MiniOB 是 OceanBase 联合华中科技大学推出的一款用于教学的小型数据库系统,希望能够帮助数据库爱好者系统性的学习数据库原理与实战。
B+ 树介绍
B+ 树是传统数据库中常见的索引数据结构,比如MySQL、PostgreSQL都实现了B+树索引。B+ 树是一个平衡多叉树,层级少(通常只有3层)、数据块(内部节点/叶子节点)大小固定,是一个非常优秀的磁盘数据结构。关于B+ 树的原理和实现,网上有非常多的介绍,就不在此聒噪。这里将介绍如何实现支持并发操作的B+树以及MiniOB中的实现。
B+树的并发操作
在多线程并发操作时,通常使用的手段是加锁,这里的实现方法也是这样。不过在学习并发B+树实现原理之前,需要对B+树的实现比较熟悉,有兴趣的同学可以网上搜索一下。
Crabing Protocol
在操作B+树时加对应的读写锁是一种最简单粗暴但是有效的方法,只是这样实现效率不高。于是就有一些研究创建了更高效的并发协议,并且会在协议设计上防止死锁的发生。
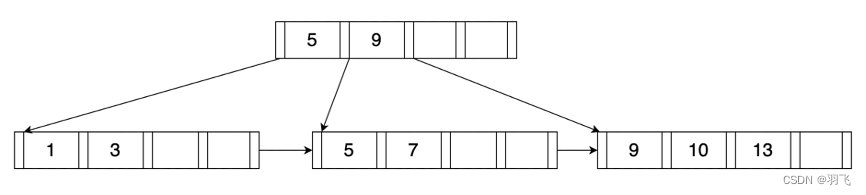
B+树是一个树状的结构,并且所有的数据都是在叶子节点上,每次操作,几乎都是从根节点开始向下遍历,直到找到对应的叶子节点。然后在叶子节点执行相关操作,如果对上层节点会产生影响,必须需要重新平衡,那就反方向回溯调整节点。
Crabing协议是从根节点开始加锁,找到对应的子节点,就加上子节点的锁。一直循环到叶子节点。在拿到某个子节点锁时,如果当前节点是“安全的”,那就可以释放上级节点的锁。
什么是“安全的”
如果在操作某个节点时,可以确定这个节点上的动作,不会影响到它的父节点,那就说是“安全的”。
B+树上节点的操作有三个:插入、删除和查询。
- 插入:一次仅插入一个数据。如果插入一个数据后,这个节点不需要分裂,就是当前节点元素个数再增加一个,也不会达到一个节点允许容纳的最大个数,那就是安全的。不会分裂就不会影响到父节点。
- 删除:一次仅删除一个数据。如果删除一个数据后,这个节点不需要与其它节点合并,就是当前节点元素个数删除一个后,也不会达到节点允许容纳的最小值,那就是安全的。不需要合并就不会影响到父节点。
- 查询:读取数据对节点来说永远是安全的。
B+树的操作除了上述的插入、删除和查询,还有一个扫描操作。比如遍历所有的数据,通常是从根节点,找到最左边的叶子节点,然后从向右依次访问各个叶子节点。此时与加锁的顺序,与之前描述的几种方式是不同的,那为了防止死锁,就需要对遍历做特殊处理。一种简单的方法是,在访问某个叶子节点时,尝试对叶子节点加锁,如果判断需要等待,那就退出本次遍历扫描操作,重新来一遍。当然这种方法很低效,有兴趣的同学可以参考[2],了解更高效的扫描加锁方案。
问题:哪种场景下,扫描加锁可能会与更新操作的加锁引起死锁?
