深度学习12. CNN经典网络 VGG16
- 一、简介
- 1. VGG 来源
- 2. VGG分类
- 3. 不同模型的参数数量
- 4. 3x3卷积核的好处
- 5. 关于学习率调度
- 6. 批归一化
- 二、VGG16层分析
- 1. 层划分
- 2. 参数展开过程图解
- 3. 参数传递示例
- 4. VGG 16各层参数数量
- 三、代码分析
- 1. VGG16模型定义
- 2. 训练
- 3. 测试

一、简介
1. VGG 来源
VGG(Visual Geometry Group)是一个视觉几何组在2014年提出的深度卷积神经网络架构。
VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG19最为著名。
VGG16和VGG19网络架构非常相似,都由多个卷积层和池化层交替堆叠而成,最后使用全连接层进行分类。两者的区别在于网络的深度和参数量,VGG19相对于VGG16增加了3个卷积层和一个全连接层,参数量也更多。
VGG网络被广泛应用于图像分类、目标检测、语义分割等计算机视觉任务中,并且其网络结构的简单性和易实现性使得VGG成为了深度学习领域的经典模型之一。
本文参考内容:https://www.kaggle.com/code/blurredmachine/vggnet-16-architecture-a-complete-guide
2. VGG分类
下图中的D就是VGG16,E就是VGG19。
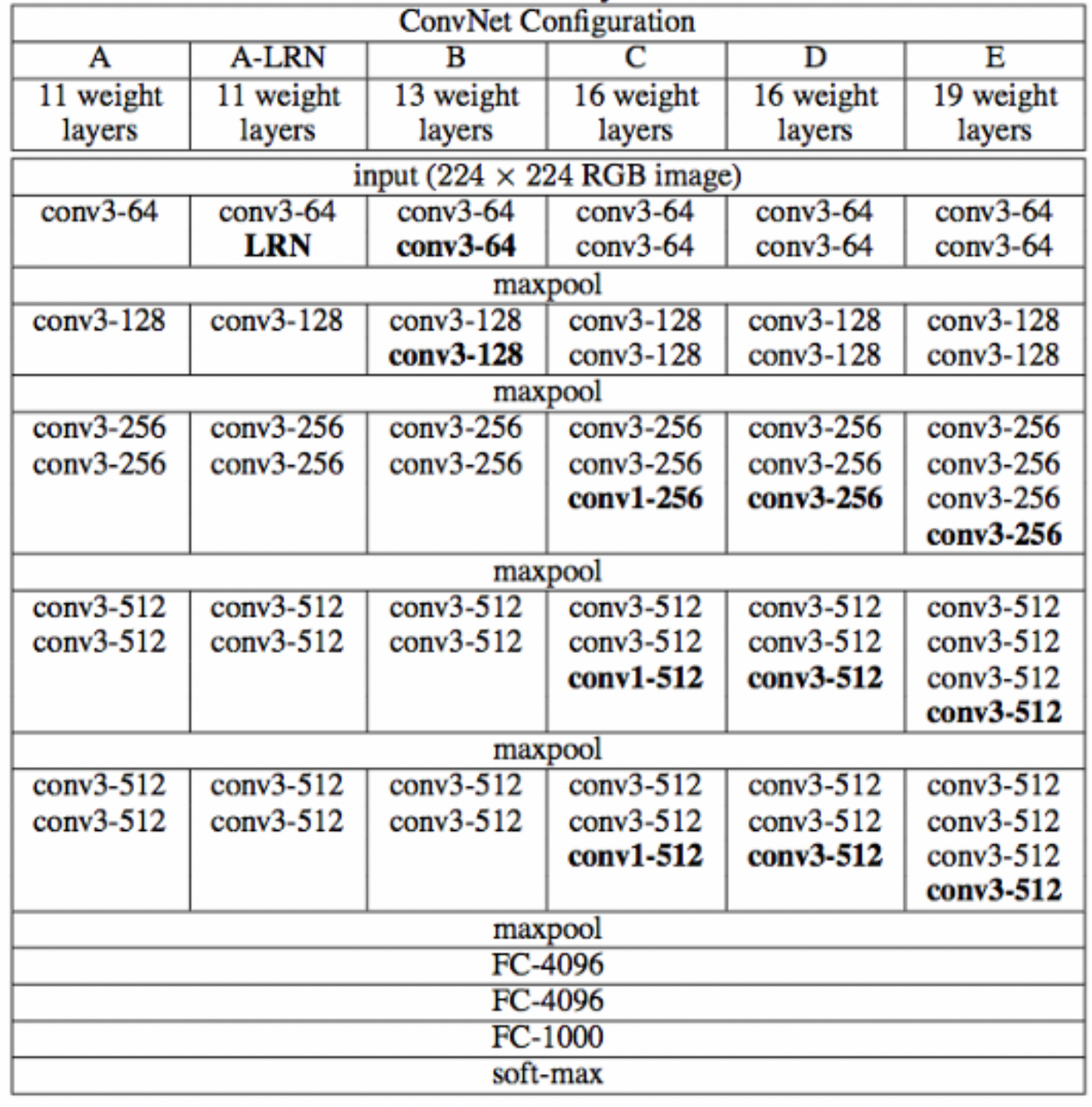
从图中看出,当层数变深时,通道数量会翻倍。
一些特点说明 :
- 每个模型分成了5个Block,所有卷积层采用的都是3x3大小的卷积核 ;
- 模型带LRN的,是加了LRN层;
- 使用 2x2 小池化核;
- 网络测试阶段将训练阶段的三个全连接替换为三个卷积;
- 测试重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入。
3. 不同模型的参数数量
单位:百万
| Network | A,A-LRN | B | C | D | E |
|---|---|---|---|---|---|
| 参数数量 | 133 | 133 | 134 | 138 | 144 |
VGG的参数数量非常大。
4. 3x3卷积核的好处
- 参数少: 一个3x3卷积核拥有9个权重参数,而一个5x5卷积核则需要25个权重参数,因此采用3x3卷积核可以大幅度减少网络的参数数量,从而减少过拟合的风险;
- 提高非线性能力: 多个3x3卷积核串联起来可以形成一个感受野更大的卷积核,而且这个组合具有更强的非线性能力。在VGG中,多次使用3x3卷积核相当于采用了更大的卷积核,可以提高网络的特征提取能力;
