一、数据库创建
- vgroups 配置
如果不了解vgroup概念,建议到官网查看:TDEngine官网-数据模型和整体架构
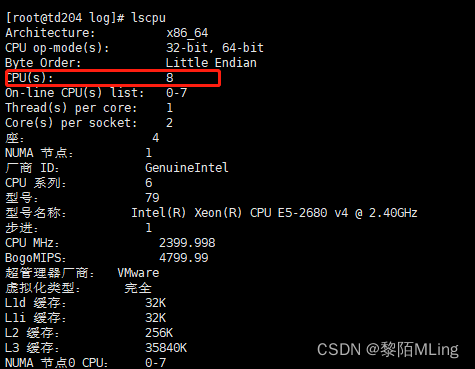
从服务端配置的角度,要根据系统中磁盘的数量,磁盘的 I/O 能力,以及处理器能力在创建数据库时设置适当的 vgroups 数量以充分发挥系统性能。如果 vgroups 过少,则系统性能无法发挥;如果 vgroups 过多,会造成无谓的资源竞争。常规推荐 vgroups 数量为 CPU 核数的 2 倍,但仍然要结合具体的系统资源配置进行调优。
#查看linux cpu核数命令:
lscpu
则 这里vgroups 设置常规为2*8=16
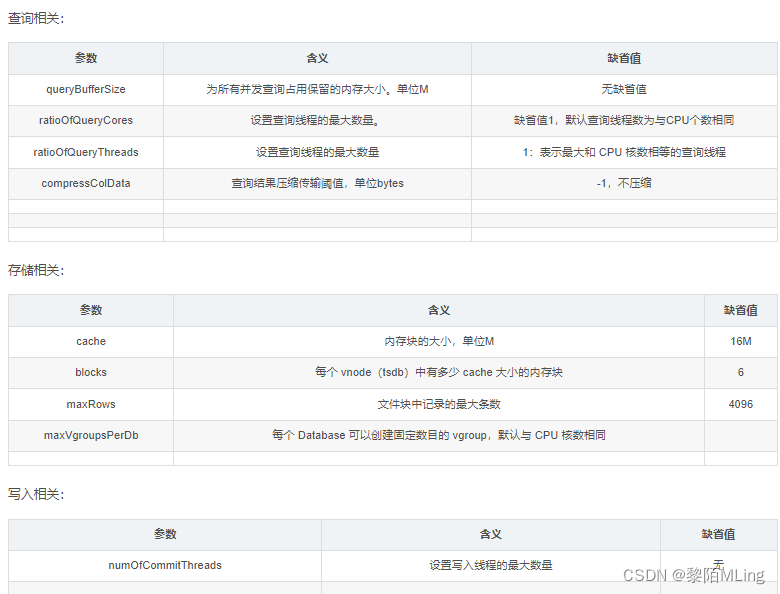
- maxRows minRows
(1)minRows:数据块中记录的最小条数,单位为条,默认值为100。
(2)maxRows:数据块中记录的最大条数,单位为条,默认值为4096。
数据块,是每个.data数据文件里存储数据的单位,每一个数据块都只能存储一个表的数据。也就是说形成一个数据块默认的最小行数是minRows行,最多就是maxRows行。表行数不足minRows时数据存放的位置.last文件;而大于maxRows行的表会生成一个新的数据块。最终在.data文件中,数据块的分布方式如下:

用实例说明:
假设创建库时使用的参数为 maxrows=1000,minrows=100。某库中有两张表A和B,我们向其中分别插入1000行和99行数据。然后,我们重启taosd服务,以上数据就会从内存中落盘到存储上。这个时候.data文件中会生成1个数据块,它就是表A的数据块1,里面拥有1000条数据。而表B的99条数据因为不足minrows所以就进入了.last文件。
接下来,继续向它们分别插入1000行和99行,然后重启taosd服务落盘。这个时候表A总共拥有2000条数据,新写入的1000行数据会被写入进表A的数据块2。而表B的数据量现在已经有了198行,大于了100行。于是它们也会被写入.data文件里面,成为表B的数据块1。
值得注意的是,当.last文件小于32k的时候,所有数据都只会追加进来。但是当.last文件大于32k的时候,每次落盘.last文件都是重写生成的了——这个的32k限制是为了防止数据的移动过于频繁。
以上场景只针对两个表,但其实放大到100个表,1000个表都是一样的逻辑。尽管每个vnode内存里存储的大量数据分属于不同的表,但是每次落盘只要这些表的行数保证大于minrows,它们都会落入到.data文件的数据块中。不满足上述条件的表数据被写入.last文件后,继续等待新数据的写入,直到该表满足了行数minrows的大小后,.last文件中该表的数据会被读入到内存,之后一起写入到.data文件中。
即:
- .data类文件存储的是真正的时序数据,为多个数据块构成。一个数据块只属于一张表,且数据块的顺序只与落盘的先后顺序有关。
- .last文件与.data文件一样,也是存储时序数据的,只不过.last文件存储的块中的数据条数小于minRows。
TDEngine知识体系
TDEngine官网-高效率写入
TDengine 的用户如何优化数据的写入速度?