本章主要内容
- elasticsearch 中别名字段的详解和范例
- elasticsearch 中二进制类型的详解和范例
- elasticsearch 中的嵌套类型的详解和范例
- elasticsearch 中的范围类型的详解和范例
- elasticsearch 中的排名类型的详解和范例
- elasticsearch 中的ip类型的详解和范例
- elasticsearch 中的search-as-you-type 类型 的详解和范例
- elasticsearch 中的token_count 类型 的详解和范例
概要
本篇文章主要讲解elasticsearch在业务中经常用到的字段类型,通过大量的范例来学习和理解不同字段类型的应用场景。范例elasticsearch使用的版本为7.17.5。
简述
在Elasticsearch的映射关系中,每个字段都对应一个数据类型或者字段类型,这些类型规范了字段存储的值和用途。
内容
elasticsearch 中别名字段的详解
- alias(别名)类型可以为索引中的字段定义一个替代名称。
elasticsearch 中别名字段的范例
#创建名为userinfo的索引库并为其创建映射关系
PUT userinfo
{"mappings": {"properties": {"age": {"type": "long"},"aliasage": {"type": "alias","path": "age"},"transit_mode": {"type": "keyword"}}}
}
- 这是一个创建名为"userinfo"的索引的请求。该索引定义了三个字段:
- "age"字段,它是一个长整型字段。它存储用户的年龄信息。
- "aliasage"字段,它是一个别名类型的字段。它通过指定"age"字段的路径作为别名的路径,将"aliasage"字段与"age"字段关联在一起。这样,对"aliasage"字段的搜索、聚合和排序操作将与对"age"字段进行的操作一样。
- "transit_mode"字段,它是一个关键字类型的字段。它存储用户的交通方式信息。
#以上语句创建了userinfo索引库,而且为age字段创建了名为aliasage的别名。
#在索引库userinfo中插入一条文档数据
PUT userinfo/_doc/1
{"age": 39,"transit_mode": "transit_mode"
}#通过年龄查询大于30的用户信息
GET userinfo/_doc/_search
{"query": {"range": {"age": {"gte": 30}}}
}#通过别名查询年龄大于30的用户信息
GET userinfo/_doc/_search
{"query": {"range": {"aliasage": {"gte": 30}}}
}#通过年龄、别名查询返回的结果信息如下
