机器学习 (ML) 研究的多个子领域(例如计算机视觉和自然语言处理)的最新重大进展是通过一种共享的通用方法实现的,该方法利用大型、多样化的数据集和能够有效吸收所有数据的表达模型。尽管已经有各种尝试将这种方法应于机器人技术,但机器人尚未利用高性能模型以及其他子领域。
有几个因素促成了这一挑战。首先,缺乏大规模和多样化机器人数据,这限制了模型吸收广泛机器人经验的能力。数据收集对于机器人技术来说特别昂贵且具有挑战性,因为数据集管理需要工程量大的自主操作,或使用人类远程操作收集的演示。第二个因素是缺乏可从此类数据集中学习并有效泛化的表达力强、可扩展且速度足够快的实时推理模型。
为了应对这些挑战,我们(谷歌)提出了Robotics Transformer 1 (RT-1),这是一种多任务模型,可以标记机器人输入和输出动作(例如,相机图像、任务指令和电机命令)以在运行时实现高效推理,它使实时控制成为可能。该模型在包含 130k 集的大规模、真实世界的机器人数据集上进行训练,该数据集涵盖 700 多项任务,使用来自Everyday Robots的 13 个机器人组成的车队收集(EDR) 超过 17 个月。我们证明,与现有技术相比,RT-1 可以显着改进对新任务、环境和对象的零样本泛化。此外,我们仔细评估和消融了模型和训练集中的许多设计选择,分析了标记化、动作表示和数据集组成的影响。最后,我们将RT-1 代码开源,希望它能为未来扩大机器人学习的研究提供宝贵的资源。
RT-1
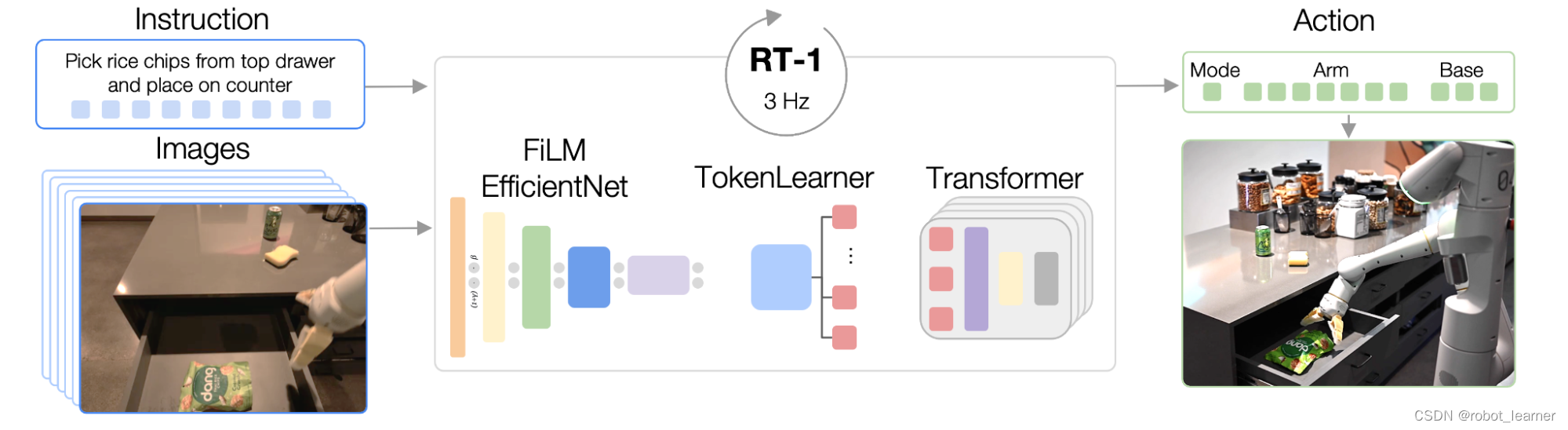
RT-1 建立在一个转换器架构 (transformer)上,该架构从机器人的相机中获取图像的简短历史以及以自然语言表达的任务描述作为输入,并直接输出标记化的动作。
RT-1 的体系结构类似于针对具有因果掩蔽的标准分类交叉熵目标训练的当代仅解码器序列模型。其主要功能包括:图像标记化、动作标记化和标记压缩,如下所述。
图像标记化:我们通过在ImageNet上预训练的EfficientNet-B3 模型传递图像,然后将生成的 9×9×512 空间特征图扁平化为 81 个标记。图像分词器以自然语言任务指令为条件,并使用初始化为身份的 FiLM 层在早期提取与任务相关的图像特征。
动作标记化:机器人的动作维度是手臂运动的 7 个变量(x、y、z、滚动、俯仰、偏航、夹具打开),3 个基本运动变量(x、y、偏航),以及一个额外的离散变量来切换在三种模式之间:控制臂、控制基地或终止剧集。每个动作维度被离散化为 256 个 bin。
令牌压缩:该模型自适应地选择图像令牌的软组合,这些组合可以根据它们对使用元素注意模块TokenLearner进行学习的影响进行压缩,从而使推理速度提高 2.4 倍以上。
