theme: juejin
来自社区 PeterH0323 投稿
AI 已经被应用到各行各业,现如今任何人都可以轻松基于开源框架快速搭建符合自身需求的 AI 应用。本文将基于 MMYOLO 开源框架,基于生活中收集的猫猫数据集,教你如何从零开始训练一个可部署检测模型。
本文档配套的视频已发布在 B 站,可前去查看: 自定义数据集从标注到部署保姆级教程
本教程所有指令是在 Linux 上面完成,Windows 也是完全可用的,但是命令和操作稍有不同。
本文为实践操作类教程。为了让不同水平用户都能基于自定义数据训练出一个不错的模型,本文将分成多个步骤详细描述。如果你自定义数据集训练效果不佳,麻烦你按照本文步骤逐条确认下是否有不正确或者不合理的地方。
完整步骤如下
- 数据集准备:
tools/misc/download_dataset.py - 使用 labelme 和算法进行辅助标注:
demo/image_demo.py+ labelme - 使用脚本转换成 COCO 数据集格式:
tools/dataset_converters/labelme2coco.py - 数据集划分为训练集、验证集和测试集:
tools/misc/coco_split.py - 构建 config 文件
- 数据集可视化分析:
tools/analysis_tools/dataset_analysis.py - 优化 anchor 尺寸:
tools/analysis_tools/optimize_anchors.py - 可视化数据处理部分:
tools/analysis_tools/browse_dataset.py - 启动训练:
tools/train.py - 模型推理:
demo/image_demo.py - 模型部署
在训练得到模型权重和验证集的 mAP 后,用户需要对预测错误的 bad case 进行深入分析,以便优化模型,MMYOLO 在后续会增加这个功能,敬请期待。
由于内容较多,因此本文只描述核心部分,详细文档请看视频或者官方文档: https://github.com/open-mmlab/mmyolo/blob/main/docs/zh_cn/user_guides/custom_dataset.md
本教程基于 MMYOLO 0.2.0,随着版本迭代更新,可能有些参数会有所改变,如果发现就不一致则请切换到 dev 分支使用,请知悉!
1. 数据集准备
为了方便大家从零开始并且不用自己准备数据集,MMYOLO 热心社区用户 @RangeKing 提供了一个 144 张图片的 cat 数据集,并由 @PeterH0323 进行数据清洗,本文都以这个小数据集为例进行讲解。
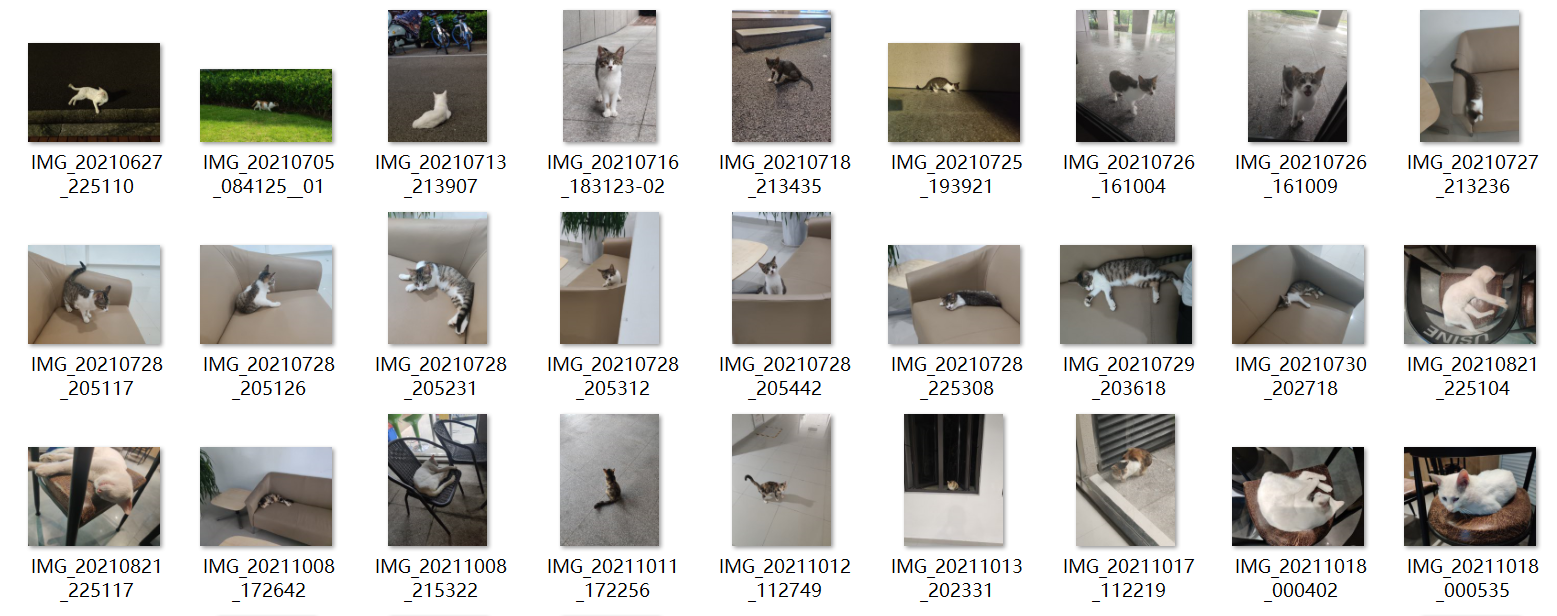
下载也非常简单,只需要一条命令即可完成(数据集压缩包大小 217 MB):
python tools/misc/download_dataset.py --dataset-name cat --save-dir ./data/cat --unzip --delete
该命令会自动下载数据集到 ./data/cat 文件夹中,该文件的目录结构是:
.
