数据结构与算法基础
考点:数组与矩阵、线性表、广义表、树与二叉树、图、排序与查找、算法基础与常见的算法
1. 数组
| 数组类型 | 存储地址计算 |
|---|---|
| 一维度数组a[n] | a[i]的存储地址为a+i*len |
| 二维数组a[m][n] | a[i][j]的存储地址;按行存储:a+(i*n+j)*len;按列存储:a+(j*m+i)*len |
2. 稀疏矩阵
采用上三角或者下三角的形式存储矩阵
例题:A、可以使用代入法判断

3. 数据结构的定义
存储和组织数据的方式
线性结构、非线性结构包含树(不存在环路)和图(存在环路);从意义上讲图可以包含树,树包含线性结构
4. 线性表的定义 - 顺序表/链表
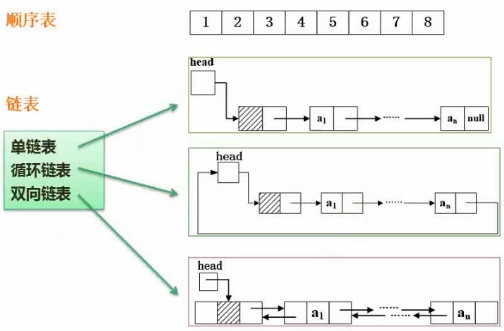
基本操作
单链表删除:p -> next = q -> next
单链表插入:s -> next = p -> next; p -> next = s;
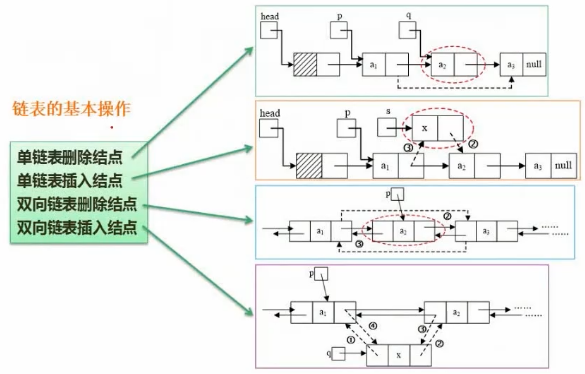
5. 顺序存储与链式存储对比
| 性能类别 | 具体项目 | 顺序存储 | 链式存储 |
|---|---|---|---|
| 空间性能 | 存储密度 | =1, 更优 | <1 |
| 容量分配 | 事先确定 | 动态改变, 更优 | |
| 时间性能 | 查找运算 | O(n/2) | O(n/2) |
| 读运算 | O(1), 更优 | O([n+1]/2), 最好1, 最坏n | |
| 插入运算 | O(n/2), 最好0, 最坏n | O(1), 更优 | |
| 删除运算 | O({n-1}/2) | O(1), 更优 |
循环队列问题:无法区分队空和队满的情况
两种解决方案:1记录队满队空状态;2少存一位元素(多数)
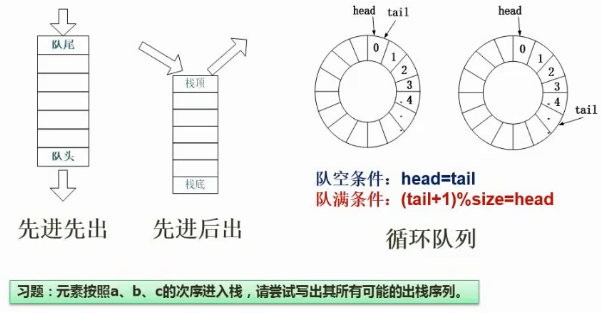
例题:
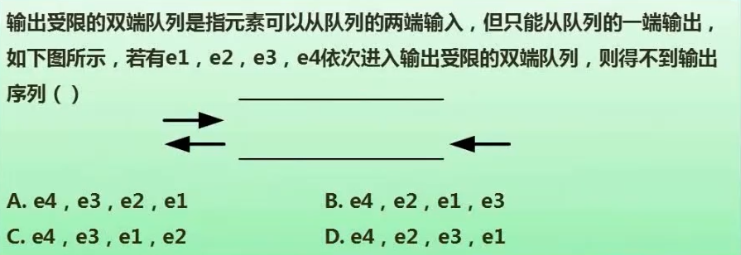
7. 广义表

例一:3,2
例二:head(head(tail(LS1)))
8. 树与二叉树
基本概念:
结点的度是它的孩子字结点数,1结点度2,3结点度1,7结点度0
