YOLO系列目标检测算法目录 - 文章链接
- YOLO系列目标检测算法总结对比- 文章链接
- YOLOv1- 文章链接
- YOLOv2- 文章链接
- YOLOv3- 文章链接
- YOLOv4- 文章链接
- Scaled-YOLOv4- 文章链接
- YOLOv5- 文章链接
- YOLOv6- 文章链接
- YOLOv7- 文章链接
- PP-YOLO- 文章链接
- PP-YOLOv2- 文章链接
- YOLOR- 文章链接
- YOLOS- 文章链接
- YOLOX- 文章链接
- PP-YOLOE- 文章链接
本文总结:
- 从一个独特的角度分析问题,人类理解事物可以通过正常的学习(称之为显性知识)或者潜意识地(称之为隐性知识)来学习,就可以从多个角度分析问题,所以考虑让模型也将显性知识和隐性知识一起编码,和人一样;
- 提出了一个可以完成各种任务的统一网络,它通过整合显性知识和隐性知识来学习一般表示,并且可以通过这种一般表示来完成各种任务;
- 在隐性知识学习过程中引入了kernel space alignment、prediction refinement和多任务学习;
- 分别讨论了利用向量、神经网络或矩阵分解作为工具对隐性知识进行建模的方法,同时验证了其有效性;
- 证实了所提出的隐性表示可以准确地对应一个特定的物理特征,也可以视觉的方式呈现它;
- 证实了如果一个运算符合一个目标的物理意义,它可以用来整合显性知识和隐性知识,会产生乘数效应;
- 结合最先进的方法,本文提出的统一网络在目标检测上达到了与Scaled-YOLO4-P7相当的精度,推理速度提高了88%。
深度学习知识点总结
专栏链接:
https://blog.csdn.net/qq_39707285/article/details/124005405
此专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
本章目录
- 1. 简介
- 1.1 问题分析
- 2. 相关知识
- 2.1 显性深度学习
- 2.2 隐性深度学习
- 2.3 知识建模
- 3. 隐性知识如何工作
- 3.1 Manifold space reduction
- 3.2 Kernel space alignment
- 3.3 More functions
- 4 隐性知识
- 4.1 公式表示
- 4.2 隐性知识建模
- 4.3 训练
- 4.4 推理
- 5. 模型与实验对比
- 5.1 模型构成
- 5.2 FPN特征对齐
- 5.3 目标检测预测细化
- 5.4 多任务处理的规范表示法
- 6. 结论
2021.5.10 YOLOR:《YOLOR:You Only Learn One Representation: Unified Network for Multiple Tasks》(您只学习一种表示法:针对多个任务的统一网络)
1. 简介
人们通过视觉、听觉、触觉和过去的经验来“理解”这个世界。人类的经验可以通过正常的学习(称之为显性知识),或者潜意识地(称之为隐性知识)来学习。【隐性知识存在于人的大脑中,是人在长期实践中积累起来的与个人经验密切相关的知识,往往是一些技巧,不易用语言表达,也不易被他人学习.显性知识,人们可以通过口头传授、教科书、参考资料、期刊杂志、专利文献、视听媒体、软件和数据库等方式获取,也可以通过语言、书籍、文字、数据库等编码方式传播,也容易被人们学习.】 这些通过正常学习或潜意识学到的经验将被编码并存储在大脑中,利用这些丰富的经验作为一个巨大的数据库,人类可以有效地处理数据,即使它们是事先没有看到的。
在本文中,提出了一个统一的网络,将显性知识和隐性知识一起编码,就像人类大脑可以从正常学习和潜意识学习中学习知识一样。统一的网络可以生成一个统一的表示法,同时服务于各种任务。可以在卷积神经网络中执行核空间对齐、预测细化和多任务学习。
结果表明,当将隐性知识引入神经网络时,有利于所有任务的性能。然后进一步分析了从提出的统一网络中学习到的隐性表示,展示了捕捉不同任务物理意义的能力。
1.1 问题分析

