目录
1. 最大矩形 🌟🌟🌟
2. 反转链表 II 🌟🌟
3. 单词接龙 II 🌟🌟🌟
🌟 每日一练刷题专栏 🌟
Golang每日一练 专栏
Python每日一练 专栏
C/C++每日一练 专栏
Java每日一练 专栏
1. 最大矩形
给定一个仅包含 0 和 1 、大小为 rows x cols 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
示例 1:
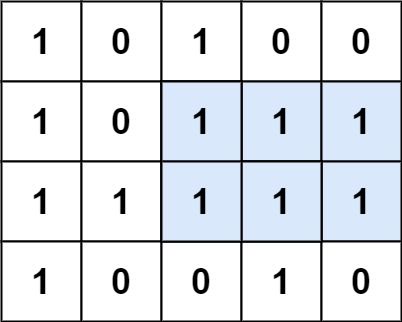
输入:matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]] 输出:6 解释:最大矩形如上图所示。
示例 2:
输入:matrix = [] 输出:0
示例 3:
输入:matrix = [["0"]] 输出:0
示例 4:
输入:matrix = [["1"]] 输出:1
示例 5:
输入:matrix = [["0","0"]] 输出:0
提示:
rows == matrix.lengthcols == matrix[0].length0 <= row, cols <= 200matrix[i][j]为'0'或'1'
出处:
https://edu.csdn.net/practice/23885007
代码:
from typing import Listclass Solution(object):def maximalRectangle(self, matrix):""":type matrix: List[List[str]]:rtype: int"""if matrix is None or len(matrix) == 0:return 0ls_row, ls_col = len(matrix), len(matrix[0])left, right, height = [0] * ls_col, [ls_col] * ls_col, [0] * ls_colmaxA = 0for i in range(ls_row):curr_left, curr_right = 0, ls_colfor j in range(ls_col):if matrix[i][j] == '1':height[j] += 1else:height[j] = 0for j in range(ls_col):if matrix[i][j] == '1':left[j] = max(left[j], curr_left)else:left[j], curr_left = 0, j + 1for j in range(ls_col - 1, -1, -1):if matrix[i][j] == '1':right[j] = min(right[j], curr_right)else:right[j], curr_right = ls_col, jfor j in range(ls_col):maxA = max(maxA, (right[j] - left[j]) * height[j])return maxA# %%
s = Solution()
matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]]
print(s.maximalRectangle(matrix))
matrix = []
print(s.maximalRectangle(matrix))
matrix = [["0"]]
print(s.maximalRectangle(matrix))
matrix = [["1"]]
print(s.maximalRectangle(matrix))
matrix = [["0","0"]]
print(s.maximalRectangle(matrix))
输出:
6
0
0
1
0
2. 反转链表 II
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
示例 1:
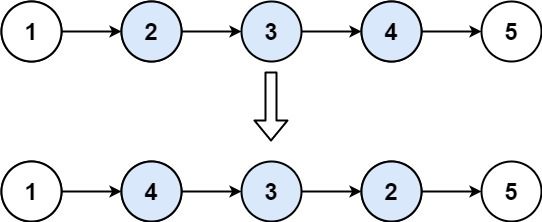
输入:head = [1,2,3,4,5], left = 2, right = 4 输出:[1,4,3,2,5]
示例 2:
输入:head = [5], left = 1, right = 1 输出:[5]
提示:
- 链表中节点数目为
n 1 <= n <= 500-500 <= Node.val <= 5001 <= left <= right <= n
进阶: 你可以使用一趟扫描完成反转吗?