树的度是所有结点度中最高的结点的度;树的度为2
叶子结点是没有子结点的;4,5,7,8
分支节点,度不为0的节点
内部节点,即不是叶子结点,也不是根结点;2,3,6
父结点和子结点是相对的概念;2是1的子结点;4是2的子结点
兄弟结点;4和5
层次,4层
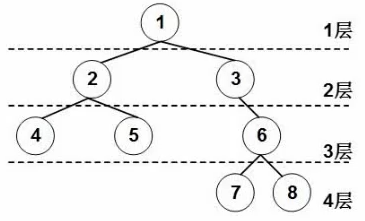
9. 满二叉树和完全二叉树
满二叉树:可以构成一个完整的三角形
完全二叉树:完全二叉树的定义是一个深度为k的有n个节点的二叉树,对树中的节点按从上至下、从左到右的顺序进行编号,编号1≤i≤n的结点与满二叉树中编号为i的结点在二叉树中的位置相同。

10. 二叉树的特性
二叉树的第i层最多有2^(i-1)个结点
深度为k的二叉树最多有2^k - 1个结点
对任何一颗二叉树,如果叶子结点数为n0,度为2的结点数为n2,则n0=n2+1
如果对一颗有n个结点的完全二叉树按层序编号,对任意结点i(1<=i<=n),有:
如果i=1,则结点无父结点,是二叉树的根,如果i>i,则它的父结点是i/2
如果2i>n,则结点为i为叶子结点,无左子结点;否则,其左子结点是2i
如果2i+1>n,则结点i无右叶子结点,否则,其右子结点是2i+1
11. 二叉树遍历
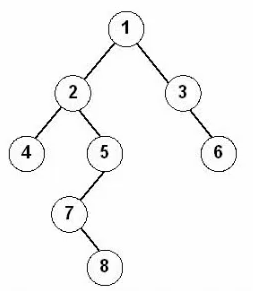
层次遍历:从根结点开始,每层依次从左至右访问完;12345678
前序遍历(根左右)是先访问根结点,再访问左子结点和右子结点;12457836
中序遍历(左根右)是先访问左子结点,在访问根结点和右子结点;42785136
后序遍历(左右根)是先访问左子结点,再访问右子结点和根结点;48752631
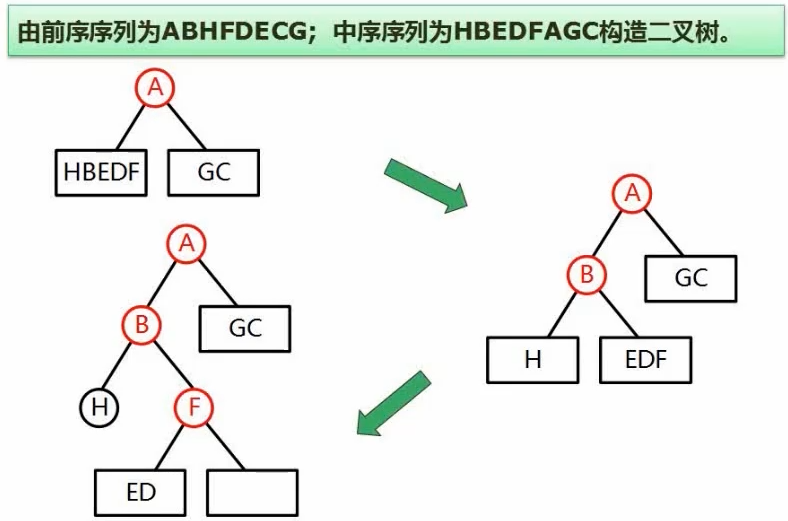
12. 反向构造二叉树
根据二叉树的遍历序列,反向构造二叉树;必须有中序序列和任意前序或后序序列才能实现
标记根结点,然后推理左右结点
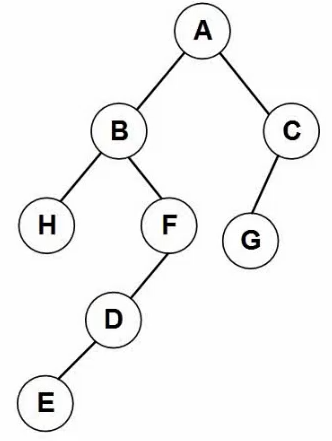
13. 树转二叉树
孩子结点 - 左子树结点
兄弟结点 - 右孩子结点

14. 查找二叉树(二叉排序树)
也称二叉排序树;左子结点小于根;右子结点大于根;
