日常工作中,主要还是应用HQL和SparkSQL,数据量大,分布式计算很快;
本地数据处理,一般会使用python的pandas包,api丰富,写法比较简单,但只能利用单核性能跑数,数据量大可能会比较慢;spark可以利用多核性能;
单机上,这里尝试构造一个大数据集分别对pandas和sparksql进行跑批测试:
# 数据集构造
import pandas as pd
import numpy as np
import pyarrow
import sys
import time
from pyspark.sql import SparkSessiondf = pd.DataFrame(columns=['id','sales'])
df['id']= np.random.randint(1,10,800000000)
df['sales']= np.random.randint(30,1000,800000000) # 生成8亿数据
df = df.append(df) # 数据量膨胀一倍
df.to_parquet('parquet_test') # 写入本地文件print(sys.getsizeof(df) / 1024 / 1024 / 1024) # 总数据占用内存:23个g
定义pandas计算函数
pandas的read函数会将数据一次读入内存,本地机器资源不够可能会有内存溢出,这时候要考虑逐块读取,分别对每块进行聚合,再进行累聚合;
def pandas_duration():start = time.time()# df.to_csv('data.txt',index=False,sep=',')df = pd.read_parquet('parquet_test')mid_time = time.time()print('pandas读取数据用时:{:.2f}'.format(mid_time-start))print(df.groupby('id',as_index=False).max()) # 分组求最大值end = time.time()print(end-start)
定义pyspark读取计算函数
# 防止driver内存溢出,可以把资源调大点,笔者电脑64个g就随意填了个32g,分区数结合实际数据大小资源调整
spark = SparkSession.Builder()\.master("local[*]")\.config("spark.sql.shuffle.partitions",24)\.config("spark.driver.memory","32g")\.config("spark.driver.maxResultSize","32g")\.appName('pyspark')\.getOrCreate()def pyspark_duration():start = time.time()# df.to_csv('data.txt',index=False,sep=',')spark_df = spark.read.parquet('parquet_test')mid_time = time.time()print('spark读取数据用时:{:.2f}'.format(mid_time-start))spark_df.groupBy('id').agg({"sales":"max"}).show() # 分组求最大值end = time.time()print(end-start)
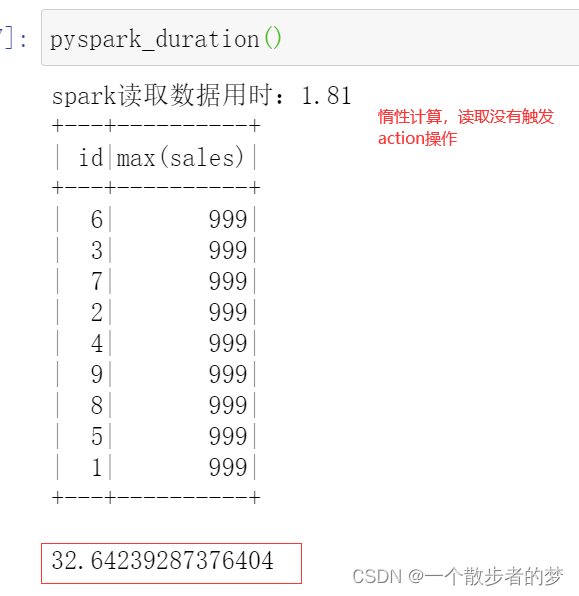
查看spark计算时间:
在整个运行过程中,电脑最大内存使用14%;(包括其他系统软件占用),数据读取计算只花了32秒
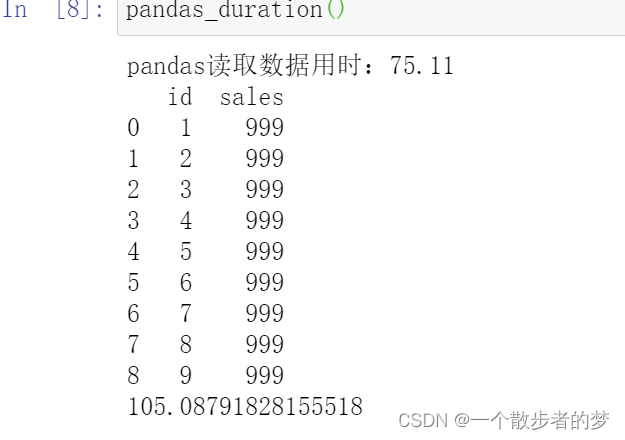
查看pandas计算时间:
计算巅峰时刻内存在80-90%跳动,差点把我机器干爆了,计算耗时105秒,远大于spark处理32秒
结论:
小数据量通常我们使用pandas处理会更快;对于大量数据,即使是单机,充分利用多核性能,我们使用spark读取往往会有更好的表现,不用定义分块读取聚合,计算更快,内存使用表现更好;
数据处理&优化技巧相关,感兴趣的同学可以点击下面链接:
SparkSQL优化:https://blog.csdn.net/me_to_007/article/details/130916946
hive优化: https://blog.csdn.net/me_to_007/article/details/126921955
pandas数据处理详解:https://blog.csdn.net/me_to_007/article/details/90141769




