注意:kubeadm与docker是有版本要求的。
如果版本不兼容,初始化 kubeadm是会出现以下问题。

什么是 Pod 控制器类型 K8S 网络通讯模式
Kubernetes 构建 K8S 集群
- 资源清单
资源 掌握资源清单的语法 编写 Pod 掌握 Pod 的生命周期
Pod控制器
掌握各种控制器的特点以及使用定义方式
- 服务发现
掌握 SVC 原理及其构建方式
- 存储
掌握多种存储类型的特点 并且能够在不同环境中选择合适的存储方案(有自己的简介)
- 调度器
掌握调度器原理 能够根据要求把Pod 定义到想要的节点运行
- 安全
集群的认证 鉴权 访问控制 原理及其流程
- HELM
Linux yum 掌握 HELM 原理 HELM 模板自定义 HELM 部署一些常用插件
- 运维
修改Kubeadm 达到证书可用期限为 10年 能够构建高可用的 Kubernetes 集群
- 服务分类
- 有状态服务:
DBMS
- 有状态服务:
无状态服务:LVS APACHE
高可用集群副本数据最好是 >= 3 奇数个
一、大纲
二、组件
2.1、borg系统架构
这是一个谷歌Borg调度器的架构。

- BorgMaster
负责分发,这里不能部署为偶数节点,只能部署技术节点。为了工作保障,做好部署3个以上的BorgMaster,说白了,这就有点类似注册中心。
- Borglet
真正工作的就是Borglet,由于BorgMaster分发过来处理。
2.2、k8s架构
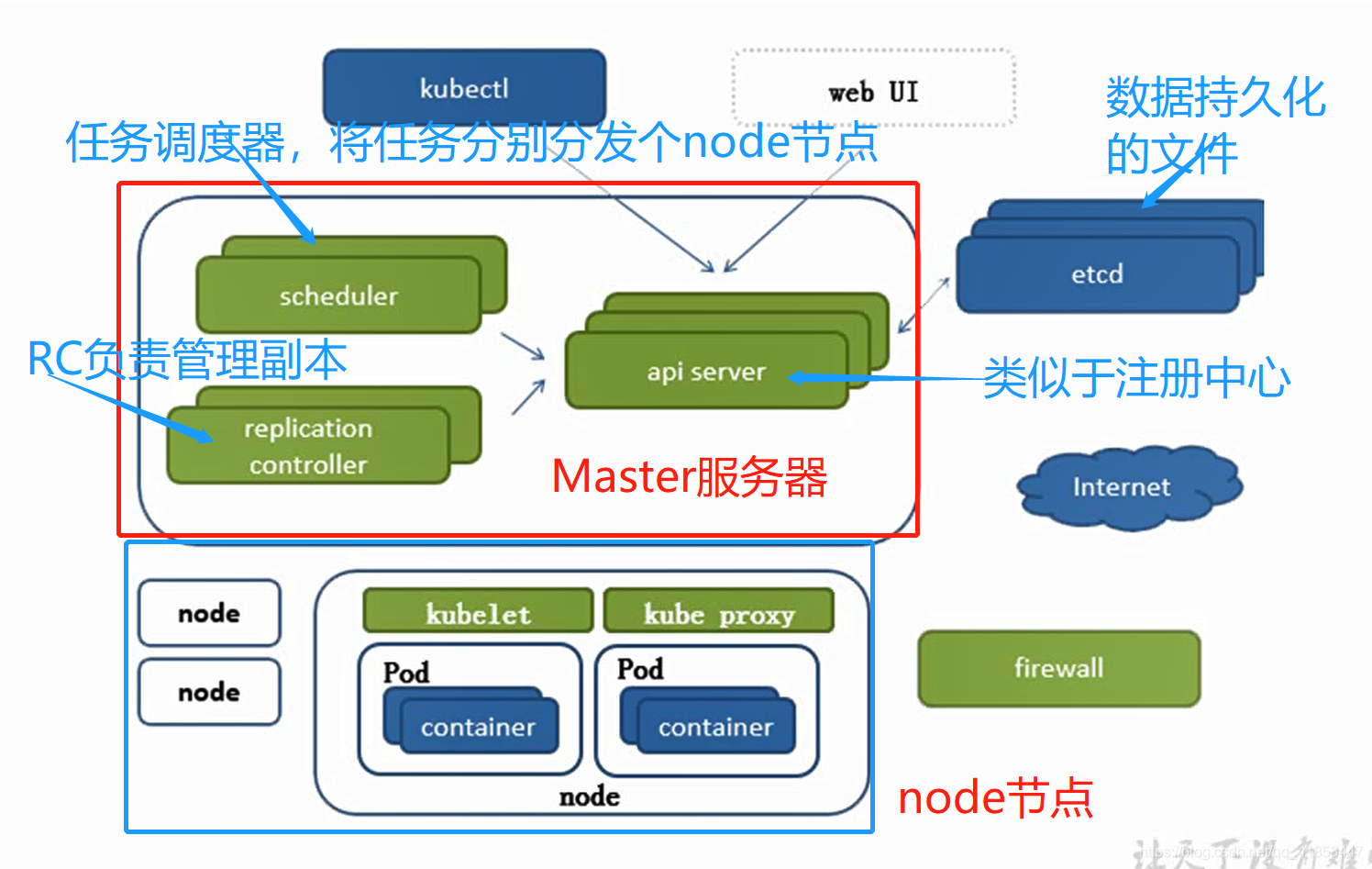
Master服务
Schduler任务调度
负责将任务分发给node节点处理。但是scheduler不会直接和node节点交互,会将任务交给 api server保存到etcd持久化文件中。
replication controller简称RC
控制器,管理副本的。
因为Schduler和replication controller和etcd都会去访问 api server,所以会在 Schduler和replication controller本地生成一次缓存,为了减少对 api server的访问。
etcd
etcd架构图(了解)

保存需要持久化的重要数据,etcd的官方将它定位成一个可信赖的分布式键值存储服务,它能够为整个分布式集群存储些关键数据,协助分布式集群的正常运转。
etcd保存数据访问- v2版:Memory 保存在内存中
- v3版:Database 保存在磁盘的卷中(说白了就相当于将数据写成一个文件放在这里,关机重启数据还在)
注意:k8s在1.11版本之前是没有v3版的,使用的是v2版本。但是 1.11以后的版本etcv2版已经放弃使用了,都是v3版了。
node节点
主要软件有三个
kubelet:与replication controller简称RC、接口、运行环境之前的调用,并且维持Pod生命周期,也就是Pod的创建和销毁。kube proxy实现Pod与Pod之间的负载均衡调用。container:容器,可以值docker,也可以是其他容器机制。docker只是目前最流行引擎的实现方案。
总结
api server:所有服务访问统一入口
CrontrollerManager:控制器,维持副本期望数目
Scheduler:负责介绍任务,选择合适的节点进行分配任务
etcd:键值对数据库 储存K8S集群所有重要信息(持久化)
Kubelet:直接跟容器引擎交互实现容器的生命周期管理
Kube-proxy:负责写入规则至 IPTABLES、IPVS 实现服务映射访问的
其他插件说明

coredns:可以为集群中的SVC创建一个域名IP的对应关系解析
dashboard:给 K8S 集群提供一个 B/S 结构访问体系
Ingress Controller:官方只能实现四层代理,INGRESS 可以实现七层代理
Federation:提供一个可以跨集群中心多K8S统一管理功能
Prometheus:提供K8S集群的监控能力
ELK:提供 K8S 集群日志统一分析介入平台
三、Pod概念和网络通讯方式
3.1、Pod分类
自主式Pod
不被控制器管理的,销毁后不会自动创建
控制器管理的Pod
-
Replication Controller & ReplicaSet & Deployment -
HPA (Horizontalpodautoscale) -
Statefull Set -
Daemonset Set -
Job, Cronjob
ReplicationController简称RC: 用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod 来替代;而如果异常多出来的容器也会自动回收。在新版本的Kubernetes 中建议使用ReplicaSet 来取代ReplicationControlle。
ReplicaSet 跟ReplicationController 没有本质的不同,只是名字不一样,并且ReplicaSet 支持集合式的selector。
虽然ReplicaSet 可以独立使用,但一般还是建议使用Deployment 来自动管理ReplicaSet ,这样就无需担心跟其他机制的不兼容问题(比如ReplicaSet 不支持rolling-update 但Deployment 支持)
ReplicaSet简称RS:跟 Replicationcontroller没有本质的不同,只是名字不一样,并且Replicase支持集合式的 selector。
虽然 ReplicaSet可以独立使用,但一般还是建议使用 Deployment来自动管理ReplicaSet,这样就无需担心跟其他机制的不兼容问题(比如 Replicase不支持rolling-update但 Deployment支持。
虽然 Deployment实现滚动更新,但是需要和ReplicaSet一起使用,因为Deployment不支持Pod创建。
Deployment 为Pod 和ReplicaSet 提供了一个声明式定义(declarative) 方法,用来替代以前的ReplicationController 来方便的管理应用。典型的应用场景包括:
定义Deployment 来创建Pod 和ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续Deployment
Horizontal Pod Autoscaling 仅适用于Deployment 和ReplicaSet ,在V1 版本中仅支持根据Pod 的CPU 利用率扩所容,在v1alpha 版本中,支持根据内存和用户自定义的metric 扩缩容。
StatefulSet是为了解决有状态服务的问题(对应Deployments 和ReplicaSets是为无状态服务而设计),其应用场景包括:
稳定的持久化存储,即Pod 重新调度后还是能访问到相同的持久化数据,基于PVC 来实现
稳定的网络标志,即Pod 重新调度后其PodName和HostName不变,基于Headless Service (即没有Cluster IP 的Service )来实现
有序部署,有序扩展,即Pod 是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0 到N-1,在下一个Pod 运行之前所有之前的Pod 必须都是Running 和Ready 状态),基于init containers 来实现
有序收缩,有序删除(即从N-1 到0)
DaemonSet 确保全部(或者一些)Node 上运行一个Pod 的副本。当有Node 加入集群时,也会为他们新增一个Pod 。当有Node 从集群移除时,这些Pod 也会被回收。删除DaemonSet 将会删除它创建的所有Pod
使用DaemonSet 的一些典型用法
运行集群存储daemon,例如在每个Node 上运行glusterd、ceph。
在每个Node 上运行日志收集daemon,例如fluentd、logstash。
在每个Node 上运行监控daemon,例如Prometheus Node Exporter返回
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod 成功结束Cron Job管理基于时间的Job,即:
在给定时间点只运行一次
周期性地在给定时间点运行

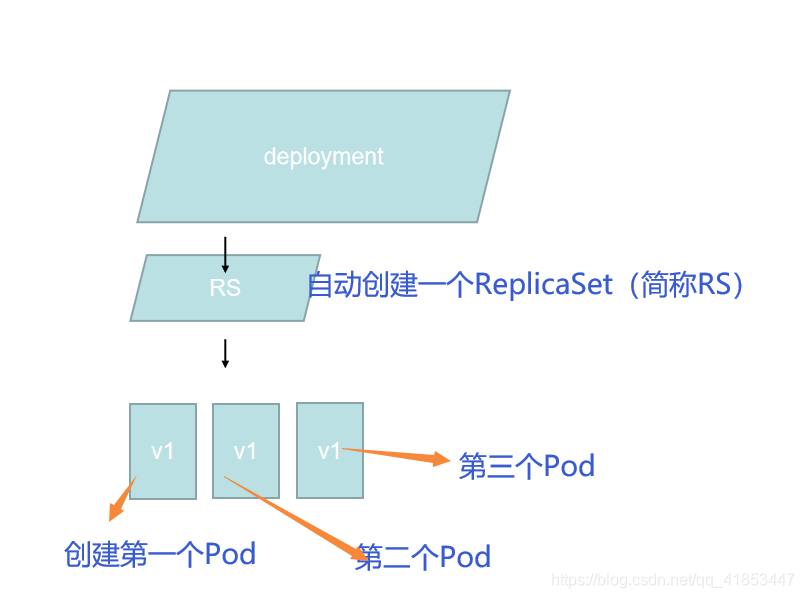
如果要时间滚动更新,Deployment会另外创建一个RS。然后在新建的RS下创建Pod,新建一个Pod,就将原来的Pod停用,这里也可以回退的,因为原来的Pod并没有删除,只是停用。

3.2、Pod概念
- 概念
3.3、网络通讯方式
Kubernetes 的网络模型假定了所有Pod 都在一个可以直接连通的扁平的网络空间中,这在GCE(Google Compute Engine)里面是现成的网络模型,Kubernetes 假定这个网络已经存在。而在私有云里搭建Kubernetes 集群,就不能假定这个网络已经存在了。我们需要自己实现这个网络假设,将不同节点上的Docker 容器之间的互相访问先打通,然后运行Kubernetes。
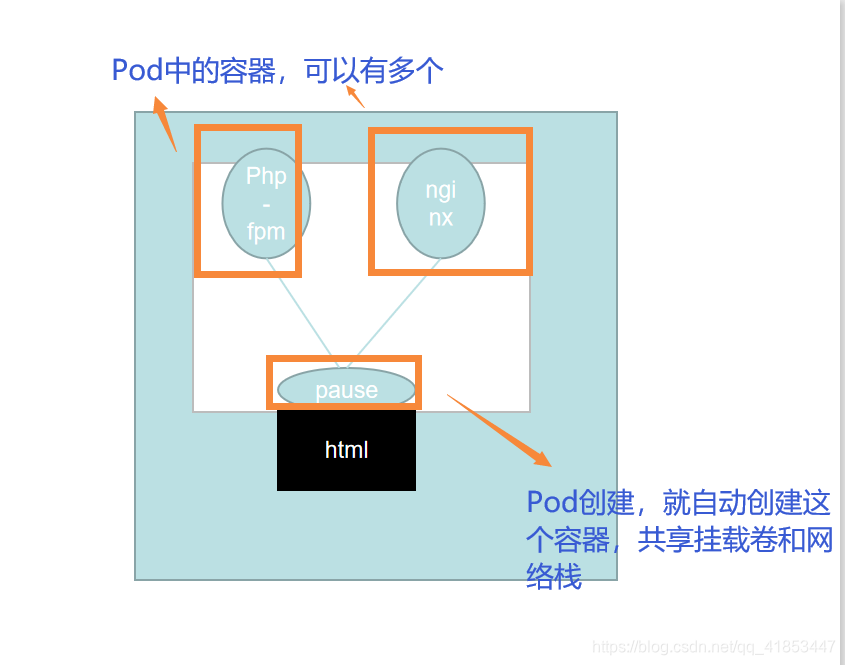
同一个Pod内的多个容器之间:lo
创建一个Pod之后,会自动创建一个容器。这个容器主要作用是共享当前Pod的网络栈和挂在卷,然后这个Pod在创建其他容器时,就共享这个网络栈。这样就可以实现Pod中的容器网路通信和存储问题,需要注意:在同一Pod中端口不能重复,因为使用的都是同一个网络栈,如果端口重复了,会启动失败或者无限的启动。
各Pod之间的通讯: Overla Network
Pod与 Service之间的通讯:各节点的 Iptables规则
Flannel是Core0S团队针对 Kubernetes设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的 Docker容器都具有全集群唯一的虚拟IP地址。而且它还能在这些IP地址之间建立一个覆盖网络(0 verla Network),通过这个覆盖网络,将数据包原封不动地传递到目标容器内。

这张图上有两个物理主机,每台物理主机上运行了两个Pod。需要实现这四个来自不同物理主机的Pod通讯,在同主机的Pod直接采用共享网络栈的方式是很好做到的,不同主机之间的通讯是通过Flannel实现的。
- ETCD 之 Flannel 提供说明:
存储管理Flannel 可分配的IP 地址段资源
监控ETCD 中每个 Pod 的实际地址,并在内存中建立维护 Pod 节点路由表。
总结上图工作工程
- 同一个Pod 内部通讯
同一个Pod 共享同一个网络命名空间,共享同一个Linux 协议栈
- Pod1 至Pod2
Pod1 与Pod2 不在同一台主机,Pod的地址是与docker0在同一个网段的,但docker0网段与宿主机网卡是两个完全不同的IP网段,并且不同Node之间的通信只能通过宿主机的物理网卡进行。将Pod的IP和所在Node的IP关联起来,通过这个关联让Pod可以互相访问。
Pod1 与Pod2 在同一台机器,由Docker0 网桥直接转发请求至Pod2,不需要经过Flannel。
- Pod 至 Service的网络
目前基于性能考虑,全部为iptables 维护和转发。
- Pod 到外网
Pod 向外网发送请求,查找路由表, 转发数据包到宿主机的网卡,宿主网卡完成路由选择后,iptables执行Masquerade,把源IP 更改为宿主网卡的IP,然后向外网服务器发送请求。
- 外网访问Pod
必须通过Service