└── ./data/cat├── images # 图片文件│ ├── image1.jpg│ ├── image2.png│ └── ...├── labels # labelme 标注文件│ ├── image1.json│ ├── image2.json│ └── ...├── annotations # 数据集划分的 COCO 文件│ ├── annotations_all.json # 全量数据的 COCO label 文件│ ├── trainval.json # 划分比例 80% 的数据│ └── test.json # 划分比例 20% 的数据└── class_with_id.txt # id + class_name 文件
这个数据集可以直接训练,如果您想体验整个流程的话,可以将 images 文件夹以外的其余文件都删除。
2. 使用 labelme 和算法进行辅助标注
有了数据集后,如果要训练必然是要标注的,通常,标注有 2 种方法:
- 软件或者算法辅助 + 人工修正 label(推荐,降本提速)
- 仅人工标注
为了减少标注时间,MMYOLO 特意基于 labelme 支持了软件辅助标注功能。
辅助标注的原理是用已有模型进行推理,将得出的推理信息保存为标注软件 label 文件格式。然后人工操作标注软件加载生成好的 label 文件,只需要检查每张图片的目标是否标准,以及是否有漏掉、错标的目标。
如果已有模型(典型的如 COCO 预训练模型)没有您自定义新数据集的类别,建议先人工打 100 张左右的图片 label,训练个初始模型,然后再进行辅助标注。
下面会分别介绍其过程。
2.1 算法辅助标注
使用 MMYOLO 提供的模型推理脚本 demo/image_demo.py,并设置 --to-labelme 则可以将推理结果生成 labelme 格式的 label 文件。
这里使用 YOLOv5-s 作为例子来进行辅助标注刚刚下载的 cat 数据集,先下载 YOLOv5-s 的权重:
mkdir work_dirs
wget https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth -P ./work_dirs
由于 COCO 80 类数据集中已经包括了 cat 这一类,因此我们可以直接加载 COCO 预训练权重进行辅助标注:
python demo/image_demo.py ./data/cat/images \./configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \./work_dirs/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \--out-dir ./data/cat/labels \--class-name cat \--to-labelme
生成的 label 文件会在 --out-dir 中:
.
└── $OUT_DIR├── image1.json├── image1.json└── ...
这是一张原图及其生成的 json 例子:

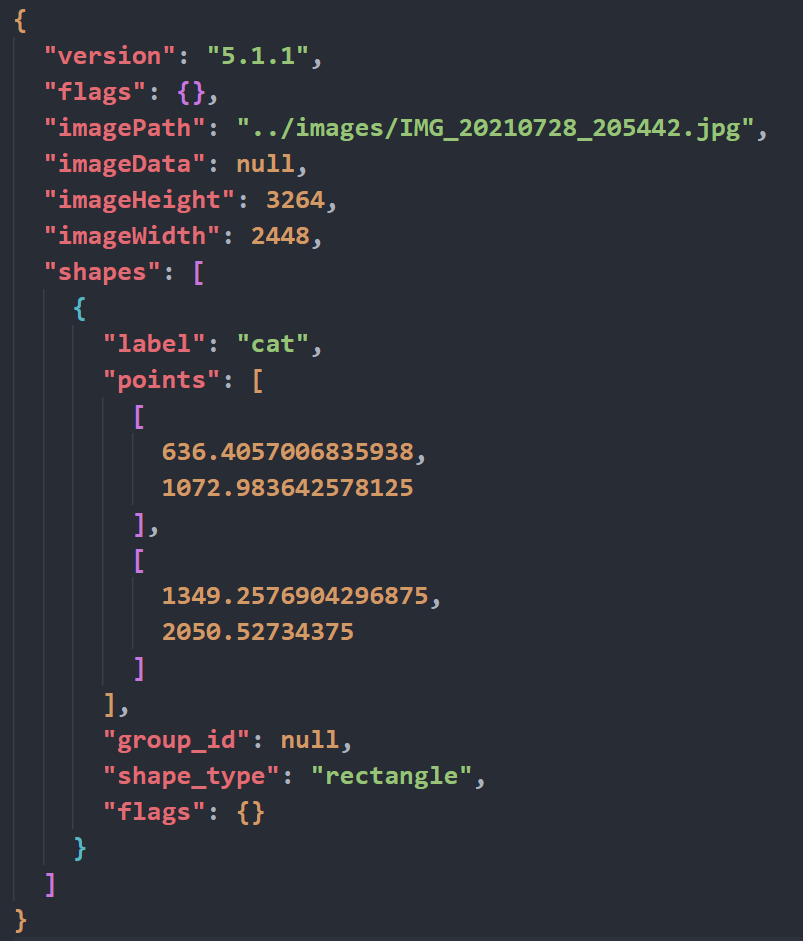
2.2 人工校正标签
在算法辅助标注后,需要人工检查伪标签是否有问题,本教程使用的标注软件是 labelme。
- 安装 labelme
conda create -n labelme python=3.8
conda activate labelme
pip install labelme==5.1.1
- 启动 labelme
cd /path/to/mmyolo
labelme ./data/cat/images --output ./data/cat/labels --autosave --nodata
输入命令之后 labelme 就会启动,然后进行 label 检查即可。如果 labelme 启动失败,命令行输入 export QT_DEBUG_PLUGINS=1 查看具体缺少什么库,安装一下即可。下面是一张采用 labelme 软件打开的效果图:

3. 使用脚本转换成 COCO 数据集格式
标注的格式需要转换为最常用的 COCO 格式,这也是方便后续可视化分析。
3.1 使用脚本转换
MMYOLO 提供脚本将 labelme 的 label 转换为 COCO label:
python tools/dataset_converters/labelme2coco.py --img-dir ${图片文件夹路径} \--labels-dir ${label 文件夹位置} \--out ${输出 COCO label json 路径} \[--class-id-txt ${class_with_id.txt 路径}]
其中: --class-id-txt:是数据集 id class_name 的 .txt 文件:
- 如果不指定,则脚本会自动生成,生成在
--out同级的目录中,保存文件名为class_with_id.txt; - 如果指定,脚本仅会进行读取但不会新增或者覆盖,同时,脚本里面还会判断是否存在
.txt中其他的类,如果出现了会报错提示,届时,请用户检查.txt文件并加入新的类及其id。
.txt 文件的例子如下( id 可以和 COCO 一样,从 1 开始):
1 cat
2 dog
3 bicycle
4 motorcycle
以本教程的 cat 数据集为例:
python tools/dataset_converters/labelme2coco.py --img-dir ./data/cat/images \--labels-dir ./data/cat/labels \--out ./data/cat/annotations/annotations_all.json
本次演示的 cat 数据集(注意不需要包括背景类),可以看到生成的 class_with_id.txt 中只有 1 类:
1 cat
3.2 检查转换的 COCO label
使用下面的命令可以将 COCO 的 label 在图片上进行显示,这一步可以验证刚刚转换是否有问题:
python tools/analysis_tools/browse_coco_json.py --img-dir ./data/cat/images \--ann-file ./data/cat/annotations/annotations_all.json

