1、消息队列模型
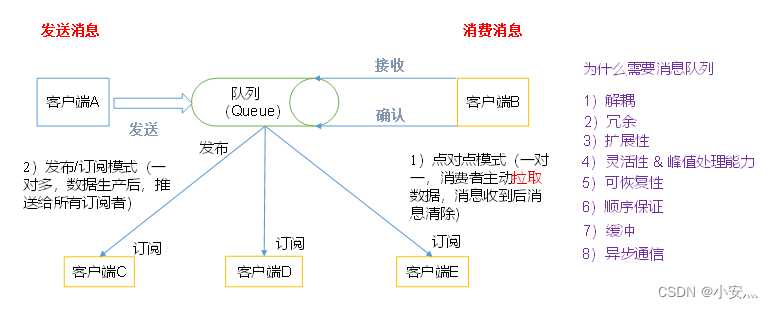
- 点对点模式
(一对一,消费者主动拉取数据,消息收到后消息清除)点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。 - 发布/订阅模式
(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
2、消息队列使用场景
-
解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。 -
冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。 -
扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。 -
灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。 -
可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。 -
顺序保证:
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka保证一个Partition内的消息的有序性) -
缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。 -
异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
3、消息队列对比
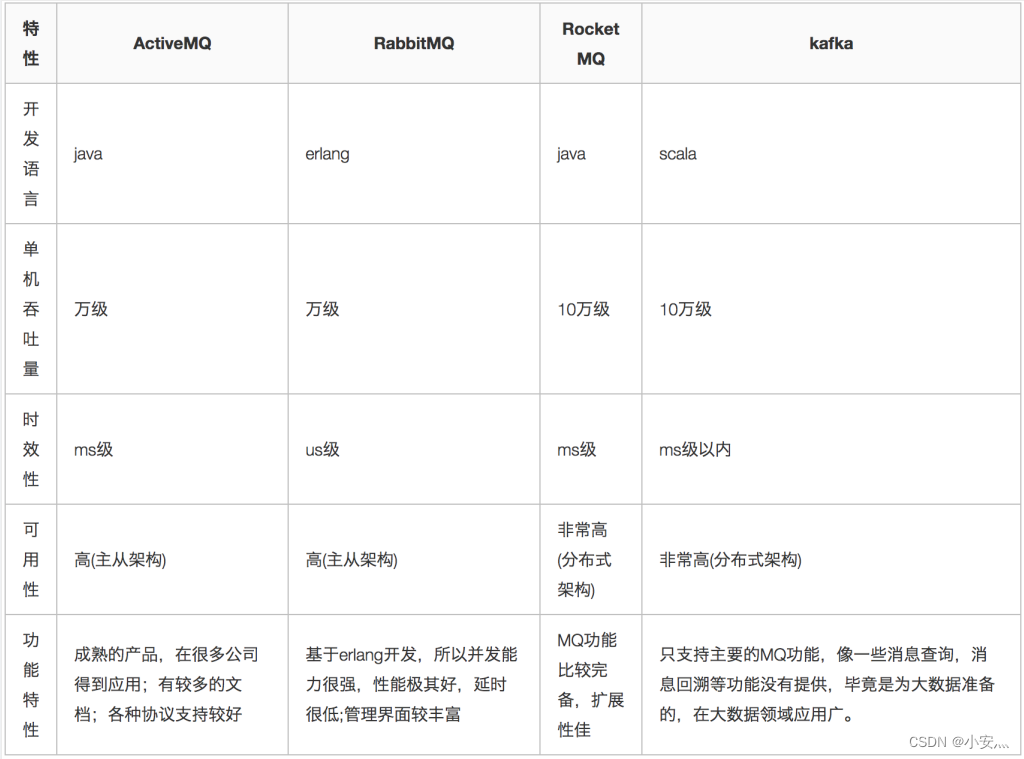
4、消息队列架构
4.1、Kafka
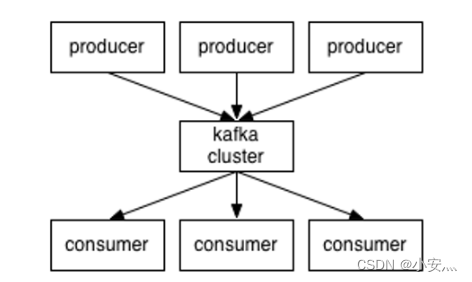
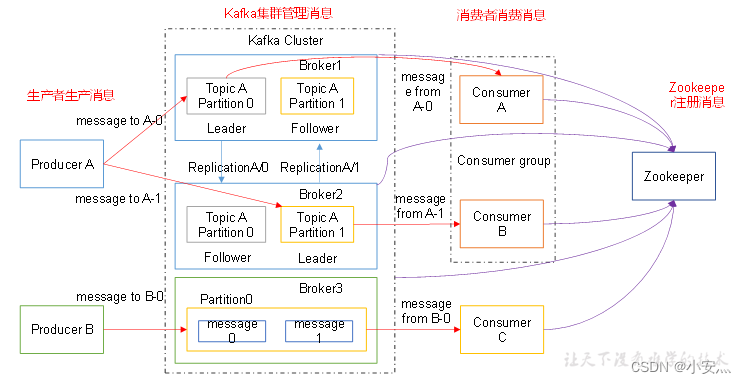
-
Producer :消息生产者,就是向kafka broker发消息的客户端;
-
Consumer :消息消费者,向kafka broker取消息的客户端;
-
Topic :可以理解为一个队列;
-
Consumer Group(CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic;
-
Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic;
