前言
大家好,我是阳哥。
今天和大家聊聊Go语言的「内存分配」和「逃逸分析」。
这期内容不仅有文档,而且有视频:
# Go语言的内存分配和逃逸分析-理论篇
# Go语言的内存分配和逃逸分析-实践总结篇
要搞清楚GO的逃逸分析一定要先搞清楚内存分配和堆栈:
内存既可以分配到堆中,也可以分配到栈中。
GO语言是如何进行内存分配的呢?其设计初衷和实现原理是什么呢?
要搞清楚上面的问题,我们先来聊一下内存管理和堆、栈的知识点:
内存管理
内存管理主要包括两个动作:分配与释放。逃逸分析就是服务于内存分配的,而内存的释放由GC负责。
栈
在Go语言中,栈的内存是由编译器自动进行分配和释放的,栈区往往存储着函数参数、局部变量和调用函数帧,它们随着函数的创建而分配,随着函数的退出而销毁。
Go应用程序运行时,每个 goroutine 都维护着一个自己的栈区,这个栈区只能自己使用不能被其他 goroutine 使用。栈是调用栈(call stack)的简称。一个栈通常又包含了许多栈帧(stack frame),它描述的是函数之间的调用关系
堆
与栈不同的是,堆区的内存一般由编译器和工程师自己共同进行管理分配,交给 Runtime GC 来释放。在堆上分配时,必须找到一块足够大的内存来存放新的变量数据。后续释放时,垃圾回收器扫描堆空间寻找不再被使用的对象。
我们可以简单理解为:我们用GO语言开发过程中,要考虑的内存管理只是针对堆内存而言的。
程序在运行期间可以主动从堆上申请内存,这些内存通过Go的内存分配器分配,并由垃圾收集器回收。
为了方便大家理解,我们再从以下角度对比一下堆栈:
堆和栈的对比
加锁
-
栈不需要加锁:每个goroutine都独享自己的栈空间,这就意味着栈上的内存操作是不需要加锁的。
-
堆有时需要加锁:堆上的内存,有时需要加锁防止多线程冲突
延伸知识点:为什么堆上的内存有时需要加锁?而不是一直需要加锁呢?
因为Go的内存分配策略学习了TCMalloc的线程缓存思想,他为每个处理器分配了一个mcache,注意:从mcache分配内存也是无锁的。
关注我,后面带大家详解这部分知识点。
性能
- 栈内存管理 性能好:栈上的内存,它的分配与释放非常高效的。简单地说,它只需要两个CPU指令:一个是分配入栈,另外一个是栈内释放。只需要借助于栈相关寄存器即可完成。
- 堆内存管理 性能差:对于程序堆上的内存回收,还需要有标记清除阶段,例如Go采用的三色标记法。
缓存策略
- 栈缓存性能更好
- 堆缓存性能较差
原因是:栈内存能更好地利用CPU的缓存策略,因为栈空间相较于堆来说是更连续的。
下面就介绍今天的重头戏了:
逃逸分析
上面说了这么多堆和栈的知识点,目的是为了让大家更好的理解逃逸分析。
正如上面讲的,相比于把内存分配到堆中,分配到栈中优势更明显。
Go语言也是这么做的:Go编译器会尽可能将变量分配到到栈上。
但是,在函数返回后无法证明变量未被引用,则该变量将被分配到堆上,该变量不随函数栈的回收而回收。以此避免悬挂指针(dangling pointer)的问题。
另外,如果局部变量占用内存非常大,也会将其分配在堆上。
Go是如何确定内存是分配到栈上还是堆上的呢?
答案就是:逃逸分析。
编译器通过逃逸分析技术去选择堆或者栈,逃逸分析的基本思想如下:检查变量的生命周期是否是完全可知的,如果通过检查,则在栈上分配。否则,就是所谓的逃逸,必须在堆上进行分配。
逃逸分析原则
Go语言虽然没有明确说明逃逸分析原则,但是有以下几点准则,是可以参考的。
- 不同于JAVA JVM的运行时逃逸分析,Go的逃逸分析是在编译期完成的:编译期无法确定的参数类型必定放到堆中;
- 如果变量在函数外部存在引用,则必定放在堆中;
- 如果变量占用内存较大时,则优先放到堆中;
- 如果变量在函数外部没有引用,则优先放到栈中;
逃逸分析举例
我们使用这个命令来查看逃逸分析的结果: go build -gcflags '-m -m -l'
1.参数是interface类型
package mainimport "fmt"func main() {
a := 666
fmt.Println(a)
}
运行结果

原因分析
因为Println(a …interface{})的参数是interface{}类型,编译期无法确定其具体的参数类型,所以内存分配到堆中。

2. 变量在函数外部有引用
package mainfunc test() *int {
a := 10
return &a
}func main() {
_ = test()
}
运行结果

原因分析
变量a在函数外部存在引用。
我们来分析一下执行过程:当函数执行完毕,对应的栈帧就被销毁,但是引用已经被返回到函数之外。如果这时外部通过引用地址取值,虽然地址还在,但是这块内存已经被释放回收了,这就是非法内存。
为了避免上述非法内存的情况,在这种情况下变量的内存分配必须分配到堆上。
3. 变量内存占用较大
package mainfunc test() {
a := make([]int, 10000, 10000)
for i := 0; i < 10000; i++ {
a[i] = i
}
}func main() {
test()
}
运行结果