关于 tools/analysis_tools/browse_coco_json.py 的更多用法请参考 可视化 COCO label。
4. 数据集划分为训练集、验证集和测试集
通常,自定义图片都是一个大文件夹,里面全部都是图片,需要我们自己去对图片进行训练集、验证集、测试集的划分,如果数据量比较少,可以不划分验证集。下面是划分脚本的具体用法:
python tools/misc/coco_split.py --json ${COCO label json 路径} \--out-dir ${划分 label json 保存根路径} \--ratios ${划分比例} \[--shuffle] \[--seed ${划分的随机种子}]
其中:
-
--ratios:划分的比例,如果只设置了 2 个,则划分为trainval + test;如果设置为 3 个,则划分为train + val + test。支持两种格式 —— 整数、小数:- 整数:按比例进行划分,代码中会进行归一化之后划分数据集。例子:
--ratio 2 1 1(代码里面会转换成0.5 0.25 0.25) or--ratio 3 1(代码里面会转换成0.75 0.25) - 小数:划分为比例。如果加起来不为 1 ,则脚本会进行自动归一化修正。例子:
--ratio 0.8 0.1 0.1or--ratio 0.8 0.2
- 整数:按比例进行划分,代码中会进行归一化之后划分数据集。例子:
-
--shuffle: 是否打乱数据集再进行划分。 -
--seed:设定划分的随机种子,不设置的话自动生成随机种子。
例子:
python tools/misc/coco_split.py --json ./data/cat/annotations/annotations_all.json \--out-dir ./data/cat/annotations \--ratios 0.8 0.2 \--shuffle \--seed 10

5. 构建 config 文件
在自定义的数据集准备工作都完成后,需要自己新建一个 config 并加入需要修改的部分信息。此处以 YOLOv5-s 算法为例,config 的命名规则:
- config 继承的是
yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py; - 训练的类以本教程提供的数据集中的类
cat为例(如果是自己的数据集,可以自定义类型的总称); - 本教程测试的显卡型号是 1 x 3080Ti 12G 显存,电脑内存 32G,可以训练 YOLOv5-s 最大批次是
batch size = 32(详细机器资料可见附录); - 训练轮次是
100 epoch。
综上所述:可以将其命名为 yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py,并将其放置在文件夹 configs/custom_dataset 中。
我们可以在 configs 目录下新建一个新的目录 custom_dataset,同时在里面新建该 config 文件,并添加以下内容:
_base_ = '../yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py'max_epochs = 100 # 训练的最大 epoch
data_root = './data/cat/' # 数据集目录的绝对路径
# data_root = '/root/workspace/mmyolo/data/cat/' # Docker 容器里面数据集目录的绝对路径# 结果保存的路径,可以省略,省略保存的文件名位于 work_dirs 下 config 同名的文件夹中
# 如果某个 config 只是修改了部分参数,修改这个变量就可以将新的训练文件保存到其他地方
work_dir = './work_dirs/yolov5_s-v61_syncbn_fast_1xb32-100e_cat'# load_from 可以指定本地路径或者 URL,设置了 URL 会自动进行下载,因为上面已经下载过,我们这里设置本地路径
# 因为本教程是在 cat 数据集上微调,故这里需要使用 `load_from` 来加载 MMYOLO 中的预训练模型,这样可以在加快收敛速度的同时保证精度
load_from = './work_dirs/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth' # noqa# 根据自己的 GPU 情况,修改 batch size,YOLOv5-s 默认为 8卡 x 16bs
train_batch_size_per_gpu = 32
train_num_workers = 4 # 推荐使用 train_num_workers = nGPU x 4save_epoch_intervals = 2 # 每 interval 轮迭代进行一次保存一次权重# 根据自己的 GPU 情况,修改 base_lr,修改的比例是 base_lr_default * (your_bs / default_bs)
base_lr = _base_.base_lr / 4anchors = [ # 此处已经根据数据集特点更新了 anchor,关于 anchor 的生成,后面小节会讲解[(68, 69), (154, 91), (143, 162)], # P3/8[(242, 160), (189, 287), (391, 207)], # P4/16[(353, 337), (539, 341), (443, 432)] # P5/32
]class_name = ('cat', ) # 根据 class_with_id.txt 类别信息,设置 class_name
num_classes = len(class_name)
metainfo = dict(CLASSES=class_name, # 注意:这个字段在最新版本中换成了小写PALETTE=[(220, 20, 60)] # 画图时候的颜色,随便设置即可
)train_cfg = dict(max_epochs=max_epochs,val_begin=20, # 第几个 epoch 后验证,这里设置 20 是因为前 20 个 epoch 精度不高,测试意义不大,故跳过val_interval=save_epoch_intervals # 每 val_interval 轮迭代进行一次测试评估
