Speaker Identification
1.Goal
根据给定的语音内容,识别出说话者是谁
2.Data formats
2.1data directory
目录下有三个json文件和很多pt文件,三个json文件作用标注在下图中,pt文件就是语音内容。
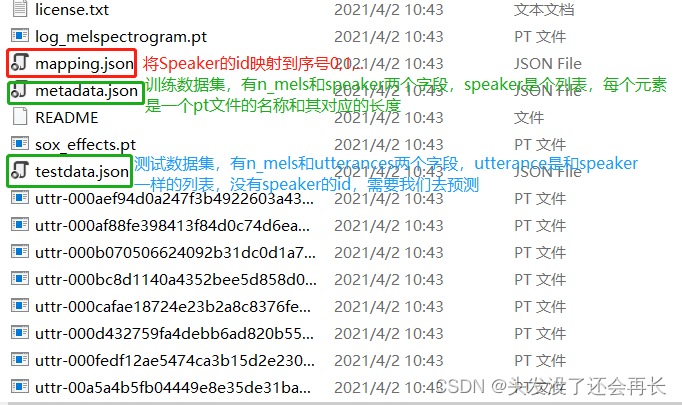
mapping文件

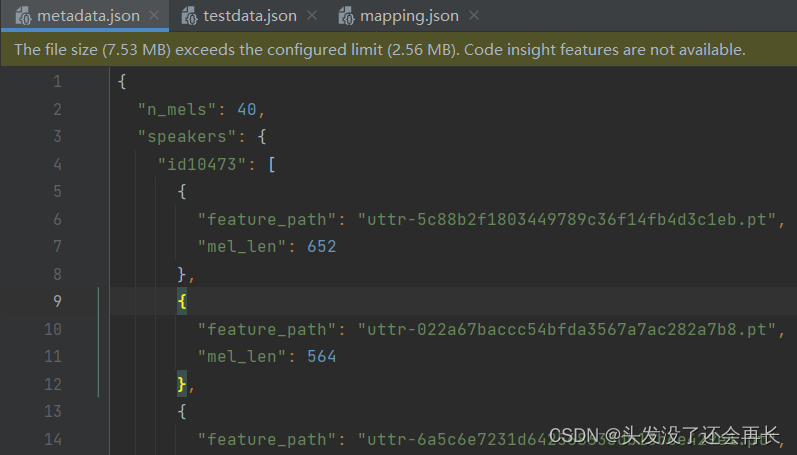
metadata文件
n_mels:The demission of mel-spectrogram(特征数是40)
speakers: A dictionary
- key: speaker id
- value: feature_path and mel_len
可以发现,pt文件内容长度不一样,所以后期需要我们自己统一长度
testdata文件

3.DataSet
构建自己的Dataset类,需要知道数据集的地址,由于每个数据长度不一样,所以还要规定数据的长度,返回值应该是,语音数据和对应的speaker的label
Dataset有三个重要的方法需要重写
- __init__(): 初始化,一般用于读取给定的数据到内存,在该任务中,需要从给定的路径中,读取语音path和label到data数组,读取mapping将speaker的id映射为对应序号。
- __getitem__(): 该方法根据传入的参数返回指定id的数据,在该任务中,对于传入的id,我们从data数组取出path和label,并将指定path的语音数据读出后分割,最后返回语音片段和对应的label。
- __len__(): 该方法返回数据集的长度,在该任务中,数据集的长度即data数组的长度。
代码如下:
import os
import json
import torch
import random
from pathlib import Path
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import Datasetclass myDataset(Dataset):def __init__(self, data_dir, segment_len=128):self.data_dir = data_dirself.segment_len = segment_len# Load the mapping from speaker neme to their corresponding id.mapping_path = Path(data_dir) / "mapping.json"mapping = json.load(mapping_path.open())self.speaker2id = mapping["speaker2id"] # 在mapping.json 文件中 字典的key是speaker2id# Load metadata of training data.metadata_path = Path(data_dir) / "metadata.json"metadata = json.load(open(metadata_path))["speakers"]# get the total number of speakerself.speaker_num = len(metadata.keys())self.data = []for speaker in metadata.keys():for utterance in metadata[speaker]:self.data.append([utterance["feature_path"], self.speaker2id[speaker]])def __len__(self):return len(self.data)def __getitem__(self, index):feature_path, speaker = self.data[index]# Load preprocessed mel-spectrogram.mel = torch.load(os.path.join(self.data_dir, feature_path))# segment mel-spectrogram into "segment_len" frames.if len(mel) >self.segment_len:start = random.randint(0, len(mel)-self.segment_len) #随便选取一个开始截取的位置 这个位置往后的长度要大于segment_lenmel = torch.FloatTensor(mel[start:start+self.segment_len])else:mel = torch.FloatTensor(mel)# Turn the speaker id into long for computing loss later.speaker = torch.FloatTensor([speaker]).longreturn mel, speakerdef get_speaker_number(self):return self.speaker_num最后的数据中,发言人一共600个,语音一共69438个
4.DataLoader
DataLoader的完整参数列表
class torch.utils.data.DataLoader( dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=<function default_collate>, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None)其中有一个参数
collate_fn,可能比较陌生
collate_fn作用:
在最后一步堆叠的时候可能会出现问题: 如果一条数据中所含有的每个数据元的长度不同, 那么将无法进行堆叠. 如: multi-hot类型的数据, 序列数据。在使用这些数据时, 通常需要先进行长度上的补齐, 再进行堆叠. 以现在的流程, 是没有办法加入该操作的。此外, 某些优化方法是要对一个batch的数据进行操作。collate_fn函数就是手动将抽取出的样本堆叠起来的函数。
所以我们需要自己定义collate_fn函数来统一特征大小
def collate_batch(batch):# Process features within a batchmel, speaker = zip(*batch)# Because we train the model batch by batch, we need to pad the features in the same batch to make their lengths the samemel = pad_sequence(mel, batch_first=True, padding_value=-20) # pad long 10^(-20) ehich is small value.# mel: (batch size, length, 40)return mel, torch.FloatTensor(speaker).long()
然后定义自己的dataloader,并在DataLoader中划分训练集和验证集
def get_dataloader(data_dir, batch_size, n_workers):dataset = myDataset(data_dir)speaker_num = dataset.get_speaker_number()# splittrainlen = int(0.9 * len(dataset))lengths = [trainlen, len(dataset) - trainlen]trainset, validset = random_split(dataset, lengths)train_loader = DataLoader(trainset,batch_size=batch_size,shuffle=True,num_workers=n_workers,drop_last=True,pin_memory=True,collate_fn=collate_batch,)valid_loader = DataLoader(validset,batch_size=batch_size,num_workers=n_workers,drop_last=True,pin_memory=True,collate_fn=collate_batch,)return train_loader, valid_loader
