在上一篇博客中讲到位图是用来判定一个正整数是否存在的。对于一个负数,我们可以统一规定让他们加上一个数,变成正数,然后用位图的方式存储。但是对于字符串,我们就没办法存储了。因此发明了布隆过滤器
概念
对于网络上很多需要判定是否存在的字符串信息(例如垃圾邮件的地址),我们没有办法使用位图或者其他数据结构来高效的查找。因此发明了布隆过滤器
布隆过滤器是将一个字符串通过多个哈希函数,得到不容的正数,然后将这些正数插入到位图中。由于其他的字符串也可能哈希出一样的值,多个字符串就可能哈希到重合的位置上。因此布隆过滤器的查找并不是准确的,而是得出——这个字符串一定不存在,或者这个字符串可能存在
当一个字符串哈希成不同的值后,分别判断这些值是否在位图上存在,如果有一个不存在,则可以判断这个字符串一定不存在(如果存在,那么在存储时这些值都应该存在)。而如果这些值都存在,这个字符串也不能说是百分百存在的,因为可能这些值都是别的字符串哈希后存储的
可以看到,布隆过滤器在效率和空间上都是十分优秀的,并且,我们存储的位图并不包含字符串的相关信息,因此也认为是一种安全的存储方式
MyBloomFilter
SimpleHash
先创建一个自己的哈希函数
这里我们需要传输当前的容量和随机的种子,不同的种子就会产生不同的哈希值
然后定义一个hash方法,在之后,我们将调用这个hash方法,来将字符串转换为不同的正数
这里的哈希值计算和源码的形成方法类似
class SimpleHash {public int capacity;// 当前容量public int seed; //随机种子public SimpleHash(int capacity, int seed){this.capacity = capacity;this.seed = seed;}/*** 根据不同的seed,创建不同的哈希函数* @param key* @return*/int hash(String key){int h;return (key == null) ? 0 : (seed * (capacity - 1)) & ((h = key.hashCode()) ^ (h >>> 16));}
}
定义
定义SimpleHash的默认容量,SimpleHash中用到的所有种子,然后在初始化MyBloomFilter的时候,创建所有的SimpleHash,给他们赋不同的种子
public final int DEFAULT_SIZE = 1 << 20;
public BitSet bitSet;
public int usedSize;
public static final int[] seeds = {5,7,11,13,27,33};
public SimpleHash[] simpleHashes;public MyBloomFilter(){bitSet = new BitSet(DEFAULT_SIZE);simpleHashes = new SimpleHash[seeds.length];for (int i = 0; i < simpleHashes.length; i++) {simpleHashes[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);}
}
add方法
遍历每一个SimpleHash,调用其中的hash方法,传入字符串得到不同的index,然后用位图将这些index设置为true,最后让usedSize++
/*** 添加val到布隆过滤器* @param val*/
public void add(String val){// 用X个不同的哈希函数处理数据//将处理后的数据存储在位图中for (SimpleHash simpleHash : simpleHashes) {int index = simpleHash.hash(val);bitSet.set(index);}usedSize++;
}
contains方法
还是调用所有的SimpleHash中的hash方法,得到所有的index,然后判断这些index在位图中是否存在,如果不存在,说明这个字符串一定不存在,如果存在,只能说明这个字符串可能存在
/*** 判断val是否存在* @param val* @return 可能存在(返回true) / 一定不存在(返回false)*/
public boolean contains(String val){for (SimpleHash simpleHash : simpleHashes) {int index = simpleHash.hash(val);if(!bitSet.get(index)){return false;}}return true;
}
test测试
public class test {public static void main(String[] args) {MyBloomFilter myBloomFilter = new MyBloomFilter();myBloomFilter.add("hello");myBloomFilter.add("hello2");myBloomFilter.add("hi");myBloomFilter.add("world");myBloomFilter.add("xiao");System.out.println(myBloomFilter.contains("hello"));System.out.println(myBloomFilter.contains("hello1"));System.out.println(myBloomFilter.contains("hahahaha"));}
}
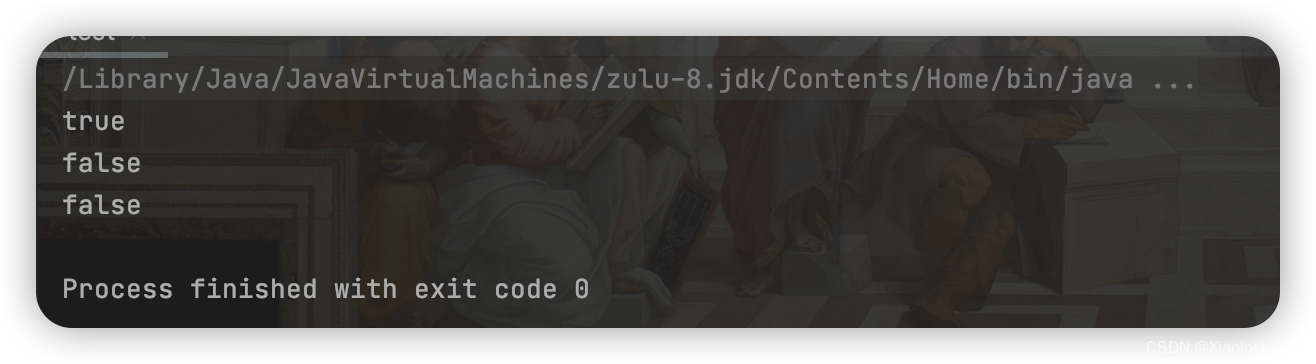
可以看到我们得到的结果是正确的
外部引用
谷歌也有布隆过滤器的实现,可以用maven引用
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>19.0</version>
</dependency>
可以分别传入自己要插入的数据的个数和期待的误判率是多高
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;public class Test {private static int size = 1000000;//预计要插入多少数据private static double fpp = 0.01;//期望的误判率private static BloomFilter<Integer> bloomFilter= BloomFilter.create(Funnels.integerFunnel(), size, fpp);public static void main(String[] args) {//插入数据for (int i = 0; i < 1000000; i++) {bloomFilter.put(i);}int count = 0;for (int i = 1000000; i < 2000000; i++) {if (bloomFilter.mightContain(i)) {count++;System.out.println(i + "误判了");}}System.out.println("总共的误判数:" + count);}}
最终得到的误判个数是接近误判率的
![[附源码]Python计算机毕业设计高校学生管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/1b20d5c2e061491fb237e428fc269450.png)