)model = dict(bbox_head=dict(head_module=dict(num_classes=num_classes),prior_generator=dict(base_sizes=anchors),# loss_cls 会根据 num_classes 动态调整,但是 num_classes = 1 的时候,loss_cls 恒为 0loss_cls=dict(loss_weight=0.5 *(num_classes / 80 * 3 / _base_.num_det_layers))))train_dataloader = dict(batch_size=train_batch_size_per_gpu,num_workers=train_num_workers,dataset=dict(_delete_=True,type='RepeatDataset',# 数据量太少的话,可以使用 RepeatDataset ,在每个 epoch 内重复当前数据集 n 次,这里设置 5 是重复 5 次times=5,dataset=dict(type=_base_.dataset_type,data_root=data_root,metainfo=metainfo,ann_file='annotations/trainval.json',data_prefix=dict(img='images/'),filter_cfg=dict(filter_empty_gt=False, min_size=32),pipeline=_base_.train_pipeline)))val_dataloader = dict(dataset=dict(metainfo=metainfo,data_root=data_root,ann_file='annotations/trainval.json',data_prefix=dict(img='images/')))test_dataloader = val_dataloaderval_evaluator = dict(ann_file=data_root + 'annotations/trainval.json')
test_evaluator = val_evaluatoroptim_wrapper = dict(optimizer=dict(lr=base_lr))default_hooks = dict(# 设置间隔多少个 epoch 保存模型,以及保存模型最多几个,`save_best` 是另外保存最佳模型(推荐)checkpoint=dict(type='CheckpointHook',interval=save_epoch_intervals,max_keep_ckpts=5,save_best='auto'),param_scheduler=dict(max_epochs=max_epochs),# logger 输出的间隔logger=dict(type='LoggerHook', interval=10))
我们在 projects/misc/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py 放了一份相同的 config 文件,用户可以选择复制到 configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py 路径直接开始训练。
6. 数据集可视化分析
数据集可视化分析有两个目的:
- 验证配置文件写的是否正确
- 对数据集有个初步分析
脚本 tools/analysis_tools/dataset_analysis.py 能够帮助用户得到数据集的分析图。该脚本可以生成 4 种分析图:
- 显示类别和 bbox 实例个数的分布图:
show_bbox_num - 显示类别和 bbox 实例宽、高的分布图:
show_bbox_wh - 显示类别和 bbox 实例宽/高比例的分布图:
show_bbox_wh_ratio - 基于面积规则下,显示类别和 bbox 实例面积的分布图:
show_bbox_area
以本教程 cat 数据集 的 config 为例。
查看训练集数据分布情况:
python tools/analysis_tools/dataset_analysis.py configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py \--out-dir work_dirs/dataset_analysis_cat/train_dataset
查看验证集数据分布情况:
python tools/analysis_tools/dataset_analysis.py configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py \--out-dir work_dirs/dataset_analysis_cat/val_dataset \--val-dataset
| 基于面积规则下,显示类别和 bbox 实例面积的分布图 | 显示类别和 bbox 实例宽、高的分布图 |
|---|---|
 |  |
| 显示类别和 bbox 实例个数的分布图 | 显示类别和 bbox 实例宽/高比例的分布图 |
 |  |
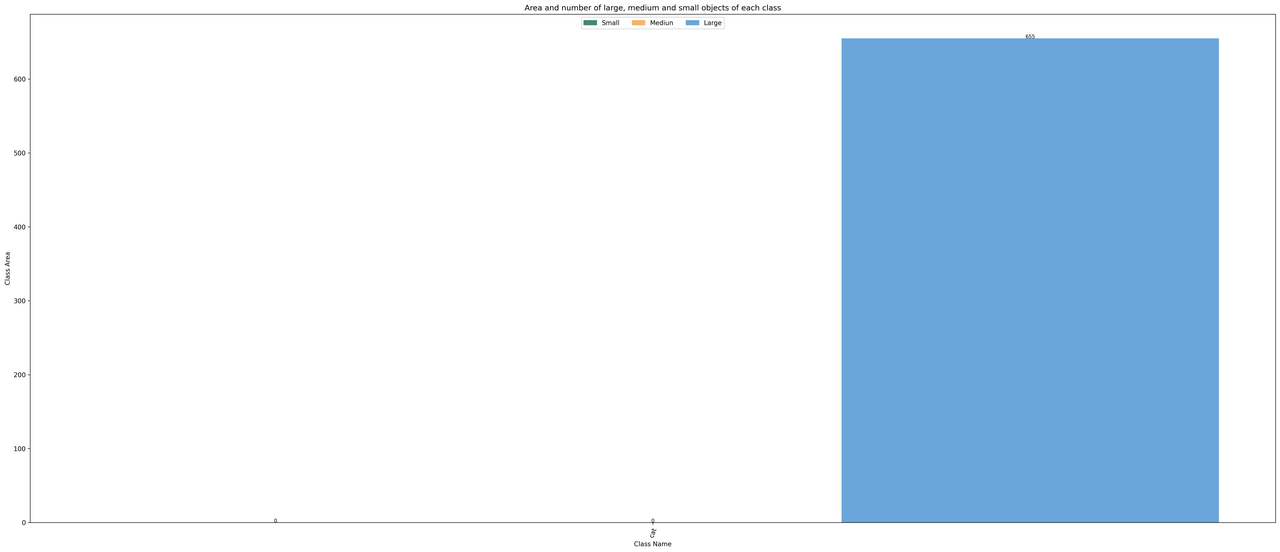
基于面积规则下,显示类别和 bbox 实例面积的分布图
显示类别和 bbox 实例宽、高的分布图

显示类别和 bbox 实例个数的分布图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tmokTAs8-1672831496747)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/2e539f094b66445d91013458838e97fc~tplv-k3u1fbpfcp-zoom-1.image)]
显示类别和 bbox 实例宽/高比例的分布图