如上图所示,人类可以从不同的角度来分析同一条数据。然而,一个经过训练的卷积神经网络(CNN)模型通常只能满足一个目标。
一般来说,从训练过的CNN中提取的特征通常很难适应其他类型的问题。造成上述问题的主要原因是我们只从神经元中提取特征,而没有使用CNN中丰富的隐式知识。当真实的人的大脑在工作时,上述的隐性知识可以有效地帮助大脑执行各种任务。
隐性知识是指在潜意识状态下所学到的知识,但是没有一个系统的定义隐性学习是如何运作的,以及如何获取隐性知识。在神经网络的一般定义中,从浅层获得的特征通常被称为显性知识,而从深层获得的特征则被称为隐性知识。在本文中,将直接对应于观察的知识称为显性知识。对于模型中隐含的、与观察无关的知识,称之为隐性知识。
本文提出了一个统一的网络来整合隐性知识和显性知识,并使学习到的模型包含一个通用的表示,而这种通用的表示使子表示适合于各种任务。图2. ©展示了所提出的统一网络架构,构建统一网络的方法是将压缩感知和深度学习相结合。

2. 相关知识
完成本文算法的设计,需要用到一些知识,主要分为三个方面:
- 显性深度学习:涵盖一些可以根据输入数据自动调整或选择特征的方法;
- 隐性深度学习:涵盖隐式深度知识学习和隐式微分导数;
- 知识建模:列出几种方法,可用于集成显性知识和隐性知识。
2.1 显性深度学习
显式深度学习可以通过以下方式进行:
- Transformer是一种方式,它主要使用query、key或value来获得self-attention;
- Non-local网络是另一种获得attention的方式,它主要在时间和空间上提取成对的注意力;
- 另一种常用的显性深度学习方法是通过输入数据自动选择合适的核。
2.2 隐性深度学习
属于隐性深度学习范畴的方法主要是隐性神经表征和深度平衡模型,前者主要是获得离散输入的参数化连续映射表示,以执行不同的任务,而后者主要是将隐性学习转化为残差形式的神经网络,并对其进行平衡点计算。
2.3 知识建模
对于属于知识建模范畴的方法,主要包括稀疏表示和memory network。前者使用范例、预定义的完整字典或学习字典来执行建模,而后者依赖于结合各种嵌入形式来形成内存,并使内存能够动态地添加或更改内存。
3. 隐性知识如何工作
本文研究的主要目的是建立一个能够有效训练隐性知识的统一网络,因此我们首先关注如何快速训练和推理隐性知识。由于隐性表示ziz_izi与观测无关,所以可以把它看作是一组常数张量z=z1,z2,⋅⋅⋅,zkz={z_1,z_2,···,z_k}z=z1,z2,⋅⋅⋅,zk,下面介绍如何将隐性知识作为常数张量应用于各种任务。
3.1 Manifold space reduction

一个好的表示应该能够在它所属的流形空间中找到一个适当的投影,并促进后续的目标任务的成功。例如,如图3所示,如果投影空间中的超平面能够成功地分类目标类别,这将是最好的结果。在上面的例子中,我们可以利用投影向量和隐式表示的内积来实现降低流形空间的降维,有效地实现各种任务的目标。
3.2 Kernel space alignment

在多任务和multi_head神经网络中,核空间错位是一个常见的问题,图4. (a)展示了多任务和multi_head神经网络中核空间错位的一个例子。为了解决这个问题,可以对输出特征和隐式表示进行加法和乘法,使核空间进行平移、旋转和缩放,以对齐神经网络的每个输出核空间,如图4(b)所示。上述操作模式可以广泛应用于不同的领域,如特征的大目标和小目标的排列在特征金字塔网络(FPN),使用知识蒸馏集成大模型和小模型,处理zero-shot域转移等问题。
3.3 More functions