- 减少计算量: 一个3x3的卷积核可以通过步长为1的卷积操作,得到与一个5x5卷积核步长为2相同的感受野,但计算量更小(即2个3x3代替一个5x5);3个3x3代替一个7x7的卷积;因此,VGG网络采用多个3x3的卷积核,可以在不增加计算量的情况下增加感受野,提高网络的性能;
5. 关于学习率调度
学习率调度(learning rate scheduling)是优化神经网络模型时调整学习率的技术,它会随着训练的进行动态地调整学习率的大小。通过学习率调度技术,可以更好地控制模型的收敛速度和质量,避免过拟合等问题。
常用的学习率调度包括常数衰减、指数衰减、余弦衰减和学习率分段调整等。
本文将使用StepLR学习率调度器,代码示例:
schedule = optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=0.5, last_epoch=-1)
optim.lr_scheduler.StepLR 是 PyTorch中提供的一个学习率调度器。这个调度器根据训练的迭代次数来更新学习率,当训练的迭代次数达到step_size的整数倍时,学习率会乘以gamma这个因子,即新学习率 = 旧学习率 * gamma。例如,如果设置了step_size=10和gamma=0.5,那么学习率会在第10、20、30、40…次迭代时变成原来的一半。
本文使用的 optimizer是SGD优化器。
6. 批归一化
nn.BatchNorm2d(256)是一个在PyTorch中用于卷积神经网络模型中的操作,它可以对输入的二维数据(如图片)的每个通道进行归一化处理。
Batch Normalization 通过对每批数据的均值和方差进行标准化,使得每层的输出都具有相同的均值和方差,从而加快训练速度,减少过拟合现象。nn.BatchNorm2d(256)中的256表示进行标准化的通道数,通常设置为输入数据的特征数或者输出数据的通道数。
在使用nn.BatchNorm2d(256)时,需要将其作为神经网络的一部分,将其添加进网络层中,位置是在卷积后、ReLU前,经过训练之后,每个卷积层的输出在经过BatchNorm层后都经过了归一化处理,从而使得神经网络的训练效果更加稳定。
二、VGG16层分析
1. 层划分
- 输入:224x224的RGB 彩色图像;
- block1:包含2个 [64x3x3] 的卷积层;
- block2:包含2个 [128x3x3] 的卷积层;
- block3:包含3个 [256x3x3] 的卷积层;
- block4:包含3个 [512x3x3] 的卷积层;