5.Define Model
分类器是由transformerEncoder和全连接层构成的,输入是mels(shape为[batch size, length, 40]),输出是out(shape为[batch size, length, d_model])
# -*- coding = utf-8 -*-
# @Time : 2023/4/7 14:44
# @Author : 头发没了还会再长
# @File : mdoel.py
# @Software : PyCharm
import torch
import torch.nn as nn
import torch.nn.functional as F
# 分类器 使用transformer
class Classifier(nn.Module):def __init__(self, d_model=80, n_spks=600, dropout=0.1):super().__init__()# project the dimession of features from that of input into d_modelself.prenet = nn.Linear(40, d_model)self.encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, dim_feadforeard=256, nhead=2)self.pred_layer = nn.Sequential(nn.Linear(d_model, d_model),nn.ReLU(),nn.Linear(d_model, n_spks),)def forward(self, mels):''':param mels: (batch size, length, 40):return: (batch size, length, d_model)'''out = self.prenet(mels)out = out.permute(1, 0, 2)out = self.encoder_layer(out)out = out.transpose(0, 1)stats = out.mean(dim=1)out = self.pred_layer(stats)return out6.Train and Valid
6.1 learning rate schedule
The warmup schedule
- Set learning rate to 0 in the beginning
- The learning rate increases linearly from 0 to initial learning rate during warmup period
import mathimport torch
from torch.optim import Optimizer
from torch.optim.lr_scheduler import LambdaLRdef get_cosine_schedule_with_warmup(optimizer: Optimizer,num_warmup_steps: int,num_training_steps: int,num_cycles: float = 0.5,last_epoch: int = -1,
):"""Create a schedule with a learning rate that decreases following the values of the cosine function between theinitial lr set in the optimizer to 0, after a warmup period during which it increases linearly between 0 and theinitial lr set in the optimizer.Args:optimizer (:class:`~torch.optim.Optimizer`):The optimizer for which to schedule the learning rate.num_warmup_steps (:obj:`int`):The number of steps for the warmup phase.num_training_steps (:obj:`int`):The total number of training steps.num_cycles (:obj:`float`, `optional`, defaults to 0.5):The number of waves in the cosine schedule (the defaults is to just decrease from the max value to 0following a half-cosine).last_epoch (:obj:`int`, `optional`, defaults to -1):The index of the last epoch when resuming training.Return::obj:`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule."""def lr_lambda(current_step):# Warmupif current_step < num_warmup_steps:return float(current_step) / float(max(1, num_warmup_steps))# decadenceprogress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))return LambdaLR(optimizer, lr_lambda, last_epoch)
6.2定义model_fn
输入一组batch,输出损失和准确率
def model_fn(batch, model, criterion, device):mels, labels = batchmels = mels.to(device)labels = labels.to(device)outs = model(mels)loss = criterion(outs, labels)preds = outs.argmax(1)accuracy = torch.mean((preds == labels).float())return loss, accuracy
6.3 validation
def valid(dataloader, model, criterion, device): """Validate on validation set."""model.eval()running_loss = 0.0running_accuracy = 0.0pbar = tqdm(total=len(dataloader.dataset), ncols=0, desc="Valid", unit=" uttr")for i, batch in enumerate(dataloader):with torch.no_grad():loss, accuracy = model_fn(batch, model, criterion, device)running_loss += loss.item()running_accuracy += accuracy.item()pbar.update(dataloader.batch_size)pbar.set_postfix(loss=f"{running_loss / (i+1):.2f}",accuracy=f"{running_accuracy / (i+1):.2f}",)pbar.close()model.train()return running_accuracy / len(dataloader)
6.4 有了前期的准备,就可以开始训练模型了
- 首先,需要准备训练数据,即加载dataloader,定义损失函数,优化器等
- 然后开始循环,在训练集上计算梯度反向传播,在验证集上计算准确率
- 存储最优的模型