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "userinfo","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"age" : 39,"transit_mode" : "transit_mode"}}]}
}
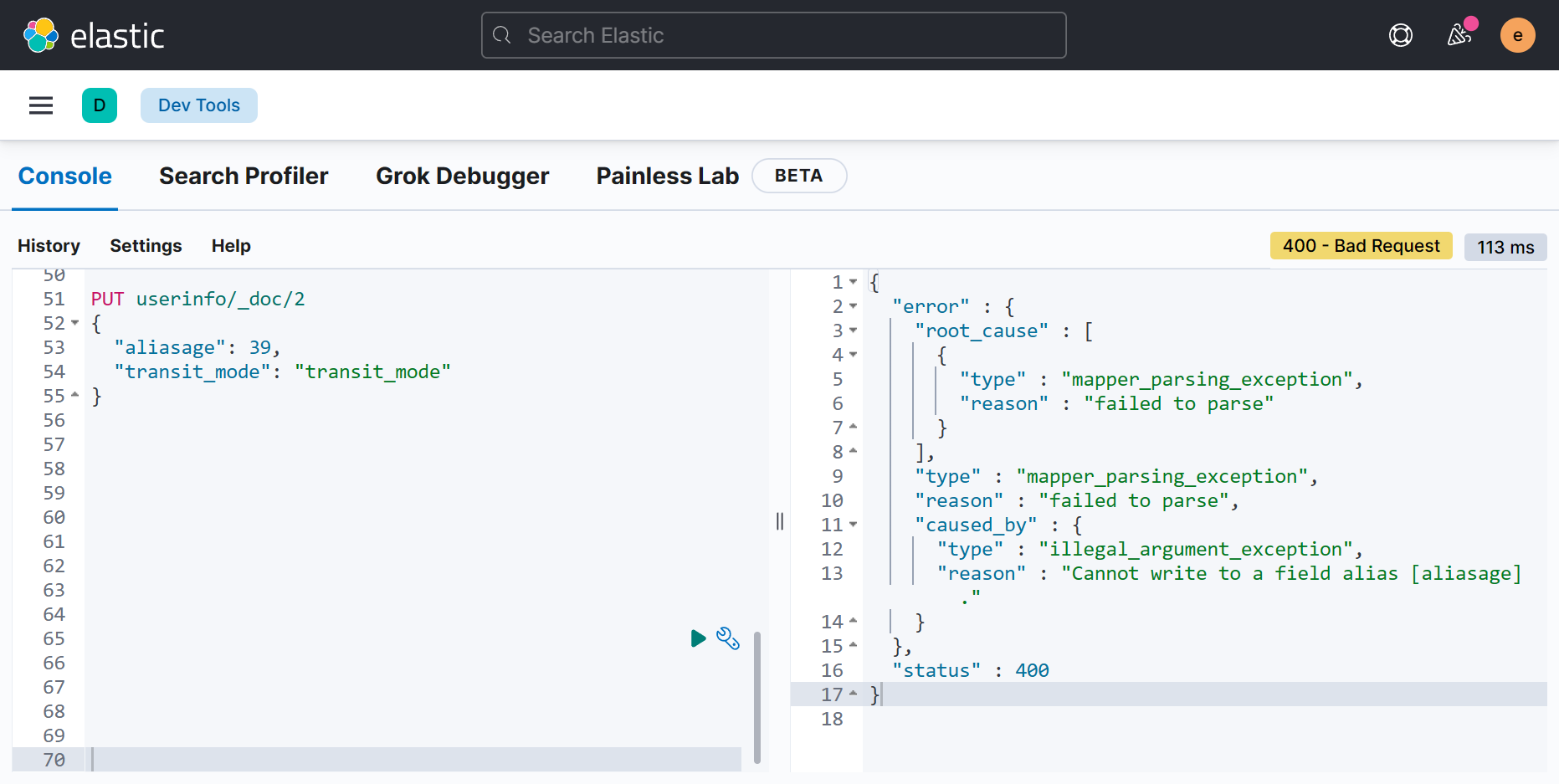
- 需要注意的是,别名字段只能作为查询的目标,而不能作为源字段。也就是说,你不能将文档数据写入"aliasage"字段,只能写入"age"字段。另外,别名的路径也必须指向实际存在的字段。如果路径指向的字段不存在,则会发生错误。
elasticsearch 中二进制类型的详解
- 在 Elasticsearch 中,二进制字段的数据必须是 Base64 编码的字符串。这是因为 Elasticsearch 使用 JSON 作为其数据交换格式,而 JSON 不支持原始二进制数据。通过将二进制数据转换为 Base64 编码的字符串,可以确保数据在传输过程中不会出现问题。
- 在 Elasticsearch 中,二进制类型(binary)用于存储和检索原始的二进制数据。通常情况下,Elasticsearch 主要用于处理结构化或半结构化的文本数据,但在某些场景下,您可能需要处理二进制数据,例如图片、音频、视频或其他非文本数据。在这种情况下,您可以使用二进制类型将这些数据存储在 Elasticsearch 中。
elasticsearch 中二进制类型的范例
#创建索引映射并指定blob字段的类型为二进制类型
PUT myindex-2_02
{"mappings": {"properties": {"name": {"type": "text"},"blob": {"type": "binary"}}}
}#在索引库中插入数据,blob的内容是Base64编码的字符串
PUT myindex-2_02/_doc/1
{"name":"Some binary blob","blob":"c2FkZw=="
}
- 需要注意的是,二进制类型字段不支持全文搜索功能,因为这些字段存储的数据通常不是文本数据。此外,在处理大量的二进制数据时,Elasticsearch 的性能可能会受到影响。因此,在使用二进制类型时,请确保您了解其限制,并确保 Elasticsearch 适用于您的用例。
- 最后,请记住,Elasticsearch 不是专门针对存储和检索大量二进制数据而设计的。根据您的需求,您可能需要评估其他数据存储解决方案(如分布式文件系统或对象存储),这些解决方案可能更适合处理大量二进制数据。在这种情况下,您可以将 Elasticsearch 用于存储和搜索元数据,而将实际的二进制数据存储在其他系统中。
elasticsearch 中的嵌套类型的详解
- 嵌套类型用于在 Elasticsearch 文档中表示对象数组,它允许您对数组中的对象进行独立查询和过滤。这是处理具有父子关系或层次结构的数据非常有用的方法。
elasticsearch 中的嵌套类型的范例