原因分析
我们定义了一个容量为10000的int类型切片,发生了逃逸,内存分配到了堆上(heap)。
注意看:
我们再简单修改一下代码,将切片的容量和长度修改为1,再次查看逃逸分析的结果,我们发现,没有发生逃逸,内存默认分类到了栈上。
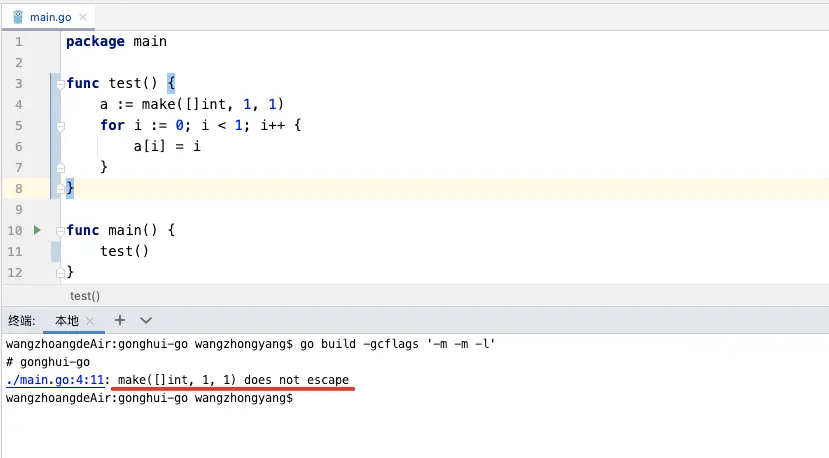
所以,当变量占用内存较大时,会发生逃逸分析,将内存分配到堆上。
4. 变量大小不确定时
我们再简单修改一下上面的代码:
package mainfunc test() {
l := 1
a := make([]int, l, l)
for i := 0; i < l; i++ {
a[i] = i
}
}func main() {
test()
}
运行结果
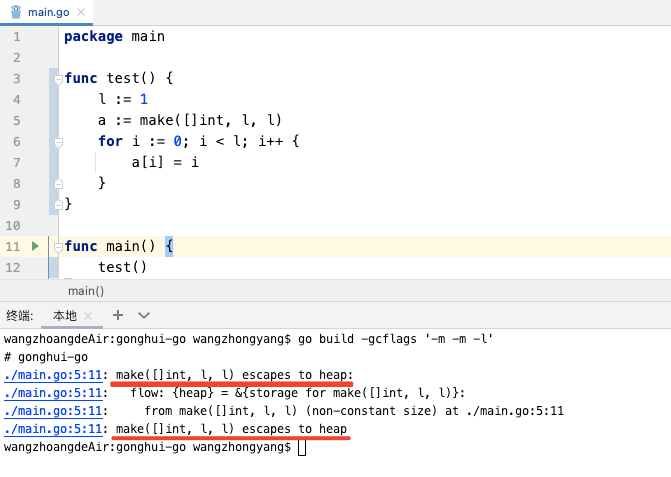
原因分析
我们通过控制台的输出结果可以很明显的看出:发生了逃逸,分配到了heap堆中。
原因是这样的:
我们虽然在代码段中给变量 l 赋值了1,但是编译期间只能识别到初始化int类型切片时,传入的长度和容量是变量l,编译期并不能确定变量l的值,所以发生了逃逸,会把内存分配到堆中。
思考题
好了,我们举了4个逃逸分析的经典案例,相信聪明的你已经理解了逃逸分析的作用和发生逃逸的场景。
我们来想一下,在理解逃逸分析的原理之后,在开发的过程中如何更好的编码,进而提高程序的效率,更好的利用内存呢?
如何实践?
理解逃逸分析一定能帮助我们写出更好的程序。知道变量分配在栈堆之上的差别后,我们就要尽量写出分配在栈上的代码。因为堆上的变量变少后,可以减轻内存分配的开销,减小GC的压力,提高程序的运行速度。
但是我们也要有过犹不及的指导思想。
我认为没有一成不变的开发模式,我们一定是在不断的需求变化,业务变化中求得平衡的:
举个栗子
举个日常开发中函数传参例子:
有些场景下我们不应该传递结构体指针,而应该直接传递结构体。
为什么会这样呢?虽然直接传递结构体需要值拷贝,但是这是在栈上完成的操作,开销远比变量逃逸后动态地在堆上分配内存少的多。
当然这种做法不是绝对的,要根据场景去分析:
- 如果结构体较大,传递结构体指针更合适,因为指针类型相比值类型能节省大量的内存空间
- 如果结构体较小,传递结构体更适合,因为在栈上分配内存,可以有效减少GC压力
总结
通过本文的介绍,相信你一定加深了堆栈的理解;搞清楚逃逸分析的作用和原理之后能够指导我们写出更优雅的代码。
我们在日常开发中,要根据实际场景考虑,如何将内存尽量分配到栈中,减少GC的压力,提高性能。
如何找到应用开发效率、程序运行效率、对机器的压力及负载的平衡点,是程序员进阶之旅中的必修课。
更多资料
因为C站不支持添加太多外链,需要上述资源链接的朋友可以加入我在CSDN创建的社区:
点这里—>加入高质量学编程专属群👏👏👏