关注、点赞、收藏是对我最大的支持,谢谢^v^
目录
1. 背景介绍
2. 多通道信号的公式描述
3. 传统波束形成(delay-and-sum和filter-and-sum)
4. MVDR
4.1 传统MVDR
4.2 融入深度学习的MVDR
5. GEV(Generalized eigenvalue) beamformer
6. GSC(Generalized sidelobe canceler)
1. 背景介绍
波束形成是个很有意思的方向,应用从雷达领域到5G领域,近几年在语音识别领域也大放光彩。本文主要聚焦于波束形成在语音领域的应用。
对于单麦克风来说,没有波束的概念;波束形成主要针对多麦克风阵列,融合多个通道的数据,对噪声和干扰方向进行抑制,增强目标方向的信号。
一种方式是找到目标信号的方向,一般用导向矢量(steering vector)进行表示,基于此增强目标信号;一种方式是找到干扰信号的方向,进行抑制,剩下的就是目标信号。
2. 多通道信号的公式描述
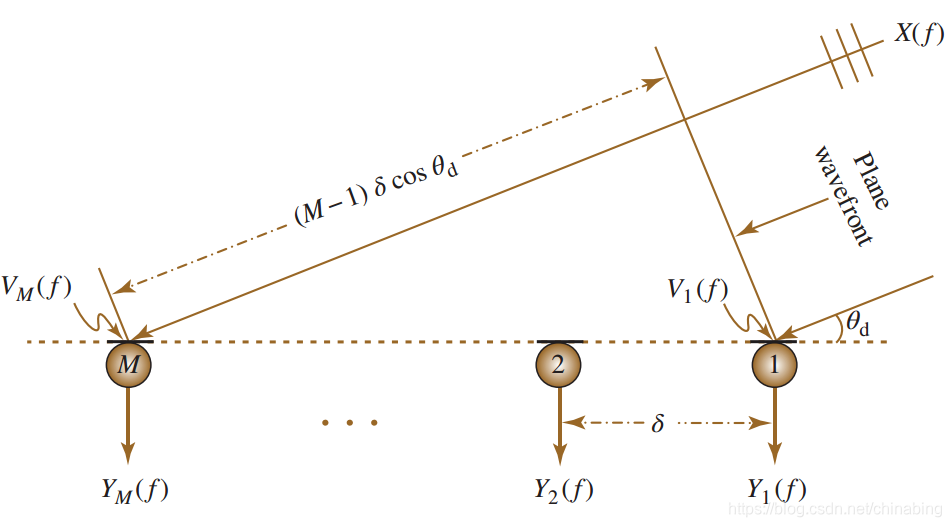
图1:M个麦克组成的线性阵列
观察信号的数学表达(频域形式)如下,这里的![]()
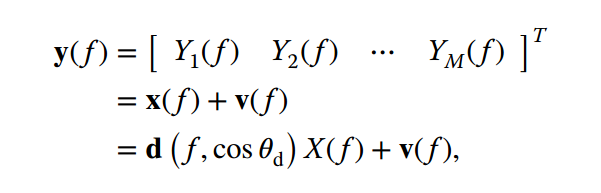
![]()
![]() 表示信号传到两个麦克之间的时间差,如果声音入射角是theta,还需要乘以
表示信号传到两个麦克之间的时间差,如果声音入射角是theta,还需要乘以,某频率的波传递了多少个周期,再乘以该波的频率
![]() 表示连续两个麦克风之间的相位差
表示连续两个麦克风之间的相位差
其实用表示相位差更容易理解,其中
表示频率f的波长
3. 传统波束形成(delay-and-sum和filter-and-sum)
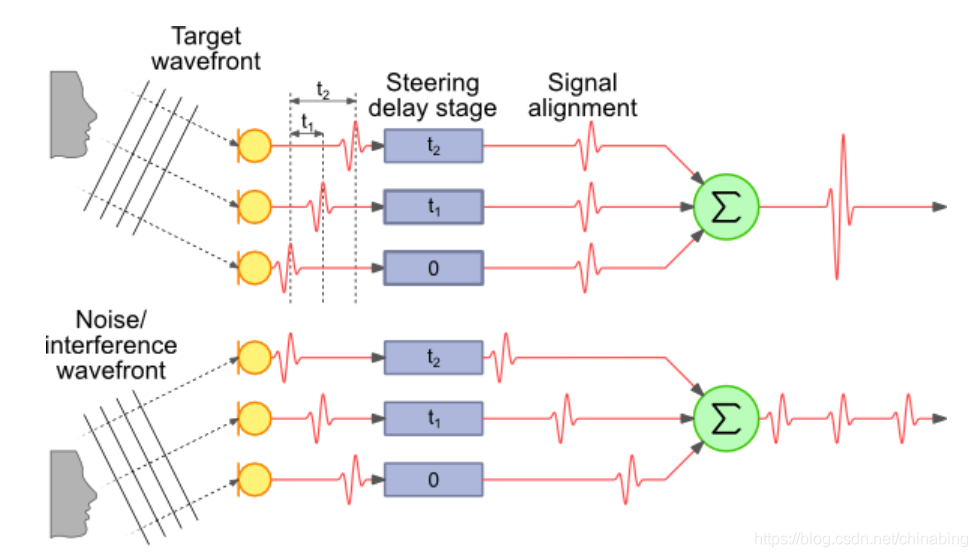
delay-and-sum: 传统的波束形成可以描述为一个空间滤波器,用该滤波器构建一个特定的波束方向图;可以分解为两步:时间对其和加权求和。时间对齐的物理意义在于,某一固定方向信号,传递到麦克风阵列时,不同麦克之间存在相位差,将信号理解为波,让波对齐,再加权求和就起到了增加信号的作用。时间对齐控制着波束方向,加权求和控制着主瓣的波束宽度和旁瓣的特性。
filter-and-sum: 它是上述delay-and-sum的扩展,将简单的delay操作用滤波filter操作代替,更具扩展性。
