专注系列化、高质量的R语言教程
推文索引 | 联系小编 | 付费合集
Advanced R是R语言大神Hadley Wickham写的一本书,主要介绍R语言底层的运行原理,帮助用户从R User转变为R Programmer。该书最新版为第二版,网页版地址为:https://adv-r.hadley.nz/。
本书共25章。第1章为“Introduction”,不涉及具体知识。本篇推文是学堂君学习第2章“Names and values”的笔记,原文链接是https://adv-r.hadley.nz/names-values.html,可在文末“阅读原文”处直达。
注:这里的章节序号和标题均与原文对应,章节缺省表示没有笔记。
2.2 Binding basics
2.2.1 Non-syntactic names
2.3 Copy-on-modify
2.3.1 tracemem()
2.3.3 Lists
2.3.4 Data frames
2.3.5 Character vectors
2.4 Object size
2.4.1 Exercises
2.5 Modify-in-place
2.5.1 Objects with a single binding
2.5.2 Environments
2.6 Unbinding and the garbage collector
2.2 Binding basics
本部分介绍了值(对象)与名称的关系:绑定(binding)。
例如下面的代码:
x <- c(1,2,3)我们通常会理解成“创建一个名称为x的对象,包含的值为1、2、3”,但这种简化的理解不能使我们理解背后的运行原理,实际过程是:
创建一个对象
c(1,2,3);并把该对象绑定一个名称——
x。
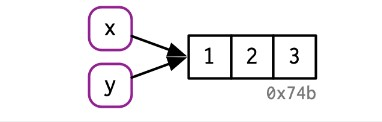
一个名称同时只能绑定一个对象,但一个对象可以同时绑定多个名称。名称可以看作是对象的“索引”(reference)。
再如下面代码:
y <- x这段代码并不是把x的值复制一份给y,而是将名称y绑定到已存在的对象(也就是x所绑定的对象)。二者的区别是:复制对象会增加内存占用,绑定已有对象不增加内存占用。
示意图如下:
lobstr::obj_addr()函数可以查看名称对应的对象地址,从而帮助我们判断不同名称是否对应同一个对象:
library(lobstr)
obj_addr(x)
## [1] "0x23a1fb67d98"obj_addr(y)
## [1] "0x23a1fb67d98"
学堂君注:读者运行出的地址字符串可能与这里不同,但是
x和y的结果总是相同的。
2.2.1 Non-syntactic names
R语言中的命名需要符合的规则:
构成要素是字母(取决于语言环境)、阿拉伯数字、小数点
.(ASCII编码)和下划线_的一种或多种;不能以下划线或数字开头;
若以小数点开头,后面不能紧接数字;
不能使用保留词(reserved words),如
TRUE、NULL、if、function等;详细清单见Reserved的帮助文档。
不符合以上规则的名称在使用时程序会报错:
_abc <- 1
## Error: unexpected symbol in "_abc"不过如果加上反引号则可以使用任意字符串作为名称:
`_abc` <- 1此外,一些基础包的函数,如read.csv(),在加载数据时会自动把非法名称转换为合法名称;详细转换规则见make.names()的帮助文档,主要有:
如有必要(如开头不合规),添加
X作为开头;无效字符转换为小数点
.;缺失值转换为
NA。
2.3 Copy-on-modify
R语言在修改名称对应的值时有两种模式:
“copy-on-modify”模式不会直接修改名称的对象,而是复制对象修改后再绑定到该名称;
“copy-on-modify”模型是直接修改名称的对象,详细介绍见下文2.5节。
如果对象绑定的名称在两个及以上,当修改其中一个名称的值时就会采用“copy-on-modify”模式,这样不会影响其他名称的值。
比如下面的代码:
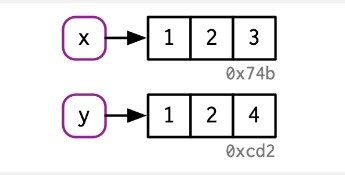
y[[3]] <- 4
x
#> [1] 1 2 3名称x和y原本绑定的是同一个对象。上面代码修改了y的值,从而改变了它所绑定的对象,而x仍然与原对象相绑定。新绑定的对象可以视作原对象的抄本(copy):
obj_addr(x)
## [1] "0x23a1fb67d98"obj_addr(y)
## [1] "0x23a1fc9e5b8"
x对应的地址不变,而y对应的地址变化。
示意图如下:
2.3.1 tracemem()