- 定义嵌套类型:在 Elasticsearch 的映射中,通过将字段类型设置为 "nested",可以定义嵌套类型
#创建索引映射并指定user字段为一个嵌套类型
PUT myindex-2_07
{"mappings": {"properties": {"user":{"type": "nested"}}}
}
- 索引嵌套文档:使用嵌套类型时,可以将多个对象作为数组索引到 Elasticsearch 中。
#在索引库中插入文档数据,user字段中嵌套了键值对
PUT myindex-2_07/_doc/1
{"group": "fans","user": [{"first": "John","last": "Smith"},{"first": "Alice","last": "White"}]
}
- 查询嵌套文档:要查询嵌套文档,需要使用 "nested" 查询。
#查询user索引库字段中user.first的值是Alice以及User.last的值是Smith的结果
GET myindex-2_07/_search
{"query": {"nested": {"path": "user","query": {"bool": {"must": [{"match": {"user.first": "Alice"}},{"match": {"user.last": "Smith"}}]}}}}
}
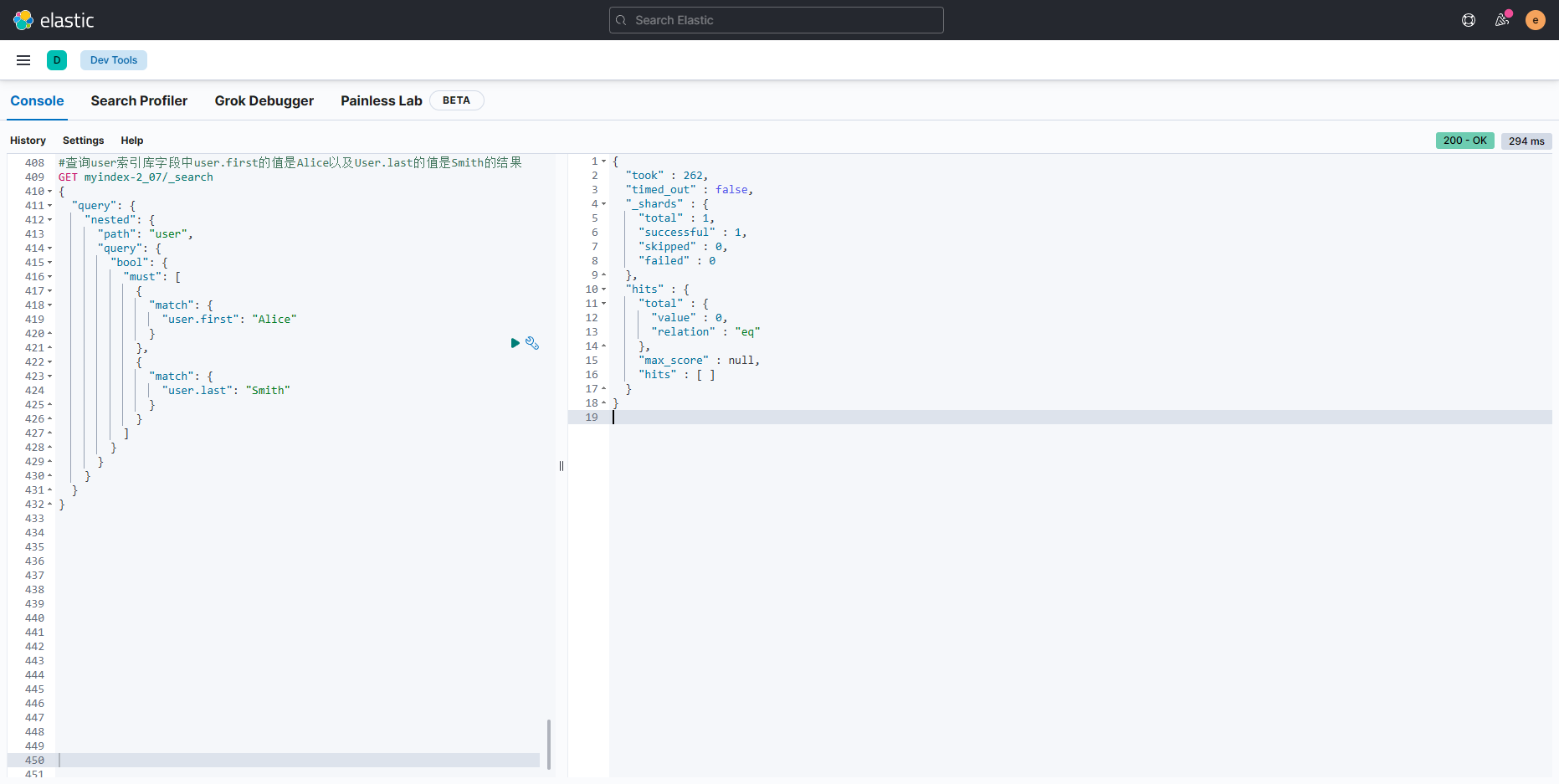
- 以上查询语句中需要注意的是,利用嵌套字段进行筛选查询时,必须两个字段值都要符合条件,如果其中一个字段值不满足查询条件,则从索引库中查询不到任何数据,执行结果如图所示:
- 嵌套类型在处理具有复杂关系的文档时非常有用。使用嵌套类型,可以在 Elasticsearch 中更有效地查询和过滤对象数组,并获取所需的详细信息。
elasticsearch 中的范围类型的详解
- 范围类型 (range type) 是 Elasticsearch 中一种特殊的字段类型,它可以表示一个连续的范围或间隔.
- range(范围)类型表示介于上限和下限之间的连续值范围,可以使用运算符gt(大于)、gte(大于等于)、lt(小于)、lte(小于等于)定义存储文档的数据范围。每一种范围类型的说明表如下:
| 范围类型 | 说明 |
| integer_range | 表示由符号的32位整数 |
| float_range | 表示单精度浮点数 |
| long_range | 表示有符号的64位整数 |
| double_range | 表示双精度浮点数 |
| date_range | 表示日期范围,可以通过format映射参数支持各种日期格式。无论使用哪种格式,日期值都会被解析为一个无符号的64位整数,该整数为纪元以来的毫秒数。 |
| ip_range | 表示IPv4或IPv6地址的一系列IP值 |
- 范围类型的主要应用场景是对某个范围内的值进行查询和过滤。例如,查找生产日期在特定日期范围内的商品,或者查找价格在特定范围内的房屋等。
