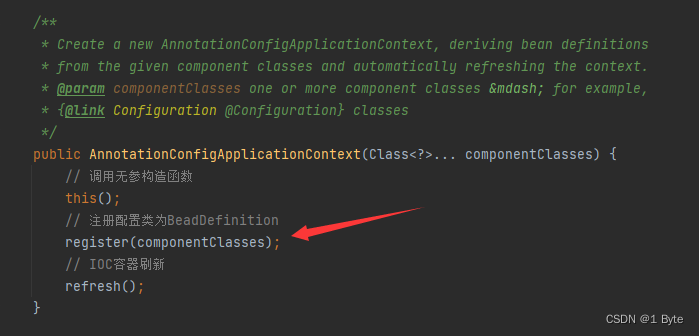
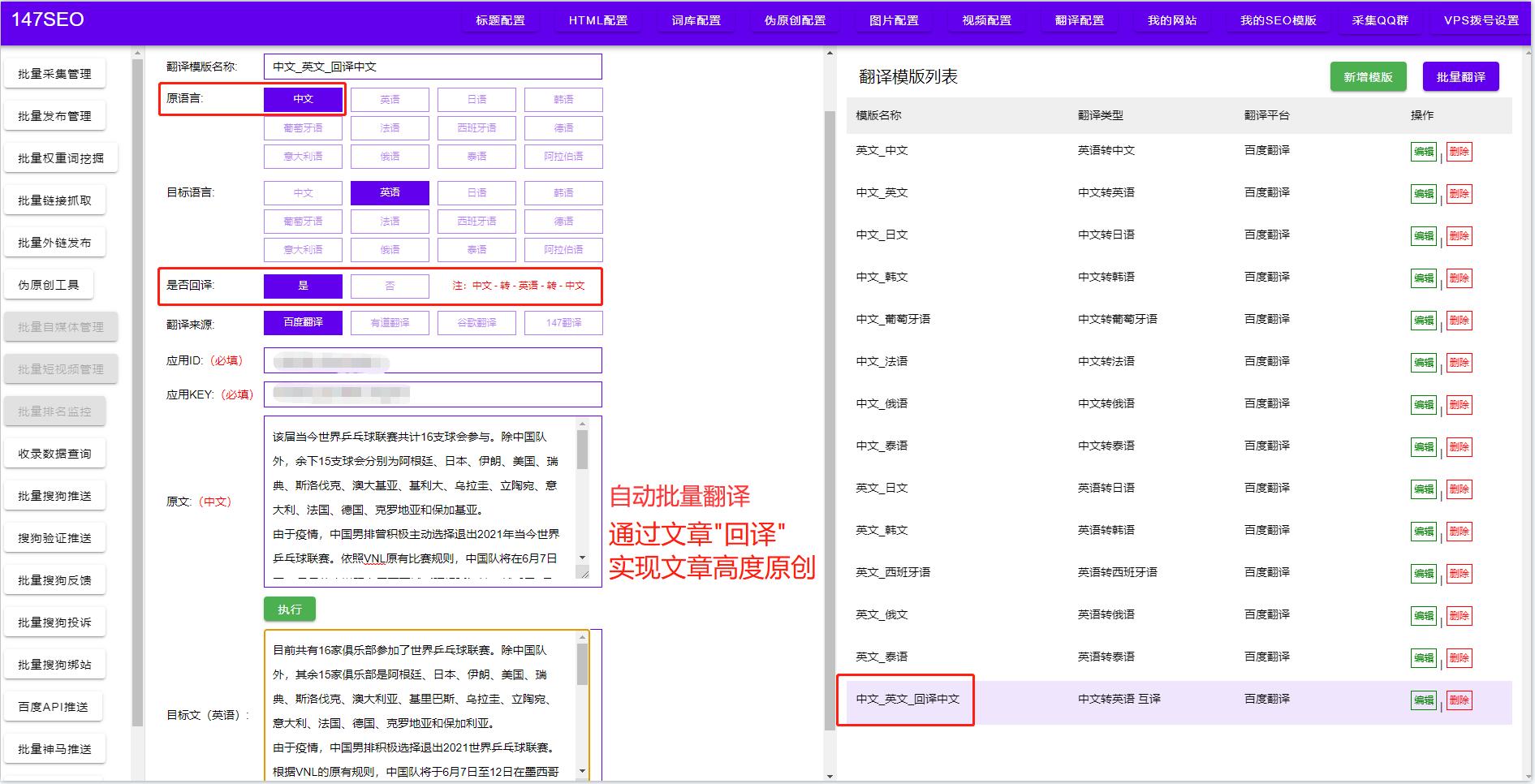
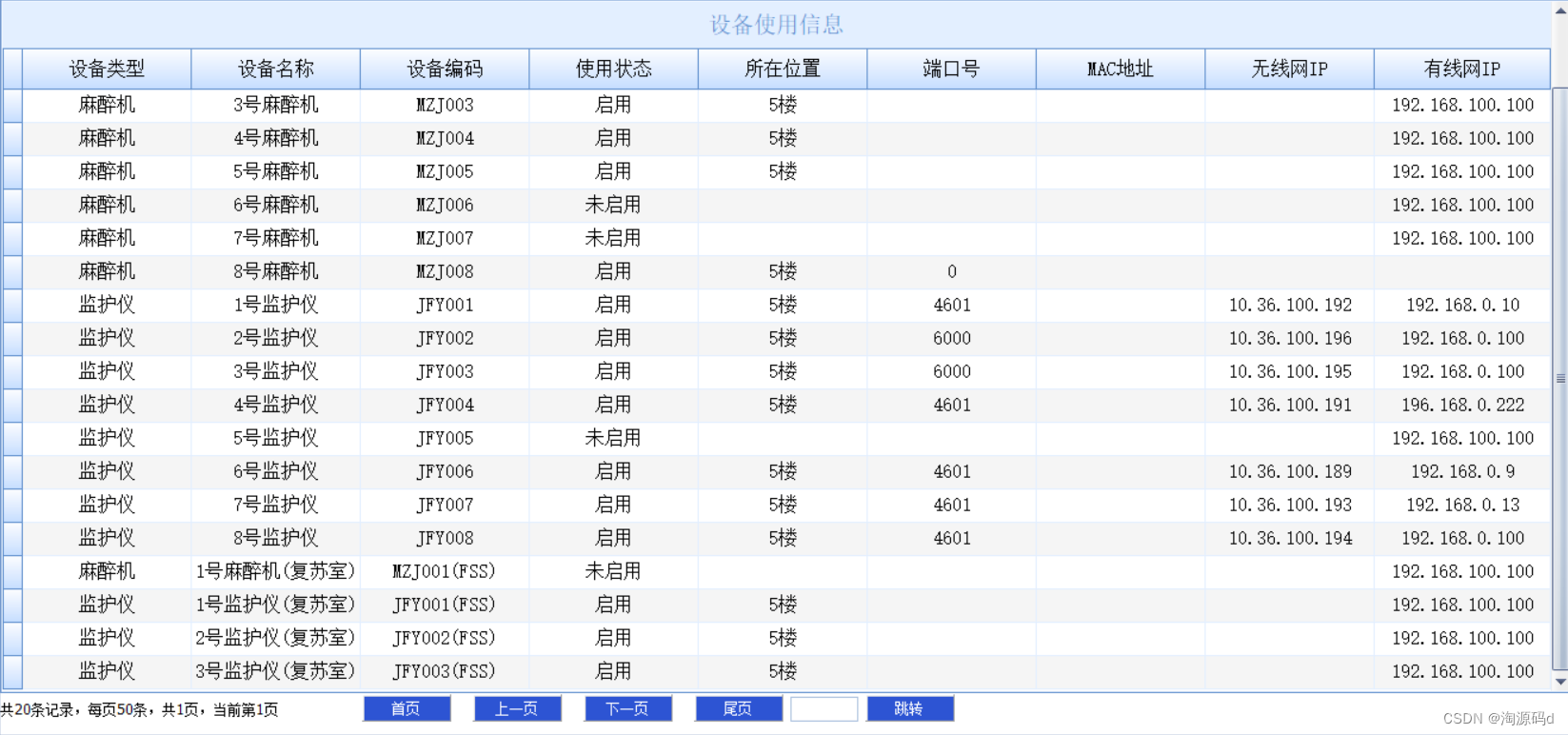
一、介绍
- 导论:Transformer 背景介绍,Transformer 能胜任的任务介绍。
- 相关知识:深度学习基础(神经网络,回归,分类,优化,激活函数等),具体介绍序列到序列模型,RNN,Seq2Seq,LSTM等。
- Transformer 基本概念:编码器、解码器,多头注意力,位置编码,层归一化等。
二、实践
- 利用Transformer构建NLP任务模型:语义匹配、文本分类等。
- 模型优化:加载预训练模型,细节的调优,数据增强,调整Dropout等。
- 模型深度:尝试不同网络深度,以及不同模型结构,熨帖过程等。
三、实践项目
- 训练自己的Transformer模型:自行构建数据集,熟悉模型参数,进行模型训练和验证过程。
- 扩展Transformer模型:例如增加更多层、多头注意力,特定序列模型结构,语义匹配函数等。
- 尝试不同数据集:尝试大规模的神经机器翻译,语义匹配,视觉问答,语音识别等不同领域的数据集进行测试,探索Transformer在不同场景的应用。
四、学习资源
- 课外资料:诸如论文、博客文章、官方文档等资料对比学习,了解各家的实现方式。
- 项目实践:深入理解实际项目中模型搭建,损失函数,数据准备,模型验证等。
- 其他资源:尝试一些开源项目,例如TensorFlow,PyTorch,Keras等。
![[linux]基础IO](https://img-blog.csdnimg.cn/2f98b0eb353b4b1eaada62a57abcab1e.png)