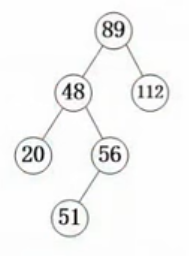
插入结点:
若该键值结点已存在,则不再插入,如48
若查找二叉树为空树,则以新结点为查找二叉树
将要插入结点键值与插入后父结点键值比较,就能确定新结点是父结点的左子结点还是右子结点
删除结点:
若删除结点是叶子结点,则直接删除
若待删除结点只有一个子结点,则将这个子结点与待删除结点的父结点直接连接,如56
若待删除的结点p右两个子结点,则在其左子树上,用中序遍历寻找关键值最大的结点S,用结点s的值代替结点p的值,然后删除结点s,结点s必属于上述两种情况之一,如89
15. 最优二叉树(哈夫曼树)
树的路径长度:树的路径累加长度
权:某个叶子结点的键值,即某个字符出现的频度
带权路径长度:路径长度 * 权值;例如2结点,2*2=4;4结点3*4=12
树的带权路径长度(树的代价):所有叶子节点的带权路径长度之和
构造哈夫曼树是尝试让树的带权路径长度最小;如下第一种树的带权路径长度是41,第二种是25
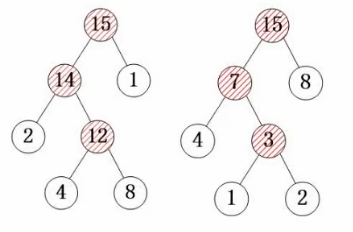
例题:
1、从序列中选出2个权值最小的数 3,5构成一颗小树,小树的权是8,将8添加到序列
2、再从序列中选2个权值最小的7,8构成一颗树,得到权值15的树加到序列
3、依此类推不断构成树
4、求树的叶子结点带权路径长度只和得到树的带权路径长度
通过构造发现我们最开始的序列都是叶子结点,所以回头看定义树的带权路径长度也就是所以叶子结点带权路径长度只和

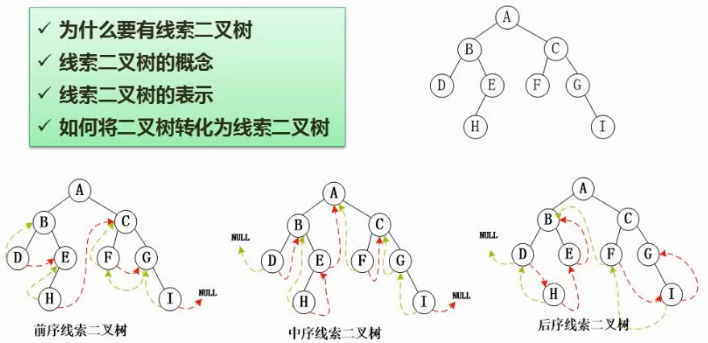
16. 线索二叉树
如图在二叉树的基础上有虚线建线把结点连接起来;
因为在二叉树中许多结点是空闲状态,一些结点的左子树和右子树的指针是空的
按照前序遍历、中序遍历、后序遍历序列的顺序连接指针,就构成了相对应种类的线索二叉树
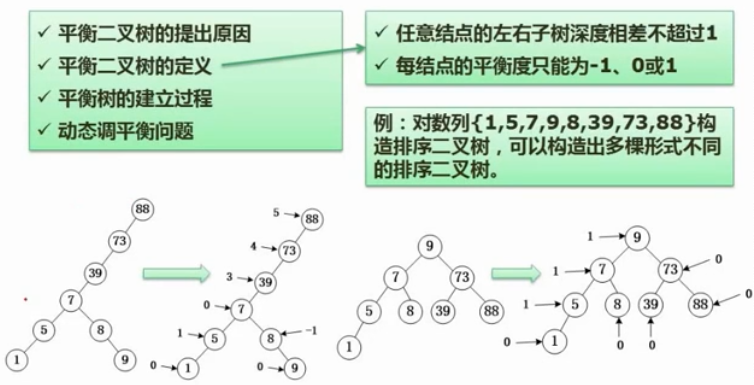
17. 平衡二叉树
结点平衡度 = 左子树深度 - 右子树深度
18. 图 - 基本概念
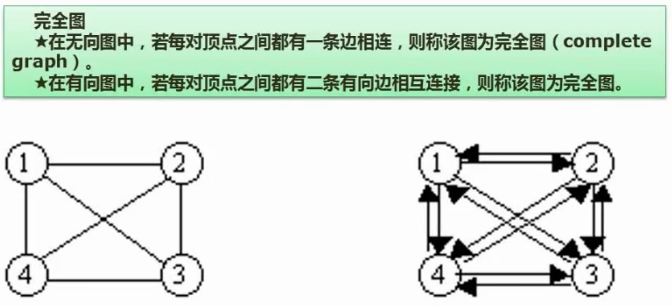
邻接矩阵
无向图的邻接矩阵全对角线为0(自己连接自己的点),沿对角线对称,所以存储时可以只存上三角或下三角