4. MVDR
4.1 传统MVDR
阵列采集信号:
目标:得到信号源的无偏、最小方差估计
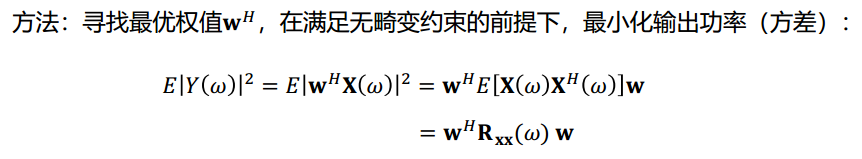
无畸变约束保证语音不失真,最小输出功率保证干扰噪声被最小化。
转换成带经典约束条件的凸优化问题:
最优解
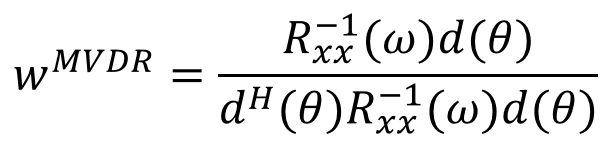
需要计算出导向矢量和协方差矩阵。
MVDR是一种自适应波束形成器, 而Delay-and-Sum是固定波束形成器。当各个通道的噪声互不相关, 并且具有相同功率的时候, MVDR退化成Delay-and-Sum。如果噪声是一个点声源, MVDR会自适应地在噪声方向形成一个零点。
4.2 融入深度学习的MVDR
引入深度学习的目的:更好的估计目标信号或噪声信号的协方差矩阵。


5. GEV(Generalized eigenvalue) beamformer
GEV同MVDR极为相似,不同之处在于目标准则,MVDR为最小化输出功率(在无畸变的约束下),GEV为最大化SNR。
该问题转换为广义特征值问题(generalized eigenvalue problem)
最优波束系数为广义主成分。
不同于MVDR,GEV波束形成器会引入语音失真。需要增加后置滤波(post-filter)。
6. GSC(Generalized sidelobe canceler)
Griffiths and Jim (1982)提出将MVDR分解为两个正交的波束形成器GSC,一个用于满足无畸变响应约束,另一个用于噪声功率最小化。
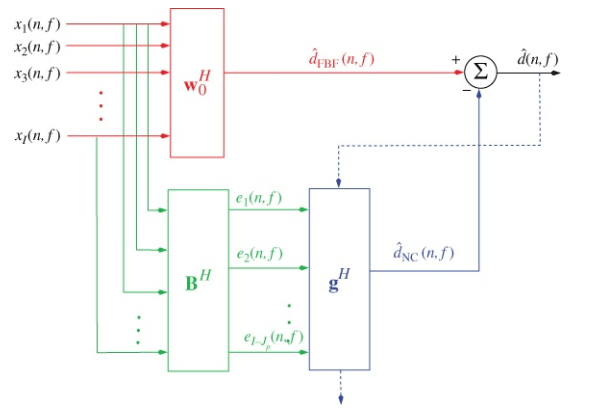
固定波束形成器
阻塞矩阵:为产生只包含噪声的信号
自适应噪声相消器:用于消除固定波束形成中的噪声信号
参考资料
[1] Fundamentals of Signal Enhancement and Array Signal Processing
[2] 麦克风阵列信号处理
[3] NEURAL NETWORK BASED SPECTRAL MASK ESTIMATION FOR ACOUSTIC BEAMFORMING
[4] Audio source separation and speech enhancement
关注、点赞、收藏是对我最大的支持,谢谢^v^