elasticsearch 中的范围类型的范例
#创建索引映射,并指定expected_attendees字段类型为整数范围类型,time_frame字段类型为日期范围类型
PUT myindex-2_08
{"mappings": {"properties": {"expected_attendees": {"type": "integer_range"},"time_frame":{"type": "date_range","format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"}}}
}#插入文档数据
PUT myindex-2_08/_doc/1?refresh
{"expected_attendees":{"gte":10,"lt":20},"time_frame":{"gte":"2021-10-31 12:00:00","lte":"2021-11-01"}
}
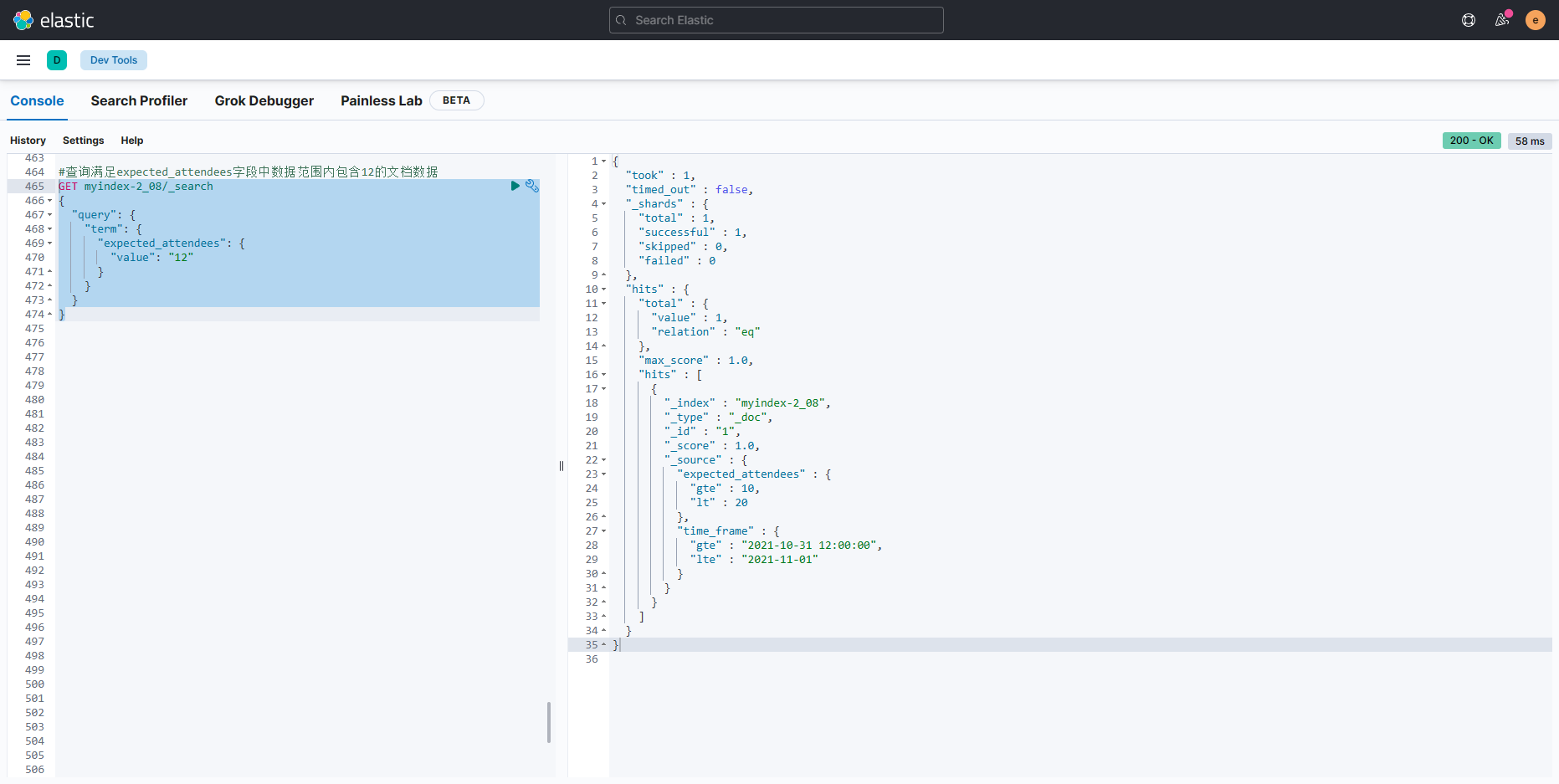
- 查询满足expected_attendees字段中数据范围内包含12的文档数据
GET myindex-2_08/_search
{"query": {"term": {"expected_attendees": {"value": "12"}}}
}
- 根据日期范围查询符合条件的文档数据
#根据日期范围查询符合条件的文档数据
GET myindex-2_08/_search
{"query": {"range": {"time_frame": {"gte": "2021-10-31","lte": "2021-11-01","relation": "within"}}}
}
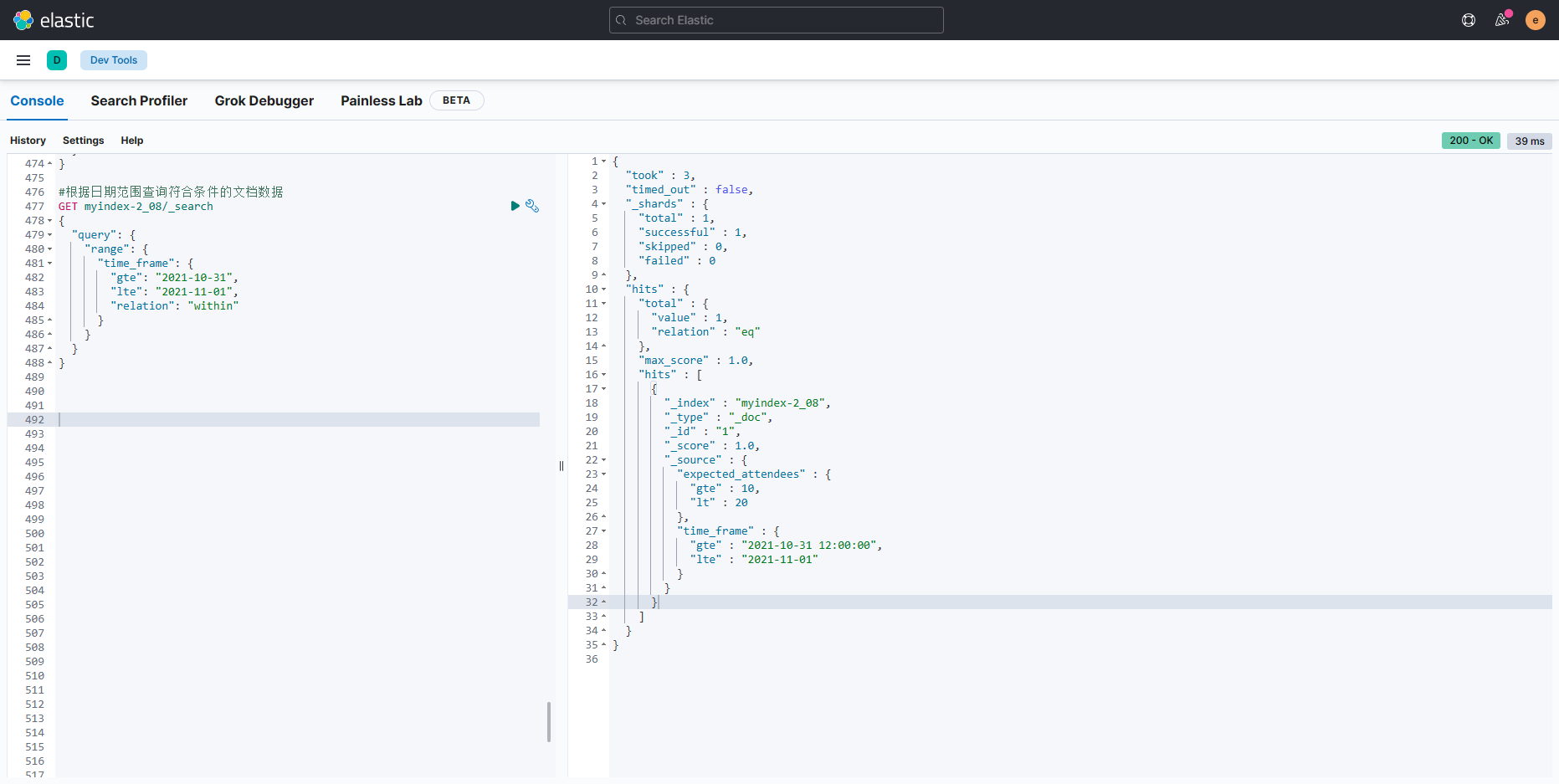
- 由以上结果可知,只要范围类型字段的内容包含在筛选的范围内,就会返回当前文档的内容。
- 总之,Elasticsearch 中的范围类型提供了对连续范围或间隔的查询和过滤功能,支持整数、长整数、浮点数、双精度浮点数、日期和 IP 地址等多种数据类型。这使得在特定范围内对数据进行筛选和分析变得更加简单和高效。
elasticsearch 中的排名类型的详解
- rank_feature(排名)类型的字段可以存储数字,并且对搜索文档的分数有所影响(搜索文档的分数就是用户搜索的内容和搜索返回文档的匹配度,分数越高,就表示匹配度越高)
- 这种字段类型在特定场景下非常有用,例如,当您需要根据某些特征对文档进行排序时。例如,电商网站中的产品排名,根据销量、评价等特征对产品进行排序。
- rank_feature 字段的主要优势在于它可以在查询时高效地为文档评分。Elasticsearch 会在索引时预先计算相关的评分数据,从而加快查询性能。
elasticsearch 中的排名类型的范例