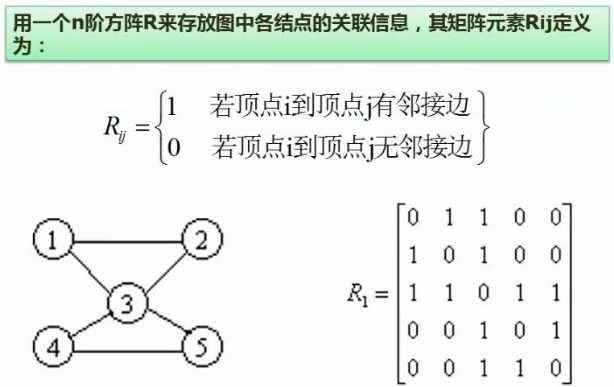
邻接表
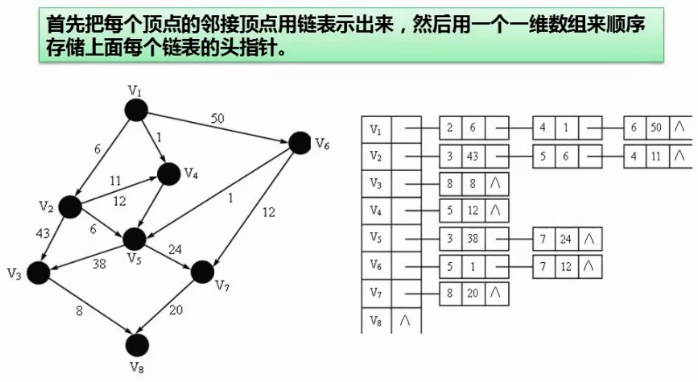
图的遍历
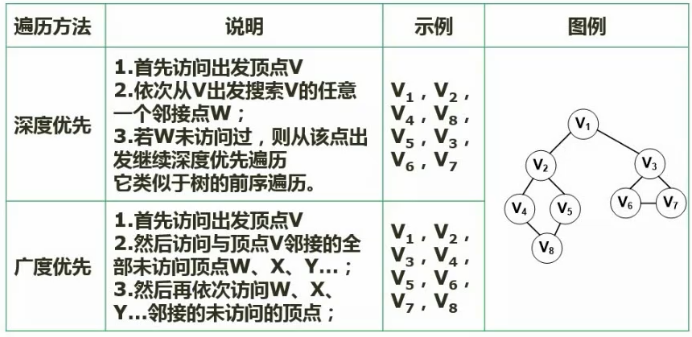
19. 图 - 拓扑排序
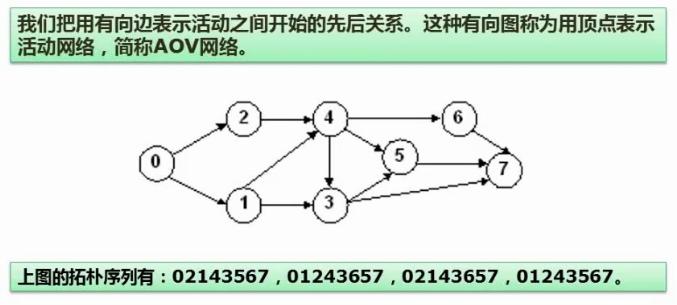
20. 图的最小生成树
保留最小权值的边并能使图连贯;
树和图的区别,树没有环路;设树的结点n,边则n-1;
普里姆算法
例题:从一个任意结点出发,将这个结点定义为红点集,其他结点为蓝点集;找出从红点集中到蓝点集中最小的权
比如选A,找到权值最小的A -> B,连接后将B加入红点集
再次判断的时候就需要把红点集的A,B找到蓝点集中到最小权;依此类推
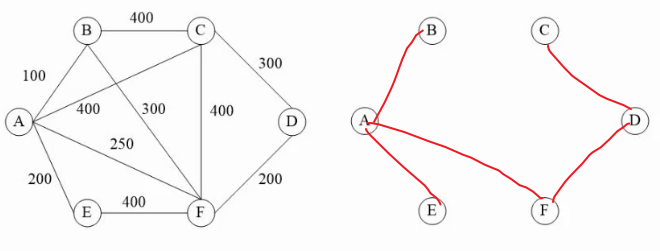
克鲁斯卡尔算法
设顶点树为n,依次选择出图中最短的n-1条边,且每次选择下一条边时要保证不形成环路
21. 算法的特性
有穷性:执行有穷步数之后结束
确定性:算法中每一条指令都必须有确切的含义,不能含糊不清
输入数量(>=0)
输出数量(>=1)
有效性:算法的每个步骤都能有效执行并能得到确定的结果。例如a=0,b/a就无效。
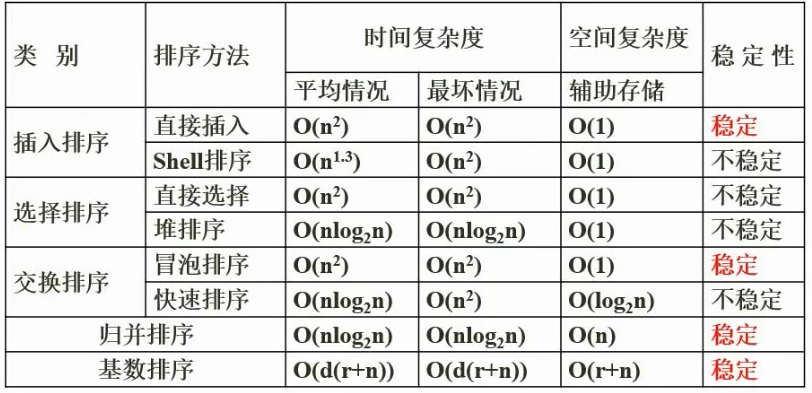
22. 算法的复杂度
时间复杂度(重点,下午设计题出现问程序的时间复杂度计算)、空间复杂度

23. 顺序查找
时间复杂度O(n)

24. 二分查找
时间复杂度(log以2为底n的对数)

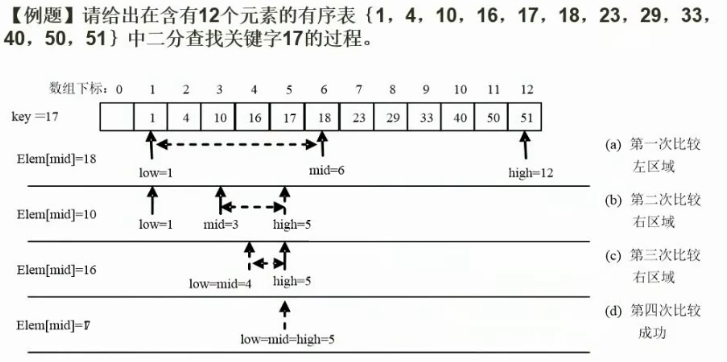
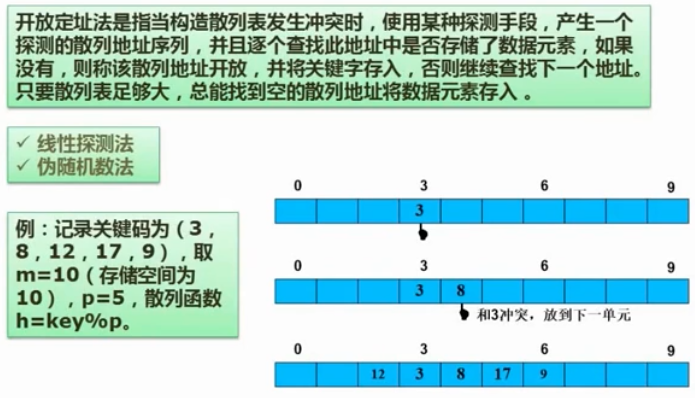
25. 散列表
在数据存储时遵循一定的规则。
26. 排序算法总结**
(有时只在上午考,有时上下午都考)
排序的概念
稳定与不稳定排序(排序前后原有的相等两个数字的顺序是否改变,比如分数的排名先来后到等)、内排序(在内存进行)与外排序(涉及到外部存储空间)
27. 冒泡排序
