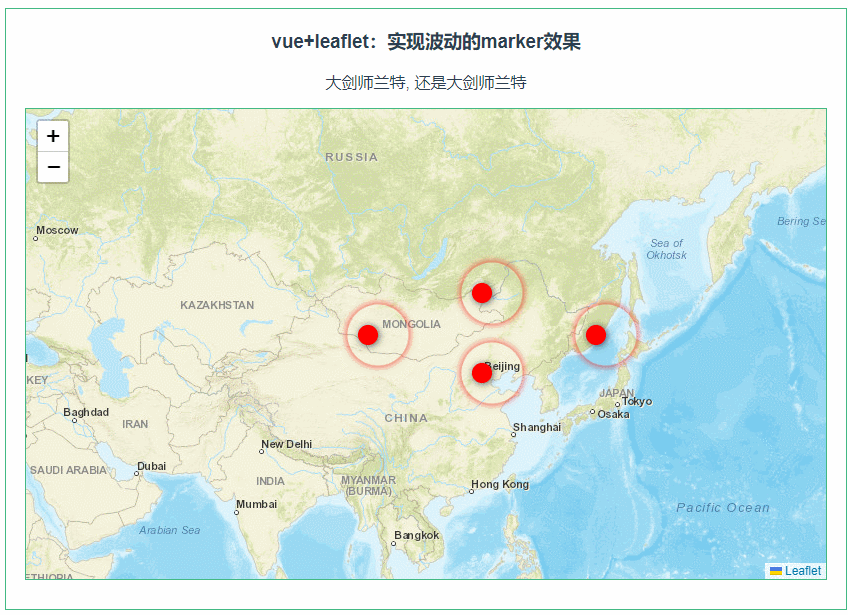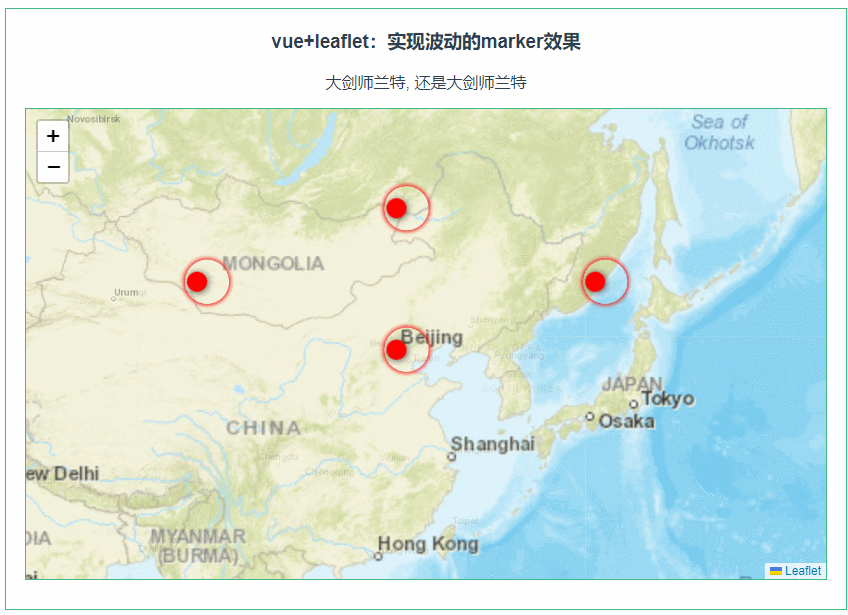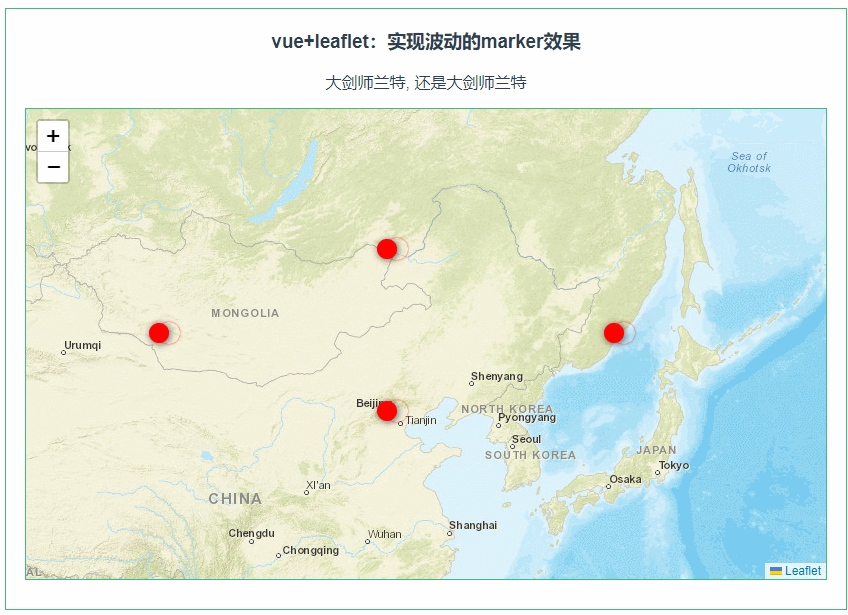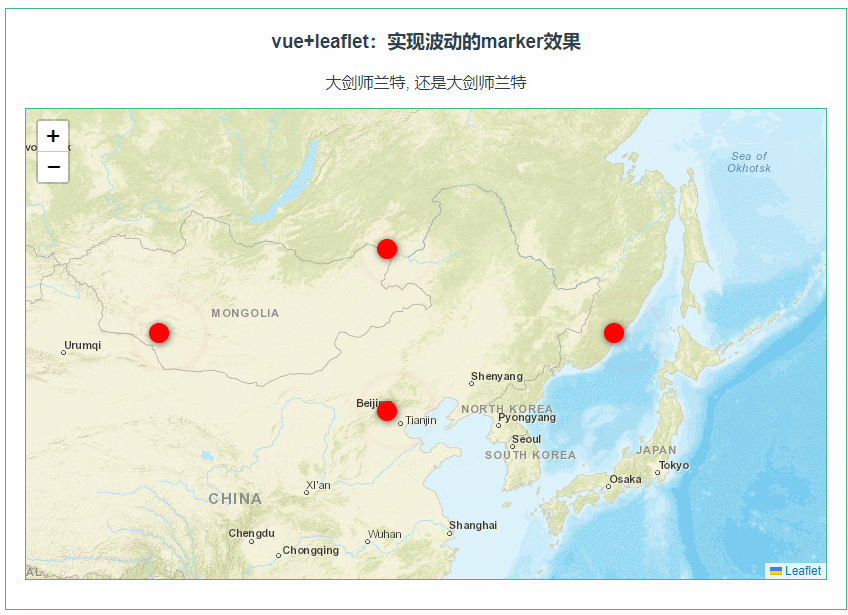
目录
1.数据集准备、预训练模型准备
2.对VGG16模型进行微调
3.对数据集进行预处理
4.对模型进行训练并可视化训练过程
5.该测试案例的完整代码
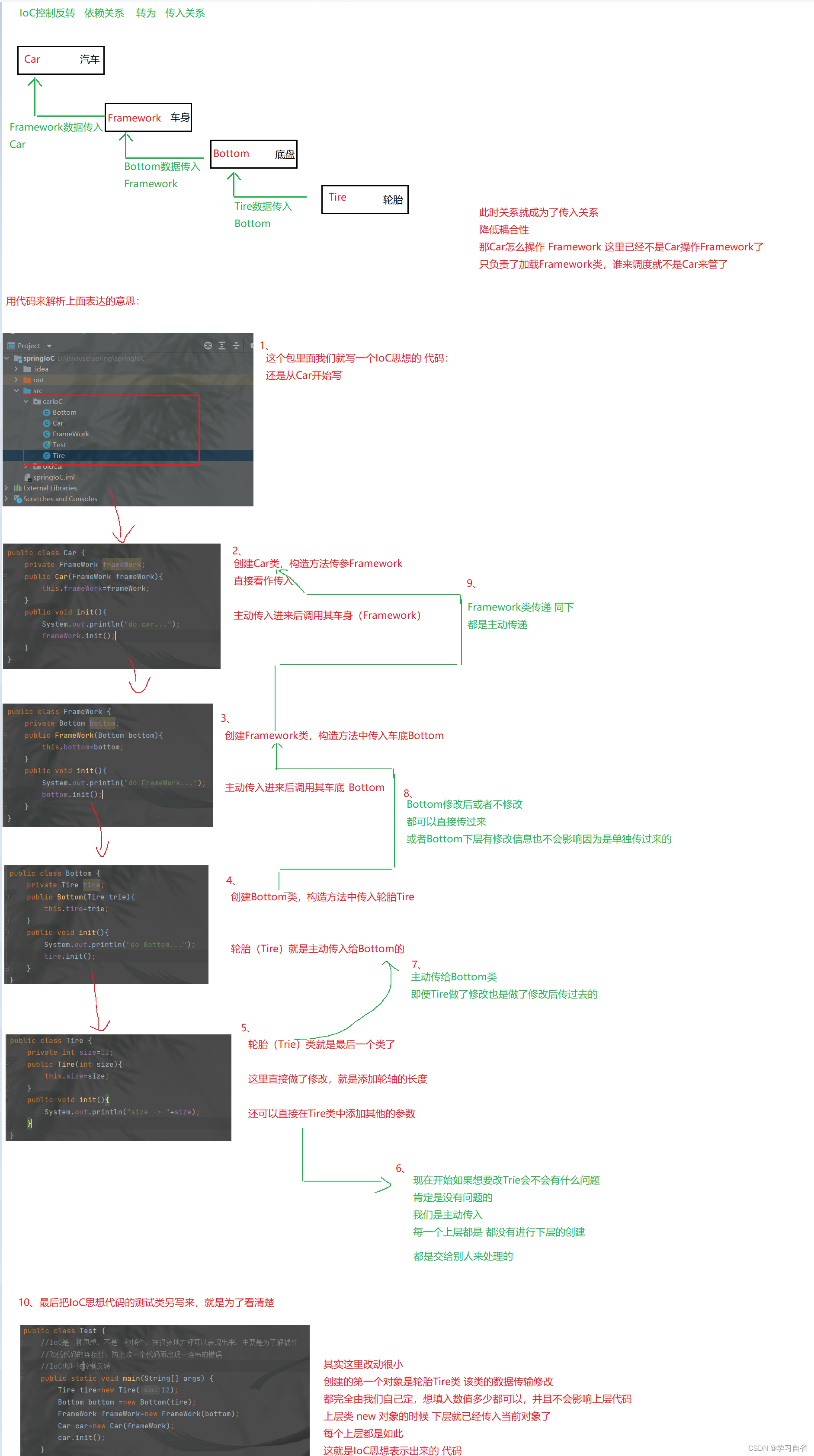
对于一个复杂的卷积神经网络来说,通常网络的层数非常大,网络的深度非常深、网络的参数非常多,单单设计一个卷积网络就需要颇费心思,何况网络还需要大量的数据集进行漫长时间的训练,若没有一个好的算力平台也很难迅速训练出模型。可见,从头到尾搭建一个中等规模的卷积神经网络对于我们来说绝非易事。幸运的是PyTorch已经许多预训练好的模型,比如内置了使用ImageNet数据集预训练好的、流行的VGG、AlexNet等深度学习网络,我们可以针对自己的需求,对预训练好的网络进行微调,从而快速完成自己的任务。下面,我们使用基于pytorch提供的预训练好的VGG16,对其进行微调,使用其他的数据集,训练一个图片分类器。
1.数据集准备、预训练模型准备
我们使用来自kaggle数据库中的10类猴子数据集。在该数据集中包含训练数据集和验证数据集,其中训练数据集中每类约140张RGB图像,验证数据集中每类约30张图像。针对该数据集使用VGG16的卷积层和池化层的预训练好的权重,提取数据特征,然后定义新的全连接层,用于图像的分类。
import torch
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report
import matplotlib.pyplot as plt
import seaborn as sns
import hiddenlayer as hl
import torch.nn as nn
from torch.optim import SGD,Adam
import torch.utils.data as Data
from torchvision import models
from torchvision import transforms
from torchvision.datasets import ImageFolder
#导入预训练好的VGG16
vgg16=models.vgg16(pretrained=True)
vgg=vgg16.features#获取vgg16的特征提取层
for param in vgg.parameters():param.requires_grad(False)
在上面的程序中,使用models.vgg16(pretrained=True)导入网络,其中参数pretrained=True表示导入的网络是使用ImageNet数据集预训练好的网络。在得到的VGG16网络中,使用vgg16.features获取VGG16网络的特征提取模块,即前面的卷积核池化层,不包括全连接层。为了提升网络的训练速度,只使用VGG16提取图像的特征,需要将VGG16的特征提取层参数冻结,不更新其权重,通过for循环和param.requires_grad_(False)即可
2.对VGG16模型进行微调
获取VGG16网络的特征提取模块后,需要在VGG16特征提取层之后添加新的全连接层,网络结构定义如下:
class MyVggNet(nn.Module):def __init__(self):super(MyVggNet, self).__init__()#预训练的vgg16特征提取层self.vgg=vgg#添加新的全连接层self.classify=nn.Sequential(nn.Linear(25088,512),nn.ReLU(),nn.Dropout(0.5),nn.Linear(512,256),nn.ReLU(),nn.Dropout(0.5),nn.Linear(256,10),nn.Softmax(dim=1))#定义网络的前向传播def forward(self,x):x=self.vgg(x)x=x.view(x.size(0),-1)#多维度的tensor展平成一维output=self.classify(x)return output
MyVggNet=MyVggNet()
print(MyVggNet)在上面的程序中,定义了一个卷积神经网络类包含两个大的结构,一个是self.vgg,使用预训练好的VGC16的特征提取,并且其参数的权重已经冻结;另一个是self.classify,由三个全连接层组成。在全连接层中使用ReLU函数作为激活函数,并通过nn.Dropout层防止模型过拟合。输出的网络的详细结构如下:
MyVggNet(
(vgg): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classify): Sequential(
(0): Linear(in_features=25088, out_features=512, bias=True)
(1): ReLU()
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=512, out_features=256, bias=True)
(4): ReLU()
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=256, out_features=10, bias=True)
(7): Softmax(dim=1)
)
)
3.对数据集进行预处理
在定义好网络结构之后,就需要对数据集的数据进行预处理,主要包括定义训练集和测试集的预处理过程。
#对训练集进行预处理
train_data=transforms.Compose([transforms.RandomResizedCrop(224),#随机长宽比裁剪为224*224transforms.RandomHorizontalFlip(),#依据P=0.5的概率水平翻转transforms.ToTensor(),#转化为张量并归一化至[0-1]transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])#图像标准化处理
])
#对验证集进行预处理
val_data=transforms.Compose([transforms.Resize(256),#重置图像分辨率transforms.CenterCrop(224),#依据给定的size从中心裁剪transforms.ToTensor(),#转化为张量并归一化至[0-1]#图像标准化处理transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
])值得注意的是:在图像标准化时,我们始终都使用mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225]。这是因为image_mean=[0.485,0.456,0.406]、image_std=[0.229,0.224,0.225]是Imagenet数据集的均值和标准差,使用Imagenet的均值和标准是一种常见的做法。如果我们想在自己的数据集上从头开始训练,我们可以计算新的平均值和标准。否则,建议使用Imagenet的平均值和标准差。是否使用ImageNet的均值和标准差取决于我们的数据:假设数据是“自然场景”的普通照片(人,建筑,动物,不同的照明/角度/背景等等),并且假设数据集和 ImageNet 存在类似的偏差(在类别平衡方面),那么使用 ImageNet 的数据进行规范化就可以了。如果照片是“特殊的”(颜色过滤,对比度调整,不寻常的光线,等等)或“非自然的主题”(医学图像,卫星地图,手绘等) ,那么建议在模型训练之前正确地规范化数据集(计算新的平均值和标准)。
因为该数据集的每类图像都分别保存在一个单独的文件夹中,如下图:

所以可以使用ImageFolder()函数从文件中读取训练集和验证集,数据读取的程序如下所示:
#读取训练集图像
train_data_dir="./Dataset/10-monkey-species/training"
train_data=ImageFolder(train_data_dir,train_data_transforms)
train_data_loader=Data.DataLoader(train_data,batch_size=32,shuffle=True,num_workers=0)
#读取验证集
val_data_dir="./Dataset/10-monkey-species/validation"
val_data=ImageFolder(val_data_dir,val_data_transforms)
val_data_loader=Data.DataLoader(val_data,batch_size=32,shuffle=True,num_workers=0)
print("训练集样本数:",len(train_data.targets))
print("验证集样本数:",len(val_data.targets))训练集样本数: 1097
验证集样本数: 272
从输出结果可以发现,训练集有1097个样本,验证集有272个样本。下面我们获取训练集的一个batch图像,然后将获取的32张图像进行可视化,观察数据中图像的内容。
#获取一个batch的数据
for step,(b_x,b_y) in enumerate(train_data_loader):if step>0:break
mean=np.array([0.485,0.456,0.406])
std=np.array([0.229,0.224,0.225])
plt.figure(figsize=(12,6))
for i in np.arange(len(b_y)):plt.subplot(4,8,i+1)image=b_x[i,:,:,:].numpy().transpose((1,2,0))image=std * image+meanimage=np.clip(image,0,1)plt.imshow(image)plt.title(b_y[i].data.numpy())plt.axis("off")
plt.subplots_adjust(hspace=0.3)
plt.show()上面的程序在获取了一个batch图像后,在可视化前,需要将图像每个通道的像素值乘以对应的标准差并加上对应的均值,最后得到的可视化图像如图所示

4.对模型进行训练并可视化训练过程
为了验证准备好的网络的泛化能力,使用训练集对网络进行训练,使用验证集验证。模型在训练时使用Adam优化算法,损失函数使用nn.CrossEntropyLoss()交叉嫡损失。在训练过程中使用HiddenLayer库可视化网络在训练集和验证集上的表现。
#定义优化器
optimizer=torch.optim.Adam(MyVggNet.parameters(),lr=0.003)
loss_func=nn.CrossEntropyLoss()#使用交叉熵损失函数
if torch.cuda.is_available():loss_func=loss_func.cuda()history1=hl.History()
canvas1=hl.Canvas()
#对模型进行迭代训练
for epoch in range(10):train_loss_epoch=0val_loss_epoch=0train_corrects=0val_corrects=0#对训练数据的加载器进行迭代计算MyVggNet.train()for step,(b_x,b_y) in enumerate(train_data_loader):if torch.cuda.is_available():b_x=b_x.cuda()b_y=b_y.cuda()#计算每个batch上的损失output=MyVggNet(b_x)#CNN在训练batch上的输出loss=loss_func(output,b_y)#交叉熵损失函数pre_lab=torch.argmax(output,1)optimizer.zero_grad()#每个迭代步的梯度初始化为0loss.backward()#损失的后向传播,计算梯度optimizer.step()#使用梯度进行优化train_loss_epoch += loss.item() * b_x.size(0)train_corrects +=torch.sum(pre_lab==b_y.data)#计算一个epoch上的损失和精度train_loss=train_loss_epoch / len(train_data.targets)train_acc=train_corrects.double() / len(train_data.targets)#计算在验证集上的表现MyVggNet.eval()for step,(val_x,val_y) in enumerate(val_data_loader):if torch.cuda.is_available():val_x=val_x.cuda()val_y=val_y.cuda()output=MyVggNet(val_x)loss=loss_func(output,val_y)pre_lab=torch.argmax(output,1)val_loss_epoch +=loss.item() * val_x.size(0)val_corrects+=torch.sum(pre_lab==val_y.data)#计算一个epoch上的精度和损失val_loss=val_loss_epoch/len(val_data.targets)val_acc=val_corrects.double()/len(val_data.targets)#保存每个epoch上输出的loss和acchistory1.log(epoch,train_loss=train_loss,val_loss=val_loss,train_acc=train_acc.item(),val_acc=val_acc.item())
#可视化网络训练过程
with canvas1:canvas1.draw_plot([history1["train_loss"],history1["val_loss"]])canvas1.draw_plot([history1["train_acc"],history1["val_acc"]])
使用上面的程序对模型训练10个epoch,在训练过程中,动态可视化模型的损失函数和识别精度的变化情况如上图所示。网络经过训练后,最终预测结果保持稳定,并且在验证集上的精度高于在训练集上的高度,在验证集上的损失低于在训练集上的损失。
5.该测试案例的完整代码
import torch
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report
import matplotlib.pyplot as plt
import seaborn as sns
import hiddenlayer as hl
import torch.nn as nn
from torch.optim import SGD,Adam
import torch.utils.data as Data
from torchvision import models
from torchvision import transforms
from torchvision.datasets import ImageFolder
#导入预训练好的VGG16
vgg16=models.vgg16(pretrained=True)
vgg=vgg16.features#获取vgg16的特征提取层
for param in vgg.parameters():param.requires_grad_(False)class MyVggNet(nn.Module):def __init__(self):super(MyVggNet, self).__init__()#预训练的vgg16特征提取层self.vgg=vgg#添加新的全连接层self.classify=nn.Sequential(nn.Linear(25088,512),nn.ReLU(),nn.Dropout(0.5),nn.Linear(512,256),nn.ReLU(),nn.Dropout(0.5),nn.Linear(256,10),nn.Softmax(dim=1))#定义网络的前向传播def forward(self,x):x=self.vgg(x)x=x.view(x.size(0),-1)#多维度的tensor展平成一维output=self.classify(x)return output
MyVggNet=MyVggNet()
if torch.cuda.is_available():MyVggNet=MyVggNet.cuda()
print(MyVggNet)
#对训练集进行预处理
train_data_transforms=transforms.Compose([transforms.RandomResizedCrop(224),#随机长宽比裁剪为224*224transforms.RandomHorizontalFlip(),#依据P=0.5的概率水平翻转transforms.ToTensor(),#转化为张量并归一化至[0-1]transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])#图像标准化处理
])
#对验证集进行预处理
val_data_transforms=transforms.Compose([transforms.Resize(256),#重置图像分辨率transforms.CenterCrop(224),#依据给定的size从中心裁剪transforms.ToTensor(),#转化为张量并归一化至[0-1]#图像标准化处理transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
])
#读取训练集图像
train_data_dir="./Dataset/10-monkey-species/training"
train_data=ImageFolder(train_data_dir,train_data_transforms)
train_data_loader=Data.DataLoader(train_data,batch_size=32,shuffle=True,num_workers=0)
#读取验证集
val_data_dir="./Dataset/10-monkey-species/validation"
val_data=ImageFolder(val_data_dir,val_data_transforms)
val_data_loader=Data.DataLoader(val_data,batch_size=32,shuffle=True,num_workers=0)
print("训练集样本数:",len(train_data.targets))
print("验证集样本数:",len(val_data.targets))# #获取一个batch的数据
# for step,(b_x,b_y) in enumerate(train_data_loader):
# if step>0:
# break
# mean=np.array([0.485,0.456,0.406])
# std=np.array([0.229,0.224,0.225])
# plt.figure(figsize=(12,6))
# for i in np.arange(len(b_y)):
# plt.subplot(4,8,i+1)
# image=b_x[i,:,:,:].numpy().transpose((1,2,0))
# image=std * image+mean
# image=np.clip(image,0,1)
# plt.imshow(image)
# plt.title(b_y[i].data.numpy())
# plt.axis("off")
# plt.subplots_adjust(hspace=0.3)
# plt.show()#定义优化器
optimizer=torch.optim.Adam(MyVggNet.parameters(),lr=0.003)
loss_func=nn.CrossEntropyLoss()#使用交叉熵损失函数
if torch.cuda.is_available():loss_func=loss_func.cuda()history1=hl.History()
canvas1=hl.Canvas()
#对模型进行迭代训练
for epoch in range(10):train_loss_epoch=0val_loss_epoch=0train_corrects=0val_corrects=0#对训练数据的加载器进行迭代计算MyVggNet.train()for step,(b_x,b_y) in enumerate(train_data_loader):if torch.cuda.is_available():b_x=b_x.cuda()b_y=b_y.cuda()#计算每个batch上的损失output=MyVggNet(b_x)#CNN在训练batch上的输出loss=loss_func(output,b_y)#交叉熵损失函数pre_lab=torch.argmax(output,1)optimizer.zero_grad()#每个迭代步的梯度初始化为0loss.backward()#损失的后向传播,计算梯度optimizer.step()#使用梯度进行优化train_loss_epoch += loss.item() * b_x.size(0)train_corrects +=torch.sum(pre_lab==b_y.data)#计算一个epoch上的损失和精度train_loss=train_loss_epoch / len(train_data.targets)train_acc=train_corrects.double() / len(train_data.targets)#计算在验证集上的表现MyVggNet.eval()for step,(val_x,val_y) in enumerate(val_data_loader):if torch.cuda.is_available():val_x=val_x.cuda()val_y=val_y.cuda()output=MyVggNet(val_x)loss=loss_func(output,val_y)pre_lab=torch.argmax(output,1)val_loss_epoch +=loss.item() * val_x.size(0)val_corrects+=torch.sum(pre_lab==val_y.data)#计算一个epoch上的精度和损失val_loss=val_loss_epoch/len(val_data.targets)val_acc=val_corrects.double()/len(val_data.targets)#保存每个epoch上输出的loss和acchistory1.log(epoch,train_loss=train_loss,val_loss=val_loss,train_acc=train_acc.item(),val_acc=val_acc.item())
#可视化网络训练过程
with canvas1:canvas1.draw_plot([history1["train_loss"],history1["val_loss"]])canvas1.draw_plot([history1["train_acc"],history1["val_acc"]])