摘要:Web 应用程序中经常使用数据分页技术,该技术是提高海量数据访问性能的主要手段。实现web数据分页有多种方案,本文通过实际项目的测试,对多种数据分页方案深入分析和比较,找到了一种更优的数据分页方案Row_number()二分法。它依靠二分思想,将整个待查询记录分为2部分,使扫描的记录量减少一半,进而还通过对数据表及查询条件进行优化,实现了存储过程的优化。根据Row_number()函数的特性,该方案不依赖于主键或者数字字段,大大提高了它在实际项目中的应用,使大数据的分页效率得到了更显著的提高。
在web应用程序开发过程中,不可避免的要频繁查询数据库中的数据。随着互联网的飞速发展,中大型系统的数据量变得庞大而复杂,要提高系统的响应性能,就需要降低客服端和服务器端数据的传输量,因此大数据分页的功能不可或缺。若选择一个不合理的数据分页方案,大数据在查询时就会引发网络资源严重浪费【1】,网站拥堵,查询界面等待时间过长等一系列严重影响系统性能的问题。所以,一个有效的大数据分页方案对于系统的性能而言至关重要。解决大数据分页的问题,不同的人会采用不同的方法,其访问性能各有优劣。笔者通过比较多种分页研究方案【2】,根据实际案例的测试结果,综合分析各种分页方案的利弊,扬长避短,最终找到一种更优于以往的分页方案,Row_number()二分法。二分思想在计算机中早有应用,二分查找算法就是二分思想的具体体现,将它引入到存储过程中,依靠二分法的思想,对Row_number()存储过程分页进行优化设计,从而加快查询速度,提高大数据的分页效率。
1 动态网页数据分页
Web数据分页是基于降低数据传输量来提高服务响应时间的分页方法。但是不同的数据分页方法,带给Web主机的系统I/O访问性能是不同的。无论是JAVA平台,还是.NET平台,对数据的分页都提供了多种方法,主要分为2大类:一类是内存数据分页,一类是数据源分页。
1.1内存数据分页
所谓内存数据分页【3】就是当客户端向 Web服务器发出查询请求时,Web 服务器响应请求并构建 SQL 语句发送到数据库服务器,数据库服务器执行 SQL 语句并返回整个结果集给 Web 服务器,Web 服务器再执行内存数据分页操作并把该页数据发往客户端,完成一次查询。内存数据分页的流程如图1所示:
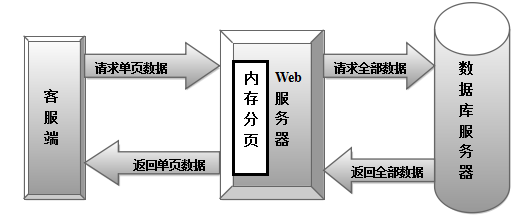
图1内存数据分页
内存数据分页的优点是编程上容易实现,对于少量数据检索效率高,能提高开发者开发的效率。缺点是使用内存数据分页机制时,首先需要把所有的数据库记录调入内存。调入数万条记录进入内存本身需要消耗大量时间,所以当数据量超过百万时,数据访问性能急剧下降,几乎让Web服务器的系统I/O不堪重负,对于大型系统而言,内存数据分页不能满足基本性能的要求。
对于内存数据分页,在.NET平台下常用的分页方案是GridView控件自带的分页【4】,GridView是DataGrid的后继控件, GridView和DataGrid功能相似,都是在web页面中显示数据源中的数据,将数据源中的一行数据,也就是一条记录,显示为在web页面上输出表格中的一行。GridView控件功能强大,对于分页操作简单容易。 利用GridView控件自带的分页功能实质是把查询的所有数据从后台读取出来,然后通过内存分页的方式返回单页数据,因此第一页和最后一页的显示速度基本相同。常用的查询语句为:Select * from @TableName.
