允中 发自 凹非寺
量子位 报道 | 公众号 QbitAI
鹅厂开源,+1 again~
又一来自腾讯AI实验室的资源帖。
腾讯AI实验室宣布,正式开源一个大规模、高质量的中文词向量数据集。
该数据包含800多万中文词汇,相比现有的公开数据集,在覆盖率、新鲜度及准确性上大幅提高。
在对话回复质量预测、医疗实体识别等自然语言处理方向的业务应用方面,腾讯内部效果提升显著。

数据集特点
总体来讲,腾讯AI实验室此次公开的中文词向量数据集包含800多万中文词汇,其中每个词对应一个200维的向量。
具体方面,腾讯自称,该数据集着重在3方面进行了提升:
覆盖率(Coverage):
该词向量数据集包含很多现有公开的词向量数据集所欠缺的短语,比如“不念僧面念佛面”、“冰火两重天”、“煮酒论英雄”、“皇帝菜”、“喀拉喀什河”等。
以“喀拉喀什河”为例,利用腾讯AI Lab词向量计算出的语义相似词如下:
墨玉河、和田河、玉龙喀什河、白玉河、喀什河、叶尔羌河、克里雅河、玛纳斯河
新鲜度(Freshness):
该数据集包含一些最近一两年出现的新词,如“恋与制作人”、“三生三世十里桃花”、“打call”、“十动然拒”、“供给侧改革”、“因吹斯汀”等。
以“因吹斯汀”为例,利用腾讯AI Lab词向量计算出的语义相似词如下:
一颗赛艇、因吹斯听、城会玩、厉害了word哥、emmmmm、扎心了老铁、神吐槽、可以说是非常爆笑了
准确性(Accuracy):
由于采用了更大规模的训练数据和更好的训练算法,所生成的词向量能够更好地表达词之间的语义关系,如下列相似词检索结果所示:
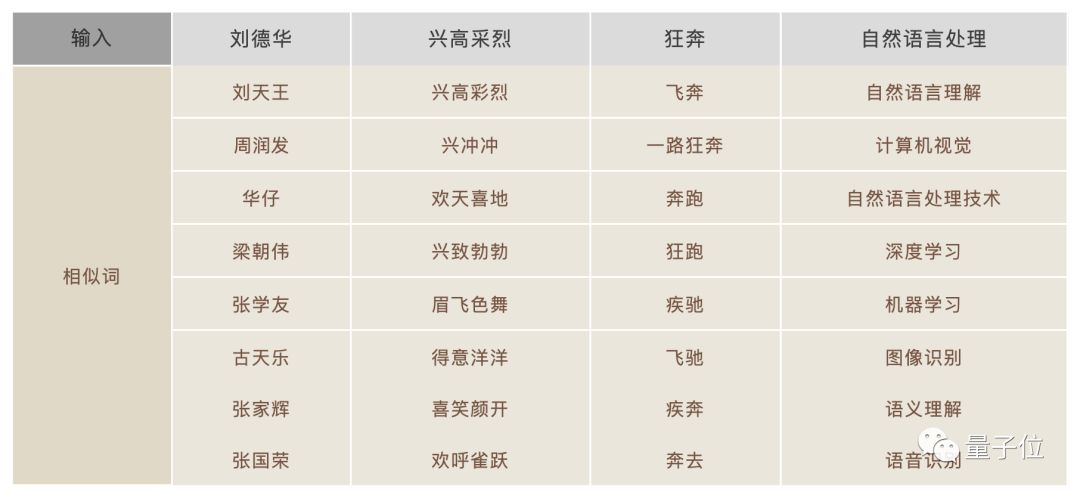
在开源前,腾讯内部经历了多次测评,认为该数据集相比于现有的公开数据集,在相似度和相关度指标上均达到了更高的分值。
数据集构建经验
那么这样的数据集,腾讯AI实验室是如何构建的呢?
他们围绕3方面分享了构建及优化经验:
语料采集:
训练词向量的语料来自腾讯新闻和天天快报的新闻语料,以及自行抓取的互联网网页和小说语料。
大规模多来源语料的组合,使得所生成的词向量数据集能够涵盖多种类型的词汇。
而采用新闻数据和最新网页数据对新词建模,也使得词向量数据集的新鲜度大为提升。
词库构建:
除了引入维基百科和百度百科的部分词条之外,还实现了Shi等人于2010年提出的语义扩展算法,可从海量的网页数据中自动发现新词——根据词汇模式和超文本标记模式,在发现新词的同时计算新词之间的语义相似度。
训练算法:
腾讯AI Lab采用自研的Directional Skip-Gram (DSG)算法作为词向量的训练算法。
DSG算法基于广泛采用的词向量训练算法Skip-Gram (SG),在文本窗口中词对共现关系的基础上,额外考虑了词对的相对位置,以提高词向量语义表示的准确性。

意义
最后,表扬一下鹅厂的开源之举。
目前针对英语环境,工业界和学术界已发布了一些高质量的词向量数据集,并得到了广泛的使用和验证。
其中较为知名的有谷歌公司基于word2vec算法、斯坦福大学基于GloVe算法、Facebook基于fastText项目发布的数据集等。
然而,目前公开可下载的中文词向量数据集还比较少,并且数据集的词汇覆盖率有所不足,特别是缺乏很多短语和网络新词。
所以有资源有能力的腾讯,还有心做这样的事情,对业界实属利好。
希望腾讯AI实验室的开源之举,多多益善吧~
传送门
数据下载地址:https://ai.tencent.com/ailab/nlp/embedding.html
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
加入社群
量子位AI社群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态