https://www.runoob.com/w3cnote/bubble-sort.html
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
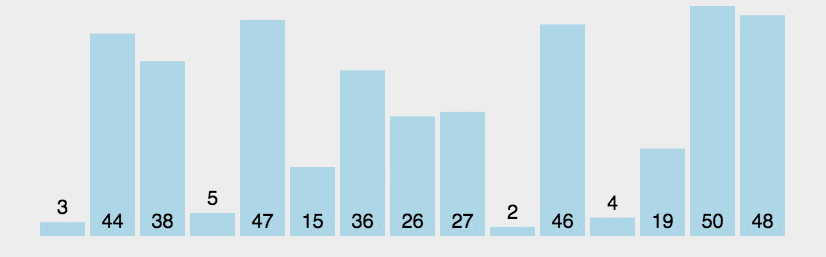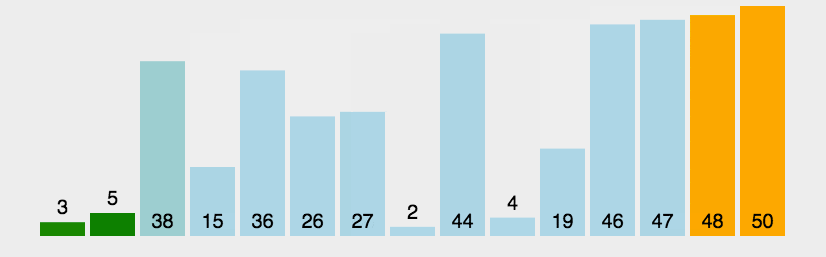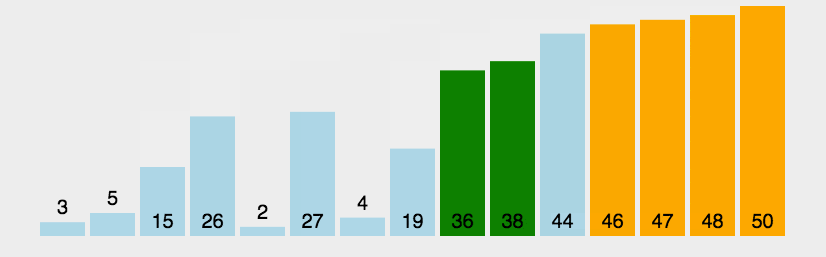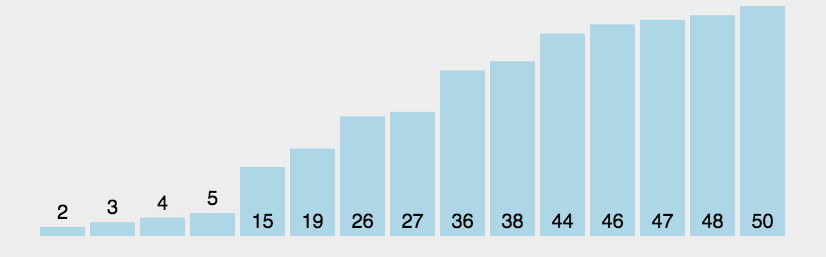
28. 直接选择排序
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
重复第二步,直到所有元素均排序完毕。
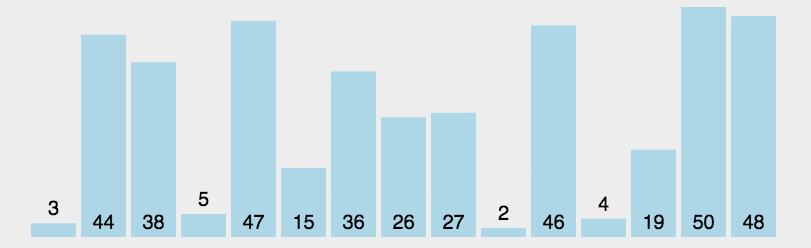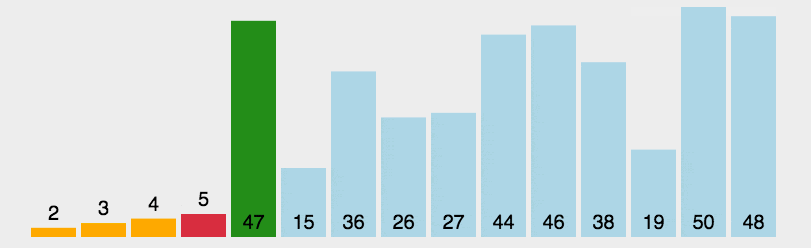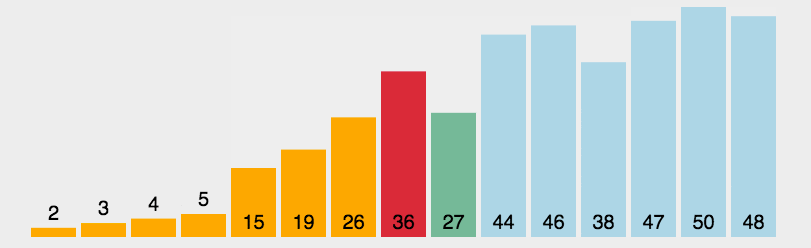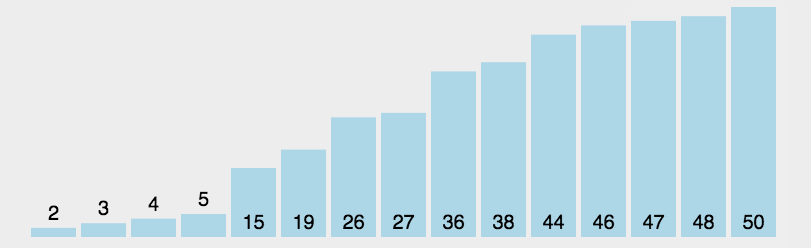
29. 直接插入排序
将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
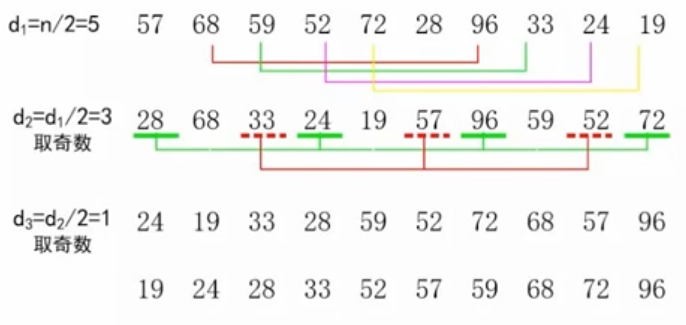
30. 希尔排序(Shell)
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。
算法步骤:
选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
按增量序列个数 k,对序列进行 k 趟排序;
每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
31. 归并排序
归并排序(Merge sort)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。对有多个有序序列进行排序,为了方便一般每次操作两个序列。
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置;