出处:
https://edu.csdn.net/practice/23885008
代码:
class ListNode(object):def __init__(self, x):self.val = xself.next = Noneclass LinkList:def __init__(self):self.head=Nonedef initList(self, data):self.head = ListNode(data[0])r=self.headp = self.headfor i in data[1:]:node = ListNode(i)p.next = nodep = p.nextreturn rdef convert_list(self,head):ret = []if head == None:returnnode = headwhile node != None:ret.append(node.val)node = node.nextreturn retclass Solution(object):def reverseBetween(self, head, m, n):""":type head: ListNode:type m: int:type n: int:rtype: ListNode"""if m == n:return headsplit_node, prev, curr = None, None, headcount = 1while count <= m and curr is not None:if count == m:split_node = prevprev = currcurr = curr.nextcount += 1tail, next_node = prev, Nonewhile curr is not None and count <= n:next_temp = curr.nextcurr.next = prevprev = currcurr = next_tempcount += 1if split_node is not None:split_node.next = previf tail is not None:tail.next = currif m == 1:return prevreturn head# %%
l = LinkList()
list1 = [1,2,3,4,5]
l1 = l.initList(list1)
left = 2
right = 4
s = Solution()
print(l.convert_list(s.reverseBetween(l1, left, right)))
输出:
[1, 4, 3, 2, 5]
3. 单词接龙 II
按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一个表示此过程的 转换序列 是形式上像 beginWord -> s1 -> s2 -> ... -> sk 这样的单词序列,并满足:
- 每对相邻的单词之间仅有单个字母不同。
- 转换过程中的每个单词
si(1 <= i <= k)必须是字典wordList中的单词。注意,beginWord不必是字典wordList中的单词。 sk == endWord
给你两个单词 beginWord 和 endWord ,以及一个字典 wordList 。请你找出并返回所有从 beginWord 到 endWord 的 最短转换序列 ,如果不存在这样的转换序列,返回一个空列表。每个序列都应该以单词列表 [beginWord, s1, s2, ..., sk] 的形式返回。
示例 1:
输入:beginWord = "hit", endWord = "cog" wordList = ["hot","dot","dog","lot","log","cog"] 输出:[["hit","hot","dot","dog","cog"],["hit","hot","lot","log","cog"]] 解释:存在 2 种最短的转换序列: "hit" -> "hot" -> "dot" -> "dog" -> "cog" "hit" -> "hot" -> "lot" -> "log" -> "cog"
示例 2:
输入:beginWord = "hit", endWord = "cog" wordList = ["hot","dot","dog","lot","log"] 输出:[] 解释:endWord "cog" 不在字典 wordList 中,所以不存在符合要求的转换序列。
提示:
1 <= beginWord.length <= 7endWord.length == beginWord.length1 <= wordList.length <= 5000wordList[i].length == beginWord.lengthbeginWord、endWord和wordList[i]由小写英文字母组成beginWord != endWordwordList中的所有单词 互不相同
出处:
https://edu.csdn.net/practice/23885009
代码:
from typing import Listclass Solution:def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:import collectionsans = []steps = float("inf")if not beginWord or not endWord or not wordList or endWord not in wordList:return []word_dict = collections.defaultdict(list)L = len(beginWord)for word in wordList:for i in range(L):word_dict[word[:i] + "*" + word[i+1:]].append(word)queue = [[beginWord]]cost = {beginWord : 0}while queue:words_list= queue.pop(0)cur_word = words_list[-1]if cur_word == endWord:ans.append(words_list[:])else:for i in range(L):intermediate_word = cur_word[:i] + "*" + cur_word[i+1:]for word in word_dict[intermediate_word]:w_l_temp = words_list[:]if word not in cost or cost[word] >= cost[cur_word] + 1:cost[word] = cost[cur_word] + 1w_l_temp.append(word)queue.append(w_l_temp[:])return ans# %%
s = Solution()
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log","cog"]
print(s.findLadders(beginWord, endWord, wordList))
输出:
[['hit', 'hot', 'dot', 'dog', 'cog'], ['hit', 'hot', 'lot', 'log', 'cog']]
🌟 每日一练刷题专栏 🌟
✨ 持续,努力奋斗做强刷题搬运工!
👍 点赞,你的认可是我坚持的动力!
🌟 收藏,你的青睐是我努力的方向!
✎ 评论,你的意见是我进步的财富!
☸ 主页:https://hannyang.blog.csdn.net/
 | Golang每日一练 专栏 |
 | Python每日一练 专栏 |
 | C/C++每日一练 专栏 |
 | Java每日一练 专栏 |