base::tracemem()函数输出程序运行时对象及其抄本被复制的过程:被复制的对象、复制后的新地址。
例如:
x <- c(1,2,3)
cat(tracemem(x), "\n")
## <0000023A1FC02568>y <- x
y[[3]] <- 4
## tracemem[0x0000023a1fc02568 -> 0x0000023a1fc127c8]:
学堂君注:前面我们已经创建了
x所对应的对象,这里第一行代码相当于重新创建一次,内存地址会变化。
如果继续修改y的值,此时y的对象只绑定一个名称(也就是y自己),不符合“copy-on-modify”模式使用条件,而是使用“modify-in-place”模式,该模式需要创建抄本,而是直接修改对象:
y[[3]] <- 5
上面代码如果在RStudio中运行,会显示地址变化信息,但在RMarkdown中运行则不会显示;
实际过程并没有发生地址变化,即没有复制对象;此外,函数运行性能在RStudio和RMarkdown中也没有区别。
untracemem()函数可以关闭地址追踪:
untracemem(x)下面为学堂君自行探索的结果,原文不含这部分。
语句tracemem(x)追踪的是该语句运行时x所对应的对象及其抄本在后续程序运行时的复制过程,而不是名称x对应对象的地址变化过程。下面通过三个例子加以解释。
例1:
x <- c(1,2,3) # a
cat(tracemem(x), "\n")
## <0000023A1F9D7028>x <- c(2,3,4) # b
untracemem(x)很显然,在语句tracemem(x)前后x对应的对象发生了变化,从而地址也变化了,但结果并没有输出地址变化信息。原因如下:
假设在变化前后对应的对象分别记为a和b,当tracemem(x)运行时,x绑定的是a,那么tracemem()就会追踪对象a以及之后抄本的地址变化信息。但对象b并不是a的抄本,因此不会有地址变化信息输出出来。简言之,该函数追踪的是对象,而不是名称。
例2:
x <- c(1,2,3) # a
cat(tracemem(x), "\n")
## <0000023A1FC012C8>y <- x # a
y[[3]] <- 4 # a1
## tracemem[0x0000023a1fc012c8 -> 0x0000023a1f5cc0a8]: z <- y # a1
y[[3]] <- 5 # a2
## tracemem[0x0000023a1f5cc0a8 -> 0x0000023a1e6d8808]:
untracemem(x)记y第一次被修改后对应的对象为a1,它是a的抄本。前面介绍了,如果继续修改y的值,此时a1只绑定一个名称,因此a1不会被复制。这里,我们使用z <- y使得a1与两个名称绑定(y、z),然后再修改y的值就会仍然使用“copy-on-modify”模式,得到a1的抄本a2,此时有地址变化信息输出出来。
例3:
x <- c(1,2,3) # a
cat(tracemem(x), "\n")
## <0000023A1FAA2A18>y <- x # a
y[[3]] <- 4 # a1
## tracemem[0x0000023a1faa2a18 -> 0x0000023a1fac00b8]:z <- x # a
x[[3]] <- 5 # a2
## tracemem[0x0000023a1faa2a18 -> 0x0000023a1fb92bb8]:
untracemem(x)在得到a1后,使用z <- x使得a再次与两个名称绑定(x、z),然后修改x,得到a的另一个抄本a2,此时也有地址变化信息输出出来。
2.3.3 Lists
下面一个列表与前面的向量很相似:
l1 <- list(1,2,3)但它的结构更加复杂:它不仅储存每个元素的值,还储存每个值的索引。示意图如下:
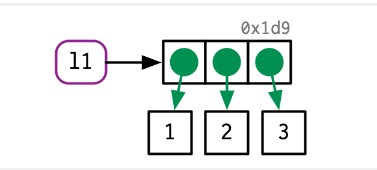
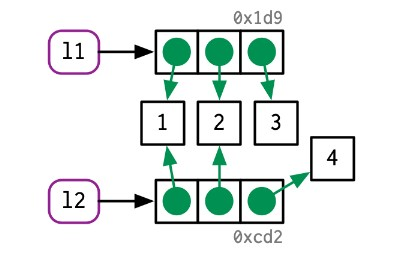
这使得如果需要使用“copy-on-modify”模式修改列表的值时,会使用浅复制(shallow copy):列表绑定的对象会变化,但值的索引却不会变化。
l2 <- l1
l2[[3]] <- 4示意图如下:
lobstr::ref()函数可以以树的形式输出列表及其值所绑定对象的地址:
ref(l1)