1.2数据源分页
数据源分页【4】是在数据库服务器上实现截取请求页数据的分页操作,在 Web 服务器上无需做分页操作。数据源分页一般采用存储过程[5]的方式,由于存储过程是在数据库服务器中预先编译的,访问存储过程时只需给出存储过程名及参数即可,往返的数据量非常小安全性也更高。数据源分页机制的执行流程如图 2所示。客户端向 Web服务器发出查询请求,Web 服务器响应请求,通过连接到服务器数据库执行存储过程,同时返回请求页记录给 Web 服务器,Web 服务器再把该页数据发往客户端,完成一次查询。
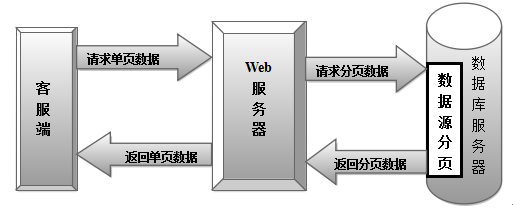
图2 数据源分页
数据源分页的优点是减轻 Web 服务器和数据库服务器的负担,在大数的处理上保证了高效率的分页功能。缺点是分页方法必须由开发人员编程实现,过程较为复杂。
对于数据源分页,人们提出了使用临时表或表变量的方法来提升访问主键字段的效率,其效率也相当高。目前常用到的数据源分页方案有如下五种:首先说明几个变量:@ PageSize表示分页大小,默认值为10;@TableName表示分页表的名称;@ IDField表示分页表的排序字段;@ PageIndex表示当前为第几个分页,默认值为1。
1 Select top and Not in分页:此分页方案的基本思想就是利用id自增数字字段连续不间断时通过分页传递的参数实现分页信息的显示,其通用的存储过程写法为:SelectTop @PageSize* from @TableNamewhere(@ IDField not in (SelectTop @PageSize* (@PageIndex-1) @ IDField from @TableName order by @IDField))order by @IDField.
2 Select top and Max()分页:根据Max()函数的性质,在分页时依赖于数据表的id自增数字段,首先得到排序后的id记录值;然后利用Max()来得到待分页需要的最大记录;最后根据id值得到分页记录信息。这种方式避免了全表扫描的大量I/O操作,其效率相当高。 其通用的存储过程写法为:select top '+str(@pageSize)+' * From @TableName where (@ IDField >(select max(@ IDField) From (select top '+str(@pageSize*@pageIndex)+' @ IDField From @TableName order by @ IDField asc) as TempTable)) order by @ IDField asc .
3 Row_number()分页:Row_number()函数是sql sever2005数据库推出的新功能函数,它的功能是返回结果集分区内行的序列号,每个分区的第一行从 1 开始。其分页存储过程写法为:select* from (select*,Row_Number() over(orderby @IDField) asRowNumber from @TableName ) asTempTable where RowNumber between (@ PageIndex - 1) * @ PageSize + 1 and @PageIndex* @ PageSize.
4游标分页:游标提供了一种对从表中检索出的数据进行操作的灵活手段,就本质而言,游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标总是与一条TSQL 选择语句相关联因为游标由结果集(可以是零条、一条或由相关的选择语句检索出的多条记录)和结果集中指向特定记录的游标位置组成。其通用的存储过程写法为:declare @P1 int, --P1是游标的id,@rowcount int,@str=’select * from @TableName’,exec sp_cursoropen @P1 output,@str,@scrollopt=1,@ccopt=1,@rowcount=@rowcount output,set @ PageIndex=(@PageIndex-1)*@pagesize+1,exec sp_cursorfetch @P1,16, @ PageIndex,@pagesize,exec sp_cursorclose @P1.
5 selectMax()结合临时表:临时表【6】是一种因为暂时需要而创建的数据表,主要用来临时存储数据处理的中间结果。利用该方案的优点是可以摆脱对于数字字段的依赖,能够更方便的应用于实际项目的分页。其通用存储过程的语句为:declare @indextable table(id int identity(1,1),nid int) --定义表变量insert into @indextable(nid) select @IDField From @TableName order by @IDField asc;select top (@pageSize) * from @TableName O,@indextable t whereO.bid=t.nid and (id>(select max(id) From(selecttop(@pageSize*@pageIndex) id From @indextable order by id asc) as TempTable)) order by id asc.
