目录
第一节 模型介绍和学习策略
模型介绍
学习策略
第二节 梯度下降法
概念
算法
梯度下降法:例子
原理
第三节 学习算法之原始形式
学习问题
原始形式
例题分析
第三节 学习算法之对偶形式
对偶形式
例题分析
第四节 原始形式算法的收敛性
第一节 模型介绍和学习策略
模型介绍
- 输入空间:
; 输入:
- 输出空间:
; 输出:
- 感知机:
其中,称为权值(Weight),
称为偏置(Bias),
表示内积
- 假设空间:
线性方程:
特征空间中的一个超平面S(超平面比特征空间向量少一维)
法向量:w; 截距:b
学习策略
前提条件:数据集需要线性可分
给定数据集
若存在某个超平面S
能够将数据集的正负实例点完全正确的划分到超平面两侧,即
那么,称T为线性可分数据集;否则,称T为线性不可分。
到S的距离:
- 若是正确分类点,则
- 若是错误分类点,则
误分类点到S的距离:
所有误分类点到S的距离:
其中,M代表所有误分类点的集合
损失函数(不影响最后的结果):
第二节 梯度下降法
概念
- 梯度,指某一函数在该点出最大的方向导数,沿着该方向可取得最大的变化率
- 若
是凸函数,可通过梯度下降法进行优化:
算法
输入:目标函数,步长为
,计算精度
;
输出:得极小值点
(1)选取初始值,置k=0
(2)计算
(3)计算梯度
(4)置,计算
;当
或者
时,停止迭代,令
(5)否则,置k=k+1,转(3)
梯度:
单变量
,
,
多变量:
通俗的理解,当为多变量时,梯度可以是一个一阶导数矩阵
梯度下降法:例子
梯度下降法:
例子:
,
- 初始值和步长分别设置为:
,
,
- 迭代计算过程:
原理
泰勒展开:
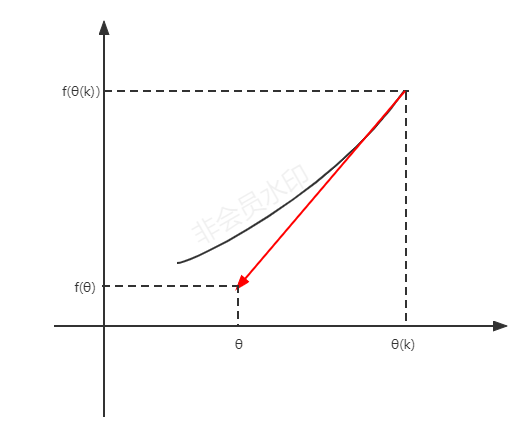
的单位向量用v表示,
为标量
- 重新表达,
- 更新θ使函数值变小,因此
- v和
互为反向才能满足这一条件,即
- 更新θ
- 化简
第三节 学习算法之原始形式
学习问题
- 训练数据集:
其中,,
- 损失函数:
其中,M代表误分类点的集合
- 模型参数估计:
原始形式
损失函数:
梯度:
;
参数更新:
- 批量梯度下降法(Batch Gradient Descent):每次迭代时使用所有误分类点来进行参数更新
;
其中,代表步长
- 随机梯度下降法(Stochastic Gradient Descent):每次随机选取一个误分类点
;
算法
输入:训练集:
其中,,
;步长
输出:w,b;感知机模型
(1)选取初始值;
(2)在训练集中随机选取数据;
(3)若,
;
(4)转(2),直到训练集中没有误分类点
例题分析
输入:训练集:
其中,,假设η=1
输出:w,b;感知机模型
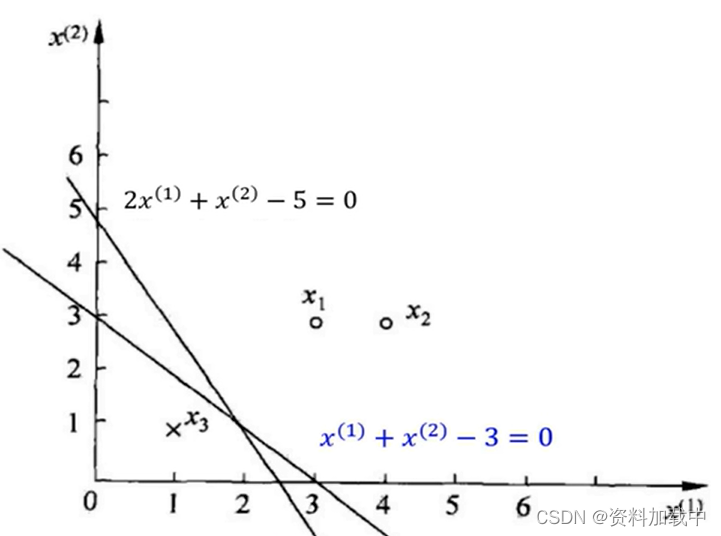
此时学习问题转化为:
(1)选取初始值;
(2)对于点,有
- 更新参数,
,
- 模型,
(3)对于点,有
(被正确分类)
对于点,有
(被正确分类)
对于点,有
(被错误分类)
- 更新参数,
,
-模型,
(4)重复以上步骤,直到没有误分类点

