1. GPU计算简介
Nvidia在1999年研发了图形处理器GPU。GPU在算术吞吐量和内存带宽上超过CPU。
尽管通用GPU模型展示了巨大的加速度,但是它也存在着几个缺点:
(1)要求程序员需要图形API和GPU架构知识;
(2)程序是用顶点坐标,纹理和shade表示;
(3)不支持内存的随机读写
(4)不支持双精度;
为了解决这些问题,NVIDIA引入了两个关键技术:G80架构统一了图形和计算,CUDA平台(软硬件平台)使得GPU可以用许多高级语言编程,人们称其为GPU 计算--表明更广的应用支持,更多的编程语言支持。
2. G80架构
生产于2006年11月的GeForce 8800导致了GPU编程模型的诞生,其中几个关键创新点在于:
(1)G80第一个支持C语言,无需学习新的编程语言;
(2)G80第一个将分隔的顶点和像流水线素用一个统一的核心来替换,该核心执行顶点、几何、像素和计算程序;
(3)G80引入了SIMT执行模型,多个独立的线程可以并发执行一条指令;
(4)G80引入共享内存和用于线程通信的路障同步;
(Tesla)2008年6月,NVIDIA对G80架构作出重大修改--即G200,提高了G80性能和功能:
(1)将流多处理器核心数目从128个增加至240,
(2)每个处理器的寄存器文件数目翻倍,促使许多线程可以并行执行;
(3)引入硬件融合内存访问提高内存访问效率;
(4)支持双精度浮点数;
3. Fermi架构
Fermi架构注重以下几方面改进:
(1)提高双精度浮点数运算性能;
(2)ECC支持,防止数据被被电磁场修改;
(3)真正的内存体系,对于不能使用共享内存的程序;
(4)更快的上下文切换--在计算或图像应用中切换;
(5)更快的原子操作;
Fermi架构关键创新点在于,极大地提高了可编程性和计算效率:
(1)第三代SM
32 CUDA cores/SM,4倍于GT200;
8倍于GT200的双精度运算速度;
双线程束调度器同时对两个独立的线程束调度和派发指令;
64KB可配置的共享/L1缓存
(2)第2代并行线程执行指令集架构(PTX ISA)
带有C++支持的一致寻址空间;
对OpenCL和DirectCompute支持优化;
完整的IEEE 754-2008 32位和64位精度;
支持64位地址内存访问;
通过分支预测提升性能
(3)改善的内存子系统
可配置L1缓存和统一L2缓存;
支持ECC内存;
极大地提升原子内存运算性能;
(4)NVIDA GigaThread Engine
10倍于GT200的上下文切换;
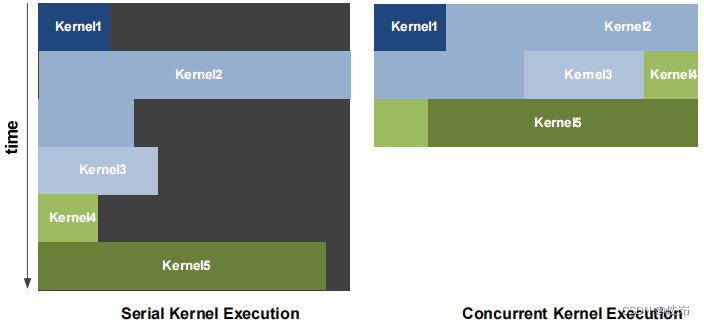
并发内核执行(软件层面,Kepler才支持硬件层面并发内核);
线程块乱序执行;
双工内存传输(同时支持读写);
4. CUDA速览
内核通过并发一组线程来并行执行。程序员和编译器把这一组线程组织成线程块和线程网格。GPU在一个并行线程块的线程网格实例化一个内核程序。线程块中每一个线程都执行内核函数的一个实例,拥有线程块内的线程编号,程序计数器,寄存器,线程私有内存,输入输出结果。
线程块是一组并发执行线程的集合,这些线程通过路障同步和共享内存协作,拥有线程网格的线程块编号。
线程网格是执行同一个内核函数的线程块的数组,从全局内存读写,在前后内核函数调用中同步。
在CUDA变成模型中,线程配给用于寄存器溢出,函数调用,C中automatic数组变量的私有内存空间。线程块配给用于线程级通信,数据共享和结果共享的共享内存。线程网格在调用内核函数级别全局同步后共享全局内存中的结果。
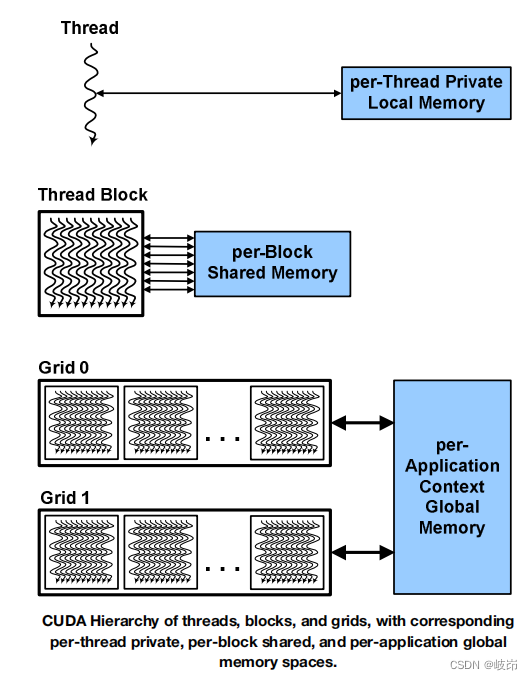
CUDA中的线程结构映射至GPU中处理器结构;GPU可以执行一个或多个内核函数;SM执行一个或多个线程块;SM上的CUDA core和执行单元执行线程;SM以线程束(32个线程)为单位执行线程。通过线程束内32个线程执行同一代码和访问相邻内存极大地提高了程序性能。
5. Fermi架构整观
Fermi GPU拥有512 CUDA core,分布在16个SM上, 有6个64位内存部分以供384位内存接口,总计6GB的GDDR5 DRAM内存,主机和设备之间通过PCIe连接,GigaThread全局调度器分配线程块至SM上的线程束调度器。

