到相应的计算器里去;之后直接调用VTBX.8一条指令就可以完成。这比开放快了许多。
2、SSSE3代码
第二是SSSE3代码。在英特尔的SSSE3之前,并行查表还是不可能的。但是在SSSE3出现之后,它提供了一个被称为pshufb的指令。这实际上是一个根据索引改变自己顺序的排列组合指令,我们可以用它拿来查表,下面是用它来查表的一个例子:

如果是AVX1代或者以前的代码,寄存器有效长度是16个字节,所以当做32字节的时需要进行两次,中间进行切换。这个代码是最早的代码,但如果是AVX2,或者AVX512代码更短,一次查表就能查完。
四、使用动态代码做重采样
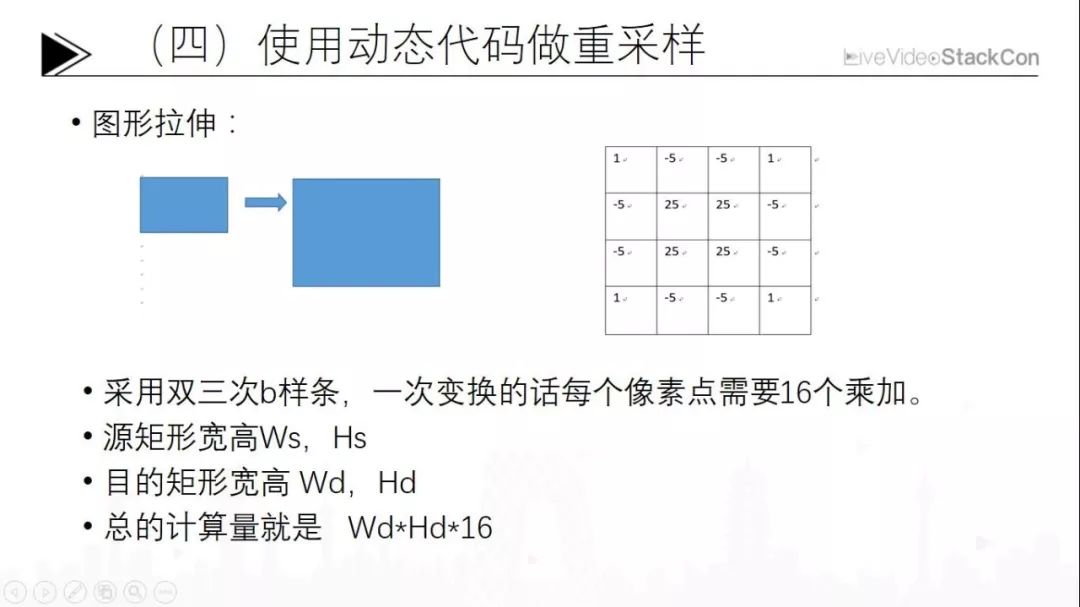
第四是利用动态代码做重采样。以图形拉伸为例,图形拉伸采用不同的算法会产生抖动,例如比较粗糙的临近点法、双线性法。而性价比较高的是双三次b样条,质量好而且速度也能够接受。一般的情况下,按照算法原理来说是一次变换上面的参数矩阵, 4×4也就是16个乘加。当我们做一次拉伸的时候,可以看出来是目的像素总数乘以16,总体来说计算量还是非常庞大。
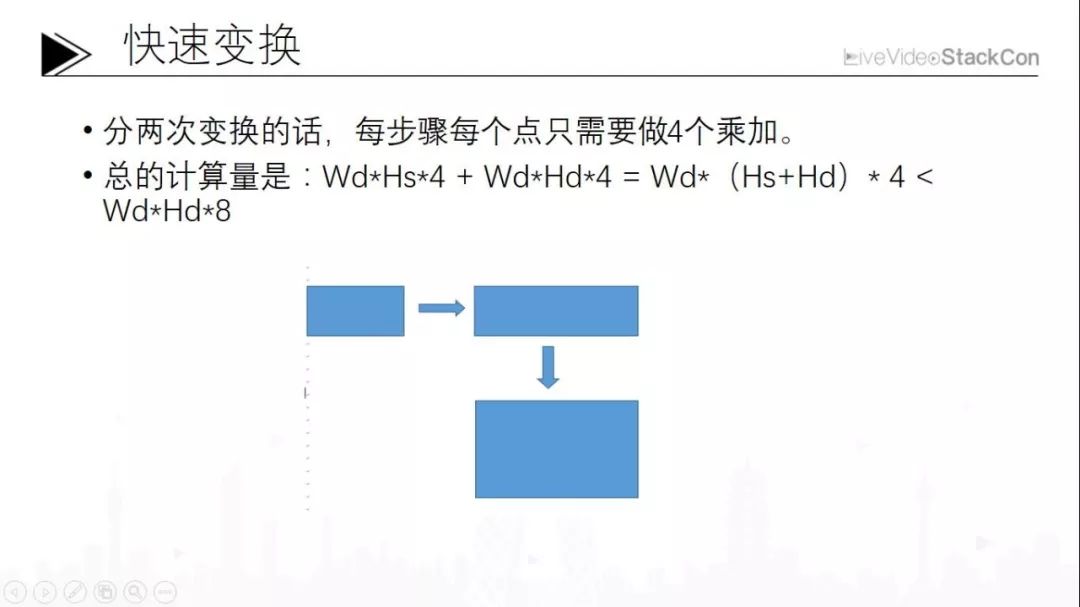
如果是快速变化的话需要进行两次,先进行水平变化再进行垂直变化。这使得运算量被大幅减小,同时预先生成的参数表体积小很多。这些改进带来的实际性能提升可达到3倍以上,可以说是巨大提升了。一般我们现在看到的,不论哪里的代码,做一个拉伸都是做两次而不是做一次;当然也有特殊情况下迫不得已做一次的,比如当我们进行旋转或者一些特殊变换时,做两次变化实在不方便。最后面的例子会讲做两次变化会有多么复杂。