def parse_args():"""arguments"""config = {"data_dir": "./Dataset","save_path": "model.ckpt","batch_size": 32,"n_workers": 8,"valid_steps": 2000,"warmup_steps": 1000,"save_steps": 10000,"total_steps": 70000,}return configdef main(data_dir,save_path,batch_size,n_workers,valid_steps,warmup_steps,total_steps,save_steps,
):"""Main function."""device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"[Info]: Use {device} now!")train_loader, valid_loader, speaker_num = get_dataloader(data_dir, batch_size, n_workers)train_iterator = iter(train_loader)print(f"[Info]: Finish loading data!",flush = True)model = Classifier(n_spks=speaker_num).to(device)criterion = nn.CrossEntropyLoss()optimizer = AdamW(model.parameters(), lr=1e-3)scheduler = get_cosine_schedule_with_warmup(optimizer, warmup_steps, total_steps)print(f"[Info]: Finish creating model!",flush = True)best_accuracy = -1.0best_state_dict = Nonepbar = tqdm(total=valid_steps, ncols=0, desc="Train", unit=" step")for step in range(total_steps):# Get datatry:batch = next(train_iterator)except StopIteration:train_iterator = iter(train_loader)batch = next(train_iterator)loss, accuracy = model_fn(batch, model, criterion, device)batch_loss = loss.item()batch_accuracy = accuracy.item()# Updata modelloss.backward()optimizer.step()scheduler.step()optimizer.zero_grad()# Logpbar.update()pbar.set_postfix(loss=f"{batch_loss:.2f}",accuracy=f"{batch_accuracy:.2f}",step=step + 1,)# Do validationif (step + 1) % valid_steps == 0:pbar.close()valid_accuracy = valid(valid_loader, model, criterion, device)# keep the best modelif valid_accuracy > best_accuracy:best_accuracy = valid_accuracybest_state_dict = model.state_dict()pbar = tqdm(total=valid_steps, ncols=0, desc="Train", unit=" step")# Save the best model so far.if (step + 1) % save_steps == 0 and best_state_dict is not None:torch.save(best_state_dict, save_path)pbar.write(f"Step {step + 1}, best model saved. (accuracy={best_accuracy:.4f})")pbar.close()if __name__ == "__main__":main(**parse_args())
这是训练过程中的截图:
7.Test
训练完模型,我们会得到最好的参数,并且保存在model.ckpt文件中了,接下来,只需要定义训练的函数,使用保存的最优模型开始训练即可。
测试和训练基本相同,需要准备dataset,dataloader
7.1 Inference dataset
class InferenceDataset(Dataset):def __init__(self, data_dir):testdata_path = Path(data_dir)metadata = json.load(testdata_path.open())self.data_dir = data_dirself.data = metadata["utterances"]def __len__(self):return len(self.data)def __getitem__(self, index):utterance = self.data[index]feature_path = utterance["feature_path"]mel = torch.load(os.path.join(self.data_dir, feature_path))return feature_path, mel
7.2可以开始预测啦
def inference_collate_batch(batch):feature_paths, mels = zip(*batch)return feature_paths, torch.stack(mels)def parse_args():"""arguments"""config = {"data_dir": "dataset","model_path": "./model.ckpt","output_path": "./output.csv",}return configdef main(data_dir,model_path,output_path,):device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"[Info]: Use {device} now!")mapping_path = Path(data_dir) / "mapping.json"mapping = json.load(mapping_path.open())dataset = InferenceDataset(data_dir)dataloader = DataLoader(dataset,batch_size=1,shuffle=False,drop_last=False,num_workers=0,collate_fn=inference_collate_batch,)print(f"[Info]: Finish loading data!", flush=True)speaker_num = len(mapping["id2speaker"])model = Classifier(n_spks=speaker_num).to(device)model.load_state_dict(torch.load(model_path))model.eval()print(f"[Info]: Finish creating model!", flush=True)results = [["Id", "Category"]]for feat_paths, mels in tqdm(dataloader):with torch.no_grad():mels = mels.to(device)outs = model(mels)preds = outs.argmax(1).cpu().numpy()for feat_path, pred in zip(feat_paths, preds):results.append([feat_path, mapping["id2speaker"][str(pred)]])with open(output_path, 'w', newline='') as csvfile:writer = csv.writer(csvfile)writer.writerows(results)