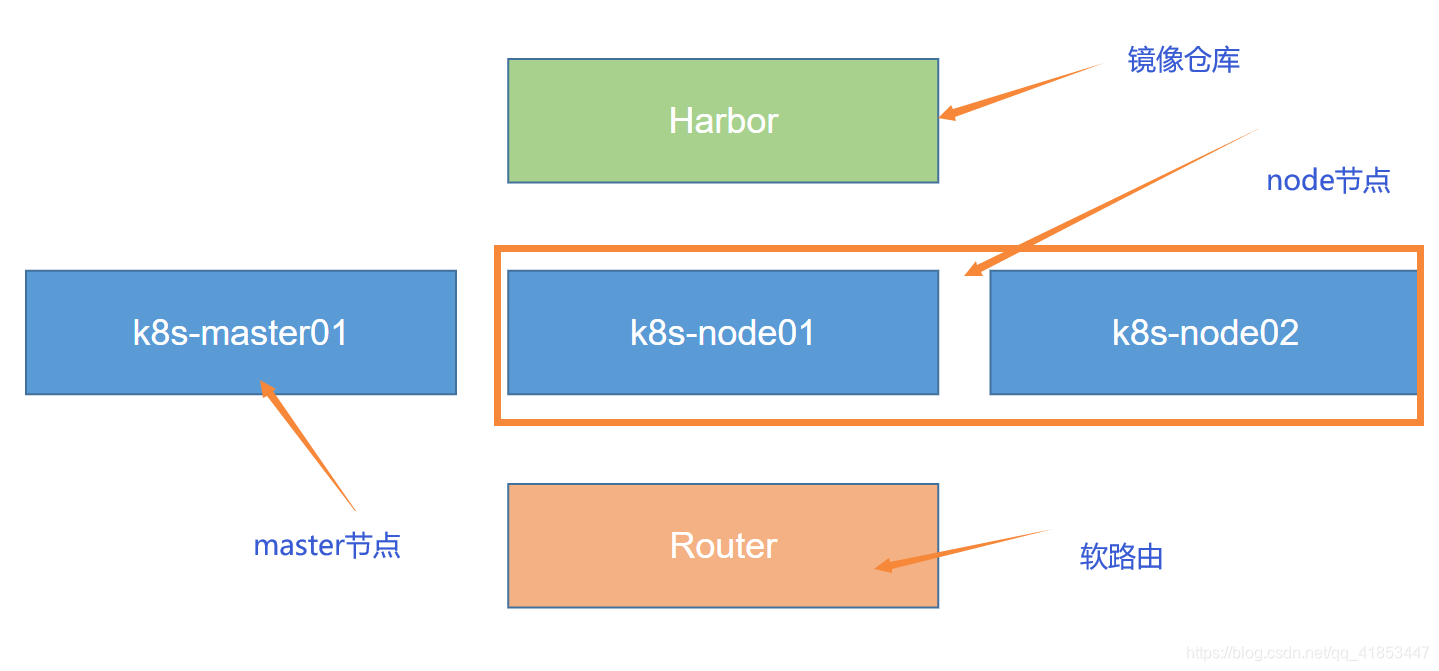
四、k8s安装
k8s安装,采用 Kubeadm 自动化安装方式。如果采用源码包构建,这样会每个组件都占用一个进程,如果进程杀死了就没有不能使用了。
更改操作系统源(不用更改)
这里就是我们使用yum install软件的地址,默认好像是国外的,下载起来特别缓慢,需要这是为国内的,例如:清华大学的,或者阿里云的都可以。配置地址在 /etc/yum.repos.d下的 CentOS-Base.repo。这个问价那种是可以配置多个数据源的。
- 备份原来的数据
cp /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak
- 将
CentOS-Base.repo文件替换为一下数据
# CentOS-Base.repo
#
# The mirror system uses the connecting IP address of the client and the
# update status of each mirror to pick mirrors that are updated to and
# geographically close to the client. You should use this for CentOS updates
# unless you are manually picking other mirrors.
#
# If the mirrorlist= does not work for you, as a fall back you can try the
# remarked out baseurl= line instead.
#
#[base]
name=CentOS-$releasever - Base
baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/os/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=os
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7#released updates
[updates]
name=CentOS-$releasever - Updates
baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/updates/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=updates
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7#additional packages that may be useful
[extras]
name=CentOS-$releasever - Extras
baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/extras/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=extras
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7#additional packages that extend functionality of existing packages
[centosplus]
name=CentOS-$releasever - Plus
baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/centosplus/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=centosplus
gpgcheck=1
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
- 清空缓存
yum clean all # 清除系统所有的yum缓存
yum makecache # 生成yum缓存
- 查看yum源
yum repolist all # 查看所有的yum源
yum repolist enabled # 查看可用的yum源
设置静态IP(具有很多问题)(不更改)
如果是真实服务器就不用设置了,应为真实服务器的IP本来就是静态的,不会随机变动。
这里如果不设置,默认是动态IP,这样后面会很麻烦的。我们将配置文件中的IP配置成当前的IP,但是重启后IP有改变了。所以这里有必要设置以下的。
设置地址在 /etc/sysconfig/network-scripts/目录下有一个 ifcfg-*的文件,根据电脑不同,这个文件名不同,通常都是 ifcfg-ens33。
设置VMware网络(重点)




设置Windows网络
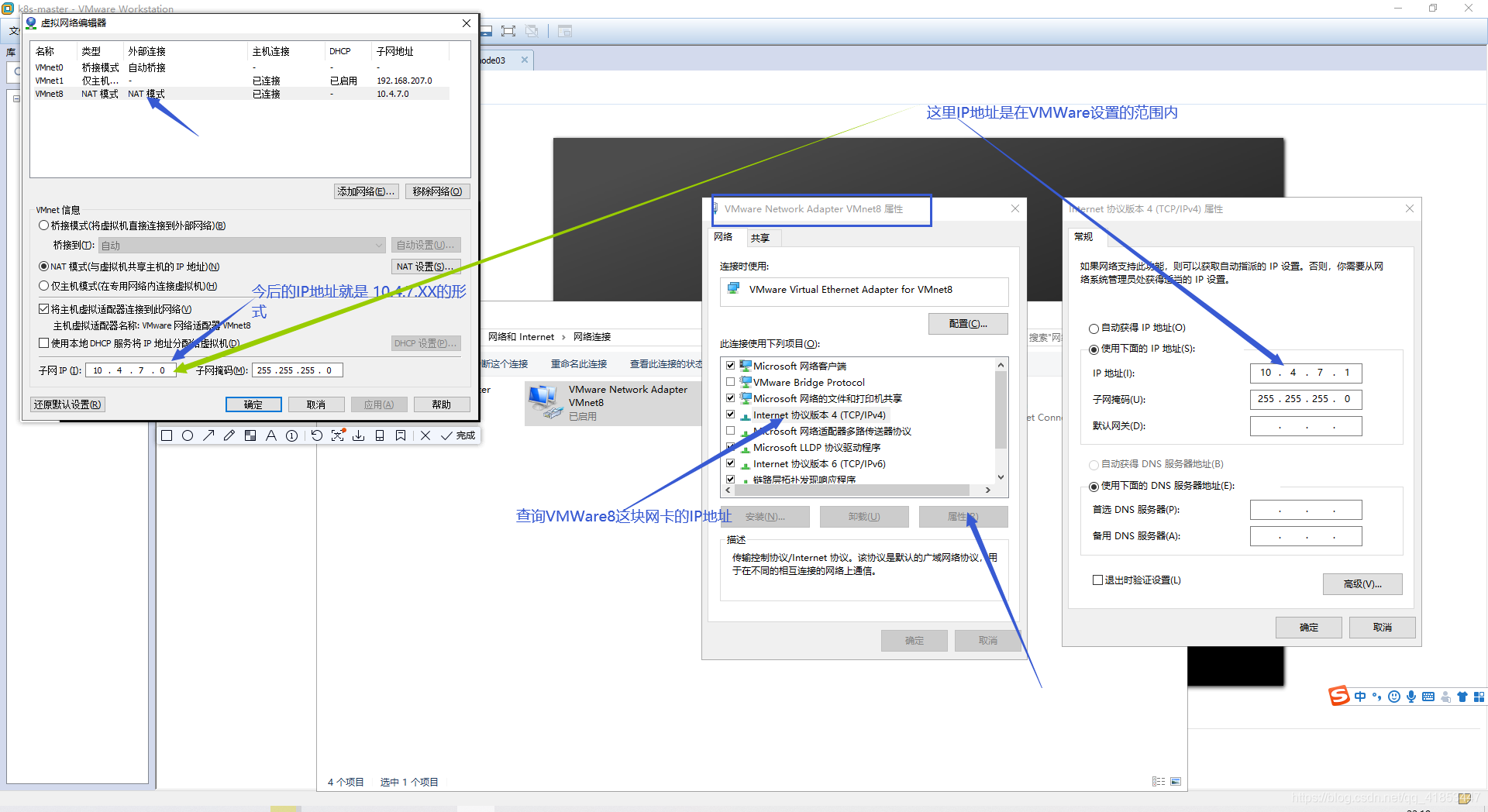
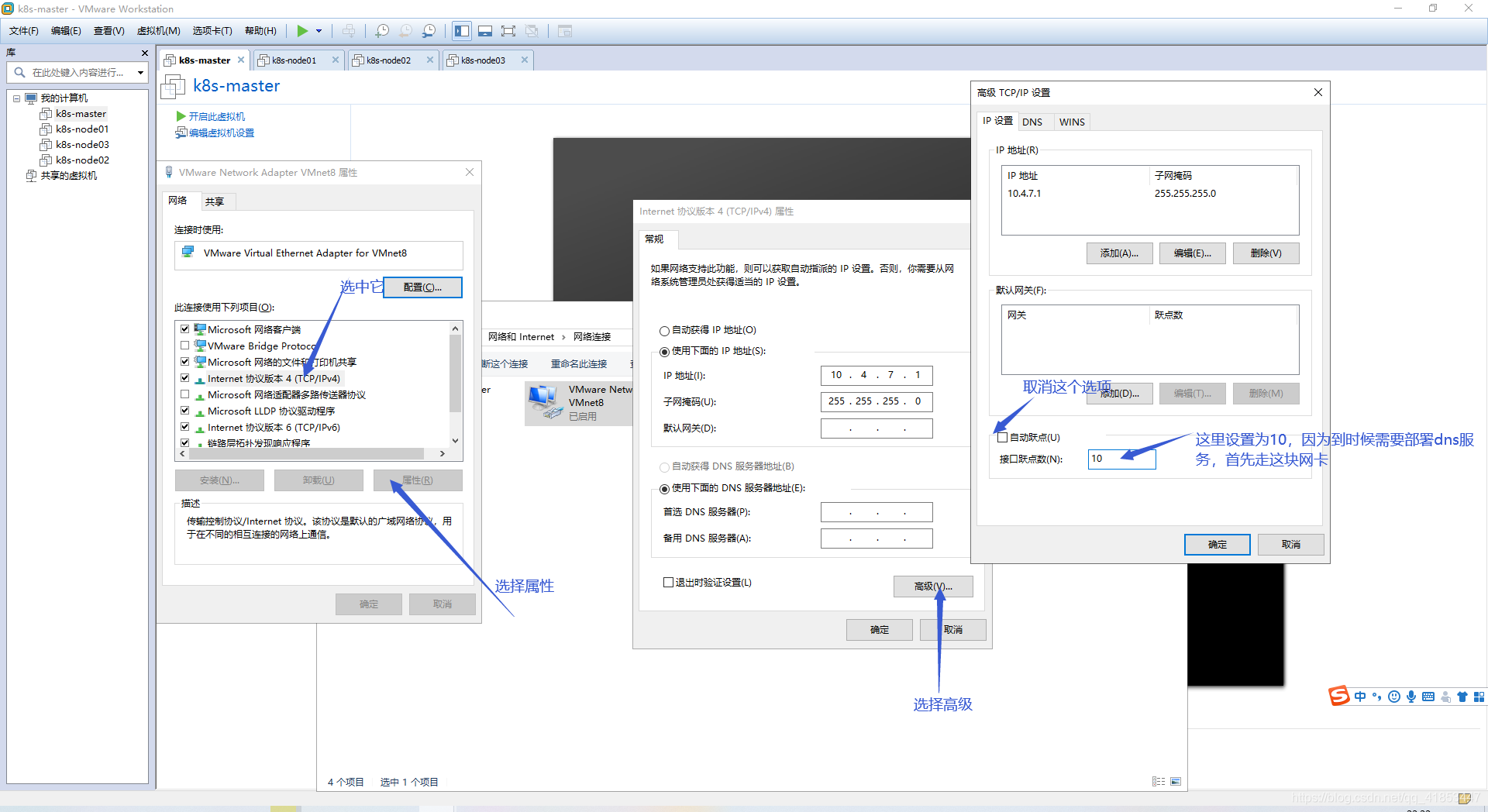
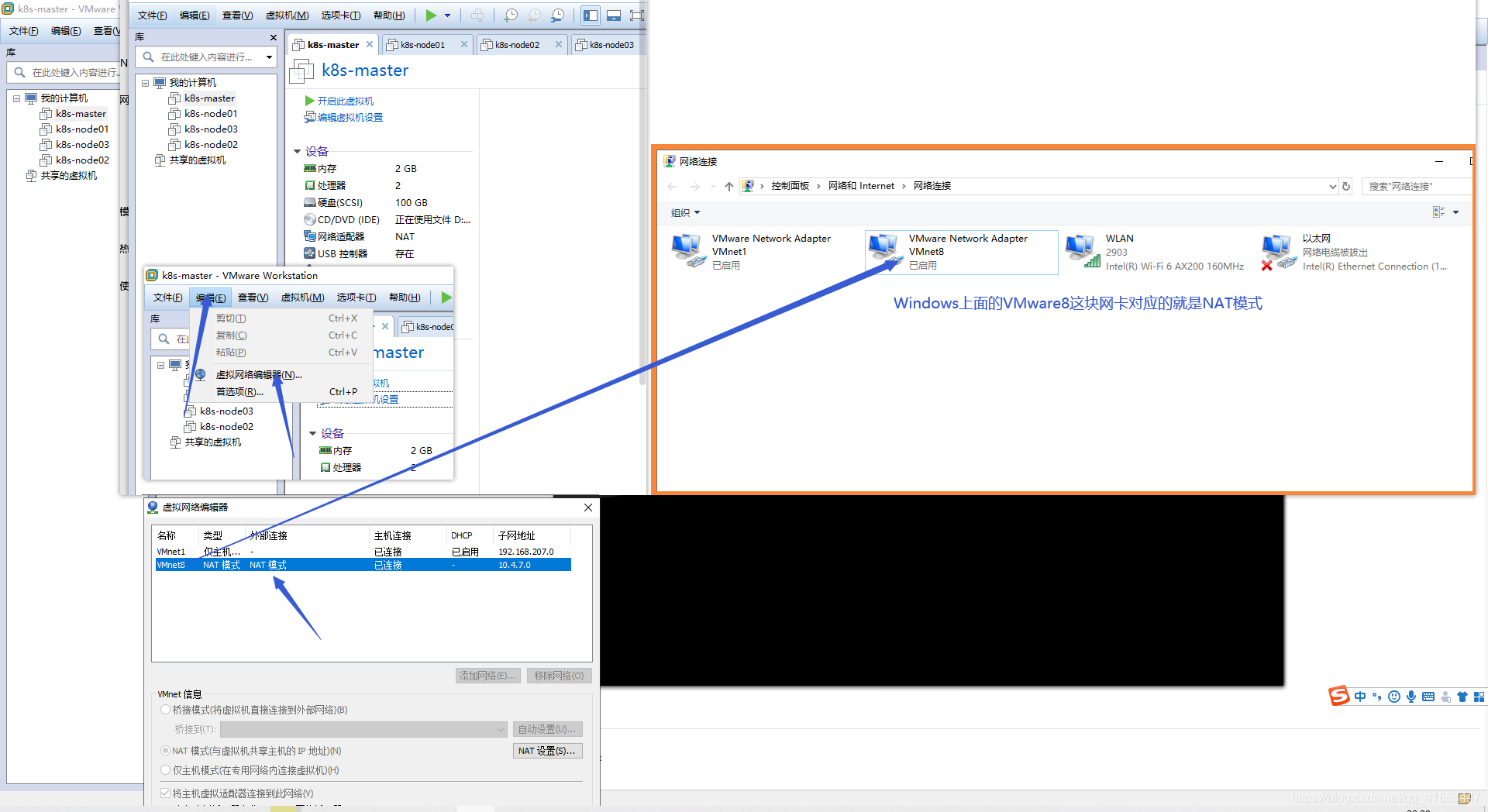
- 设置IP为静态地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
需要更改 BOOTPROTO="static"设置为static,默认是 BOOTPROTO="dhcp"这样的。
- 添加一下网络信息
IPADDR=192.168.22.132 # 静态IP地址
NETMASK=255.255.255.0 # 子网掩码
GATEWAY=192.168.22.1 # 网管,如果配置利润软路由koolshare之类的,这里需要指定软路由的地址。
DNS1=192.168.22.1 # DNS1 这两个DNS配置了干嘛不太清楚
DNS2=114.114.114.114 # DNS2

- 重启网络服务
这里一定要重启网络服务,否则配置不生效。
service network restart
或者
/etc/init.d/network restart
安装软路由(koolshare)
官网:https://github.com/koolshare
安装软路由的主要目的是:我们国内访问不到谷歌的镜像仓库,通过软路由配置一个能够访问外网的SSR服务器信息,在软路由里面安装一个安全上网插件,这样就可以访问了。不推荐这样干,国内有阿里镜像仓库,可以直接配置阿里镜像仓库就可以了。
4.1、系统初始化
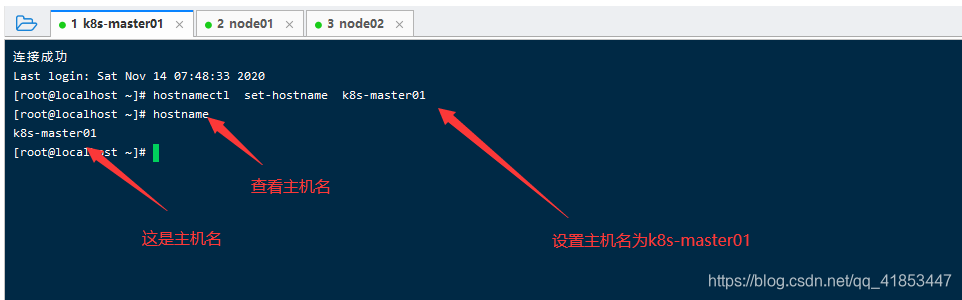
设置系统主机名
分别将每台主机的设置为响应的名称,不用设置也是没有问题的,不过设置过了,后面的操作会要方便一些。
- k8s-master01 主机
hostnamectl set-hostname k8s-master01
- node01
hostnamectl set-hostname node01

