来源:投稿 作者:摩卡
编辑:学姐
Motivation
现阶段出现了大量的Transformer-style图像分类模型,并且这些模型在ImageNet上取得了不俗的成绩,这些Transformer-style模型将取得高性能的功劳归功于Multi-head attention注意力机制,但是是否由于attention而取得好效果目前还不明确。故本文为了验证该想法Is the attention necessary? 进行了研究。
Method
为了验证attention是否在图像分类问题上起决定性作用,本文使用Feed-Forward Network (single-layer MLP)替换Multi-head attention,模型图如下所示:

然后选取了当下流行的ViT(2020年提出的纯Transformer的图像分类网络)和DeepViT(2021年提出,在几乎不扩充ViT占用内存的情况下提升ViT性能的图像分类模型)作为baseline,将ViT/DeepViT中的Transformer模块替换为上图所示的类Transformer的Feed-Forward模块,在保证任何参数都与baseline相同的情况下进行实验。
Result
实验结果如下图所示:
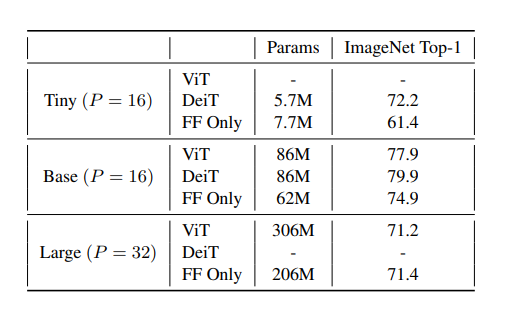
由上表可知,在Base的参数设置下FFN-only模型在使用0.72%ViT/DeepViT参数的情况下,效果达到了74.9%。而在Large的参数设置下FFN-only模型在使用0.67ViT/DeepViT参数的情况下效果与ViT不相上下。
作者还验证了Attention-only模型的效果(即将Transformer模块中的FFN替换为Multi-head attention),使用ViT-BASE的设置,在ImageNet上的效果仅仅为28.2%。
Conclusion
上述结果表明,虽然FFN-only模型没有刷新ImageNet的指标,但是相比较于Attention-only模型已经是质的飞跃,由此引发研究者的思考:到底是哪一部分使得Transformer-style模型的性能提升?
作者认为是patch-embedding和train procedure。因为patch-embedding对图像特征进行了很强的归纳,而train procedure中的trick会变相的进行数据增强。
个人体会
该论文出自Oxford University,与重新让研究者关注MLP的论文有异曲同工之妙,Feed-Forward Network(FFN)作用在patch上,可以将其看作一个特殊的convolution,只不过该卷积只作用于单通道。
而FFN作用在image features上时实际上就是一个1*1 convolution。由此引发我的思考,可以将该思想迁移到其他任务之上,研究在该任务中Multi-head attention的作用。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“CVPR”获取顶会必读论文合集
码字不易,欢迎大家点赞评论收藏!