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
- 重复步骤 3 直到某一指针达到序列尾;
- 将另一序列剩下的所有元素直接复制到合并序列尾。
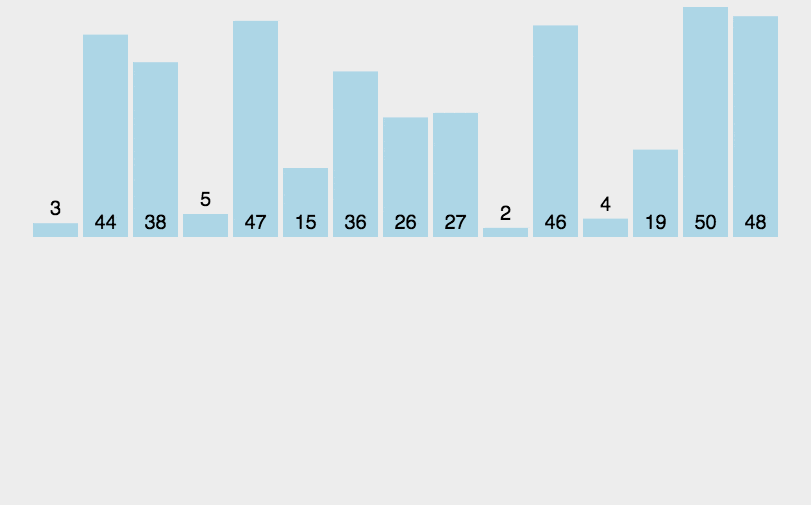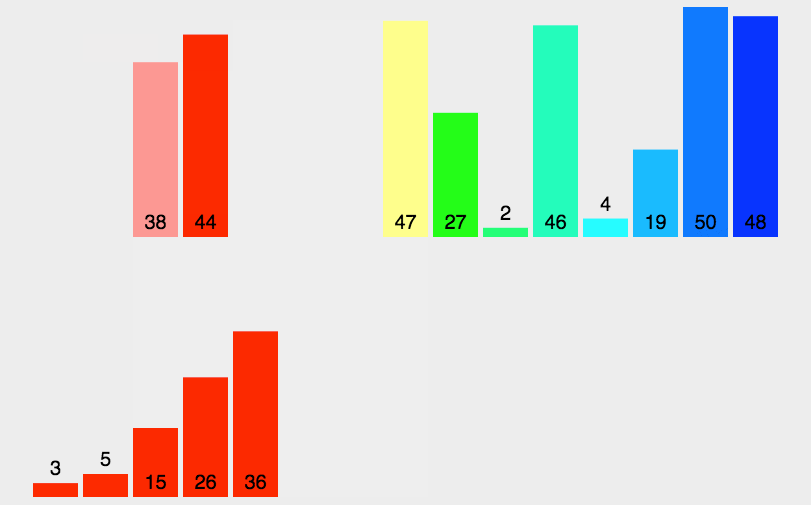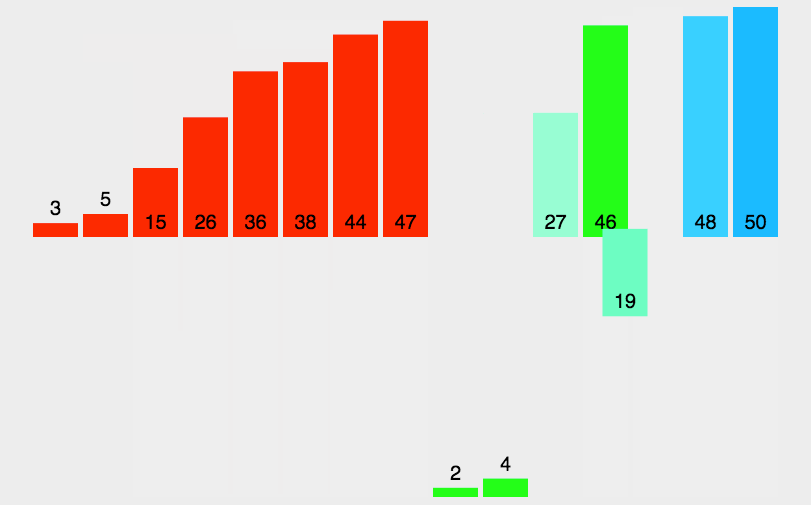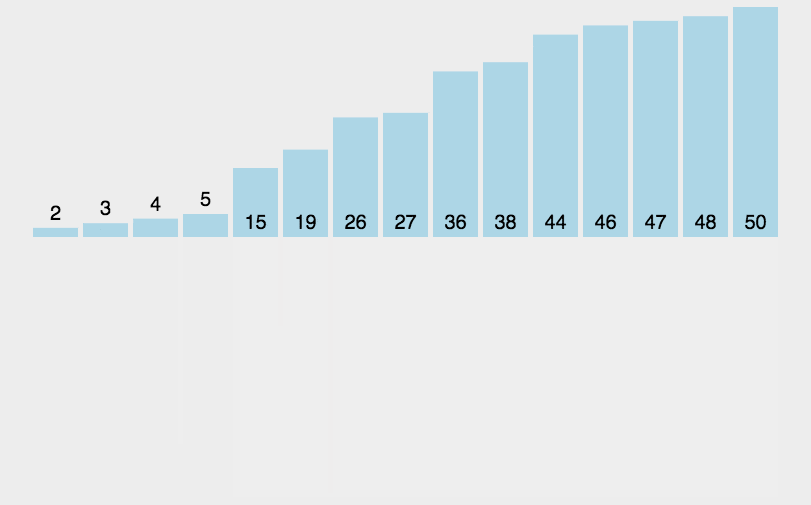
31. 快速排序
快速排序是一种常用的排序算法,也是一种基于交换排序的算法。它的基本思想是通过一趟排序将待排序序列分割成独立的两部分,其中一部分的所有元素都比另一部分小,然后再按此方法对这两部分分别进行快速排序,递归地进行,以达到整个序列有序的目的。
具体实现过程如下:
- 选定一个枢纽元素(pivot),一般可以选择待排序数组的第一个元素,也可以随机选择。这个枢纽元素可以将数组分为两部分,一部分的元素都小于等于枢纽元素,另一部分的元素都大于枢纽元素。
- 然后将小于等于枢纽元素的元素放到枢纽元素的左边,大于枢纽元素的元素放到枢纽元素的右边。这一步称为分区(partitioning)。
- 递归地对枢纽元素左右两部分分别进行上述步骤,直到所有子问题的规模都变得足够小,可以直接采用插入排序等其他算法进行排序。
- 合并所有已排序的子序列,得到最终的排序结果。
快速排序的时间复杂度为O(nlogn),其中n为待排序序列的长度。它是原地排序算法,因此不需要额外的空间,但是快速排序的实现依赖于递归,因此递归过程中需要使用栈空间。同时,由于快速排序是一种不稳定的排序算法,因此在需要保持排序前后元素相对位置关系的情况下需要进行特殊处理。
public class QuickSort {public static void sort(int[] arr) {if (arr == null || arr.length == 0) {return;}quickSort(arr, 0, arr.length - 1);}private static void quickSort(int[] arr, int left, int