问题:请参考[2],给出一个遍历时不需要重试的加锁方案。
MiniOB实现
MiniOB的B+树并发实现方案与上个章节描述的方法是一致的。这里介绍一些实现细节。
在这里假设同学们对B+树的实现已经有了一定的了解。
B+树与Buffer Pool
B+树的数据是放在磁盘上的,但是直接读写磁盘是很慢的一个操作,因此这里增加一个内存缓冲层,叫做Buffer Pool。了解数据库实现的同学对这个名词不会陌生。在MiniOB中,Buffer Pool的实现是 class DiskBufferPool。对Buffer Pool实现不太了解也没关系,这里接单介绍一下。
DiskBufferPool 将一个磁盘文件按照页来划分(假设一页是8K,但是不一定),每次从磁盘中读取文件或者将数据写入到文件,都是以页为单位的。在将文件某个页面加载到内存中时,需要申请一块内存。内存通常会比磁盘要小很多,就需要引入内存管理。在这里引入Frame(页帧)的概念(参考 class Frame),每个Frame关联一个页面。FrameManager负责分配、释放Frame,并且在没有足够Frame的情况下,淘汰掉一些Frame,然后将这些Frame关联到新的磁盘页面。
那如何知道某个Frame关联的页面是否可以释放,然后可以与其它页面关联?
如果这个Frame没有任何人使用,就可以重新关联到其它页面。这里使用的方法是引用计数,称为 pin_count。每次获取某个Frame时,pin_count就加1,操作完释放时,pin_count减1。如果pin_count是0,就可以将页面数据刷新到磁盘(如果需要的话),然后将Frame与磁盘文件的其它数据块关联起来。
为了支持并发操作,Frame引入了读写锁。操作B+树时,就需要加对应的读写锁。
B+ 树的数据保存在磁盘,其树节点,包括内部节点和叶子节点,都对应一个页面。当对某个节点操作时,需要申请相应的Frame,pin_count加1,然后加读锁/写锁。由于访问子节点时,父节点的锁可能可以释放,也可能不能释放,那么需要记录下某个某个操作在整个过程中,加了哪些锁,对哪些frame 做了pin操作,以便在合适的时机,能够释放掉所有相关的资源,防止资源泄露。这里引入class LatchMemo 记录当前访问过的页面,加过的锁。
问题:为什么一定要先执行解锁,再执行unpin(frame引用计数减1)?
处理流程
B+树相关的操作一共有4个:插入、删除、查找和遍历/扫描。这里对每个操作的流程都做一个汇总说明,希望能帮助大家了解大致的流程。
插入操作
除了查询和扫描操作需要加读锁,其它操作都是写锁。
- leaf_node = find_leaf // 查找叶子节点是所有操作的基本动作memo.init // memo <=> LatchMemo,记录加过的锁、访问过的页面lock root page- node = crabing_protocal_fetch_page(root_page)loop: while node is not leaf // 循环查找,直到找到叶子节点child_page = get_child(node)- node = crabing_protocal_fetch_page(child_page)frame = get_page(child_page, memo)lock_write(memo, frame)node = get_node(frame)// 如果当前节点是安全的,就释放掉所有父节点和祖先节点的锁、pin_countrelease_parent(memo) if is_safe(node)- insert_entry_into_leaf(leaf_node)- split if node.size == node.max_size- loop: insert_entry_into_parent // 如果执行过分裂,那么父节点也会受到影响- memo.release_all // LatchMemo 帮我们做资源释放
删除操作
与插入一样,需要对操作的节点加写锁。
- leaf_node = find_leaf // 查找的逻辑与插入中的相同
- leaf_node.remove_entry
- node = leaf_node
- loop: coalesce_or_redistribute(node) if node.size < node.min_size and node is not rootneighbor_node = get_neighbor(node)// 两个节点间的数据重新分配一下redistribute(node, neighbor_node) if node.size + neighbor_node.size > node.max_size// 合并两个节点coalesce(node, neighbor_node) if node.size + neighbor_node.size <= node.max_sizememo.release_all