-
Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序;
-
Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
4.、RocketMQ
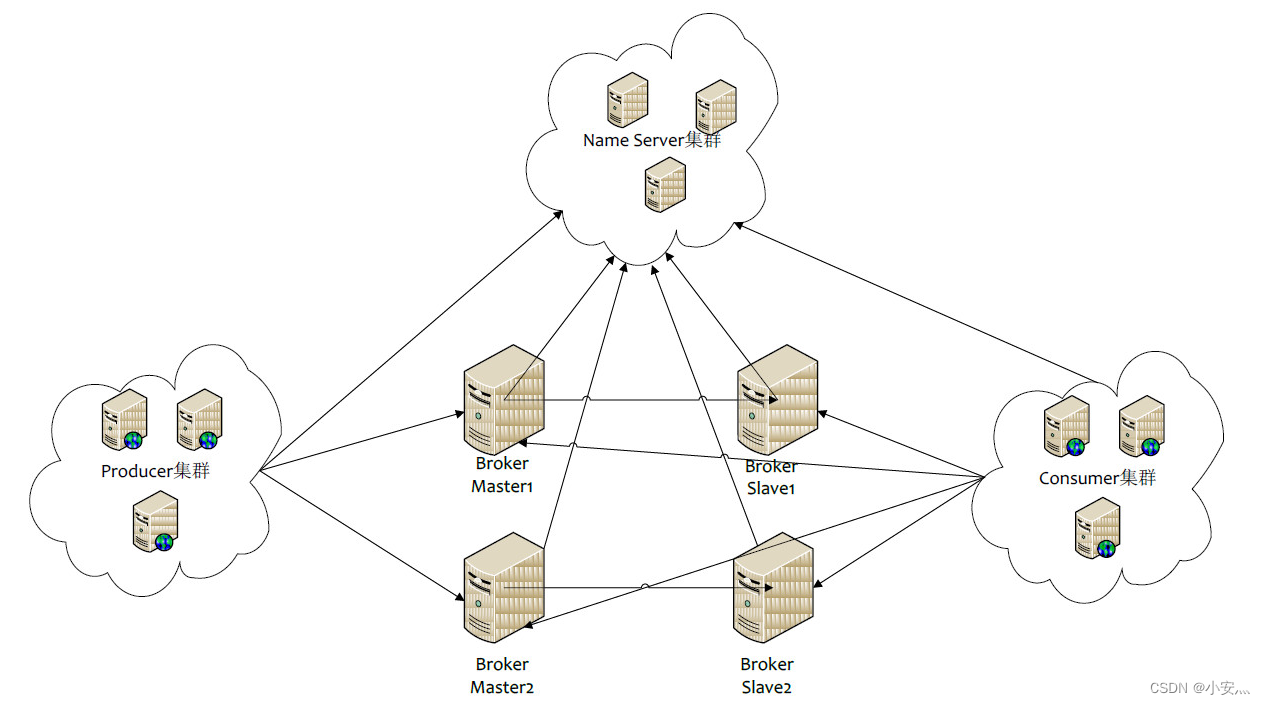
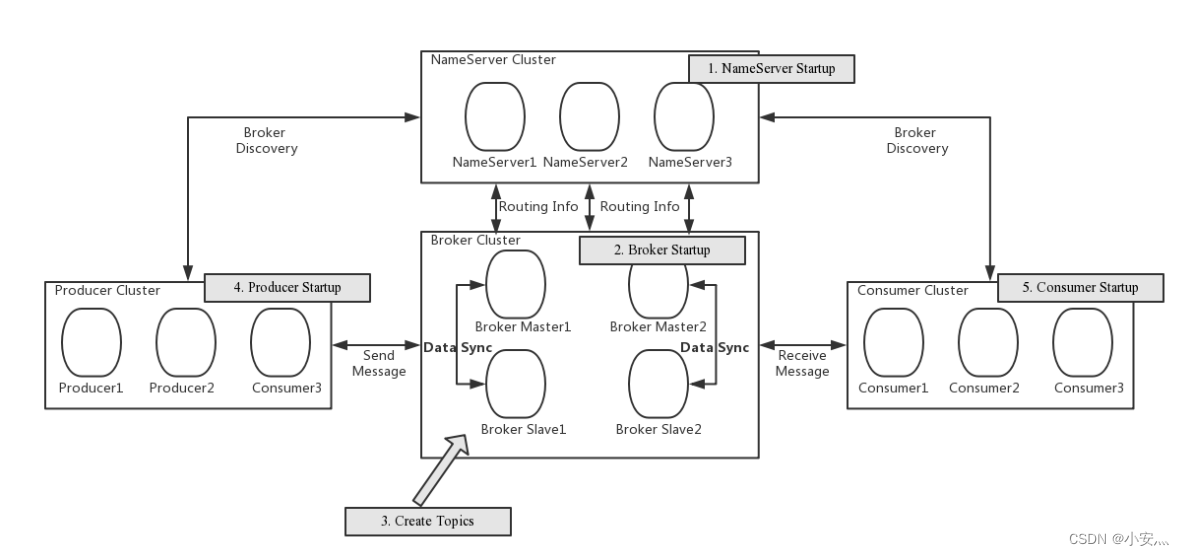
-
NameServer:是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
-
Broker:Broker部署相对复杂,Broker分为Master与Slave,一个Master可以对应多个Slave,但是一个Slave只能对应一个Master,Master与Slave的对应关系通过指定相同的BrokerName,不同的BrokerId来定义,BrokerId为0表示Master,非0表示Slave。Master也可以部署多个。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有NameServer。
-
Producer:Producer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群部署。
-
Consumer:Consumer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
5、数据写入流程
5.1、Kafka
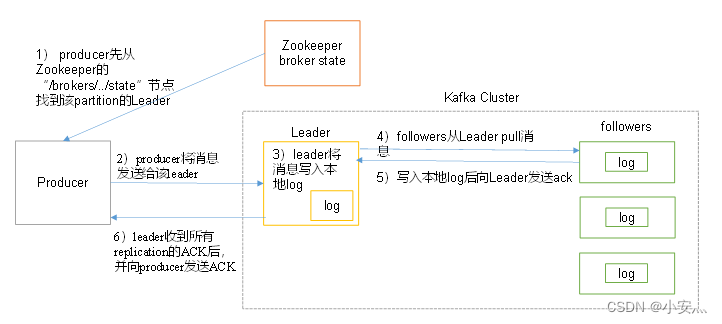
- producer先从zookeeper的 "/brokers/…/state"节点找到该partition的leader
- producer将消息发送给该leader
- leader将消息写入本地log
- followers从leader pull消息,写入本地log后向leader发送ACK
- leader收到所有ISR中的replication的ACK后,增加HW(high watermark,最后commit的offset)并向producer发送ACK
6、数据存储结构
6.1、Kafka
6.1.1、broker
- 物理上把topic分成一个或多个patition
- patition:对应server.properties中的num.partitions=3配置