- node02
hostnamectl set-hostname node02
- 查看主机名
hostname
设置HostS 文件的相互解析
在Hosts问价里面定义域名核对应的IP,今后使用直接使用域名就方便很多了。这里还可以安装一个DNS服务器解析。Hosts文件路径 /etc/hosts。
需要使用到的主机都要配置,我目前只使用三台主机,所以这三台我都配置。
- 命令
vim /etc/hosts
192.168.22.132 k8s-master01
192.168.22.129 node01
192.168.22.131 node02
IP 地址和 主机名根据自己的实际情况来配置。

安装依赖包
yum install -y conntrack ntpdate ntp ipvsadm ipset jq iptables curl sysstat libseccomp wgetvimnet-tools git
设置防火墙为 Iptables 并设置空规则
这里的防火墙不是使用 firwalld了,而是使用iptables,因为 iptables相对来说要牛批一些。今后需要开放那些端口,需要针对iptables防火墙开启。
- 关闭防火墙
systemctl stop firewalld
- 设置为开机不启动防火墙
systemctl disable firewalld
- 安装
iptables-services管理工具
iptables是一个防火墙,可以配置有状态的防火墙。有状态防火墙,举个例子:我不想让其它主机连接本机的任何端口,但又希望,当我主动去连接别人的时候,别人回过来的包我可以收到。
yum -y install iptables-services
- 启动
iptables
systemctl start iptables
- 设置为开机自动启动
iptables
systemctl enable iptables
- 清空
iptables规则
iptables -F
- 保存
iptables默认规则
service iptables save
关闭 selinux
selinux是一个安全增强型的Linux,详细介绍参考:https://www.cnblogs.com/kelelipeng/p/10371593.html
swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
swapoff -a关闭swapoff分区,这个分区表示虚拟内存。
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab: 永久关闭
setenforce 0临时关闭selinuxgetenforce //查看Selinux状态
关闭 swapoff分区(虚拟内存)的原因是: Kubeadm(k8m)安装k8s的时候,init初始化的时候会去检测 虚拟内存是否关闭,如果开启虚拟内存,Pod会有可能放到虚拟内存中运行,会降低工作效率的。
调整内核参数,对于 K8S
在 /etc/sysctl.d/目录下创建一个 kubernetes.conf文件,并写入以下数据。但是我们这里直接在当前文件夹下创建 kubernetes.conf文件,并将输入写入,然后在复制到 /etc/sysctl.d文件夹下面。
- 创建
kubernetes.conf文件并写入数据
cat > /opt/data/kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables=1 # 开启网桥模式(必须)
net.bridge.bridge-nf-call-ip6tables=1 # 开启网桥模式(必须)
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0vm.swappiness=0 # 禁止使用 swap 空间,只有当系统 OOM 时才允许使用它vm.overcommit_memory=1 # 不检查物理内存是否够用
vm.panic_on_oom=0 # 开启
OOMfs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963 # 开启最大打开数目
net.ipv6.conf.all.disable_ipv6=1 # 关闭ipv6协议(必须)
net.netfilter.nf_conntrack_max=2310720
EOF
net.bridge.bridge-nf-call-iptables=1 net.bridge.bridge-nf-call-ip6tables=1这两条是开启网桥模式
net.ipv6.conf.all.disable_ipv6=1关闭ipv6以上这三个是必备的,其余的都是一个写优化。
cat > kubernetes.conf <<EOF 输入的数据 EOF ,这是在当前文件夹下创建
kubernetes.conf文件,并写入数据,写入得数据以 <<EOF 开头 EOF 结尾。但是<<_EOF 这种写法并不会以EOF结束,参考:https://blog.csdn.net/robin90814/article/details/86705155
- 将
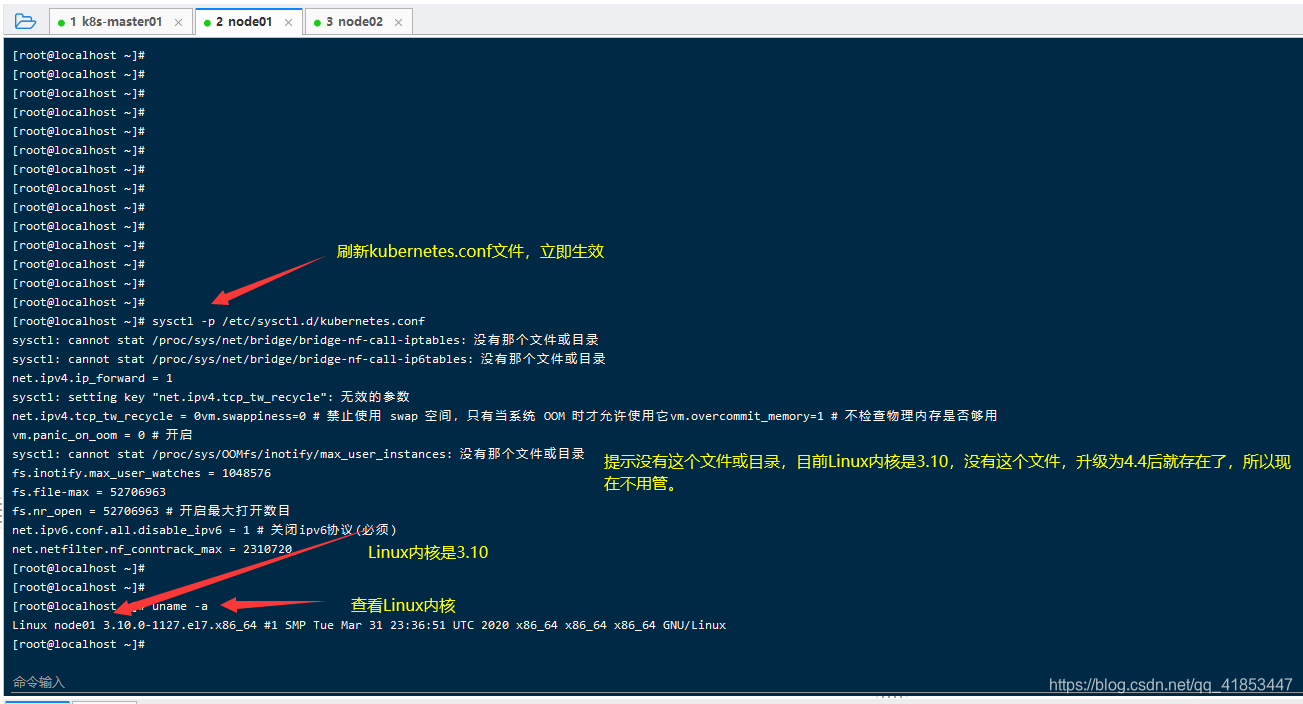
kubernetes.conf文件复制到/etc/sysctl.d文件夹下并刷新。
cp /opt/data/kubernetes.conf /etc/sysctl.d/kubernetes.conf
# 刷新,立即生效
sysctl -p /etc/sysctl.d/kubernetes.conf
调整系统时区
# 设置系统时区为中国/上海
timedatectl set-timezone Asia/Shanghai
# 将当前的 UTC 时间写入硬件时钟
timedatectl set-local-rtc 0
# 重启依赖于系统时间的服务
systemctl restart rsyslog
systemctl restart crond
关闭系统的邮件服务 postfix
如果使用到邮件发送,那么可以不用关闭。
systemctl stop postfix && systemctl disable postfix
设置 rsyslogd 和 systemd journald
CentOS7以后,引导方式改为 systemd journald,所以日志系统就有两个同时在工作。我们需要更改为一个日志就可以了,更改为 systemd journald日志工作就行。
# 创建持久化保存日志的目录
mkdir /var/log/journal
# 创建配置文件文件存放目录
mkdir /etc/systemd/journald.conf.d
- 创建配置文件,并写入数据
cat > /etc/systemd/journald.conf.d/99-prophet.conf <<EOF
[Journal]
# 持久化保存到磁盘
Storage=persistent
# 压缩历史日志
Compress=yesSyncIntervalSec=5m
RateLimitInterval=30s
RateLimitBurst=1000
# 最大占用空间
10GSystemMaxUse=10G
# 单日志文件最大
200MSystemMaxFileSize=200M
# 日志保存时间 2 周
MaxRetentionSec=2week
# 不将日志转发到 syslog
ForwardToSyslog=no
EOF
# 不将日志转发到 syslogForwardToSyslog=no
这里设置 no 以后,我们的日志就不会转发到
syslog里面去,这样就会减轻服务器的压力。
- 重启
journald配置
systemctl restart systemd-journald
升级系统内核
参考:https://www.cnblogs.com/jaxyoun/p/12845360.html
CentOS 7.x 系统自带的 3.10.x 内核存在一些 Bug,导致运行的 Docker、Kubernetes 不稳定。
- 更新
yum源库
yum -y update
- 安装
ELRepo仓库的yum源
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm

- 查看可用的系统内核包
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
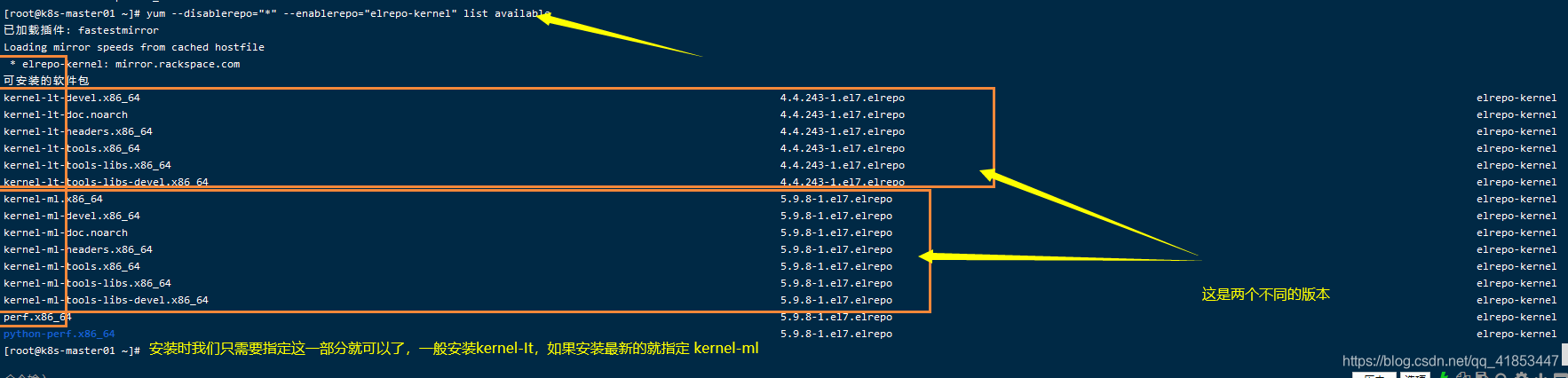
这里有4.4X和 5.9.X两个版本
- 安装内核
安装 4.4.X版本,下面我直接写 kernel-lt,需要看一下 kernel-lt与查询出来的是否为 4.4内核,如果是其他内核,那么安装的就是其他内核了。
yum --enablerepo=elrepo-kernel install -y kernel-lt
如果安装最新版本yum --enablerepo=elrepo-kernel install kernel-ml

- 查看当前系统上的所有可用内核
sudo awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg

- 查看当前系统中全部内核
rpm -qa | grep kernel

- 删除旧内核的 RPM 包
yum remove kernel-3.10.0-1160.2.2.el7.x86_64
注意:当前使用的内核是删除不了的。
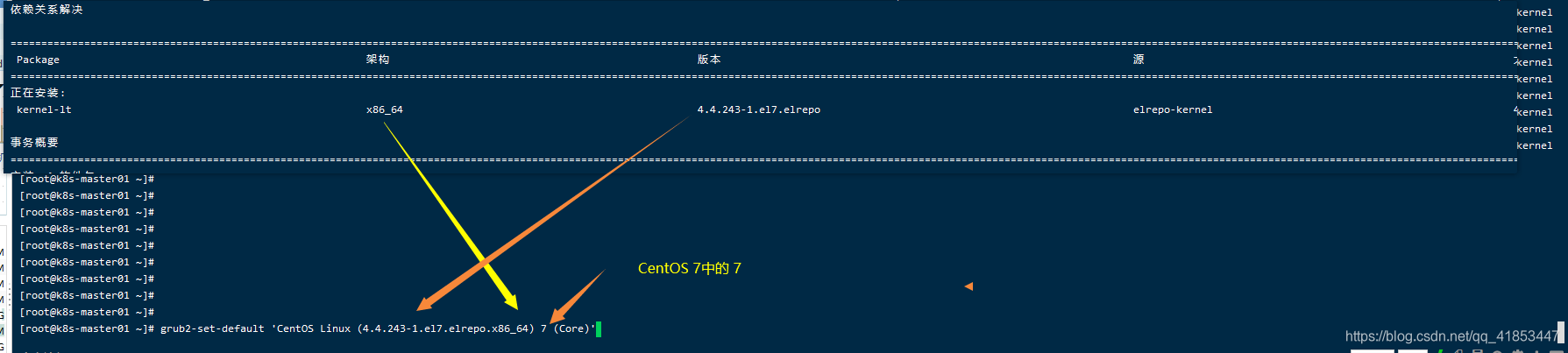
- 设置启动的内核版本
设置了需要重启才会生效。
grub2-set-default 'CentOS Linux (4.4.243-1.el7.elrepo.x86_64) 7 (Core)'
- 重启
Linux
reboot
- 检测内核版本
uname -r

4.2、Kubeadm 部署安装
kube-proxy开启ipvs的前置条件
kube-proxy主要是解决SVC与Pod之间的调度关系,将 kube-proxy模式更改为 ipvs的调度方式,ipvs很大程度上提高kube-proxy的访问效率。
- 加载透明防火墙
br_netfilter
br_netfilter : 透明防火墙,介绍:https://blog.csdn.net/weixin_33804582/article/details/92542460?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
参考:https://www.cnblogs.com/sxwen/p/8417268.html
modprobe br_netfilter
- 编写文件引导
ipvs相关依赖的加载。
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
- 给予权限,并且查看这些文件是否被引导
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4