因为本教程使用的 cat 数据集数量比较少,故 config 里面用了 RepeatDataset,显示的数目实际上都是重复了 5 次。如果您想得到无重复的分析结果,可以暂时将 RepeatDataset 下面的 times 参数从 5 改成 1。
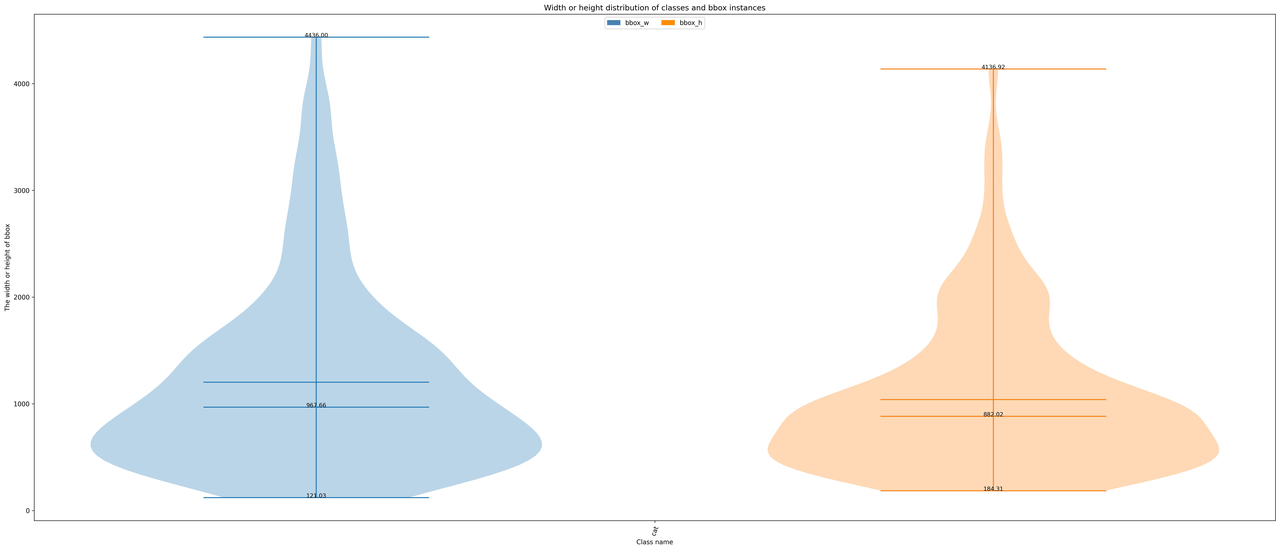
经过输出的图片分析可以得出,本教程使用的 cat 数据集的训练集具有以下情况:
- 图片全部是
large object; - 类别 cat 的数量是
655; - bbox 的宽高比例大部分集中在
1.0 ~ 1.11,比例最小值是0.36,最大值是2.9; - bbox 的宽大部分是
500 ~ 600左右,高大部分是500 ~ 600左右。
关于 tools/analysis_tools/dataset_analysis.py 的更多用法请参考 可视化数据集分析 。
7. 优化 Anchor 尺寸
YOLOv5 是一个 anchor-based 算法,需要对 anchor 进行自适应计算,anchor-free 的模型可以跳过此步骤。
脚本 tools/analysis_tools/optimize_anchors.py 支持 YOLO 系列中三种锚框生成方式,分别是 k-means、Differential Evolution、v5-k-means。
本示例使用的是 YOLOv5 进行训练,使用的是 640 x 640 的输入大小,使用 v5-k-means 进行描框的优化:
python tools/analysis_tools/optimize_anchors.py configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py \--algorithm v5-k-means \--input-shape 640 640 \--prior-match-thr 4.0 \--out-dir work_dirs/dataset_analysis_cat
经过计算的 Anchor 如下:

修改 config 文件里面的 anchors 变量:
anchors = [[(68, 69), (154, 91), (143, 162)], # P3/8[(242, 160), (189, 287), (391, 207)], # P4/16[(353, 337), (539, 341), (443, 432)] # P5/32
]
因为该命令使用的是 k-means 聚类算法,存在一定的随机性,这与初始化有关。故每次执行得到的 Anchor 都会有些不一样,但是都是基于传递进去的数据集来进行生成的,故不会有什么不良影响。
关于 tools/analysis_tools/optimize_anchors.py 的更多用法请参考 优化锚框尺寸。
8. 可视化数据处理部分
脚本 tools/analysis_tools/browse_dataset.py 能够帮助用户直接可视化 config 配置中数据处理部分,同时可以选择保存可视化图片到指定文件夹内。
下面演示使用我们刚刚新建的 config 文件 configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py 来可视化图片,该命令会使得图片直接弹出显示,每张图片持续 3 秒,图片不进行保存:
python tools/analysis_tools/browse_dataset.py configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py \--show-interval 3


关于 tools/analysis_tools/browse_dataset.py 的更多用法请参考 可视化数据集 。
9. 启动训练
下面会从以下 3 点来进行讲解:
- 训练可视化
- YOLOv5 模型训练
- 切换 YOLO 模型训练
9.1 训练可视化
如果需要采用浏览器对训练过程可视化,MMYOLO 目前提供 2 种方式: WandB 和 TensorBoard,根据自己的情况选择其一即可(后续会扩展更多可视化后端支持)。
9.1.1 WandB
WandB 可视化需要在官网注册,并在 https://wandb.ai/settings 获取到 WandB 的 API Keys。
然后在命令行进行安装:
pip install wandb
# 运行了 wandb login 后输入上文中获取到的 API Keys ,便登录成功。
wandb login

在我们刚刚新建的 config 文件 configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py 的最后添加 WandB 配置:
visualizer = dict(vis_backends=[dict(type='LocalVisBackend'), dict(type='WandbVisBackend')])
9.1.2 TensorBoard
安装 Tensorboard 环境:
pip install tensorboard
在我们刚刚新建的 config 文件 configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py 中添加 tensorboard 配置:
visualizer = dict(vis_backends=[dict(type='LocalVisBackend'),dict(type='TensorboardVisBackend')])
运行训练命令后,Tensorboard 文件会生成在可视化文件夹 work_dirs/yolov5_s-v61_syncbn_fast_1xb32-100e_cat/${TIMESTAMP}/vis_data 下, 运行下面的命令便可以在网页链接使用 Tensorboard 查看 loss、学习率和 coco/bbox_mAP 等可视化数据了:
tensorboard --logdir=work_dirs/yolov5_s-v61_syncbn_fast_1xb32-100e_cat
9.2 执行训练
使用下面命令进行启动训练(训练大约需要 2.5 个小时):
python tools/train.py configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py
