文章目录
- 一、Parquet简介
- 二、读取和写入Parquet的方法
- (一)利用parquet()方法读取parquet文件
- 1、数据准备
- 2、读取parquet文件
- 3、显示数据帧内容
- (二)利用parquet()方法写入parquet文件
- 1、写入parquet文件
- 2、查看生成的parquet文件
- 三、Schema合并
- (一)Schema合并简介
- (二)开启Schema合并功能
- 1、利用option()方法设置
- 2、利用config()方法设置
- (三)案例演示Schema合并
- 1、提出任务
- 2、完成任务
一、Parquet简介
Apache Parquet是Hadoop生态系统中任何项目都可以使用的列式存储格式,不受数据处理框架、数据模型和编程语言的影响。Spark SQL支持对Parquet文件的读写,并且可以自动保存源数据的Schema。当写入Parquet文件时,为了提高兼容性,所有列都会自动转换为“可为空”状态。
二、读取和写入Parquet的方法
加载和写入Parquet文件时,除了可以使用load()方法和save()方法外,还可以直接使用Spark SQL内置的parquet()方法
(一)利用parquet()方法读取parquet文件
1、数据准备
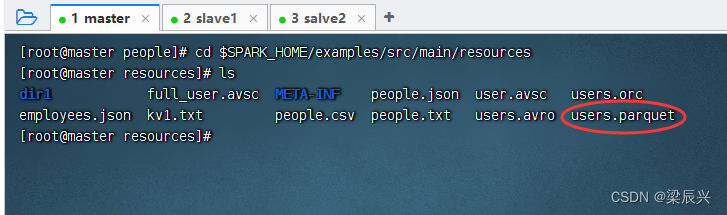
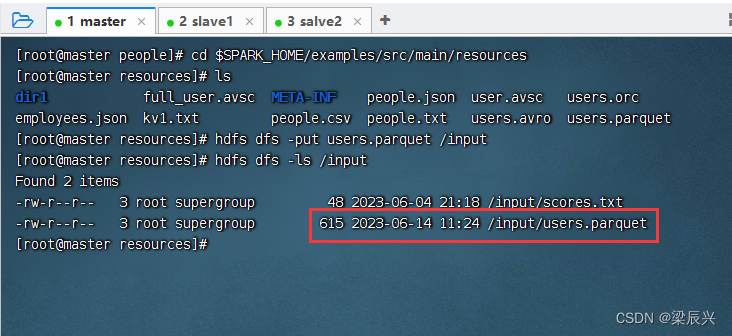
执行命令:cd $SPARK_HOME/examples/src/main/resources,查看Spark的样例数据文件 users.parquet
将users.parquet上传到hdfs的/input目录,执行命令:hdfs dfs -put users.parquet /input
hdfs dfs -put users.parquet /input
2、读取parquet文件
使用集群方式启动spark shell
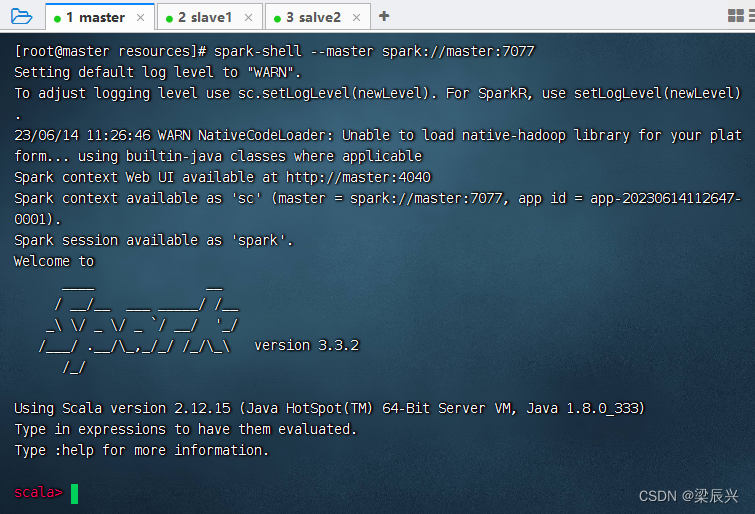
执行命令:val usersdf = spark.read.parquet(“hdfs://master:9000/input/users.parquet”)

3、显示数据帧内容
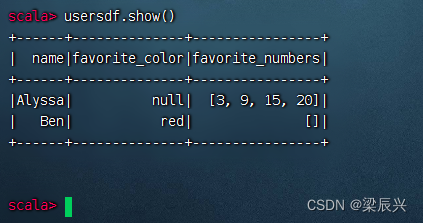
执行命令:usersdf.show()
(二)利用parquet()方法写入parquet文件
1、写入parquet文件
执行命令:usersdf.select(“name”, “favorite_color”).write.parquet(“hdfs://master:9000/result”)
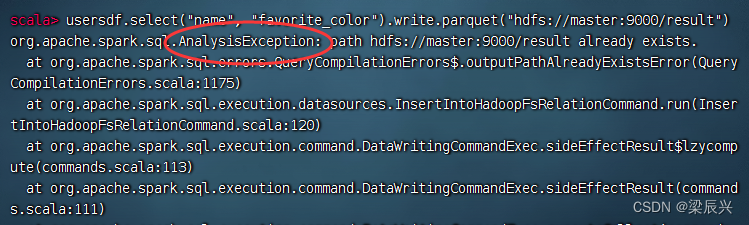
报错说/result目录已经存在,有两种解决问题的方式,一个是删除result目录,一个是修改命令,设置覆盖模式
导入SaveMode类:import org.apache.spark.sql.SaveMode后,执行命令:usersdf.select(“name”, “favorite_color”).write.mode(SaveMode.Overwrite)parquet(“hdfs://master:9000/result”)
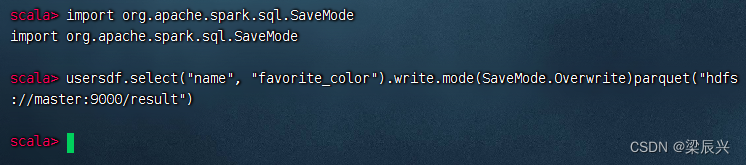
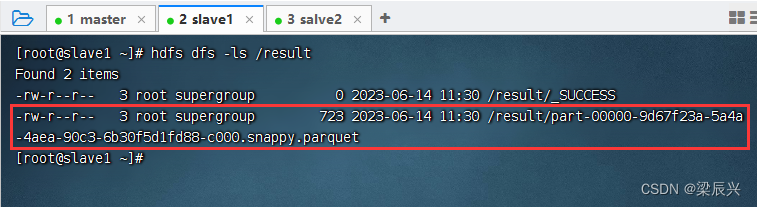
2、查看生成的parquet文件
在slave1虚拟机上执行命令:hdfs dfs -ls /result
三、Schema合并
(一)Schema合并简介
与Protocol Buffer、Avro和Thrift一样,Parquet也支持Schema合并。刚开始可以先定义一个简单的Schema,然后根据业务需要逐步向Schema中添加更多的列,最终会产生多个Parquet文件,各个Parquet文件的Schema不同,但是相互兼容。对于这种情况,Spark SQL读取Parquet数据源时可以自动检测并合并所有Parquet文件的Schema。