安装 Docker 软件
- 安装
docker相关依赖
yum install -y yum-utils device-mapper-persistent-data lvm2
- 设置镜像仓库为阿里云
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
有些时候,这个 \不能识别为换行,下面的网址就会提示没问文件或目录,所以我们可以使用一样来执行。
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
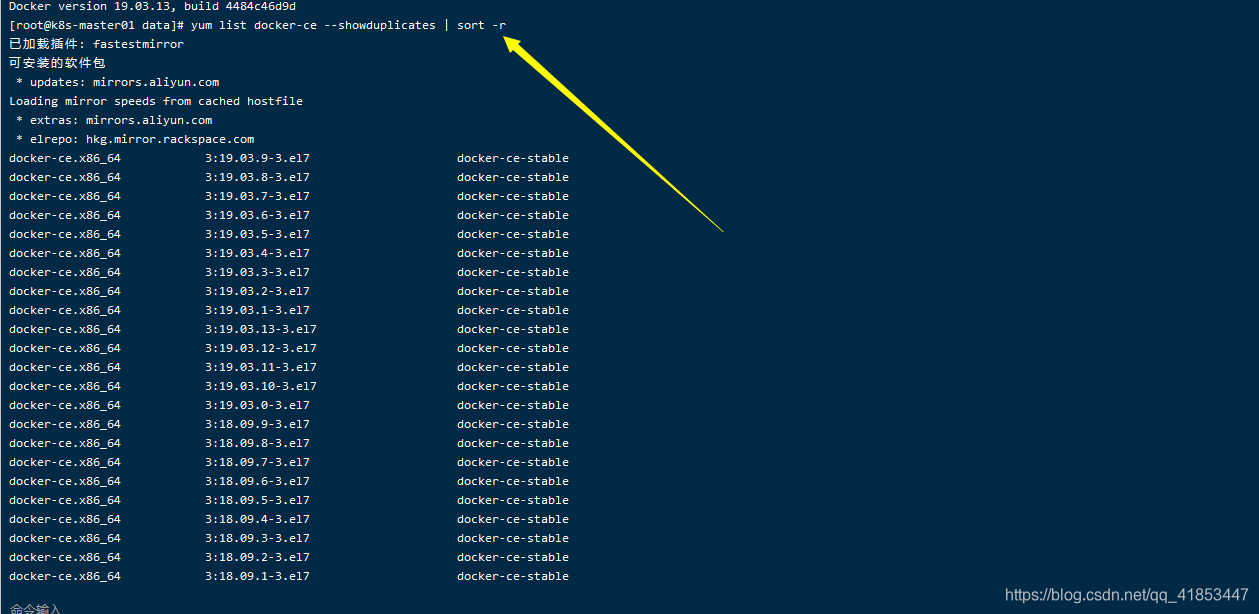
- 列出并排序您存储库中可用的版本。此示例按版本号(从高到低)对结果进行排序。
上面已经设置了阿里云仓库地址了,这里查询的就是阿里云仓库地址中的版本。
yum list docker-ce --showduplicates | sort -r
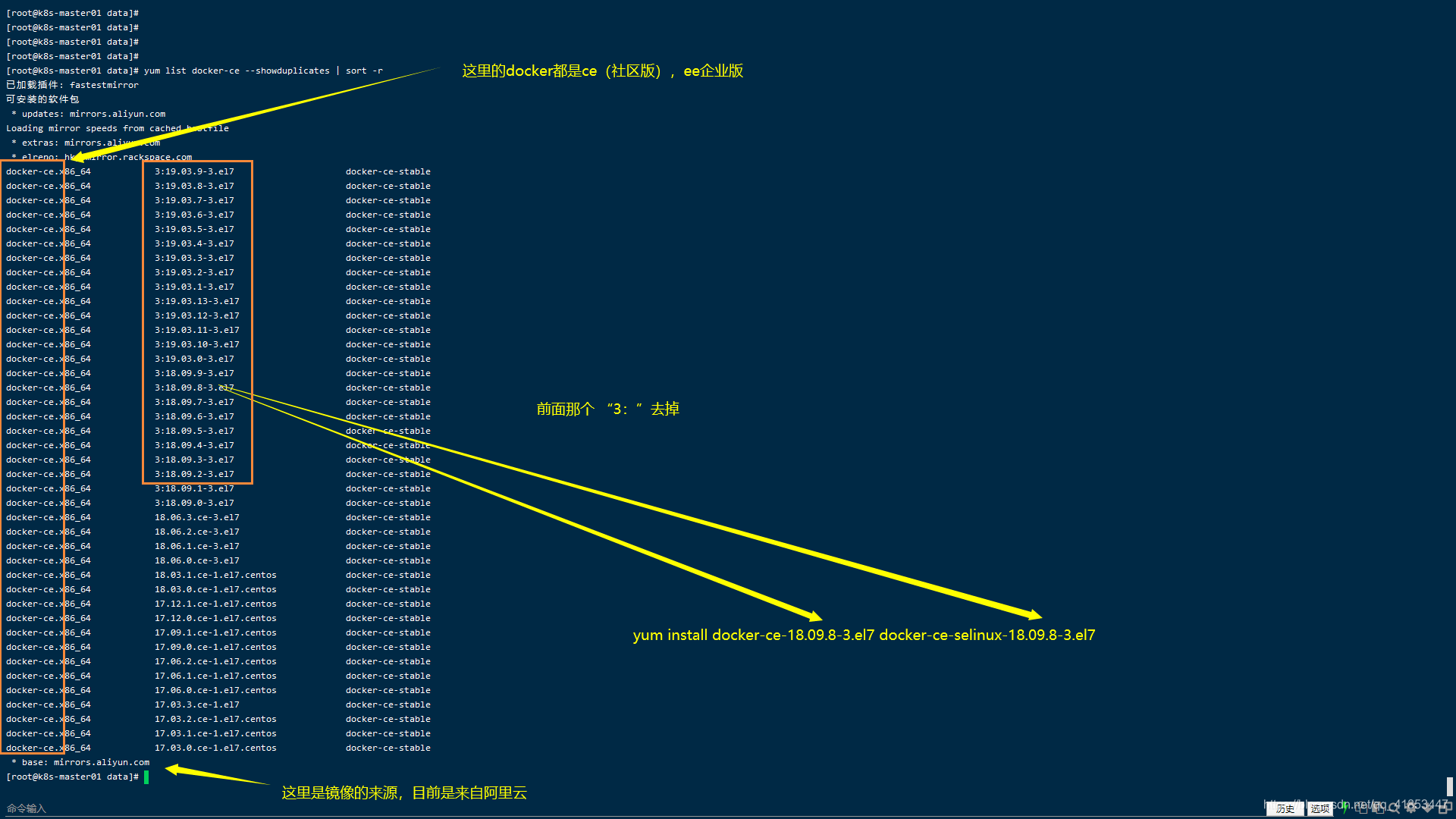
- 安装指定版本的
docker(方式一,推荐)
yum install docker-ce-18.09.8-3.el7
yum install docker-ce-18.09.8-3.el7 docker-ce-selinux-18.09.8-3.el7后面的 docker-ce-selinux-18.09.8-3.el7可以不用写。
- 安装最新的
docker(方式二)
yum install -y docker-ce
- 安装最新的
docker(方式三)
yum update -y && yum install -y docker-ce
yum -y update:升级所有包同时也升级软件和系统内核
yum -y upgrade:只升级所有包,不升级软件和系统内核
yum install -y docker-ce:安装docker-ce,这是docker的一个开源版本。docker也分为几种。
将docker安装完成后,重新启动操作系统查看一下Linux内核,发现会回到原来的历史版本,3.10。这是因为安装docker的时候执行了 yum update -y 命令,升级所有包、升级软件、系统内核造成的。
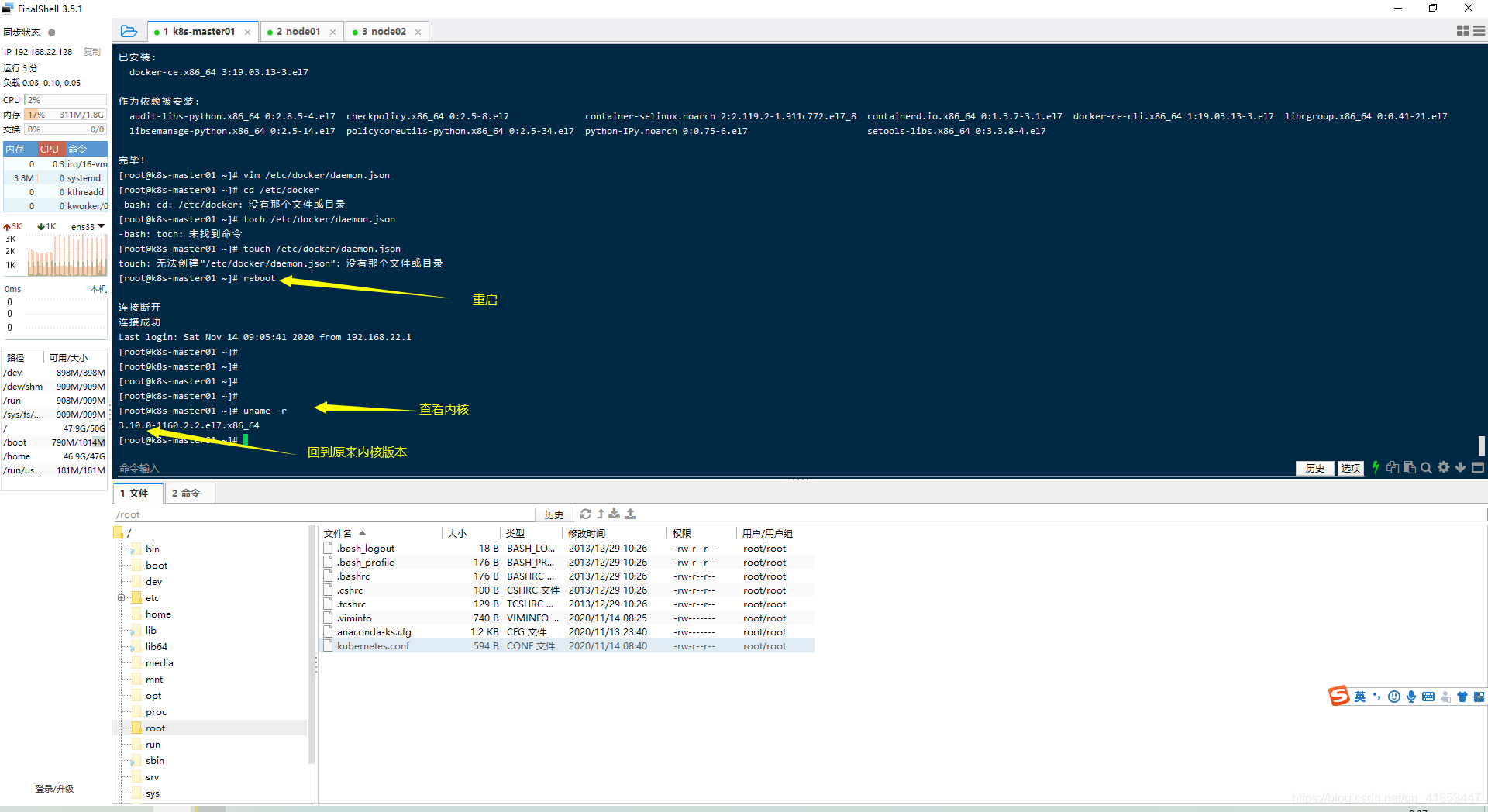
解决方式
查看4.1升级内核部分。
- 查询docker版本
docker -v
- 启动
docker
systemctl restart docker
- 设置开机自启
systemctl enable docker
- 配置
daemon(docker日志信息)
注意:这些文件需要docker启动过了才会有的,如果没有启动过docker就想设置的,那么就先创建文件在启动docker。
cat > /etc/docker/daemon.json <<EOF
{"exec-opts": ["native.cgroupdriver=systemd"],"log-driver": "json-file","log-opts": {"max-size": "100m" },"registry-mirrors": ["https://w57n2hu2.mirror.aliyuncs.com"]
}
EOF
“exec-opts”: [“native.cgroupdriver=systemd”] 设置docker中cgroupdriver分组为systemd
“log-driver”: “json-file” 设置
docker日志存储类型为json-file类型存储“log-opts”: {“max-size”: “100m” } 日志存储大小为 100M
"registry-mirrors": ["https://w57n2hu2.mirror.aliyuncs.com"]:设置镜像仓库地址。

- 创建目录存放
docker配置文件
更改daemon.json配置文件一定要刷新。
mkdir -p /etc/systemd/system/docker.service.d
- 重新读取配置文件
systemctl daemon-reload
注意:daemon-reload没有空格的。
- 重启docker
systemctl restart docker
- 开启docker自启
systemctl enable docker
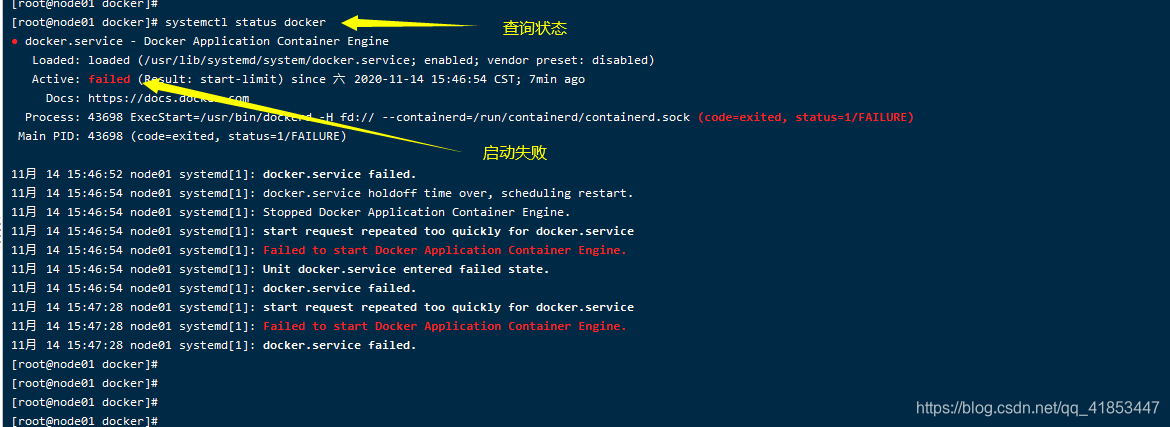
如果启动失败,重新设置 /etc/docker/daemon.json配置文件,在 systemctl daemon -reload刷新配置文件,重新启动。
- 启动docker: systemctl start docker
- 停止docker: systemctl stop docker
- 重启docker: systemctl restart docker
- 查看docker状态: systemctl status docker
- 开机自动启动docker: systemctl enable docker
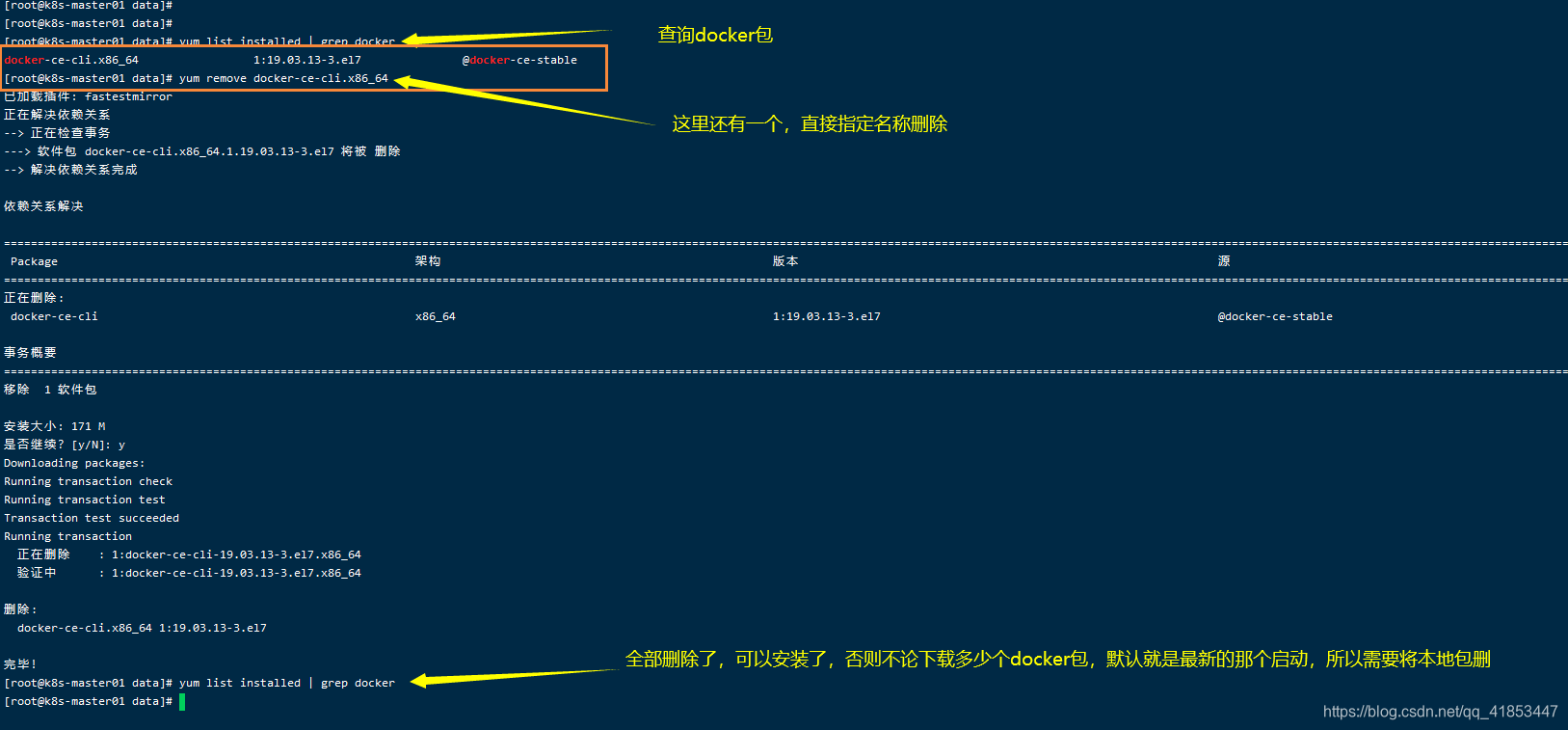
卸载docker
- 卸载docker依赖
yum remove docker-ce docker-ce-cli containerd.io
- 删除资源
rm -rf /var/lib/docker
- 卸载旧版本:(如果安装过旧版本的话)
yum remove docker docker-common docker-selinux docker-engine
- 列出所有docker安装过的包
yum list installed | grep docker
- 卸载 Docker 软件包
yum remove docker-ce
这里需要指定版本删除,不指定就匹配最新版本的docker。
- 删除镜像/容器等
rm -rf /var/lib/docker
安装 Kubeadm (主从配置)
卸载:https://www.cnblogs.com/cpw6/p/12483258.html
- 设置
kubeadm为国内镜像
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
- 安装
kubeadm、kubelet和kubectl
官网文档:https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
您需要在每台机器上安装以下的软件包:
kubeadm:用来初始化集群的指令。kubelet:在集群中的每个节点上用来启动pod和容器等。kubectl:用来与集群通信的命令行工具。
注意:这几个的版本必须一致,否则会导致版本不匹配问题。
yum -y install kubeadm-1.15.1 kubectl-1.15.1 kubelet-1.15.1
- 设置
kubelet开机自启
k8s是以docker的形式存在,所以需要设置为开机自启。
systemctl enable kubelet.service