以这种情况为例,例如黑方块中存储了原始图像的数据。因为是拉伸,一定要在中间要插入一些数据,插入数据时基本遵循两点:第一是根据它的位置计算相应乘法的四个系数,以此对应的原始的像素就是四个像素;第二个是做乘法时先查表,查表之后load四个像素进来,然后做四个乘加。

做两趟虽然优化了很多,但还是不够的。例如以此方法对1080p的视频进行拉伸处理,做两趟拉伸的时候按照现在的CPU性能还是非常慢,一般来说单核心也需要二三十毫秒;如果是4K就更不行了。能不能更快一点?分析一下不难得出,查表有天然的劣势:第一是两个点四个像素一样,但写静态代码、查表是无法预先判断出来这一点的,于是就会重复地读取源像素;第二会造成大量的地址不对齐情况。以下是解决办法:
1、动态代码

动态代码可以解决以上两个问题。什么是动态代码呢?这个函数在执行的时候,我们获取了原始宽和高和目的宽和高,可以立刻编译生成一对代码,在编译的时候我们就可以把这个宽高信息完全写进代码。这样这个代码可以做得很短小精悍,避免任何重新读取的情况。下面是具体过程:首先输入拉伸参数,将参数写在内存里面;根据拉伸比生成参数数组。每条指令都要判断,如果这个像素点需要重复使用的时候,可以PUSH或者MOVE,储存以便于下次运算时使用。在这之后用SIMD指令一次读取多字节进来,读取数据时候地址对齐。我们需要哪些的时候,通过一类PSRLQ指令,PSLLQ、或者是其他的一些类似的指令,一次将其读取出来,这样读取的次数就少很多了。这两点上的改进十分明显,通过一个保守的测试可以看出,使用双三次b样条拉伸的动态代码,SSESE3的版本提高了15%,neon版本提高了30%。