(二)开启Schema合并功能
由于Schema合并是一个相对耗时的操作,并且在多数情况下不是必需的,因此从Spark 1.5.0开始默认将Schema自动合并功能关闭,可以通过两种方式开启。
1、利用option()方法设置
读取Parquet文件时,通过调用option()方法将数据源的属性mergeSchema设置为true
val mergedDF = spark.read.option("mergeSchema", "true").parquet("hdfs://master:9000/input")
2、利用config()方法设置
构建SparkSession对象时,通过调用 config() 方法将全局SQL属性 spark.sql.parquet.mergeSchema 设置为true
val spark = SparkSession.builder().appName("SparkSQLDataSource").config("spark.sql.parquet.mergeSchema", true).master("local[*]") .getOrCreate()
(三)案例演示Schema合并
1、提出任务
向HDFS的目录/students中首先写入两个学生的姓名和年龄信息,然后写入两个学生的姓名和成绩信息,最后读取/students目录中的所有学生数据并合并Schema。
2、完成任务
建SchemaMergeDemo单例对象
package net.army.sql.day01import org.apache.spark.sql.{SaveMode, SparkSession}/*** 功能:演示Schema合并* 日期:2023年06月14日* 作者:梁辰兴*/
object SchemaMergeDemo {def main(args: Array[String]): Unit = {// 创建或得到SparkSessionval spark = SparkSession.builder().appName("SparkSQLDataSource").config("spark.sql.parquet.mergeSchema", true).master("local[*]").getOrCreate()// 导入隐式转换import spark.implicits._// 创建列表集合,存储姓名和年龄val studentList1 = List(("李克文", 23), ("张晓琳", 28))// 将列表集合转为数据帧,并指定列名name和ageval studentDF1 = spark.sparkContext.makeRDD(studentList1).toDF("name", "age")// 输出数据帧内容studentDF1.show()// 将数据帧写入HDFS指定目录studentDF1.write.mode(SaveMode.Append).parquet("hdfs://master:9000/students")// 创建列表集合,存储姓名和成绩val studentList2 = List(("梁辰兴", 66), ("陈鸿宇", 78))// 将列表集合转为数据帧,并指定列名name和ageval studentDF2 = spark.sparkContext.makeRDD(studentList2).toDF("name", "score")// 输出数据帧内容studentDF2.show()// 将数据帧写入HDFS指定目录studentDF2.write.mode(SaveMode.Append).parquet("hdfs://master:9000/students")// 读取指定目录下多个文件val mergedDF = spark.read.option("mergeSchema", true).parquet("hdfs://master:9000/students")// 输出Schema信息mergedDF.printSchema()// 输出数据帧内容mergedDF.show()}
}