#创建索引映射并将"pagerank"和"topics"这两个字段类型分别指定为"rank_feature"类型和"rank_features"类型
PUT myindex-2_10
{"mappings": {"properties": {"pagerank":{"type": "rank_feature"},"url_length":{"type": "rank_feature","positive_score_impact":false},"topics":{"type": "rank_features"}}}
}#在索引库中插入数据
PUT myindex-2_10/_doc/1
{"url": "http://en.wikipedia.org/wiki/2016_Summer_Olympics","content": "Rio 2016","pagerank": 50.3,"url_length": 42,"topics": {"sports": 50,"brazil": 30}
}#在索引库中插入数据
PUT myindex-2_10/_doc/2
{"url": "http://en.wikipedia.org/wiki/2016_Brazilian_Grand_Prix","content": "Formula One motor race held on 13 November 2016 at the Autodromo Jose Carlos Pace in Sao Paulo,Brazil","pagerank": 50.3,"url_length": 47,"topics": {"sports": 50,"brazil": 20,"formula one":65}
}#在索引库中插入数据
PUT myindex-2_10/_doc/3
{"url": "http://en.wikipedia.org/wiki/Deadpool_(film)","content": "Deadpool is a 2016 American superhero film","pagerank": 50.3,"url_length": 37,"topics": {"movies":60,"super hero":65}
}#查询索引库的content字段值中包含"2016"的文档,并根据评分(score字段的值)排序输出
GET myindex-2_10/_search
{"query": {"bool": {"must": [{"match": {"content": "2016"}}],"should": [{"rank_feature": {"field": "pagerank"}},{"rank_feature": {"field": "url_length","boost": 0.1}},{"rank_feature": {"field": "topics.sports","boost": 0.4}}]}}
}
- 返回的查询结果如图:
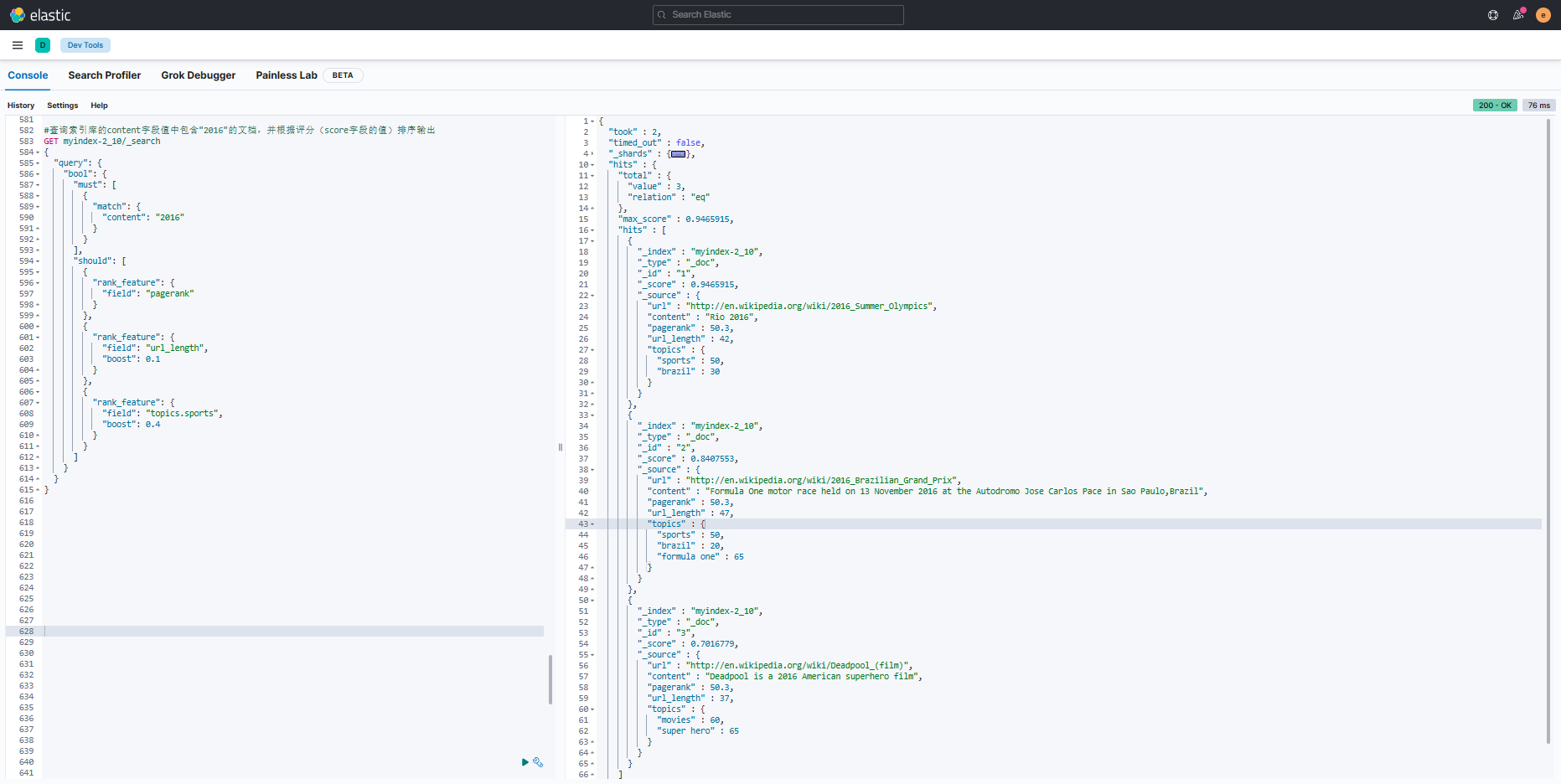