- block5:包含3个 [512x3x3] 的卷积层;
- 接着有3个全连接层;
- 一个分类输出层,经过 SoftMax 输出 1000个类的后验概率。
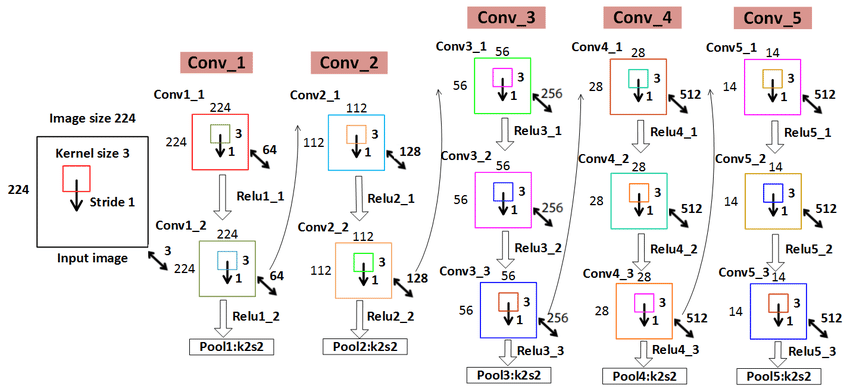
2. 参数展开过程图解
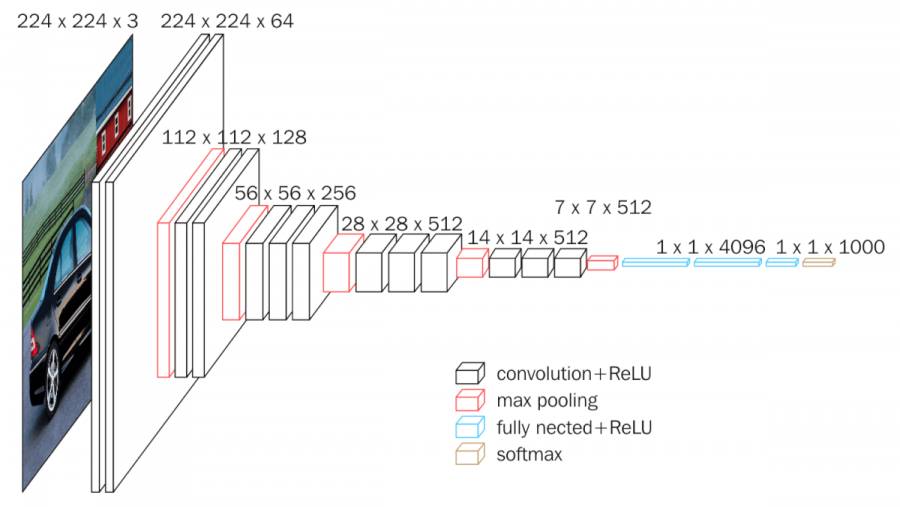
- 上图中神经网络划分了5个block;
- 红色:下采样 (Max Pooling);
- 白色:卷积层+ReLU;
- 蓝色:全连接+ReLU;
- 神经网络参数传递从左向右;
- 参数传递过程中,通道数越来越深,尺寸越来越小;
- 从7x7x512下采样后,参数被拉平为1x1的长向量,进入全连接层;
下图可以更清晰看出每个层的参数尺寸:
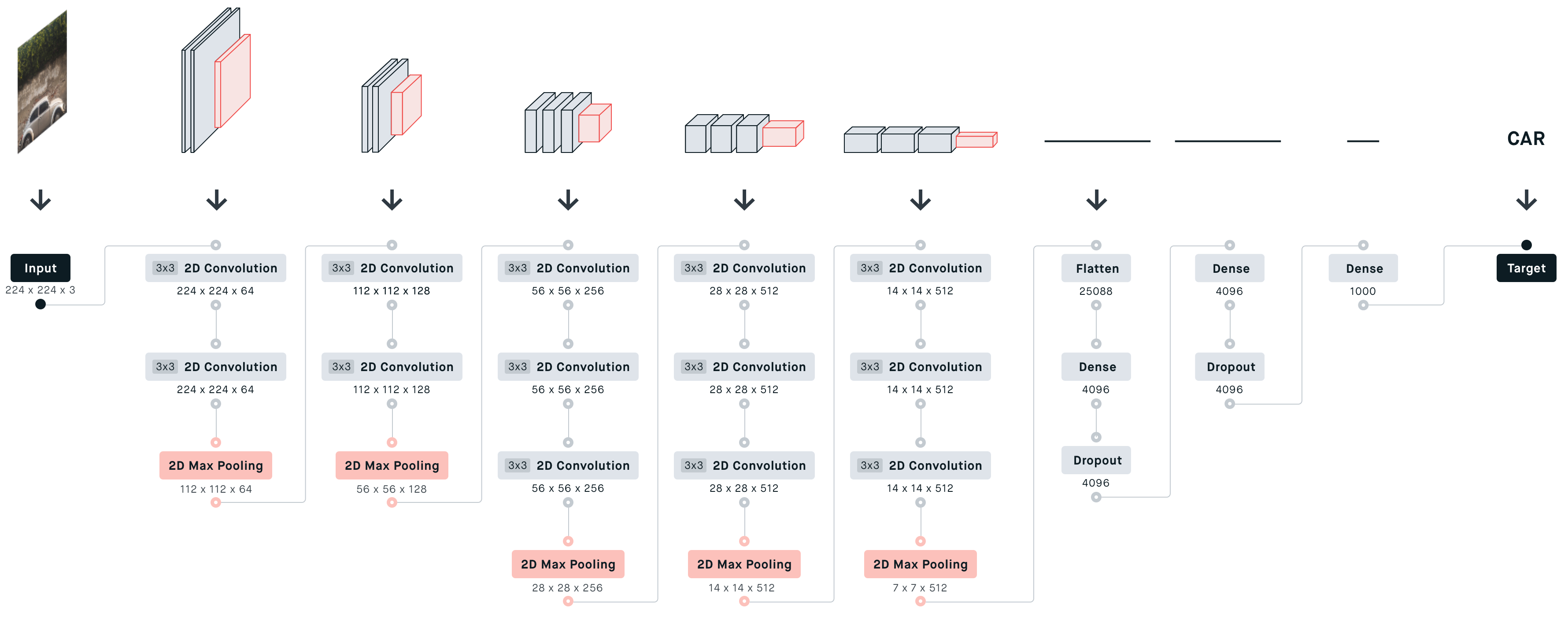
3. 参数传递示例
4. VGG 16各层参数数量
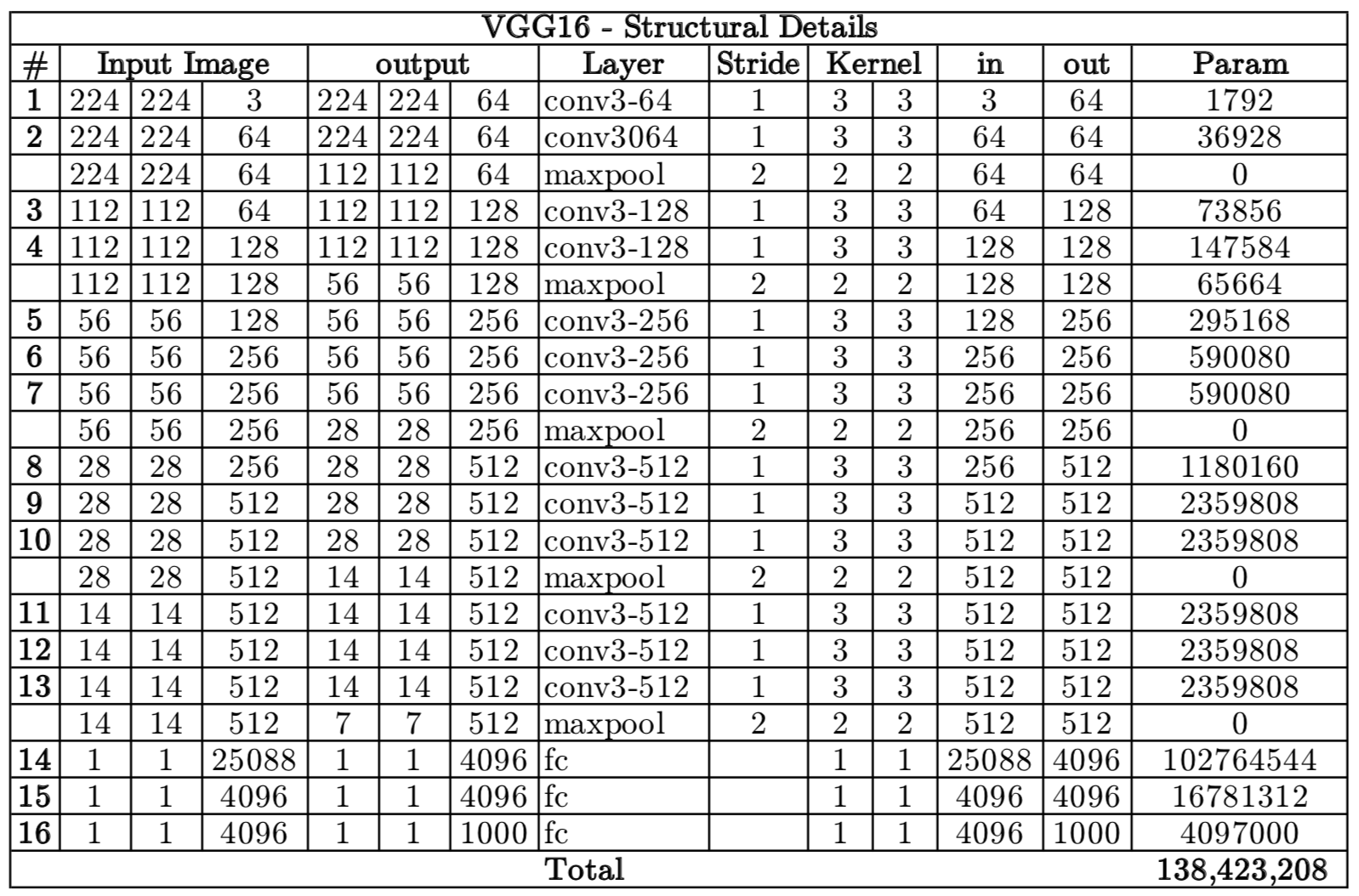
从图中可以看出,第一个全连接nfcr参数数量最多,达到了1亿多,这是因为前一个卷积层输出的向量在拉长成25088维向量,第一个全连接层4096要与25088相乘(每个神经元都要相连)。
三、代码分析
1. VGG16模型定义
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms# VGG16网络模型
class Vgg16_net(nn.Module):def __init__(self):super(Vgg16_net, self).__init__()# 第一层卷积层self.layer1 = nn.Sequential(# 输入3通道图像,输出64通道特征图,卷积核大小3x3,步长1,填充1nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1),# 对64通道特征图进行Batch Normalizationnn.BatchNorm2d(64),# 对64通道特征图进行ReLU激活函数nn.ReLU(inplace=True),# 输入64通道特征图,输出64通道特征图,卷积核大小3x3,步长1,填充1nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),# 对64通道特征图进行Batch Normalizationnn.BatchNorm2d(64),# 对64通道特征图进行ReLU激活函数nn.ReLU(inplace=True),# 进行2x2的最大池化操作,步长为2nn.MaxPool2d(kernel_size=2, stride=2))# 