如果您开启了 WandB 的话,可以登录到自己的账户,在 WandB 中查看本次训练的详细信息了:
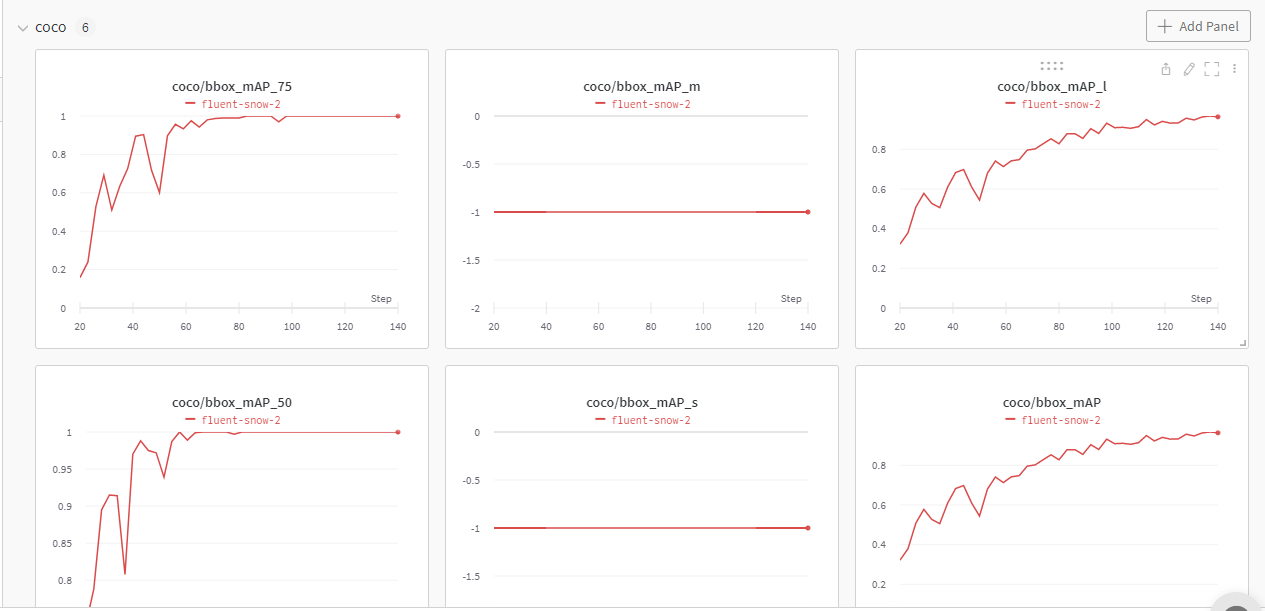

下面是 1 x 3080Ti、batch size = 32,训练 100 epoch 最佳精度权重 work_dirs/yolov5_s-v61_syncbn_fast_1xb32-100e_cat/best_coco/bbox_mAP_epoch_98.pth 得出来的精度(详细机器资料可见附录):
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.968Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 1.000Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 1.000Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.968Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.886Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.977Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.977Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.977bbox_mAP_copypaste: 0.968 1.000 1.000 -1.000 -1.000 0.968
Epoch(val) [98][116/116] coco/bbox_mAP: 0.9680 coco/bbox_mAP_50: 1.0000 coco/bbox_mAP_75: 1.0000 coco/bbox_mAP_s: -1.0000 coco/bbox_mAP_m: -1.0000 coco/bbox_mAP_l: 0.9680
在一般的 finetune 最佳实践中都会推荐将 backbone 固定不参与训练,并且学习率 lr 也进行相应缩放,但是在本教程中发现这种做法会出现一定程度掉点。猜测可能原因是 cat 类别已经在 COCO 数据集中,而本教程使用的 cat 数据集数量比较小导致的。
下表是采用 MMYOLO YOLOv5 预训练模型 yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth 在没对 cat 数据集进行 finetune 的测试精度,可以看到 cat 类别的 mAP 只有 0.866,经过我们 finetune mAP 提升到了 0.968,提升了 10.2 %,可以证明训练是非常成功的:
+---------------+-------+--------------+-----+----------------+------+
| category | AP | category | AP | category | AP |
+---------------+-------+--------------+-----+----------------+------+
| person | nan | bicycle | nan | car | nan |
| motorcycle | nan | airplane | nan | bus | nan |
| train | nan | truck | nan | boat | nan |
| traffic light | nan | fire hydrant | nan | stop sign | nan |
| parking meter | nan | bench | nan | bird | nan |
| cat | 0.866 | dog | nan | horse | nan |
| sheep | nan | cow | nan | elephant | nan |
| bear | nan | zebra | nan | giraffe | nan |
| backpack | nan | umbrella | nan | handbag | nan |
| tie | nan | suitcase | nan | frisbee | nan |
| skis | nan | snowboard | nan | sports ball | nan |
| kite | nan | baseball bat | nan | baseball glove | nan |
| skateboard | nan | surfboard | nan | tennis racket | nan |
| bottle | nan | wine glass | nan | cup | nan |
| fork | nan | knife | nan | spoon | nan |
| bowl | nan | banana | nan | apple | nan |
| sandwich | nan | orange | nan | broccoli | nan |
| carrot | nan | hot dog | nan | pizza | nan |
| donut | nan | cake | nan | chair | nan |
| couch | nan | potted plant | nan | bed | nan |
| dining table | nan | toilet | nan | tv | nan |
| laptop | nan | mouse | nan | remote | nan |
| keyboard | nan | cell phone | nan | microwave | nan |
| oven | nan | toaster | nan | sink | nan |
| refrigerator | nan | book | nan | clock | nan |
| vase | nan | scissors | nan | teddy bear | nan |
| hair drier | nan | toothbrush | nan | None | None |