- 由以上语句可知,rank_feature字段类型和rank_feaures字段类型只能搭配rank_feature参数进行查询。
elasticsearch 中的ip类型的详解
- IP 类型用于存储和搜索 IPv4 和 IPv6 地址。它允许您高效地索引和查询 IP 地址数据,因此在处理网络日志、安全分析等场景时非常有用。
- IP 类型的字段定义如下:
{"mappings": {"properties": {"ip_field": {"type": "ip"}}}
}
elasticsearch 中的ip类型的范例
- 存储和查询 IPv4 和 IPv6 地址。Elasticsearch 可以处理 IPv4 和 IPv6 地址。
PUT my-index/_doc/1
{"ip_field": "192.168.1.1"
}PUT my-index/_doc/2
{"ip_field": "2001:0db8:85a3:0000:0000:8a2e:0370:7334"
}
- 范围查询。您可以使用范围查询来查找特定 IP 地址范围内的文档。
GET my-index/_search
{"query": {"range": {"ip_field": {"gte": "192.168.1.1","lte": "192.168.1.10"}}}
}
- CIDR 符号。您还可以使用 CIDR 符号来查询特定子网内的 IP 地址。
GET my-index/_search
{"query": {"term": {"ip_field": "192.168.1.0/24"}}
}
- 排序和聚合。Elasticsearch 允许您根据 IP 地址对结果进行排序和聚合。
GET my-index/_search
{"sort": [{"ip_field": {"order": "asc"}}]
}
- 注意事项:
- IP 类型只能用于存储 IP 地址。不要将其用于其他类型的数据。
- 如果您的数据包含可能包含非 IP 地址的字符串,请在索引之前进行清理或使用关键字类型进行索引。
- 总之,Elasticsearch 中的 IP 类型为处理 IP 地址数据提供了丰富的功能,使得在网络分析、安全监控等场景中非常实用。
elasticsearch 中的search-as-you-type 类型 的详解
- search_as_you_type字段类型和text字段类型很相似,Elasticsearch对其进行了优化,为用户提供了开箱即用的功能。search_as_you_type字段类型的字段可以创建一系列的子字段
- Search-as-you-type 是 Elasticsearch 中的一种特殊字段类型,用于实现实时的、基于部分输入的搜索建议功能。这种类型通过对输入的数据进行分析和索引,使得用户在输入查询的过程中就能看到相关的搜索建议。
- search-as-you-type 字段类型的主要特点如下:
- 分词器(Tokenizer)和分析器(Analyzer):为了实现部分匹配,search-as-you-type 字段类型使用了一种特殊的分词器和分析器。它们能够将输入的文本划分为多个递增的令牌(token),从而实现部分匹配。这些令牌会被存储在倒排索引中,以便在搜索时匹配。
- 边缘 N-gram:为了提高搜索建议的相关性,search-as-you-type 字段类型使用了边缘 N-gram 技术。这种技术可以将输入的文本切分成一个个递增的子字符串,从而在搜索时能够实现部分匹配。这对于处理拼写错误、缩写或其他输入不完整的情况非常有用。
- 实时性:search-as-you-type 字段类型提供了实时的搜索建议功能,这意味着当用户输入查询时,系统会立即返回与部分输入匹配的建议。这种实时性可以帮助用户更快地找到他们想要的信息,提高搜索体验。
elasticsearch 中的search-as-you-type 类型 的范例
- 为了使用 search-as-you-type 字段类型,你需要在映射(mapping)中定义该字段。例如:
{"mappings": {"properties": {"title": {"type": "search_as_you_type"}}}
}
- 当执行下面的映射模板时,将会为my_field字段创建下表中的所有字段作为其子字段。
| 创建的字段 | 说明 |
| my_field | 按照映射中的配置进行分析,如果未配置分词器,则使用索引的默认分词器 |
| my_field._2gram | 用大小为2的shingle token filter 分词器对 ny_field进行分词 |
| my_field._3gram | 用大小为3的shingle token filter 分词器对 ny_field进行分词 |
| my_field._index_prefix | 用edge ngram token filter 打包 my_field._3gram的分词器 |
- 在这个例子中,我们为文档的 "title" 字段定义了 search-as-you-type 类型。之后,在索引文档时,Elasticsearch 会自动使用相应的分析器和分词器处理该字段。
- 当你要查询 search-as-you-type 字段时,可以使用 "multi_match" 查询类型,并指定 "type" 为 "bool_prefix"。例如:
{"query": {"multi_match": {"query": "search text","type": "bool_prefix","fields": ["title","title._2gram","title._3gram"]}}
}
- 这个查询会在 "title" 字段及其 N-gram 子字段上执行部分匹配查询,返回与输入文本匹配的文档。这样,用户就可以在输入过程中获得相关的搜索建议。
- 总之,search-as-you-type 字段类型是 Elasticsearch 中一种实现实时搜索建议功能的有效方式。通过使用特殊的分词器