## █ [1:0x23a1ebd75f8] <list>
## ├─[2:0x23a1fb79f90] <dbl>
## ├─[3:0x23a1fb7a1c0] <dbl>
## └─[4:0x23a1fb7a3f0] <dbl>ref(l2)
## █ [1:0x23a1fb72068] <list>
## ├─[2:0x23a1fb79f90] <dbl>
## ├─[3:0x23a1fb7a1c0] <dbl>
## └─[4:0x23a1e49b900] <dbl>
l1和l2对应地址不同,但它们相同元素(即前两个元素)对应的地址是相同的。
2.3.4 Data frames
数据框可看作由向量构成的列表:每列表示一个向量。如果修改数据框的列,相当于修改列表的一个元素,其他列的索引不会被修改;如果修改的是行,所有列的索引都会被修改。
分别修改列和行,查看数据框及其各列的地址变化:
df <- data.frame(x = 1:3,y = 4:6
)
ref(df)
## █ [1:0x23a2030b448] <df[,2]>
## ├─x = [2:0x23a1e461400] <int>
## └─y = [3:0x23a1e4614e0] <int>df$x <- 2*df$x
ref(df)
## █ [1:0x23a22351d68] <df[,2]>
## ├─x = [2:0x23a226f0dd8] <dbl>
## └─y = [3:0x23a1e4614e0] <int>df[1,] <- 2*df[1,]
ref(df)
## █ [1:0x23a22562ec8] <df[,2]>
## ├─x = [2:0x23a22b89668] <dbl>
## └─y = [3:0x23a22b89618] <dbl>2.3.5 Character vectors
字符串向量的每个元素也都有自己的索引,同一字符串不管在哪个向量里地址都是相同的。
示意图如下:
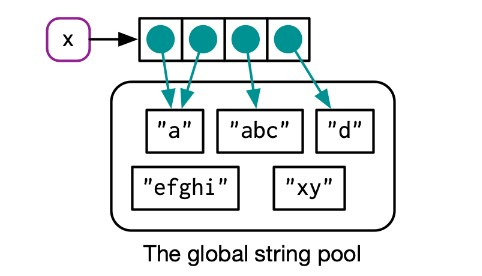
str1 <- c("a", "abc", "a")
ref(str1, character = T)
## █ [1:0x23a233afe58] <chr>
## ├─[2:0x23a1c638f48] <string: "a">
## ├─[3:0x23a20220258] <string: "abc">
## └─[2:0x23a1c638f48]str2 <- c("a", "b")
ref(str2, character = T)
## █ [1:0x23a22a7a788] <chr>
## ├─[2:0x23a1c638f48] <string: "a">
## └─[3:0x23a1ca64e20] <string: "b">
str1中的两个a的地址是相同的;
str1和str2中的a的地址也是相同的。
2.4 Object size
lobstr::obj_size()函数可以查看对象占用的内存大小:
obj_size(x)
## 80 B列表
同一对象的索引出现在列表的多个元素位置上时,不会重复占用内存:
x <- runif(1e6)
obj_size(x)
## 8.00 MBy <- list(x, x, x)
obj_size(y)
## 8.00 MB上面x与y的内存之差等于三个空元素列表的大小:
obj_size(y) - obj_size(x)
## 80 Bobj_size(list(NULL, NULL, NULL))
## 80 B两个列表的相同元素也不会重复占用总内存:
obj_size(x, y)
## 8.00 MB字符串向量
字符串向量的各元素是分别绑定到对象的,重复字符串所占用的内存不会线性增加:
banana <- "bananas bananas bananas"
obj_size(banana)
## 136 Bobj_size(rep(banana, 100))
## 928 BALTREP
“alternative representation”的缩写,R3.5.0版本开始增加的功能。
对于形如1:3、1:30的向量表示方法,R不会储存它的所有元素,而是仅储存首、尾数字,因此无论向量的实际长度是多少,所占内存都是相同的:
obj_size(1:3)
## 680 B
obj_size(1:30)
## 680 B
obj_size(1:30000)
## 680 B
obj_size(1:3000000000000)
## 680 B对于较短的向量,不缩写占用内存反而会更小:
obj_size(c(1,2,3))
## 80 B2.4.1 Exercises
在下面的例子中,为何object.size(x)和obj_size(y)的结果区别这么大?请参考object.size()函数的帮助文档。
y <- rep(list(runif(1e4)), 100)object.size(y)
#> 8005648 bytes