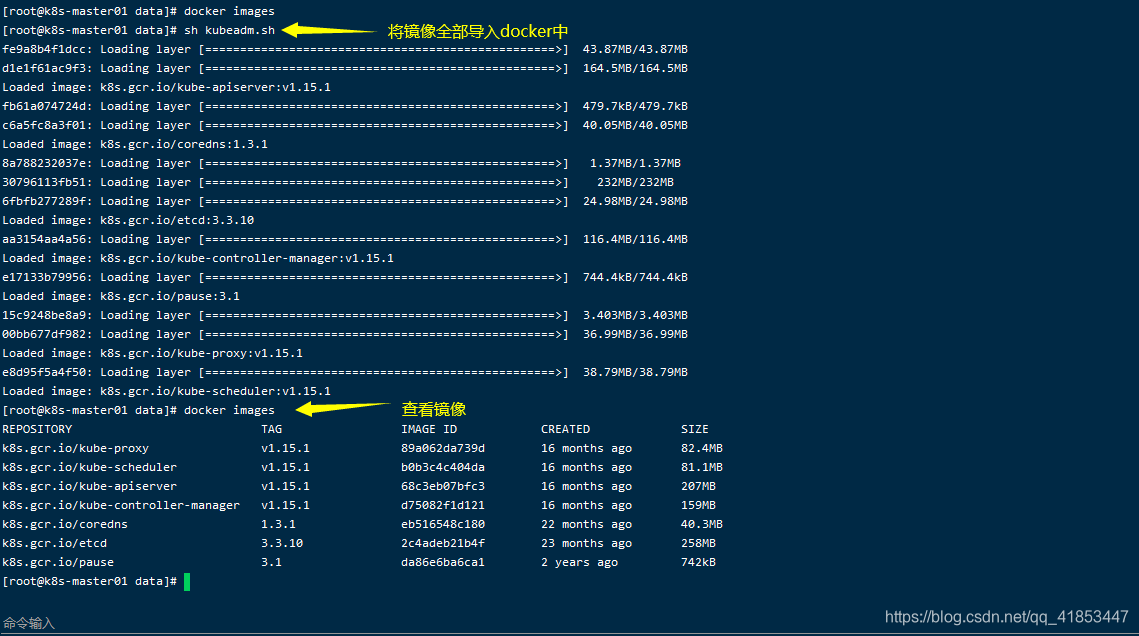
上传kubeadm镜像并创建容器
- 上传并解压
tar -zxvf kubeadm-basic.images.tar.gz
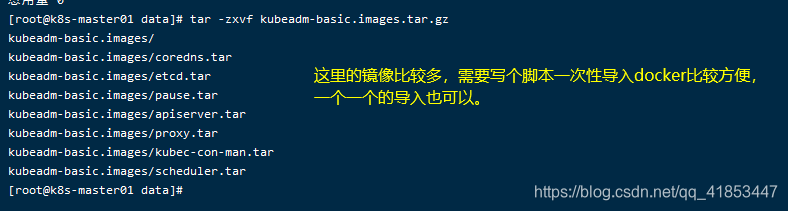
如果镜像有很多个需要导入,如果我们一个一个的导入会很麻烦,所以写一个脚本导入会更加方便。
- 创建启动脚本
touch /opt/data/kubeadm.sh
- 写入启动脚本
#!/bin/bash
ls /opt/data/kubeadm-basic.images > /opt/data/list.txt
cd /opt/data/kubeadm-basic.images
for x in $(cat /opt/data/list.txt)
dodocker load -i $x
done
rm -rf /opt/data/list.txt # 将这个删除,不删除也没问题
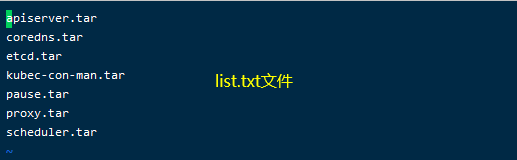
ls /opt/data/kubeadm-basic.images > /opt/data/list.txt: 将kubeadm-basic.images这个目录中的所有问价名读取到list.txt中。
cd /opt/data/kubeadm-basic.images进入kubeadm-basic.images文件夹for x in $(cat /opt/data/list.txt) dodocker load -i $x done循环list.txt中的文件,
docker load -i $x添加到docker中。
初始化主节点
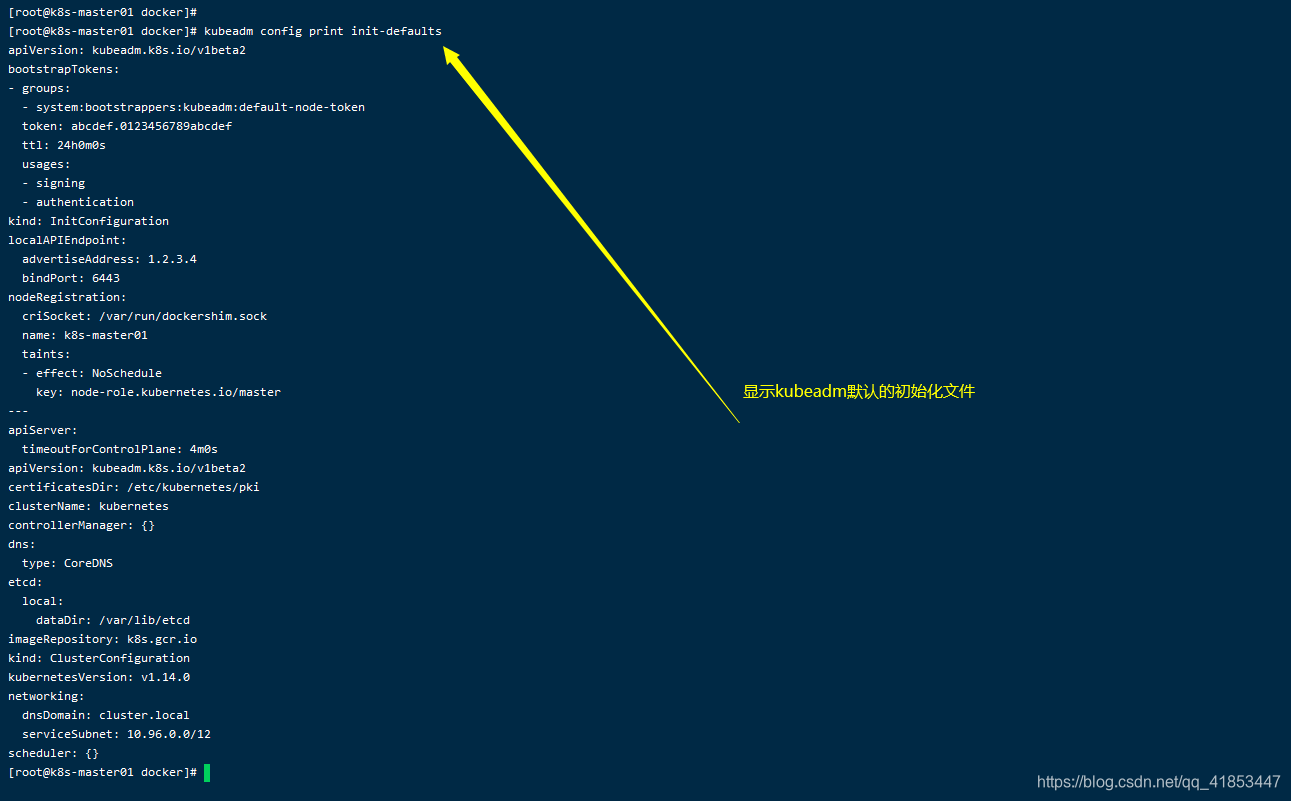
- 将kubeadm默认的初始化文件复制到
kubeadm-config.yaml文件中
kubeadm config print init-defaults > /opt/data/kubeadm-config.yaml
kubeadm config print init-defaults:显示kubeadm默认的初始化文件。
kubeadm config print init-defaults > /opt/data/kubeadm-config.yam: 将kubeadm:默认的初始化文件打印到kubeadm-config.yam文件中。
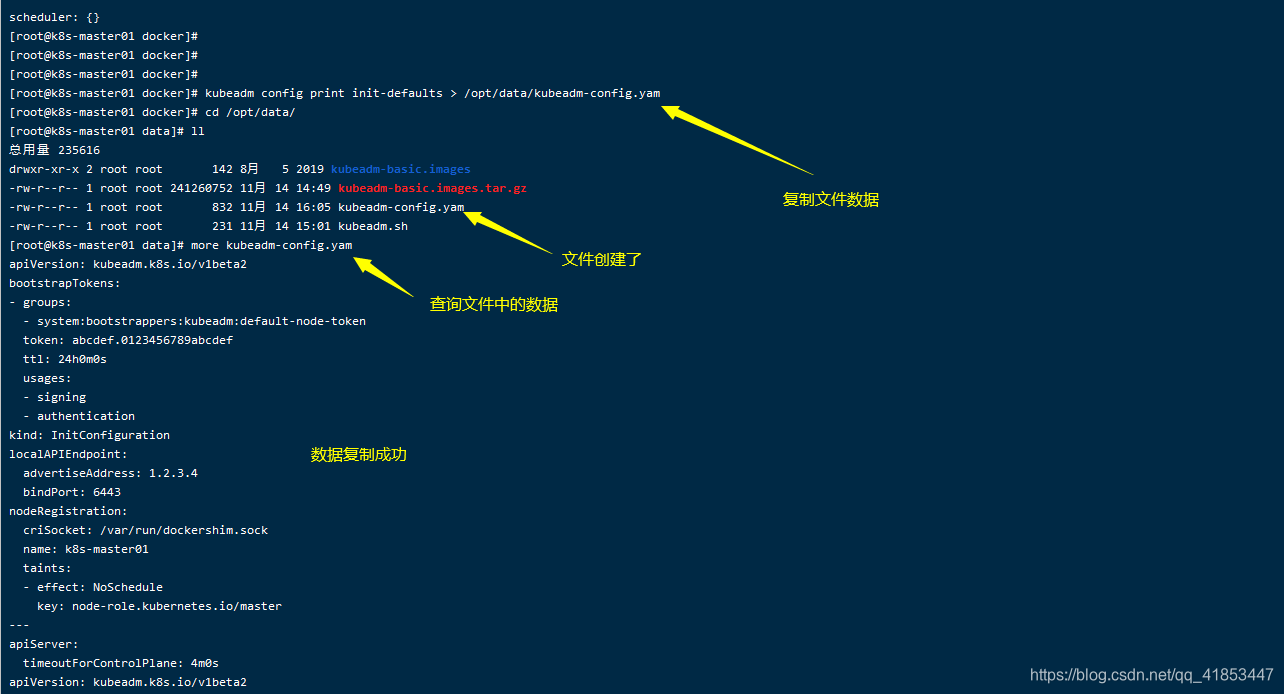
注意:上面截图中将 kubeadm-config.yaml文件后缀写成 yam了,少了 l,需要注意一下。
- 更改
kubeadm-config.yaml文件
需要更改一下配置,注意:这里读语法很讲究,直接使用vim命令更改,注意缩进不要使用tab键,使用空格。
advertiseAddress: 192.168.22.132 # 当前服务器节点地址 (当前服务器的IP地址)
kubernetesVersion: v1.15.1 # 版本号 podSubnet: "10.244.0.0/16" # Pod 网段
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:SupportIPVSProxyMode: true
mode: ipvs # 默认的调度模式更改为ipvs模式
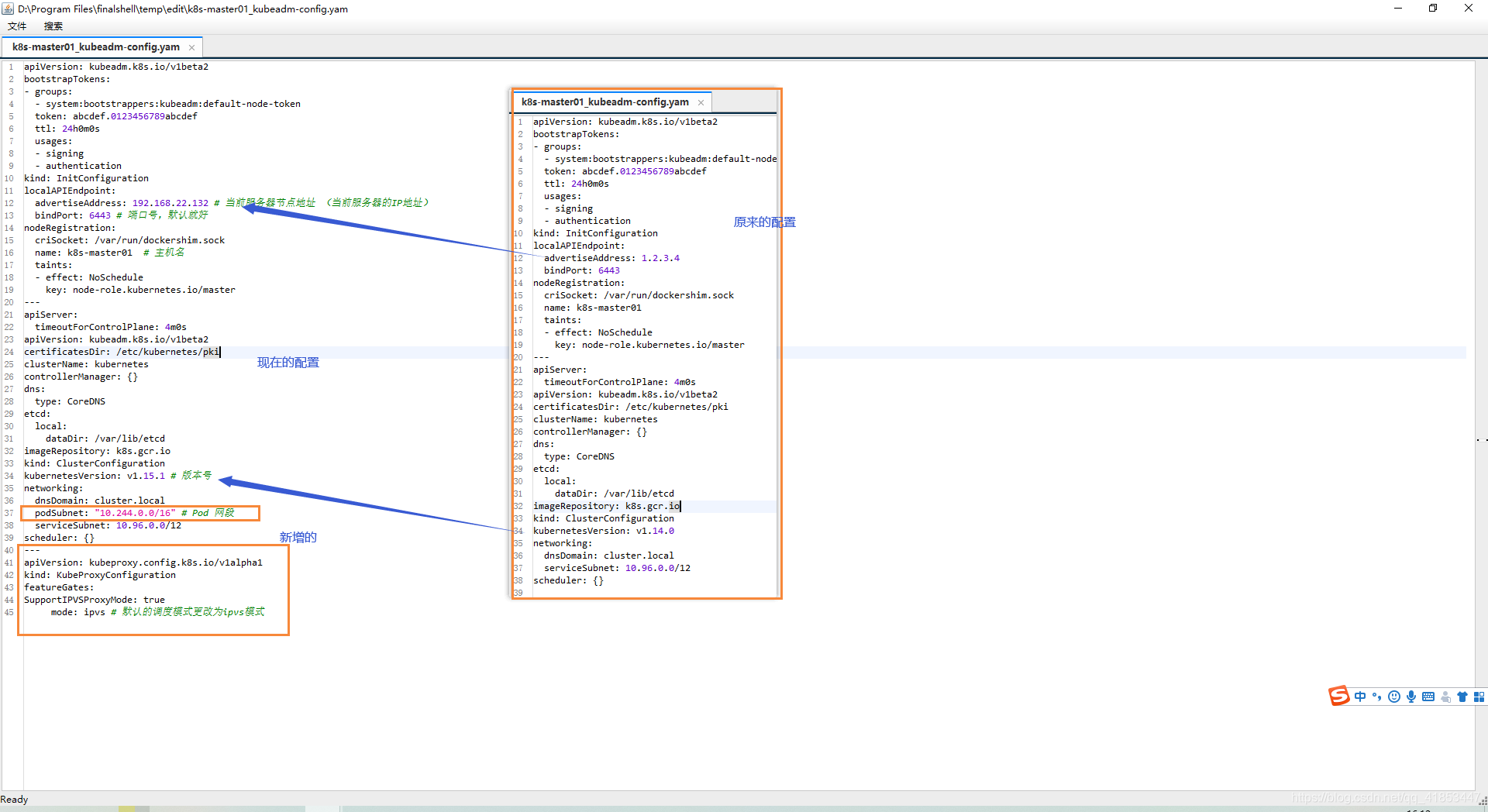
全部配置
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:- system:bootstrappers:kubeadm:default-node-tokentoken: abcdef.0123456789abcdefttl: 24h0m0susages:- signing- authentication
kind: InitConfiguration
localAPIEndpoint:advertiseAddress: 192.168.22.132 # 当前服务器节点地址 (当前服务器的IP地址)bindPort: 6443 # 端口号,默认就好
nodeRegistration:criSocket: /var/run/dockershim.sockname: k8s-master01 # 主机名taints:- effect: NoSchedulekey: node-role.kubernetes.io/master
---
apiServer:timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:type: CoreDNS
etcd:local:dataDir: /var/lib/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kubernetesVersion: v1.15.1 # 版本号
networking:dnsDomain: cluster.localpodSubnet: "10.244.0.0/16" # Pod 网段serviceSubnet: 10.96.0.0/12
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:SupportIPVSProxyMode: true
mode: ipvs # 默认的调度模式更改为ipvs模式
- 开始安装kubeadm
kubeadm init --config=/opt/data/kubeadm-config.yaml --experimental-upload-certs | tee /opt/data/kubeadm-init.log
kubeadm init --config=/opt/data/kubeadm-config.yaml:指定从/opt/data/kubeadm-config.yaml文件初始化安装。
experimental-upload-certs: 在高可用的节点下自动颁发证书。
tee kubeadm-init.log: 将日志问价写入到kubeadm-init.log文件中。
初始化节点遇到的问
执行这条命令后会报一下异常,好像是版本升级导致的,需要将
--experimental-upload-certs替换为--upload-certs。
上面这种方式是没有问题的,下面这种方式创建出来有些配置文件没有,并且连
kubeadm-init.log日志文件都是加密的,所以不要使用下面这种方式,这里写出来说明这个坑已经踩过了。# 这种方式不使用 kubeadm init --config=/opt/data/kubeadm-config.yaml --upload-certs | tee /opt/data/kubeadm-init.log

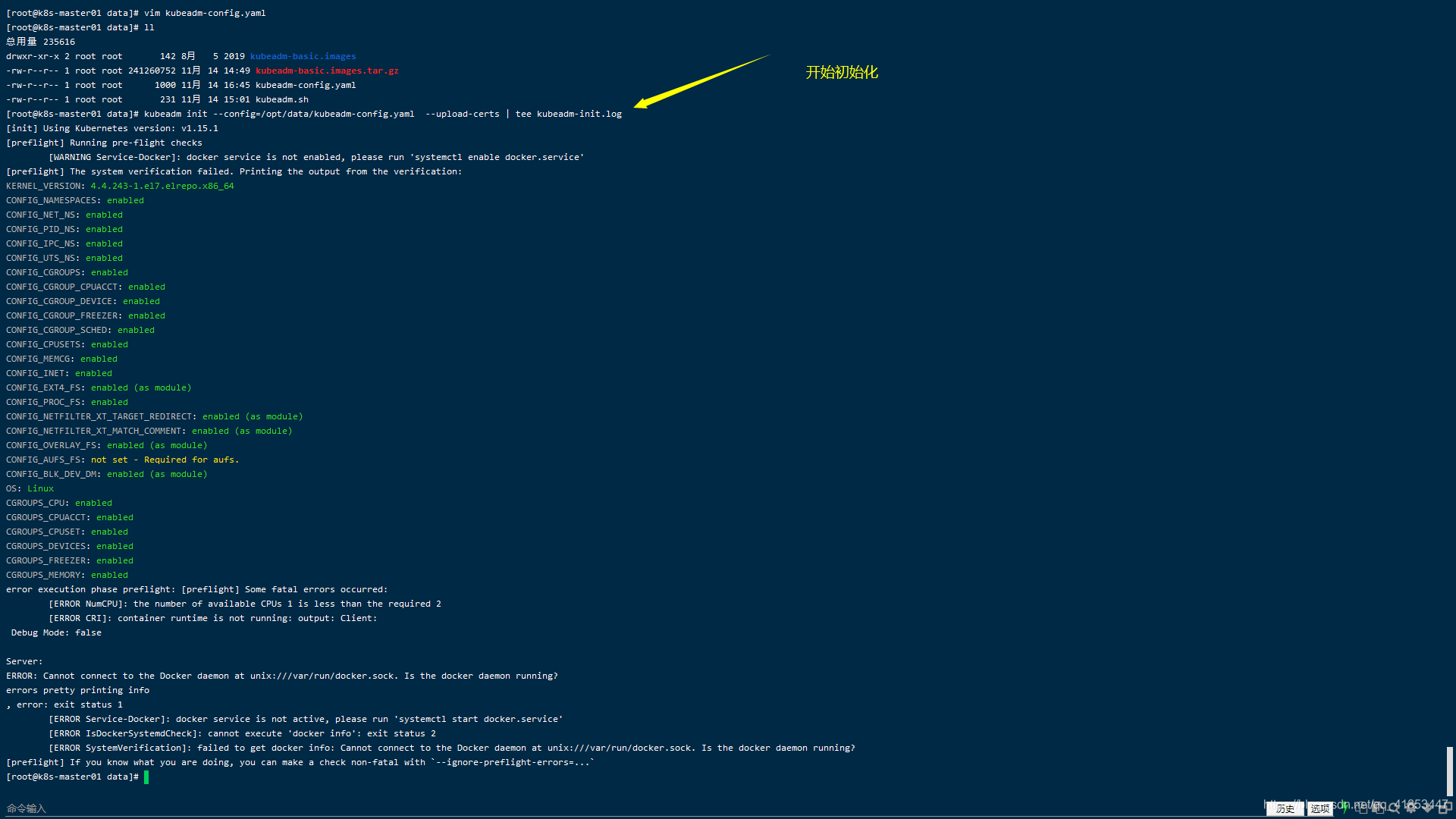
- kubeadm与docker版本不支持
- CPU数量少于2
第一次启动失败,第二次启动包端口等信息被占用
问题解决
kubeadm reset # 重启kubeadm


