项目简介
- 借助图灵机器人和百度语音识别和合成等第三方平台和第三方工具
- 使用C++编写一个智能AI对话和语音命令执行的语音管理工具
- 除去交流功能之外还可以执行Linux下相关命令,可执行的命令支持自己配置
项目技术点
- C++ STL中主要是map和unorder_map的使用
- 了解http第三方库,使用http中的post接口进行http请求
- 通过图灵机器人API接口将机器人接入Linux平台下
- 百度语音识别和语音合成
- Linux系统/网络编程
- 各种第三方库和第三方工具的安装与使用
项目框架

项目前期准备
准备需要使用的第三方库和sdk
- 因为项目编译需要高版本的gcc,因此我们通过以下命令升级gcc
# sudo yum install centos-release-scl
# sudo yum install devtoolset-6
# scl enable devtoolset-6 bash
但是我在做项目的时候遇到一个比较麻烦的情况就是在电脑关机重启之后gcc的版本又会回到之前未升级的状态,但是经过测试发现此时只需要再执行最后一句命令即可。
- 升级Linux系统下camke版本,通过cmake可以高效率和更简易的管理我们的项目
1、查看当前版本cmake --version
2、下载获得cmake-3.9.2源码 wget https://cmake.org/files/v3.9/cmake-3.9.2.tar.gz
3、解压、安装新版本tar -zxvf cmake-3.9.2.tar.gzcd cmake-3.9.2./configuresudo make && make install
安装camke我遇到了很多困难,首先是下载好cmake源码之后,解压时未将tar命令用对,导致解压出的文件不全,因此在安装时报了很多错误,其次是开始安装时我是在xshell中执行命令安装的,但是多次安装之后依旧找不到camke工具,最后多次测试发现只有到虚拟机下才能查看到cmake工具。
- 下载百度C++语音识别SDK
在 http://ai.baidu.com/sdk 下载,识别、合成 RESTful API C++ SDK,后面的工具,基本都要支持C++11以上,这也就为什么我们要将gcc升级的原因
- 安装jsoncpp,要求:>1.6.2版本,0.x版本将不被支持
在json官网:http://www.json.org/json-zh.html 官网中下载jsoncpp,其实个人更推荐使用 https://github.com/open-source-parsers/jsoncpp/releases 1.8.3版本,因为其他最新版本可能会有中文编码的问题,下载之后依据如下命令安装好
# cd jsoncpp-1.8.3
# make build
# cd build
# cmake ..
# make
# sudo make install
- 安装openssl
# sudo yum install openssl-devel
- 安装libcurl(为之后http请求做准备)
官网:https://curl.haxx.se/download.html
下载curl-7.64.1.tar.gz版本
# tar xzvf curl-7.64.1.tar.gz
# cd curl-7.64.1
# ./configure
# make
# sudo make install
这里需要提到一个Linux底下很好用的命令就是rz命令,但是这个命令在只能xshell中使用,作用就是将Windows下的文件导入虚拟机中,因为我们一般习惯在Windows中下载文件,其他方法将文件导入Linux中都比较麻烦,但是这个命令就很方便。
准备Centos 7的录音工具
- 对于录音工具我们可以使用Linux自带的
arecord -t wav -c 1 -r 16000 -d 5 -f S16_LE demo.wav进行录音,生成wav格式 的文件 - 用
aplay demo.wav可播放对应的语音文件
安装vlc/cvlc播放器
我们在语音合成之后,直接使用aplay播放会有一定问题,我们采用第三方工具vlc/cvlc实现MP3文件播放
# sudo yum -y install epel-release # sudo rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-5.el7.nux.noarch.rpm# sudo yum install vlc -y
当然除了这些准备之外,因为我们要使用图灵机器人,自然应该去注册一个自己的机器人,这个按照平台指示进行即可,值得一提的是必须进行个人认证才能使用该平台的机器人,认证时间大概是三天左右才能通过,接着我们要使用百度ai平台的语音识别和语音合成功能,自然也应该注册百度ai平台,都是一些比较简单的操作。
正式进入编码
这里我想分为三个部分来介绍实现这个项目的代码
- 接入图灵机器人Sosuke,使其能够进行文本的交流
- 完成录音并将语音消息转为文本消息传递给图灵机器人
- 将图灵机器人回复的文本消息转换为语音消息并播放
接入图灵机器人Sosuke
首先我们应该仔细阅读图灵机器人API V2.0接入文档,这里我们定义一个Robot类来实现图灵机器人的接入。
- 定义一个类之后我们来考虑一下,这个类需要哪些成员变量,通过阅读文档我们可以知道,需要一个请求接口url,需要机器人的api_key,还需要一个user_id,那我们就定义好这些成员变量
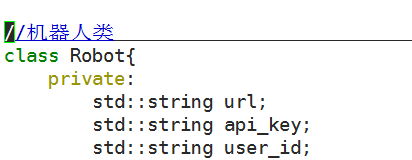
- 定义好成员变量之后,写好构造函数和析构函数之后,接下来我们就应该考虑该类应该实现什么功能,那就是需要哪些成员函数来实现,我们知道机器人最重要的就是和我们进行交流,那我们定义一个Talk函数实现和机器人Sosuke的交流工作,其实接入机器人Sosuke简单的来说就是向我们创建的图灵机器人发起http请求,并取得http回复就是这么简单的操作。