为了构建一个可以泛化到新任务并显示出对不同干扰因素和背景的鲁棒性的系统,我们收集了一个大型、多样化的机器人轨迹数据集。我们使用了 13 个 EDR 机器人操纵器,每个都带有 7 个自由度的手臂、一个 2 指夹持器和一个移动底座,在 17 个月内收集了 13 万集。我们使用人类通过远程操作提供的演示,并用机器人刚刚执行的指令的文本描述对每一集进行注释。数据集中表示的一组高级技能包括拾取和放置物品、打开和关闭抽屉、将物品放入和取出抽屉、将细长的物品直立放置、将物体打翻、拉餐巾和打开罐子。生成的数据集包括 130k+ 集,涵盖使用许多不同对象的 700 多个任务。
实验和结果
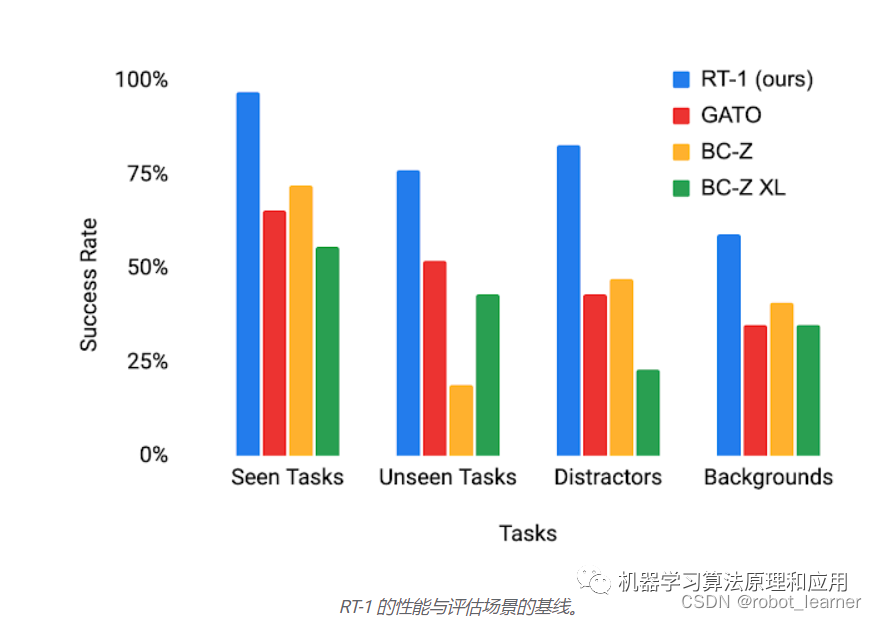
为了更好地理解 RT-1 的泛化能力,我们研究了它针对三个基线的性能:Gato、BC-Z 和 BC-Z XL(即具有与 RT-1 相同数量的参数的 BC-Z),分为四个类别:
1.Seen tasks performance:在训练期间 看到的任务表现
- 看不见的任务表现:在看不见的任务上的表现,其中技能和对象在训练集中是分开看到的,但以新颖的方式组合在一起
3.稳健性(干扰因素和背景):干扰因素(最多 9 个干扰因素和遮挡)的性能和背景变化(新厨房、照明、背景场景)的性能
- 长期场景:在真实厨房中执行SayCan类型的自然语言指令
RT-1 在所有四个类别中都大大优于基线,表现出令人印象深刻的泛化和鲁棒性。
合并异构数据源
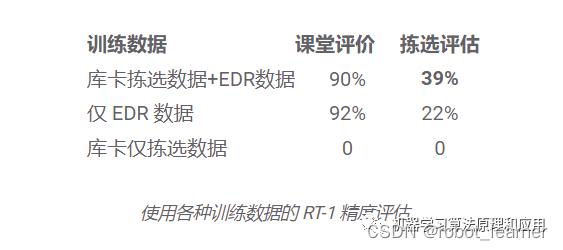
为了进一步推动 RT-1,我们使用从另一个机器人收集的数据对其进行训练,以测试 (1) 模型在出现新数据源时是否保持其在原始任务上的性能,以及 (2) 模型是否在泛化方面得到提升具有新的和不同的数据,这两者对于通用机器人学习模型都是可取的。具体来说,我们使用在QT-Opt 项目的固定底座Kuka 手臂上自主收集的 209k 次不加区别的抓握事件. 我们转换收集的数据以匹配我们使用 EDR 收集的原始数据集的动作规范和边界,并用任务指令“选择任何东西”标记每一集(Kuka 数据集没有对象标签)。然后在每个训练批次中将 Kuka 数据与 EDR 数据以 1:2 的比例混合,以控制原始 EDR 技能的回归。
我们的结果表明 RT-1 能够通过观察其他机器人的经验来获得新技能。特别是,当 RT-1 在 Kuka 的垃圾箱拣选数据和机器人教室的现有 EDR 数据上进行训练时,仅使用 EDR 数据进行训练时的 22% 准确率跃升了近 2 倍,达到 39%,我们在机器人教室收集了大部分 RT- 1 数据。当单独使用来自 Kuka 的拣选数据训练 RT-1,然后使用来自 EDR 机器人的拣选数据对其进行评估时,我们看到准确率为 0%。另一方面,混合来自两个机器人的数据允许 RT-1 在面对 Kuka 观察到的状态时推断 EDR 机器人的动作,而无需在 EDR 机器人上明确展示拾取箱子,并利用经验库卡收集。这为未来的工作提供了一个机会,可以结合更多的多机器人数据集来增强机器人的能力。
