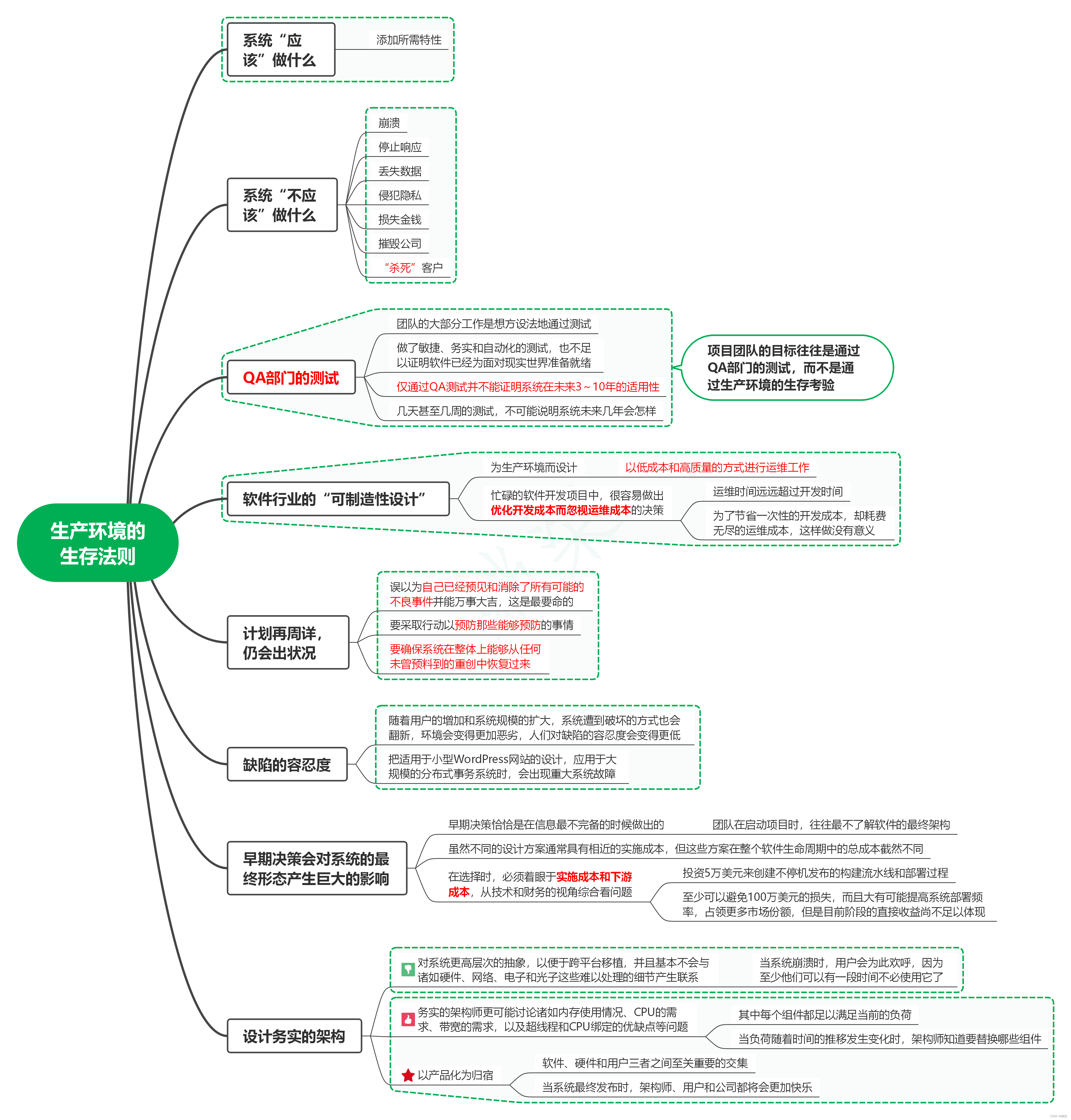
1. 系统“应该”做什么 1.1. 添加所需特性 2. 系统“不应该”做什么 2.1. 崩溃 2.2. 停止响应 2.3. 丢失数据 2.4. 侵犯隐私 2.5. 损失金钱 2.6. 摧毁公司 2.7. “杀死”客户 3. QA部门的测试 3.1. 团队的大部分工作是想方设法地通过测试 3.2. 做了敏捷、务实和自动化的测试,也不足以证明软件已经为面对现实世界准备就绪 3.3. 仅通过QA测试并不能证明系统在未来3~10年的适用性 3.4. 几天甚至几周的测试,不可能说明系统未来几年会怎样 3.5. 项目团队的目标往往是通过QA部门的测试,而不是通过生产环境的生存考验 4. 软件行业的“可制造性设计” 4.1. 为生产环境而设计 4.1.1. 以低成本和高质量的方式进行运维工作 4.2. 忙碌的软件开发项目中,很容易做出优化开发成本而忽视运维成本的决策 4.2.1. 运维时间远远超过开发时间 4.2.2. 为了节省一次性的开发成本,却耗费无尽的运维成本,这样做没有意义 5. 计划再周详,仍会出状况 5.1. 误以为自己已经预见和消除了所有可能的不良事件并能万事大吉,这是最要命的 5.2. 要采取行动以预防那些能够预防的事情 5.3. 要确保系统在整体上能够从任何未曾预料到的重创中恢复过来 6. 缺陷的容忍度 6.1. 随着用户的增加和系统规模的扩大,系统遭到破坏的方式也会翻新,环境会变得更加恶劣,人们对缺陷的容忍度会变得更低 6.2. 把适用于小型WordPress网站的设计,应用于大规模的分布式事务系统时,会出现重大系统故障 7. 早期决策会对系统的最终形态产生巨大的影响 7.1. 早期决策恰恰是在信息最不完备的时候做出的 7.1.1. 团队在启动项目时,往往最不了解软件的最终架构 7.2. 虽然不同的设计方案通常具有相近的实施成本,但这些方案在整个软件生命周期中的总成本截然不同 7.3. 在选择时,必须着眼于实施成本和下游成本,从技术和财务的视角综合看问题 7.3.1. 投资5万美元来创建不停机发布的构建流水线和部署过程 7.3.2. 至少可以避免100万美元的损失,而且大有可能提高系统部署频率,占领更多市场份额,但是目前阶段的直接收益尚不足以体现 8. 设计务实的架构 8.1. 对系统更高层次的抽象,以便于跨平台移植,并且基本不会与诸如硬件、网络、电子和光子这些难以处理的细节产生联系 8.1.1. 当系统崩溃时,用户会为此欢呼,因为至少他们可以有一段时间不必使用它了 8.2. 务实的架构师更可能讨论诸如内存使用情况、CPU的需求、带宽的需求,以及超线程和CPU绑定的优缺点等问题 8.2.1. 其中每个组件都足以满足当前的负荷 8.2.2. 当负荷随着时间的推移发生变化时,架构师知道要替换哪些组件 8.3. 以产品化为归宿 8.3.1. 软件、硬件和用户三者之间至关重要的交集 8.3.2. 当系统最终发布时,架构师、用户和公司都将会更加快乐