第二层卷积层self.layer2 = nn.Sequential(# 输入64通道特征图,输出128通道特征图,卷积核大小3x3,步长1,填充1nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),# 对128通道特征图进行Batch Normalizationnn.BatchNorm2d(128),# 对128通道特征图进行ReLU激活函数nn.ReLU(inplace=True),# 输入128通道特征图,输出128通道特征图,卷积核大小3x3,步长1,填充1nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),# 对128通道特征图进行Batch Normalizationnn.BatchNorm2d(128),nn.ReLU(inplace=True),# 进行2x2的最大池化操作,步长为2nn.MaxPool2d(2, 2))# 第三层卷积层self.layer3 = nn.Sequential(# 输入为128通道,输出为256通道,卷积核大小为33,步长为1,填充大小为1nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),# 批归一化nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2))self.layer4 = nn.Sequential(nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2))self.layer5 = nn.Sequential(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2))self.conv = nn.Sequential(self.layer1,self.layer2,self.layer3,self.layer4,self.layer5)self.fc = nn.Sequential(nn.Linear(512, 512),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(512, 256),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(256, 10))def forward(self, x):x = self.conv(x)# 对张量的拉平(flatten)操作,即将卷积层输出的张量转化为二维,全连接的输入尺寸为512x = x.view(-1, 512)x = self.fc(x)return x2. 训练