长期 SayCan 任务
RT-1 的高性能和泛化能力可以通过 SayCan 实现远距离、移动操作任务。SayCan 的工作原理是将语言模型置于机器人可供性中,并利用少量提示将以自然语言表达的长期任务分解为一系列低级技能。
SayCan 任务提供了一个理想的评估设置来测试各种功能:
长期任务成功率随任务长度呈指数下降,因此高操作成功率很重要。
移动操作任务需要在导航和操作之间进行多次切换,因此对初始策略条件(例如,基本位置)变化的鲁棒性至关重要。
可能的高级指令的数量随着操作原语的技能广度组合增加。
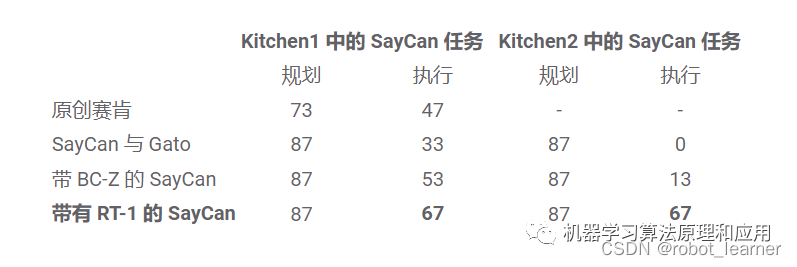
我们在两个真实厨房中使用 RT-1 和其他两个基线(SayCan with Gato 和 SayCan with BC-Z)评估 SayCan。下面,“Kitchen2”构成了比“Kitchen1”更具挑战性的泛化场景。用于收集大部分训练数据的模拟厨房是在 Kitchen1 之后建模的。
SayCan with RT-1 在 Kitchen1 中的执行成功率为 67%,优于其他基线。由于新的看不见的厨房带来的泛化困难,SayCan with Gato 和 SayCan with BCZ 的性能下降明显,而 RT-1 没有表现出明显的下降。
结论
RT-1 Robotics Transformer 是一种简单且可扩展的动作生成模型,适用于现实世界的机器人任务。它对所有输入和输出进行标记,并使用具有早期语言融合的预训练 EfficientNet 模型和用于压缩的标记学习器。RT-1 在数百个任务中显示出强大的性能,以及广泛的泛化能力和在现实世界设置中的鲁棒性。
在探索这项工作的未来方向时,我们希望通过开发允许非专家通过定向数据收集和模型提示来训练机器人的方法来更快地扩展机器人技能的数量。我们还期待通过可扩展的注意力和记忆力来提高机器人变压器的反应速度和上下文保留。要了解更多信息,请查看论文、开源RT-1 代码和项目网站。
代码
文末代码链接
最后一个问题: 现在AI这么牛,自己如何搞得定?万丈高楼拔地起来。首先找一本AI基本的原理和实践书籍入手。比如下面这本,来自小编的书:
北大出版社,人工智能原理与实践 人工智能和数据科学从入门到精通 详解机器学习深度学习算法原理
人工智能原理与实践 全面涵盖人工智能和数据科学各个重要体系经典