得到参数
模型,
结果:
分离超平面
感知机模型,
注:
若误分类点依次取
可以得到分离超平面
若误分类点依次取
可以得到分离超平面
第三节 学习算法之对偶形式
对偶形式
- 在原始形式中,若
为误分类点,可得如下更新参数的方式:
;
- 假设初始值
,
,对误分类点
次之后,
的增量分别为
和
,其中
。
- 最后学习到的参数为,
;
对原始算法求解的迭代过程再做分析

更新次数:最后学习到的参数为,
其中表示第i个实例点在参数更新中贡献的次数 。
实例点为正例,因此
为+1,所以
为
;实例点
为负例,因此
为-1,所以
为
,最终
为
。同理可得b。
算法
输入:训练集:
其中,,
;步长
输出:感知机模型
,其中
(1)选取初始值
(2)在训练集中随机选取数据;
(3)若,
(4)转(2),直到训练集中没有误分类点。
对(3)步进行具体分析:
迭代条件:
矩阵:
例题分析
输入:训练集:
其中,,假设η=1
输出:,b;感知机模型
(1)选取初始值
(2)计算Gram矩阵
(3)误分类条件参数更新
(4)对于点,有
(被错误分类)
- 参数更新,
(5)对于点有
(被正确分类)
对于点,有
(被正确分类)
对于点,有
(被错误分类)
- 更新参数,
(6)重复以上步骤,直到没有误分类点

(7)得到参数
结果:
- 分离超平面
- 感知机模型
第四节 原始形式算法的收敛性
定理
记则分离超平面可以写为
Novikoff
若训练集
线性可分,其中,,
则
(1)存在满足条件的超平面
可将T完全正确分开;且
对所有
(2)令,则感知机算法在T上的误分类次数k满足不等式
证明
(1)线性可分
超平面
将T完全正确分开。(不妨令
)
那么,对有限的均有
记则有
(2)假设为n_1维;若实例被误分类,则权重更新。令
为第k个误分类实例之前的扩充权重向量,即
若
则,为第k个误分类实例,更新参数,
需要推导的两个不等式:
(1)
(2)
结合所得两个不等式,
于是,有
- 收敛性:对于线性可分的T,经过有限次搜索,可得将T完全正确分开的分离超平面。
- 依赖性:不同的初值选择,或者迭代过程中不同的误分类点选择顺序可能会得到不同的分离超平面。
- 对于线性不可分的T,算法不收敛,迭代结果会发生震荡。
- 未得到唯一分离超平面,需增加约束条件。
参考资料:
《统计学习方法》第二版
参考视频:
【合集】十分钟 机器学习 系列视频 《统计学习方法》_哔哩哔哩_bilibili