+---------------+-------+--------------+-----+----------------+------+
9.3 尝试 MMYOLO 其他模型
MMYOLO 集成了多种 YOLO 算法,切换非常方便,无需重新熟悉一个新的 repo,直接切换 config 文件就可以轻松切换 YOLO 模型,只需简单 3 步即可切换模型:
- 构建 config 文件
- 下载预训练权重
- 启动训练
MMEngine 的配置文件写法非常灵活,支持多层继承,选择不同的 base 文件后继承重写的配置也不一样。以 YOLOv6-s 为例,如果你选择直接继承上述的 YOLOv5 cat 配置,那么需要改动的地方非常少。不过为了减少继承层级,我们依然以 YOLOv6-s 配置作为 base。
- 搭建一个新的 config:
_base_ = '../yolov6/yolov6_s_syncbn_fast_8xb32-400e_coco.py'max_epochs = 100 # 训练的最大 epoch
data_root = './data/cat/' # 数据集目录的绝对路径# 结果保存的路径,可以省略,省略保存的文件名位于 work_dirs 下 config 同名的文件夹中
# 如果某个 config 只是修改了部分参数,修改这个变量就可以将新的训练文件保存到其他地方
work_dir = './work_dirs/yolov6_s_syncbn_fast_1xb32-100e_cat'# load_from 可以指定本地路径或者 URL,设置了 URL 会自动进行下载,因为上面已经下载过,我们这里设置本地路径
# 因为本教程是在 cat 数据集上微调,故这里需要使用 `load_from` 来加载 MMYOLO 中的预训练模型,这样可以在加快收敛速度的同时保证精度
load_from = './work_dirs/yolov6_s_syncbn_fast_8xb32-400e_coco_20221102_203035-932e1d91.pth' # noqa# 根据自己的 GPU 情况,修改 batch size,YOLOv6-s 默认为 8卡 x 32bs
train_batch_size_per_gpu = 32
train_num_workers = 4 # 推荐使用 train_num_workers = nGPU x 4save_epoch_intervals = 2 # 每 interval 轮迭代进行一次保存一次权重# 根据自己的 GPU 情况,修改 base_lr,修改的比例是 base_lr_default * (your_bs / default_bs)
base_lr = _base_.base_lr / 8class_name = ('cat', ) # 根据 class_with_id.txt 类别信息,设置 class_name
num_classes = len(class_name)
metainfo = dict(CLASSES=class_name, # 注意: 在新版本中已经换成了小写PALETTE=[(220, 20, 60)] # 画图时候的颜色,随便设置即可
)train_cfg = dict(max_epochs=max_epochs,val_begin=20, # 第几个 epoch 后验证,这里设置 20 是因为前 20 个 epoch 精度不高,测试意义不大,故跳过val_interval=save_epoch_intervals, # 每 val_interval 轮迭代进行一次测试评估dynamic_intervals=[(max_epochs - _base_.num_last_epochs, 1)]
)model = dict(bbox_head=dict(head_module=dict(num_classes=num_classes)),train_cfg=dict(initial_assigner=dict(num_classes=num_classes),assigner=dict(num_classes=num_classes))
)train_dataloader = dict(batch_size=train_batch_size_per_gpu,num_workers=train_num_workers,dataset=dict(_delete_=True,type='RepeatDataset',# 数据量太少的话,可以使用 RepeatDataset ,在每个 epoch 内重复当前数据集 n 次,这里设置 5 是重复 5 次times=5,dataset=dict(type=_base_.dataset_type,data_root=data_root,metainfo=metainfo,ann_file='annotations/trainval.json',data_prefix=dict(img='images/'),filter_cfg=dict(filter_empty_gt=False, min_size=32),pipeline=_base_.train_pipeline)))val_dataloader = dict(dataset=dict(metainfo=metainfo,data_root=data_root,ann_file='annotations/trainval.json',data_prefix=dict(img='images/')))test_dataloader = val_dataloaderval_evaluator = dict(ann_file=data_root + 'annotations/trainval.json')