除了可以应用于不同任务的函数外,隐式知识还可以扩展到更多的函数中。如图5所示,通过引入加法,可以通过神经网络来预测中心坐标的偏移量。还可以引入乘法来自动搜索锚点的超参数集,这是基于锚点的目标检测器经常需要的。此外,还可以分别使用点乘法和连接法来进行多任务特征选择,并为后续计算设置先决条件。
4 隐性知识
在本节中,我们将比较传统网络的目标函数和所提出的统一网络,并解释为什么引入隐式知识对于训练多用途网络很重要。同时,也将详细阐述本文中提出的方法的细节。
4.1 公式表示
- 在卷积神经网络中
对于传统的网络训练的目标函数,可以使用(1)来表示如下:

其中x为观察值,θ为神经网络的参数集,fθ表示神经网络的操作,ϵ\epsilonϵ 为误差项,y为给定任务的目标。
在传统神经网络的训练过程中,通常会将ϵ\epsilonϵ最小化,使fθ(x)尽可能接近目标。这意味着我们期望具有相同目标的不同观测结果是由fθ获得的子空间中的一个单个点,如图6(a)所示。换句话说,我们期望得到的解空间仅对当前任务tit_iti有区别,并且对各种潜在任务以外的任务不变,T∖tiT\setminus t_iT∖ti,其中T={t1,t2,...,tn}T=\{t_1,t_2,...,t_n\}T={t1,t2,...,tn}。
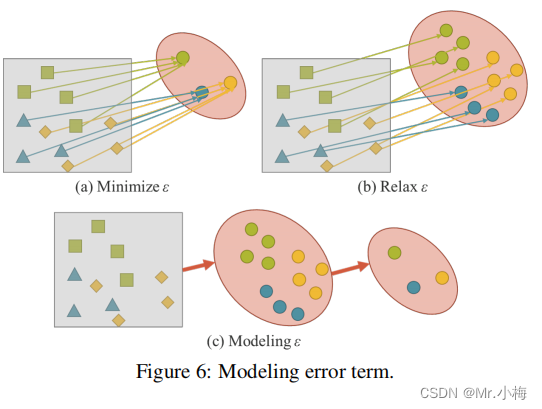
对于一般用途的神经网络,我们希望所得到的表示能够服务于属于TTT的所有任务,因此,我们需要放松ϵ\epsilonϵ,使其能够在流形空间上同时找到每个任务的解,如图6(b)所示。但是,上述要求使得我们不可能使用一个简单的数学方法,如one-hot向量的最大值,或欧氏距离的阈值,来得到tit_iti的解。为了解决这个问题,我们必须对误差项ϵ\epsilonϵ进行建模,以找到不同任务的解决方案,如图6(c)所示。
- 统一网络
为了训练所提出的统一网络,我们同时使用显性知识和隐性知识来建模误差项,然后使用它来指导多用途网络训练过程。对应的训练公式如下:

其中ϵex\epsilon_{ex}ϵex和ϵim\epsilon_{im}ϵim分别是对观测x和潜在码z的显性误差和隐性误差进行建模的操作。gϕg_\phigϕ在这里是一个特定于任务的操作,它用于从显性知识和隐性知识中组合或选择信息。
有一些现有的方法可以将显性知识集成到fθf_θfθ中,所以可以将(2)重写为(3):

⋆\star⋆表示一些可以组合fθf_θfθ和gφg_φgφ的可能的操作符,在本文中,将使用加法、乘法和连接运算。
如果将误差项的推导过程扩展到处理多个任务,可以得到以下公式:

其中Z={z1,z2,⋅⋅⋅,zT}Z=\{z_1,z_2,···,z_T\}Z={z1,z2,⋅⋅⋅,zT}是一组包含T个不同任务的隐式潜码,Φ是可以用来从Z中生成隐式表示的参数。Ψ用于计算显性表示和隐式表示的不同组合的最终输出参数。
对于不同的任务,可以使用以下公式来得到对所有z∈Z的预测:

对于所有的任务,从一个共同的统一表示fθ(x)f_θ(x)fθ(x)开始,通过特定任务的隐式表示gΦ(z)g_Φ(z)gΦ(z),最后使用特定任务的鉴别器dΨd_ΨdΨ完成不同的任务。
4.2 隐性知识建模
本文提出的隐式知识可以用以下方式进行建模:
- 向量/矩阵/张量:zzz
直接使用向量z作为隐式知识的先验,并直接作为隐式表示。此时,必须假定每个维度都是相互独立的。 - 神经网络:WzW_zWz
利用向量z作为隐式知识的先验,然后利用权值矩阵W进行线性组合或非线性化,然后成为隐式表示。此时,必须假定每个维度都是相互依赖的。也可以使用更复杂的神经网络来生成隐式表示。或者使用马尔可夫链来模拟不同任务之间的隐式表示的相关性。 - 矩阵分解:ZcTZ^T_cZcT
使用多个向量作为隐式知识的先验,这些隐式先验基Z和系数c将形成隐式表示。我们还可以进一步对c进行稀疏约束,并将其转换为稀疏表示形式。此外,我们还可以对Z和c施加非负约束,将它们转换为非负矩阵分解(NMF)形式。
4.3 训练
假设我们的模型在开始时没有任何先验隐式知识,也就是说,它对显式表示fθ(x)f_θ(x)fθ(x)没有任何影响。当组合运算⋆∈{addition,concatenation}\star∈ \{addition, concatenation\}⋆∈{addition,concatenation},初始隐式先验z∼N(0,σ)z∼N(0,σ)z∼N(0,σ),当组合运算⋆是multiplication时,z∼N(1,σ)}\star 是multiplication时,z∼N(1,σ)\}⋆是multiplication时,z∼N(1,σ)}。在这里,σ是一个非常小的值,它接近于零。对于z和φ,它们在训练过程中都采用了反向传播算法进行训练。
4.4 推理
由于隐式知识与观测x无关,无论隐式模型gϕg_\phigϕ有多复杂,在推理阶段执行之前,都可以将其简化为一组常数张量。换句话说,隐式信息的形成对本文的算法的计算复杂度几乎没有影响。此外,当上面的算符是乘法时,如果后面的层是卷积层,那么使用下面的式(9)进行积分。当遇到一个加法运算符时,如果前一层是一个卷积层,并且它没有激活函数,那么可以使用下面所示的式(10)进行积分。

5. 模型与实验对比
5.1 模型构成

选择将隐性知识应用于三个方面,包括1) FPN特征对齐,2) 预测细化,3) 单一模型中的多任务学习。多任务学习所覆盖的任务包括1) 目标检测、2) 多标签图像分类和3) 特征嵌入。本文选择YOLOv4- CSP作为基线模型,并在图8中箭头所指的位置将隐式知识引入到模型中。将所有的训练超参数与ScaledYOLOv4的默认设置进行比较。
5.2 FPN特征对齐
在每个FPN的特征映射中添加隐式表示,用于特征对齐,相应的实验结果如表1所示。从表1所示的结果可以看出:在使用隐式表示进行特征空间对齐后,所有的性能,包括APs、APm和APl,都提高了约0.5%。

5.3 目标检测预测细化
把隐式表示添加到YOLO输出层中,以进行预测细化。如表2所示,可以看到几乎所有的指标分数都得到了提高。

图9展示了隐式表示的引入如何影响检测结果。在目标检测的情况下,即使我们不提供任何隐式表示的先验知识,所提出的学习机制仍然可以自动学习每个锚点的(x、y)、(w、h)、(obj)和(classes)模式。

5.4 多任务处理的规范表示法
6. 结论
在本文中,展示了如何构建一个整合显性知识和隐性知识的统一网络,并证明了它在单一模型架构下的多任务学习仍然是非常有效的。