- 每个patition物理上对应一个文件夹(该文件夹存储该patition的所有消息和索引文件),如下:
[root@hadoop102 logs]$ ll
drwxrwxr-x. 2 root root 4096 8月 6 14:37 first-0
drwxrwxr-x. 2 root root 4096 8月 6 14:35 first-1
drwxrwxr-x. 2 root root 4096 8月 6 14:37 first-2
[root@hadoop102 logs]$ cd first-0
[root@hadoop102 first-0]$ ll
-rw-rw-r--. 1 root root 10485760 8月 6 14:33 00000000000000000000.index
-rw-rw-r--. 1 root root 219 8月 6 15:07 00000000000000000000.log
-rw-rw-r--. 1 root root 10485756 8月 6 14:33 00000000000000000000.timeindex
-rw-rw-r--. 1 root root 8 8月 6 14:37 leader-epoch-checkpoint
存储策略
无论消息是否被消费,kafka都会保留所有消息。有两种策略可以删除旧数据:
- 基于时间:log.retention.hours=168
- 基于大小:log.retention.bytes=1073741824
需要注意的是,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关。
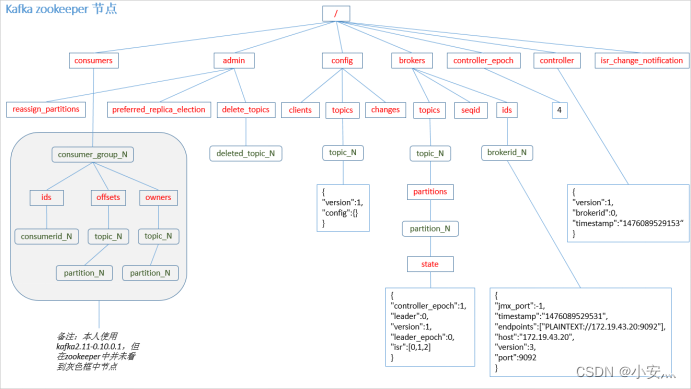
6.1.2、zookeeper
PS:producer不在zk中注册,消费者在zk中注册。
6.2、RocketMQ
- RocketMQ消息的存储是由ConsumeQueue和CommitLog配合完成的。
- CommitLog:是消息真正的物理存储文件
- ConsumeQueue:是消息的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址。
- 每个Topic下的每个Message Queue都有一个对应的ConsumeQueue文件。

- CommitLog:存储消息的元数据
- ConsumerQueue:存储消息在CommitLog的索引
- IndexFile:为了消息查询提供了一种通过key或时间区间来查询消息的方法,这种通过IndexFile来查找消息的方法不影响发送与消费消息的主流程
刷盘机制:
- RocketMQ的消息是存储到磁盘上的,这样既能保证断电后恢复, 又可以让存储的消息量超出内存的限制。
- RocketMQ为了提高性能,会尽可能地保证磁盘的顺序写。
- 消息在通过Producer写入RocketMQ的时候,有两种写磁盘方式,分别是同步刷盘和异步刷盘。
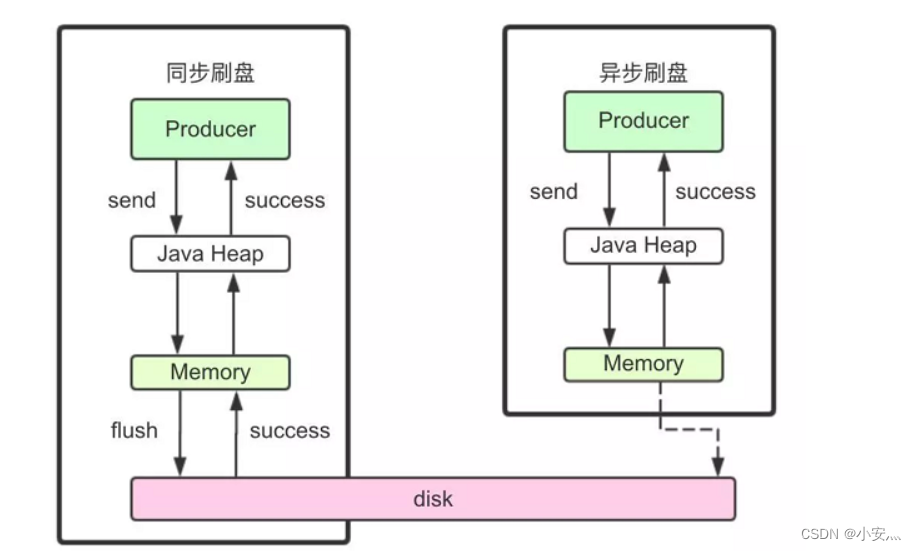
1)同步刷盘
在返回写成功状态时,消息已经被写入磁盘。具体流程是,消息写入内存的PAGECACHE后,立刻通知刷盘线程刷盘, 然后等待刷盘完成,刷盘线程执行完成后唤醒等待的线程,返回消息写 成功的状态。
2)异步刷盘
在返回写成功状态时,消息可能只是被写入了内存的PAGECACHE,写操作的返回快,吞吐量大;当内存里的消息量积累到一定程度时,统一触发写磁盘动作,快速写入。
3)配置
同步刷盘还是异步刷盘,都是通过Broker配置文件里的flushDiskType 参数设置的,这个参数被配置成SYNC_FLUSH、ASYNC_FLUSH中的 一个。
消息主从复制
如果一个Broker组有Master和Slave,消息需要从Master复制到Slave 上,有同步和异步两种复制方式。
1)同步复制
同步复制方式是等Master和Slave均写 成功后才反馈给客户端写成功状态;
在同步复制方式下,如果Master出故障, Slave上有全部的备份数据,容易恢复,但是同步复制会增大数据写入 延迟,降低系统吞吐量。
2)异步复制
异步复制方式是只要Master写成功 即可反馈给客户端写成功状态。
在异步复制方式下,系统拥有较低的延迟和较高的吞吐量,但是如果Master出了故障,有些数据因为没有被写 入Slave,有可能会丢失;
3)配置
同步复制和异步复制是通过Broker配置文件里的brokerRole参数进行设置的,这个参数可以被设置成ASYNC_MASTER、 SYNC_MASTER、SLAVE三个值中的一个。
4)总结
- 实际应用中要结合业务场景,合理设置刷盘方式和主从复制方式, 尤其是SYNC_FLUSH方式,由于频繁地触发磁盘写动作,会明显降低 性能。
- 通常情况下,应该把Master和Slave配置成ASYNC_FLUSH的刷盘方式,主从之间配置成SYNC_MASTER的复制方式,这样即使有一台 机器出故障,仍然能保证数据不丢,是个不错的选择。