right) {if (left >= right) {return;}int pivotIndex = partition(arr, left, right);quickSort(arr, left, pivotIndex - 1);quickSort(arr, pivotIndex + 1, right);}private static int partition(int[] arr, int left, int right) {int pivot = arr[left];int i = left + 1, j = right;while (i <= j) {while (i <= j && arr[i] < pivot) {i++;}while (i <= j && arr[j] >= pivot) {j--;}if (i < j) {swap(arr, i, j);}}swap(arr, left, j);return j;}private static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
}小于基准的放左边,大于基准的放右边;通过外层while里的两个while判断左右两边数是否需要交换;递归对分好的左右两边序列做相同操作
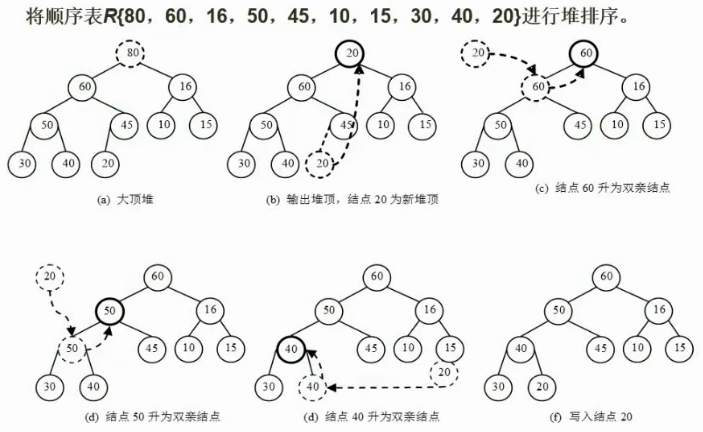
32. 堆排序
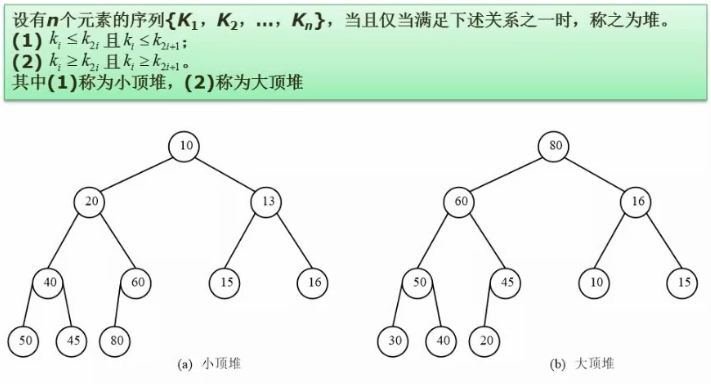

初建大顶堆:
从最后一个非叶子结点开始调整,依次倒出第2个,3个…
5和它的两个子结8,0点比较,将最大值调整为根;
4和2,6比较后调整
3个8,7比较后调整;注意跟包含子结点的8交换后还有进一步调整,3,和5,0调整
最后调整到根结点1和8,6调整,1,8交换后继续对当前包含子结点的1和5,7调整,把7换上来后7刚刚不包含子结点,所以交换结束

建立堆后的排序:
取走堆顶,将二叉树的最后一个结点放到堆顶
然后对堆进行调整,同上面的初建堆方法把20根两个子结点比对…