初始化后的日志分析
日志已经输出到 /opt/data/kubeadm-init.log文件中了,所以直接到这个文件中查看。
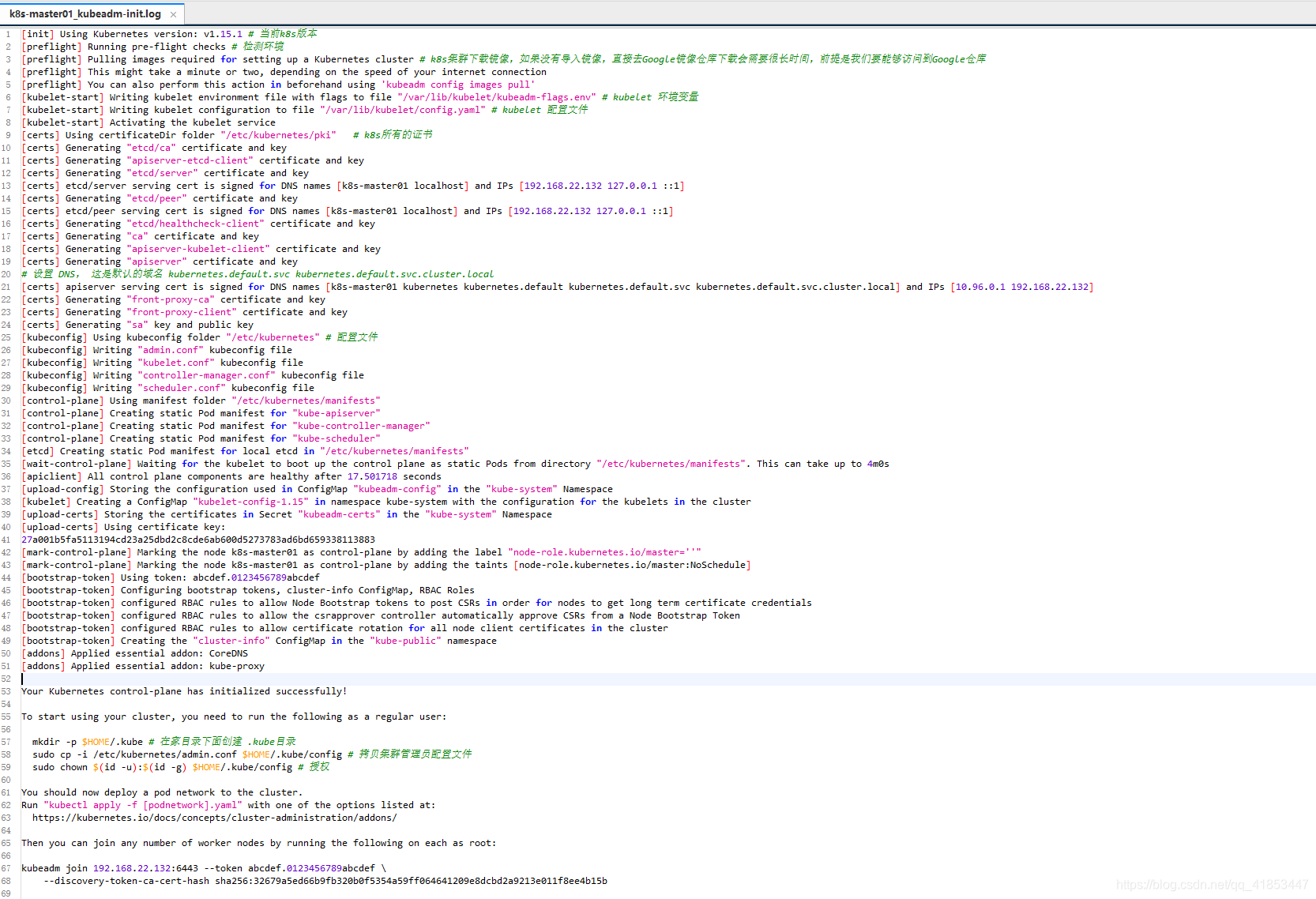
- 需要执行以下操作
这些命令都在日志文件底部
mkdir -p $HOME/.kube # 在家目录下面创建 .kube目录
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config # 拷贝集群管理员配置文件
sudo chown $(id -u):$(id -g) $HOME/.kube/config # 授权
- 查询当前节点
kubectl get node

状态为NotReady(不可用),因为k8s要求有一个扁平化的网络存在,所以需要构建flannel网路插件。
部署flannel网路插件
https://www.cnblogs.com/xiao987334176/p/12696740.html
https://www.cnblogs.com/devilwind/p/8880677.html
- 创建
flannel目录保存kube-flannel.yml文件,因为flannel是基于yml文件创建的。
mkdir -p /opt/data/flannel
- 下载
kube-flannel.yml到/opt/data/flannel目录中
cd /opt/data/flannel # 进入/opt/data/flannel目录wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
如果wget命令不存在,安装 yum -y install wget。
执行安装日志中的加入命令即可
部署网络
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
4.3、Harbor - 企业级 Docker 私有仓库
官网:https://goharbor.io
安装底层需求
-
Python应该是应该是2.7或更高版本
-
Docker引擎应为引擎应为1.10或更高版本
-
Docker Compose需要为需要为1.6.0或更高版本
-
docker-compose
curl -L https://github.com/docker/compose/releases/download/1.9.0/docker-compose-`uname -s`-`uname -m`> /usr/local/bin/docker-compose
Harbor 安装
Harbor 官方地址:https://github.com/vmware/harbor/releases
解压软件包:
tar xvf harbor-offline-installer-<version>.tgz
https://github.com/vmware/harbor/releases/download/v1.2.0/harbor-offline-installer-v1.2.0.tgz
配置harbor.cfg
- 必选参数
hostname:目标的主机名或者完全限定域名
ui_url_protocol:http或https,默认为http
db_password:用于db_auth的MySQL数据库的根密码。更改此密码进行任何生产用途。
max_job_workers:(默认值为3)作业服务中的复制工作人员的最大数量。对于每个映像复制作业,作业服务中的复制工作人员的最大数量。对于每个映像复制作业,工作人员将存储库的所有标签同步到远程目标。增加此数字允许系统中更多的并发复制作业。但是,由于每个工工作人员将存储库的所有标签同步到远程目标。增加此数字允许系统中更多的并发复制作业。但是,由于每个工作人员都会消耗一定数量的网络作人员都会消耗一定数量的网络/ CPU / IO资源,请根据主机的硬件资源,仔细选择该属性的值资源,请根据主机的硬件资源,仔细选择
九、Kubernetes Service
9.1、Service 的概念
Kubernetes Service定义了这样一种抽象:一个Pod的逻辑分组,一种可以访问它们的策略 —— 通常称为微服务。这一组Pod能够被Service访问到,通常是通过Label Selector。
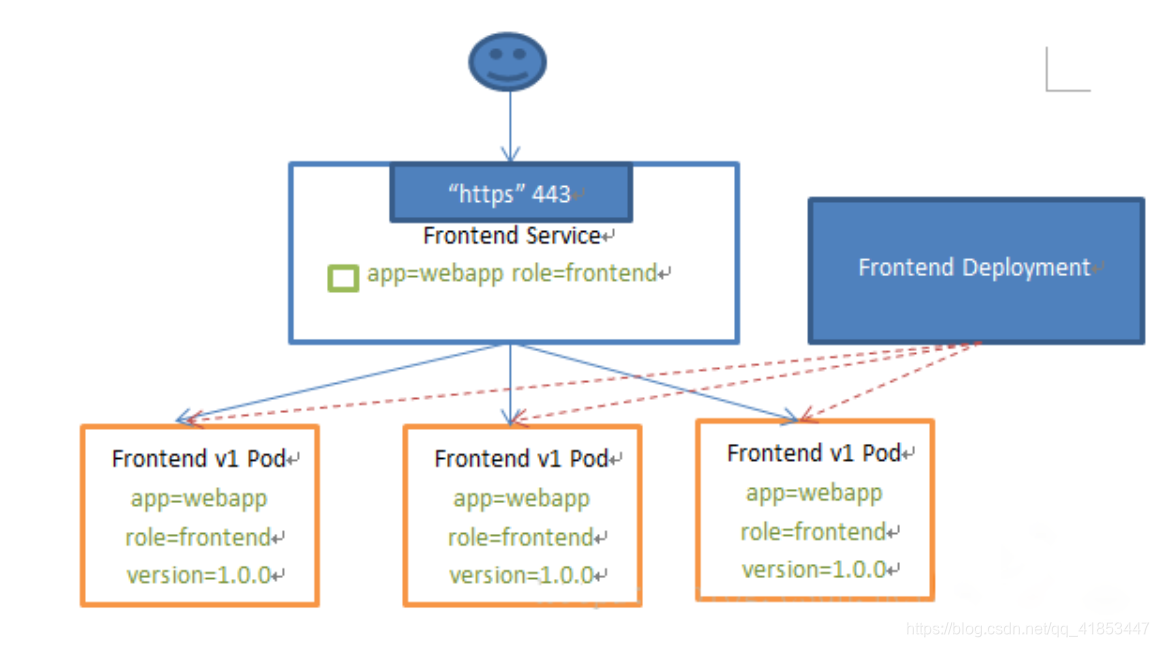
Service能够提供负载均衡的能力,但是在使用上有以下限制:
- 只提供 4 层负载均衡能力,而没有 7 层功能,但有时我们可能需要更多的匹配规则来转发请求,这点上 4 层负载均衡是不支持的
9.2、Service 的类型
Service 在 K8s 中有以下四种类型
- ClusterIp:默认类型,自动分配一个仅 Cluster 内部可以访问的虚拟 IP
- NodePort:在 ClusterIP 基础上为 Service 在每台机器上绑定一个端口,这样就可以通过: NodePort 来访问该服务
- LoadBalancer:在 NodePort 的基础上,借助 cloud provider 创建一个外部负载均衡器,并将请求转发到: NodePort
- ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这只有 kubernetes 1.7 或更高版本的 kube-dns 才支持

VIP 和 Service 代理
在 Kubernetes 集群中,每个 Node 运行一个kube-proxy进程。kube-proxy负责为Service实现了一种VIP(虚拟 IP)的形式,而不是ExternalName的形式。在 Kubernetes v1.0 版本,代理完全在 userspace。在Kubernetes v1.1 版本,新增了 iptables 代理,但并不是默认的运行模式。从 Kubernetes v1.2 起,默认就是iptables 代理。在 Kubernetes v1.8.0-beta.0 中,添加了 ipvs 代理。
在 Kubernetes 1.14 版本开始默认使用ipvs 代理。
在 Kubernetes v1.0 版本,Service是 “4层”(TCP/UDP over IP)概念。在 Kubernetes v1.1 版本,新增了Ingress API(beta 版),用来表示 “7层”(HTTP)服务。
!为何不使用 round-robin DNS?
9.3、代理模式的分类
userspace 代理模式

iptables 代理模式

ipvs 代理模式
这种模式,kube-proxy 会监视 Kubernetes Service对象和Endpoints,调用netlink接口以相应地创建ipvs 规则并定期与 Kubernetes Service对象和Endpoints对象同步 ipvs 规则,以确保 ipvs 状态与期望一致。访问服务时,流量将被重定向到其中一个后端 Pod。
与 iptables 类似,ipvs 于 netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着 ipvs 可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs 为负载均衡算法提供了更多选项,例如:
- rr:轮询调度
- lc:最小连接数
- dh:目标哈希
- sh:源哈希
- sed:最短期望延迟
- nq:不排队调度
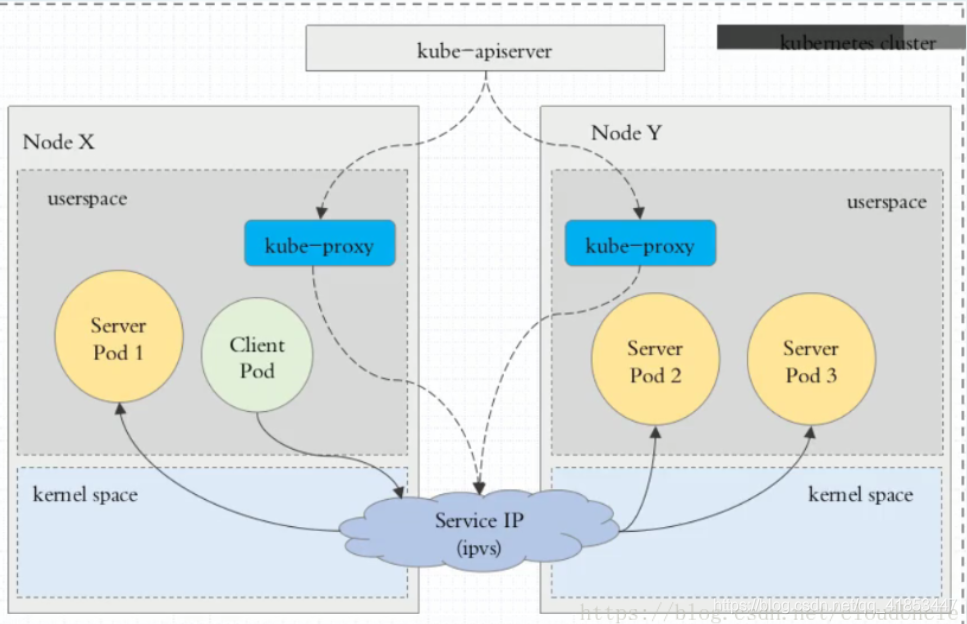
ClusterIP
clusterIP 主要在每个 node 节点使用 iptables,将发向 clusterIP 对应端口的数据,转发到 kube-proxy 中。然后 kube-proxy 自己内部实现有负载均衡的方法,并可以查询到这个 service 下对应 pod 的地址和端口,进而把数据转发给对应的 pod 的地址和端口。

为了实现图上的功能,主要需要以下几个组件的协同工作:
- apiserver 用户通过kubectl命令向apiserver发送创建service的命令,apiserver接收到请求后将数据存储到etcd中
- kube-proxy kubernetes的每个节点中都有一个叫做kube-porxy的进程,这个进程负责感知service,pod的变化,并将变化的信息写入本地的iptables规则中
- iptables 使用NAT等技术将virtualIP的流量转至endpoint中
创建 myapp-deploy.yaml 文件


创建 Service 信息
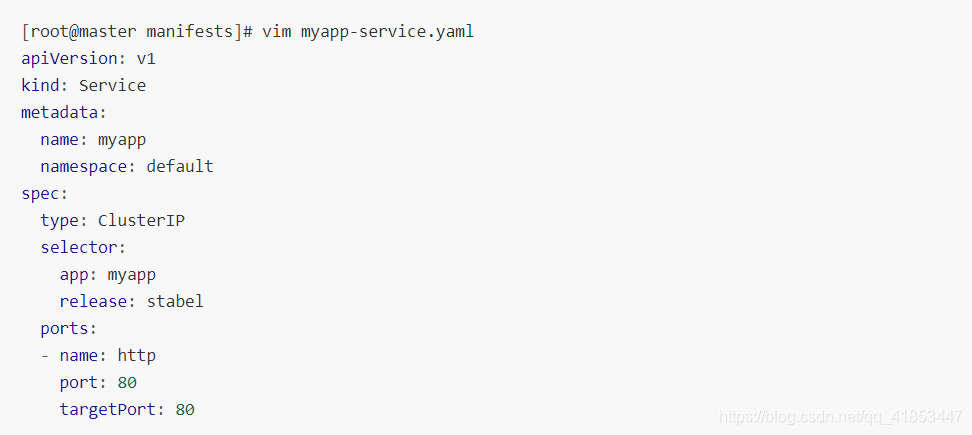
9.4、Headless Service
有时不需要或不想要负载均衡,以及单独的 Service IP 。遇到这种情况,可以通过指定 ClusterIP(spec.clusterIP) 的值为 “None” 来创建 Headless Service 。这类 Service 并不会分配 Cluster IP, kube-proxy 不会处理它们,而且平台也不会为它们进行负载均衡和路由。