一般情况下动态代码等于全展开。如果是写静态代码可能4个像素一展开,8个像素一展开,动态代码简单一点的则是全展开。这一个函数没有循环而是把这一行全部做完。这个代码很大,有可能一个函数一兆多,而且在更夸张的情况下,例如如果我们将来涉及到仿射变换,或者是VR防变形技术,这个函数可能更庞大,写完一个有16兆大小。但是没有关系,有CPU预读取技术的存在,尽管函数大但跑起来依旧是很快的。其实我们可以计算出一个周期,也可以添加循环进去,但是做完这个带来的提升效果不显著,所以后来我写这些代码的时候一律全展开。
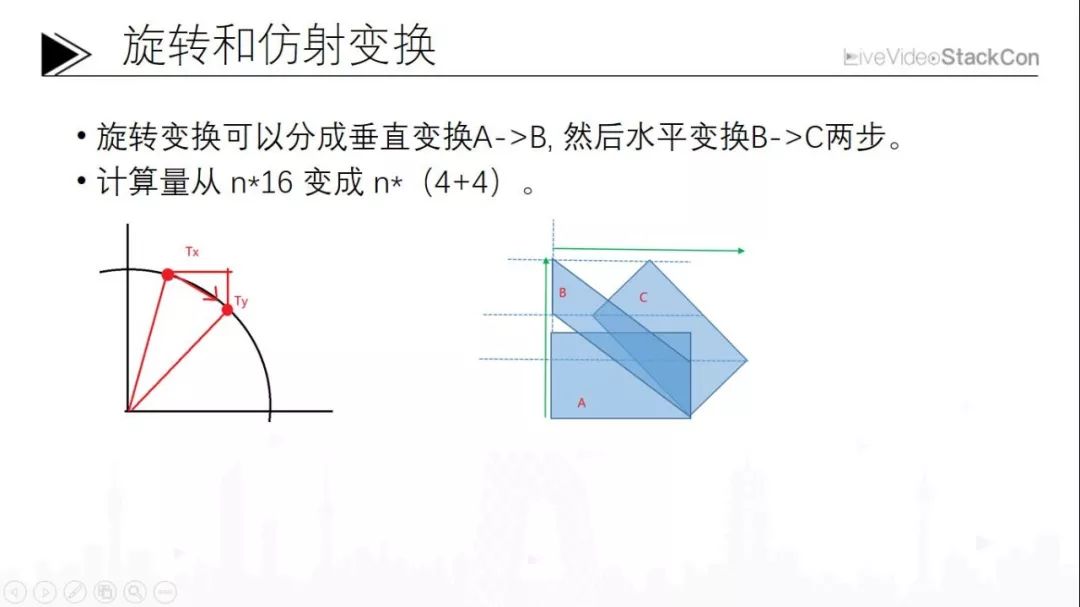
接下来是旋转。大家知道旋转是仿射变换的一种,旋转可以通过两步实现的,先做一个水平位移,再做一个垂直位移。图像基本就是这样进行旋转操作,先可以水平向上拉伸,拉伸为一个平行四边形再水平剪切,相当于旋转。这个计算量相对来说是降低了非常多。但这种情况非常复杂,跟其他的两个点阵点都是整数直接相对应的情况相比差别很大。
2、垂直变换
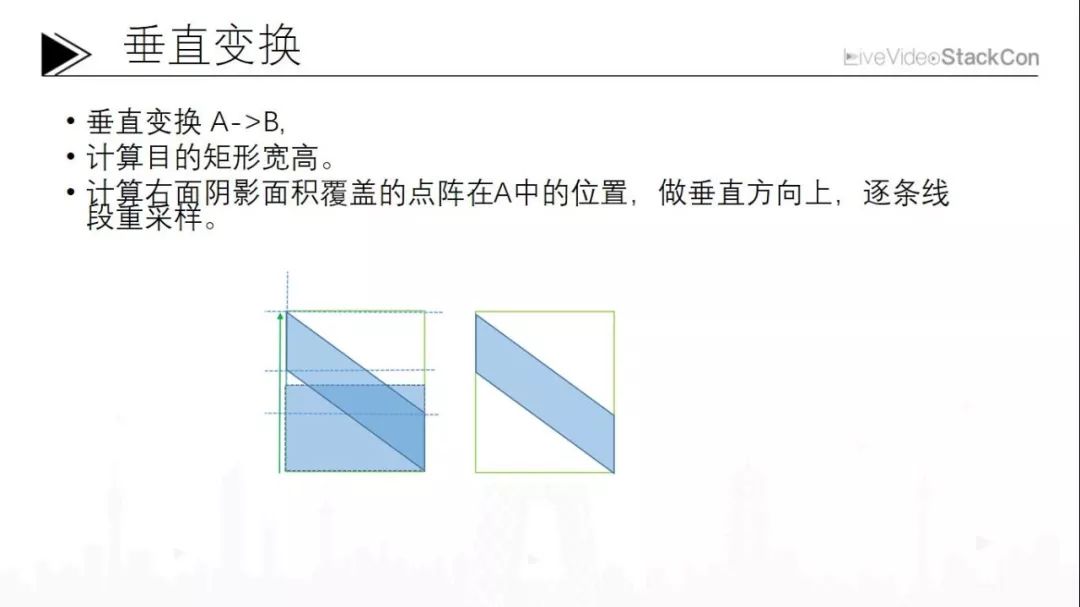
第一步是垂直变换。第一次变化的目的是內接矩形,这个线是「浮点」的。在做变换时候,如果想完全覆盖阴影,那么用的时候必须在点阵上采集数据,所以应当先逆向把点阵数据映射到原来的面积上,这一步相当于做了一个反锯齿。目视的是平行四边形,但在计算的时候并没有算实际上平行四边形的浮点数据,而是临近的一个整数上的位置数据,也就是进行重采样。这个过程跟以前任何一个重采样算法相比都是很相似的。一般来说旋转或者是仿射变换都有一种比较简单的甚至可以用临近点法;但如果是要编解码,要求最小的残差,这个时候还是要B样条。在HEVC, 264的时候大家都看到了,它在分数像素的时候,基本都是用四阶B样条来做的。