public class HeapSort implements IArraySort {@Overridepublic int[] sort(int[] sourceArray) throws Exception {// 对 arr 进行拷贝,不改变参数内容int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);int len = arr.length;buildMaxHeap(arr, len);for (int i = len - 1; i > 0; i--) {// 将堆顶(最大值)与最后一个结点交换,然后长度减一从前面的结点开始再构建大顶堆swap(arr, 0, i);len--;heapify(arr, 0, len);}return arr;}private void buildMaxHeap(int[] arr, int len) {// len长度的线性表,最后一个元素的父结点序号为n/2,因此第一个大顶堆的子根在这里诞生for (int i = (int) Math.floor(len / 2); i >= 0; i--) {heapify(arr, i, len);}}private void heapify(int[] arr, int i, int len) {// 从0开始,平衡二叉树中当前的左、右子结点int left = 2 * i + 1;int right = 2 * i + 2;int largest = i;if (left < len && arr[left] > arr[largest]) {largest = left;}if (right < len && arr[right] > arr[largest]) {largest = right;}if (largest != i) {swap(arr, i, largest);heapify(arr, largest, len);}}private void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}
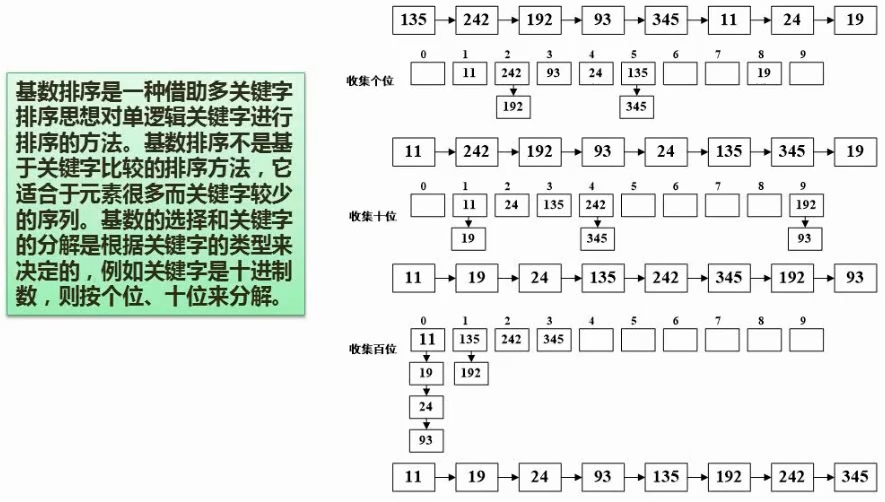
33. 基数排序
(考察的比较少)
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
先排个位,再排十位,再排百位…