9.5、NodePort
nodePort 的原理在于在 node 上开了一个端口,将向该端口的流量导入到 kube-proxy,然后由 kube-proxy 进一步到给对应的 pod

查询流程
iptables -t nat -nvLKUBE-NODEPORTS
9.6、LoadBalancer
loadBalancer 和 nodePort 其实是同一种方式。区别在于 loadBalancer 比 nodePort 多了一步,就是可以调用cloud provider 去创建 LB 来向节点导流

9.7、ExternalName
这种类型的 Service 通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容( 例如:hub.atguigu.com )。ExternalName Service 是 Service 的特例,它没有 selector,也没有定义任何的端口和Endpoint。相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。

当查询主机 my-service.defalut.svc.cluster.local ( SVC_NAME.NAMESPACE.svc.cluster.local )时,集群的DNS 服务将返回一个值 my.database.example.com 的 CNAME 记录。访问这个服务的工作方式和其他的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发。
十、Kubernetes Ingress
10.1、资料信息
Ingress-Nginx github 地址:https://github.com/kubernetes/ingress-nginx
Ingress-Nginx 官方网站:https://kubernetes.github.io/ingress-nginx


10.2、部署 Ingress-Nginx
kubectl apply -f mandatory.yaml
kubectl apply -f service-nodeport.yaml
Ingress HTTP 代理访问
deployment、Service、Ingress Yaml 文件

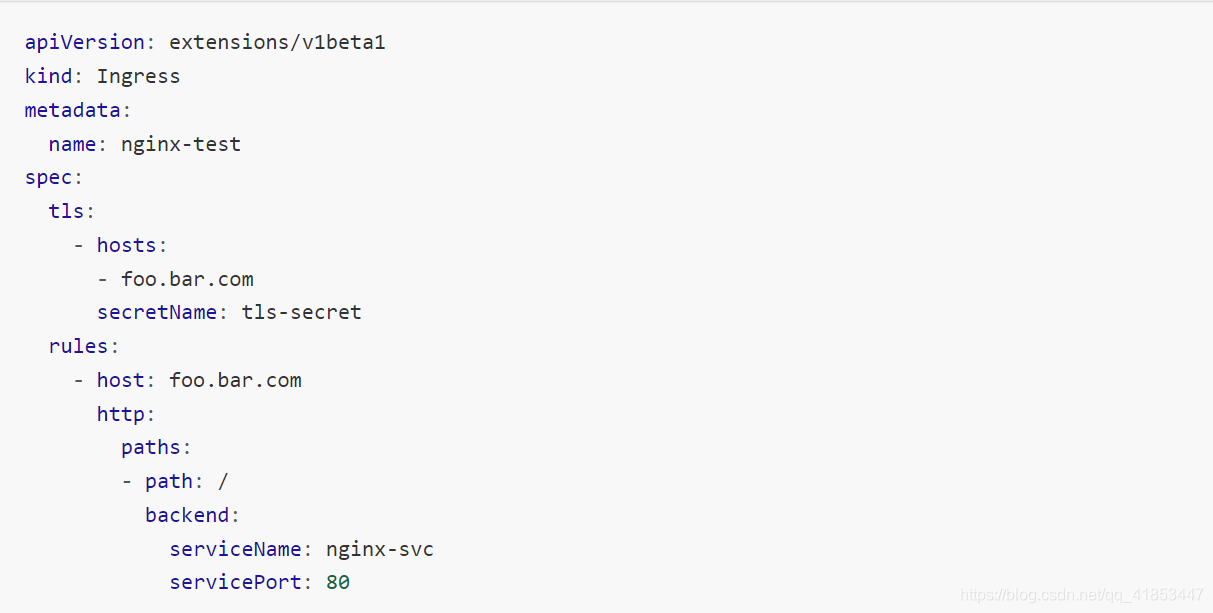
10.3、Ingress HTTPS 代理访问
创建证书,以及 cert 存储方式。
openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj"/CN=nginxsvc/O=nginxsvc"kubectl create secret tls tls-secret --key tls.key --cert tls.crt
deployment、Service、Ingress Yaml 文件
10.4、Nginx 进行 BasicAuth
yum -y install httpd
htpasswd -c auth foo
kubectl create secret generic basic-auth --from-file=auth
10.5、Nginx 进行重写
| 名称 | 描述 | 值 |
|---|---|---|
| nginx.ingress.kubernetes.io/rewrite-target | 必须重定向流量的目标URI | 字符串 |
| nginx.ingress.kubernetes.io/ssl-redirect | 指示位置部分是否仅可访问SSL(当Ingress包含证书时默认为True) | 布尔 |
| nginx.ingress.kubernetes.io/force-ssl-redirect | 即使Ingress未启用TLS,也强制重定向到HTTPS | 布尔 |
| nginx.ingress.kubernetes.io/app-root | 定义Controller必须重定向的应用程序根,如果它在’/'上下文中 | 字符串 |
| nginx.ingress.kubernetes.io/use-regex | 指示Ingress上定义的路径是否使用正则表达式 | 布尔 |

十一、Kubernetes - configMap
11.1、configMap 描述信息
ConfigMap 功能在 Kubernetes1.2 版本中引入,许多应用程序会从配置文件、命令行参数或环境变量中读取配置信息。ConfigMap API 给我们提供了向容器中注入配置信息的机制,ConfigMap 可以被用来保存单个属性,也可以用来保存整个配置文件或者 JSON 二进制大对象。
11.2、ConfigMap 的创建
用目录创建
$ ls docs/user-guide/configmap/kubectl/
game.properties
ui.properties$ cat docs/user-guide/configmap/kubectl/game.propertiese
nemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30$ cat docs/user-guide/configmap/kubectl/ui.propertie
scolor.good=purple
color.bad=yellowallow.textmode=true
how.nice.to.look=fairlyNice$ kubectl create configmap game-config --from-file=docs/user-guide/configmap/kubectl
—from-file指定在目录下的所有文件都会被用在 ConfigMap 里面创建一个键值对,键的名字就是文件名,值就是文件的内容。
使用文件创建
只要指定为一个文件就可以从单个文件中创建 ConfigMap
$ kubectl create configmap game-config-2 --from-file=docs/user-guide/configmap/kubectl/game.properties$ kubectlget configmaps game-config-2 -o yaml
—from-file这个参数可以使用多次,你可以使用两次分别指定上个实例中的那两个配置文件,效果就跟指定整个目录是一样的。
使用字面值创建
使用文字值创建,利用—from-literal参数传递配置信息,该参数可以使用多次,格式如下。
$ kubectl create configmap special-config --from-literal=special.how=very --from-literal=special.type=charm
$ kubectlget configmaps special-config -o yaml
11.3、Pod 中使用 ConfigMap
使用 ConfigMap 来替代环境变量
用 ConfigMap 设置命令行参数
通过数据卷插件使用ConfigMap
在数据卷里面使用这个 ConfigMap,有不同的选项。最基本的就是将文件填入数据卷,在这个文件中,键就是文件名,键值就是文件内容
11.4、ConfigMap 的热更新
- 修改 ConfigMap
$ kubectl edit configmap log-config
- 修改log_level的值为DEBUG等待大概 10 秒钟时间,再次查看环境变量的值
$ kubectl exec `kubectl get pods -l run=my-nginx -o=name|cut -d "/" -f2`cat /tmp/log_levelDEBUG
- ConfigMap 更新后滚动更新 Pod
更新 ConfigMap 目前并不会触发相关 Pod 的滚动更新,可以通过修改 pod annotations 的方式强制触发滚动更新。
$ kubectl patch deployment my-nginx --patch'{"spec": {"template": {"metadata": {"annotations":{"version/config": "20190411" }}}}}'
这个例子里我们在.spec.template.metadata.annotations中添加version/config,每次通过修改version/config来触发滚动更新。
!!!更新 ConfigMap 后:
- 使用该 ConfigMap 挂载的 Env 不会同步更新
- 使用该 ConfigMap 挂载的 Volume 中的数据需要一段时间(实测大概10秒)才能同步更新
十二、Kubernetes - Secret
12.1、Secret 存在意义
Secret 解决了密码、token、密钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者 Pod Spec中。Secret 可以以 Volume 或者环境变量的方式使用。
Secret 有三种类型:
- Service Account:用来访问 Kubernetes API,由 Kubernetes 自动创建,并且会自动挂载到 Pod 的/run/secrets/kubernetes.io/serviceaccount目录中。
- Opaque:base64编码格式的Secret,用来存储密码、密钥等
- kubernetes.io/dockerconfigjson:用来存储私有 docker registry 的认证信息
12.2、Service Account
Service Account
用来访问 Kubernetes API,由 Kubernetes 自动创建,并且会自动挂载到 Pod的/run/secrets/kubernetes.io/serviceaccount目录中。
$ kubectl run nginx --image nginxdeployment "nginx" created
$ kubectlget podsNAME READY STATUS RESTARTS AGEnginx-3137573019-md1u2 1/1 Running 0 13s
$ kubectl exec nginx-3137573019-md1u2 ls /run/secrets/kubernetes.io/serviceaccount
namespace
token
Opaque Secret
建说明
Opaque 类型的数据是一个 map 类型,要求 value 是 base64 编码格式:
$ echo-n"admin" | base64
YWRtaW4=
$ echo-n"1f2d1e2e67df" | base64
MWYyZDFlMmU2N2Rm
secrets.yml
apiVersion: v1
kind: Secret
metadata:name: mysecret
type: Opaque
data: password: MWYyZDFlMmU2N2Rmusername: YWRtaW4=
使用方式
- 将 Secret 挂载到 Volume 中

- 将 Secret 导出到环境变量中


kubernetes.io/dockerconfigjson
使用 Kuberctl 创建 docker registry 认证的 secret
$ kubectl create secret docker-registry myregistrykey --docker-server=DOCKER_REGISTRY_SERVER --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD --docker-email=DOCKER_EMAILsecret "myregistrykey" created.
在创建 Pod 的时候,通过imagePullSecrets来引用刚创建的 myregistrykey
apiVersion: v1
kind: Pod
metadata: name: foo
spec: containers:- name: fooimage: roc/awangyang:v1imagePullSecrets :- name: myregistrykey
十三、Kubernetes - volume
容器磁盘上的文件的生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。首先,当容器崩溃时,kubelet 会重启它,但是容器中的文件将丢失——容器以干净的状态(镜像最初的状态)重新启动。其次,在Pod中同时运行多个容器时,这些容器之间通常需要共享文件。Kubernetes 中的Volume抽象就很好的解决了这些问题。
13.1、背景
Kubernetes 中的卷有明确的寿命 —— 与封装它的 Pod 相同。所f以,卷的生命比 Pod 中的所有容器都长,当这个容器重启时数据仍然得以保存。当然,当 Pod 不再存在时,卷也将不复存在。也许更重要的是,Kubernetes支持多种类型的卷,Pod 可以同时使用任意数量的卷
13.2、卷的类型
Kubernetes 支持以下类型的卷:
-
awsElasticBlockStoreazureDiskazureFilecephfscsidownwardAPIemptyDir -
fcflockergcePersistentDiskgitRepoglusterfshostPathiscsilocalnfs -
persistentVolumeClaimprojectedportworxVolumequobyterbdscaleIOsecret -
storageosvsphereVolume
13.3、emptyDir
当 Pod 被分配给节点时,首先创建emptyDir卷,并且只要该 Pod 在该节点上运行,该卷就会存在。正如卷的名字所述,它最初是空的。Pod 中的容器可以读取和写入emptyDir卷中的相同文件,尽管该卷可以挂载到每个容器中的相同或不同路径上。当出于任何原因从节点中删除 Pod 时,emptyDir中的数据将被永久删除。
emptyDir的用法有:
- 暂存空间,例如用于基于磁盘的合并排序。
- 用作长时间计算崩溃恢复时的检查点。
- Web服务器容器提供数据时,保存内容管理器容器提取的文件。