# 批大小
batch_size = 64
# 每n个batch打印一次损失
num_print = 100# 总迭代次数
epoch_num = 30
# 初始学习率
lr = 0.01
# 每n次epoch更新一次学习率
step_size = 10
# 更新学习率每次减半
gamma = 0.5def transforms_RandomHorizontalFlip():# 训练集数据增强:随机水平翻转、转换为张量、使用均值和标准差进行归一化transform_train = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])# 测试集数据转换为张量、使用均值和标准差进行归一化transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.226, 0.224, 0.225))])train_dataset = datasets.CIFAR10(root='../path/cifar10', train=True, transform=transform_train, download=True)test_dataset = datasets.CIFAR10(root='../path/cifar10', train=False, transform=transform, download=True)return train_dataset, test_dataset# 随机翻转,获取训练集和测试集数据
train_dataset, test_dataset = transforms_RandomHorizontalFlip()
# 创建DataLoader用于加载训练集和测试集数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 创建Vgg16_net模型,并将其移动到GPU或CPU
model = Vgg16_net().to(device)
# 定义损失函数为交叉熵
criterion = nn.CrossEntropyLoss()
# 定义优化器为随机梯度下降,学习率为lr,动量为0.8,权重衰减为0.001
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.8, weight_decay=0.001)
# 定义学习率调度器,每step_size次epoch将学习率减半
schedule = optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=gamma, last_epoch=-1)# 训练