- 我们通过API接入文档可以看到,发起http-post请求请求的参数格式是json串的格式,那我们就需要将我们输入的文本信息转换为json串的格式。那我们就知道了,和图灵机器人Sosuke交流就分为三步:1.将我们的文本信息转换为json串 2.发起http-post请求并获取http-post响应。3.从将响应的json串中获取图灵机器人给我们响应的文本信息。

- json的序列化与反序列化并不难,根据json官网以及API接入文档就可以很好的进行这两项工作,但是需要注意的点就是构建和获取
Json::Value对象时必须严格根据文档要求的格式个命名进行。 - 重点介绍一下post请求的发起,这里有两种方式发起请求,一种就是自己写一个http请求模型,再发起请求,一种是直接使用百度提供的httpclient,在百度SDK文件下的base文件夹中的
http.h,这里为了方便和项目的简洁,所以我使用了后者。

到这我们就实现了将图灵机器人Sosuke接入Linux的操作了,我们可以通过输入文本和机器人进行交流
语音识别(ASR)
- 接入机器人Sosuke完成文本交流功能之后,我们接下来就可以借助百度ai平台的语音识别功能将我们录制好的语音识别成文本消息发送给图灵机器人,这里我们封装一个SpeechRec类来实现语音识别的功能
- 阅读百度语音识别C++SDK文档 通过阅读文档确定我们这个类需要的的成员变量

- 其实语音识别的最主要的功能就是通过两个接口实现的
get_file_content以及我们创建的api::speech client对象调用recognize接口
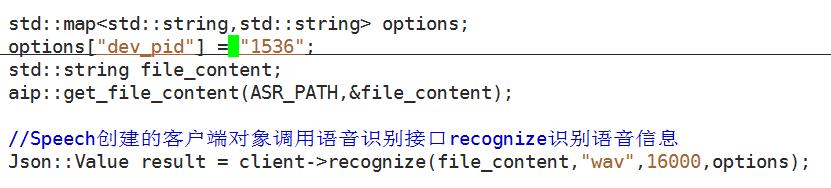
- 完成这些之后我们就可以通过语音和我们的机器人Sosuke交流,做完这些之后我们再多实现一个功能,就是通过语音让Sosuke替我们执行Linux下的命令,为了能够执行更多的命令,也为了不重复多次的修改代码,我们就直接创建一个命令配置文件,将我们想执行的命令对应说的话都写在配置文件中,然后在我们的代码中将配置文件加载进来即可,这里我们就要使用STL库中的unorder_map容器来存放我们的命令。

- 加载文件成功之后,我们需要的就是执行命令了,两种方法,第一:通过调用exec进程替换函数来执行相关命令,第二:调用popen函数执行命令,显然后者比较简单,我们就是用后者,先看看popen如何使用

- 定义一个Util类实现该功能

语音合成
- 同样是阅读百度ai平台提供的 语音识别C++SDK文档 由于需要的成员变量和语音识别的一样,所以我们也将这个功能放在我们刚刚封装的SpeechRec类中实现,语音合成最重要的接口就是
text2audio

到这我们就基本实现了我们语音小管家的大框架代码,但是我们缺个最重要的部分,一直没说的就是将三部分代码串起来的主逻辑,我们来思考一下主逻辑无非就是:先录音,将语音转换为文本信息,判断是否为命令,是则调用Exec接口执行命令,不是则调用Talk进行与机器人Sosuke交流,调用语音合成接口将机器人返回的信息转换为语音文件,再播放语音文件即可

给项目录音添加一个进度条
- 创建一个线程在执行主逻辑录音时让线程同时运行,效果会更加的好

项目效果展示
- 正常聊天

- 执行命令

- 退出
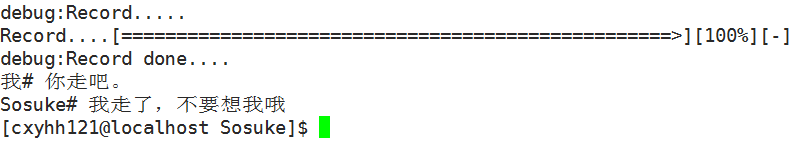
总结
语音小管家这个项目代码其实并不难,主要是第三方平台的使用,以及前期项目准备时和环境配置比较麻烦,总体来说还是比较好实现又比较好玩的一个项目
项目源码
https://github.com/CXYhh121/VoiceButler-.git