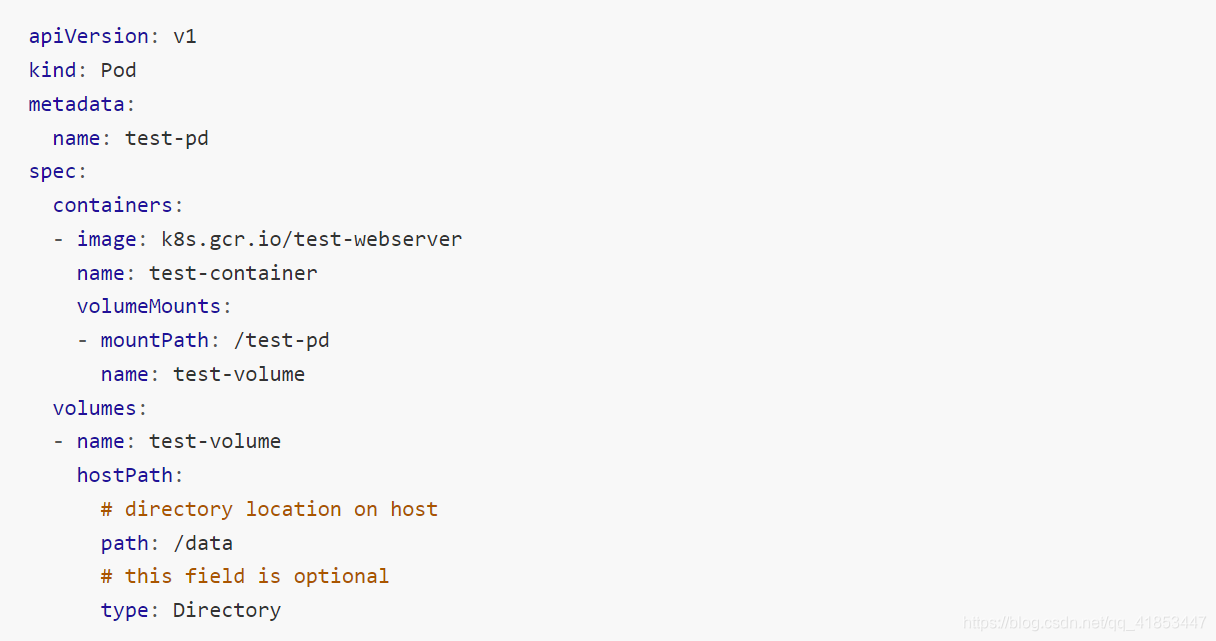
13.4、hostPath
hostPath卷将主机节点的文件系统中的文件或目录挂载到集群中
hostPath的用途如下:
- 运行需要访问 Docker 内部的容器;使用/var/lib/docker的hostPath
- 在容器中运行 cAdvisor;使用/dev/cgroups的hostPath
- 允许 pod 指定给定的 hostPath 是否应该在 pod 运行之前存在,是否应该创建,以及它应该以什么形式存在
除了所需的path属性之外,用户还可以为hostPath卷指定type
| 值 | 行为 |
|---|---|
| 空字符串(默认)用于向后兼容,这意味着在挂载 hostPath 卷之前不会执行任何检查。 | |
DirectoryOrCreate | 如果在给定的路径上没有任何东西存在,那么将根据需要在那里创建一个空目录,权限设置为 0755,与 Kubelet 具有相同的组和所有权。 |
Directory | 给定的路径下必须存在目录 |
FileOrCreate | 如果在给定的路径上没有任何东西存在,那么会根据需要创建一个空文件,权限设置为 0644,与 Kubelet 具有相同的组和所有权。 |
File | 给定的路径下必须存在文件 |
Socket | 给定的路径下必须存在 UNIX 套接字 |
CharDevice | 给定的路径下必须存在字符设备 |
BlockDevice | 给定的路径下必须存在块设备 |
使用这种卷类型是请注意,因为:
-
由于每个节点上的文件都不同,具有相同配置(例如从 podTemplate 创建的)的 pod 在不同节点上的行为可能会有所不同
-
当 Kubernetes 按照计划添加资源感知调度时,将无法考虑hostPath使用的资源。
-
在底层主机上创建的文件或目录只能由 root 写入。您需要在特权容器中以 root 身份运行进程,或修改主机上的文件权限以便写入hostPath卷。
十四、Kubernetes - Persistent Volume
14.1、概念
PersistentVolume(PV)
是由管理员设置的存储,它是群集的一部分。就像节点是集群中的资源一样,PV 也是集群中的资源。 PV 是Volume 之类的卷插件,但具有独立于使用 PV 的 Pod 的生命周期。此 API 对象包含存储实现的细节,即 NFS、iSCSI 或特定于云供应商的存储系统。
PersistentVolumeClaim(PVC)
是用户存储的请求。它与 Pod 相似。Pod 消耗节点资源,PVC 消耗 PV 资源。Pod 可以请求特定级别的资源(CPU 和内存)。声明可以请求特定的大小和访问模式(例如,可以以读/写一次或只读多次模式挂载)。
静态 pv
集群管理员创建一些 PV。它们带有可供群集用户使用的实际存储的细节。它们存在于 Kubernetes API 中,可用于消费
动态
当管理员创建的静态 PV 都不匹配用户的PersistentVolumeClaim时,集群可能会尝试动态地为 PVC 创建卷。此配置基于StorageClasses:PVC 必须请求 [存储类],并且管理员必须创建并配置该类才能进行动态创建。声明该类为""可以有效地禁用其动态配置
要启用基于存储级别的动态存储配置,集群管理员需要启用 API server 上的DefaultStorageClass[准入控制器]。例如,通过确保DefaultStorageClass位于 API server 组件的–admission-control标志,使用逗号分隔的有序值列表中,可以完成此操作
绑定
master 中的控制环路监视新的 PVC,寻找匹配的 PV(如果可能),并将它们绑定在一起。如果为新的 PVC 动态调配 PV,则该环路将始终将该 PV 绑定到 PVC。否则,用户总会得到他们所请求的存储,但是容量可能超出要求的数量。一旦 PV 和 PVC 绑定后,PersistentVolumeClaim绑定是排他性的,不管它们是如何绑定的。 PVC 跟PV 绑定是一对一的映射
持久化卷声明的保护
PVC 保护的目的是确保由 pod 正在使用的 PVC 不会从系统中移除,因为如果被移除的话可能会导致数据丢失当启用PVC 保护 alpha 功能时,如果用户删除了一个 pod 正在使用的 PVC,则该 PVC 不会被立即删除。PVC 的删除将被推迟,直到 PVC 不再被任何 pod 使用。
持久化卷类型
PersistentVolume类型以插件形式实现。Kubernetes 目前支持以下插件类型:
GCEPersistentDiskAWSElasticBlockStoreAzureFileAzureDiskFC (Fibre Channel)。FlexVolumeFlockerNFSiSCSIRBD (Ceph Block Device)CephFS。Cinder (OpenStack block storage)GlusterfsVsphereVolumeQuobyteVolumes。HostPathVMwarePhotonPortworxVolumesScaleIOVolumesStorageOS。
持久卷演示代码
PV 访问模式
PersistentVolume可以以资源提供者支持的任何方式挂载到主机上。如下表所示,供应商具有不同的功能,每个PV 的访问模式都将被设置为该卷支持的特定模式。例如,NFS 可以支持多个读/写客户端,但特定的 NFS PV 可能以只读方式导出到服务器上。每个 PV 都有一套自己的用来描述特定功能的访问模式。
- ReadWriteOnce——该卷可以被单个节点以读/写模式挂载
- ReadOnlyMany——该卷可以被多个节点以只读模式挂载
- ReadWriteMany——该卷可以被多个节点以读/写模式挂载
在命令行中,访问模式缩写为:
- RWO - ReadWriteOnce
- ROX - ReadOnlyMany
- RWX - ReadWriteMany
| Volume 插件 | ReadWriteOnce | ReadOnlyMany | ReadWriteMany |
|---|---|---|---|
| AWSElasticBlockStoreAWSElasticBlockStore | √ | - | - |
| AzureFile | √ | √ | √ |
| AzureDisk | √ | - | - |
| CephFS | √ | √ | √ |
| Cinder | √ | - | - |
| FC | √ | √ | - |
| FlexVolume | √ | √ | - |
| Flocker | √ | - | - |
| GCEPersistentDisk | √ | √ | - |
| Glusterfs | √ | √ | √ |
| HostPath | √ | - | - |
| iSCSI | √ | √ | - |
| PhotonPersistentDisk | √ | - | - |
| Quobyte | √ | √ | √ |
| NFS | √ | √ | √ |
| RBD | √ | √ | - |
| VsphereVolume | √ | - | -(当 pod 并列时有效) |
| PortworxVolume | √ | - | √ |
| ScaleIO | √ | √ | - |
| StorageOS | √ | - | - |
回收策略
- Retain(保留)——手动回收
- Recycle(回收)——基本擦除(rm -rf /thevolume/*)
- Delete(删除)——关联的存储资产(例如 AWS EBS、GCE PD、Azure Disk 和 OpenStack Cinder 卷)将被删除
当前,只有 NFS 和 HostPath 支持回收策略。AWS EBS、GCE PD、Azure Disk 和 Cinder 卷支持删除策略
状态
卷可以处于以下的某种状态:
- Available(可用)——一块空闲资源还没有被任何声明绑定
- Bound(已绑定)——卷已经被声明绑定
- Released(已释放)——声明被删除,但是资源还未被集群重新声明
- Failed(失败)——该卷的自动回收失败
命令行会显示绑定到 PV 的 PVC 的名称
持久化演示说明 - NFS
安装 NFS 服务器
yum install -y nfs-common nfs-utils rpcbind
mkdir /nfsdata
chmod666 /nfsdata
chown nfsnobod y /nfsdatacat /etc/exports/nfsdata *(rw,no_root_squash,no_all_squash,sync)
systemctl start rpcbind
systemctl start nfs
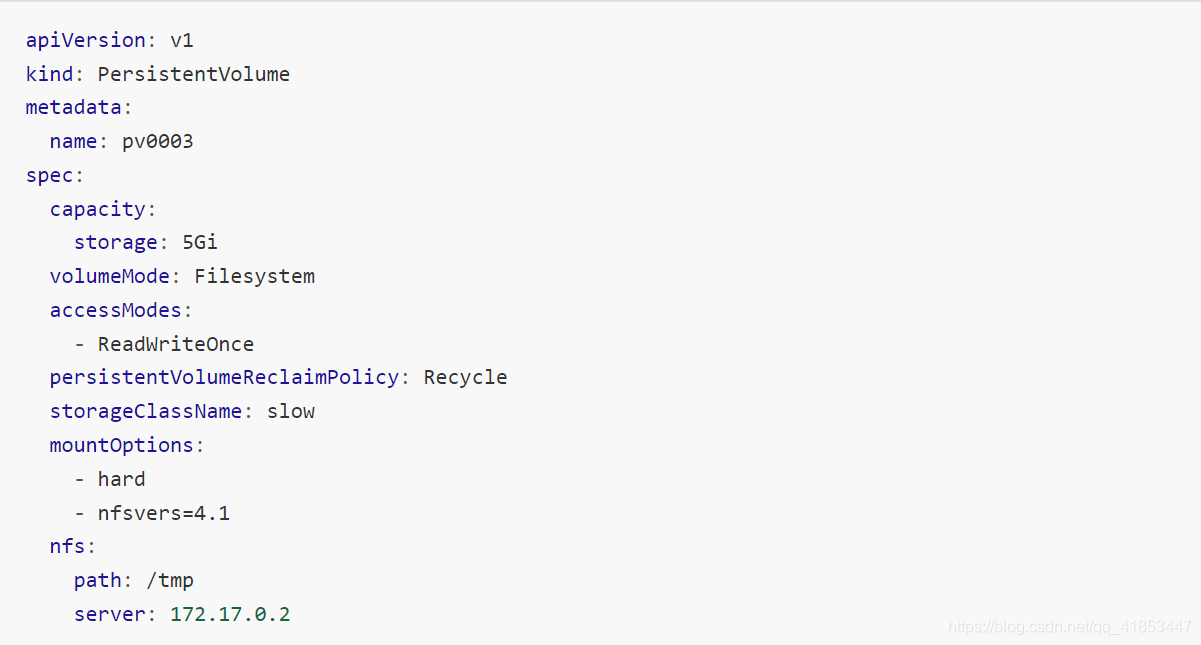
部署 PV
apiVersion: v1
kind: PersistentVolume
metadata: name: nfspv1spec: capacity:storage: 1GiaccessModes:- ReadWriteOnce persistentVolumeReclaimPolicy: RecyclestorageClassName: nfs nfs:path: /data/nfsserver: 10.66.66.10
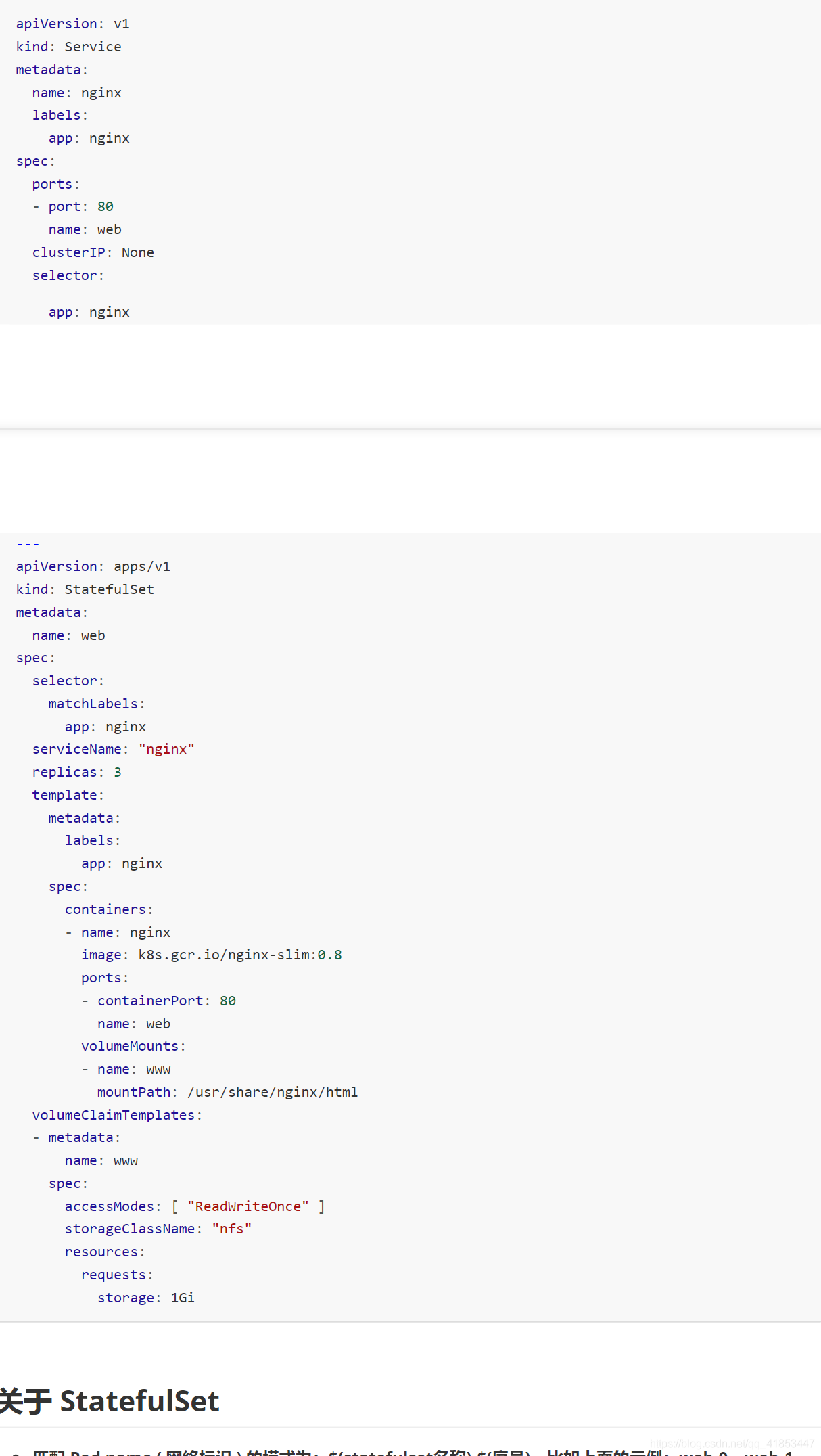
创建服务并使用 PVC
关于 StatefulSet
- 匹配 Pod name ( 网络标识 ) 的模式为: ( s t a t e f u l s e t 名称 ) − (statefulset名称)- (statefulset名称)−(序号),比如上面的示例:web-0,web-1,web-2
- StatefulSet 为每个 Pod 副本创建了一个 DNS 域名,这个域名的格式为: $(podname).(headless servername),也就意味着服务间是通过Pod域名来通信而非 Pod IP,因为当Pod所在Node发生故障时, Pod 会被飘移到其它 Node 上,Pod IP 会发生变化,但是 Pod 域名不会有变化
- StatefulSet 使用 Headless 服务来控制 Pod 的域名,这个域名的 FQDN 为: ( s e r v i c e n a m e ) . (servicename). (servicename).(namespace).svc.cluster.local,其中,“cluster.local” 指的是集群的域名
- 根据 volumeClaimTemplates,为每个 Pod 创建一个 pvc,pvc 的命名规则匹配模式:(volumeClaimTemplates.name)-(pod_name),比如上面的 volumeMounts.name=www, Podname=web-[0-2],因此创建出来的 PVC 是 www-web-0、www-web-1、www-web-2
- 删除 Pod 不会删除其 pvc,手动删除 pvc 将自动释放 pv
Statefulset的启停顺序
- 有序部署:部署StatefulSet时,如果有多个Pod副本,它们会被顺序地创建(从0到N-1)并且,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态。
- 有序删除:当Pod被删除时,它们被终止的顺序是从N-1到0。
- 有序扩展:当对Pod执行扩展操作时,与部署一样,它前面的Pod必须都处于Running和Ready状态。
StatefulSet使用场景:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于 PVC 来实现。
- 稳定的网络标识符,即 Pod 重新调度后其 PodName 和 HostName 不变。
- 有序部署,有序扩展,基于 init containers 来实现。
- 有序收缩。
十五、Kubernetes - 集群调度
15.1、Kubernetes 调度器 - 调度说明
简介
Scheduler 是 kubernetes 的调度器,主要的任务是把定义的 pod 分配到集群的节点上。听起来非常简单,但有
很多要考虑的问题:
- 公平:如何保证每个节点都能被分配资源
- 资源高效利用:集群所有资源最大化被使用
- 效率:调度的性能要好,能够尽快地对大批量的 pod 完成调度工作
- 灵活:允许用户根据自己的需求控制调度的逻辑
Sheduler 是作为单独的程序运行的,启动之后会一直坚挺 API Server,获取 PodSpec.NodeName 为空的 pod,
对每个 pod 都会创建一个 binding,表明该 pod 应该放到哪个节点上
调度过程
调度分为几个部分:首先是过滤掉不满足条件的节点,这个过程称为 predicate ;然后对通过的节点按照优先级
排序,这个是 priority ;最后从中选择优先级最高的节点。如果中间任何一步骤有错误,就直接返回错误。
- Predicate 有一系列的算法可以使用:
- PodFitsResources :节点上剩余的资源是否大于 pod 请求的资源
- PodFitsHost :如果 pod 指定了 NodeName,检查节点名称是否和 NodeName 匹配
- PodFitsHostPorts :节点上已经使用的 port 是否和 pod 申请的 port 冲突
- PodSelectorMatches :过滤掉和 pod 指定的 label 不匹配的节点
- NoDiskConflict :已经 mount 的 volume 和 pod 指定的 volume 不冲突,除非它们都是只读
如果在 predicate 过程中没有合适的节点,pod 会一直在 pending 状态,不断重试调度,直到有节点满足条件。
经过这个步骤,如果有多个节点满足条件,就继续 priorities 过程: 按照优先级大小对节点排序
优先级由一系列键值对组成,键是该优先级项的名称,值是它的权重(该项的重要性)。这些优先级选项包括:
- LeastRequestedPriority :通过计算 CPU 和 Memory 的使用率来决定权重,使用率越低权重越高。换句话
说,这个优先级指标倾向于资源使用比例更低的节点 - BalancedResourceAllocation :节点上 CPU 和 Memory 使用率越接近,权重越高。这个应该和上面的一起
使用,不应该单独使用 - ImageLocalityPriority :倾向于已经有要使用镜像的节点,镜像总大小值越大,权重越高
通过算法对所有的优先级项目和权重进行计算,得出最终的结果
自定义调度器
除了 kubernetes 自带的调度器,你也可以编写自己的调度器。通过 spec:schedulername 参数指定调度器的名
字,可以为 pod 选择某个调度器进行调度。比如下面的 pod 选择 my-scheduler 进行调度,而不是默认的
default-scheduler :
apiVersion: v1
kind: Pod
metadata:name: annotation-second-schedulerlabels:name: multischeduler-example
spec:schedulername: my-schedulercontainers:- name: pod-with-second-annotation-containerimage: gcr.io/google_containers/pause:2.0
15.2、Kubernetes 调度器 - 调度亲和性
节点亲和性
pod.spec.nodeAffinity
- preferredDuringSchedulingIgnoredDuringExecution:软策略
- requiredDuringSchedulingIgnoredDuringExecution:硬策略
requiredDuringSchedulingIgnoredDuringExecution
apiVersion: v1
kind: Pod
metadata:name: affinitylabels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: hub.atguigu.com/library/myapp:v1affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: NotInvalues:- k8s-node02
preferredDuringSchedulingIgnoredDuringExecution
apiVersion: v1
kind: Pod
metadata:name: affinitylabels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: hub.atguigu.com/library/myapp:v1affinity:nodeAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 1preference:matchExpressions:- key: sourceoperator: Invalues:- qikqiak
合体
apiVersion: v1
kind: Pod
metadata:name: affinitylabels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: hub.atguigu.com/library/myapp:v1affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: NotInvalues:- k8s-node02preferredDuringSchedulingIgnoredDuringExecution:- weight: 1preference:matchExpressions:- key: sourceoperator: Invalues:- qikqiak
键值运算关系
- In:label 的值在某个列表中
- NotIn:label 的值不在某个列表中
- Gt:label 的值大于某个值
- Lt:label 的值小于某个值
- Exists:某个 label 存在
- DoesNotExist:某个 label 不存在
Pod 亲和性
- preferredDuringSchedulingIgnoredDuringExecution:软策略
- requiredDuringSchedulingIgnoredDuringExecution:硬策略
apiVersion: v1
kind: Pod
metadata:
name: pod-3
labels:
app: pod-3
spec:
containers:
- name: pod-3
image: hub.atguigu.com/library/myapp:v1
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- pod-1
topologyKey: kubernetes.io/hostname
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- pod-2
topologyKey: kubernetes.io/hostname
亲和性/反亲和性调度策略比较如下:
| 调度策略 | 匹配标签 | 操作符 | 拓扑域支持 | 调度目标 |
|---|---|---|---|---|
| nodeAffinity | 主机 | n, NotIn, Exists,DoesNotExist, Gt, Lt | 否 | 指定主机 |
| podAffinity | Pod | In, NotIn, Exists,DoesNotExist | 是 | POD与指定POD同一拓扑域 |
| podAnitAffinity | Pod | In, NotIn, Exists,DoesNotExist | 是 | POD与指定POD不在同一拓扑域 |



![[linux] dd命令详解](/images/no-images.jpg)