obj_size(y)
#> 80,896 B
object.size()函数的帮助文档相关内容如下:本函数对原子向量使用会比较准确,但没有考虑列表的相同元素;考虑了不同字符串向量的相同元素,但没有考虑同一字符串的相同元素。
2.5 Modify-in-place
如下两种情况,修改对象会使用“modify-in-place”模式:
对象只绑定了一个名称;
对象是环境对象。
2.5.1 Objects with a single binding
如果对象只绑定了一个名称,在修改时会直接修改对象,不会产生抄本。
v <- c(1, 2, 3)
v[[3]] <- 4但是R在统计对象绑定的名称数目时,只区分0、1和许多三种情况。如果对象原本绑定了2个名称(标记为“许多”),在解除其中一个绑定后,绑定数目不会归为1:因为“许多”减去1仍然是“许多”。这可能导致在不必要的情况下复制对象。
R语言的for循环以缓慢著称,主要原因就是每次迭代都会复制对象。例如下面的代码,目的是每轮迭代让一列数据减去本列的中位数:
x <- data.frame(matrix(runif(5 * 1e4), ncol = 5))
medians <- vapply(x, median, numeric(1))for (i in seq_along(medians)) {x[[i]] <- x[[i]] - medians[[i]]
}使用tracemem()函数记录对象抄本的地址变化情况:
cat(tracemem(x), "\n")
## <0000023A23A1FA68>for (i in seq_along(medians)) {x[[i]] <- x[[i]] - medians[[i]]
}
## tracemem[0x0000023a23a1fa68 -> 0x0000023a23d27a38]:
## tracemem[0x0000023a23d27a38 -> 0x0000023a23d279c8]: [[<-.data.frame [[<-
## tracemem[0x0000023a23d279c8 -> 0x0000023a23d27958]:
## tracemem[0x0000023a23d27958 -> 0x0000023a23d278e8]: [[<-.data.frame [[<-
## tracemem[0x0000023a23d278e8 -> 0x0000023a23d27878]:
## tracemem[0x0000023a23d27878 -> 0x0000023a23d27798]: [[<-.data.frame [[<-
## tracemem[0x0000023a23d27798 -> 0x0000023a23d276b8]:
## tracemem[0x0000023a23d276b8 -> 0x0000023a23d275d8]: [[<-.data.frame [[<-
## tracemem[0x0000023a23d275d8 -> 0x0000023a23d274f8]:
## tracemem[0x0000023a23d274f8 -> 0x0000023a23d27488]: [[<-.data.frame [[<- untracemem(x)
原文这里说,每次迭代要进行三次复制,但学堂君运行的结果显示只进行两次复制。
如果想在循环中减少复制次数,可以将数据框转换为列表:
y <- as.list(x)
cat(tracemem(x), "\n")
## <0000023A23D27488>for (i in seq_along(medians)) {y[[i]] <- y[[i]] - medians[[i]]
}untracemem(y)
原文这里说一共只进行一次复制,但学堂君的结果显示没有进行复制。
2.5.2 Environments
关于环境对象,学堂君已经专门写了两篇推文:
环境Environment(上)
环境Environment(下)——函数环境
环境对象不同于其他对象,无论何种情况下修改它都会使用“modify-in-place”模式。如果环境对象与多个名称绑定,修改其中一个名称会导致其他名称对应的对象同步变化,这个属性称作“引用语义”(reference semantics)。
2.6 Unbinding and the garbage collector
使用rm()函数可以解除对象绑定的名称;当对象所有的绑定名称都被解除时,就会被放入垃圾回收器(garbage collector,GC)中。
垃圾回收器通过删除没有绑定任何名称的对象来释放内存。使用gc()函数可以强制运行垃圾回收器,但通常不需要这么做,因为它会在内存紧张时自动运行。