查找操作
查找是只读的,所以只加读锁
- leaf_node = find_leaf // 与插入的查找叶子节点逻辑相同。不过对所有节点的操作都是安全的
- return leaf_node.find(entry)
- memo.release_all
扫描/遍历操作
- leaf_node = find_left_nodeloop: node != nullptrscan nodenode_right = node->right // 遍历直接从最左边的叶子节点,一直遍历到最右边return LOCK_WAIT if node_right.try_read_lock // 不直接加锁,而是尝试加锁,一旦失败就返回node = node_rightmemo.release_last // 释放当前节点之前加到的锁
根节点处理
前面描述的几个操作,没有特殊考虑根节点。根节点与其它节点相比有一些特殊的地方:
- B+树有一个单独的数据记录根节点的页面ID,如果根节点发生变更,这个数据也要随着变更。这个数据不是被Frame的锁保护的;
- 根节点具有一定的特殊性,它是否“安全”,就是根节点是否需要变更,与普通节点的判断有些不同。
按照上面的描述,我们在更新(插入/删除)执行时,除了对节点加锁,还需要对记录根节点的数据加锁,并且使用独特的判断是否“安全的”方法。
在MiniOB中,可以参考LatchMemo,是直接使用xlatch/slatch对Mutex来记录加过的锁,这里可以直接把根节点数据保护锁,告诉LatchMemo,让它来负责相关处理工作。
判断根节点是否安全,可以参考IndexNodeHandler::is_safe中is_root_node相关的判断。
如何测试
想要保证并发实现没有问题是在太困难了,虽然有一些工具来证明自己的逻辑模型没有问题,但是这些工具使用起来也很困难。这里使用了一个比较简单的方法,基于google benchmark框架,编写了一个多线程请求客户端。如果多个客户端在一段时间内,一直能够比较平稳的发起请求与收到应答,就认为B+树的并发没有问题。测试代码在bplus_tree_concurrency_test.cpp文件中,这里包含了多线程插入、删除、查询、扫描以及混合场景测试。
其它
有条件的开启并发
MiniOB是一个用来学习的小型数据库,为了简化上手难度,只有使用-DCONCURRENCY=ON时,并发才能生效,可以参考 mutex.h中class Mutex和class SharedMutex的实现。当CONCURRENCY=OFF时,所有的加锁和解锁函数相当于什么都没做。
并发中的调试
死锁是让人非常头疼的事情,我们给Frame增加了调试日志,并且配合pin_count的动作,每次加锁、解锁以及pin/unpin都会打印相关日志,并在出现非预期的情况下,直接ABORT,以尽早的发现问题。这个调试能力需要在编译时使用条件 -DDEBUG=ON 才会生效。
以写锁为例:
void Frame::write_latch(intptr_t xid)
{{std::scoped_lock debug_lock(debug_lock_); // 如果非DEBUG模式编译,什么都不会做ASSERT(pin_count_.load() > 0, // 加锁时,pin_count必须大于0,可以想想为什么?"frame lock. write lock failed while pin count is invalid. ""this=%p, pin=%d, pageNum=%d, fd=%d, xid=%lx, lbt=%s", // 这里会打印各种相关的数据,帮助调试this, pin_count_.load(), page_.page_num, file_desc_, xid, lbt()); // lbt会打印出调用栈信息ASSERT(write_locker_ != xid, "frame lock write twice." ...);ASSERT(read_lockers_.find(xid) == read_lockers_.end(),"frame lock write while holding the read lock." ...);}lock_.lock();write_locker_ = xid;LOG_DEBUG("frame write lock success." ...); // 加锁成功也打印一个日志。注意日志级别是DEBUG
}
欢迎提交issue和pull request
MiniOB 当前还是一个非常不完善的项目,包括覆盖的知识面、代码质量、注释、测试、开发环境等,都需要完善,欢迎开源爱好者一起共同建设。
参考
[1] 15445 indexconcurrency
[2] Concurrency of Operations on B-Trees
[3] MySQL/MariaDB mini trans相关代码