题目描述
编写一种方法,对字符串数组进行排序,将所有变位词组合在一起。变位词是指字母相同,但排列不同的字符串。
注意:本题相对原题稍作修改
示例:
输入: ["eat", "tea", "tan", "ate", "nat", "bat"],
输出:
[["ate","eat","tea"],["nat","tan"],["bat"]
]
说明:
- 所有输入均为小写字母。
- 不考虑答案输出的顺序。
解题思路与代码
这道题是一道中等难度的题。考察的知识点我觉得主要是哈希映射。对于C++语言来讲,需要你对map或者是unordered_map容器的一些操作有基本的了解。这道题就不怎么难了。
方法一,使用哈希映射 + unordered_map容器解决问题
-
在这道题中,我们需要维护一个
unordered_map<string,vector<string>> map,其中,单词的字典排序作为map的key,而符合这个key的单词的一系列重组单词的集合,我们把它作为map的value。 -
理解了上面一句话后,这道题就很简单了。
-
我们先遍历题目给的这个
vector<string>& strs,将它的每一个单词拿出来,先进行字典排序,然后去查找这个字典排序后的单词是否已经作为key在map中出现了,如果没有出现,则添加这个key,并且把这个单词未被排序之前的状态,作为一个value传递进去,比如这样:map[word] = {strs[i]};。如果出现了,我们就把这个单词添加到key所对应的value中去。比如这样:map[word].push_back(strs[i]); -
最后,我们再遍历一波map,把map中的每一个key所对应的value,作为一个vector,添加到最后的结果集中
具体的代码示例长这样:
class Solution {
public:vector<vector<string>> groupAnagrams(vector<string>& strs) {unordered_map<string,vector<string>> map;for(int i = 0; i < strs.size(); ++i){string word = strs[i];sort(word.begin(),word.end());if(map.find(word) == map.end()){map[word] = {strs[i]};}else{map[word].push_back(strs[i]);}}vector<vector<string>> result;for(auto& a : map){result.push_back(a.second);}return result;}
};
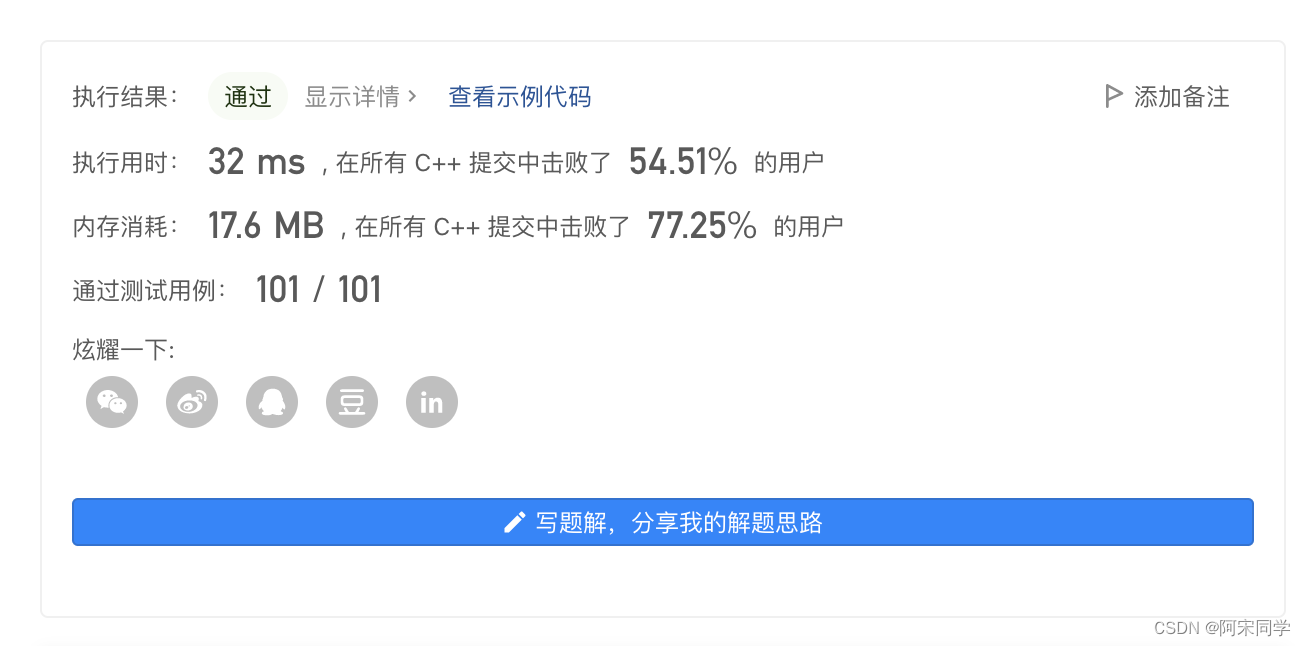
复杂度分析
时间复杂度:
- 遍历 strs 中的每个字符串,时间复杂度为 O(N),其中 N 为 strs 中的字符串数量。
对每个字符串进行排序,时间复杂度为 O(K * log(K)),其中 K 为字符串的最大长度。
使用哈希表进行查找和插入操作,时间复杂度为 O(1)(平均情况下)。
因此,总的时间复杂度为 O(N * K * log(K))。
空间复杂度:
- unordered_map 存储了所有输入字符串,空间复杂度为 O(N)。
输出结果 vector<vector> result,空间复杂度为 O(N)。
因此,总的空间复杂度为 O(N)。
总结
-
这道题目在考察使用哈希映射的能力以及对 C++ 中 map 和 unordered_map 等容器的操作是否熟悉。
-
我们可以通过设计合适的哈希函数和键值对存储,可以有效地解决这类问题。