3、水平变换
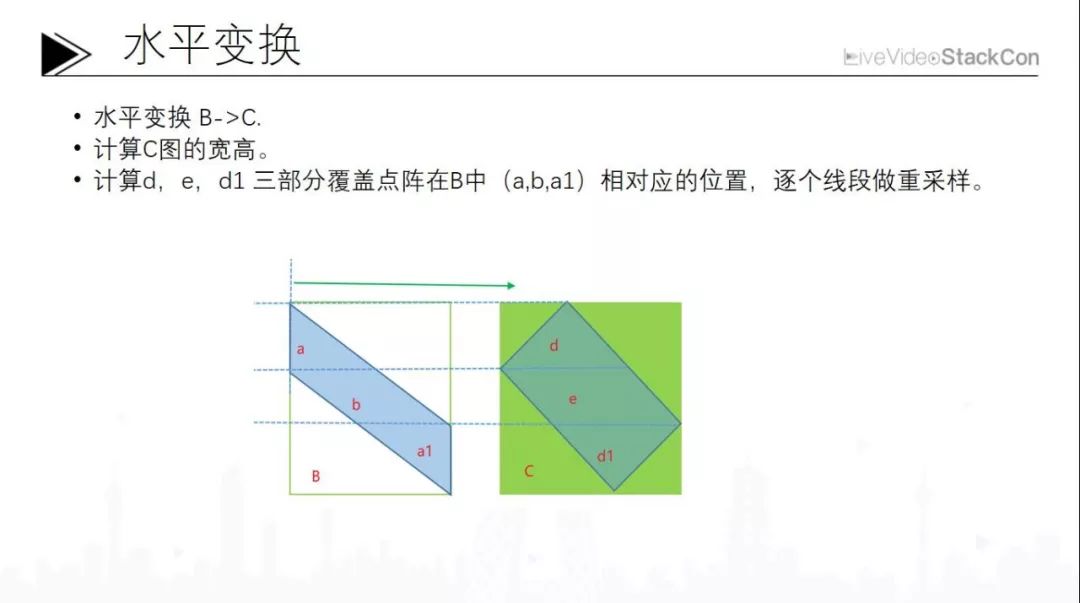
第二步是水平变换。和之前垂直变化相似,只不过这里有三个明显的部分:a1d1是一对相似三角形,中间b是一个平行四边形的拉伸,但这种拉伸不是等距的,每个点的拉伸的比例都不一样,所以每个点都要重新算。这样做两次就会造成动态代码非常大的同时运算量少很多,这种情况下运算速度也会非常快。用这种方法处理完成后,基本上处理速度会有一倍左右的提升。
4、结果

两次变化本身就比一次单个变换快。使用动态代码计算量也会非常小。下一代的编解码器例如H.266或者AV1都会加入仿射变换。做编码器时快速仿射变换必不可少。
以上是我今天为大家带来的分享内容,如果将来有机会我非常想跟大家分享以区块链播放器为代表的新兴技术。这些作为当今音视频领域的研究重点,相信在未来会有进一步的研究成果。
WebRTCon 2018
继2017年第一届LiveVideoStackCon音视频技术大会之后,LiveVideoStack又一次出发——WebRTCon 2018,将于5月在上海举行,这是一次对过去几年WebRTC技术实践与应用落地的总结。
WebRTCon 2018设立了主题演讲,WebRTC与前端,行业应用专场,测试监控和服务保障,娱乐多媒体开发应用实践,WebRTC深度开发,解决方案专场,WebRTC服务端开发,新技术跨界,WebRTC与Codec等多个专场。邀请30余位全球领先的WebRTC技术专家,为参会者带来全球同步的技术实践与趋势解读。