文章目录
- 一、DAG介绍
- 二、DAG和分区
- 三、DAG中的宽窄依赖和阶段的划分
- 1. 宽窄依赖的划分
- 2. 阶段划分
一、DAG介绍
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
DAG(Directed Acyclic Graph)叫做有向无环图,有方向没有闭环,表示有方向没有形成闭环的一个执行流程图。

上图就是一个典型的DAG图,有方向,从rdd1—>rdd2—>…collect结束;没有闭环,以action算子collect结束整个执行流程。
Action算子返回值不是RDD算子,它的作用是一个触发开关,会将Action算子之前的一串rdd依赖链条执行起来。
Job和Action:
- 1个Action算子会产生1个DAG,如果在代码中有3个Action,就会产生3个DAG,1个Action产生的1个DAG,会在程序运行中产生一个Job,所以:
1个Action=1个Job=1个DAG - 如果一个代码中,写了3个Action,那么这个代码运行起来,会产生3个Job,每个Job会有自己的DAG,一个代码运行起来,在Spark中称之为Application
- 一个Application中,可以有多个Job,每一个Job中含有一个DAG,同时每一个Job都是由一个Action产生的
二、DAG和分区
DAG是Spark代码的逻辑执行图,这个DAG的最终的作用是为了构建物理上的Spark详细执行计划。由于Spark是分布式(多分区)的,那么DAG和分区之间也是有关联的
rdd1 = sc.textFile()
rdd2 = rdd1.flastMap()
rdd3 = rdd2.map()
rdd4 = rdd3.reduceByKey()
rdd4.action()
假设有如上代码,且全部RDD都是3个分区在执行,其带分区关系的DAG图如下:
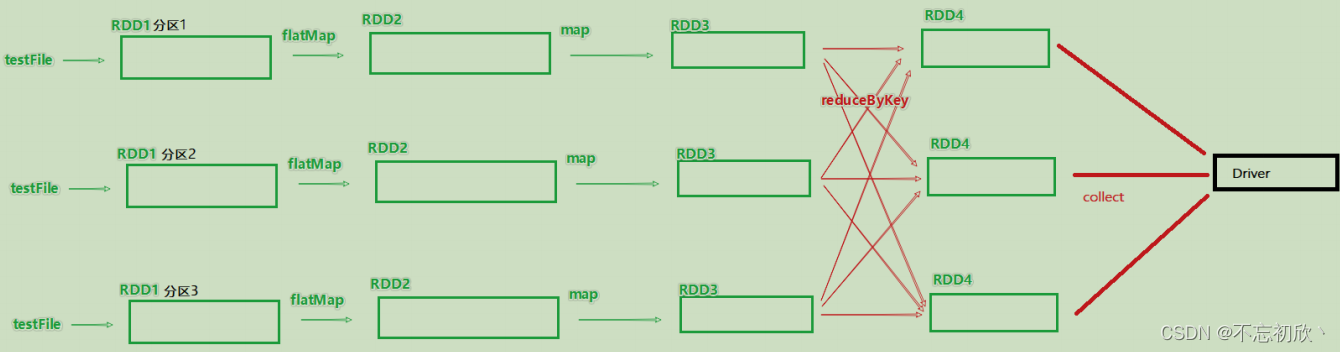
三、DAG中的宽窄依赖和阶段的划分
1. 宽窄依赖的划分
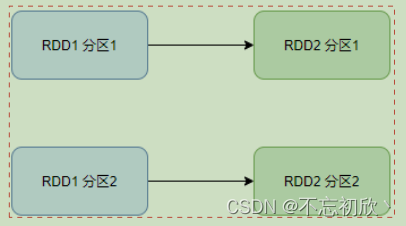
窄依赖:父RDD的一个分区,将全部数据发给子RDD的一个分区
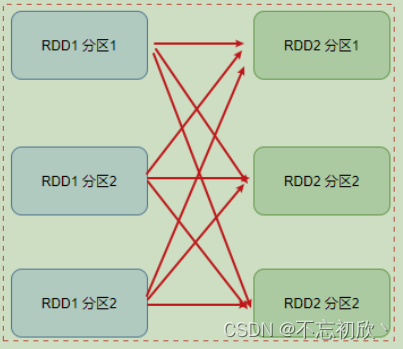
宽依赖:父RDD的一个分区,将数据发给子RDD的多个分区。宽依赖也叫shuffle
2. 阶段划分
对于Spark来说,会根据DAG,按照宽依赖,划分不同的DAG阶段,划分的依据是从后向前,遇到宽依赖就会划分出一个阶段,称为stage。
如上图,在DAG中,基于宽依赖,将DAG划分成2个stage,在stage的内部都是宽依赖。