源码和数据集请点赞关注收藏后评论区留言私信~~~
一、统计单词出现次数
单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版“Hello World。其主要功能是统计一系列文本文件中每个单词出现的次数
程序解析
首先MapReduce将文件拆分成splits,由于测试用的文件较小,只有二行文字,所以每个文件为一个split,并将文件按行分割形成<key, value>对,如下图所示,这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows和Linux环境会不同)

(2)将分割好的<key, value>对交给用户定义的Map方法进行处理,生成新的<key, value>对

(3)得到Map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果

(4)Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的Reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果

主要编写Map和Reduce函数.这个Map函数使用StringTokenizer函数对字符串进行分隔,通过write方法把单词存入word中 k/v来自于Map函数中的context,可能经过了进一步处理(combiner),同样通过context输出
运行程序后通过浏览器访问页面即可获取结果

代码如下
package com.bigdata.wc;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;import java.io.IOException;
import java.util.StringTokenizer;public class WordCount {public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());System.out.println(word);context.write(word, one);}}}public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {System.setProperty("hadoop.home.dir", "D:\\hadoop-2.7.0");System.setProperty("HADOOP_USER_NAME", "root");Configuration conf = new Configuration();conf.set("yarn.resourcemanager.address", "bigdata01:8032");conf.set("dfs.client.use.datanode.hostname", "true");conf.set("fs.defaultFS", "hdfs://bigdata02:9000/");conf.set("mapreduce.app-submission.cross-platform", "true");conf.set("mapreduce.framework.name", "yarn");conf.set("mapred.jar","D:\\hadoopdemo\\WordCount\\target\\WordCount-1.0-SNAPSHOT-jar-with-dependencies.jar");String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for (int i = 0; i < otherArgs.length - 1; ++i) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}FileOutputFormat.setOutputPath(job,new Path(otherArgs[otherArgs.length - 1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
二、倒排索引
倒排索引是文档检索系统中最常用的数据结构,被广泛应用于全文搜索引擎。倒排索引主要用来存储某个单词(或词组)在一组文档中的存储位置的映射,提供了可以根据内容来查找文档的方式,而不是根据文档来确定内容,因此称为倒排索引(Inverted Index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(Inverted File)。

现假设有三个源文件file1.txt、file2.txt和file3.txt,需要使用倒排索引的方式对这三个源文件内容实现倒排索引,并将最后的倒排索引文件输出。
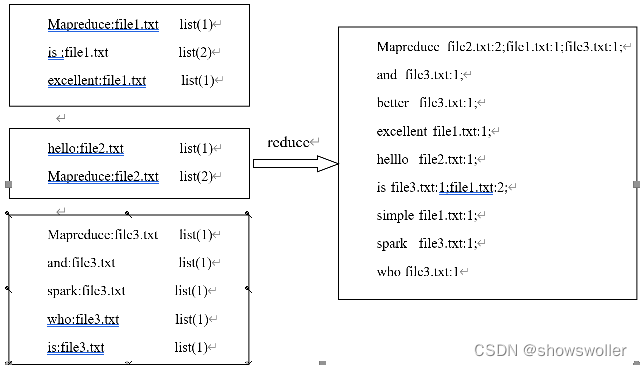
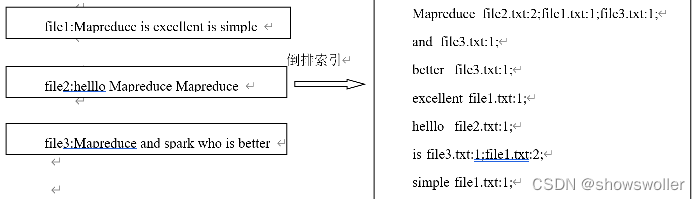 首先,使用默认的TextInputFormat类对每个输入文件进行处理,得到文本中每行的偏移量及其内容。Map过程首先分析输入的<key,value>键值对,经过处理可以得到倒排索引中需要的三个信息:单词、文档名称和词频。
首先,使用默认的TextInputFormat类对每个输入文件进行处理,得到文本中每行的偏移量及其内容。Map过程首先分析输入的<key,value>键值对,经过处理可以得到倒排索引中需要的三个信息:单词、文档名称和词频。

经过Map阶段数据转换后,同一个文档中相同的单词会出现多个的情况,而单纯依靠后续Reduce阶段无法同时完成词频统计和生成文档列表,所以必须增加一个Combine阶段,先完成每一个文档的词频统计。
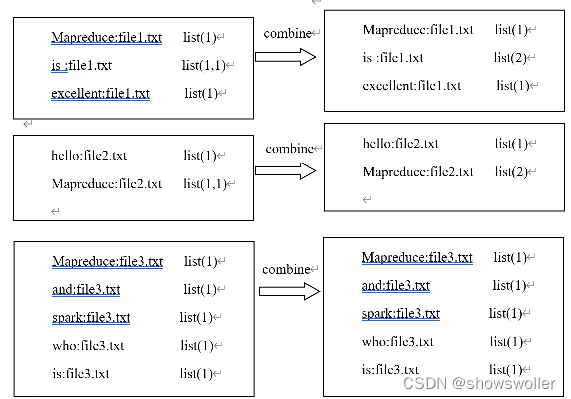
经过上述两个阶段的处理后,Reduce阶段只需将所有文件中相同key值的value值进行统计,并组合成倒排索引文件所需的格式。
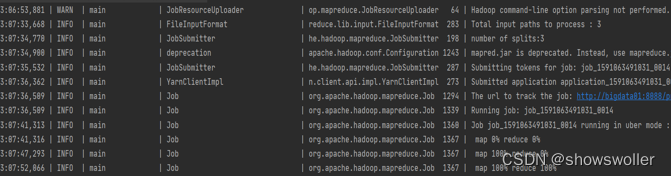
效果测试如下

部分代码如下 全部代码和数据集请点赞关注收藏后评论区留言私信
package com.mr.InvertedIndex;import java.io.IOException;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class InvertedIndexReducer extends Reducer<Text, Text, Text, Text> { private static Text result = new Text(); // 输入:<MapReduce file3:2> // 输出:<MapReduce file1:1;file2:1;file3:2;> @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // 生成文档列表 String fileList = new String(); for (Text value : values) { fileList += value.toString() + ";"; } result.set(fileList); context.write(key, result); }
} 创作不易 觉得有帮助请点赞关注收藏~~~


![[附源码]Python计算机毕业设计个人资金账户管理Django(程序+LW)](https://img-blog.csdnimg.cn/4334d7afb2f34075ae531ea2f6730b86.png)