loss_list = []# 每个epoch循环训练一遍
for epoch in range(epoch_num):# 当前迭代次数ww = 0# 累计损失值running_loss = 0.0# 遍历数据加载器,获取每个batchfor i, (inputs, labels) in enumerate(train_loader, 0):# 将数据和标签移动到GPU/CPU上inputs, labels = inputs.to(device), labels.to(device)# 梯度清零optimizer.zero_grad()# 输入数据进行前向传播,行到预测结果outputs = model(inputs)# 计算损失loss = criterion(outputs, labels).to(device)# 反向传播,计算每个参数的梯度loss.backward()# 更新参数optimizer.step()# 累计损失值running_loss += loss.item()# 将损失值放到loss_listloss_list.append(loss.item())# 打印当前epoch的平均损失值if (i + 1) % num_print == 0:print('[%d epoch,%d] loss:%.6f' % (epoch + 1, i + 1, running_loss / num_print))running_loss = 0.0lr_1 = optimizer.param_groups[0]['lr']# 打印学习率print("learn_rate:%.15f" % lr_1)schedule.step()
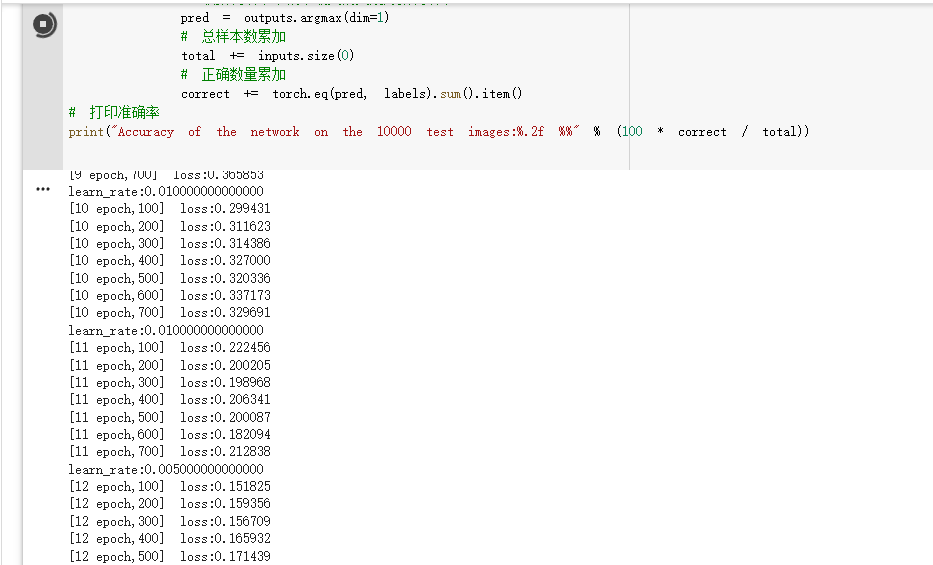
3. 测试
# 测试
model.eval()
# 记录分类正确的样本数和总样本数
correct = 0.0
total = 0
with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)# 取预测结果中概率最大的类别为预测结果pred = outputs.argmax(dim=1)# 总样本数累加total += inputs.size(0)# 正确数量累加correct += torch.eq(pred, labels).sum().item()
# 打印准确率
print("Accuracy of the network on the 10000 test images:%.2f %%" % (100 * correct / total))运行示例: