Apollo: 配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。 支持(HTTP长轮询1s内), 用户在Apollo修改完配置并发布后,客户端能实时(1秒)接收到最新的配置,并通知到应用程序
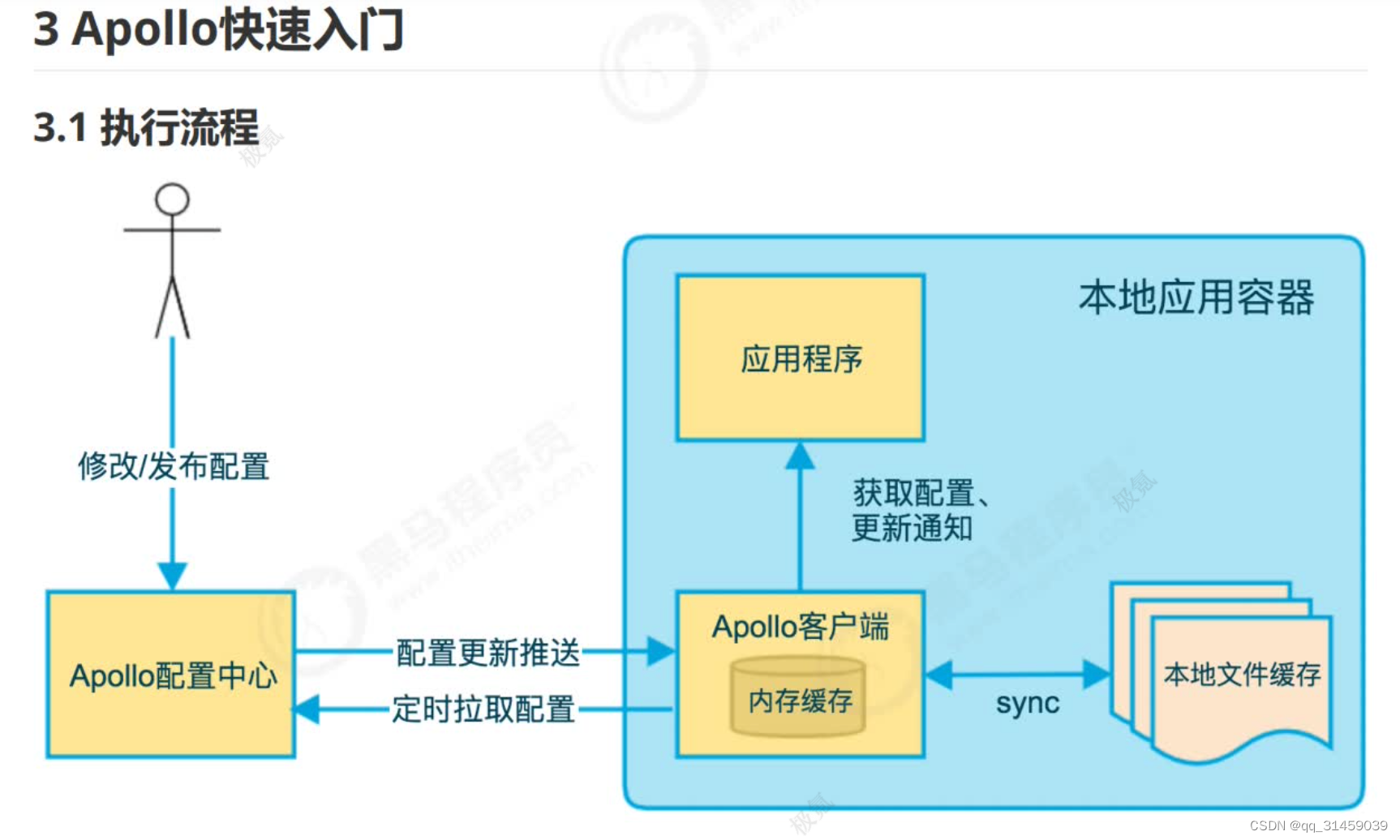
操作流程如下:1、在Apollo配置中心修改配置
2、应用程序通过Apollo客户端从配置中心拉取配置信息用户通过Apollo配置中心修改或发布配置后,会有两种机制来保证应用程序来获取最新配置:一种是Apollo配置中心会向客户端推送最新的配置;另外一种是Apollo客户端会定时从Apollo配置中心拉取最新的配置,通过以上两种机制共同来保证应用程序能及时获取到配置。
4.7配置发布原理在配置中心中,一个重要的功能就是配置发布后实时推送到客户端。
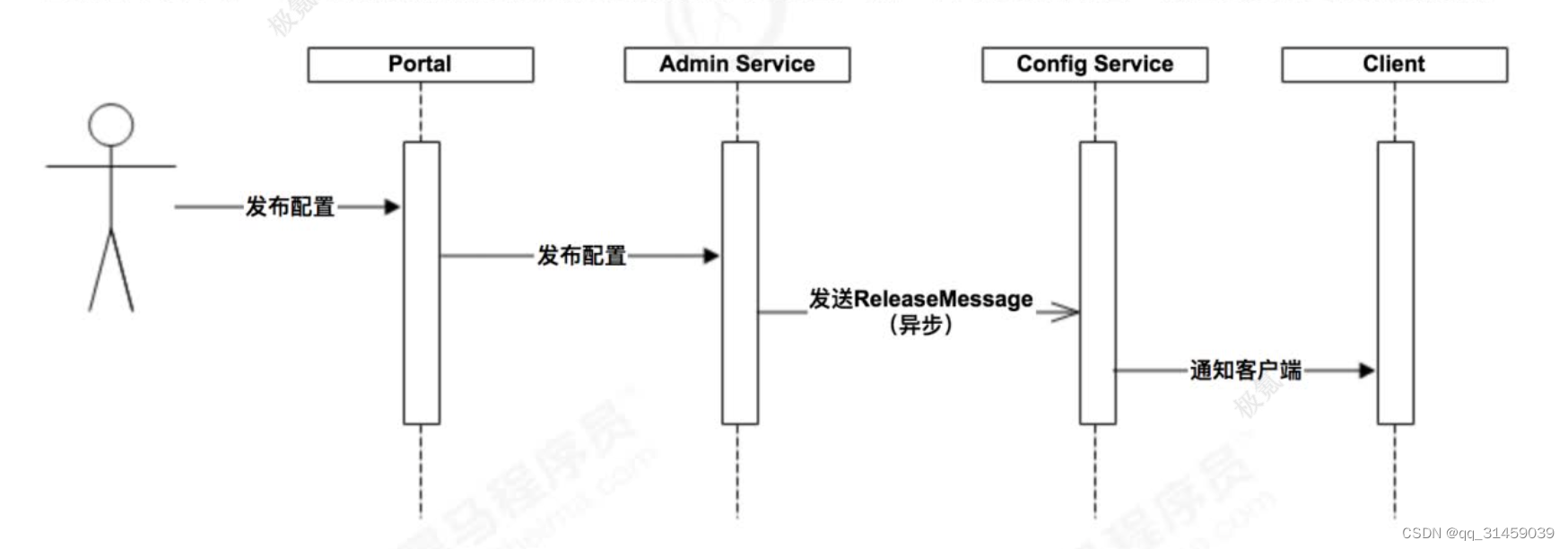
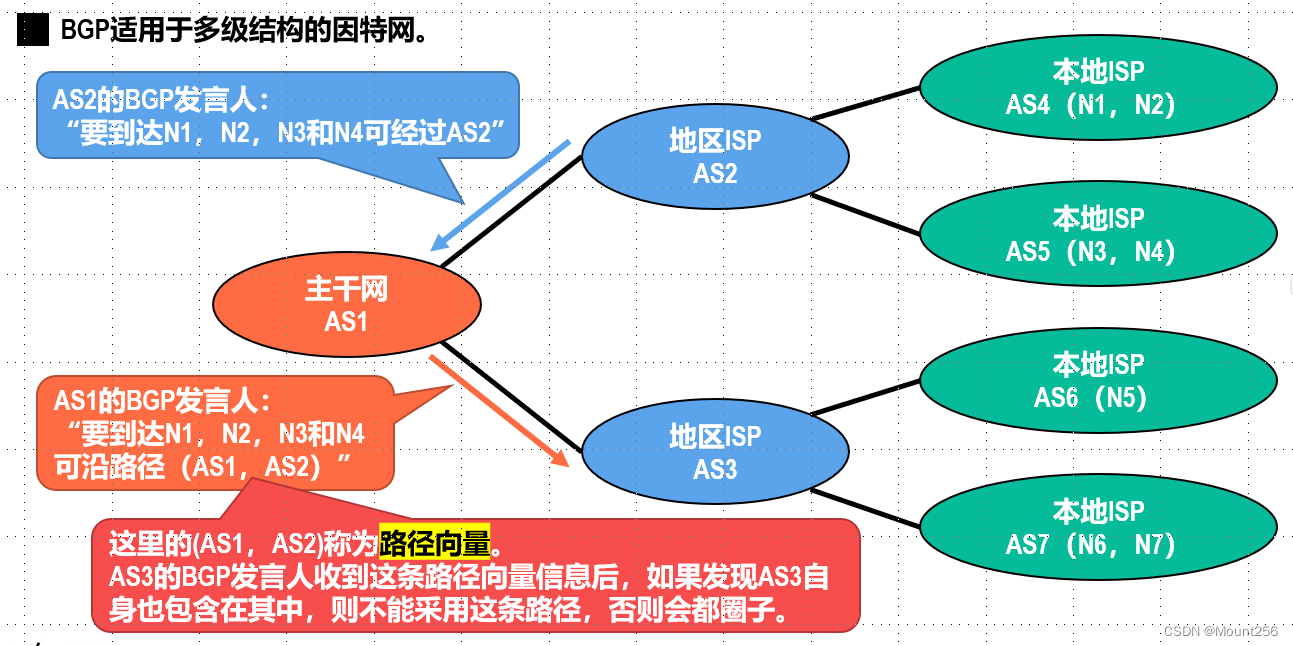
上图简要描述了配置发布的主要过程:
1.用户在Portal操作配置发布
2. Portal调用Admin Service的接口操作发布
3. Admin Service发布配置后,发送ReleaseMessage给各个Config Service
4. Config Service收到ReleaseMessage后,通知对应的客户端(客户端会发起一个Http请求到ConfigService的notifications/v2接口NotificationControllerV2)
NotificationControllerV2不会立即返回结果,而是把请求挂起。考虑到会有数万客户端向服务端发起长连,因此在服务端使用了asyncservlet(SpringDeferredResult)来服务HttpLongPolling请求。
NotificationControllerV2不会立即返回结果,而是把请求挂起。考虑到会有数万客户端向服务端发起长连,因此在服务端使用了asyncservlet(SpringDeferredResult)来服务HttpLongPolling请求。
3.如果在60秒内没有该客户端关心的配置发布,那么会返回Http状态码304给客户端。
4.如果有该客户端关心的配置发布,NotificationControllerV2会调用DeferredResult的setResult方法,传入有配置变化的namespace信息,同时该请求会立即返回。客户端从返回的结果中获取到配置变化的namespace后,会立即请求ConfigService获取该namespace的最新配置。
除了之前介绍的客户端和服务端保持一个长连接,从而能第一时间获得配置更新的推送外,客户端还会定时从Apollo配置中心服务端拉取应用的最新配置。
配置中心最核心的能力就是配置的动态推送,常见的配置中心如 Nacos、Apollo 等都实现了这样的能力。Nacos 和 Apollo 恰恰都没有使用长连接,而是使用的长轮询。
数据交互有两种模式:Push(推模式)和 Pull(拉模式)。
推模式指的是客户端与服务端建立好网络长连接,服务方有相关数据直接通过长连接通道推送到客户端。其优点是及时,一旦有数据变更,客户端立马能感知到;另外对客户端来说逻辑简单,不需要关心有无数据这些逻辑处理。缺点是不知道客户端的数据消费能力,可能导致数据积压在客户端,来不及处理。
拉模式指的是客户端主动向服务端发出请求,拉取相关数据。
其优点是此过程由客户端发起请求,故不存在推模式中数据积压的问题。缺点是可能不够及时,对客户端来说需要考虑数据拉取相关逻辑,何时去拉及拉的频率怎么控制等等。
重点介绍一下长轮询(Long Polling)和轮询(Polling)的区别,两者都是拉模式的实现。
「轮询」是指不管服务端数据有无更新,客户端每隔定长时间请求拉取一次数据,可能有更新数据返回,也可能什么都没有。
配置中心如果使用「轮询」实现动态推送,会有以下问题:
-
推送延迟。客户端每隔 5s 拉取一次配置,若配置变更发生在第 6s,则配置推送的延迟会达到 4s。
-
服务端压力。配置一般不会发生变化,频繁的轮询会给服务端造成很大的压力。
-
推送延迟和服务端压力无法中和。降低轮询的间隔,延迟降低,压力增加;增加轮询的间隔,压力降低,延迟增高。
「长轮询」则不存在上述的问题。
客户端发起长轮询,如果服务端的数据没有发生变更,会 hold 住请求,直到服务端的数据发生变化,或者等待一定时间超时才会返回。返回后,客户端又会立即再次发起下一次长轮询。
配置中心使用「长轮询」如何解决「轮询」遇到的问题也就显而易见了:
-
推送延迟。服务端数据发生变更后,长轮询结束,立刻返回响应给客户端。
-
服务端压力。长轮询的间隔期一般很长,例如 30s、60s,并且服务端 hold 住连接不会消耗太多服务端资源。
可能有人会有疑问,为什么一次长轮询需要等待一定时间超时,超时后又发起长轮询,为什么不让服务端一直 hold 住?
主要有两个层面的考虑,一是连接稳定性的考虑,长轮询在传输层本质上还是走的 TCP 协议,如果服务端假死、fullgc 等异常问题,或者是重启等常规操作,长轮询没有应用层的心跳机制,仅仅依靠 TCP 层的心跳保活很难确保可用性,所以一次长轮询设置一定的超时时间也是在确保可用性。
除此之外,在配置中心场景,还有一定的业务需求需要这么设计。
在配置中心的使用过程中,用户可能随时新增配置监听,而在此之前,长轮询可能已经发出,新增的配置监听无法包含在旧的长轮询中,所以在配置中心的设计中,一般会在一次长轮询结束后,将新增的配置监听给捎带上,而如果长轮询没有超时时间,只要配置一直不发生变化,响应就无法返回,新增的配置也就没法设置监听了。
配置中心长轮训设计
上文的图中,介绍了长轮询的流程,本节会详解配置中心长轮询的设计细节。
客户端发起长轮询
客户端发起一个 HTTP 请求,请求信息包含配置中心的地址,以及监听的 dataId(本文出于简化说明的考虑,认为 dataId 是定位配置的唯一键)。若配置没有发生变化,客户端与服务端之间一直处于连接状态。
服务端监听数据变化
服务端会维护 dataId 和长轮询的映射关系,如果配置发生变化,服务端会找到对应的连接,为响应写入更新后的配置内容。如果超时内配置未发生变化,服务端找到对应的超时长轮询连接,写入 304 响应。
客户端接收长轮询响应
首先查看响应码是 200 还是 304,以判断配置是否变更,做出相应的回调。之后再次发起下一次长轮询。
一个 Tomcat 默认也就 200 个线程,长轮询也不应该阻塞 Tomcat 的业务线程,所以需要配置中心在实现长轮询时,往往采用异步响应的方式来实现。
而比较方便实现异步 HTTP 的常见手段便是 Servlet3.0 提供的 AsyncContext 机制。