test_evaluator = val_evaluatoroptim_wrapper = dict(optimizer=dict(lr=base_lr))default_hooks = dict(# 设置间隔多少个 epoch 保存模型,以及保存模型最多几个,`save_best` 是另外保存最佳模型(推荐)checkpoint=dict(type='CheckpointHook',interval=save_epoch_intervals,max_keep_ckpts=5,save_best='auto'),param_scheduler=dict(max_epochs=max_epochs),# logger 输出的间隔logger=dict(type='LoggerHook', interval=10))custom_hooks = [dict(type='EMAHook',ema_type='ExpMomentumEMA',momentum=0.0001,update_buffers=True,strict_load=False,priority=49),dict(type='mmdet.PipelineSwitchHook',switch_epoch=max_epochs - _base_.num_last_epochs,switch_pipeline=_base_.train_pipeline_stage2)
]
同样,我们在 projects/misc/custom_dataset/yolov6_s_syncbn_fast_1xb32-100e_cat.py 放了一份相同的 config 文件,用户可以选择复制到 configs/custom_dataset/yolov6_s_syncbn_fast_1xb32-100e_cat.py 路径直接开始训练。 虽然新的 config 看上去好像很多东西,其实很多都是重复的,用户可以用对比软件对比一下即可看出大部分的配置都是和 yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py 相同的。因为这 2 个 config 文件需要继承不同的 config,所以还是要添加一些必要的配置。
- 下载 YOLOv6-s 的预训练权重
wget https://download.openmmlab.com/mmyolo/v0/yolov6/yolov6_s_syncbn_fast_8xb32-400e_coco/yolov6_s_syncbn_fast_8xb32-400e_coco_20221102_203035-932e1d91.pth -P work_dirs/
- 训练
python tools/train.py configs/custom_dataset/yolov6_s_syncbn_fast_1xb32-100e_cat.py
在我的实验中,最佳模型是 work_dirs/yolov6_s_syncbn_fast_1xb32-100e_cat/best_coco/bbox_mAP_epoch_96.pth,其精度如下:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.987Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 1.000Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 1.000Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.987Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.895Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.989Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.989Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.989bbox_mAP_copypaste: 0.987 1.000 1.000 -1.000 -1.000 0.987
Epoch(val) [96][116/116] coco/bbox_mAP: 0.9870 coco/bbox_mAP_50: 1.0000 coco/bbox_mAP_75: 1.0000 coco/bbox_mAP_s: -1.0000 coco/bbox_mAP_m: -1.0000 coco/bbox_mAP_l: 0.9870
以上演示的是如何在 MMYOLO 中切换模型,可以快速对不同模型进行精度对比,精度高的模型可以上线生产。在我的实验中,YOLOv6 最佳精度 0.9870 比 YOLOv5 最佳精度 0.9680 高出 1.9 %,故后续我们使用 YOLOv6 来进行讲解。
10. 模型推理
使用最佳的模型进行推理,下面命令中的最佳模型路径是 ./work_dirs/yolov6_s_syncbn_fast_1xb32-100e_cat/best_coco/bbox_mAP_epoch_96.pth,请用户自行修改为自己训练的最佳模型路径。
python demo/image_demo.py ./data/cat/images \./configs/custom_dataset/yolov6_s_syncbn_fast_1xb32-100e_cat.py \./work_dirs/yolov6_s_syncbn_fast_1xb32-100e_cat/best_coco/bbox_mAP_epoch_96.pth \--out-dir ./data/cat/pred_images

如果推理结果不理想,这里举例 2 种情况: 1. 模型欠拟合: 需要先判断是不是训练 epoch 不够导致的欠拟合,如果是训练不够,则修改 config 文件里面的 max_epochs 和 work_dir 参数,或者根据上面的命名方式新建一个 config 文件,重新进行训练。 2. 数据集需优化: 如果 epoch 加上去了还是不行,可以增加数据集数量,同时可以重新检查并优化数据集的标注,然后重新进行训练。
11. 模型部署
MMYOLO 提供两种部署方式:
- MMDeploy 框架进行部署
- 使用
projects/easydeploy进行部署
考虑到本部分细节较多,故不在本文说明,请跳转视频或者官方文档查看。
总结
本文从零开始教你如何基于 MMYOLO 训练一个可部署的检测模型,提供了 11 个完整步骤。用户在面对自定义数据集时候也可以按照这个步骤来逐条确认检查。
如果你对本文有任何好的建议,或者对 MMYOLO 有不同看法,欢迎留言反馈,或者直接联系微信小助手。
MMYOLO 官方地址: https://github.com/open-mmlab/mmyolo