1.3 ASP.NET实现数据源分页的调用
利用ASP.NET提供的DataSet类可轻松的实现数据源分页方案的调用,调用存储过程核心代码如下:
Void FenYe()
{
连接并打开数据库;
SqlConnection con = new SqlConnection(connectionString);
string cmdText = "数据源分页方案名称";
SqlDataAdapter da = new SqlDataAdapter(cmdText,con);
Da.SelectCommand.CommandType = CommandType.StoredProcedure;
da.SelectCommand.Parameters.Add("参数的名称",参数类型,参数大小);
da.SelectCommand.Parameters[0].Value = 参数的具体值;
DataSet ds = new DataSet();
Da.Fill(ds,"DataTable");
GridView1.datasources=ds;//绑定数据到GridView控件显示分页数据
}
1.4现有分页方案的不足
对于上述方案中的select top and NotIn和select top and Max()分页方案,在实际的项目中很难应用。根据NotIn()和max()函数的分页原理,可以发现这两种分页方案存在致命的不足,就是依赖于数据表里的id自增数字字段,并且这些自增数字必须要具有连续性,如果删除数据表里的一条或多条数据,id数字字段不再连续,那样分页的每一页数量就会变得大小不一,这种严格依赖于id自增数字字段的分页方案适用性差,对于数据表中没有数字字段或主键不能按数字大小排序的分页更是一筹莫展,所以,这样的分页方案局限性大,不能广泛应用实际项目。而内存分页GridView和传统的游标分页在大数据的分页上更是严重耗时,不能达到实际网页响应的时间要求。对于max()结合临时表这种适应性强的分页方案,在后期大数据的处理上难以保证时间的效率,随着数据量的不断增大,在构建中间临时表的时候,插入主键列数据到临时表时就会用去越来越多的时间,同时,又额外的开销了临时表和数据表匹配的时间。同max()结合临时表一样,Row_number()函数在大数据后期分页时显示的效率也并不理想,这两种分页方案更适用于中小型的数据分页,要保证大数据的分页效率,就需要用到新的分页方案,Row_number()二分法。
2 Row_number()二分法简介与优化
2.1简介
Row_number()二分法利用二分法的设计思想,此方法最大的特点在于它缩小了查询时数据扫描的范围。由于需要返回查询结果的记录数,若利用select@ RecordCount=count(* ) from +@ Ta-bleName+@ strWhere0语句返回记录数,进行大数据量查询统计时这个语句将耗费大量时间,这会降低系统分页的性能。所以,为了避免统计记录带来的系统整体性能的下降,将统计记录分离为独立存储过程,只在系统加载时统计1次,然后把统计结果以参数的方式传递给Row_number()二分法的存储过程,这样将大大提高分页的效率。根据Row_number()函数的分页原理,建立Row_number()二分法分页并不难,其通用存储过程为(@sum为独立存储过程统计的返回结果):Declare @orderStr varchar(244),if @pageSize*@pageIndex>@sum/2 @orderStr=order by @IDField desc ,else @orderStr=order by @IDField asc,select* from (select*, Row_Number() over(@orderStr) asRowNumber,From @TableName ) asTempTable where RowNumber between (@ PageIndex - 1) * @ PageSize + 1 and @PageIndex* @ PageSize.
2.2优化
对于上文提到的Row_number()二分法分页方案,在系统中还需要数据库的合理设计和sql语句的优化。对于上百万的数据查询,要提高查询的效率,就要用到数据库中的索引【7】,合理应用索引会让查询速度达到成倍的提高。索引分为聚集索引和非聚集索引两种类型,聚集索引在大数据量的查询中,查询的速度快于非聚集索引。所以,在大数据量的分页时,应采用聚集索引。由于聚集索引在一个数据表里只有一个,这个聚集索引的资源也就显得格外的宝贵,主键的默认设置为聚集索引,而很多时候查询的条件,排序的条件并不是主键字段,所以应该修改主键字段的设置,把它设置为非聚集的索引。
例如:以人员信息表mess(id,name,phone,number,work,hometown,email,time)做测试,id列为主键,设置为非聚集的类型,time为排序列,设置为聚集索引,这样在做人员信息的查询时,就会按照时间的索引,快速的找到查询的信息。一般对于多条件查询,可以把多个查询的条件集合在一起设置成为一个聚集索引。以上是仅对于一个数据表查询时建立索引的原则。当涉及到多个数据表时,可按如下案例建立索引:mess(id,name,phone,number,work,hometown,email,time),user(userid,password,power)其中mess为人员信息表,user为密码权限表。现在要查询人员的信息和权限,需要两表连接查询。查询语句为:select * from mess,user,where user.userid=mess.id order by time。根据这个查询语句,为了提高两表的连接效率,应把userid字段和id字段先建立外键关系。根据返回的结果的需要,按照时间排序,对于mess表,依旧以id列为主键,time列结合id列为聚集索引,对于user表,因为匹配的条件为useid,要获得人员的权限,应该以userid为聚集索引查询power列,这样两个表都建立了属于各种的索引,能够快速的查询到相关信息,从而达到整体的查询效率提高的目的。对于多表匹配时,在相应的单表里建立合理的索引能使查询速率达到事半功倍的效果。