elasticsearch 中的token_count 类型 的详解
- token_count(令牌计数)类型的字段实际上是一个integer类型字段,它可以对内容进行分词分析,存储内容被分词的数量
- 用途:token_count 类型用于计算给定文本中的词元数量。它通常与 text 类型字段一起使用,因为这些字段包含实际的文本数据。
- 分析器:您可以为 token_count 类型指定一个分析器。分析器负责将文本拆分为词元。在默认情况下,Elasticsearch 使用标准分析器。如果需要,可以自定义分析器来满足特定的需求。
- 需要注意的是,token_count 类型不适用于全文搜索,而主要用于过滤、排序和聚合操作。此外,词元数量不会随着文本的变化而更新,因此,如果文本内容发生更改,需要重新索引文档以更新词元计数。
elasticsearch 中的token_count 类型 的范例
#创建索引映射,给name字段添加子对象,其名称是length,类型是token_count,使用standard分词器进行分词
PUT myindex-tokencount
{"mappings": {"properties": {"name":{"type": "text", "fields": {"length":{"type":"token_count","analyzer":"standard"}}}}}
}#添加文档数据
PUT myindex-tokencount/_doc/1
{"name":"John Smith"
}#添加文档数据
PUT myindex-tokencount/_doc/2?pretty
{"name":"Rachel Alice Williams"
}PUT myindex-tokencount/_doc/3
{"name":"长大"
}#查询索引库中name字段被分词后,分词的数量等于2的文档
GET myindex-tokencount/_search
{"query": {"term": {"name.length": {"value": "2"}}}
}
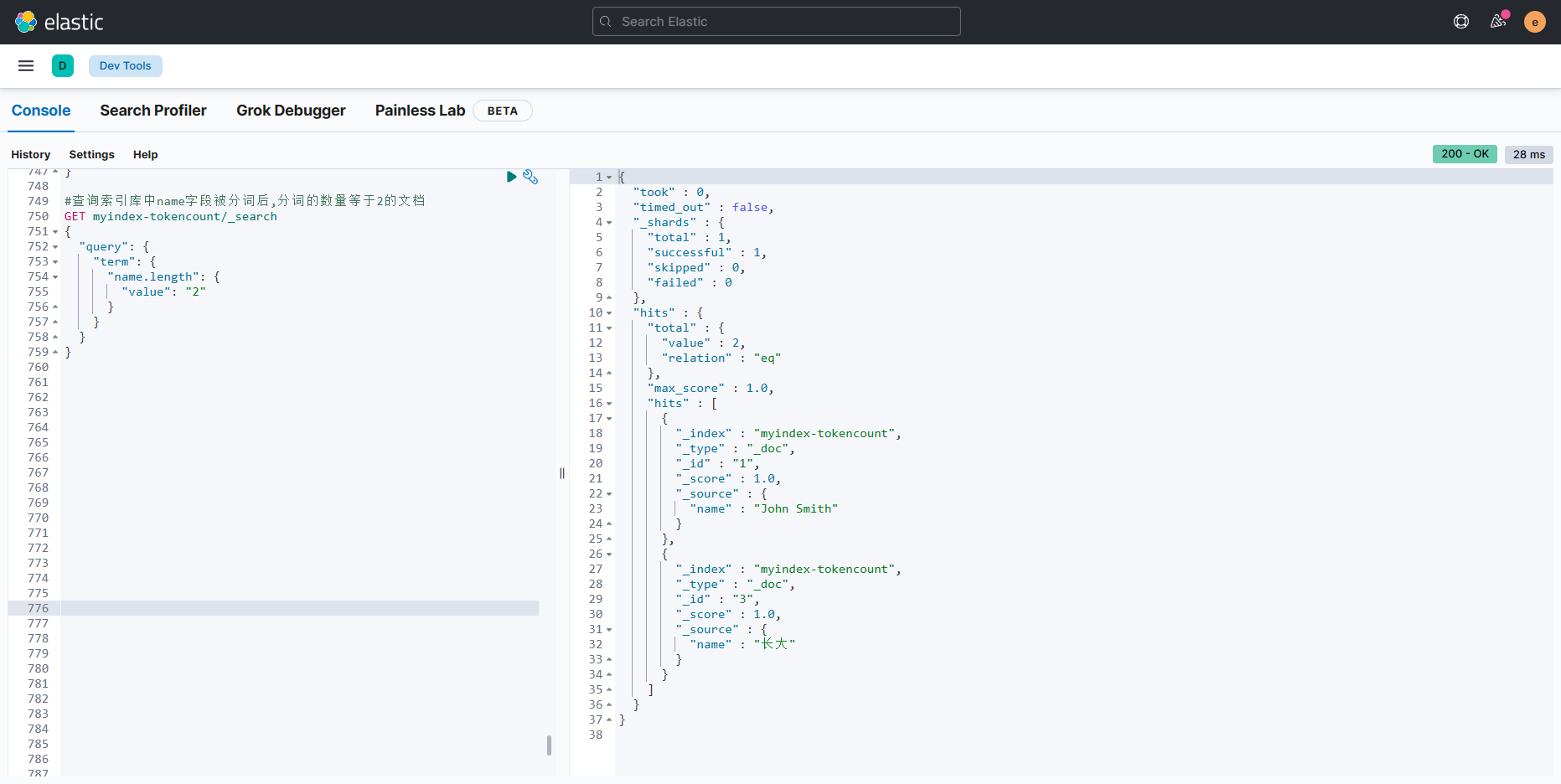
- 可以看到"John Smith"被standard分词为"John"和"Smith",所以分词数量是2。上面的返回结果符合预期。在查询过程中,我们还可以使用分析语句对查询的内容进行预判分析,范例如下:
#使用standard分词器对内容"John Smith"进行分词处理,返回分词后的结果
GET myindex-tokencount/_analyze
{"analyzer": "standard","text":["John Smith"]
}
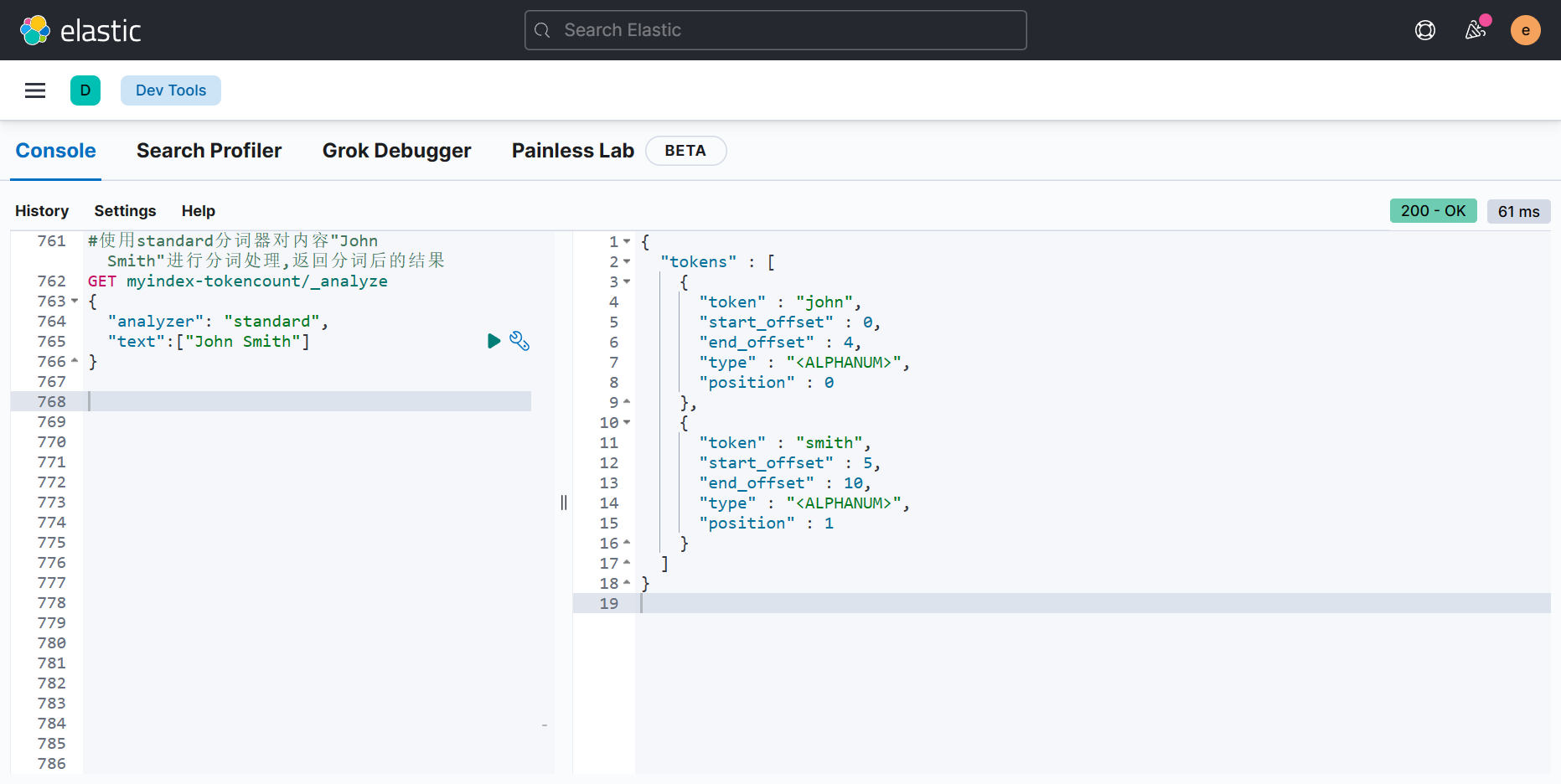
- 以上结果与我们预想的一样,"Joh Smith"被分词成两个单词,还记录了具体分词的单词在原始内容的偏移量。