6.第三代SM
(1) 512个高性能CUDA core
每个CUDA core都有一条完整流水线的算术逻辑单元和浮点运算单元。提供单双精度FMA指令。FMA指令通过在一个时间周期左右做完乘法和加法过程来提升了MAD指令性能,而不损失精度。(在GT200中,整数逻辑单元的乘法运算限制在24位精度。)

(2)16个L/S Units
每个SM布置16个L/S Units,足以每周期为16个线程计算出源操作数地址和目的操作数地址。支持在Cache或DRAM数据读写。
(3)4个SFU
特殊功能单元执行诸如超越函数执行cos,sin,倒数,平方根。每个SFU每周期为每线程执行一条指令,一个线程束超过8个周期。SFU流水线从Dispatch Unit脱离出来,使得Dispatch Unit可以在SFU忙碌时候分派指令给其他执行单元。
(4)双精度设计
每个SM每周期可以执行16条FMA指令,远远超过GT200.

(5)双线程束调度器
每个SM配备两个线程束调度器和2个指令发射单元,能够并发调度两个线程束并执行。Fermi双线程束调度器选择两个线程束,每个线程束发射一条指令至功能单元。因为线程束的执行是独立的,Fermi线程束调度器无需检查指令流的依赖性。

大多数指令可以双发射:整数、浮点数,整、(浮,读,写,特殊指令),但是双精度指令不支持双发射。
(6)64KB可配置共享内存和L1缓存
Fermi架构一大创新点在于片上共享内存,共享内存使得同一线程块内的线程可以协作,增加片上数据重用和极大地减少片外内存事务。GT80和GT200每SM拥有16KB共享内存。Fermi架构48/16KB可配置共享内存。
小结:

7. 第二代PTX指令集架构
PTX是一种低层次虚拟机器,ISA的设计目的是支持并行线程处理器功能。PTX指令被GPU驱动翻译成机器指令。
PTX的主要目标是:
(1)提供稳定的覆盖多代GPU的指令集架构;
(2)发挥GPU全部性能;
(3)提供一个与机器无关machine-independent指令集架构;
(4)对应用和中间开发者提供code distribution;
(5)提供一种用于优化代码生成器和翻译器的通用指令集架构,将PTX映射至明确的目标机器;
(6)提供一个可扩展GPU尺寸的编程模型,从少数几个core到许多core。
PTX2.0支持32位浮点数,一致寻址空间和64位寻址,提供C++支持。
8. 一致寻址空间支持C++
Fermi架构和PTX2.0使用一致寻址空间,该空间将三个分离的空间(线程私有地址,线程块共享,全局)统一寻址读写。在PTX1.0中,读写指令必须明确地址是三者其一。而C++指针并不明确指向那块内存空间。

Fermi中硬件地址转换单元自动将指针指向正确内存地址空间。
Fermi架构和PTX2.0增加了C++中虚函数、函数指针和new/delete运算符,try/catch异常。
9. IEEE 32位浮点精度
之前的GPU将偏低的操作数置0,精度损失,MAD指令会损失一部分精度,而FMA保留了全部精度,在迭代算术计算,快速除法和平方根运算的精度得以提高。
10. 通过预测值改善的条件执行
预测值使得短路判断得以执行条件代码,而无分支指令负荷。
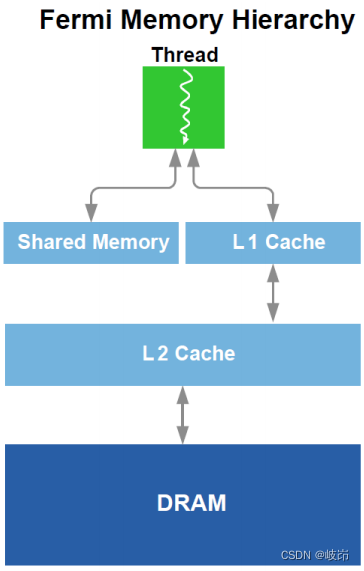
11. 内存子系统创新
(1)可配置L1缓存和统一L2缓存
优化之后的内存结构应该为共享内存和缓存都考虑在内。之前的GPU架构支持只读的纹理内存和一个用于像素数据输出的只写输出路径。很不适合C/C++期待读写有序的语言。例如一个寄存器溢出变量的读会造成写后读的灾难。
Fermi使用一个简单地一致内存请求来解决读写难题,每个SM上的L1缓存和全局L2缓存可以服务于包括读写,纹理的操作。
SM上的L1缓存可配置为支持局部或全局内存操作的共享内存和缓存。L1缓存优先配置适用于事先不知的内存访问。L1缓存也有助于缓解寄存器变量溢出情况,之前GPU架构中寄存器溢出变量至DRAM中,提升了内存访问延迟。
统一L2支持读写,纹理请求,提供了整个GPU范围内的共享变量的高速访问。
(2)第一个支持ECC内存GPU架构
(3)更快的原子内存操作
原子内存操作可以并发线程对共享数据实行read-modify-write操作。原子加,减,最大和CAS。多亏于硬件上更多的原子执行单元和L2缓存增加,Fermi的原子操作性能是GT200的20倍。
12. GigaThread线程调度器
Fermi架构的最重要技术之一是两层,分布式线程调度器。在芯片级别,全局工作分布引擎调度线程块至SM,在SM级别,每个线程束调度包含32个线程的线程束至SM中的执行单元。G80中的Giga Thread实时调度12288个线程。Fermi架构不仅提供更大线程吞吐量,而且提供更快的上下文切换,并发内核执行,和优化后的线程块调度算法。
(1)10倍快的应用上下文切换
Fermi流水线将应用切换时间优化降低至25ms以下,使得应用利用频繁的内核之间通信。
(2)并发内核执行
同一个应用的不同内核函数可以同时执行。并发内核执行使得开发者可以写出许多小内核函数来利用GPU。