同数据库的设计一样,sql语句的优化一样有助于提高分页的效率。通过测试比较,一个查询条件直接用等号匹配的速度高于用 like+%的匹配速度。例如要在前台根据条件查询信息表中人员的姓名,工作和籍贯,若是用一句sql语句可以写成:Select * from mess Where name like @name+’%’ and work like +@work+’%’ and home like @home+’%’。但是试想一下,拥有百万的数据一次一次的像上述sql语句那样like匹配,这样会因为大量的匹配消耗宝贵的时间。所以,存储过程中的sql语句,最好分情况而定:通过查询条件的不同动态匹配sql语句,例如:If(name.text!=””) {sql=select * from messWhere name = @name},If(name.text==””&&work.text!=””&&status.text!==””) {sql=select * from messWhere status = @status and work = @work}。对于多表涉及到的多条件查询,应该把查询范围小的写在查询条件的前面,这样可以缩小筛选的范围,减少后面条件匹配的范围,从而降低查询的所用时间。如select * from mess,user,where user.userid=mess.id and user.name=’a’ order by time,这样的sql语句应该优化改下为select * from mess,user,where user.name=’a’ and user.userid=mess.id order by time.同理,对于多表之间的匹配,也遵循匹配结果范围小的两个数据表优先匹配。
3 性能实验分析
3.1测试平台
数据库:sql sever2008
数据表:人员信息表mess(bid,name,phone,number,work,hometown,email,time)物理大小:103MB,共有一百万零三条数据记录。中铁建企业管理生产计划统计系统中的项目表和施工单位表,项目表的物理大小在数据量为100万条时为375.25MB,施工单位表共包括998个各级施工单位,物理大小为0.07MB。
查询要求:
1.查询mess表中的所有记录,每页返回十条记录结果。
2.查询中铁建企业管理生产计划统计系统中的项目表和施工单位表,返回项目的编号,项目的施工单位编号,施工单位的名称,项目的名称,项目的类型,项目的合同额,项目的开累数,项目的剩余开累数,及录入员,每页返回十条记录结果。
测试环境:华硕笔记本电脑K43T,CPU:A6-3400M,内存:2G。
操作系统:win7旗舰版
3.2测试结果
根据查询要求1记录各分页方案的所用时间:
表1数据表mess共有100万条数据 ms
| 页数 | 第1000页 | 第10000页 | 第50000页 | 第80000页 | 第100000页 |
| GridView | 234 | 2246 | 12722 | 18654 | 26732 |
| 游标 | 5023 | 5104 | 5102 | 5024 | 5103 |
| Select top and Not In | 34 | 157 | 921 | 1364 | 1782 |
| Select top and Max | 16 | 52 | 229 | 334 | 459 |
| Max()结合临时表 | 21 | 59 | 238 | 349 | 471 |
| Row_number() | 50 | 172 | 946 | 1406 | 1838 |
| Row_number()二分法 | 56 | 184 | 952 | 367 | 10 |
根据查询要求2记录各分页方案的所用时间(其中select top and NotIn和select top and max分页方案因为局限性不能对查询数据分页):
表2项目表和施工单位表共有210万条数据 ms
| 页数 | 第1000页 | 第10000页 | 第100000页 | 第150000页 | 第200000页 |
| 游标 | 21750 | 21413 | 22493 | 22514 | 22123 |
| Row_number() | 100 | 1023 | 10350 | 14966 | 20566 |
| Max()结合临时表 | 510 | 1346 | 13542 | 24875 | 355466 |
| Row_number()二分法 | 108 | 1045 | 10389 | 5067 | 10 |
通过表1,表2的数据,可以发现Row_number()二分法是上述所有分页研究方案中效果最好的分页方案,由于Row_number()函数本身并不依赖数据表中的数字段,所以它可以在实际项目中广泛的应用,真正的提高了大数据的分页效率。特别声明:由于笔者所用的测试电脑本身的硬件低端,CPU处理速度慢,远不及真正的服务器的处理速度,所以,在真正的服务器上即使是千万页的信息读取也是高效迅速的。
4 结束语
动态网页设计中分页显示数据有多种实现方法,本文通过上述七种分页方案的实验测试,比较各种分页方案的优缺点,一步一步的分析推导,提出了最优的分页方案Row_number()二分法,通过实际项目的测试,利用该方案能够充分提高大数据分页的效率,此方案对解决中大型系统的数据分页具有一定的指导意义。
参考文献:
[1] 洪新建,张阳,洪新华.对Web数据查询分页显示的设计与实现[J]. 电脑开发与应用, 2007, 6(6): 44.
[2] 付文平,罗键.基于Web的分页技术的设计与实现[J]. 计算机时代, 2007(10): 55.
[3]张素智,刘中锋.基于ASP. NET的Web数据分页实现与性能优化[J].郑州轻工业学院学报(自然科学版),2010( 06) .
[4]陈南. ASP. NET 中大数据量分页技术的研究与实现[J].计算机应用与软件,2011( 04) .
[5] 陈焕通,陈尧妃.基于存储过程的数据快速分页方法[J].软件导报,2008( 12) .
[6]胡配祥,张成叔,陈良敏.SQL临时表在科研管理系统数据处理中的应用[J].洛阳理工学院学报 (自然科学版),2011( 06) .
[7] 陈伟柱,苏中,张俐,王睿. 索引和查找方法 [P]. 中国专利:CN1979469,2007-06-13.
【文章出处:http://www.cnblogs.com/wlandwl/p/paginaction.html】





